改进强化学习的AI远程终端用户身份识别仿真
2023-03-29魏雨东张瑞瑞
魏雨东,张瑞瑞
(1. 电子科技大学成都学院,四川 成都 611731;2. 四川农业大学,四川 成都 611800)
1 引言
云计算与互联网的迅猛发展背景下,AI远程终端的应用数量与日俱增[1],已经成为网络远程操作的关键性技术,且绝大多数用户也将个人隐私数据保存在终端内,远程终端用户身份安全也成为了相关领域研究人员关注的热点[2]。身份识别技术是保证用户数据隐私安全的重要技术,但目前的远程终端身份识别拥有易丢失、易伪造等缺陷[3],针对该问题,该领域学者对该问题进行了深入研究。
胡宏宇等人[4]提出了基于一维卷积神经网络的身份识别方法。采集不同条件下的状态数据集,构建出一维卷积神经网络身份识别模型,利用Adam算法、L2正则化等方法改进模型性能。但由于该方法涉及了大量数据运算步骤,占据较多系统资源。张梦菲等人[5]提出了一种基于动机感知的用户识别算法。引入用户行为动机感知策略,初次匹配阶段采用启发式规则分类用户数据,实时研究用户访问动机,根据用户行为相异数矩阵,完成用户身份识别。但由于该方法没有考虑用户数据动态变化问题,导致得到的用户身份识别结果准确度不高。
为进一步解决上述已有方法的应用弊端,提出了一种基于强化学习的AI远程终端用户身份识别方法。强化学习因其探索学习能力成为了机器学习领域应用最广泛的技术之一[6],是实现人工智能灵活运用的核心步骤。分析用户终端行为类别,利用客户端采集用户身份数据,使用小波阈值法过滤冗余数据,通过强化学习中的Q-Learning学习法实现高精度AI远程终端用户身份识别,保证用户数据安全。
2 远程终端用户行为种类划分
为准确识别终端用户身份,首先深入研究用户终端行为,用户终端行为不但数量庞大,且行为特征呈多样化趋势,依照用户操作过程中可能具备的习惯,把用户行为特征划分成如下几类:
1)解锁行为
用户操作AI远程终端的首个步骤就是解锁,当前的解锁方式通常为指纹、人脸及密码。应用较多的为指纹与密码,不同用户的行为习惯也各不相等。此类特征对评估用户合法性极为重要,譬如恶意用户入侵远程终端后,使用暴力破译获得终端解锁密码,则可以通过多次使用密码登录的状况来判断该用户为恶意用户。与此同时,解锁行为在不同时段的频率也不相同[7],正常状态下有比较显著的规律,譬如周一至周五,白天解锁频率会比周末多,假如此时段终端解锁量较少,则当前用户很大概率为恶意用户。
2)网络行为
用户按照自身生活作息,使用网络也呈现特定规律。休息时不会过多登录远程终端,无法产生较多网络使用量,IP地址比较固定。倘若休息期间恶意用户入侵云端数据,会产生大量流量,此时就能评估用户身份是否合法。
3)操作行为
用户使用远程终端时,某个软件被点击的数量、应用时间均呈现出用户的操作习惯,若出现某种与日常行为不匹配的情况,极有可能是攻击者获得终端权限造成的。
4)通信行为
通信行为涵盖终端通话与信息传输行为,为确保用户隐私,本文仅统计使用次数,不牵涉通信者个人隐私。信息传输行为包含极大不确定性[8],目前诸多网络广告均会通过信息进行数据推送,不是用户主动产生的行为。
3 AI远程终端用户身份数据采集
明确远程终端用户行为种类后,需全面采集用户身份数据,为后续用户身份识别任务提供可靠支持。AI远程终端数据采集共有两种方式:服务器端采集、客户端采集。服务器端日志分析是当前使用次数最多的用户身份数据采集模式[9],利用Web服务器日志文件内的超文本传输协议统计用户访问数据。不同日志格式略有差异,但多数被划分为日常格式与拓展格式。日常格式涵盖用户ID、服务器IP地址等数据,服务器日志格式详细信息如表1所示。拓展格式不但涵盖日常格式的字段,还具备浏览器版本、操作系统等必备数据。

表1 服务器日志格式
用户身份数据采集的难点为既要采集终端实时信息,还不能影响远程终端稳定运行。倘若使用服务器端数据采集策略,会占用服务器较多系统资源[10],影响用户操作体验。客户端数据采集模式很好地避开上述缺陷,能及时采集用户身份信息,并汇总最新的终端网络状态数据。
用户在终端的浏览行为可采用一组属性来描述,涵盖用户ID、访问页面地址、页面标题等,通过此种策略,用户身份都能通过用户访问表内的记录来表示,将用户浏览操作定义成:
InforUser=〈IP,Cookie,url,title,starTm,
terminalTm,readTm,state,lastUrl〉
(1)
式中,IP代表访问IP地址,Cookie是浏览器,url表示服务器访问页面网址,title表示服务网站界面标题,starTm是浏览初始时间,terminalTm是浏览终止时间,readTm是浏览停留时间,state为页面状态数据,lastUrl是上一个页面地址。
通过式(1)就能得到用户唯一标识信息,阐明用户使用远程终端的具体经过,得到用户浏览行为与相关身份信息,将信息传输至中心服务器,并录入终端数据库,实现用户身份数据采集全过程。
4 强化学习下AI远程终端用户身份识别
4.1 用户身份数据预处理
根据采集的用户身份数据,本节通过小波阈值去噪手段进行数据预处理[11],保证数据直观性与完整性。假设初始数据为a(n),被噪声干扰后的数据是b(n),则将噪声模型表示为
b(n)=a(n)+δc(n)
(2)
其中,c(n)为噪声因子,δ为噪声强度。
倘若c(n)为高斯白噪声,且δ值为1,小波去噪的目标就是从含噪数据b(n)中剔除噪声c(n),恢复至初始数据a(n)。分析可知,数据通过小波变换后,噪声的小波指数幅值会伴随小波分解尺度的增多而快速降低,但有效数据小波指数的幅值没有明显改变。小波阈值去噪就是挑选恰当的阈值对小波指数采取阈值处理,将小于此阈值的小波指数判定为噪声相对的小波系数,设定为0,保存大于此阈值的小波指数,将其看作有效信号相对的小波指数。
小波阈值去噪流程为:挑选一个小波基对数据采取N层小波分解,利用恰当阈值与阈值函数分解第一层至第N层的高频指数,保存第N层小波分解的全部低频指数,利用保存的小波指数重构用户身份数据。
实际计算中,对数据的小波分解多数使用离散小波变换,执行离散小波变换最可靠的为Mallat方法,将该方法下小波分解公式记作
(3)
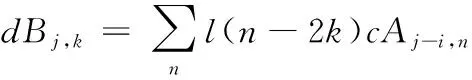
(4)
其中,dAj,k、dBj,k均为j尺度下的展开指数,dAj,k为信号a(n)在j尺度中的低频部分小波指数,dBj,k为信号a(n)在j尺度中的高频部分小波指数,g(·)、l(·)均为滤波器指数。
和数据的小波分解及重构相比,阈值与阈值函数的选择更加重要,阈值使用Donoho统一阈值,将其定义为式(5)。式中,M表示用户数据集。
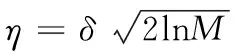
(5)
阈值函数分为硬阈值与软阈值,综合评定应用环境,将软阈值看作用户身份数据去噪阈值函数,并输出去噪后的身份数据,软阈值公式为
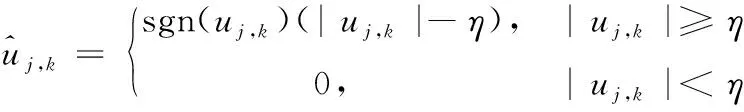
(6)
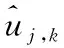
4.2 用户身份识别
强化学习的基本思路为智能体和环境交互时,依照环境反馈获得的奖励持续调节自身策略以完成最优决策[12],可用于处理数据识别工作。基于强化学习的用户身份识别算法中,将Q-Learning学习运用在身份识别,设定一个用户行为特征子集,行为列表内涵盖加入与消除两个模式[13]。设置AI远程终端用户行为数据集为
X=(Xji)O×Q
(7)
其中,X代表用户数据集函数,(Xji)O×Q为O个用户行为与Q个样本特征。由此,将用户行为样本的种类记作
F=(fj)O×1
(8)
其中,F代表远程终端用户行为样本个数,fj为AI远程终端下用户各类行为的身份样本。
在用户数据库内提取用户身份标识信息[14],即准确的用户身份数据。假设终端用户样本数据集是(F1,F2,…,FO),则用户身份行为特征集合是(r1,r2,…,rn)。把特征集合(r1,r2,…,rn)引入强化学习算法中,初始化用户行为特征子集,并把备选特征集合表示成
T=(r1,r2,…,rn)2
(9)
在备选特征集合T内随机择取一个用户身份特征W,推算特征子集识别精度SW,得到当前用户身份特征子集R的相关指数最大特征。随机挑选用户数据库内的特征Z,推导用户行为特征子集的识别精度SZ,则SW与SZ之间的耦合关系为
qSW>SZ:R←R∪{W},T←T/{W}
(10)
qSW>SZ:R←R∪{Z},T←T/{Z}
(11)
其中,q表示行为变换指数。
判断当前输出结果是否满足终止条件,若满足条件,将计算结果与保存的标志信息进行对比[15],对比成功则允许用户访问,失败则拒绝用户访问,以此完成期望远程终端用户身份识别。
5 仿真研究
5.1 仿真环境与指标的设置
为表明所提方法可行性,对其进行仿真分析,因没有公开的用户身份数据集,本次实验中采用的数据集是从Facebook上爬取的数据集,包含1587名用户,17493个链接,共发出302189条消息。仿真平台为MATLAB,在该平台上构建AI远程终端模型,利用该模型完成仿真。
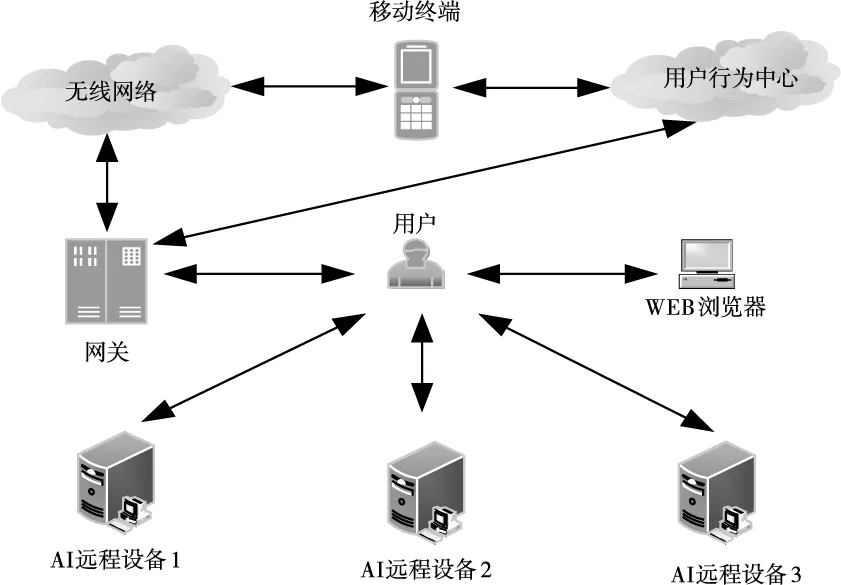
图1 AI远程终端仿真模型
在所构建的AI远程终端仿真模型中,涉及本次实验。利用精准度、召回率、F1值、先验种子节点与识别效率五个指标判断方法用户身份识别性能,并将文献[4]提出的基于一维卷积神经网络的身份识别方法与文献[5]提出的一种基于动机感知的用户识别方法作为对比方法。
精准度是正确性的度量指标,用来描述识别为正样本中具备多少真正的正样本,其计算式为
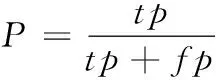
(12)
其中,tp表示被识别为正确且最终为正确的数据量,即成功匹配的用户身份个数;fp被识别为正确且最终错误的数据量,即错误识别用户。
召回率是整体性度量指标,表示样本内的正例可以被识别的个数,计算公式为

(13)
其中,fn表示被识别为错误且最终正确的数据量,即被忽略的可识别用户。
F1值为召回率与精准度的平均值指标,F1值越大,表明方法用户身份识别性能越好,计算式为
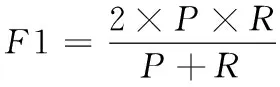
(14)
5.2 实验结果分析
三种方法精准度、召回率、F1值实验对比结果如图2~4所示。
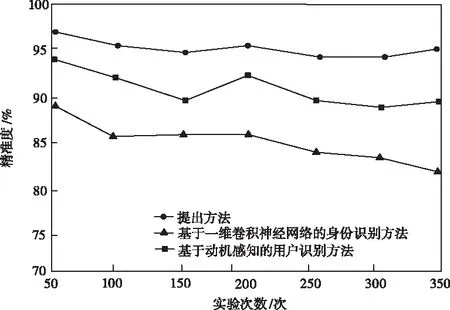
图2 用户身份识别精准度对比
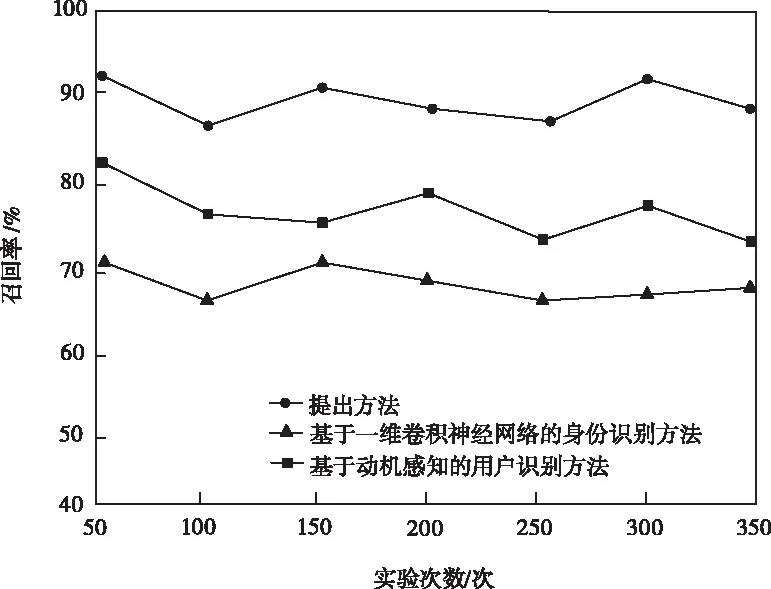
图3 用户身份识别召回率对比
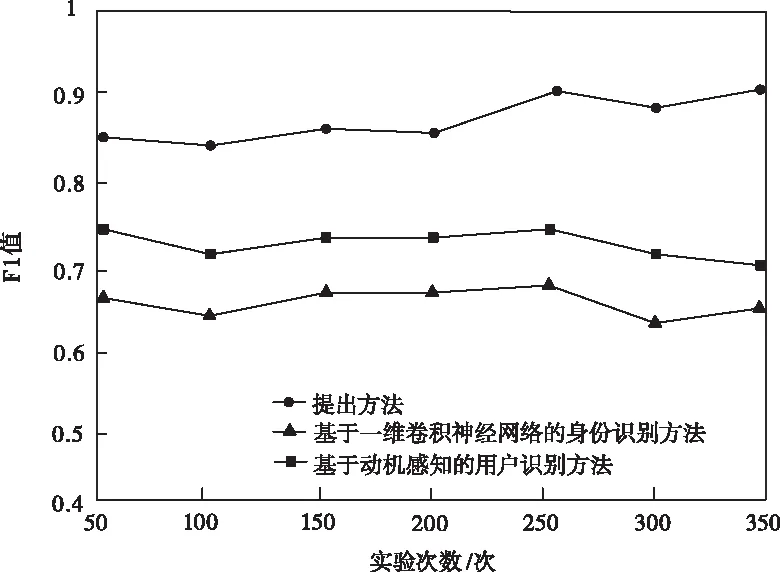
图4 用户身份识别F1值对比
根据图2~图4的实验结果可知,本文方法的精准度、召回率与F1值均高于两个对比方法,具有明显的用户身份识别方法的应用性能优势。文献[4]提出的基于一维卷积神经网络的身份识别方法仅适用于小型数据集识别,在网络结构扩大数据变多的情况下,无法完成预期用户身份识别任务;文献[5]提出的一种基于动机感知的用户识别方法在识别过程中仅训练了用户单一属性信息,识别结果比较片面,无法满足自适应用户身份识别目标。而本文方法利用强化学习强大的数据处理能力,通过Q-Learning学习即可实现高质量远程终端用户身份识别。
远程终端网络内,先验种子节点影响力巨大,其节点数量也被用于评估用户身份识别性能,节点匹配数量越多,识别结果精度越高。任意选取150个先验种子节点,使用三种方法对其进行用户迭代识别,结果如图5所示。
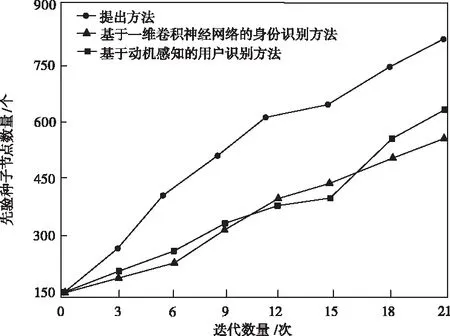
图5 先验种子迭代匹配数量对比
从图5可知,本文方法从迭代初期至结束,匹配的节点数量数远远多于两个文献方法,说明提出方法下用户信息被动态划分至不同区域,使得匹配结果覆盖更为全面,识别结果准确性也随之提升。
基于以上实验结果,用户身份识别的效率也是决定其实用性的关键性指标之一,因此,相同实验环境下,测试三种方法用户身份信息识别速率情况如图6。
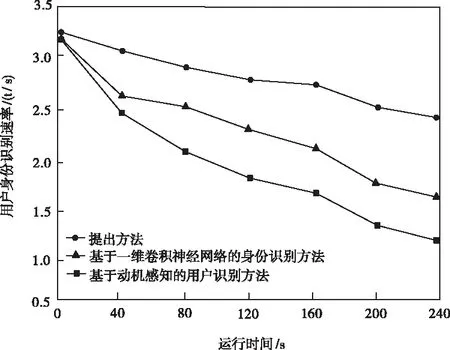
图6 用户身份识别效率对比
分析图6看出,伴随终端运行时间的加长多,三种方法识别效率均呈现减少趋势,但相比之下本文方法识别效率变化幅度较小,始终高于文献方法,即提出方法能够在短时间内实现身份识别,进一步表明了本文方法的可靠性。
6 结论
为有效维护远程终端用户数据隐私安全,提出一种基于强化学习的AI远程终端用户身份识别方法。该方法阐明了用户身份识别存在的隐含问题,利用小波阈值法消除用户身份冗余信息,通过强化学习技术完成预期身份识别目标。与此同时,在仿真中也说明了方法的有效性,为处理远程终端用户隐私问题发挥重要作用。
