基于八度卷积神经网络的多标签胸部X光图像分类算法
2023-03-15刘开华
刘开华,田 岚,李 锵,关 欣
(天津大学微电子学院,天津 300072)
胸部疾病严重威胁着人类的生命健康安全,其中肺炎、肺结节是癌症转变率最高的疾病种类,转变率高达 20%[1].胸部 X光图像是目前较为常见的诊断胸部疾病方式之一,具有成本低、方便快捷的优势.医生通过 X光图像识别病灶,判断疾病种类,可以尽早确诊疾病,使患者能够在发病初期获得治疗,有效提高治疗成功率.但由于放射科医生经验和主观方面的差异,识别结果可能出现一定程度的误差,因此亟需开发一套计算机辅助诊断系统[2],帮助医生进行病灶判断,从而降低误诊率.
基于深度学习的计算机辅助诊断系统,例如肺炎检测[3]、肺结节分类[4]、脑肿瘤分割[5]等已取得较好的效果.自 ChestX-Ray14数据集发布以来,国内外学者提出了大量胸部疾病自动分类的方法.方法大致分为两类.一类是传统机器学习分类方法.Agrawal等[6]提出一种神经网络高斯过程模型,在贝叶斯神经网络基础上将宽度无限增大,5层深度的网络模型优于其他非卷积模型,进一步缩小了非卷积模型与卷积模型之间的差距.另一类是深度学习分类方法.Xu等[7]提出 DeepCXray网络,训练 InceptionV3模型提取特征,并且使用交叉熵损失作为目标函数,获得了优秀的分类效果.Gozes等[8]将在 ChestX-Ray14数据集上预训练的模型用于小数据集结核病的检测获得了优异的分类结果,说明大型数据集预训练学习到的特征有助于提升小数据集上的分类结果.Wang等[9]将预训练的全卷积作为特征提取器,通过训练全连接分类层,评估了 4种经典 CNN模型,得出ResNet性能最优的结论,然而传统 ResNet仅对全连接层进行微调,忽略了网络其他层特征提供的信息,尤其是针对医学图像,特征提取部分有待进一步优化;Yao等[10]采用长短期记忆(long- short-term memory,LSTM)网络作为解码器学习病理标签之间的依赖关系,该方法通过重新整理多标签之间的关系进一步提高了分类的准确率,但是没有考虑样本不平衡、多标签问题,造成模型倾向于学习样本量大的疾病特征,从而导致预测精度较低.Rajpurkar等[11]提出用肺炎数据训练 121层 DenseNet卷积神经网络,然后模型微调用于其他 13种胸部疾病的检测,该方法使用121层DenseNet网络,参数量和计算复杂度较大.
针对上述问题,为了进一步提高胸部 X光图像分类算法的性能,本文提出一种基于八度卷积[12]的残差神经网络(octave convolution based residual network,OC-ResNet),OC-ResNet主要有 3方面的改进:①在 ResNet[13]网络架构中利用八度卷积改进普通卷积,分离出图像中的高低频信息特征,降低低频特征比例,增加高频信息权,在提升对胸部病灶特征表达能力的同时,降低了计算复杂度;②采用渐进式微调的迁移学习方法[14],在 ImageNet数据集上预训练提取图像一般性公共特征,获得初始网络参数,然后固定网络浅层参数,在 ChestX-Ray14数据集上微调网络深层参数,获得最优的迁移学习效果;③采用焦点损失(focal-loss)函数[15],减小样本数量多的疾病类别权重,从而解决样本不平衡问题.
1 OC-ResNet网络
1.1 OC-ResNet网络结构
本节介绍以ResNet为基础,将ResNet网络中的普通卷积替换成八度卷积,构成的 OC-ResNet胸部X光图像分类网络,如图1所示.ChestX-Ray14数据集的样本数量虽有11万,但是相较ImageNet数据集有千万级的数据量,医学图像数据量依然较少,仍然存在泛化性差、易过拟合等问题.因此加入迁移学习解决在小样本数量目标域上的训练困难.第 1阶段预训练,在 ImageNet数据集上训练 OC-ResNet,预训练模型的最后一层是 ImageNet数据集对应的1000个类别的输出向量.第 2阶段迁移学习,保留除全连接层之外的所有层级参数,迁移至 ChestXRay14数据集上进行微调训练.由于网络浅层通常提取到的是边缘、颜色等基础信息,网络深层提取到的则是物体个性特征等语义信息.因此在迁移学习过程中采用渐进式微调策略,即网络浅层参数固定不变,深层参数进行微调,此时迁移学习效果最优[14].X光图像通过预训练模型的输入层,依次经过残差单元中的八度卷积层、池化层、正则化层,最后通过全连接层,将结果输出为1×14的向量.
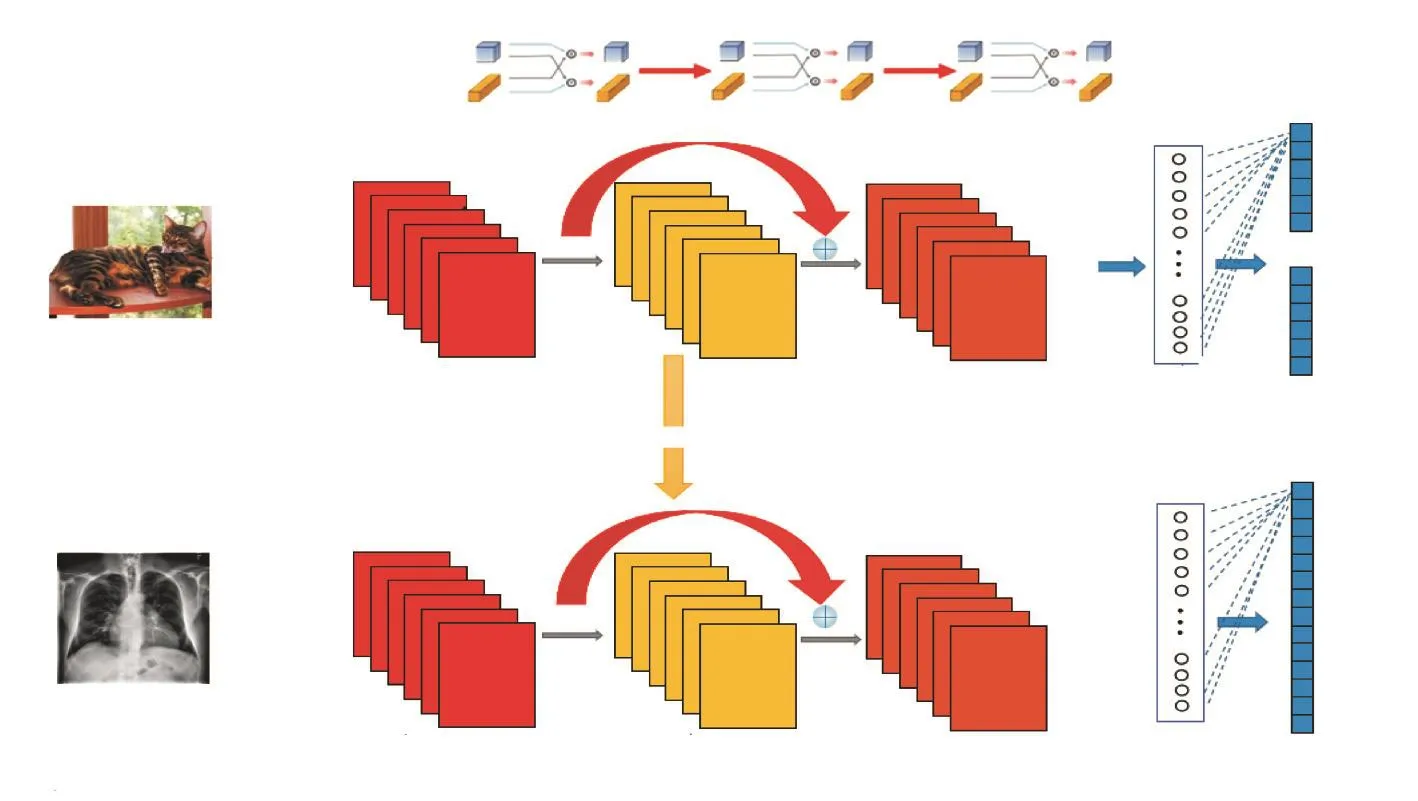
图1 OC-ResNet网络结构Fig.1 OC-ResNet network structure
为解决深层网络的过拟合和梯度消失问题,本文采用 ResNet网络结构,该网络由残差单元模块组成.本文将残差单元模块改进为八度卷积残差单元,其模块结构如图2所示.
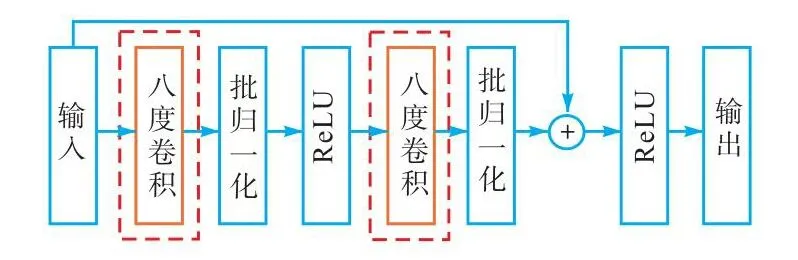
图2 八度卷积残差单元结构Fig.2 Octave convolution residual unit structure
一个八度卷积残差单元由2层八度卷积层组成,在八度卷积的每一层后面都使用 ReLU激活函数和批归一化来代替实例正则化.
1.2 八度卷积模块结构
随着网络层数逐渐加深,导致网络内存消耗和计算成本不断增加,为了缓解该问题,本文采用八度卷积改进普通卷积,通过八度卷积存储和处理空间分辨率较低且空间变化较慢的特征图,可以有效降低内存和计算成本,同时有效提取图像中的高频特征信息,有利于图像的识别分类.
八度是指八音阶,在音乐中降低八音阶代表频率减半.八度卷积[8]将“八度”的概念应用到卷积神经网络中,其核心思想是对图像数据中低频信息减半,从而达到加速卷积运算和降低内存与计算成本的目的.
Xu等[16]将八度卷积用在胶囊网络中进行高光谱图像分类获得优异的分类结果.Wang等[17]在 3维CT肝脏肿瘤分割中使用八度卷积神经网络,通过学习多空间频率特征,完成端到端的学习和推理.文献[16-17]已证明八度卷积在其他任务中的有效性.
在普通卷积神经网络中,设W 是k×k大小的卷积核,X ,Y ∈ Rc×h×w分别表示输入和输出张量,(p,q)为进行卷积运算的位置坐标,则卷积运算可表示为
八度卷积实现的目标是有效地处理相应频率张量中的低频和高频分量,同时使八度特征表示的高频分量和低频分量之间能够有效地通信.八度卷积实现过程如图3所示.八度卷积核大小为k×k,权重W ∈ Rcin×cout×k×k,与普通卷积核有相同的参数,八度卷积核示意如图4所示.4个卷积核分别参与到4条卷积路径中,WH→H表示高频之间的卷积核,WH→L表示高频到低频之间的卷积核,WL→H表示低频到高频之间的卷积核,WL→L表示低频之间的卷积核.
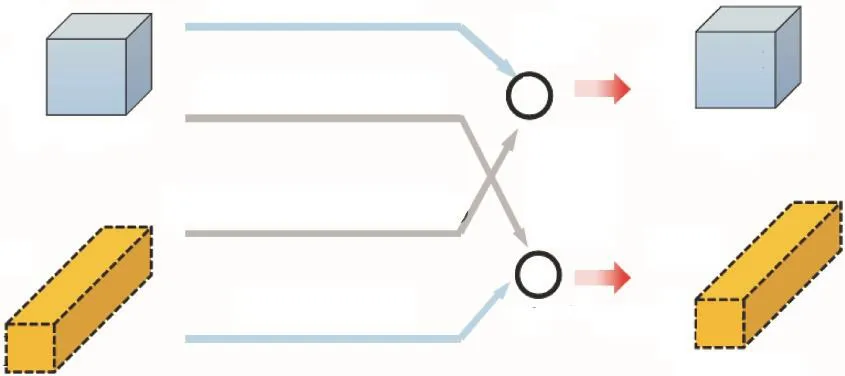
图3 八度卷积运算过程Fig.3 Octave convolution operation procedure
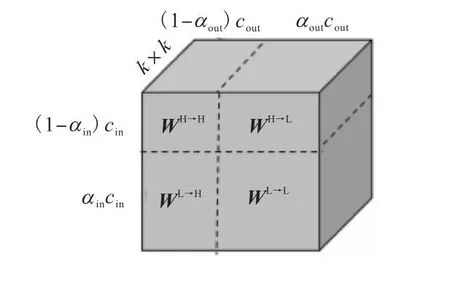
图4 八度卷积核示意Fig.4 Schematic of octave convolution kernel
在卷积层中,输入张量和输出张量都被分成高频和低频两部分,其中高频部分表示为低频部分表示为.为了实现高低频特征之间的有效通信,需要将在低频分量上采样的信息通过 WL→H更新到高频分量上,同时,将在高频分量上的采样信息通过 WH→L更新到低频分量上.于是输出特 征 表 示 为 YH= YH→H+YL→H和YL= YL→L+YH→L.它由4条计算路径组成,如图3所示,两条蓝色路径对应于高频和低频特征图的信息更新,两条灰色路径便于两个八度之间的信息交换.实现方式如下.
式中: f(X ;W ) 表示输入特征与参数之间的卷积;upsample(X ,k)是通过最近差值进行k倍的上采样操作;p o ol(X ,k)表示池化操作,池的核大小为k,步长为k.
八度卷积的具体网络结构与卷积网络参数定义如图5所示,假设低频通道占比为α,则高频通道占比为 1-α.高频输入和低频输入的尺寸分别是 224×224×3×(1-α)和 112×112×3×α.高频输入分别进行两次运算:一个是经过 16×(1-α)个尺寸为 3×3×3的卷积核进行卷积运算得到尺寸为224×224×16×(1-α)的特征图;另一个是经过步长为 2、核尺寸为 2的池化之后,再与 16×α个尺寸为 3×3×3卷积核进行卷积运算得到尺寸为 112×112×16×α的特征图.低频输入也分别进行两次运算:一个是经过 16×(1-α)个尺寸为 3×3×3的卷积核进行卷积运算得到尺寸为 112×112×16×(1-α)的特征图,再通过步长为 2、核尺寸为 2的上采样得到 224×224×16×(1-α)的特征图;另一个是经过 16×α个尺寸为 3×3×3卷积核进行卷积运算得到尺寸为112×112×16×α的特征图.尺寸相同的特征图进行相加,得到最终尺寸为 224×224×16×(1-α)的高频输出和尺寸为112×112×16×α的低频输出.
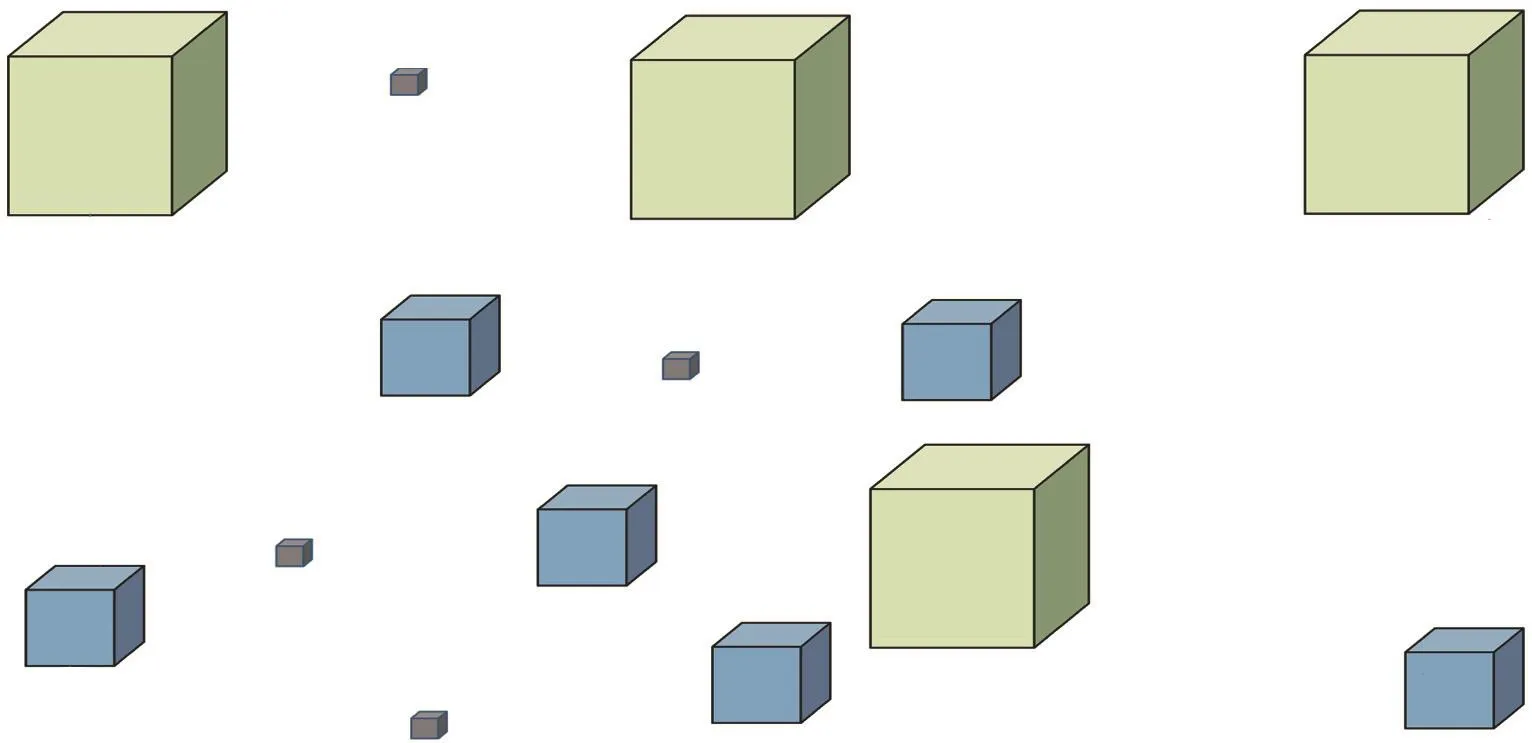
图5 八度卷积网络结构与参数设置Fig.5 Octave convolution network structure and parameter setting
1.3 渐进式微调迁移学习
微调深度对迁移学习的效果有很大影响,文献[18]通过实验发现不同数据集在同一个网络上以不同微调深度进行训练时,随着微调深度的增加准确率会先增大,达到峰值后准确率开始下降.这说明当从最小的深度开始对比,如果后一个较大深度的准确率低于前一个深度,那么前一个深度为最佳微调深度,而且准确率不会随着微调深度变化出现波动,很适合迭代方法去寻找最优解.据此提出渐进式微调深度的迁移学习方法,算法步骤描述如下.
步骤1输入以下数据:
(1) 在大规模数据集上训练的模型权重W(0);
(2) 训练数据x和真实标签y;
(3) 学习率η;
(4) 网络深度depth;
(5)微调深度不一样的网络结构文件NET=[net1, net2, … ,n etdepth],其中net1微调深度最小,n e tdepth微调深度最大;
(6) 每C次迭代进行一次竞争;
(7) 最大迭代次数MAX.
步骤2最佳模型Wbest,最佳微调深度Dbest.
该方法能够较快确定微调深度,减少训练开销,提升迁移学习后网络的准确率.在训练过程中,微调深度不断增大,从深层特征向浅层特征逼近,先让较深层的参数达到最优,损失函数降到一定程度后,再加入一些较浅层的网络,进一步降低损失函数.然而损失函数不是越低越好,过低会导致训练过拟合,这种逐层微调的训练方式能够让损失函数在一定范围内逐步下降,所以需要根据测试集的反馈决定微调深度是否继续加深.
1.4 焦点损失函数
在 ChestX-Ray14数据集的多标签类别中,本文为每张 X光图像定义了一个 14维标签向量y=[y1, y2, … ,y14],每个维度代表一种疾病,yc(c=1,2,…,14)表示是否存在相应的疾病,值为 1表示患有该疾病,值为0表示未患该疾病.
之前的研究中很多都选择二分类交叉熵作为损失函数,公式为
式中:c为病变类别;yc为真实标签;为预测标签.但在 ChestX-Ray14数据集中,疾病样本的数量严重不平衡,较少的疾病拥有大量的样本数据,导致训练不充分,为了解决这个问题,本文采用焦点损失函数[15],如式(4)所示,在交叉熵的基础上增加权重因子γ(γ> 0 )和平衡因子σ,以使网络更加关注难分类的样本,平衡正负样本比例.根据实验对比分析[15],当σ=0.5、γ=2时,网络的分类效果最佳.
2 实验设置与评价指标
2.1 实验环境与参数设置
本文使用的服务器为CPU Intel® Core i7-6800K 3.5GHz,GPU Nvidia GTX1080Ti(11GB)×2,操作系统为 Ubuntu 16.04,采用 Pytorch[19]开源深度学习框架.
实验过程中,首先搭建基于 Pytorch框架的网络,将全连接层的参数随机初始化,并使用 Adam 优化器[20]进行优化.训练过程中将学习率设置为1×10-3,衰减率设为 0.9,激活函数使用 ReLU[21],分类函数使用 Softmax.为了充分发挥实验设备作用,将批尺寸(batch size)设置为128,训练轮数为150次.
2.2 评价指标
在计算机辅助诊断中,为了选择客观公正的指标对比算法的性能,业界通常采用受试者特征(receiver operating characteristic,ROC)曲线来表现算法的识别能力.ROC的计算和混淆矩阵相关,混淆矩阵如表1所示.
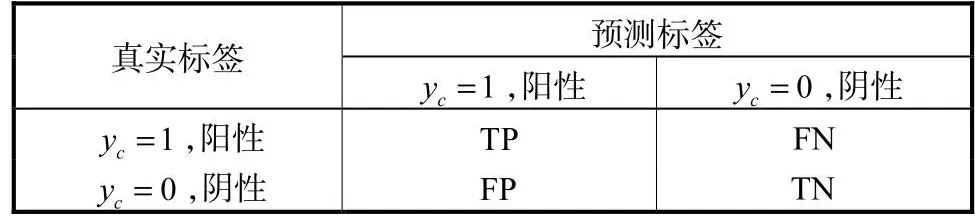
表1 混淆矩阵Tab.1 Confusion matrix
表2中TP表示真正例,意为预测为阳性,实际也是阳性的样本数;FP表示假正例,意为预测是阳性,实际是阴性的样本数;FN表示假反例,意为预测是阴性,实际是阳性的样本数;TN表示真反例,意为预测是阴性,实际也是阴性的样本数.
ROC曲线的横轴表示假阳率(false positive rate,FPR),意为在所有阴性样本中,预测为阳性的比例;纵轴表示真阳率(true positive rate,TPR),意为在所有阳性样本中,预测为阳性的比例;FPR和TPR的计算公式如下.
ROC曲线下的面积(area under the curve of ROC,AUC)用于比较分类模型的性能,最初使用是在文献[9]中,现在广泛应用在医学图像分类算法评估中.ROC曲线越接近1,AUC值越大,说明算法性能越好,分类效果越好.
分类模型的准确率(A)即为在所有样本中,预测正确的数量占总样本数量的比重,准确率可以判断总体的正确率.准确率公式表示为
分类模型的精确率(P)即为预测为正样本占全部预测为正样本的比重,含义是对正样本结果中的预测准确程度,精确率的提出是为了让预测结果尽可能不出错.精确率公式表示为
分类模型的召回率(R)即为预测为正的样本数量占所有实际为正的样本数量的比重,含义是在实际为正的样本中被预测为正样本的概率,召回率公式表示为
精确率和召回率互相影响,理想状态下会追求两者都高,但实际上两者互相制约,如果追求精确率高,则召回率低,如果追求召回率高,则精确率会低.基于上述情况,需要综合考虑,最好的方法是 F1值(F1-Score),F1值是精确率和召回率的调和平均,F1值越大说明模型质量更高,F1值公式表示为
2.3 数据预处理
实验使用的数据集为美国国立卫生研究院(NIH)于 2017年发布的 ChestX-Ray14公共胸部 X射线数据集,该数据集包含 30805例患者的 112120张正面 X光图像,图像大小为 1024×1024.每张图像都被标记为一种或多种常见的胸部疾病标签,例如肺炎、心脏肿大、积液、浸润等,比较特殊的是,该数据集的标签是由自然语言处理识别放射学报告生成,并不是由专家直接标注,自然语言处理标注的准确率大于90%.数据集中疾病种类分布情况如图6所示,可以明显看出样本分布极其不均衡,疝气、肺炎等样本数量较少,浸润、积液等疾病样本数量较多,这种情况导致分类模型训练的难度加大.
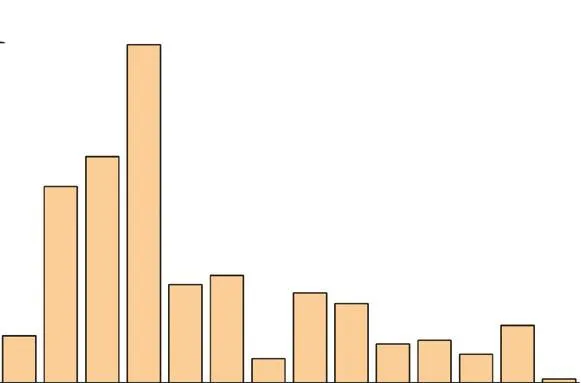
图6 ChestX-Ray14数据集疾病种类比例Fig.6 Proportion of disease types in the ChestX-Ray14 dataset
多数研究通过随机分割数据集进行训练、验证和测试对比,但是这种方案在 ChestX-Ray14数据集中存在问题.由于同一名患者平均拥有 3.6张 X光图像,可能会同时存在于训练集和测试集中.因此本文根据公开的官方数据分割标准,采用7∶1∶2的比例将数据集分割成训练集、验证集和测试集,确保同一患者的图像在 3个数据集中无任何交叉.数据集划分好后,训练前将图像转化为灰度图像,在灰度图像基础上进行自适应直方图均衡化[22],提高胸部 X 光图像的对比度.然后随机裁剪为 224×224像素的图像,并通过随机翻转、旋转进行数据增强.预处理前后的图像对比如图7所示.
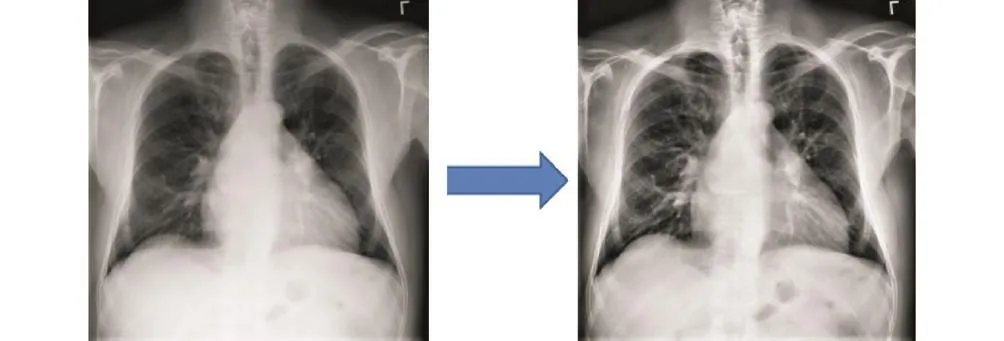
图7 原始X光图像与处理后的X光图像Fig.7 Original and processed X-ray images
3 实验结果分析
在八度卷积过程中,参数α表示分配给低频通道的比率,当α=0时,表示不使用低频特征,即普通卷积.由于变量α∈ [ 0,1],在 ResNet_50网络中将α分别取值为 0、0.25、0.50、0.75、1.00 进行实验,将其所对应的网络参数量、计算复杂度(floating point operations,FLOPs)、平均 AUC(average-AUC)值进行统计比较.选择ResNet_50作为基础网络的原因是该网络层数相对较小,训练时间较短,可以低成本获得参数α对于基础网络的影响效果数据.实验结果如表2所示.
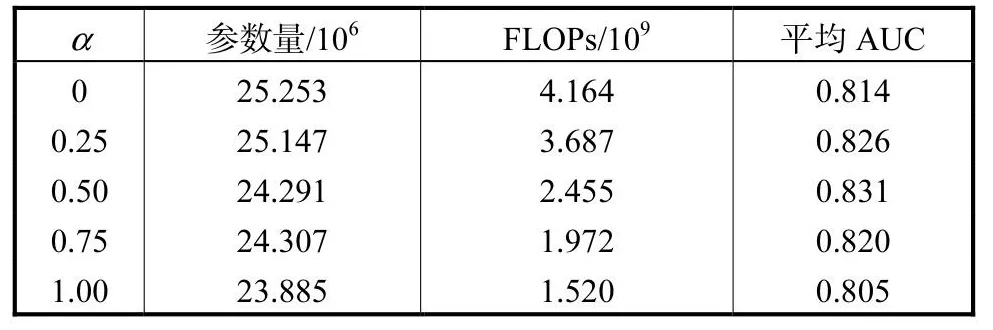
表2 ResNet_50中网络参数量、计算复杂度、平均AUC值与α 的对应关系Tab.2 Correspondence among the network parameters,FLOPs, average AUC values and α with Res-Net_50
3.1 有效性分析
由表2数据可知,随着α的增加,参数量和计算复杂度逐渐降低,当α从0增加到0.25时,FLOPs减少 0.477×109,降低 11.46%,参数量减少 0.106×106.当α增加到 0.50时,FLOPs减少了 1.709×109,降低41.04%,参数量减少了 0.962×106.说明低频特征通道的比例增加,确实能够减少网络的计算复杂度和网络参数量.并且 AUC值随着α的增大先增大后减小,当α=0.50时,达到峰值 0.831,比基础网络的AUC值提高 0.017,说明当α=0.50时训练结果最优.表2数据说明八度卷积模块的加入,能够有效提取高频信息,适当弱化低频信息,对模型的准确率提升有较大作用.
3.2 消融实验
本文对不同层数的 ResNet进行了实验对比,分别选择了50层、101层和152层作为基础网络.然后分别对零基础训练 ResNet网络、经过迁移学习的ResNet网络、零基础训练嵌入八度卷积的 ResNet网络以及经过迁移学习的嵌入八度卷积的ResNet网络进行消融实验.由表2数据分析结论将八度卷积的参数α取值为 0.50.将各自训练模型的参数量、计算复杂度和平均AUC值进行对比,数据如表3所示.
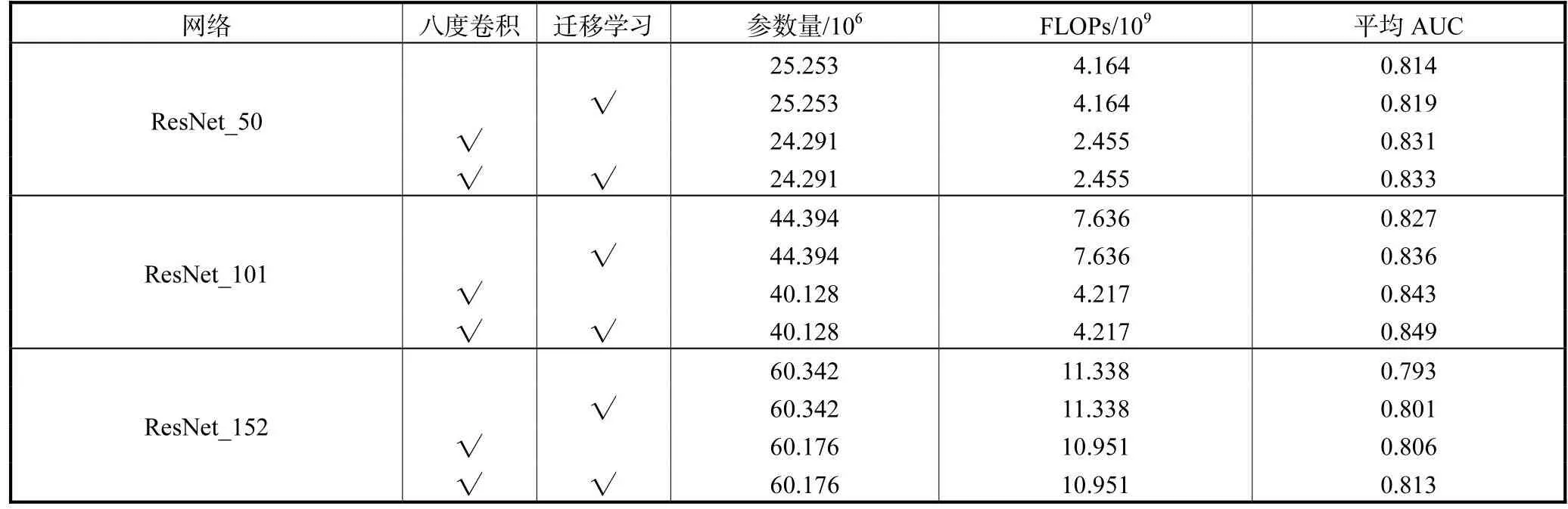
表3 消融实验结果Tab.3 Results of ablation experiments
根据表3数据可知,经过迁移学习的ResNet_50的 AUC值相比基础网络提高 0.005,经过迁移学习的ResNet_101的AUC值相比基础网络提高0.009,经过迁移学习的ResNet_152的AUC值相比基础网络提高 0.008,说明迁移学习后的模型对网络性能有提高作用.3种不同层数的 ResNet网络嵌入八度卷积后,参数量和计算复杂度均有不同程度的下降,平均AUC值均有提升.嵌入八度卷积的ResNet_50相比基础网络 FLOPs下降 41.04%,平均 AUC值提高0.017;嵌入八度卷积的 ResNet_101相比基础网络FLOPs下降 44.77%,平均 AUC值提高 0.016;但是嵌入八度卷积的 ResNet_152相比基础网络 FLOPs只下降3.41%,平均AUC值提高 0.013,可能是因为八度卷积在减少网络计算复杂度方面,对于较深层数的网络降低幅度有限制.这些网络参数量的下降幅度在 ResNet_101网络表现较为明显,减少 9.6%.嵌入八度卷积的 ResNet网络经过迁移学习后,平均AUC 值也均有提升,ResNet_50、ResNet_101、ResNet_152分别提升0.002、0.006、0.007.其中 AUC值最佳的是 ResNet_101网络,嵌入八度卷积且经过迁移学习的ResNet_101平均AUC值达到了0.849.
在表4中表现最优的模型经过迁移学习并嵌入八度卷积的 ResNet_101,把交叉熵函数换为焦点损失函数,得到的平均AUC值为0.856,相比交叉熵损失函数平均 AUC值提高 0.007,交叉熵损失函数与焦点损失函数的实验结果数据如表4所示.肺炎疾病数据量仅为 1431张,数量相对其他疾病较少,焦点损失函数相比交叉熵损失函数,肺炎的 AUC值提高 0.016,说明焦点损失函数对于样本较少类别的准确率提升有帮助.
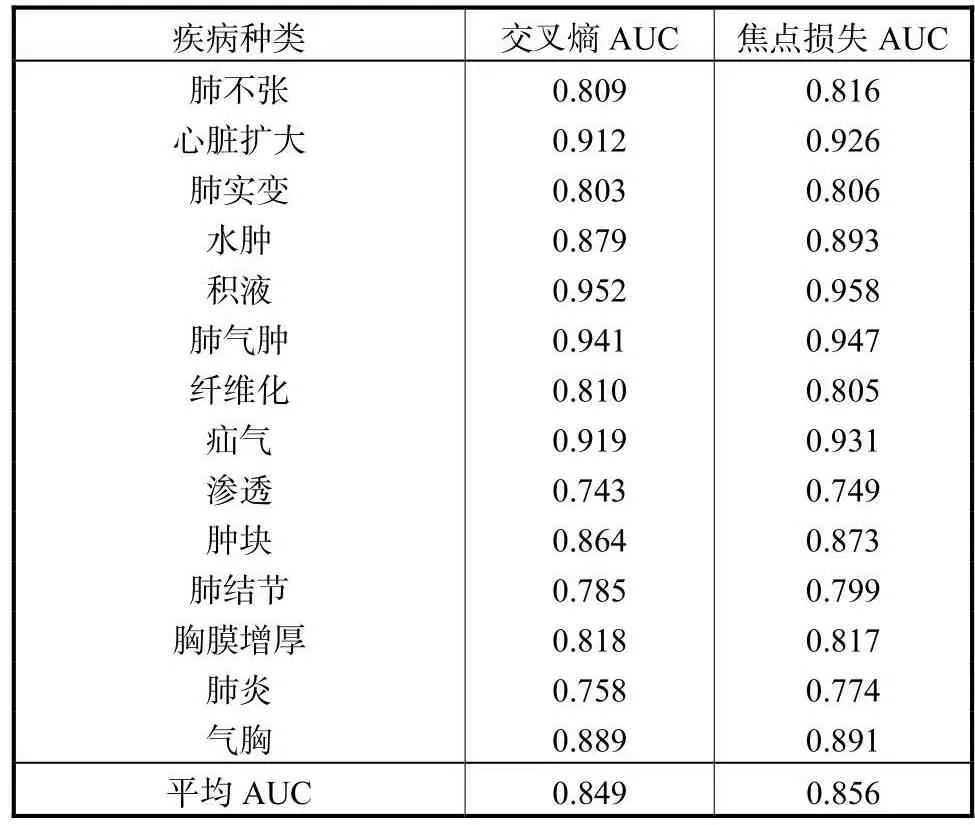
表4 交叉熵损失函数和焦点损失函数AUC值对比Tab.4 Comparison of the AUC values of cross-entropyloss function and focus-loss function
3.3 实验结果对比
经过表3数据分析发现性能最优的算法组合是嵌入八度卷积和经过迁移学习的 ResNet_101,在此基础上将交叉熵损失函数换为焦点损失函数,得到的平均AUC值为0.856.在ChestX-Ray14数据集上14种胸部疾病分类结果ROC曲线如图8所示.
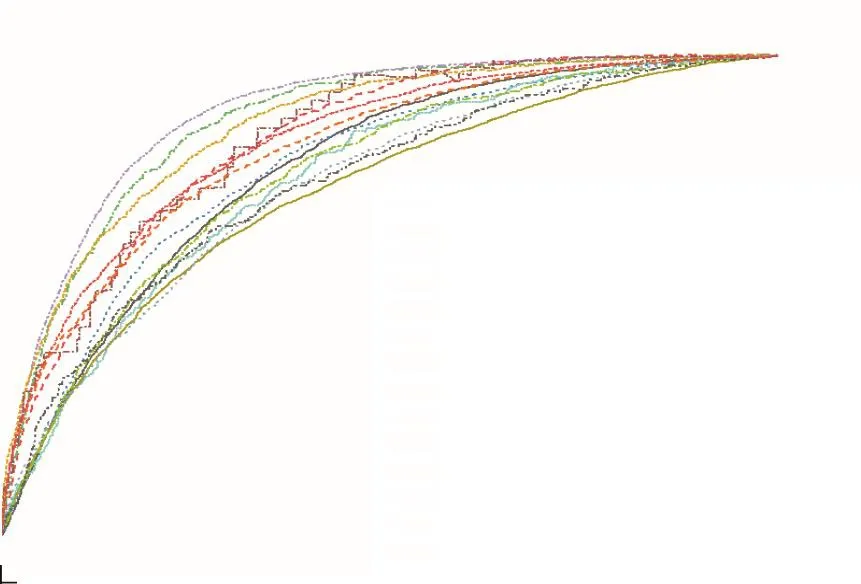
图8 ChestX-Ray14数据集14种疾病分类ROC曲线Fig.8 ROC curves for classification of 14 diseases in the ChestX-Ray14 dataset
在相同条件下得到的 OC-ResNet在 ChestXRay14数据集上的准确率和F1值如表5所示.平均准确率为0.791,平均F1值为0.481.准确率和F1值作为AUC值的补充指标,进一步说明OC-ResNet算法的分类性能优异.
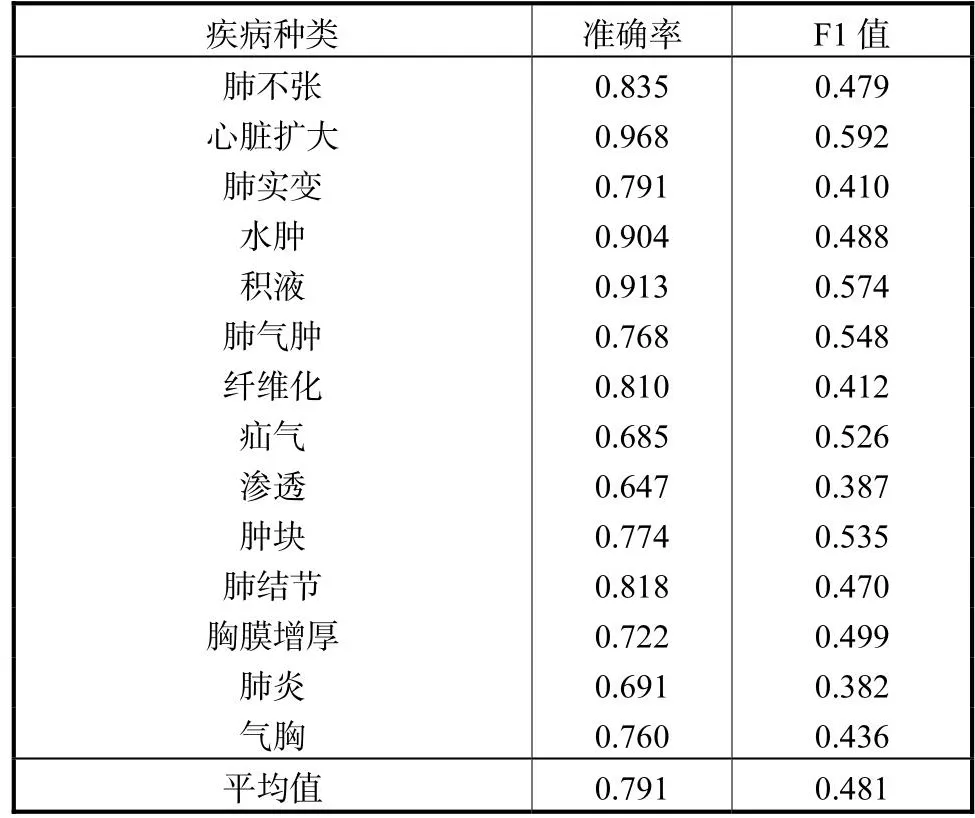
表5 OC-ResNet准确率和F1值Tab.5 OC-ResNet accuracy and F1 score
将此方法与当前最先进的方法进行比较,分别与Yao 等[10]、Ma 等[23]、Rajpurkar 等[11]、张智睿等[24]提出的方法进行了对比实验.将 ChestX-Ray14数据集分为训练集(70%)、验证集(10%)和测试集(20%),遵循和他们相同比例的数据集划分方式,表6是用不同方法对14种胸部疾病进行分类的AUC值比较的结果.
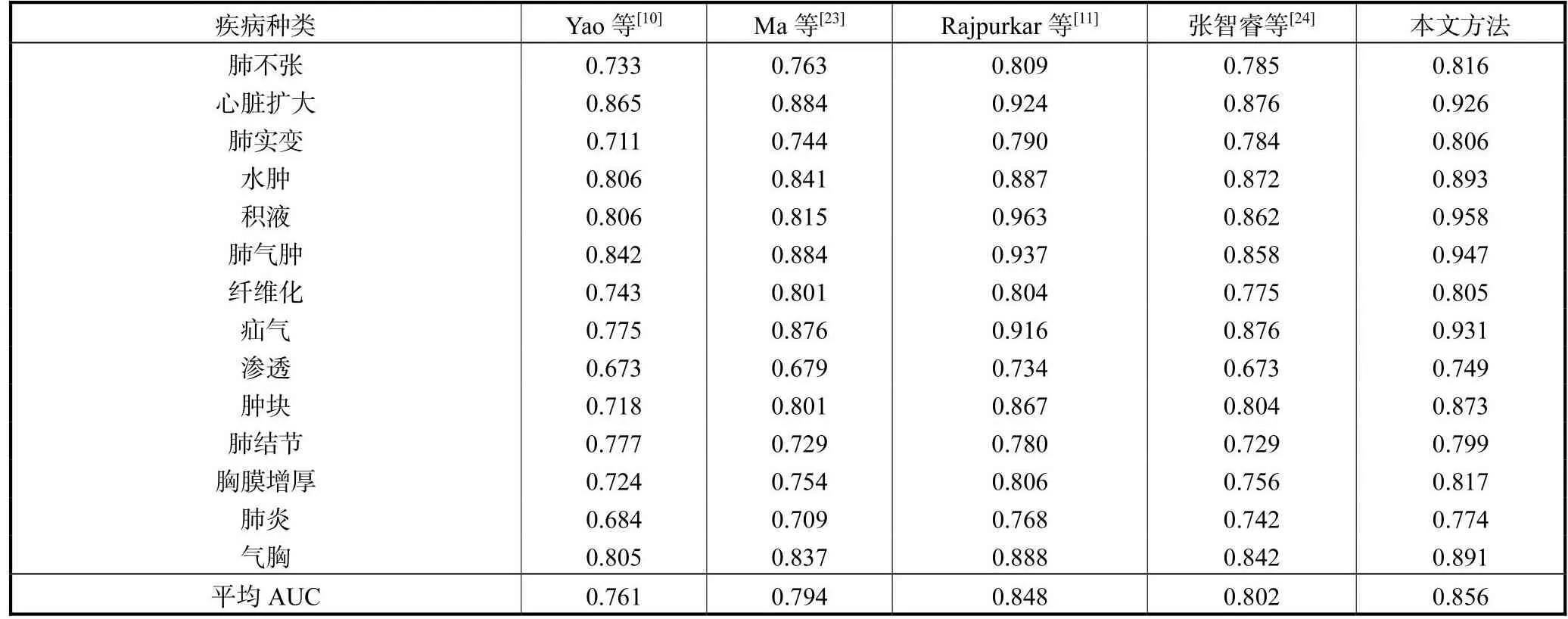
表6 在ChestX-Ray14数据集上与最优的方法比较AUC值Tab.6 Comparison of AUC values between the proposed method and the state-of-the-art methods on ChestX-Ray14 dataset
首先从整体分类效果来看,本文方法与其他4种方法相比,14种胸部疾病的平均 AUC值有较大提升,AUC值比其中最优方法(文献[11])提高了 0.008.其次在心脏扩大、积液、肺气肿、疝气疾病分类中的表现较为优异,AUC值均达到了0.900以上,说明本文提出的 OC-ResNet对图像细粒度的特征学习较好,且通过高低频的分量卷积运算,对高频像素的学习效果更优.另外对于除积液之外的其他 13种疾病,本文模型的分类 AUC值均有提升.而在渗透疾病的分类中效果表现较差,可能是因为渗透的病灶位置处于低频像素区域,学习效果较差.
本文方法与 Yao等[10]方法相比平均 AUC值提升0.095,其中疝气疾病的AUC值提升幅度最大,提高 0.156,Yao等[10]提出的方法受限于训练数据集样本不平衡,依赖标签之间的关系不够准确,本文方法采用焦点损失函数,在一定程度上缓解样本不平衡带来的准确度不高问题.
本文方法相比 Ma等[23]提出的方法,平均 AUC值提升 0.062,其中积液疾病提升幅度最大,提高0.143.本文和 Rajpurkar等[11]相比,平均 AUC值提高 0.008,肺实变和肺结节提升较为明显,分别提高0.016和 0.019.本文和张智睿等[24]方法相比,平均AUC值提高0.054.
4 结 语
本文将八度卷积引入胸部疾病分类中,改进ResNet网络中的普通卷积,提出一种 OC-ResNet算法,提升了胸部多标签 X光图像自动分类方法的性能.八度卷积模块通过分离图像的高低频通道,降低低频通道比例,使模型能够有效提取高频信息,同时大幅度降低网络的计算冗余,并且将 ChestX-Ray14数据集的14种胸部疾病的平均AUC值相比基础网络提高 0.016,FLOPs相比基础网络下降 44.77%,参数量下降 9.6%.通过渐进式迁移学习的训练方式,将平均 AUC值提高 0.006.焦点损失函数解决了样本分布不平衡的问题,相比交叉熵损失函数,平均AUC值提高0.007.在ChestX-Ray14数据集的14种疾病图像上分类效果优秀,平均AUC值达到0.856.
