改进U−Net网络的高纹理表面缺陷检测方法
2023-03-19杨彬亚森江木沙张凯
杨彬,亚森江·木沙,张凯
(新疆大学机械工程学院,新疆 乌鲁木齐 830047)
1 引言
缺陷检测是生产实际中不可缺少的一个程序。传统的机器视觉在检测物体缺陷时,必须要设定明确的规则去进行检测。但是在实际生产中很难用这种方法去实现检测要求。当今工业产品外形的多样性,使得很多生产企业员工或技术人员很难用这些特殊规则去描述其产品外表的缺陷。虽然人们很容易去看懂一个缺陷,但是真正用程序化语言去描述它是非常困难的。深度学习技术是一种不需要人工设计规则的数据驱动方法。
通过构建多层网络来构建基于视觉的缺陷检测模型,用于评估产品外表上的缺陷。同时,利用合理的损失函数和优化算法使模型自主学习隐含在图像数据内部的潜在关系,从而使模型具有更好的泛化能力,以至于自主预测出产品的缺陷。
基于深度学习的缺陷检测大致可分为三大类。分别为基于分类的方法,基于检测的方法及基于分割的方法等。文献[1]使用分类的方法,用一种多层的CNN网络对DAGM2007数据集中的六类缺陷样本进行分类。文献[2]基于GoogLeNet 网络的CNN 对LCD屏进行异常检测。文献[3]使用GoogLeNet网络迁移学习的方法进行热轧带钢表面质量检测。虽然基于分类的方法具有检测速度快等优点,但无法能够精确描述缺陷的具体信息。为了克服分类法的这种不足,许多研究者想到每次把样本图像分成多个区域,然后逐次选择某个小区域并判断在选定区域内是否存在缺陷。利用深度学习分类网络对样本图像的各个小区域进行分类训练,然后利用滑动窗口对整张图片进行预测,直到把缺陷区域分割出来文献[4]利用这种方法对混凝土裂缝进行检测。
但是这种方法同样无法完成像素级的缺陷检测,其检测精度很难得到保证。目标检测主要是找到图像中感兴趣的特征信息,并精确定位其位置。在缺陷检测中,文献[5]把Faster R−CNN用于土木建筑领域的混凝土、钢裂纹等的损伤检测。文献[6]结合SSD、YOLO等方法构建了一种从粗到细的级联检测网络,并应用到高铁线路紧固件缺陷检测。
然而,目标检测技术使用矩形框架来定位物体的缺陷,而缺陷的分布和表面形状不规则。因此,这种方法也无法能够描述缺陷的具体特征。有些学者为了提高检测精度,将缺陷检测任务作为一个语义分割任务来处理。其目的是对样本图像中的缺陷进行像素级的分类。
即,将缺陷区域和非缺陷区域分为两类,并产生像素级的检测结果,将会大大提高检测精度。文献[7]应用FCN进行检测混凝土裂缝,但是这种网络架构不适用于数据集较少的情况。然而在现实情况中产品缺陷的图片是较少的,且比较难获得的。因此,找到一种在训练集较少的情况下能够得到较高的检测精度和效率是非常关键。
在缺陷检测中许多产品表面是高纹理的,例如纺织品、大理石等,它们存在的高纹理对缺陷的识别带来了更大的挑战性,背景纹理和缺陷存在相似性,纹理和缺陷不容易区分。针对这种类型的缺陷,对不同高纹理背景下存在不同缺陷的数据集进行检测,会得到高纹理下缺陷检测更加通用的模型。
2 U−Net网络结构
U−Net网络,如图1所示。它是一种全卷积网络结构,可以对任意大小的图像进行快速精确分割,能够在很少的训练图像前提下产生更精确的分割。该网络首先由文献[8]提出,并应用于各种生物医学图像分割。在最近几年由于U−Net优异的性能也被用在其他领域的应用中。例如,用它从遥感图像中提取水体[9]、桥梁裂缝检测[10]、石块图像分割[11]等。由于缺陷数据集往往有采集比较困难、数据量比较小以及图片大小可能随时变化等特点,检测中采用基于U−Net的网络很好弥补这些缺点。

图1 原始的U−Net网络模型Fig.1 Original U−Net Network Model
由于缺陷检测更偏向于分析数字图像中的纹理信息,缺陷的语义信息比较弱。因此,底层的特征信息对于缺陷检测非常重要。然而在U−Net网络中经过大量卷积和池化后丢失掉诸多底层特征信息,这对于缺陷检测是非常不利的。
3 改进的U−Net网络结构
主要对原始的U−Net网络结构进行三处优化。在下采样阶段中,对每前一阶段获得的特征经过下采样融合到下一阶段中,使其在采样过程中能够充分利用底层信息,防止过多纹理细节的丢失。在上采样阶段,将每一阶段的特征进行转置卷积到跟输出层一样的大小,使它们融合到输出层中。在下采样的最后一层用空洞卷积来替代普通卷积,增加卷积核的感受野。
3.1 下采样阶段中的特征融合
在缺陷检测中,缺陷没有具体的形状,且语义信息较弱,在检测中应该更注重底层的纹理特征信息。在原始网络模型的下采样过程中,随着深度的增加会丢掉许多有用的底层特征信息。在下采样过程中采用特征融合策略可以有效保留更多有用的纹理信息,从而提高检测精度。
以U−Net 作为基础网络,对其网络结构中的上采样阶段stage1到stage4进行改进。在stage1到stage4中,每个阶段的第一层和第二层为卷积层,第三层为最大池化层。将输入特征图和第一阶段的中间层进行融合,在stage1到tage4中下一阶段的中间层依次融合上一阶段的最后一层。让每一阶段都能够充分融合到上一阶段的特征,让底层特征尽可能保留更多的细节信息。在U−Net网络结构中上采样都融合了对称的下采样的信息。即,在下采样和上采样过程中都进行了丰富的纹理特征信息。改进的网络,如图2所示。

图2 改进的U−Net网络模型Fig.2 Improved U−Net Network Model
3.2 上采样阶段的多尺度融合
在缺陷检测中缺陷大小是未知的,形状也是不规则的。为了能够对缺陷进行精确的检测,在上采样阶段采用多尺度融合的策略,将局部细节信息和整体轮廓信息结合,使其更好地适用于缺陷较大或较小时的检测精度。
对U−Net网络结构中的上采样阶段stage6到stage9进行如下改进。在上采样中每个阶段的第一层为反置卷积层,第二层和第三层为卷积层。把stage6到stage8的最后一层进行转置卷积,转置卷积到与stage9 第一层同样的大小,并把它们直接拼接到stage9的第一层。这样在stage9中融合了多尺度特征,可以有效地提高检测的精度。
3.3 增加空洞卷积
通过计算在下采样阶段最高层的感受野为(140*140)。针对最高层的边缘特征感受野不够大,要提高特征的感受野,利用空洞卷积提高感受野,并且不会带来额外的计算量。
在原始U−Net网络中stage5两层都为卷积核大小为(3*3)步幅为1的卷积层。在stage5中使用空洞卷积来代替卷积层,增加卷积核的感受野,两个空洞卷积的膨胀系数分别取1和4。用普通卷积stage5输出的感受野为(140*140),换成空洞卷积后感受野变为(268*268),远大于普通卷积的感受野。可以增加对图像中边缘缺陷检测的准确度。
4 数据集介绍
在DAGM(The German Association for Pattern Recognition)和GNNS(German Chapter of the European Neural Network Society)联合举办的“工业光学检测的弱监督学习”竞赛提出的基准数据集DAGM[12]上进行大量的实验,评估所提出方法的有效性。
DAGM数据集包含大小为(512×512)像素的6个类的图像样本,如图3所示。在图中缺陷用红色椭圆标出,它由常见的不同的高纹理类和不同的缺陷类型组成。在图3(a)中代表了高纹理下的模糊类缺陷,图3(b)和图3(e)代表了高纹理下划痕缺陷,图3(c)代表了高纹理下坏点缺陷,图3(e)代表了高纹理下擦伤缺陷,图3(f)代表了高纹理下裂纹缺陷。每一类由1000个无缺陷图像和150个缺陷图像组成。此数据集为弱标记数据集,分割标签不是以像素级给出的,而是以椭圆圈出缺陷区域。由于在实际标注中,像素级的标注代价成本特别高,弱标记可以节省大量成本,对标注要求低,更符合现实情况。
此数据集具有很高的挑战性。它的部分样例,如图3所示。在图3(a)中,背景中有和缺陷相似的均匀纹理信息;在图3(d)和(f)中背景纹理信息干扰特别大,其具有和缺陷类似的高频纹理信息;在图3(c)中背景纹理信息和缺陷具有很大相似性;在图3(b)和图3(e)中背景噪声很大,使得缺陷区域和非缺陷区域区别不明显,对缺陷监测造成较大的干扰。

图3 DAGM数据集中的部分样例展示Fig.3 Some Examples of DAGM Dataset
5 实验与评估
在实验中,每一类随机选择575张图片作为训练集,剩下的575 张图片作为测试集。在训练集中采用5 折交叉验证,总共3450幅图像被随机分成5组,编号从0到4。每次选择4组作为训练集,其余一组作为验证集。每类每次有2760张训练图像和690张验证图像。
采用Adam算法对模型进行优化。Adam算法是一种对随机目标函数执行一阶梯度优化的算法[13],其学习率在训练过程中会发生改变。Adam 可以通过计算梯度的一阶矩估计和二阶矩估计,为不同的参数设计独立的自适应性学习率。这就可以加快前期训练的速度,而不影响后期训练的收敛性。算法的初始学习率η=0.0001,一阶矩估计的指数衰减率β1=0.9,二阶矩估计的指数衰减率β2=0.999。每次随机选择2张样本图像作为一个小批量进行训练。
在U−Net进行分割中的评价指标为Dice系数,其计算公式如式所示:
式中:mask—真实标注;prediction—预测结果;Dice—描述图像分割算法的结果与其相应的真实缺陷标注的相似程度;用Dice损失函数训练可以更直观地达到更高的Dice值;Dice损失函数如式所示:
在进行训练时发现,Dice损失无法在初始训练时提供有意义的梯度。这会导致模型的不稳定性,而这种不稳定性往往会促使模型难以训练。用Dice损失函数训练过程中训练损失和验证损失,如图4所示。
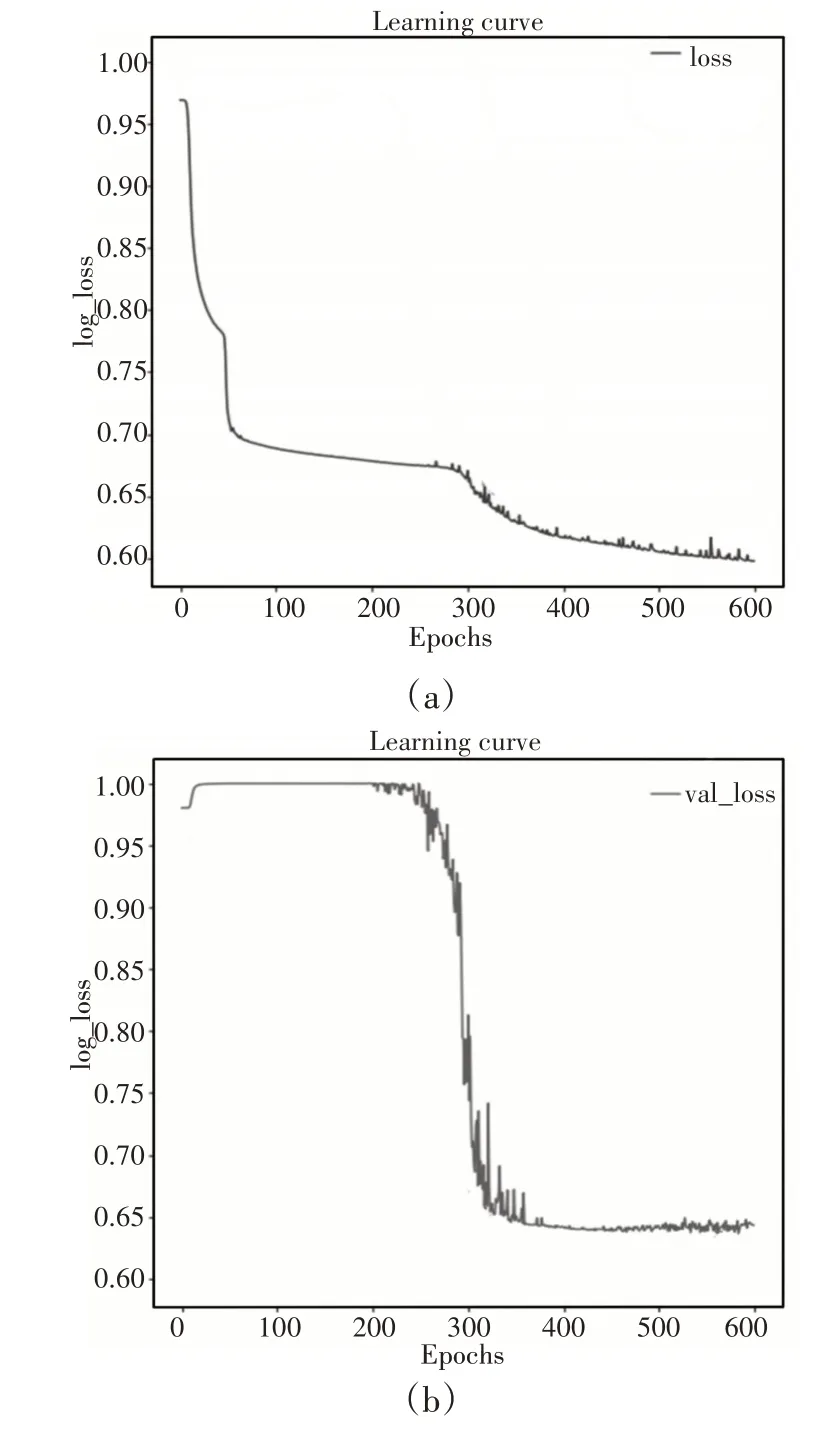
图4 Dice损失函数下训练和验证损失Fig.4 Training And Verifying Loss with Dice Loss Function
由于交叉熵损失函数在开始训练中收敛速度快,算法也引入了交叉熵损失函数,其数计算公式如式所示:
采用交叉熵损失函数和Dice损失函数的联合形式训练的训练损失和验证损失,如图5所示。
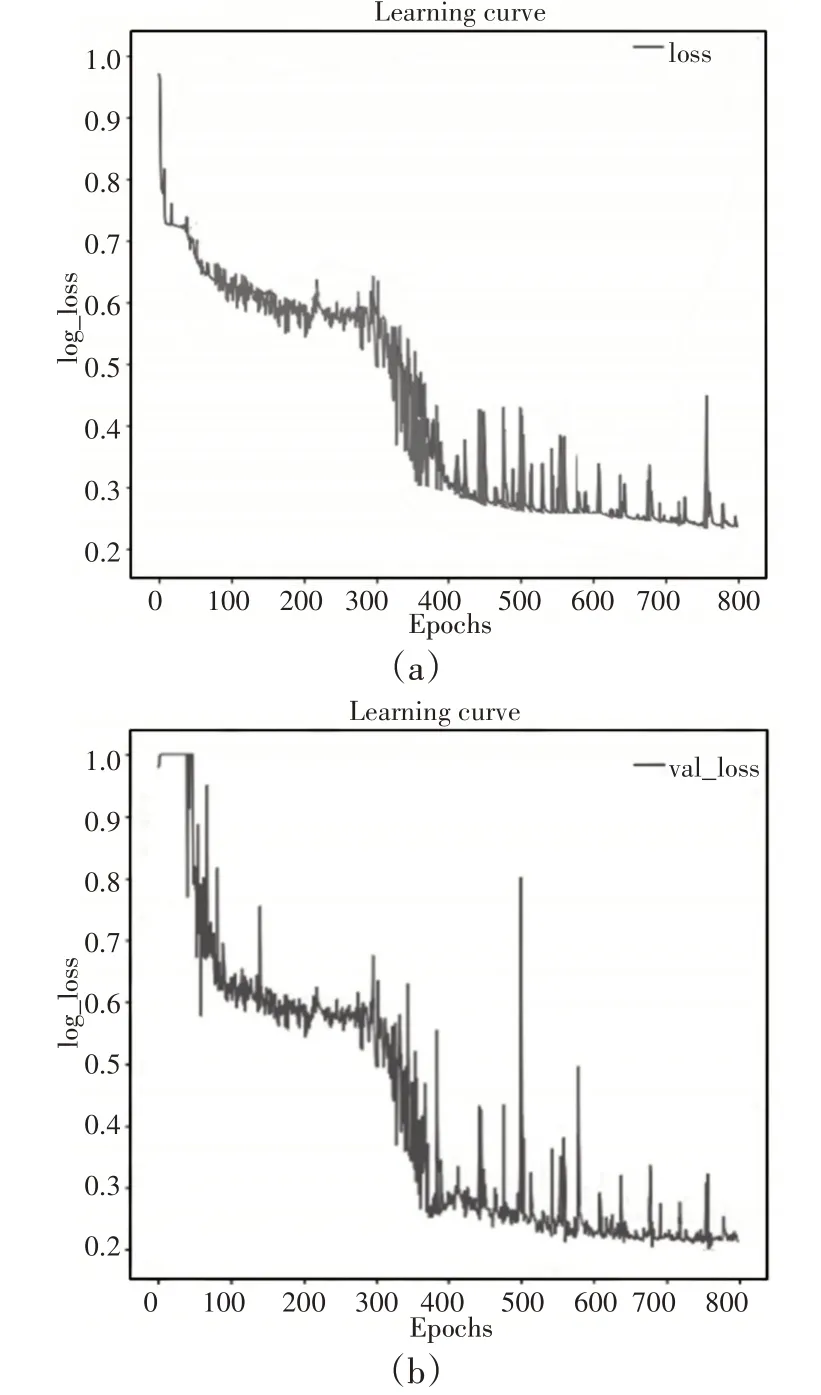
图5 联合损失函数下训练和验证损失Fig.5 Training and Verifying Loss with Joint Loss Function
6 结果
缺陷检测算法实验采用Python3.7.3开发,其深度学习框架采用TensorFlow[14]。实验设备为一台CPU 为Intel Xeon E5−2650L v3、显卡为NVIDIA GTX−970上进行。所改进的网络结构同文献[3]中基于滑动窗口的CNN方法、SegNet方法、U−Net方法进行比较。基于滑动窗口的CNN 方法是把原始图像(512*512)分割成(32*32)像素后做分类训练。一个图像分成256个小块,预测时在原图上滑动窗口进行预测。通过实验发现,滑动步长越小,预测精度越高,但是预测用时越长。当所设的步长为1、4、8、16、32时,所用的时间分别为351ms、23ms、16ms、8ms、2ms等。考虑到预测的实时性,预测时设定滑动窗口大小为32,滑动步长为8,对原图进行预测。对改进的U−Net方法和原始U−Net方法、SegNet方法以及基于滑块窗口的CNN方法进行比较。检测结果图,如图6所示。在图中可以看出改进的网络具有比较好的检测效果。

图6 各算法缺陷检测结果对比Fig.6 Comparison of Defect Detection Results of Each Algorithm
对测试集上的图片进行预测时,由于基于滑动窗口CNN的方法在检测中不能提供像素级的缺陷检测,当预测时滑动窗口具有比较明显的滑动痕迹。当把滑动步长减少时,虽然滑动窗口痕迹变弱,精度变高,但是检测时间变长,达不到实时性要求。只列出它在预测中滑动窗口步长为8时的预测图片,不再用它与其它检测方法进行参数比较。对于其它检测方法分别用Dice系数值和Accuracy值来进行评估。得到它们的平均Dice系数值、最大Dice值以及Accuracy值,如表1所示。
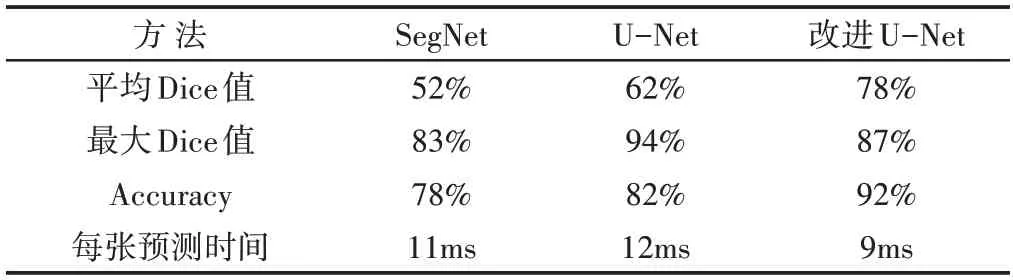
表1 各算法缺陷检测参数值对比Tab.1 Comparison of Defect Detection Parameters of Each Algorithm
对于Accuracy设定,当有缺陷时预测的Dice<0.5或把无缺陷预测成有缺陷时,假设为预测失败。当有缺陷时预测的Dice>0.5或预测正确无缺陷类型时,认为预测成功。其Accuracy评价指标用如下公式确定:
式中:TP—预测成功的数量;FP—预测失败的数量;Dice系数公式如式(1)所示。
7 结论
在DAGM缺陷数据集上验证了改进的U−Net算法,并与原始U−Net算法、SegNet算法以及文献[3]中基于滑动窗口的CNN网络进行对比。实验结果表明,改进的U−Net方法平均Dice系数值以及Accuracy值都高于其它检测方法,具有更高的分割精度和检测效率。特别是对第四类缺陷进行检测时,其余方法存在检测不到或错检的现象,而改进的U−Net 网络可以有效地检测出缺陷。这就说明该算法有较强的通用性,对不同高纹理图案的适应性强。在同等条件下的缺陷检测中,能够体现出更高的检测精度和的更好稳定性。
