基于BERT和LightGBM的文本关键词提取方法
2023-03-19何传鹏王明胜郭茹燕巨家骥
何传鹏,尹 玲,黄 勃,王明胜,郭茹燕,张 帅,巨家骥
(上海工程技术大学 电子电气工程学院,上海 201620)
关键词提取(Keywords Extraction)是为了方便人们在阅读工作过程中由于时间有限无法详细了解文本内容而产生的一种自然语言处理技术。该技术可从文本中选择若干个词,这些词具有易于理解,可高度概括全文,且不改变文章原意的特点。目前,该技术被广泛应用于文献检索、文本摘要、文本聚类等领域。网络技术的飞速发展促使网络用户数量快速增加,进而导致互联网新闻内容参差不齐。面对大量的文本数据,例如网络评论、社会新闻等,若能够在短时间内提取出有效的信息,既能节省工作时间,也能为生产者以及社会带来更多效益[1-2]。
目前,已有一系列关于提高关键词提取效果的研究。文献[3]提出了基于Xgboost算法的关键词自动抽取方法。该方法融合TF-IDF、词性、词语长度等多种特征,用Xgboost算法来对关键词进行自动抽取。文献[4]提出了融合词和文档嵌入的关键词抽取算法。该算法中,通过计算单词与文档在相同维度上的向量表示,得出语义相似度,进而通过初始化单词节点的权重计算每个单词以及筛选出词的分值,最终选择得分较高的前k个候选词作为文章关键词。文献[5]提出了基于word2vec与textrank的关键词提取研究。首先将经过去除停用词、jieba分词、文本清洗等预处理后的文本doc输入到word2vec模型中进行训练,得到每个词的向量表示,并计算每个词相互之间的余弦距离cosθ;然后结合内部文档确定连接边。这种方法不仅照顾到外部文档信息,还能将内部文档信息联系起来,可解决相同语义关键词同时被抽取出来的问题。近几年,由于BERT(Bidirection Encoder Representation from Transformers)预训练方法的产生,许多研究开始基于BERT来进行关键词抽取,并取得了良好的成果。文献[6]提出了融合BERT语义加权与网络图的关键词抽取方法,利用BERT预训练的词向量,使得textrank迭代运算出的词语综合得分排序更加准确,抽取效果更佳。尽管这些模型在特定数据集上对算法进行了优化,但是当数据量较多且文本类型错综复杂时,处理数据较耗费时间,且当数据规模超过一定程度后,准确率将有所下降。
随着科技不断发展,人们认知的需求越来越高,为了节省更多的时间,必须寻找效率更高且算法更准确的模型来满足当今人们日益增长需要处理和分析海量数据的需求。本文提出潜在狄利克雷分布(Latent Dirichlet Allocation, LDA)、BERT、轻量梯度提升机(Light Gradient Boosting Machine,LightGBM)相结合的算法,即LB-LightGBM算法。该算法首先利用LDA主题模型得到主题及其主题词分布,根据设定的阈值进行关键词初步筛选;然后将筛选出来的特征词和原评论文本拼接,一起输入到BERT模型中进行词向量的训练,并结合LightGBM算法进行关键词的二次过滤;最终确定预测概率较高的词作为文本关键词。
1 相关工作
1.1 基于主题模型的关键词检测
1.1.1 主题模型概述
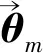
1.1.2 主题模型提取步骤

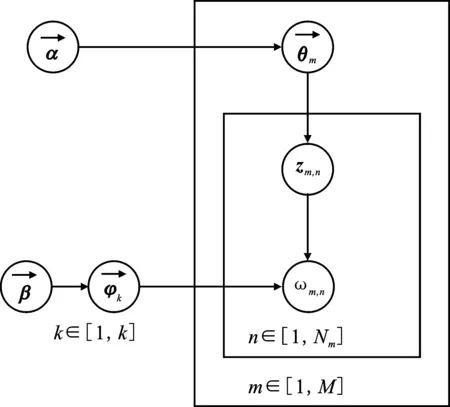
图1 LDA主题模型Figure 1. LDA topic model
1.2 BERT语言模型
针对传统语言模型无法解决一词多义的问题[17],本文采用BERT预训练语言模型进行解决,具体模型结构如图2所示。图中最下方表示输入向量,它由3种向量按元素进行相加得到,中间部分为Transformer的编码器(Encoder)结构[18],相当于特征提取器。作为本文使用的结构模型,其具有12层Encoder结构,每个Encoder有相似的组成部分,主要包含自注意力模块(Self-Attention)和前馈网络模块(Feed Forward Network)。自注意力模块不仅只关注当前词,还能够学习到更多相关联的语义信息,从而得到上下文的语义。前馈网络模块主要为非线性函数,以适应复杂语义环境。本文使用拼接最后4层隐含层的向量作为最后训练得到的词向量进行分类实验。
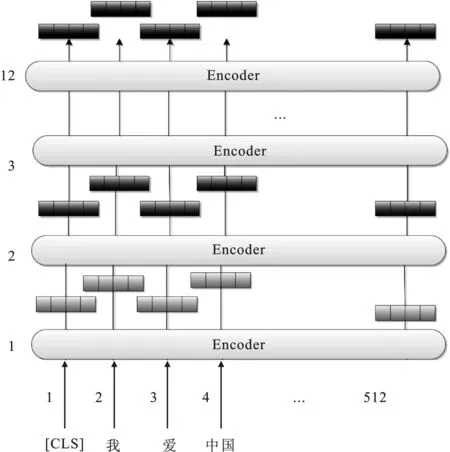
图2 BERT预训练语言模型Figure 2. BERT pre-training language model
1.2.1 BERT输入组成
BERT[19-20]中每个向量的输入由词向量(Token Embeddings)、段向量(Segment Embeddings)和位置向量(Position Embeddings)3种向量按元素进行相加组成,如图3所示。词向量(Token Embeddings)会将每个token转化成固定维度的向量,其中的E[CLS]表示每一个句子开始的信息,E[SEP]表示两个句子分割的信息。段向量(Segment Embeddings)用来区分两个不同的句子,其中EA和EB分别表示两个句子的段向量。Segment Embeddings 层只有两种向量表示,即0和1。第1个句子中的各个token取为0,第2个句子中的各个token取为1。如果输入只有一个句子,则它的Segment Embeddings为全0。Position Embeddings用来表示输入序列的顺序性,不同位置的相同单词有着不同的向量表示。得到这些向量之后,依次按元素相加,得到一个合成表示,即BERT编码层的输入部分。
图3 BERT预训练模型输入向量构成Figure 3. BERT pre-training model input vector composition
1.2.2 BERT内部结构组成
BERT内部结构如图4所示。Normalization的目的是把数据转化为均值为0方差为1的数据,以防止数据落在激活函数的饱和区里。内部有残差连接,以保证信息可以完整地传到下一层。
BERT最重要的结构是自注意力机制,其完全取代了卷积神经网络和循环神经网络,能够使用较短的信息传递路径学习文本中的长距离语境依赖。自注意力机制采用了尺度缩放点积注意力(Scaled Dot-product Attention)[21]来计算注意力权重。
(1)
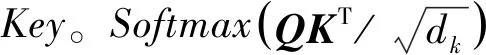
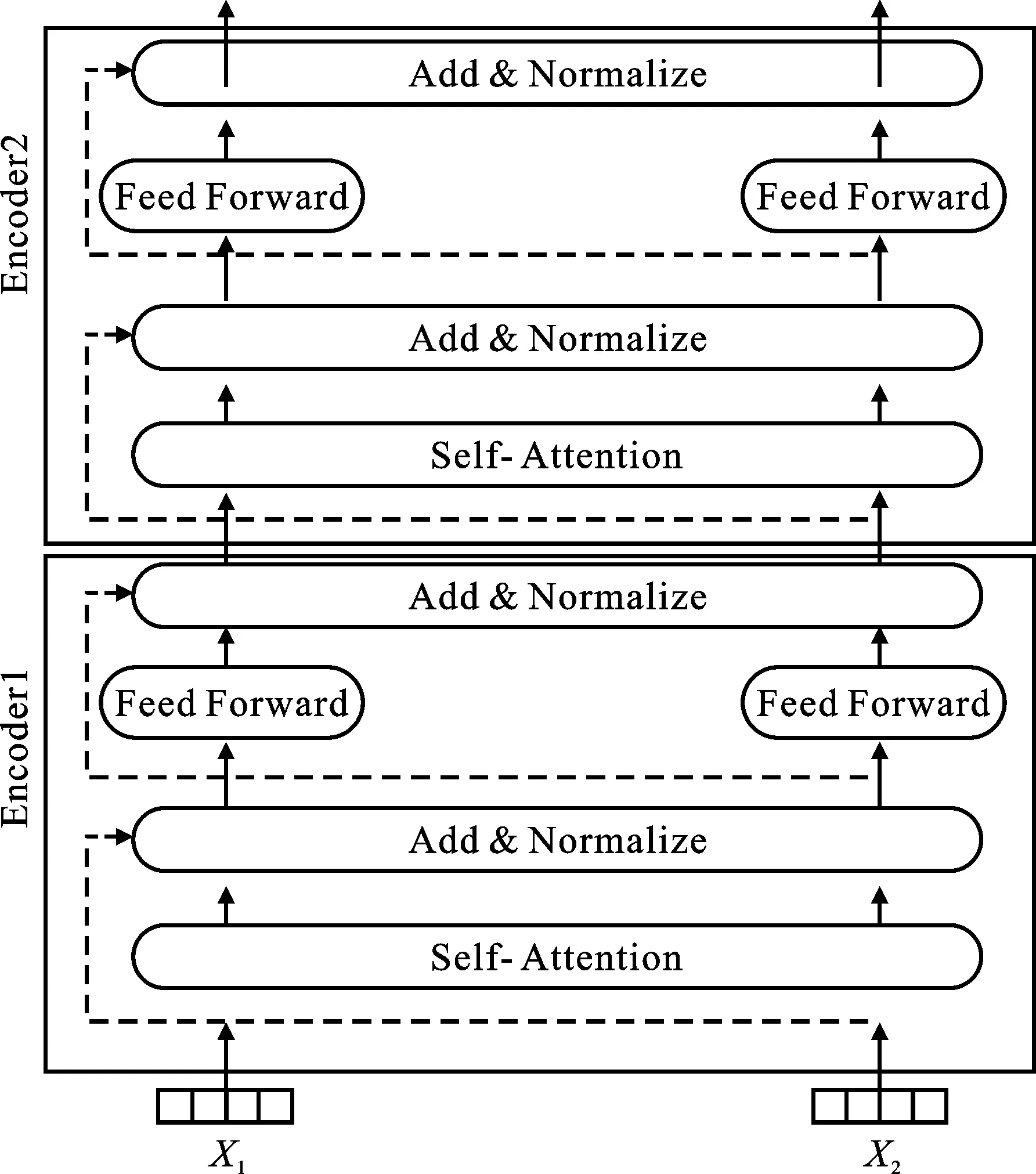
图4 BERT内部结构Figure 4. BERT internal structure
在自注意力机制中,Q、K、V都是由输入序列的向量生成的矩阵。记xi是输入序列中第i个词对应的行向量,维度为dmodel,qi、ki、vi分别是Q、K、V的第i行向量,则
(2)

然而单一的自注意力机制获取的子空间信息有限,为了获得更加丰富完整的语义信息,需使用多头注意力机制(Multihead-Attention)。该机制不仅只初始化一组Q、K、V的矩阵,而是初始化多组,并将多组输出连在一起,与随机初始化好的矩阵相乘,最后得到一个最终的矩阵,以便获得更多的子空间信息。由此过程可以得到预训练的词向量,为下一步关键词提取做准备。
1.3 LightGBM算法
1.3.1 LightGBM算法概述
通过BERT特征提取器获得的特征主题向量,采用LightGBM算法将主题信息提取问题转化为二分类问题。轻量梯度提升机是梯度提升决策树(Gradient Boosting Decision Tree,GBDT)衍生的一个算法框架,其能够使算法更加高效地并行训练,解决了GBDT在大规模数据集上应用效果不明显的问题。优化一些基于预排序方法的决策树算法(Xgboost)可降低空间消耗以及减少时间成本。LightGBM的并行训练效率较高,且具有模型训练时内存消耗较低、测试准确率高、海量数据处理速度快等优点。单边梯度采样(Gradient-based One-Side Sampling,GOSS)在采样过程中可保留梯度较大的数据,在计算增益时梯度较小的数据被赋予一定权重,使训练更关注训练不足的样本。互斥稀疏特征绑定(Exclusive Feature Bundling,EFB)通过降维的方式,把冲突比例(衡量特征不互斥程度)较小的两个特征进行捆绑,得到低维稠密的向量,从而加快训练速度而不损失精度。从按层生长(Level-wise)转变为按叶子生长(Leaf-wise)的决策树生长策略,从当前叶子中找到分裂增益最大的一个进行分裂,一直循环下去,同时将深度进行限制,可有效控制模型复杂度,避免产生过拟合[22]。
1.3.2 LightGBM算法优化
LightGBM算法的突出特点是直方图优化。直方图算法的基本思想是先把连续的浮点特征值离散化成若干个整数,并且将其建立为一个同等宽度的直方图。遍历数据时,以离散化后的值作为索引,在直方图中累积统计量。遍历一次数据后,直方图就会累加统计量,遍历直方图寻找最优分割点,减少了内存消耗,不需要额外存储预先排序的结果,降低了计算成本。将BERT模型预训练出来的主题词向量输入到LightGBM算法中进行二次过滤筛,即可选出最后的关键词。
2 基于LightGBM算法的文本关键词提取
本文基于LightGBM算法提出融合主题模型(LDA)、BERT、轻量梯度提升机(LightGBM)的算法,即LB-LightGBM。该算法的关键词提取研究框架如图5所示。首先对文本进行词袋模型编码,输入到LDA模型中,获得每条评论的主题分布以及每个主题的词分布;然后,对得到的特征词分布矩阵设置合适的阈值,选取超过阈值的词作为关键词提取的初步筛选词,并将其与评论文本进行拼接融合一起输入到BERT模型中,进行词向量表示,得到包含主题信息的词向量;随后,再经由LightGBM算法将关键词提取转换为二分类问题;最终选择预测概率较高的词作为最终的文本关键词。
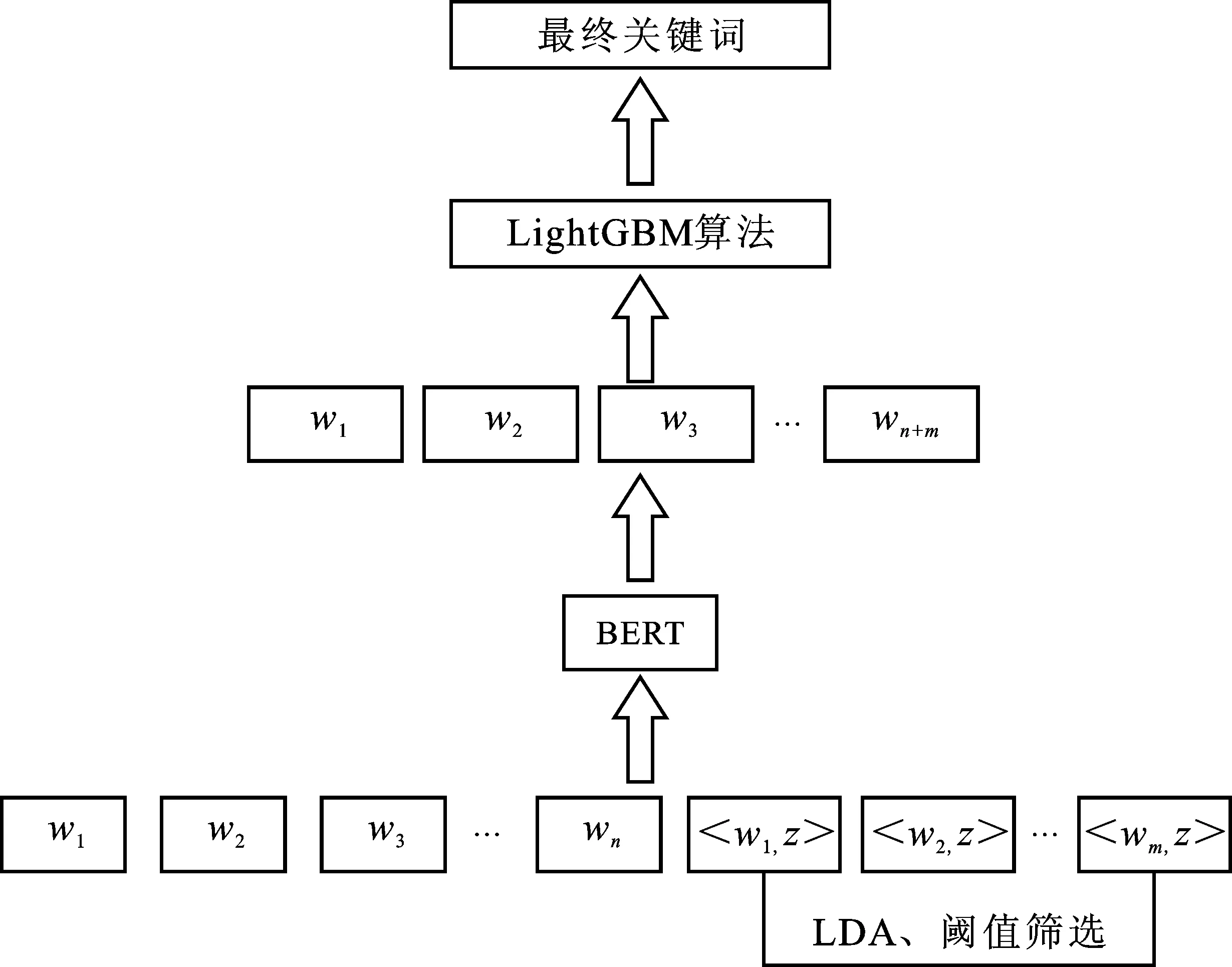
图5 研究框架Figure 5. Research framework
2.1 评论主题信息检测与提取

(3)
根据设置的阈值,选取ZW中超过设定阈值的词作为主题词。
2.2 利用BERT进行向量表示
为了得到更加丰富的主题语义信息以及上下文信息,本文将原文本信息里融合包含该文本主题的信息进行拼接作为向量的输入,输入到BERT模型中,训练出包含文本信息的主题向量。每条评论矩阵行数为dk,列数为n+m(文本长度为n,主题词个数为m),W=
3 关键词提取
根据式(3),选取阈值为0.05,筛选出符合条件的主题词。通过上述步骤建立一个样本集T,则T={(w1,y1), (w2,y2)…(wm,ym)},其中wi为上述训练出来的主题词向量,yi∈{0,1}为词向量标签,y初始化为1,利用LightGBM算法进行概率预测,设置分裂阈值以及最大深度等参数,具体步骤如下所述。
步骤1对建立的样本T进行Normalization
(4)
步骤2利用式(5)初始化梯度值θ
(5)
步骤3进行直方图构建以及直方图差加速。先将连续的浮点特征值离散化成若干个整数,并且将其建立为一个同等宽度的直方图,进行分桶操作。遍历数据时,以离散化后的值作为索引,在直方图中累积统计量。遍历一次数据后,直方图就会累加统计量,遍历直方图寻找最优分割点。与此同时可以用直方图做差加速,叶子直方图等于其父亲节点直方图减去其兄弟直方图,进而提升优化速度。构建过程如图6所示;

图6 直方图构建过程Figure 6. Histogram construction process
步骤4调节迭代次数、叶子数量、分裂阈值、最大深度、存入bin的最大数量等参数,输出预测概率,通过设置阈值,得到分类结果。
4 实验分析
本文选择百度算法竞赛公开的数据集,包含数十万篇百度网站上的新闻报道以及媒体评论,通过实验来验证本文算法在关键词提取方面的性能。本文采用精确率(Precision,P)、召回率(Recall,R)、F1值作为关键词提取评价指标。
LDA中主题数的确定关系到最终关键词提取的准确性。本文采用困惑度(Perplexity)为指标计算最佳主题数。困惑度可用来衡量文档所属主题的不确定性程度,其值越低,说明LDA模型越好。困惑度值计算方法如式(6)所示。
(6)
根据式(6)可画出Perplexity-topic number曲线,如图7所示。主题数过多会导致计算复杂度增加,易产生过拟合,影响最终分类准确度。由图7可知,当主题数为45时,困惑度值较小而主题数不至于过多,因此实验确定主题数为45。
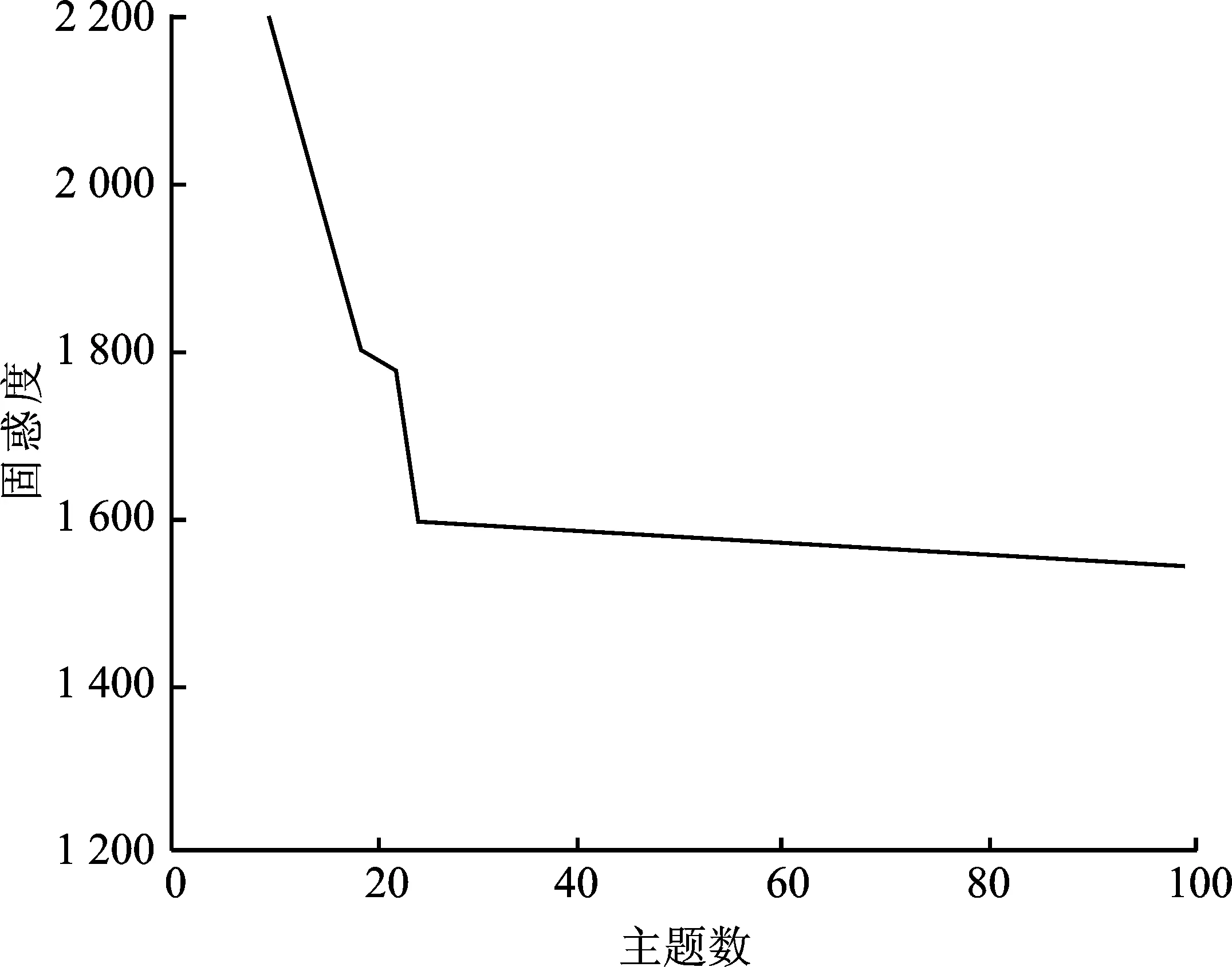
图7 Perplexity-topic number变化曲线Figure 7. The changing curve ofperplexity-topic number
实验中将选择3~6个关键词来进行实验比较分析,并将抽取结果与数据集中的关键词进行对比。本文选择TextRank、LDA、LightGBM算法抽取的关键词进行对比,对比结果如表1、图8~图10所示。
从表1和图8~图10可知,本文提出的LB-LightGBM方法优于相关方法,且TopN越小,其精确率、召回率、F1值越高,本文方法F1平均值比当前最优方法提升3.5%。因此考虑实验的整体效果,可以看出本文方法的各项指标值高于主流的大多数方法,整体表现显著提高。
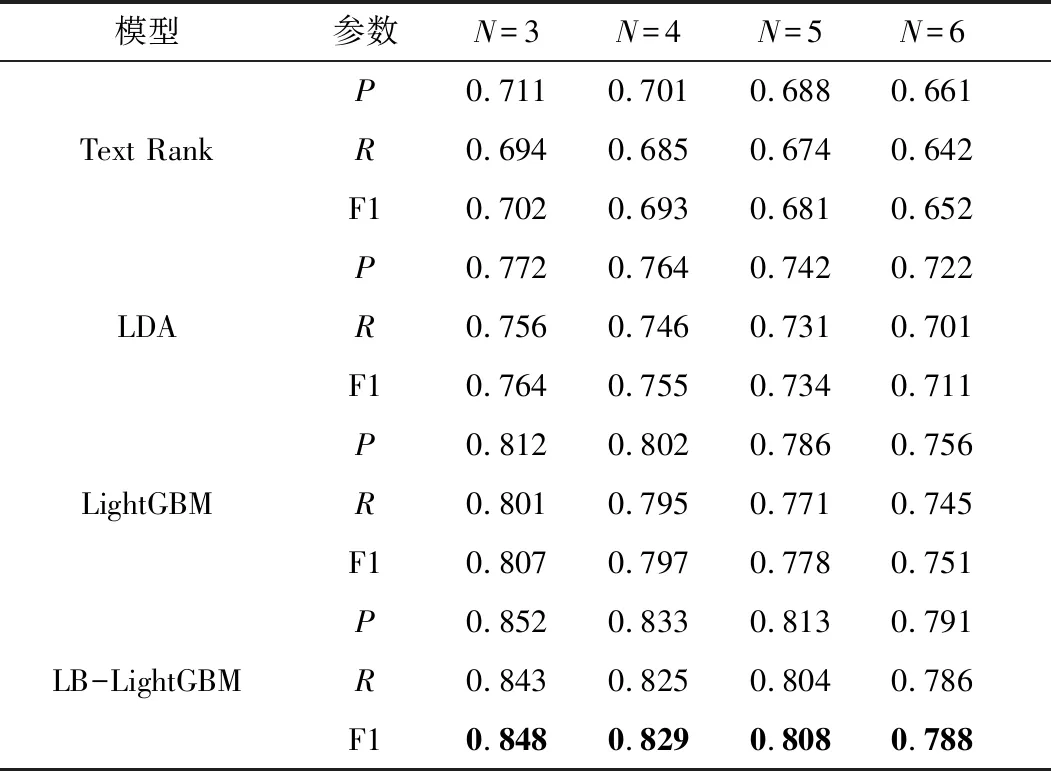
表1 多类关键词提取方法对比结果
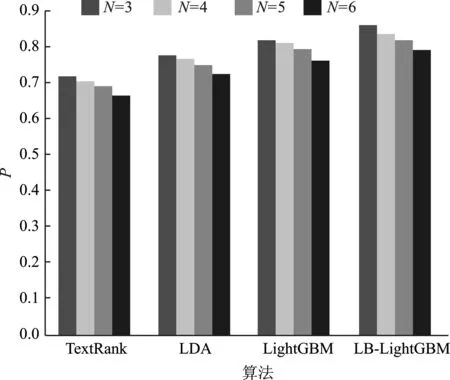
图8 精确率P变化Figure 8. The change of accuracy P

图9 召回率R变化Figure 9. The change of recall R
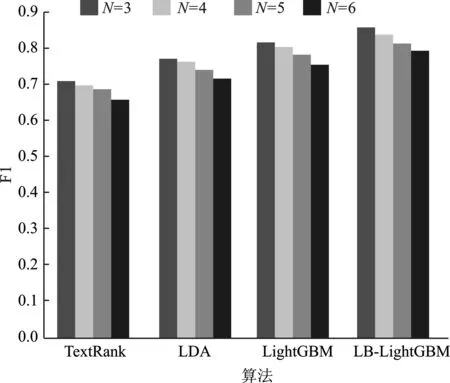
图10 F1值变化Figure 10. The change of F1 value
5 结束语
关键词提取是文本研究领域的重要任务。自然语言处理中的文档分类、摘要生成等均与关键词提取技术紧密相关。本文提出的方法主要分为:LDA主题模型初步筛选出候选关键词、BERT预训练词向量、LightGBM的二次过滤筛选出最终关键词。本文在提取较少关键词进行了一定的研究,但并没有针对更长文本以及提取更丰富的关键词做深入探讨。因此,下一步将针对长文本关键词提取做研究,找到适用于各类文章关键词提取的算法。
