基于双模型识别的知识图谱可视化建模仿真
2023-03-29秦鹏,唐忠
秦 鹏,唐 忠
(1. 桂林学院理工学院,广西 桂林 541006;2. 广西医科大学信息与管理学院,广西 南宁 530021)
1 引言
计算机技术与信息技术水平飞速提升,网络应用呈多元化发展。在互联网的日益普及下,网络逐渐演变成信息与知识的主要获取渠道,但与日俱增的数据量、越来越复杂的内容与形式,都不断加剧着目标信息的寻找难度。为更便捷地找到目标信息,语义网、万维网等[1,2]搜索引擎层出不穷,其中,由语义网衍生出的知识图谱[3]最具研究价值与应用价值。知识图谱通过字符串符号映射,根据语义关系连接物理世界的实体与概念,形成有向或无向的语义网络。此种知识表达模式不仅可以实现知识间的智能推理,而且能为用户提供与检索词对应的实体结构化信息。
随着大数据时代的到来,知识图谱更是在诸多关键领域中发挥着重要作用,建构方案也成为热点研究课题。例如:电力领域中,郭榕等人[4]利用模式层、数据层等部分,架构出电网故障处置知识图谱,该方法通过综合运用TextCNN、LR-CNN、BiGRU-Attention等多种深度学习模型,有效解决了词错分、候选词冲突等问题,有效性与应用性较为理想;教育领域中,李永卉等人[5]利用Protégé软件,将本体转换为资源描述框架下的三元组数据,把映射至图数据结构上的数据储存至Neo4j图数据库中,得到诗词知识图谱,该方法充分发挥出检索、分析、应用等功能作用,有助于知识图谱得到进一步开发与探索。
可视化技术[6]的发展,使可视化知识图谱被广泛应用且优势显著,不仅能提升数据的直观性,而且便于查询等操作。因此,基于文献方法优势,采用深度学习技术,设计一种可视化知识图谱建构模型。该方法的研究重点如下:
1)jieba分词工具经动态规划找出最大词频组合,有助于实现高准确性与高效率性的知识图谱构建;
2)文本分类模型中注意力机制的加权属性,有助于提高全局信息的处理效果;
3)以深度学习的BiLSTM-CRF算法与BiGRU-Attention模型为基础,设计知识实体识别模型与实体关系识别模型,能更好地联立词向量与语义之间的联系,更精准地提取出实体关系,为知识图谱建构奠定基础。
2 可视化知识图谱建构模型整体架构
预处理待建图谱的数据集,利用知识实体识别与实体关系识别方法,结合开源的Neo4j图数据库[7],建立可视化知识图谱建构模型,如图1所示。该模型的四个主要部分是:数据源层、预处理层、识别层、建构层。

图1 可视化知识图谱建构模型
2.1 知识图谱数据预处理
针对数据集中存在缺失、冗余等问题的数据类型,采用清洗、分词、分类等处理手段,减少无效信息,为后续操作提供高质量数据集合,提升知识图谱建构效率。预处理方法的实现流程描述如下:
1)清洗:根据停用词表[8],直接去除符号、表情等无效字符串;对于信息项空白等缺失类数据,如果不能进行有效填充则去除;对于超文本标记语言标签、网络地址等冗余类信息,直接去除。
2)分词:该阶段的处理结果决定知识图谱的实用性与可靠性,采用jieba0.42.1版本中文分词工具[9]。经前缀词典词图扫描输入的句子,由隐马尔可夫模型[10]进行识别,通过维特比算法的动态规划计算,得到最优状态序列,完成分词处理。
假设t、t-1、t+1时刻下词i与词o的状态分别是it、ot、it-1、ot-1、it+1、ot+1,两词的初始状态与结束状态分别是i0、o0、ite、ote,则利用下列隐马尔可夫模型识别数据
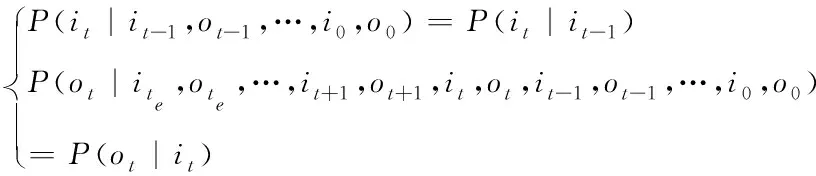
(1)
其中,P(·)表示词当前状态的受影响指数;{it-1,ot-1,…,i0,o0}表示词i与词o的历史状态;{ite,ote,…,it+1,ot+1,it,ot,it-1,ot-1,…,i0,o0}表示两个词从初始到结束的全部状态。
通过维特比算法动态规划计算识别模型,查找出最优状态序列。已知词i、o、ι、j,若t时刻下词i的单路径集合是{i1,…,it},则该集合中的最大概率求解公式如下所示:
ιt(i)=max{i1,…,it}P(it-1,ot-1,…,i0,o0|λ)
(2)
其中,λ表示任意词的任意状态。
由此推导出词ι的递推公式
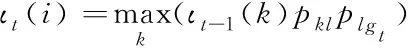
(3)
其中,k、l表示词的两种状态,pkl表示两状态间的转移概率;g表示词的观察状态,plgt表示t时刻下词状态从l状态转变为观察状态的概率。
针对t时刻下词i的单路径集合,利用下列公式得出词频最大的前n个词
jt(i)=arg max(ιt-1(k)pklplgt)
(4)
则t+1时刻下词i的动态规划结果如下所示
i′t+1=arg max(ιt(i))=jt+2(i)
(5)
经整合,得到由n个词构成的分词序列表达形式,如下所示
I=(i′1,i′2,…,i′n)
(6)
3)分类:基于深度学习的卷积神经网络[11],构建分类模型。分类流程如下所述:
①输入层:输入经过分词处理的数据;
②卷积层:假设句子m中的词τ经嵌入式表示法[12]处理后,得到词向量xmτ,通过双向循环神经网络[13],取得正反方向的两种特征编码h′mτ、h″mτ,如下所示

(7)
③池化层:融合注意力机制[14]与双向门控循环神经网络[15],构建双层级网络层,针对词与句子对语义影响的权重比,提取特征。根据卷积层得到的特征编码h′mτ、h″mτ,利用tanh激活函数,取得基于注意力机制的词向量x′mτ,通过下列sigmoid激活函数求解其权值ωmτ

(8)
其中,x′表示融入注意力机制的任意词向量。
根据所得权重ωmτ与特征编码h′mτ、h″mτ,生成句子m的双向特征编码h′m、h″m,如下所示
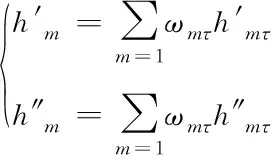
(9)
结合sigmoid函数解得的句子权值ωm与网络的隐藏层信息,得到数据的句向量,如下所示
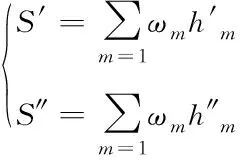
(10)
④全连接层:拼接所得全部句向量,得到全连接层的输出项(S′|S″);
⑤softmax函数层:利用该网络层的二分类模型,完成数据分类
L=softmax(ωS′|S″×(S′|S″)+b)
(11)
其中,ωS′|S″表示输出项(S′|S″)的权值,b表示偏置项。
2.2 基于深度学习的知识实体识别
在深度学习的BiLSTM-CRF算法[16]中,添加BERT模型[17],建立知识实体识别模型,加强语义关联度。模型实现知识实体识别的步骤如下所述:
1)输入层:把预处理过的语料集输入知识实体识别模型;
2)BERT层:采用BERT模型的自注意力机制函数Att(·)取得字向量,作为下一层的输入项
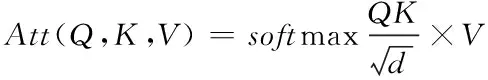
(12)
其中,Q、K、V分别表示字向量矩阵,d指代矩阵Q、K的组合维度。
3)编码层:经双向长短时记忆网络[18]处理,完成数据编码。假设t时刻下记忆单元c、遗忘门f、输入门r、输出门R的输出结果分别是tanh(ct)、ft、rt、Rt,则通过下列公式得到编码项ht
ht=ftrtRttanh(ct)
(13)
4)解码层:该层通过条件随机场模型[19]实现解码处理,提升知识实体的识别准确度。若输入序列与输出标签序列各是X、Y,yq、yq+1分别为序列Y中的两个连续标签,则知识实体的分值s由下式解得
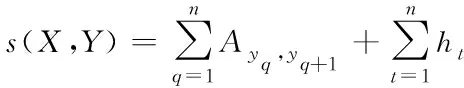
(14)
其中,Ayq,yq+1表示两标签间的转移矩阵。
Y′=argmaxs(X,)
(15)
5)softmax层:利用式(11)分类处理所有实体;
6)输出层:训练模型,用取得的最优模型,输出测试集的知识实体识别结果。
2.3 基于深度学习的实体关系识别
面向BiGRU-Attention模型,引入BERT模型,构建双注意力机制的实体关系识别模型,在保留关键数据的前提下,提高实体关系的识别准确度。实现流程分为以下六个步骤:
1)输入层:在模型中输入待识别的知识实体;
2)嵌入层:利用BERT模型构建实体向量,经词嵌入与位置嵌入处理,传输至下一层;
3)编码层:假设t时刻下双向门控循环单元网络的隐藏状态及权重为ut、ωut,则所得输出编码h′t的表达式如下所示
h′t=sigmoid(ωut×ut+b)
(16)
4)机制层:运用双重注意力机制与式(8)~(10),得到句向量;
5)分类层:利用式(11)分类句向量;
6)输出层:重复运行第2)~第4)步,训练模型,针对测试集,得到最优模型输出的实体关系识别结果。
2.4 知识图谱可视化实现
为实现知识图谱可视化,将识别的知识实体与实体关系储存至Neo4j图数据库中,绘制知识图谱。绘制流程如图2所示。

图2 知识图谱可视化实现流程图
3 实验研究
3.1 数据集与评价指标选取
从百度开放数据集的人工标注数据集合中随机抽取1000句中文语料,作为知识图谱的建构对象。将前300句与后700句分别作为模型的测试集与训练集。通过不断训练、更新,得到本文模型中两个识别模型的最优参数,如表1所示。

表1 建构模型参数设置

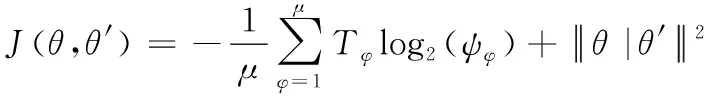
(17)
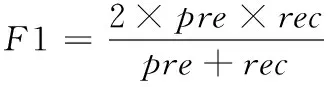
(18)
其中,模型的准确程度与对数损失函数指标呈正相关,J(θ,θ′)值越大,模型建构的知识图谱越精准;模型的有效程度与F1指标呈正相关,F1值越高,模型性能越好。
3.2 知识实体识别效果分析
图3为不同方法下损失函数随迭代次数变化的曲线走势图。
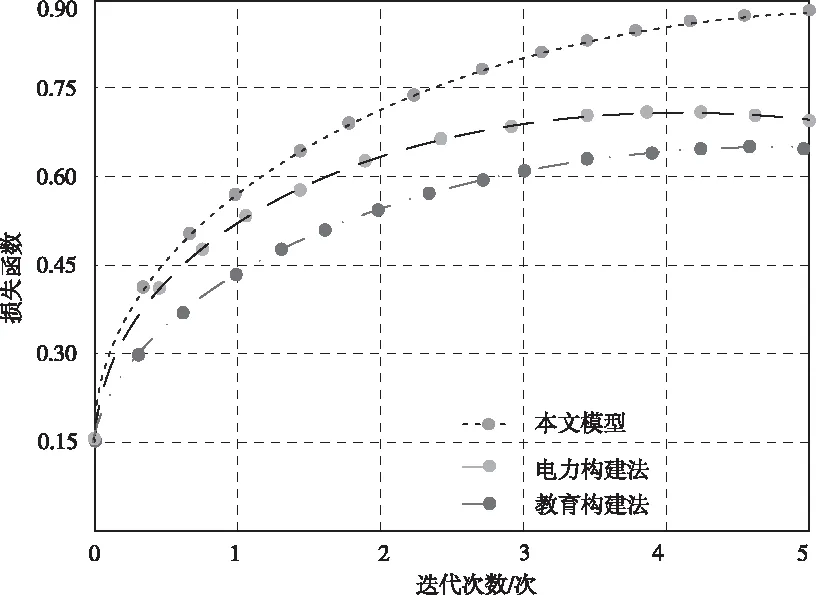
图3 不同方法的知识实体识别效果评估示意图
根据图3可以看出:本文模型的指标值与迭代次数之间存在一定的线性关系,提升幅度较大且速度较快;而对比方法则因领域限制,指标值始终低于本文模型。这说明当迭代至一定次数后,本文模型即可根据预处理后的高质量数据集,通过在BiLSTM-CRF算法中添加BERT模型,精准识得知识实体。
3.3 实体关系识别效果分析
表2为实体关系正确识别数量对比结果,图4为F1值对比结果。
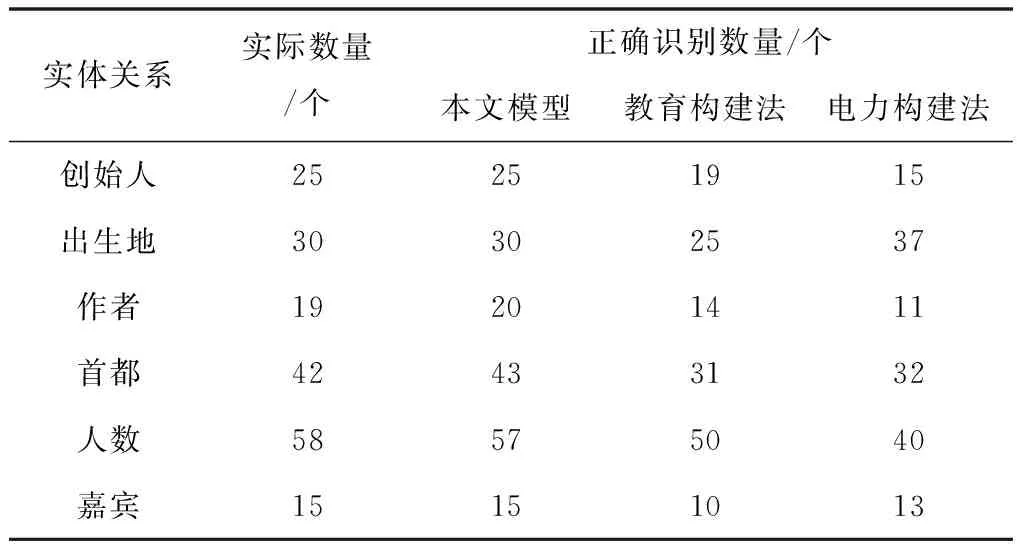
表2 正确识别数量
从表2中的数据可以看出:对于正确识别数量指标,本文模型仅在作者、首都及人数三类关系上,各出现一次错识别情况,而对比方法则因较强的领域性与针对性,仅识别出极少部分实体间的关系。
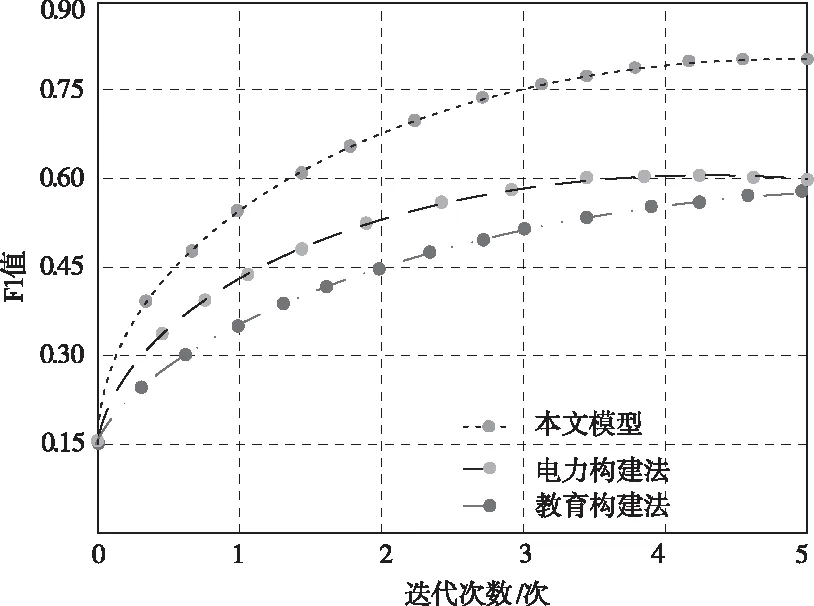
图4 不同方法的实体关系识别效果评估示意图
根据图4可以看出:对于F1值,各方法的数值变化走势与实体关系识别环节的实验结果大同小异。以上分析说明,本文通过融合BiGRU-Attention模型与BERT模型,建立双注意力机制的实体关系识别模型,在保留关键数据的前提下,使词嵌入与位置嵌入处理得以有效开展,令词向量与语义间的关联更加紧密,因此,既取得了优越的实体关系识别效果,还拓宽了该模型的应用范围与发展前景。
4 结论
知识图谱作为高效的知识表达模型,在人工智能技术的推动下,得以广泛应用。不论是在个性化推荐领域还是数据挖掘领域中,知识图谱通过让计算机学习人的语言交流方式,快速获取目标知识间的逻辑关系,令反馈给用户的信息更具智能性。因此,对知识图谱建构技术展开研究意义重大。尽管本文模型适用性较强,但仍存在以下几个不足之处:选用的分词工具对于英文文本不具备良好的适用性,应尝试采用对中英文均具有较高准确度的分词工具,打破模型的语料限制;实验数据量较少,今后应针对大规模数据集建构知识图谱,探究模型的处理效果;将图谱后续使用场景对建构模型的影响作为下一阶段的研究方向。
