ZB+-tree:一种ZNS SSD 感知的新型索引结构
2023-03-27刘扬金培权
刘扬 金培权
(中国科学技术大学计算机科学与技术学院 合肥 230026)
(中国科学院电磁空间信息重点实验室 合肥 230026)
ZNS SSD(Zoned Namespaces SSD)[1-7]是2019 年由西部数据公司和三星公司推出的新一代固态硬盘(solid state drive,SSD),目前受到了工业界和学术界的广泛关注.由于基于闪存的SSD只有在块被完全擦除以后才能重写,传统的 SSD 通过使用闪存转换层(flash translation layer,FTL)[8]来适应这一特性,但由于闪存块存在物理限制(擦除操作以块大小进行,而读写操作以页大小进行),因此经常需要进行垃圾回收(garbage collection,GC)[5,9],同时也带来了预留空间(over provisioning,OP)[10]和写放大(write amplification,WA)[11]等问题,ZNS SSD 可以有效提升SSD 的读写吞吐,降低写入时的写放大,减少SSD 本身的预留空间,并且还能解决传统SSD 在空间占用达到一定程度时由于内部垃圾回收导致的性能不稳定的问题[12-13],因此利用ZNS SSD 来构建数据库系统是一个趋势[3].
图1 展示了ZNS SSD 和传统 SSD 数据放置对比,在ZNS SSD 上数据由主机程序显式地控制放置.虽然ZNS SSD 具有如此多优点,但它同样带来了一些挑战[3,7].与传统基于闪存的SSD 相比,ZNS SSD 移除了FTL,将分区(Zone)的空间直接交由主机程序控制管理,由主机程序来处理垃圾回收、磨损均衡、数据放置等,这扩大了用户数据布局的设计空间.由用户程序来决定数据的放置、生命周期和垃圾回收时机,通过有效合理地组织数据,可以提高系统的性能.但ZNS SSD 同样给主机程序的设计带来了新的要求,比如一个Zone 内有一个写指针只能进行顺序写、不同Zone 性能有差异、何时进行Zone-Reset 操作等[7,14].

Fig.1 Comparison of ZNS SSD and conventional SSD data placement图1 ZNS SSD 和传统SSD 数据放置对比
B+-tree 是数据库中经典的索引结构,以往研究者已经提出了多种针对SSD、持久性内存等新型存储的B+-tree 优化方法[15-26].但是,已有的SSD 索引设计重点在于减少对SSD 的随机写操作.虽然ZNS SSD的底层介质仍是闪存,但由于Zone 内只能顺序写,因此随机写的问题不再是ZNS SSD 上B+-tree 索引优化的第一目标.B+-tree 如何在没有FTL 的情况下适应ZNS SSD 的分区特性以及Zone 内顺序写要求,是ZNS SSD 感知的B+-tree 索引需要解决的关键问题.针对传统SSD 设计的索引由于没有考虑ZNS SSD 的特性,所以都无法直接运行在ZNS SSD 上.此外,根据我们的调研,目前也还没有提出ZNS SSD 感知的索引结构.
本文提出了一种ZNS SSD 感知的新型索引结构——ZB+-tree(ZNS-aware B+-tree).我们发现,虽然ZNS SSD上要求Zone 内顺序写,但是实际的分区块设备(zoned block device,ZBD)中除了只允许顺序写的顺序Zone(sequential zone,Seq-Zone),还存在着少量允许随机写的常规Zone(conventional zone,Cov-Zone).因此,我们结合了ZNS SSD 内部这2 类Zone 的特性设计了ZB+-tree 的结构来适配ZNS SSD.具体而言,本文的主要工作和贡献可总结为3 个方面:
1)提出了一种ZNS SSD 感知的新型索引结构ZB+-tree.ZB+-tree 利用了ZNS SSD 内部的Cov-Zone来吸收对Zone 的随机写操作,并将索引节点分散存储在Cov-Zone 和Seq-Zone 中,通过设计不同的节点结构来管理不同Zone 上的节点,在保证Zone 内顺序写要求的同时提高空间效率.
2)设计了ZB+-tree 上的相 关操作,包括Sync,Search,Insert,Delete 等,在保证索引性能的同时减少操作过程中的读写次数.
3)利用null_blk[27]和libzbd[28]模拟ZNS SSD 设备开展实验,并将传统的CoW B+-tree 修改后作为对比索引.结果表明,ZB+-tree 能有效阻断级联更新,减少读写次数,在运行时间、空间利用率上均优于CoW B+-tree.
1 背景与相关工作
本节主要介绍目前业界对于ZNS SSD 的相关研究和SSD 感知的B+-tree 索引的相关工作,同时也介绍本文用于对比实验的CoW B+-tree.
1.1 ZNS SSD 相关工作
ZNS SSD 将其空间划分为许多的Zones,在一个Zone 内可以随机读,但是只能顺序写,当一个Zone写满时会触发Zone-Reset 和GC 操作.图2 显示了Zone 的大致结构,每个Zone 内有一个写指针,Zone内有严格的顺序写限制.

Fig.2 The structure of Zone图2 Zone 的结构
传统SSD 由于FTL 的存在,会给主机程序提供块接口[1],各类任务都交由FTL 来处理,SSD 通过FTL提供给上层应用的接口是支持随机读写的,在程序设计时可以视为硬盘.FTL 的存在使得之前为硬盘设计的各类应用程序可以几乎不用修改而直接迁移到SSD 上,但同时也导致了SSD 需要预留空间、需要进行内部的垃圾回收、在空间占比达到一定程度时会发生性能抖动等问题[1,12].
ZNS SSD 相比于传统块接口的SSD 有以下优点:首先在ZNS SSD 上减少甚至移除了FTL,将映射表的管理、垃圾回收和顺序写的限制都交给主机端进行控制,节约了成本,同时解决了预留空间的问题.其次由于主机程序能控制ZNS SSD 上数据的放置、垃圾回收时机,通过将不同特性的数据放置在不同的Zone,选择合理的垃圾回收时机等策略将有助于提高系统性能、延长SSD 使用寿命.
由于在Zone 内只能顺序写,因此很多基于传统SSD 抽象接口开发的应用和系统不能直接应用在ZNS SSD 上[1-6].此外,由于ZNS SSD 移除了设备内的垃圾回收,因此需要用户自行设计垃圾回收机制,带来了额外的复杂性.Stavrinos 等人[3]分析了ZNS SSD的各项优势,并通过调研发现一旦行业因为ZNS SSD的成本和性能优势开始转向ZNS SSD,则之前大多数SSD 上的工作都需要重新审视,因此呼吁研究者转向ZNS SSD 的研究.Shin 等人[7]通过在ZNS SSD原型硬件上进行各种性能测试,为ZNS SSD 上的软件设计提供了有效思路.Choi 等人[5]提出了一种在ZNS SSD 上的LSM(log-structured merge)风格的垃圾回收机制,他们建议针对ZNS SSD 进行细粒度的垃圾回收,并根据数据热度将细粒度数据存储在不同的分区内.西部数据的Bjørling 等人[1]基于ZNS SSD 开发出了ZenFS 文件系统来适配 RocksDB 的文件接口,目前已经成功提交到 RocksDB 的社区.Han 等人[2]在ZNS 接口的基础上更进一步,提出了ZNS+接口.ZNS+是一种对日志结构文件系统(log-structured file system,LFS)感知的ZNS 接口,将用户定义的垃圾回收产生的有效数据拷贝放到设备内部进行,从而减少I/O 操作,提升文件系统垃圾回收的效率.
虽然ZNS SSD 具有如此多优点,但它同样带来了一些挑战.与传统SSD 相比,ZNS SSD 移除了FTL,将Zone 的空间直接交由主机程序控制管理,由主机程序来处理垃圾回收、磨损均衡、数据放置等,这扩大了用户数据存储管理的设计空间,也带来了设计上的困难.总体而言,ZNS SSD 的顺序写和Zone 划分等限制对现有的数据存储管理机制提出了诸多新的挑战,包括存储分配、垃圾回收、索引结构等.
1.2 SSD 感知的B+-tree 相关工作
在过去的10 多年里,由于闪存技术的快速发展,学术界针对闪存感知的B+-tree 优化方法开展了广泛的研究.Roh 等人[15]利用SSD 内部的并行性来优化B+-tree 索引.Na 等人[16]提出了一种动态页内日志风格的B+-tree 索引.Agrawal 等人[17]设计了一种惰性更新的机制来使B+-tree 更适合SSD 特性.Ahn 等人[18]利用CoW B+-tree 的性质对SSD 上的B+-tree 进行了优化.Fang 等人[19]提出一种感知SSD 持久度的B+-tree方案.Jin 等人[20]则利用布隆过滤器(Bloom filter)和节点的更新缓存实现了不降低读性能的同时减少SSD写操作.Lv 等人[21]通过日志的方式将随机写转为顺序写来优化SSD 上的R-tree 的读写操作.Jin 等人[22]通过利用SSD 内部的并行来批量处理小的写入,提出了一种flash 感知的线性散列索引.Ho 和Park[23]通过在内存中设计一个写模式转换器,将随机写转换为顺序写,以此来充分利用SSD 的特性.文献[24]使用IPL(in-page logging)和写缓存等技术设计符合SSD 特性的LSB+-tree,同时提高了索引的时间和空间效率.
总体而言,SSD 感知的B+-tree 索引的设计重点在于减少对SSD 的随机写操作.这是因为B+-tree 本身是一种写不友好的索引,因此对于SSD 上的写密集应用性能较差.ZNS SSD 的介质仍是闪存,因此同样需要考虑减少随机写操作.但由于Zone 内只能顺序写,随机写的问题不再是ZNS SSD 上B+-tree 索引优化的第一目标.如何适应数据的分区存储和顺序写特性,是设计ZNS SSD 感知的B+-tree 索引需要重点考虑的问题.就目前的研究进展,还没有一种已有的SSD 索引能够直接运行在ZNS SSD 上.
1.3 CoW B+-tree
目前学术界还没有提出针对ZNS SSD 的索引结构.与本文工作较相关的已有工作主要是CoW B+-tree.CoW B+-tree 是一种追加写(append-only write)的B+树结构[25].这刚好适应了ZNS SSD 的Zone 内顺序写要求,因此如果不考虑Zone 内数据存储分配的话,可以将CoW B+-tree 修改后运行在ZNS SSD 上.图3 给出了CoW B+-tree 的数据更新过程.
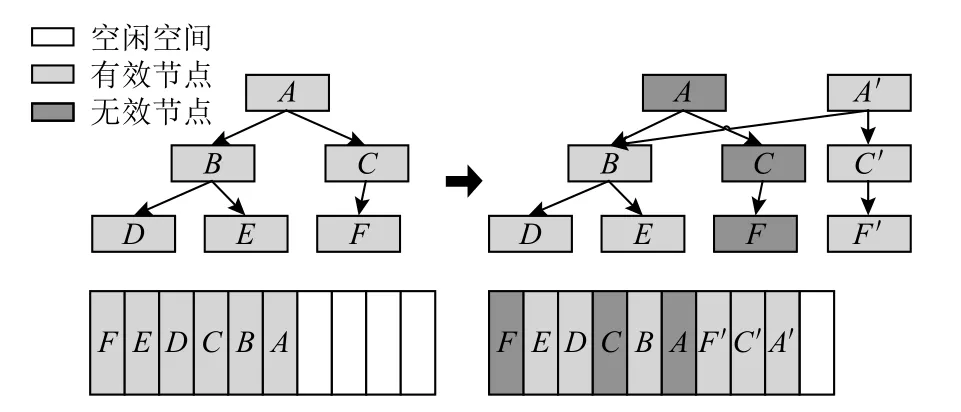
Fig.3 An example of CoW B+-tree update图3 CoW B+-tree 更新过程示例
文献[18]对Cow B+-tree 针对SSD 特性做了一些优化以减少写放大,但是却无法保证B+-tree 节点大小相同,因此本文还是选择传统CoW B+-tree[25]进行对比,CoW B+-tree 算法流程和传统的B+-tree 基本一样,只是修改叶节点时由于不能原地更新,因此需要把修改后的节点直接附加在写指针处,由于叶节点的地址发生了改变,因此还需要修改其父节点中指向叶节点的指针.这一修改会级联往上传递,直到根节点.
但是,直接将CoW B+-tree 的所有节点都写在一个Zone 中将会很快耗尽Zone 的空间,从而频繁触发Zone-Reset 操作.因此,在本文后续的对比实验中,我们对CoW B+-tree 进行了修改使其能够利用所有的Zone,并减少频繁的Zone-Reset 操作.由于主机程序可以得知Zone 的使用情况,我们总是将CoW B+-tree节点写入剩余空间最多的Zone,并根据当前Zone 的使用情况动态选择Zone 而不是固定写入一个Zone.这样可以在使用该索引时尽量减少Zone-Reset,同时充分利用ZNS SSD 的空间.
2 ZB+-tree 索引结构
2.1 设计思路
由于ZNS SSD 具有多分区特性,不同的Zone 性能有所差异,在频繁访问的磨损较多的Zone 会有更高的访问延迟[7],且在Seq-Zone 中有严格的顺序写要求.当Zone 写满时会触发Zone-Reset 操作和垃圾回收,这2 个操作非常耗时,会带来性能的抖动.因此ZB+-tree 主要针对4 个目标进行设计:1)索引要能充分利用ZNS SSD 的多分区特性;2)要满足在Seq-Zone 中的严格顺序写限制;3)将频繁访问的数据尽量放置在磨损较少的Zone 以降低访问延迟;4)尽量减少在运行过程中的GC 和Zone-Reset 操作,以避免性能抖动.
针对上述目标,ZB+-tree 进行了全新设计,主要设计思路总结为5 个方面:
1)将索引节点分散在多个Zone 中,允许节点在不同Zone 之间进行移动.由于Cov-Zone 中允许进行原地更新,如果能充分利用这一特性,就能将对索引的原地更新吸收在Cov-Zone 中.当节点写满时则整体移动到Seq-Zone 中,既保证不会有太大的写放大,而同时也能保证在Seq-Zone 中的顺序写要求.
2)将对Seq-Zone 中节点的更新也吸收在Cov-Zone 中,为Seq-Zone 中不可原地更新的节点设计了日志节点结构,日志节点放置在Cov-Zone 中以进行原地更新,减少写放大.同时为避免日志节点过多而影响整体的读写性能,需要将日志与节点合并,可通过设计新的Sync 操作来实现.
3)为不同类型的节点动态选择不同的Zone 进行放置,由于叶节点和内部节点更新频率不同,叶节点频繁更新而内部节点相对更新较少,因此我们提出一种动态选择Zone 的策略,将频繁更新的叶节点放置在空间占用较少、磨损较少的Zone 中,而将内部节点放置于空间占用和磨损相对较多的Zone 中,以充分利用ZNS SSD 的多分区特性,并降低访问延迟.
4)为管理分散在不同Zone 的节点和对应的日志节点,我们为叶节点和内部节点都设计相应的head节点,以记录节点的状态、地址、日志情况,并将head 节点存储于Cov-Zone 中,以阻断级联更新.
5)由于不同分层的节点处于不同类型的Zone 中,对节点的合并控制也将采用不同的策略,对于都在Cov-Zone 中的节点,采用严格控制合并策略;对于节点分散在Cov-Zone 和Seq-Zone 中的节点,则采用机会主义合并策略.通过不同的控制合并策略,在保证索引性能的同时尽量减少级联更新和写放大.
2.2 ZB+-tree 总体结构
在本文的设计中,ZB+-tree 总共分为4 层,从上到下分别是IH 层、Interior 层、LH 层、Leaf 层,其中IH层由interior-head 节点组成,LH 层由leaf-head 节点组成,Interior 层由interior 节点和interior-log 节点组成,Leaf 层由leaf 节点和leaf-log 节点组成.由于通常来说B+-tree 为3~4 层,我们设计的IH 可以视为B+-tree的根节点.IH 层和LH 层的节点既可以作为B+-tree的内部节点(里面存着key 值和子节点地址),同时又记录着下一层的节点状态和日志情况.图4 展示了ZB+-tree 的逻辑结构,其中F 代表key 值为First(key无法取到的最小值),K 代表普通key 值.

Fig.4 ZB+-tree logical structure图4 ZB+-tree 逻辑结构
由于主机程序可以随时知道ZNS SSD 上各个Zone 的使用情况,这里提出一种动态选择Zone 的方法,即当有节点需要从Cov-Zone 移入到Seq-Zone 中时,如果是leaf 节点,则动态选择当前剩余容量最多的Zone(称为Hot-Seq-Zone)放置,如果是interior 节点,则动态选择当前剩余容量最少的Zone(称为Cold-Seq-Zone)放置.之所以这么区分,是因为叶节点和内部节点的更新频率不同,把更新频率高的叶节点往剩余空间最大的Zone 内放置可以避免由于Zone 空间被迅速占满而导致的Zone-Reset 操作.同时剩余容量多、磨损较少的Zone 的读写性能也更好,可以便于leaf 的频繁读写.
图5 显示了ZB+-tree 节点在ZNS SSD 上的具体分布情况,其中IH 和LH 层都位于Cov-Zone 中,而interior 节点和leaf 节点则分布在Cov-Zone 和Seq-Zone中.在本文中,我们约定:白色代表Cov-Zone,深灰色代表Hot-Seq-Zone,浅灰色代表Cold-Seq-Zone,灰色渐变代表处于Seq-Zone 中可能是Hot 状态也可能是Cold 状态.

Fig.5 Distribution of ZB+-tree nodes on ZNS SSD图5 ZB+-tree 节点在ZNS SSD 上的分布
对于interior 节点和leaf 节点,设计了相应的状态转换机制,如图6 所示.ZB+-tree 的interior 节点和leaf 节点有4 种可能的状态.
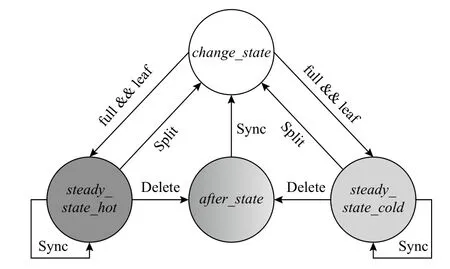
Fig.6 ZB+-tree node state transition图6 ZB+-tree 节点状态转换
1)change_state.处 于change_state的节点 都位于Cov-Zone 中,并且节点未满,可以就地插入、删除、更新.处于change_state的节点一旦满了,如果是叶节点,则整体移动到Hot-Seq-Zone 中;如果是内部节点,则整体移动到Cold-Seq-Zone 中,这刚好符合ZNS SSD 的顺序写限制.
2)steady_state_hot.节点位于Hot-Seq-Zone 中,且为叶节点,节点一定是满的,并且不可就地更改.对此状态的节点进行插入将导致其分裂成2 个change_state的叶节点,对此状态节点的更新和删除将记录在leaf-log 节点中.
3)steady_state_cold.节点位 于Cold-Seq-Zone 中,且是内部节点,节点一定是满的,并且不可就地更改.对此状态的节点进行插入将导致其分裂成2 个change_state的内部节点,对此状态节点的更新和删除将记录在interior-log 节点中.
4)after_state.处于该状态的节点一定带有log 节点,并且log 节点中有删除记录,表示该节点在steady_state经过了删除.对此状态的节点进行插入会首先触发Sync 操作,将节点和对应的log 节点合并之后再进行插入,对此状态节点的更新和删除将记录在log 节点中.
处于steady_state的节点可能带log 节点也可能不带log 节点,log 节点都位于Cov-Zone 中以吸收对Seq-Zone 中节点的原地更新,对steady_state的节点进行的更新和删除操作会直接写到对应的log 节点里(如果该节点原本不带log 节点则为其分配一个log节点).处于steady_state的节点可以进行3 种操作:
1)Sync 操作.将节点与对应的log 节点进行合并,Sync 操作完成之后节点还是处于steady_state.
2)Delete 操作.在log 节点中增加删除记录,Delete操作完成之后节点转换为after_state表示节点已经经过了删除.
3)Split 操作.节点分裂成2 个,Split 操作完成之后节点转化为2 个change_state的节点并移动到Cov-Zone 中.
处于after_state的节点可以进行Sync 操作,将节点与对应的log 节点进行合并.由于必然经过了删除操作,实际上after_state的节点在逻辑上代表一个未满的节点,因此合并后节点状态转换为change_state.
2.3 ZB+-tree 节点结构设计
leaf 节点设置为n个key 值和n个value 值,leaflog 节点的结构与leaf 节点的结构完全相同,之所以设置为结构相同,是因为在Sync 操作中需要将leaflog 节点直接转化为leaf 节点(具体细节见3.1 节Sync操作),在leaf-log 节点中通过位置与leaf 节点中的键值对应,如图7 所示.
对于leaf-head 节点,结构为n+1 个key 值和n+1个ptr 结构,如图8 所示.ptr 结构中包括3 个值:
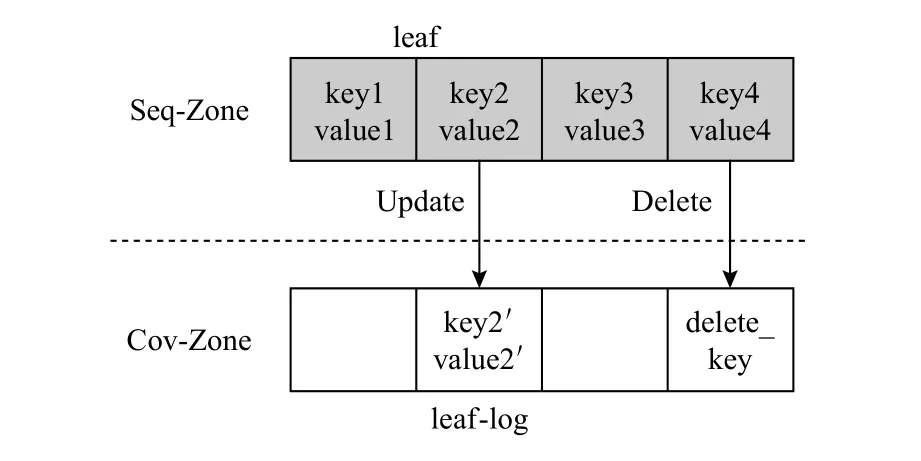
Fig.7 An example of leaf and corresponding leaf-log图7 leaf 和对应的leaf-log 示例
1)state.表示子节点所处的状态.
2)addr.表示子节点所在的位置.
3)log_addr.表示子节点对应的日志节点所处的位置.
leaf-head 节点的第1 个key 值一定是First(key 无法取到的最小值).
interior 节点的 结构为n+1 个key 和n+1 个addr(子节点的地址),interior-log 和interior 结构完全相同(同样是因为Sync 操作的要求),interior-head 的结构和leaf-head 的结构相同.在interior 和interior-head 节点中,第1 个key 值同样设置为First.之所以在interior节点中引入First 值是因为在ZB+-tree 中的Sync 操作需要让日志节点和interior 节点保持相同结构以便于log 节点与正常的内部节点之间直接进行转化,而日志节点又是通过位置与原内部节点进行对应,所以需要给第1 个位置一个key 值,代表这是第1 个子节点.之所以在leaf-head 和interior-head 中引入First 值,是因为对于每一个leaf 节点或者是interior 节点,都需要相应的ptr 结构来指示其状态、位置和日志情况.即使树中只有一个leaf 节点或只有一个interior节点也要有对应的ptr 结构,因此,需要为第1 个ptr结构设置key 值为First,表示这是子树中第1 个interior 节点或者第1 个leaf 节点,而其他的key 值则与正常B+-tree 中的key 值含义相同,代表对应子树中的最小key 值.
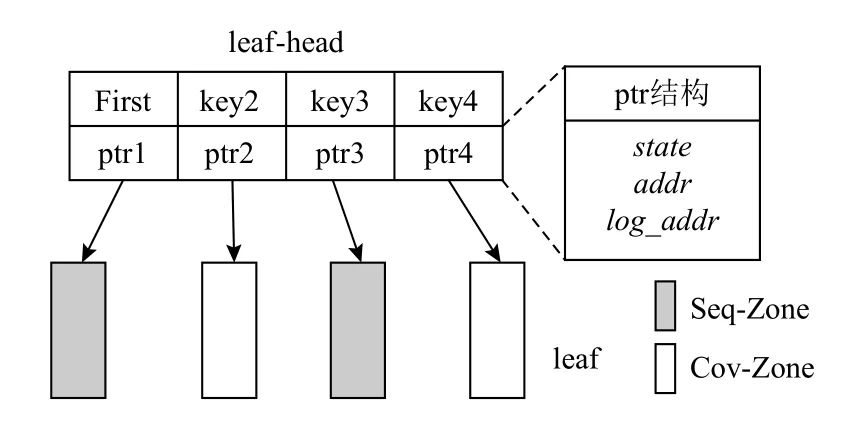
Fig.8 The structure of leaf-head图8 leaf-head 的结构
3 ZB+-tree 索引操作
本节主要介绍ZB+-tree 的Sync,Search,Insert,Delete等操作,并给出了时间性能和空间代价分析.
3.1 Sync
在ZB+-tree 中无论是interior-log 节点还是leaflog 节点都只记录更新和删除操作,其结构和对应的interior 节点或leaf 节点相同,当树中存在的日志节点过多时会对Cov-Zone 有较大的占用而且会影响整体的查找性能,因为读一个节点之后还需要再读一次日志节点来重建最新的节点.因此需要将日志节点和对应的节点进行合并,构建最新的节点并释放日志节点空间,我们称之为Sync 操作.在日志节点写满时同样需要将日志与节点进行合并.在ZB+-tree 中,我们设计了2 种方式的合并,当日志节点未满时的合并称之为Normal_apply,当日志节点满了时的合并称之为Switch_apply.
1)Normal_apply.图9 给出了Normal_apply 的 过程.当节点对应的log 节点还未满时,如果节点处于steady_state,表示节点还未进行过删除操作,log 节点中无删除记录,因此根据log 节点进行更新后的节点仍然处于steady_state,此时将新的节点写回Seq-Zone并释放Cov-Zone 上log 节点的空间.如果节点处于after_state,则表示节点经过了删除操作,log 节点中一定有删除记录,根据log 节点进行更新后的节点转换成change_state并写到Cov-Zone 中原log 节点的位置.算法1 给出了Normal_apply 操作流程.
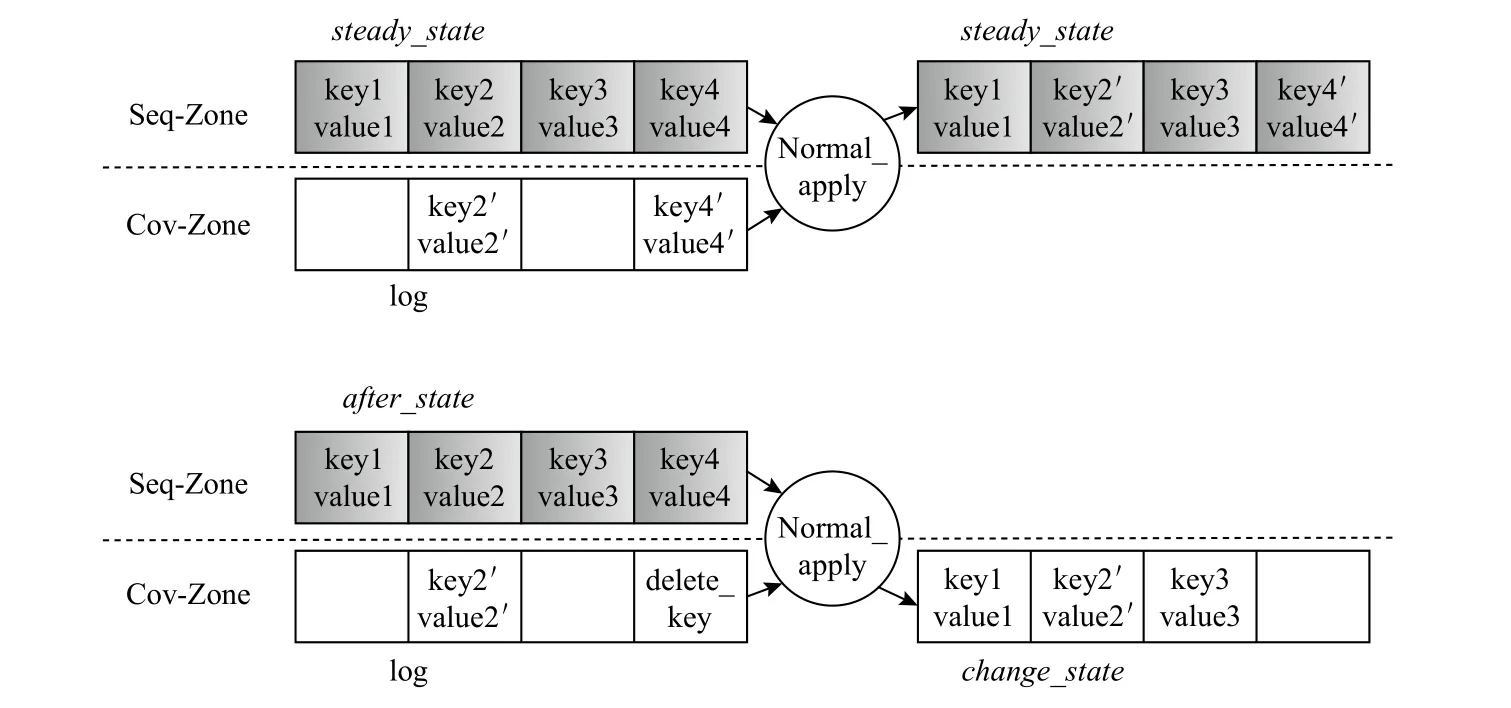
Fig.9 Normal_apply schematic图9 Normal_apply 示意图
算法1.Normal_apply_leaf(&leaf,&leaf_log,&leaf_ptr).
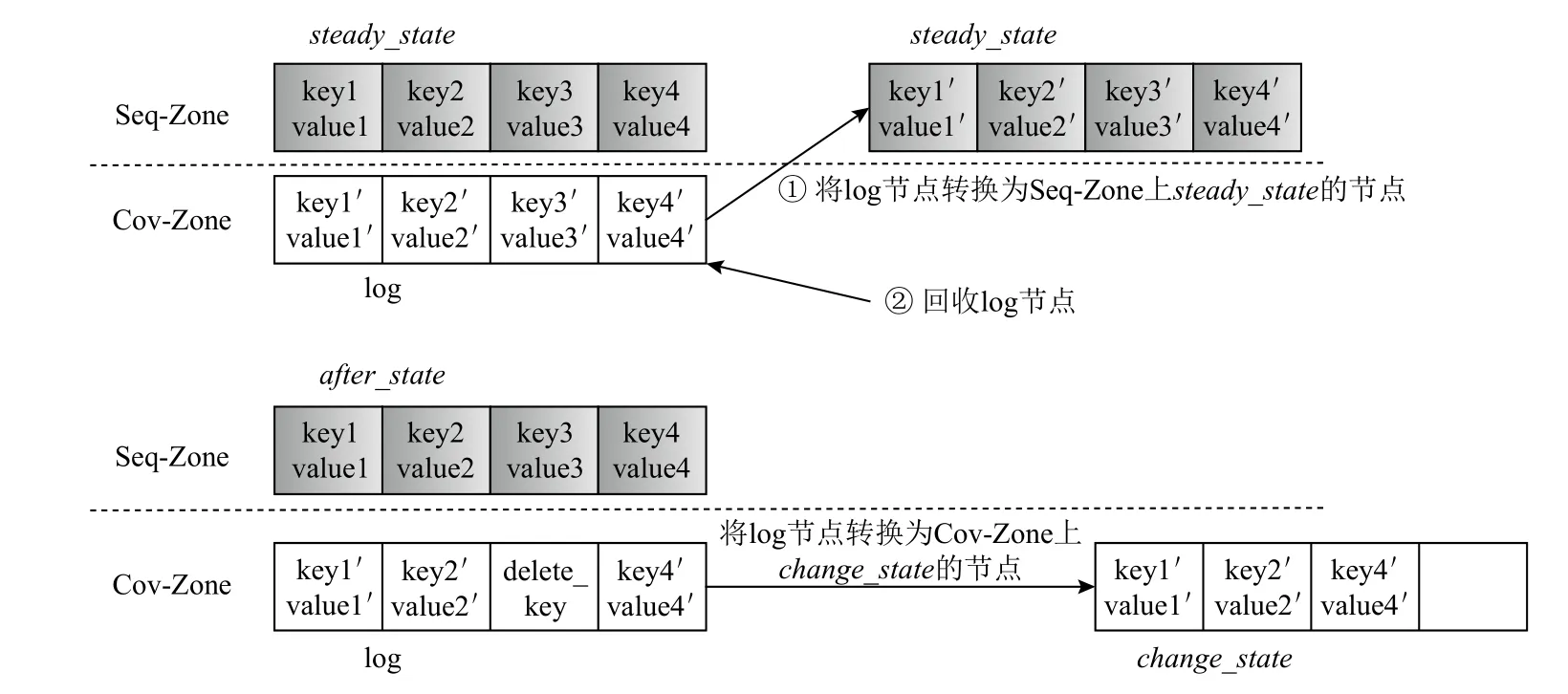
Fig.10 Switch_apply schematic图10 Switch_apply 示意图
2)Switch_apply.图10 给出了Switch_apply 的 过程.当节点对应的log 节点已经写满时,将发生Switch_apply,与Normal_apply 不同的是,Switch_apply 不需要读原节点,而只需要读其log 节点,因为日志已满说明原节点中所有键值对都已经经过了更新或者删除.如果原节点处于steady_state,说明对节点的所有键值对都进行过更新操作,因此直接将log 节点作为新的节点写入Seq-Zone 中,并释放在Cov-Zone 中log节点的空间.如果原节点处于after_state,说明其除了进行过更新操作之外还有删除操作,因此把log 节点中有删除标记(delete_key)的键值对去除后,转化为change_state的节点,直接写回Cov-Zone 中原log 节点位置.算法2 给出了Switch_apply.
算法2.Switch_apply_leaf(&leaf_log,&leaf_ptr).
Sync 操作(见算法3)对于interior 节点和leaf 节点都类似,唯一区别在于interior 节点中为n+1 个键值对而leaf 节点中为n个键值对.对leaf 节点的操作为Sync,对于interior 节点也有相应的in_Sync 操作.
算法3.Sync(&leaf,&leaf_log,&leaf_ptr).
3.2 Search
在ZB+-tree 上的Search 过程如算法4 所示,如果ZB+-tree 中还没有IH 层,也就是整棵树只有2 层(LH层和Leaf 层)时,只有一个leaf-head 节点,此时直接从leaf-head 开始进行搜索.如果树中存在IH 层,则根据要搜索的key 值,先从IH 中得到interior 节点对应的ptr 结构,如果interior 节点没有log 节点,则直接读出interior 节点;如果interior 节点有log 节点,则会触发apply_innner_log()操作,这个操作只是在内存中重建最新的interior 节点,并不会对ZNS SSD 上的interior节点和日志节点进行修改.这样做的目的是避免在Search 过程中触发写操作.得到了最新的interior 节点之后,在其中根据key 值搜索得到leaf-head 节点的地址,并读出leaf-head 节点,再从leaf-head 开始搜索,即触发Search_leaf_head()操作,具体见算法5.其过程与从IH 搜索interior 节点的过程类似,其中apply_leaf_log()也只是在内存中建立最新的leaf 节点,并不修改ZNS SSD 上的leaf 节点和log 节点.得到最新的leaf 节点之后,再根据key 值进行搜索,如果搜到则返回value 值,否则返回Null,表示没有搜到.
算法4.Search(key).
算法5.Search_leaf_head(leaf_head,key).
3.3 Insert
在ZB+-tree 上的Insert 操作会先根据要插入的key 值从根节点一路搜索到叶节点对应的leaf-head节点,搜索过程与Search 相同,从leaf-head 节点中得到对应的ptr 结构,如果叶节点处于change_state,则直接往叶节点中插入键值对,如果满了则移动到Seq-Zone 中.而对于steady_state的叶节点,如果不带log节点,则直接进行Split 操作,分裂成2 个Cov-Zone 上的change_state的节点,如果带log 节点,则先进行Sync 操作,合并leaf 节点和log 节点之后再插入键值对,Insert 具体细节见算法6,ZB+-tree 上的Split 操作和正常B+-tree 的操作类似,唯一需要注意的是对树中First 值的维护.
算法6.Insert(key,value).
3.4 Delete
ZB+-tree 上的删除操作与经典B+-tree 算法有许多不同之处,由于不同层的节点所处的Zone 性质是不同的,对于不同层的节点在进行Delete 操作时,也将采用不同的控制合并的策略.
对于IH 层,由于所有的leaf-head 节点都处于Cov-Zone 中,可以发生原地更新,因此在删除时当节点容量达到下限(lower_bound),我们采取严格控制合并的策略,即leaf-head 节点的容量严格控制在lower_bound 和full 之间(整棵树只有一个leaf-head 节点时例外).而对于Leaf 层,在进行删除时我们采取的是机会主义策略控制合并,即查看邻居节点,能合并就合并(二者容量之和小于n),不能合并就不作处理,能满足合并条件则意味着二者必然都处于change_state,即都在Cov-Zone 中.之所以采取不同策略,是因为Leaf 层的节点分散在Seq-Zone 和Cov-Zone 中,且节点可能带log 节点也可能不带log 节点.如果不能发生合并,从steady_state的邻居借一个键值对,并不会减少空间的占用,反而将引发级联的修改,还要处理log 节点.在机会主义策略控制下,leaf 节点的容量范围为1~n.
对于Interior 层的节点我们同样采取机会主义控制合并的策略,理由和Leaf 层相同,interior 节点的容量范围为1~n+1,当节点只有一个key 值时必然是First,算法7 展示了对Leaf 层的Delete 操作.
算法7.Delete(key).
3.5 理论代价分析
3.5.1 时间性能
4 层的ZB+-tree 在查询时最坏情况下需要读6 次,即读interior-head 节点、读interior 节点和interior-log节点、读leaf-head 节点、再读leaf 节点和leaf-log 节点,如果Interior 层和Leaf 层没有log 节点,则与4 层的CoW B+-tree 一样,需要读4 次.在进行插入操作时,CoW B+-tree 需要先4 次读出根到叶节点的路径,如果不发生分裂需要4 次写操作,在最坏情况下除了根节点外每层节点都分裂,则需要7 次写操作.而ZB+-tree 插入时同样需要先进行4~6 次读,如果不发生分裂则只需要1 次写操作(即直接往Cov-Zone 中就地插入),如果发生分裂,最坏情况下需要7 次写操作,但大多数情况下不会出现每一层都恰好分裂,因此往往只需要1~2 次写操作即可,即将级联的更新阻断在Cov-Zone 中.对CoW B+-tree 的删除操作,同样需要先进行4 次读,随后如果没发生合并,最好情况下需要4 次写操作,如果发生合并或者向邻居借键值对则需要更多的读写.而ZB+-tree 在进行4~6 次读操作之后,如果没发生合并,则只需要1 次写操作(change_state的节点就地删除后只需要1 次写;steady_state的节点则往log 节点中插入删除记录,也只需要1 次写),如果发生合并,则在机会主义策略控制合并的2 层进行的合并操作会更少,并且在这2层不会发生向邻居借键值对的操作,而在LH 层和IH 层与CoW B+-tree 一样都采用了严格控制合并的策略,因此总体上的读写次数也会少于CoW B+-tree.结合上述分析,可知ZB+-tree 在查询性能上与CoW B+-tree 接近,在插入时会减少写操作,而在删除时会同时减少读写操作.
3.5.2 空间代价
CoW B+-tree 的每次更新都至少需要将从根到叶节点的路径重新写回到ZNS SSD 中;而ZB+-tree 则将更新吸收在Cov-Zone 中,往往只需要在Cov-Zone 中进行一次原地更新.因此,相比于CoW B+-tree,ZB+-tree 会大大减少对Seq-Zone 的占用.
假设一个节点大小为m,一个4 层的ZB+-tree,阶数为n,最坏情况下,每个leaf 节点都带有leaf-log 节点,且每个interior 节点都带有interior-log 节点,此时有效节点总大小可估计为
1 棵4 层的CoW B+-tree 有效节点所占空间大小即正常B+-tree 所占空间大小,总空间大小可估计为
随着对索引的修改,CoW B+-tree 会不断将修改过的节点以及到根节点的路径上的节点写入SSD 中.上述分析仅仅针对其有效节点部分,实际运行中CoW B+-tree 还会产生大量无效节点,进一步增加空间占用率.而ZB+-tree 将原地更新吸收在Cov-Zone 中,实际运行时虽然也会在Seq-Zone 中产生无效节点,但数量会远远少于CoW B+-tree,且其有效节点部分在最坏情况下也和CoW B+-tree 处于同一个量级.因此,总体上,ZB+-tree 的空间代价低于CoW B+-tree.
ZB+-tree 相比于CoW B+-tree 在LH 层和IH 层增加了一些数据结构用于管理下一层的节点,由于IH 层和LH 层都是内部节点,相对较少,因此额外的空间代价并不会特别高.ZB+-tree 对Cov-Zone 的占用情况则主要和工作负载有关,需要通过实验来进行验证.
4 实验与分析
4.1 实验设置
服务器操作系统为Ubuntu20.04.1LTS,内核版本5.4.0,gcc 版本为 9.4.0 .由于目前还没有商用ZNS SSD,因此我们使用了null_blk 来模拟ZNS SSD设备,并使用西部数据的ZBD 操作库libzbd 进行实验.具体的实验配置如表1 所示.
由于目前还没有提出ZNS SSD 感知的索引,因此我们将CoW B+-tree 进行了修改使其能够运行在ZNS SSD 上.具体而言,总是将CoW B+-tree 节点写入剩余空间最多的Zone,并根据当前Zone 的使用情况动态选择要写入的Zone,以尽量减少Zone-Reset 操作,同时充分利用ZNS SSD 的空间.
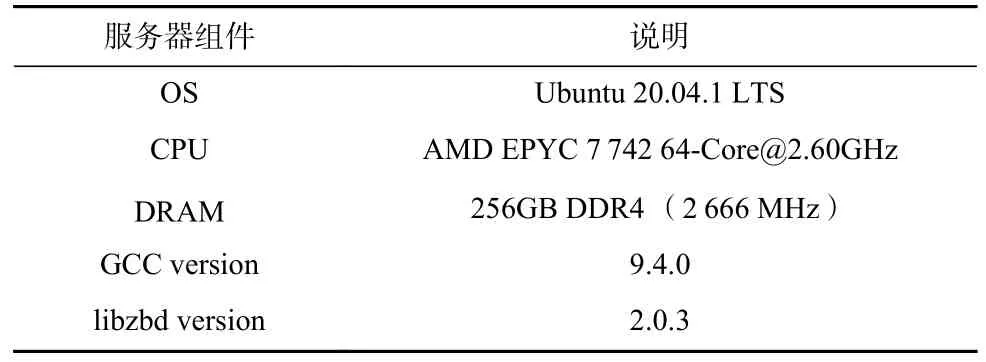
Table 1 Experimental Configuration表1 实验配置
实验使用YCSB[29]作为测试负载.YCSB 是目前在存储和数据库领域广泛使用的测试负载,它也允许用户自行配置读写比例和访问倾斜性.在实验中我们利用YCSB 生成了5 个测试负载,说明如下:
1)Workload1 是写密集的负载,包含插入、删除、查找操作,并且3 类操作的占比分别为插入40%、删除30%、查找30%.
2)Workload2 是读密集的负载,包含插入、删除、查找操作,并且3 类操作的占比分别为插入10%、删除10%、查找80%.
3)Workload3 是读写均衡的负载,包含插入、删除、查找操作,并且3 类操作的占比分别为插入25%、删除25%、查找50%.
4)Workload4 是纯写负载,包含插入、删除操作,并且2 类操作的占比分别为插入50%、删除50%.
5)Workload5 是纯读负载,只包含查找操作.
我们在5 种负载上分别测试不同数据量和不同数据分布下的性能.数据量分别设置为50 万、150 万、250 万键值记录对,数据分布采用了文献[29]中的3类分布,包括Zipfian 分布、uniform 分布、latest 分布.在YCSB 中执行测试前会先加载数据,以下的实验数据都是指在数据加载完成之后再进行各种操作时统计的数据.CoW B+-tree 实验中模拟的ZBD 设备为40个Seq-Zone 以及1 个Cov-Zone(为保证实验对比公平,我们把Cov-Zone 按照Seq-Zone 的顺序写模式来使用),每个Zone 大小为2 GB;ZB+-tree 实验中模拟的ZBD 设备为40 个Seq-Zone 以及1 个Cov-Zone,大小都为2GB.在模拟器中块大小统一设置为4 KB.
4.2 实验结果分析
4.2.1 运行时间比较
图11~13 给出了ZB+-tree 和CoW B+-tree 的运行时间对比.可以看到,在不同数据规模和不同工作负载下,ZB+-tree 运行时间都要小于CoW B+-tree.虽然ZB+-tree 相对于CoW B+-tree 在查询时可能要多读1~2 次log 节点,但由于在插入和删除操作中减少了读写次数,且SSD 读操作比写操作要快[7],因此ZB+-tree 总体性能要好于CoW B+-tree,与理论分析相符.

Fig.11 Running time comparison under the Zipfian distribution图11 Zipfian 分布下运行时间对比
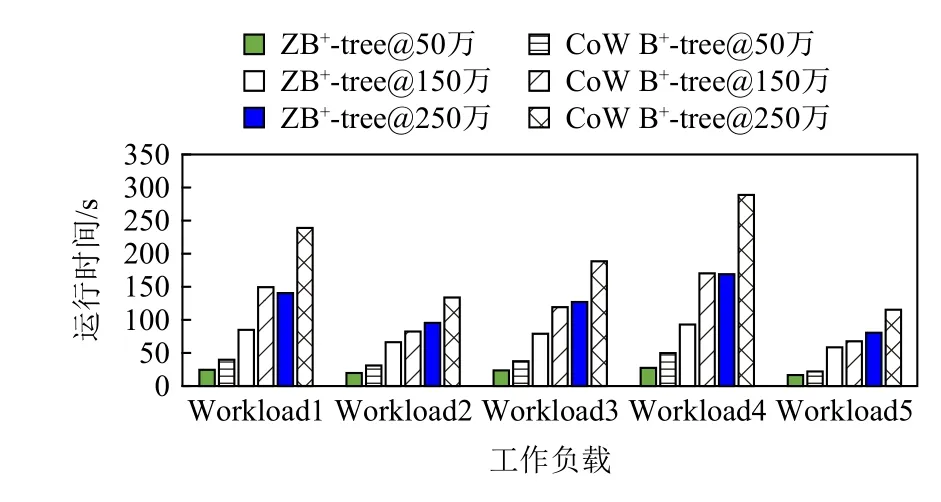
Fig.12 Running time comparison under the uniform distribution图12 uniform 分布下运行时间对比

Fig.13 Running time comparison under the latest distribution图13 latest 分布下运行时间对比
4.2.2 读写次数比较
图14~16 和图17~19 分别显示了ZB+-tree 和CoW B+-tree 的读操作次数和写操作次数对比.ZB+-tree 比CoW B+-tree 在读操作次数上减少了25%左右,这是因为在删除操作时,相比于CoW B+-tree 需要级联的读写,ZB+-tree 在机会主义策略控制的2 层减少了合并操作并去除了从邻居借键值对的操作.在写操作次数方面,ZB+-tree 在不同数据规模时平均节约了75%的写,这主要是因为ZB+-tree 通过LH 层和IH 层的独特设计将级联的更新进行了2 次阻断.由于LH和IH 都位于Cov-Zone 中,允许进行原地更新,因此节点修改后的地址不发生改变,所以级联的更新被阻断在了Cov-Zone 中.相比于CoW B+-tree 每次更新至少需要4 次写操作,ZB+-tree 只需要1~2 次写操作即可.

Fig.14 Read counts comparison under the Zipfian distribution图14 Zipfian 分布下读次数对比
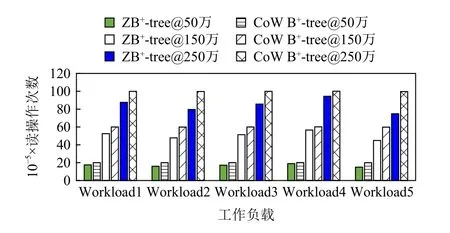
Fig.15 Read counts comparison under the uniform distribution图15 uniform 分布下读次数对比
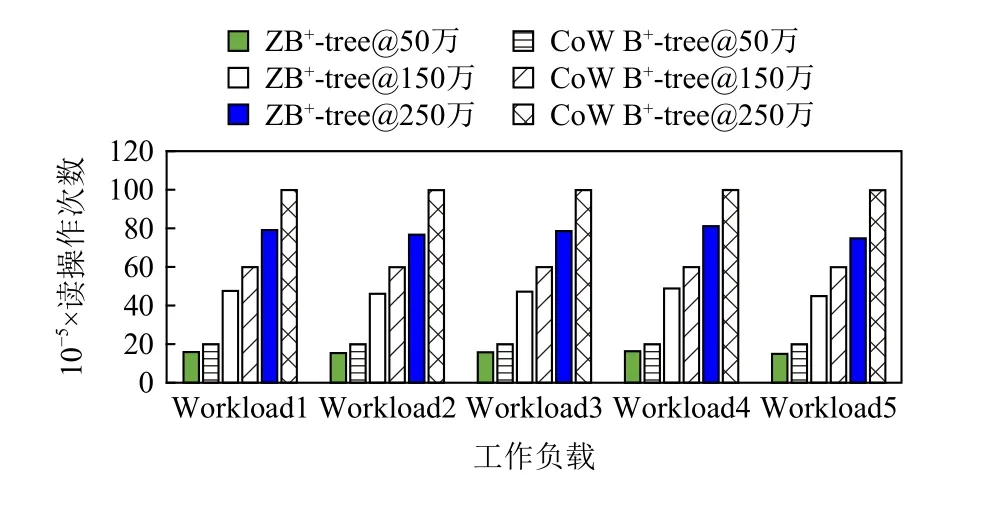
Fig.16 Read counts comparison under the latest distribution图16 latest 分布下读次数对比
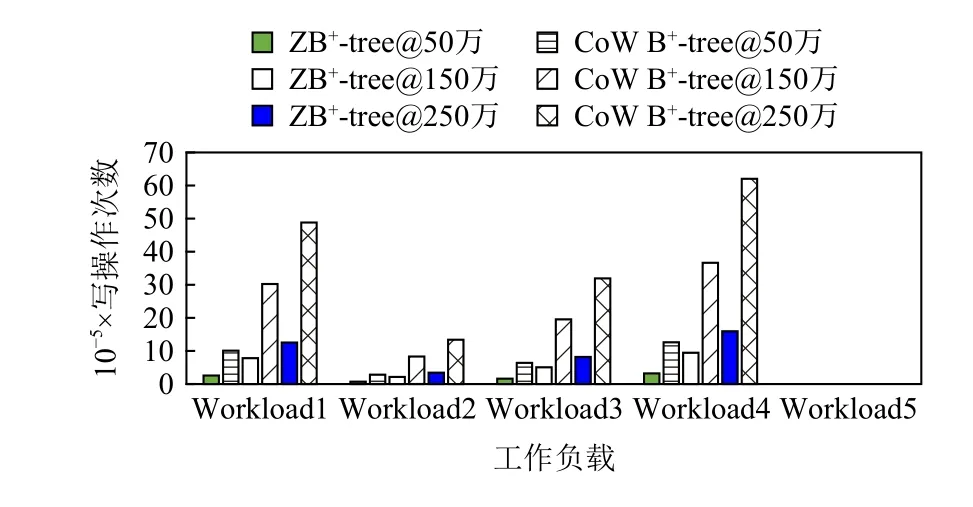
Fig.17 Write counts comparison under the Zipfian distribution图17 Zipfian 分布下写次数对比
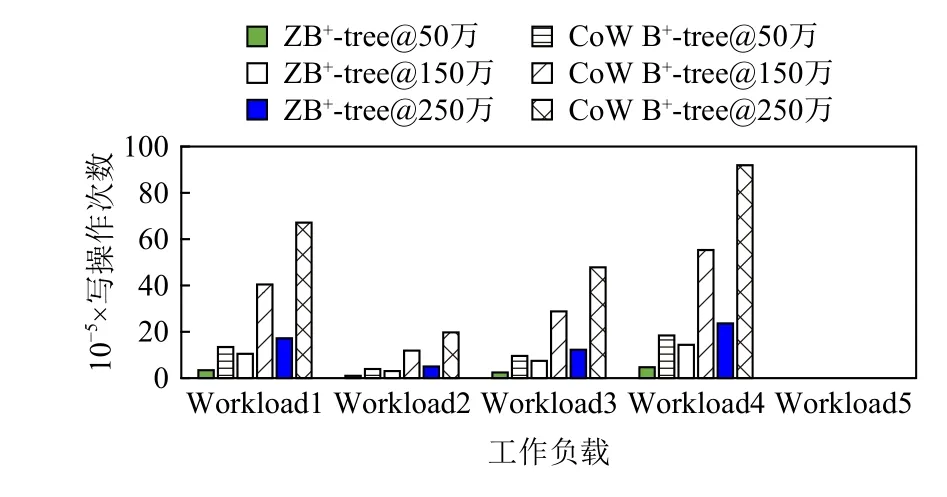
Fig.18 Write counts comparison under the uniform distribution图18 uniform 分布下写次数对比
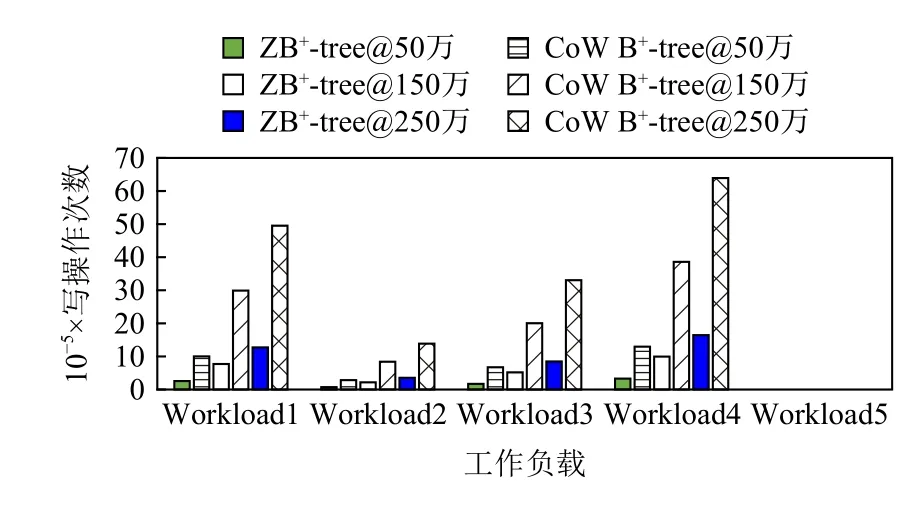
Fig.19 Write counts comparison under the latest distribution图19 latest 分布下写次数对比
4.2.3 空间占用率比较
表2~6 分别显示了在Zipfian 分布下,5 种工作负载和3 种数据规模下ZB+-tree 和CoW B+-tree 对于所有Seq-Zone 的平均占用情况,其他数据分布下实验结果类似.可以看出,随着数据规模的增加,CoW B+-tree 将快速占用Seq-Zone 的空间.在当数据规模为250万时,CoW B+-tree 对Seq-Zone 的占用率最大达到了0.739 822(Workload4),最小也有0.450 943(Workload5).因此,在大规模写入负载下,CoW B+-tree 的Seq-Zone将被快速写满,从而触发耗时的Zone 垃圾回收和Zone-Reset 操作,导致系统性能出现急剧下降.
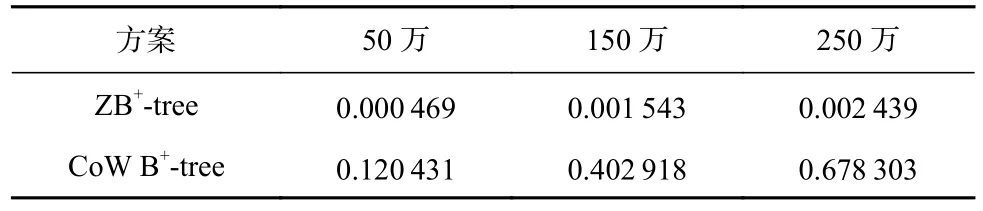
Table 2 Occupancy Rate of Seq-Zone Under Workload1 at Different Data Scales表2 不同数据规模下Workload1 下对Seq-Zone 的占用率
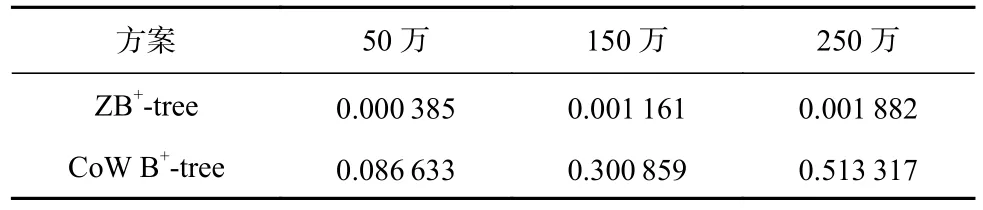
Table 3 Occupancy Rate of Seq-Zone Under Workload2 at Different Data Scales表3 不同数据规模下Workload2 下对Seq-Zone 的占用率

Table 4 Occupancy Rate of Seq-Zone Under Workload3 at Different Data Scales表4 不同数据规模下Workload3 下对Seq-Zone 的占用率

Table 5 Occupancy Rate of Seq-Zone Under Workload4 at Different Data Scales表5 不同数据规模下Workload4 下对Seq-Zone 的占用率
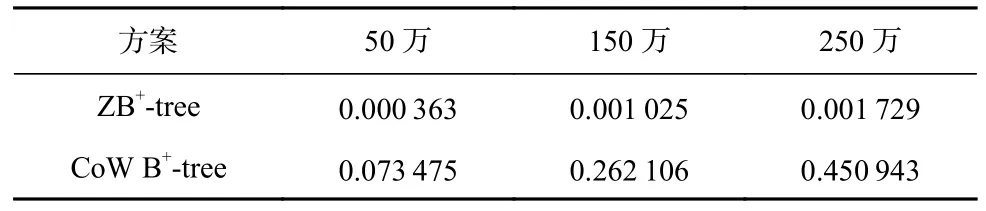
Table 6 Occupancy Rate of Seq-Zone Under Workload5 at Different Data Scales表6 不同数据规模下Workload5 下对Seq-Zone 的占用率
此外,ZB+-tree 对于所有Seq-Zone 的平均占用率在5 种不同负载下均低于0.002 7,远远低于CoW B+-tree.而且ZB+-tree 的Seq-Zone 占用率不会因为数据规模的增大而出现Seq-Zone 被快速写满的情况.因此,在系统运行过程中,ZB+-tree 一般不会频繁触发Zone 垃圾回收和Zone-Reset 操作,从而可以在保证系统性能和稳定性的同时节省较多的Seq-Zone 空间,提升空间效率.
4.2.4 Cov-Zone 和Seq-Zone 的不同比例
由于当前还没有ZNS SSD 的真实设备,因此Cov-Zone 和Seq-Zone 的比例可能会发生变化,因此,我们改变Cov-Zone 和Seq-Zone 的比例来测试ZB+-tree的效果.
在本节实验中,我们测试了3 种不同的Cov-Zone和Seq-Zone 的比例,分别是1∶32,1∶48,1∶64,数据分布为Zipfian 分布,数据量设置为100 万键值对,测试的负载为Workload1 和Workload2,如图20 所示.
从图20 可以看出,在不同比例下,ZB+-tree 的运行时间 都要少于CoW B+-tree,更 改Cov-Zone 与Seq-Zone 的比例并不影响读写次数,只会影响对Seq-Zone 的占用率大小,具体结果如表7 和表8 所示.
由表7 和表8 可知,在不同比例下,ZB+-tree 对Seq-Zone 的占用率都远小于CoW B+-tree.同时,我们发现更改Seq-Zone 和Cov-Zone 的比例对ZB+-tree 的空间效率影响不大,表明ZB+-tree 能够适应不同的Zone 配置.
4.2.5 Zone-Reset 次数比较

Fig.20 Comparison of running time under different ratios of Cov-Zone and Seq-Zone图20 Cov-Zone 和Seq-Zone 不同比例下运行时间对比
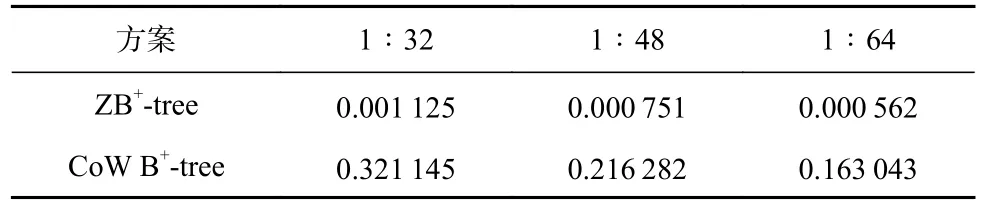
Table 7 Occupancy Rate of Seq-Zone Under Workload1 at Different Ratios表7 不同比例下Workload1 下对Seq-Zone 的占用率
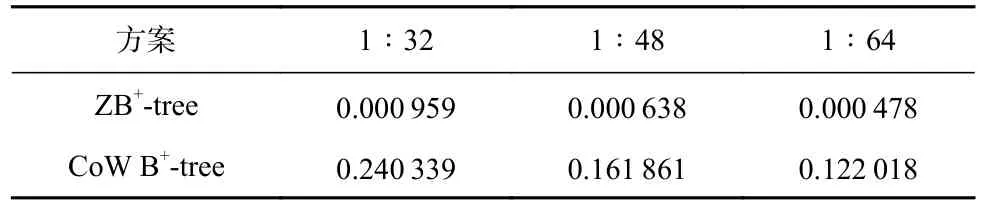
Table 8 Occupancy Rate of Seq-Zone Under Workload2 at Different Ratios表8 不同比例下Workload2 下对Seq-Zone 的占用率
在4.2.1~4.2.4 节的实验中,ZB+-tree 和CoW B+-tree都采用了动态选择Zone 的策略.该策略将叶子节点和内部节点分开存放以充分利用ZNS SSD 内部各个Zone 的空间,并且尽量减少Zone-Reset 操作,同时将不同特性的节点放在不同的Zone 来降低访问延迟.
本节的实验旨在进一步验证ZB+-tree 在不采用动态选择Zone 策略时的性能.为了保证实验的公平性,CoW B+-tree 同样不采用动态选择Zone 的策略.此外,为了体现实验完整性,本实验中我们通过统计Zone-Reset 的次数来对比ZB+-tree 和CoW B+-tree.
对于ZB+-tree,设 置1 个Seq-Zone 和1 个Cov-Zone,大小都为2 GB,然后统计Zone-Reset 次数.对于CoW B+-tree,设 置1 个Seq-Zone 和1 个Cov-Zone(按顺序写模式使用),大小都为2 GB,当某一个Zone 写满时,读出有效节点写到另一个Zone,然后进行Zone-Reset 操作并统计次数.实验数据量分别为250 万、500 万、750 万键值 对,数据分 布设置 为Zipfian,测试负载为Workload1 和Workload2.
实验结果表明,在Workload1 下,在数据量分别为250 万、500 万、750 万键值对时,ZB+-tree 均没有触发Zone-Reset 操作;而CoW B+-tree 则分别触发了10,22,37 次Zone-Reset 操 作.在Workload2 下,ZB+-tree 在数据量为250 万、500 万、750 万键值对时依然没有触发Zone-Reset 操作;而CoW B+-tree 则分别触发了2,6,9 次Zone-Reset 操作.
因此,CoW B+-tree 比ZB+-tree 会更容易触发Zone-Reset 操作,而ZB+-tree 即使不进行动态选择优化,也能够在插入大量键值时不触发Zone-Reset 操作.由于Zone-Reset 和Zone 垃圾回收操作的时间延迟高,因此ZB+-tree 相对于CoW B+-tree 具有更好的时间性能,尤其是在写密集型负载下,这种优势更加明显.
4.2.6 对Cov-Zone 的占用分析
在本节实验中,我们创建了40 个Seq-Zone 和1个Cov-Zone(每个Zone 大小都为2 GB),并分别在100万、250 万、500 万、750 万、1 000 万键值对的数据集上运行在Zipfian 分布下的Workload1 和Workload2,然后统计ZB+-tree 对Cov-Zone 的空间占用率.
实验结果如图21 所示.随着数据规模的增大,ZB+-tree 对Cov-Zone 的空间占用率呈线性增长趋势,这是因为数据规模越大,负载中涉及更新的键值越多,因此对Cov-Zone 的使用量也增大.但是,即使数据规模达到了1 000 万,对Cov-Zone 的占用率也没有超过0.50,这表明Cov-Zone 的空间不会用满,因此可以满足绝大部分应用的需要.

Fig.21 Changes in the occupancy rate of Cov-Zone by ZB+-tree图21 ZB+-tree 对Cov-Zone 的占用率变化
5 结束语
本文提出了一种ZNS SSD 感知的新型索引结构ZB+-tree,通过合理利用ZNS SSD 中的常规Zone 和顺序Zone 的特性来吸收对Zone 的随机写操作、阻断级联更新、减少读写次数.我们为2 种Zone 内的节点设计了不同的节点结构,并通过将不同访问频率的节点分散在不同Zone 中以降低访问延迟,并且满足ZNS SSD 顺序写的限制.我们利用ZNS SSD 模拟器展开了实验,并对比了ZB+-tree 和传统CoW B+-tree,结果表明ZB+-tree 在运行时间和读写次数上均优于CoW B+-tree.同时,ZB+-tree 具有更低的Seq-Zone 空间占用率,可以有效减少系统运行过程中进行的垃圾回收和Zone-Reset 操作,提高系统性能,并且对Cov-Zone 的占用率也能够在数据规模增大时始终保持在0.50 以下,可以满足大多数应用的需要.
未来的工作将主要集中在3 个方向:1)为ZB+-tree增加合理的GC 机制;2)在选择节点放置时设置更加合理的Zone 选择方案;3)在真实的ZNS SSD 设备上进行实验.
作者贡献声明:刘扬提出算法思路,完成实验并撰写论文初稿;金培权提出指导意见并修改论文.
