基于粒子群优化算法改进的XGBoost模型制备C4烯烃工艺条件优化
2023-03-27徐博涵阮敬
徐博涵,阮敬
(首都经济贸易大学统计学院,北京 100070)
C4烯烃常作为化工生产中的基础原料,以C4烯烃为原料生产清洁友好燃料已成为大势所趋[1]。增大C4烯烃产量并对其进行综合利用更是提高经济效益的必要手段。因此,优化制备C4烯烃的反应条件对提高C4烯烃收率具有重要意义。通过分析实验数据和调整反应条件,对有机化工反应进行优化,已成为近年来的研究热点。
在乙醇偶合制备C4烯烃的反应中,收率是反应C4烯烃选择性和转化率的重要指标。项阳阳[2]利用回归分析对反应数据进行建模,探究对实验有高度显著影响的因素以及各因素之间的交互作用,最后进行单因素优化。其中陈佳硕等[3]对数据建立回归模型,得到在温度和催化剂影响下C4烯烃收率的关系表达式,拟合优度达到0.98,但缺点在于该研究将由5个连续变量组成的催化剂组合视为分类变量,导致求解最佳工艺条件的范围缩小。李三杰等[4]从关联分析的角度对数据进行探究,但这一方法有着较好的可解释性,但无法对优化效果进行量化,只能确定最佳的催化剂组合。
对于各因素之间影响关系复杂、难以量化表示的实验,网络和机器学习方法在构建预测模型和优化求解过程中能够取得较好的效果。张栋等[5]在对变量进行特征选择后,利用XGBoost算法构建预测模型,利用遗传算法求解得到优化值。
王岩立等[6]、吴文俊等[7]采用机器学习方法对实验数据进行拟合,将收率最大视为目标函数,通过优化模型寻找各因素的最佳值,虽然可以得到较高的拟合优度和更大的目标值,但依然会出现因约束条件使用不当而导致的解溢出边界、计算结果不理想等问题。
虽然各学者利用统计学习和机器学习方法能够很好地拟合实验数据,提高了C4烯烃的收率,确定了最佳反应条件,但对于大多数算法来说,超参数是模型在开始训练之前设定的参数,训练过程中一直保持不变,其取值控制着模型的拟合程度[8]。因此,通过对模型参数进行优化,提高模型拟合效果,进行更精准的预测和优化,是该研究的创新之处。
为得到较高的预测精度,现以XGBoost模型为基础,以模型对已知数据的拟合优度最大为目标的优化模型,并设计粒子群优化(particle swarm optimization,PSO)算法得到最优超参数。建立XGBoost和PSO-XGBoost模型,对仿真数据进行预测,从而得到最大收率及其对应的最佳工艺条件,并通过对比验证超参数优化的有效性。
1 实验介绍
乙醇在不同的Co负载量、Co/SiO2和羟基磷灰石(hydroxyapatite,HAP)装料比、乙醇浓度以及一定温度的作用下,通过反应生成C4烯烃和乙烯、乙醛、脂肪醇等副产物。不同的催化剂组合和温度会导致产物的分布发生变化,从而对C4烯烃选择性和乙醇转化率产生影响。采用选择性和转化率描述这一可逆反应的反应程度,选择性表示某一个产物在所有产物中的占比,转化率表示反应物转换成特定生成物的百分比。在上述反应中将C4烯烃选择性与乙醇转化率的乘积表示为C4烯烃收率。C4烯烃收率最大时所对应的条件即为最佳反应条件。实验数据包含115条,记录了21种催化剂组合在不同温度下的乙醇转化率和C4烯烃选择性。以2021年全国大学生数学建模竞赛[9]数据为基础进行分析和建模,求解C4烯烃收率最大所需的温度和催化剂组合。
2 实验结果讨论
2.1 相关性分析
数据中每种催化剂组合可用4个变量表示:Co负载量、Co/SiO2和 HAP装料比、乙醇浓度、总质量,为方便表示和计算,将变量用符号表示,如表1所示。

表1 符号说明表Table 1 Symbol description table
如图1所示,对于以上定量变量,通过散点图矩阵展示其分布于相关性情况。从分布上看,各变量分布无明显规律,催化剂的质量、Co负载量等变量大多集中在一个或多个水平上。温度与乙醇转化率、C4烯烃选择性、C4烯烃收率存在一定正相关关系。还需进一步探究变量间关系。

2.2 影响因素分析
数据中共有21个实验组,其中A1~A14使用装料方式Ⅰ,B1~B7组使用装料方式Ⅱ。通过控制变量的方法,在21组实验中选取3组,作为主要的对比研究对象。3组实验的催化剂配比如表2所示。

表2 催化剂成分配比表Table 1 Symbol description table
通过控制变量的方法对催化剂载体、装料方式、反应温度进行逐个分析,探究这些因素对乙醇转化率和C4烯烃收率产生的影响。
2.2.1 催化剂载体对烯烃收率的影响
催化剂载体能够起到提升催化剂活性、提高催化效率的作用。当前催化剂组合中仅有A11使用石英砂作为载体,其余均为HAP。为研究催化剂载体不同对反应的影响,在所有催化剂组合中通过控制变量的法则找到A11和A12两组实验,除催化剂载体不同之外,其余条件均相同。
对两组实验在不同温度下的实验数据进行分析,对比其在不同温度下乙醇转化率和C4烯烃收率的变化情况。两组实验的乙醇转化率和C4烯烃选择性变化趋势分别如图2、图3所示。随着温度升高乙醇转化率和C4烯烃选择性逐渐增大,经过对比发现,和石英砂相比,A12催化剂使用HAP作为载体,在所有温度条件下乙醇转化率更高,C4烯烃选择性更高,因此使用HAP载体效果更好。
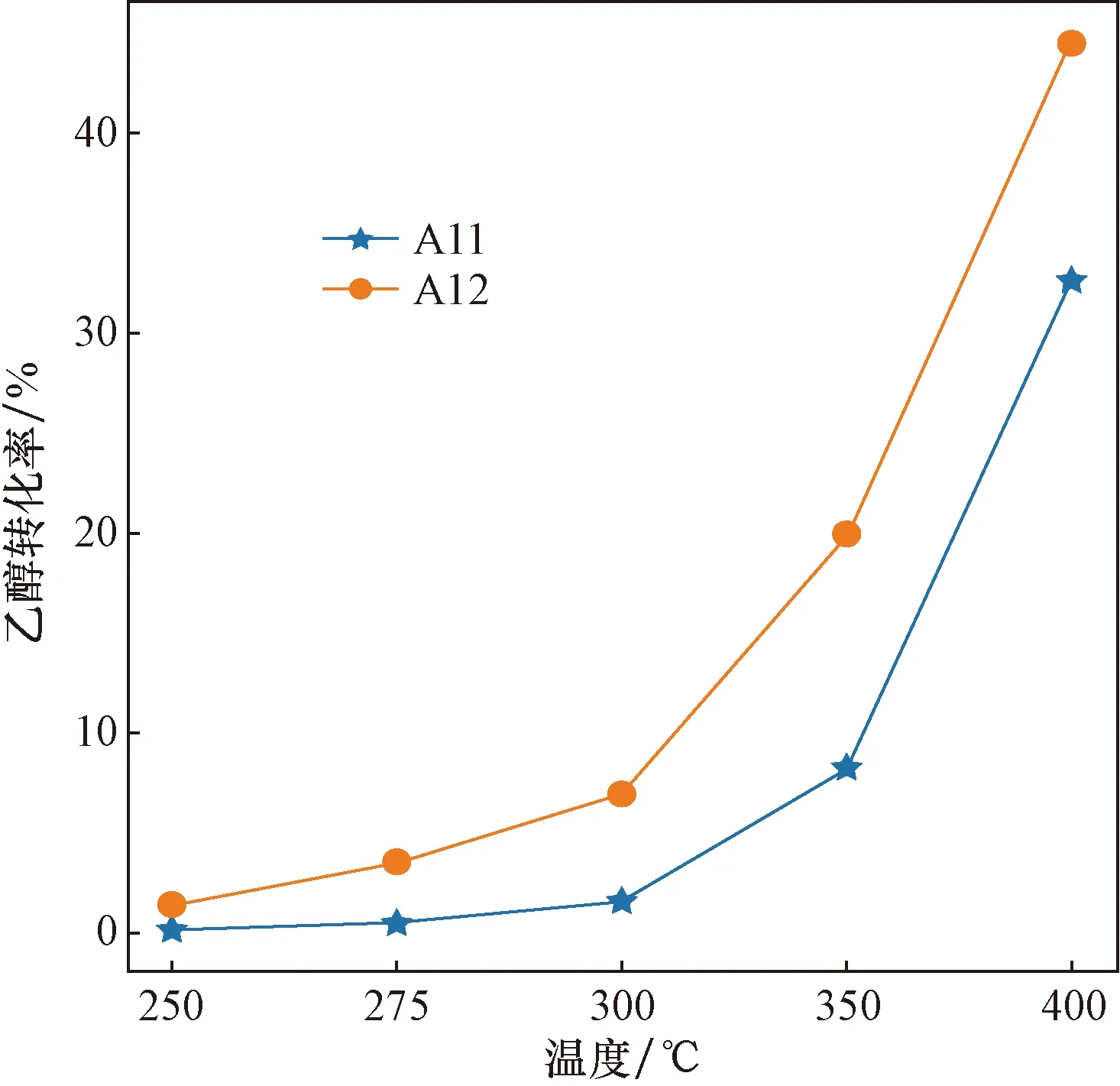
图2 不同催化剂载体乙醇转化率折线图Fig.2 Line chart of ethanol conversion of different catalyst supports

图3 不同催化剂载体C4烯烃选择性折线图Fig.3 Line chart of C4 olefin selectivity for different catalyst supports
2.2.2 装料方式对烯烃收率的影响
除催化剂载体不同之外,还应注意到A1~A14使用装料方式Ⅰ,B1~B7使用装料方式Ⅱ,为研究不同装料方式对反应的影响,通过控制变量的法则找出A12和B1两组实验,除催化剂装料方式不同之外其余条件均相同。对两组实验在不同温度下的实验数据进行分析,对比其在不同温度下乙醇转化率和C4烯烃收率的变化情况。两组实验的乙醇转化率和C4烯烃选择性变化趋势分别如图4、图5所示。

图4 不同装料方式乙醇转化率折线图Fig.4 Line chart of ethanol conversion by different charging methods

图5 不同装料方式C4烯烃选择性折线图Fig.5 Line chart of C4 olefin selectivity for different charging methods
虽然装料方式不同,但各个温度下的乙醇转化率基本相同,C4烯烃选择性在低于275 ℃时完全相同,高于275 ℃时装料方式I效果更好。
由以上两项对影响因素的初步分析可得出结论,在确定最优反应条件时,应使用HAP作为催化剂载体。同时,因为装料方式对反应程度无显著影响,在后续研究中不考虑这一变量。
因此可将乙醇转化率和C4烯烃选择性作为因变量,Co/SiO2、Co负载量、HAP、乙醇浓度、温度作为自变量。以C4烯烃收率最大为目标,进一步探究因变量和自变量的关系,从而确定最佳的反应条件。
2.2.3 反应温度对烯烃收率的影响
由表3可知,温度和乙醇转化率、C4烯烃选择性、C4烯烃收率的相关系数均在0.7以上,并且显著性检验P<0.001。对于所有催化剂组合,乙醇转化率和C4烯烃选择性均随着温度升高而升高。

表3 温度与各因变量相关系数表Table 3 Correlation coefficient between temperature and dependent variable
3 原理分析和模型参数选择
3.1 XGBoost算法原理分析
XGBoost算法思想是在训练一棵树的基础上训练下一棵树,通过不断训练弥补差距的树,用树的组合实现对真实分布的模拟。算法优势在于目标函数的正则项能够控制模型复杂度,有效避免过拟合出现,通过计算损失函数的二阶导数,又进一步考虑了梯度变化的趋势,达到拟合速度快、精度高的效果[10]。
3.1.1 XGBoost建立回归树拟合
XGBoost使用分类回归树(classification and regression tree,CART)模型,可看作根据输入的xi预测yi的结构,公式为
(1)

obj(θ)=l(θ)+Ω(θ)
(2)
式(2)中:l为训练损失函数,用来衡量模型的预测能力,预测准确率越高l则越小;Ω为正则化项,与树的复杂度有关。

(3)
在添加最后一个新函数时,得到一棵最优的CART树ft(xi),该树是在ft-1(xi)树的基础上使得目标函数最小,即
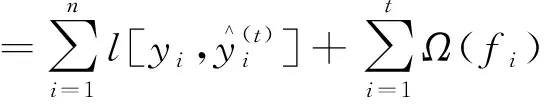
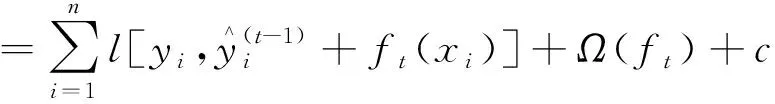
(4)
式(4)中:c为简化后与自变量无关的常数部分。对目标函数进行求解,需要分为损失函数和正则项两部分计算。
3.1.2 处理损失函数
为了找到能够最小化目标函数的ft(xi),模型对其中的损失函数进行二阶泰勒展开,得到目标函数的近似函数为

Ω(ft)
(5)
在ft=0处进行二阶泰勒展开可得

Ω(fi)+c
(6)
去掉常数项可得
(7)
式(7)中:gi和hi被定义为
(8)
3.1.3 正则化项计算
首先将树的定义可表示为
ft(x)=ωq(x),ω∈RT,q:Ra→{1,2,…,T}
(9)
式(9)中:ω为用来记录各个叶子节点得分的向量;RT为长度为T的一维向量的集合;q(x)函数的作用是将输入的xi∈Ra映射到某个叶子节点,→表示映射关系。在XGBoost模型中,正则化项可表示为
(10)
式(10)中:λ为正则化项的权重;γ为用于控制节点分裂的阈值,因此λ和γ越大,模型越简单。
Ij={i|q(xi)=j}为分配给第j个叶子的数据点的指数集合,至此公式可变形为

(11)

(12)
求解所得到的最优ω值和目标函数值分别为
(13)
(14)
3.2 模型参数选取和调整
3.2.1 参数选取
超参数直接影响XGBoost模型的性能和预测的效果,通常选择超参数是手动调节的,依靠有限次数的实验,得到一组相对合适的超参数。这样的方法很容易错过最优超参数组合,为了可以更合理、更准确地选择最优超参数,采用粒子群对超参数进行优化[12]。
XGBoost模型预测时需要确定3种参数:通用参数、Booster参数和学习任务参数。其中学习任务参数定义了最小化的损失参数,对于回归问题默认损失函数为均方根误差(root mean squared error,RMSE),与减小模型误差目的相同,不再进行更改。通用参数根据CART树及其公式描述,选择gbtree表示的树模型对数据进行拟合,用RMSE作为损失函数。相比前两种参数,Booster参数对算法的性能有着更大的影响,包括学习率、树的最大深度、最小权重总和、每棵树随机采样的比例等参数。
如果max_depth树的最大深度过大会导致模型过拟合,过小会导致模型过于简单。n_estimators 迭代次数过多会影响训练速度,过少会得不到理想的效果。为降低仿真优化步骤的时间复杂度,将原始数据的20%作为验证集,80%作为训练集,在验证集中考察模型拟合程度和误差。首先,应用如表4所示的XGBoost的初始化参数拟合数据,在训练集和测试集中的拟合情况如图6所示,模型出现过拟合现象,训练集精确度为0.99,平均绝对误差(mean absolute error,MAE)为4.58,验证集精确度为0.76,MAE为247.83。由于超参数对XGBoost模型性能有着较大的影响,并且参数过多,为了得到更精确的仿真模型,选择利用PSO算法寻找最优参数。

表4 参数初始化值Table 4 Initial values of parameters
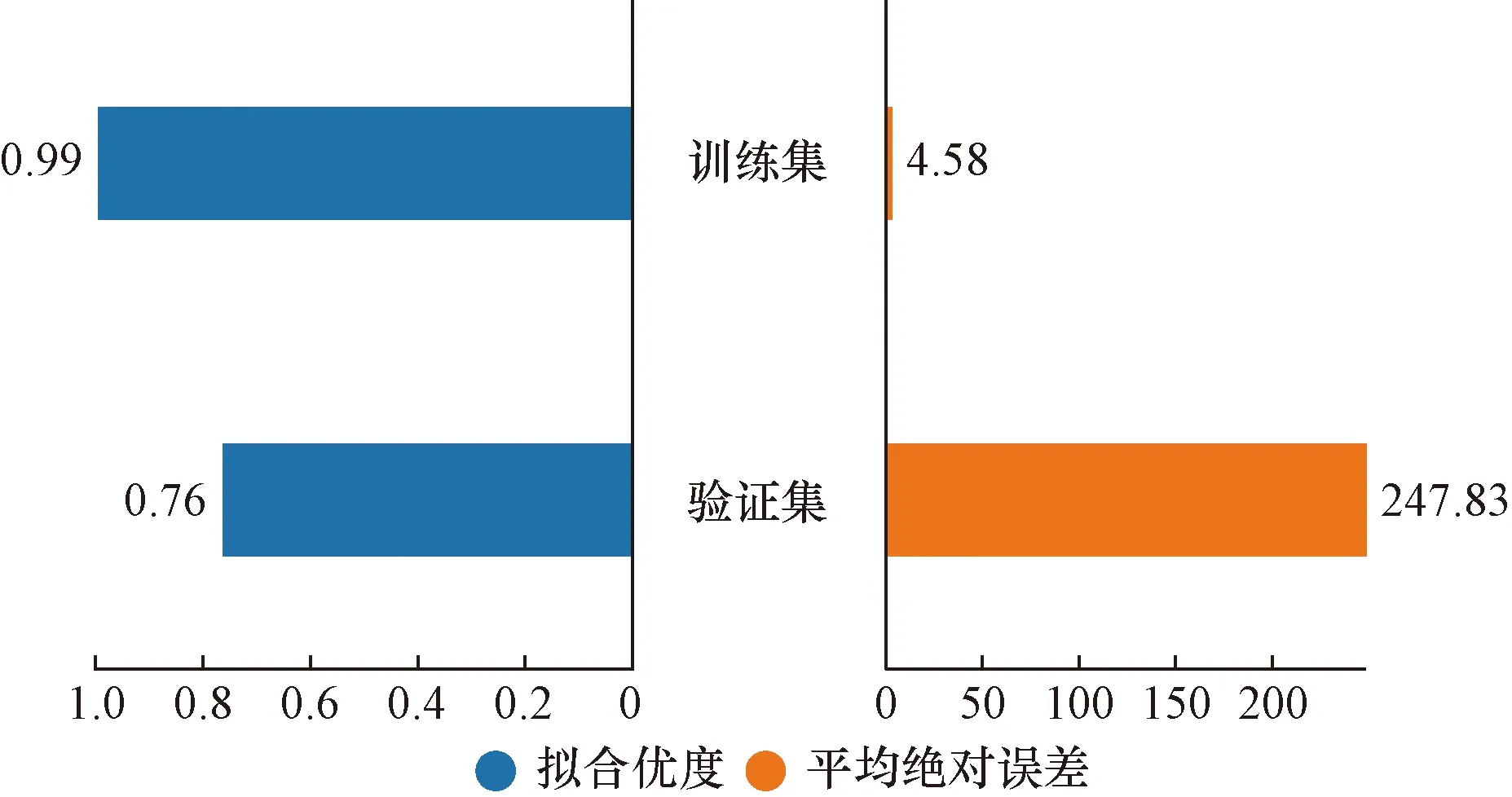
图6 XGBoost拟合效果Fig.6 XGBoost model fitting effect
3.2.2 应用粒子群算法进行调参
粒子群算法作为一种智能优化算法,常用来求解复杂的多目标优化问题。算法不依赖于梯度下降为搜索方向,而是以适应度函数值作为衡量标准,依概率随机地在决策空间中进行寻优搜索。该算法的优势在于操作简单、收敛速度快,目前已被广泛应用于函数优化、神经网络训练、模糊系统控制以及其他遗传算法的应用领域。
应用python中的optunity调参优化库,将验证集的R2作为目标函数,选择粒子群算法作为优化方法。调用optunity.maximize函数将约束条件和优化方法作为参数输入,执行150次。执行粒子群算法过程中,将一些随机粒子作为初始解,随后在每一次迭代中,粒子与个体极值和历史全局最优解进行比较,更新自己的速度和位置。
vi=vi+c1rand()(pbestti-xi)+
c2rand()(gbestti-xi)
(15)
xi+1=xi+vi+1
(16)
式中:i=1,2,…,N,N为群中的粒子总数;vi为第i个粒子的速度;rand ()为介于(0,1)的随机数;xi为粒子的当前位置,当算法达到指定迭代次数并且全局最优位置满足最小界限时终止迭代,初始状态分散的粒子聚集在一个小范围中或一个点附近。
通过粒子群算法的寻优计算,最终确定文本所用的XGBoost回归模型最佳参数如表5所示。应用最佳参数组合拟合数据,验证集效果得到显著提升,过拟合现象有所缓解。如图7所示,训练集R2为0.99,验证集R2为0.93,MAE为78.00。相比优化之前模型拟合优度提升17%,平均绝对误差降低169,优化效果明显。
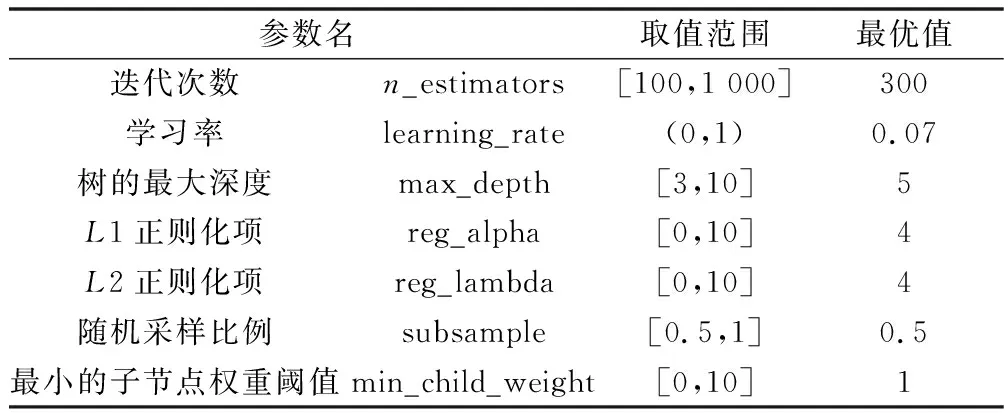
表5 最优参数值Table 5 Optimal parameter value

图7 PSO-XGBoost拟合效果Fig.7 PSO-XGBoost model fitting effect
4 模型求解
4.1 构造仿真数据
对于乙醇制备C4烯烃这一可逆反应,其反应程度除了受到催化剂和温度的影响之外,还需考虑有机物分子结构复杂、不稳定的特点,以及生成物之间的相互影响、生成物对产物的影响。鉴于反应的复杂性和可变性,函数往往带有随机参、变量[13],导致基于数学模型的优化方法在应用中具有相当局限性。
利用仿真方法可以求解一些难以用数学模型表达的优化问题。侯影飞等[14]通过建模对微波反应器的负载参数进行仿真训练,优化出使得微波反应器获得最优加热均匀性和加热效率的负载参数。仿真优化的过程先用XGBoost模型拟合自变量和因变量,并通过粒子群算法调整参数提升拟合优度,最后将生成的催化剂和温度组合策略逐一输入仿真模型中,比较模型训练后的输出结果,从中确定最佳制备条件[15-17]。
通过对Co/SiO2质量、Co负载量、HAP质量、乙醇浓度、温度5个自变量设置取值范围和间隔,并将各自变量取值进行组合,生成1 312 000种反应条件的组合。其中温度取值为250~450、步长为5的序列;Co/SiO2质量取值为10~200、步长为10的序列;HAP质量为50~200、步长为10的序列;Co负载量为0.5~5、步长为0.5的序列;乙醇每分钟滴入的浓度为0.3~2.1、步长为0.3的序列,设置模型的输出结果为C4烯烃收率。
4.2 应用改进后模型优化工艺条件
经过粒子群优化算法调整后的XGBoost模型可以较好地拟合数据,将模型应用于构造出的测试数据集。其中温度、Co/SiO2质量、HAP质量、Co负载量、乙醇浓度作为输入变量,应用改进后的XGBoost模型对输入数据进行预测,输出每一种条件下对应的C4烯烃收率。找出输出结果中最大值及其对应的反应条件。最终得到C4烯烃收率最大值为43.52%,对应的反应条件为450 ℃、Co/SiO2质量为200 mg、Co负载量为1%、HAP质量为200 mg、乙醇浓度为0.9 mL/min,即催化剂组合为200 mg 1%Co/SiO2-180 mg HAP质量-0.9 mL/min乙醇浓度。
4.3 模型结果分析
如图8所示,从各变量重要程度看出,温度对C4烯烃收率的提升起到了重要的作用,将各变量F-score进行归一化后,温度变量的影响占比56.5%。其次是Co/SiO2质量,结合相关系数热力图(图9)可知,Co/SiO2质量增大能够对反应起到促进作用。Co负载量和乙醇浓度变量重要程度较低,从相关系数可知,C4烯烃收率随着两个变量的增大而减小。HAP质量对反应优化的贡献最小,影响占比仅有5%。

图8 变量重要程度直方图Fig.8 Histograms of the importance of variables
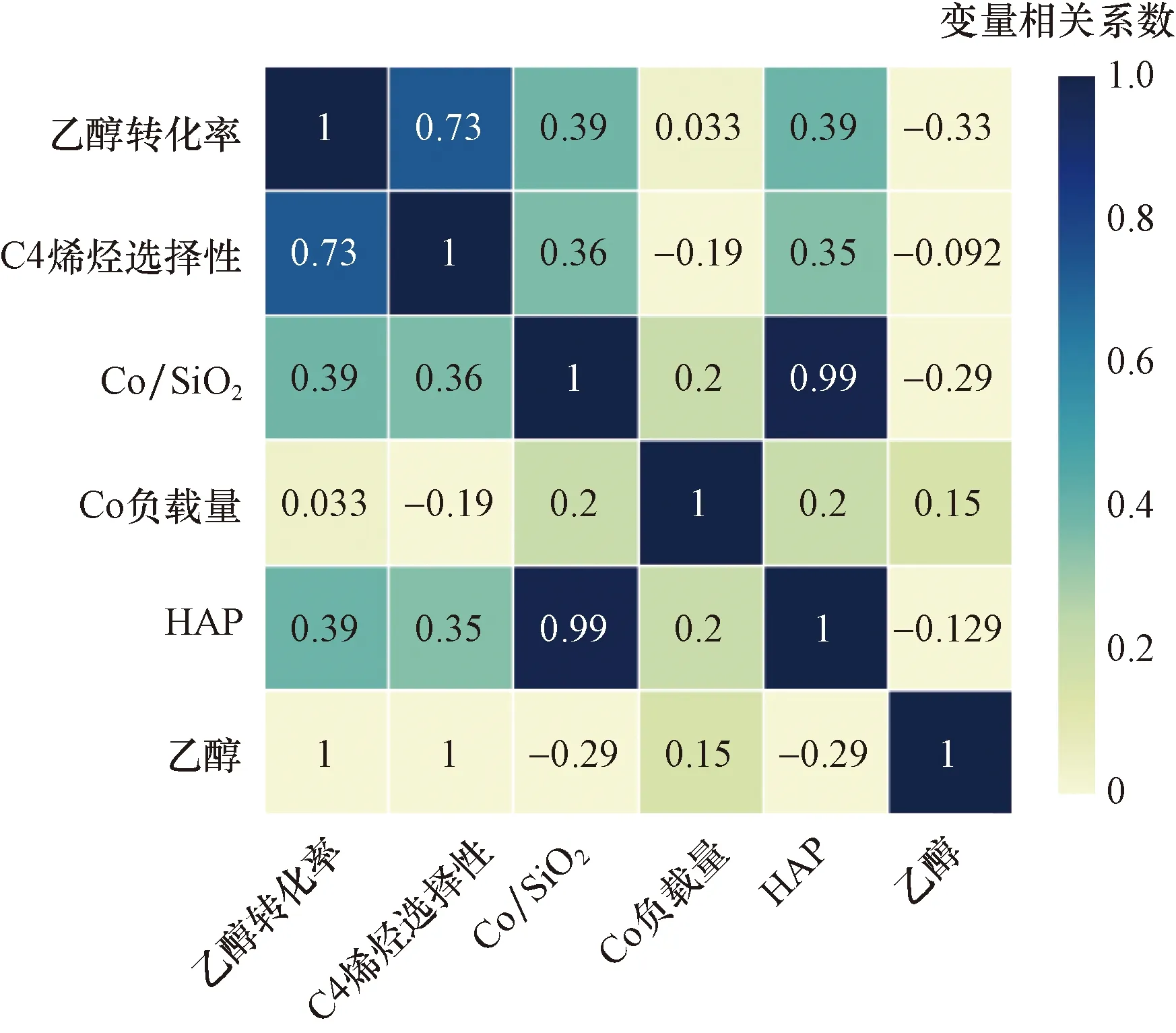
图9 变量相关系数热力图Fig.9 Variable correlation coefficient thermal map
5 结论
XGBoost和粒子群算法等机器学习模型,已广泛应用于各个领域的系统分析及优化,采用粒子群算法确定XGBoost模型的最佳参数,将其用于提升XGBoost回归模型对数据拟合的效果,从而进行更精确的仿真训练、寻找最优反应条件,得出如下结论。
(1)对原始数据给出的实验结果进行分析可知,对C4烯烃收率产生影响的有如下5个变量:Co/SiO2、Co负载量、HAP质量、乙醇浓度、温度。并且随着温度增加,乙醇转化率和C4烯烃选择性逐渐增大。
(2)通过粒子群算法确定XGBoost模型的最优参数,目的在于提高数据拟合精度,得到更准确的预测结果。实验结果表明,使用最优参数的XGBoost模型拟合优度达到93%,能有效提高模型的精度。
(3)通过将调参后的XGBoost模型应用至构造的数据中,输出的C4烯烃收率最大值为43.52%,对应的最佳反应条件为:温度450℃,Co/SiO2质量为200 mg,Co负载量为1%,HAP质量为200 mg,乙醇浓度为0.9 mL/min,即催化剂组合为200 mg 1%Co/SiO2-180 mg HAP-乙醇浓度0.9 mL/min。
(4)通过对数据进行拟合以及仿真训练确定最佳工艺制备条件,为其他工业生产中的问题提供了方法上的参考,具有一定的经济价值。
