基于倒置残差注意力的无人机航拍图像小目标检测
2023-03-31刘树东刘业辉孙叶美李懿霏王娇
刘树东,刘业辉,孙叶美,李懿霏,王娇
(天津城建大学 计算机与信息工程学院,天津 300384)
近年来,深度学习技术表现出优异的性能,基于深度学习的无人机航拍图像检测已被广泛应用于各行各业[1],如城市规划、环境监测和灾害检测等。由于无人机飞行高度变化较快、拍摄角度和位置具有特殊性,航拍图像具有背景复杂、小目标较多的特点,影响算法的检测精度,采用深度学习的方法提升目标检测精度仍需进一步研究。
基于深度学习的目标检测算法主要分为两阶段检测算法和单阶段检测算法2 类。其中,两阶段检测算法先生成候选区域,再对候选区域进行分类和定位,如R-CNN 系列[2-4]算法、Mask R-CNN[5]算法和Cascade R-CNN 算法[6]等,但这些算法在检测过程中存在候选区域,通常会产生较大的计算开销和计算成本。单阶段检测算法通过初始锚点框对目标预测类别并定位,可以在不进行候选区域的情况下完成端到端的目标检测,使得网络结构更加简单且快速运行,具有良好的实用性能,如YOLO 系列[7-10]算法、SSD[11]算法RetinaNet[12]算法等。与两阶段检测算法相比,单阶段检测算法具有较高的实时性,更能满足无人机航拍图像目标检测的需求。目前,基于单阶段检测算法的无人机航拍图像目标检测越来越受到人们的关注。Liu 等[13]基于YOLOv3检测框架提出UAV-YOLO,通过增加浅层卷积改善整个网络结构,丰富空间信息,但对于小目标存在漏检和误检问题。Liang 等[14]提出一种基于特征融合和尺度缩放的单阶段检测模型FS-SSD,利用反卷积模块和特征融合模块进行预测,并通过上下文分析进一步提高检测精度。Zhang 等[15]提出一种实时检测模型SlimYOLOv3,通过对YOLOv3 进行稀疏训练及通道剪枝的方式来减少模型的计算量和参数,以达到实时检测的效果,但对小目标的检测精度不高。裴伟等[16]提出一种改进的SSD 无人机航拍图像目标检测算法,通过提出的特征融合机制将网络的浅层视觉特征与深层语义特征进行有效结合,改善了SSD 算法存在的重复检测问题,但由于网络深度增大了计算量。刘婷婷等[17]在YOLOv3模型的基础上,通过轻量化主干网络和融合场景上下文信息提升检测精度,但对于小目标存在漏检情况。虽然目前算法在评价指标上取得了一定的提高,但仍存在小目标检测精度较低的问题。
目前,轻量化网络结构在几乎不影响性能的同时使得参数量明显下降,其主要采用深度可分离卷积(depthwise separable convolution, DS-Conv)和倒置残差结构实现。倒置残差结构[18-19]将残差块的“降维-提取-升维”转换为“升维-提取-降维”模式,能实现将特征图的通道进行扩张,丰富特征数量,进一步提升检测精度,减少深度卷积提取特征较少的问题。倒置残差注意力(inverted residuals attention,IRA)模块添加了基于通道注意力的压缩激励模块,提高了通道之间的相关性,提升了模型检测精度,在表面缺陷检测和隧道渗漏水检测方面均取得了良好的效果。刘艳菊等[20]提出一种具有实时性的钢条表面缺陷检测算法,利用倒置残差注意力优化YOLOv4 的特征提取网络,并采用K-Means 聚类加快收敛速度,有效提升了检测精度。周中等[21]提出一种基于语义分割的隧道渗漏水图像识别算法,利用倒置残差注意力对DeepLabv3+语义分割算法进行优化,在降低参数量的同时提升图像目标识别精度。在此基础上,本文在倒置残差注意力模块中添加有效通道注意力(efficient channel attention,ECANet)[22]模块,通过不降维的逐通道全局平均池化来减少信息丢失,并建立通道之间的依赖关系,更多地关注小目标特征。倒置残差(inverted residuals,IR)模块采用3×3 卷积替换深度可分离卷积,避免在获取丰富浅层特征的同时减少内存访问开销,并提升模型训练速度。
针对上述问题,本文提出了一种基于倒置残差注意力的无人机航拍图像小目标检测算法模型,改进YOLOv5x 特征提取阶段的CSPDarknet53(C3)模块以提升特征提取能力,设计多尺度特征融合(multi-scale feature fusion,MFF)模块以加强特征融合,设计马赛克混合(mosaic-mixup,MM)数据增强方法以实现数据增强,提升无人机航拍图像的检测精度。
1)设计倒置残差注意力C3(IRAC3)模块,利用倒置残差中“升维-提取-降维”的模式,进一步在倒置残差注意力模块中采用ECA-Net 模块,通过跨通道交互策略实现通道间的信息交流,减少信息丢失问题,并建立通道之间的依赖关系,突出感兴趣区域特征的表达能力,获取丰富的小目标的细节信息,并通过深度可分离卷积[23]的通道和特征区域分离降低模型参数量。设计倒置残差C3(IRC3)模块,倒置残差模块在倒置残差注意力模块的基础上采用3×3 卷积替换深度可分离卷积,在激活函数之前增加通道数,将低维特征映射到高维空间,提升浅层特征的提取能力,减少非线性激活函数造成的空间信息损失,获取丰富的小目标位置信息,在获取丰富浅层特征的同时减少内存访问开销,并提升模型训练速度。
2)设计多尺度特征融合模块,将提取的深层语义信息经过上采样放大后与浅层空间信息融合,生成用于极小目标的检测头,增强特征图中小尺寸目标的学习能力和对感兴趣区域的定位能力。通过结合3 个不同感受野的检测头,提升模型在多尺度目标下的识别能力,进一步减少小目标的漏检情况。
3)设计马赛克混合数据增强方法,利用4 张训练图像进行裁剪拼接,形成1 张新的训练图像,并将同一批次内不同的新的训练图像逐像素线性混合相加,建立数据样本之间的线性关系,增加数据集中图像的背景复杂度,提升数据集的泛化性,使模型可以在复杂背景的干扰下更专注于对目标物体的提取,提升了模型的鲁棒性。与YOLOv5x 算法相比,本文算法更好地适用于无人机航拍图像中小目标的检测。
1 本文算法
本文提出的基于倒置残差注意力的无人机航拍图像小目标检测算法包括特征提取模块与多尺度特征融合模块,整体模型结构如图1 所示。图中:SPP 为空间金字塔池化。首先,通过特征提取模块从输入图像中提取低级空间信息和高级语义特征;然后,利用多尺度特征融合模块将提取的多层次特征进行融合,获得不同尺度的检测头,生成密集的边界框,并预测类别分数;最后,采用非极大值抑制算法消除冗余的预测候选框,得到最终结果。
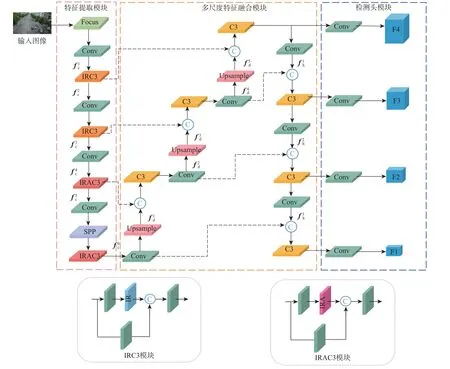
图1 基于倒置残差注意力的无人机航拍图像小目标检测模型结构Fig.1 Structure of small object detection in UAV aerial image based on inverted residual attention
1.1 特征提取模块
为进一步提高模型的特征提取能力,对YOLOv5x特征提取阶段的 C3 模块进行改进。将倒置残差模块嵌入到第3 层和第5 层的C3 模块中,称为IRC3 模块;将倒置残差注意力模块嵌入到第7 层和第10 层的C3 模块中,称为IRAC3 模块。通过引入本文设计的IRC3 模块和IRAC3 模块,提取不同尺度的特征,提高模型对特征的可分辨性,使得特征提取模块能够更有指向性地提取小目标的特征。
1.1.1 IRC3 模块
IRC3 模块利用倒置残差模块将残差块中“降维-提取-升维”转换为“升维-提取-降维”的模式,以获取丰富浅层空间中小目标的位置信息,模块结构如图2 所示。
倒置残差模块的网络结构如图2 中虚线框部分所示。首先,利用扩张因子 a(a=2)对输入特征图实现 C×a的通道数扩张,获取丰富的浅层特征;然后,利用线性变换实现高维到低维通道的映射,有效防止通道压缩时因非线性激活函数引起的特征信息丢失问题;最后,通过残差操作将恒等映射与输入特征相结合。
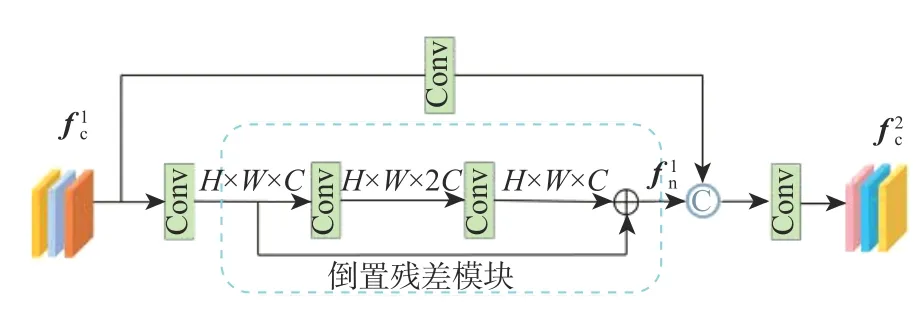
图2 IRC3 模块Fig.2 IRC3 module
对于输入的无人机航拍图像,首先通过卷积提取特征,获得的特征图 fc1可表示为

1.1.2 IRAC3 模块
IRAC3 模块中,设计倒置残差注意力模块(见图3),引入深度可分离卷积和ECA-Net 模块。首先,利用 k×k的卷积核对扩展后的特征图在二维平面内进行逐通道深度卷积(depthwise convolution, DConv)操作(见图4(a)),减少模型参数量。然后,通过ECA-Net 模块建立通道和权重的关系,突出小目标特征的显著性,通过跨信道交互的方式,在显著降低模块复杂度的同时增强特征的表达能力,提取更丰富的小目标区域语义特征,提升模型细节信息的提取能力。进一步,利用1×1 的卷积对特征图进行逐点卷积(pointwise convolution, P-Conv)操作(见图4(b)),将高维空间信息映射到低维空间,减少特征丢失。最后,进行随机深度(stochastic depth,SD)[24]计算,减少前向传播过程和梯度计算,缓解梯度消失现象,提高整体网络的泛化性。
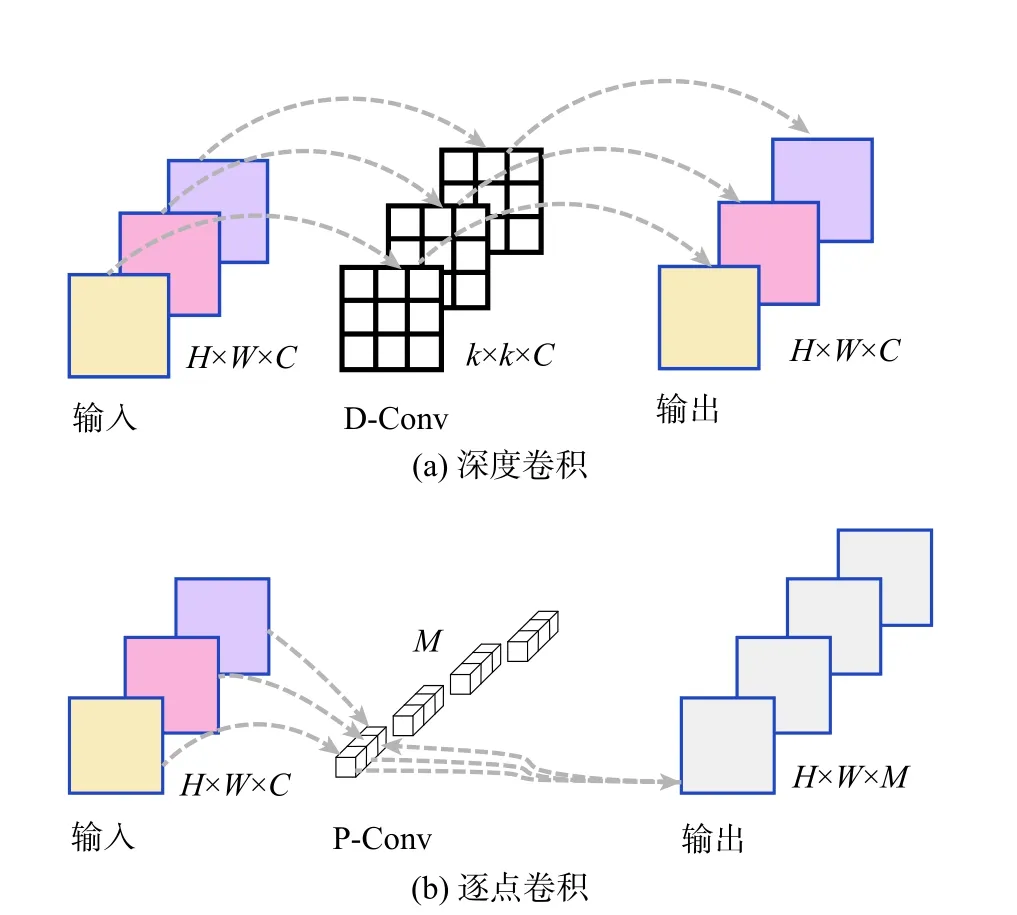
图4 深度可分离卷积模块Fig.4 Depthwise separable convolution module
倒置残差注意力模块的特征提取过程具体可分为如下4 步完成:

2)ECA-Net 模块如图5 所示,其提升了通道特征利用率,并突出了小目标的显著性。将特征图 fm2输入到ECA-Net 模块中,首先,该特征图在不降低维度的情况下进行逐通道全局平均池化(global average pooling, GAP),进而利用共享权重的快速一维卷积进行特征学习,在特征学习过程中通过当前通道及 k个邻域通道来捕获局部跨通道信息交互,其中,k为一维卷积核大小,同时也表示局部跨通道交互覆盖率;然后,通过sigmoid 激活函数获得相应通道的权重;最后,将其与输入特征相乘作为下一层的输入:
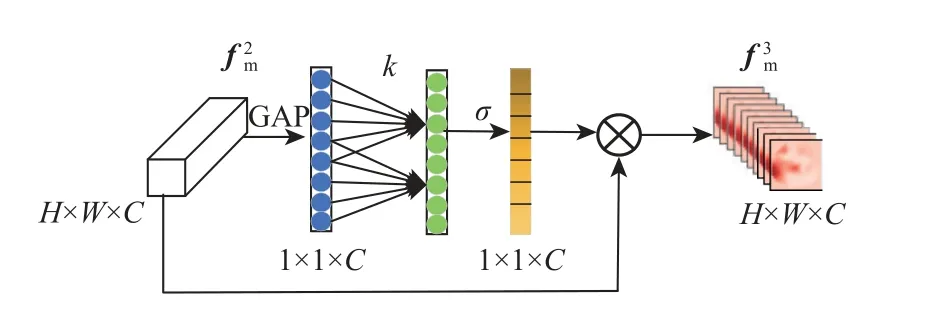
图5 ECA-Net 模块Fig.5 ECA-Net module

这种捕捉跨通道信息交互的方式选择性地增强特征,提高了模型对航拍图像细节信息的提取能力,进而提高模型的检测精度。
3)利用逐点卷积对特征图 fm3应用单个卷积核,来共同创建一个深度输出的线性组合,得特征图

式中:C 为输入通道数;M为输出通道数;PDS-Conv为深度可分离卷积的参数量;PConv为标准卷积的参数量;NP为倍数。

式中:R eLU 代表激活函数。当 bl=1时,将这2 部分求和后经过激活函数输出,当 bl=0时,残差部分没有被激活,整个结构为一个恒等映射:

1.2 多尺度特征融合模块
无人机航拍图像中小尺寸目标居多且目标之间比较密集,如图6 所示。按照相对尺寸大小,绘制了数据集中的目标分布图,如图7 所示。可以看出,目标分布图中的目标尺寸与图像尺寸相比小于0.12%的小目标数量占总目标数量的72%。浅层特征图分辨率较大包含空间特征细节更丰富,但感受野小所反映出的语义表征能力较弱。随着网络层数的加深,深层卷积在提取小目标特征信息时容易丢失关键位置信息,但感受野较大能获得高级语义信息。因此,为进一步加强模型对小目标的检测性能,本文提出了多尺度特征融合模块,将浅层空间信息和深层语义相融合。在多尺度特征融合模块中,在原始YOLOv5x 模型3 个检测头的基础上增加1 个检测头,生成了4 种不同尺度的检测头,分别用于无人机航拍图像中极小目标、小目标、中目标及大目标的检测。次经过C3 模块和卷积层获得特征图 F3,其特征图尺寸为原图像的 1/8,用于小目标的检测。同理,通过这种方式还可以获得特征图 F2 和 F1,其特征尺寸为原图像的 1/16 和 1/32,用于中目标和大目标的检测,特征图 F1、F2、F3、F4的具体过程如下:


图6 无人机航拍图像Fig.6 UAV aerial image

图7 目标分布图像Fig.7 Object distribution image
式中:FC3为C3 模块操作。
通过多尺度特征融合的方式,将浅层网络中丰富的位置信息和纹理信息更好地与深层网络的语义特征信息相融合,增强模型在小目标下的多尺度特征学习能力,从而提升模型在复杂场景下的小目标检测能力。
1.3 数据增强模块
为提升复杂背景干扰下的小目标检测精度,进而提升模型的鲁棒性,本文在YOLOv5x 原有的马赛克数据增强方法上增加混合[25]数据增强方法,采用马赛克数据增强和混合数据增强相结合的方式,称为马赛克混合数据增强方法。
该方法首先确定高为h、宽为w 的图像模板作为输出图像尺寸,同时在宽高方向随机生成2 条分割线,将选取的4 张图像按照图像模板经过随机裁剪后进行拼接操作。同理,再选取另外4 张图像进行随机裁剪并进行拼接,拼接后的图像形成新的训练样本。其主要利用随机裁剪丰富了数据集中目标的特征,使模型更易于学习,并通过拼接的方式保留了图像的目标特征,极大程度地丰富了检测目标的背景,有效减少了由于训练背景相似导致模型泛化性降低的问题。然后通过逐像素线性相加将2 类图像混合,融合示意图如图8 所示。该样本的混合过程是利用贝塔分布生成的融合系数进行图像融合,生成后的融合训练样本在尺寸上与原始的训练样本相同。本文通过阈值对生成的融合训练样本进行控制,由于在融合过程中每个批次样本都会随机产生相应的权重,而权重在 N个批次中的期望值近似为0.5,将本文阈值设置为0.5。融合过程为

图8 融合增强方法过程Fig.8 Fusion enhancement method process
式中:xi、xj代表同一批次内不同的训练样本;yi、yj分别对应该样本的标签;λ 为由参数 α、β的贝塔分布计算出的混合系数,服从 B eta(α,β)分 布;x˜为混合后的批次样本;y˜为混合后的批次样本对应的标签。
通过该方法生成的训练样本计算量小,且扩展了训练数据的空间分布,在保持检测速度不变的情况下,降低了不同分辨率下识别能力的衰弱速度,提高了模型对航空图像中目标检测的泛化性,提升了模型的鲁棒性。
2 实验结果与分析
2.1 数 据 集
本文在无人机航拍图像目标检测公开数据集Vis-Drone 上进行了训练和测试,该数据集包含10 209 张图像,其中,包括6 471 张训练集图像,548 张验证集图像,3 190 张测试集图像,并对10 个类别的对象进行了丰富的标注,包括行人(Pedestrian)、人(Person)、汽车(Car)、货车(Van)、公 共 汽 车(Bus)、卡 车(Truck)、摩托车(Motor)、自行车(Bicycle)、遮阳篷三轮车(Awning-tricycle)和三轮车(Tricycle)。该数据 集 的 图 像 分 为1 360×765 像 素 和960×540 像 素2 种不同的图像尺寸,本文使用验证集来评估提出的算法。
2.2 实验环境
实验采用的硬件环境为:GPU 为NVIDIA TITAN V12 GB,CPU 为 IntelXeon(R)Gold 5 115 CPU @2.40 GHz;软件环境为Windows7 操作系统,选用Pytorch 为深度学习框架。采用YOLOv5x 进行实验,分别在训练集和验证集上进行训练和测试,输入图像尺寸大小为832×832,批次为2,Epochs 为120,初始学习率为0.01,终止学习率为0.2,采用随机梯度下降策略,动量和权重衰减分别为0.937 和0.000 5。
2.3 评价指标
本文使用平均精度(AP)、平均精度均值(mAP0.5:0.95)和模型参数作为衡量模型性能的相关指标。AP 为单一类别检测精度的评价指标。对各类别的AP 值相加再除以类别数得到mAP。mAP0.5:0.95的计算方法是:设置10 个IoU 阈值,从0.5 到0.95,步长为0.05,并计算每个IoU 对应的mAP,再对所有mAP 求平均值。本文将mAP0.5∶0.95 简称为mAP。文中mAP0.5 为IoU=0.5 时的mAP,mAP0.75为IoU=0.75 时的mAP,IoU 为交并比。AP 和mAP计算过程如下:
式中:N 为类别个数;TP 表示正样本被正确标识为正样本,即真阳性;FP 表示负样本被错误标识为正样本,即假阳性;FN 表示正样本被错误识别为负样本,即假的负样本。
2.4 总体性能分析
为验证本文算法的有效性,针对不同模型进行了消融实验。模型1 只采用多尺度特征融合模块进行训练;模型2 在模型1 的基础上添加数据增强模块;模型3 在模型2 的基础上添加倒置残差注意力模块;模型4 在模型3 的基础上添加倒置残差模块,即为本文提出的最终模型。如表1 所示,所有实验在VisDrone 数据集上进行测试,分别以mAP、mAP0.5、mAP0.75、参数量及检测速度作为衡量标准。表中:FPS 表示帧/s。以原始YOLOv5x 为基准,分别添加相应的模块改进,通过对客观评价指标的计算比较不同模型性能。

表1 不同模型的客观指标对比Table 1 Comparison of objective indicators of different models
由表1 可以看出,模型1 在加入多尺度特征融合模块后,增强了模型在小目标下的多尺度特征学习能力,其mAP 相比于基准模型YOLOv5x 提高了1.2%,由于小目标检测层的增加,参数量略有提升,检测速度有所下降。模型2 相比模型1 的mAP 提高了0.8%,其参数量和检测速度基本不变,验证了数据增强模块的有效性。模型3 在加入倒置残差注意力模块后,其mAP 相比模型2 提升了1.4%,并且参数量降低了16.2×106,由于倒置残差注意力模块中深度可分离卷积具有大量数据读写操作,在检测速度方面略有降低。模型4 相比模型3,虽然参数量略有提升,检测速度略有降低,但mAP 提升了0.6%,进一步验证了在使用倒置残差注意力模块的基础上增加倒置残差模块的有效性。综上所述,在4 个模块同时加入时达到的效果最佳,mAP 相比于基准模型YOLOv5x 提升4.0%,参数量下降10.7×106,进一步验证了模型的有效性。
从图9 中可以看出,YOLOv5x 基准模型存在漏检情况,对小目标检测效果不佳,模型1 和模型2降低了部分小尺寸目标的漏检情况,仍存在漏检和误检问题。模型3 中误检问题减少,并进一步降低了小目标漏检情况,相比之下,模型4 达到了较好的检测效果,较大程度上降低了小目标漏检。
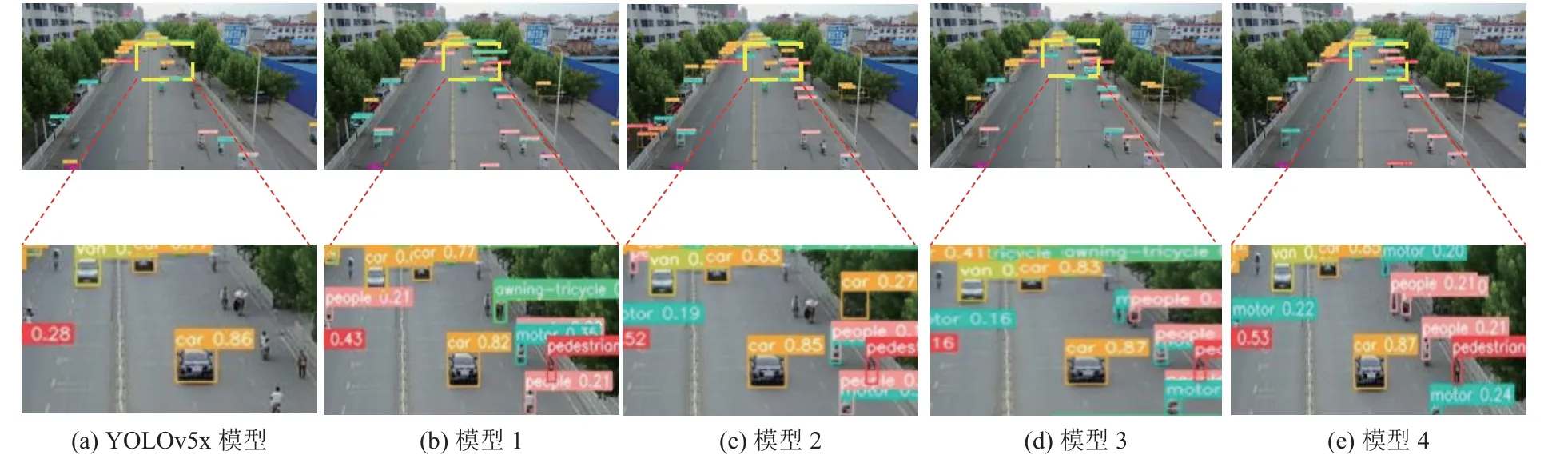
图9 不同模型检测结果Fig.9 Detection results of different models
2.5 算法对比分析
本节将本文模型与当前经典的RetinaNet、Faster R-CNN 和Cascade R-CNN 模型进行了比较,并与这些比较算法增加MMF[26]、SimCal[27]、BGS[28]和DSHNet[29]后的模型进行了比较。采用不同的主干网络(backbone),平均精度均值mAP 的对比结果如表2 所示。在检测速度方面,将本文模型与当前经典的RetinaNet、Faster R-CNN和Cascade R-CNN 在此基础上增加DSHNet 后的模型进行了比较,实验同样在VisDrone 数据集上进行训练,采用相同的验证集图像进行验证,在相同硬件环境NVIDIA TITAN V12 GB GPU 上进行测试,其模型的平均精度均值mAP 与检测速度的对比结果如表3 所示。视觉效果如图10 所示,展示了3 幅图像的检测结果及其部分放大图。
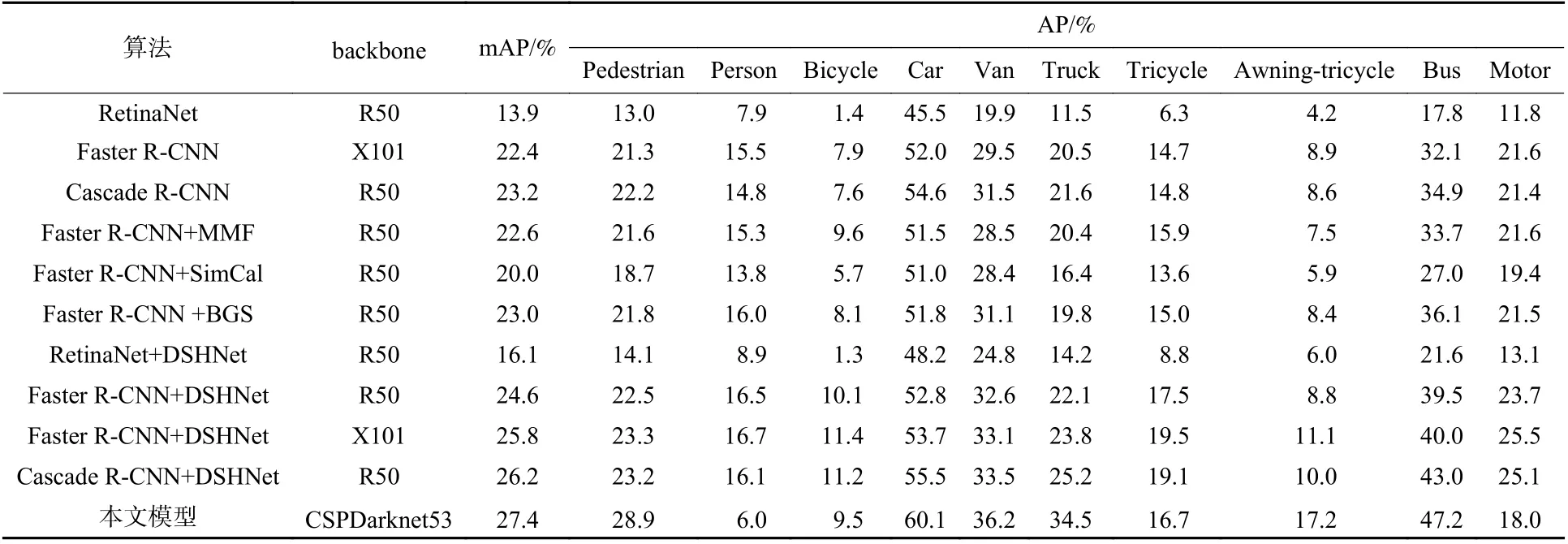
表2 不同算法的检测结果对比Table 2 Comparison of detection results of different algorithms
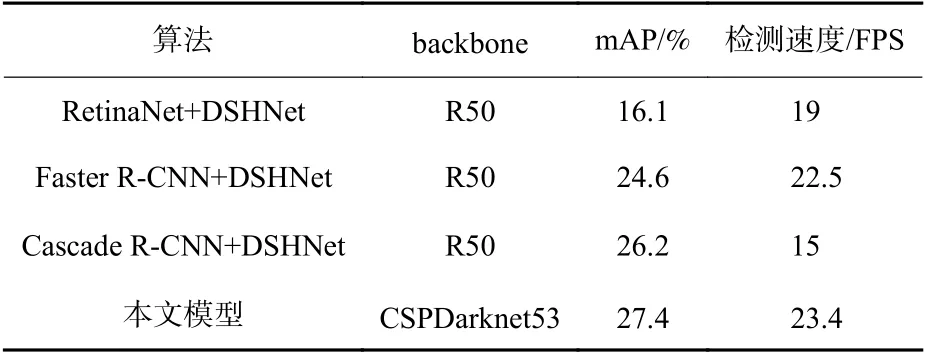
表3 不同算法的平均精度均值与检测速度结果对比Table 3 Comparison of average accuracy and detection speed of different algorithms
从表2 可以看出,在经典RetinaNet、Faster R-CNN和Cascade R-CNN 基础上增加DSHNet 模型后,客观评价指标较高;与DSHNet 模型相对比,本文模型取得了最优的综合性能。一方面,在行人、汽车、遮阳篷三轮车等小目标类别中取得了优秀的检测指标;另一方面,相比最优的DSHNet 模型,mAP 增长了1.2%。由表3 看出,本文模型在平均精度均值和检测速度方面均得到了有效提升。从图10 可以看出,对于小目标密集区域的检测结果,DSHNet 存在漏检情况,而本文模型能够在小目标密集区域充分挖掘其特征信息,对于小目标密集区域的检测结果要优于DSHNet 模型,降低了漏检情况,在处理无人机航拍图像目标检测任务时具有较大优势。

图10 三种模型检测结果Fig.10 Detection results of three models
2.6 结果分析
为进一步验证模型的有效性,图11 给出了本文模型在不同背景下的部分航空图像目标检测结果。其中,图11(a)为背景简单、目标单一时的检测结果及区域放大图;图11(b)为背景复杂、小目标密集时的检测结果及区域放大图。从图11 可以看出,对于以下这2 种情况,本文模型都可以较好地完成目标检测,对于场景复杂、目标较小的情况下仍能完全检测,没有出现汽车和行人的误检情况。综上所述,从主观视觉和评价指标来看,目标检测准确率有所提升,对于背景复杂、密集小目标的漏检情况有所改善。
3 结 论
针对无人机航拍图像中存在的小尺寸目标检测精度低的问题,本文提出一种基于倒置残差注意力的无人机航拍图像小目标检测算法。
1) 将倒置残差和倒置残差注意力模块添加到YOLOv5x 特征提取阶段的CSPDarknet53(C3)模块中,获取丰富的空间信息和语义特征,使模型更多地关注图像中的小目标区域,同时利用通道之间的信息交互增强了模型的特征表达能力,提升了小目标的检测精度。
2) 设计了多尺度特征融合模块,将不同感受野的浅层空间信息和深层语义信息相融合,有效改善了小目标的漏检问题。
3) 通过马赛克混合数据增强方法,对混合后的训练样本进行线性混合相加,丰富了训练样本的多样性,增强了模型在复杂背景干扰下目标特征提取的能力。
4) 实验结果表明,在背景复杂的情况下,本文算法对小尺寸目标具有更强的辨识能力,平均精度均值方面达到最优,相比DSHNet 算法提升了1.2%,减少了漏检和误检。
下一步将继续研究高效目标检测算法,保证精准度的同时,进一步提升检测的实时性。
