基于改进核极限学习机的风电功率短期预测
2023-03-14黄文聪杨子潇常雨芳
黄文聪,潘 风,杨子潇,常雨芳
(湖北工业大学 太阳能高效利用及储能运行控制湖北省重点实验室, 武汉 430068)
0 引言
随着全球能源短缺和环境问题的日益严峻,可再生能源的开发和应用变得越来越重要。风能是目前应用最广泛的可再生能源之一,在能源系统中的比重不断提高,迄今为止,全球风电装机总容量已达到744 GW,占全球电力需求的7%[1-3]。风力发电功率具有很强的随机性和波动性,给风电系统的稳定运行带来了巨大挑战[4]。提高对风电功率预测的准确性是保证风电系统稳定运行的重要手段[5]。
目前,研究人员研究了各种风电功率预测模型,一般可分为物理模型和统计模型两大类[6]。其中,物理模型利用物理因素和气象因素预测风电功率,需要求解高维非线性方程,计算复杂度高,在超短期风电功率预测中的能力有限[7]。统计模型通过建立数学函数来拟合历史数据和风电功率输出值的映射关系[8-9],但处理非周期的预测信号表现欠佳。与传统的神经网络算法不同,核极限学习机(kernel extreme learning machines,KELM)对波动性较大的数据样本适应能力强。赵鹏等[10]利用小波包变换分解原始风电功率信号,得到若干个不同频率的信号分量,采用极限学习机模型对不同分量提取非线性特征信息进行预测;王伟峰等[11]引入时间注意力机制来加强风力发电数据的时间特征信息,建立门控循环单元神经网络模型进行预测。上述采用的方法仅根据风电功率历史样本数据构建预测模型,没有考虑影响风电出力的重要环境因素。史加荣等[12]利用高斯混合模型筛选近似日,采用麻雀算法优化改进KELM的超参数,得到最佳模型;杨磊等[13]采用主成份分析法选取对风电发电有影响的关键因素,并将其作为模型的输入,提升模型预测效果。然而考虑到季节气候变化的复杂性,风速波动范围较大,随机性更强,上述方法可能无法真正提取到关键环境因素的非线性特征信息。
综合上述分析,充分考虑对风力发电输出功率影响较大的环境因素变量,构建一种基于改进KELM的风电功率组合预测模型。利用CEEMDAN算法结合小波阈值去噪方法,降低原始数据的随机性和波动性,强化局部特征信息的多样性,针对KELM神经网络算法容易陷入局部最优解的问题,利用粒子群算法优化KELM的核参数;最后通过实验对比分析,实现在不同季节场景下的风电功率预测,进而验证本文所提出的预测模型的有效性。
1 风电功率预测整体流程
充分考虑各种环境因素对风电功率预测的影响,并且根据重要的环境因素,选取与预测日相似度最高的日子作为训练样本;然后采用CEEMDAN算法结合小波阈值去噪处理重要环境因素序列数据,得到若干个局部特征向量;最后利用粒子群算法优化后的KELM网络进行预测,具体预测步骤为:
步骤1对风电功率和重要的环境数据进行数据清洗,剔除异常数据;
步骤2利用皮尔逊相关系数定量表示不同环境因素与风电功率的相关性,得到影响风电功率的主要环境因素;
步骤3通过CEEMDAN算法和阈值去噪法降低原始序列样本的非平稳性,得到环境因素的子分量,进一步突显出环境因素的不同特征尺度;
步骤4利用粒子群算法优化KELM网络的输出权重参数,构建预测模型;
步骤5将数据预处理后的环境因素分量和风电功率数据构成数据样本,利用改进后的KELM算法分别进行预测;
步骤6对子分量的预测结果进行求和,并在四季的场景中比较不同的模型的预测结果,验证本文方法的有效性。预测流程如图1所示。

图1 风电功率预测流程框图
2 相似日选取原理
2.1 探究影响风电输出功率的环境因素
采用河北张家口某风力发电场的数据集,包括测风塔10 m风速、测风塔30 m风速、测风塔50 m风速、测风塔70 m风速、测风塔10 m风向、测风塔30 m风向、测风塔50 m风向、测风塔70 m风向、温度、气压、湿度11种环境因素。
皮尔逊相关系数[14]能反映2个变量相关性程度。因此,通过皮尔逊相关系数定量分析不同的环境因素与风电输出功率的相关性关系,筛选出与风电输出功率相关性较大的环境因素,皮尔逊相关系数表达式为:
(1)
式中:P为2个变量的相关性系数,P值的区间范围为-1~1;Xj和Yj为第j个数据样本点的2个环境变量因素的值。
为了更加直观地表示不同环境因素与风电输出功率的相关性,借用热力图的方式对P值进行可视化处理,如图2所示。由图2可知,测风塔10 m风速、测风塔30 m风速、测风塔50 m风速、测风塔70 m风速、气压、湿度与风电出力均具有较强的相关性,而测风塔不同距离的风向和温度表现出较弱的相关性。因此,文中选择测风塔10 m风速、测风塔30 m风速、测风塔50 m风速、测风塔70 m风速、气压、湿度作为关键环境因素。

图2 皮尔逊相关系数热力图
2.2 相似日选取
通过极差法对原始数据进行归一化处理:
(2)
式中:dm(n)为第m个向量的第n个分量;Xmax和Xmin为数据集中第n个分量的最大值和最小值,归一化后的训练集和预测日的向量矩阵分别为:
Xm=[xm(1),xm(2),xm(3),xm(4),xm(5)]
X0=[X0(1),X0(2),X0(3),X0(4),X0(5)]
Xm和X0在第l个环境影响因素下的关联系数为:
(3)
式中:|Δm(l)|=X0(l)-xm(l);η为分辨系数,η越小,分辨程度越大,取η值为0.5。综合衡量不同分量的相关系数,相似度为:
(4)
在进行实验分析时,为了提高风电功率模型的预测效率,在春、夏、秋、冬季分别选取相似日。以春季为例,首先随机在春季选择1天作为预测日,从数据集中2017年3月1日开始,计算每日与预测日的相似度,直至2017年6月30日,得出4个月的相似度,并将相似度从高到低排列,选取相似度最高的几日作为训练样本。以2017年3月1日为例,首先利用式(2)对该日的训练样本和预测日的数据样本进行归一化,保持量纲统一,得到该日和预测日的特征向量,特征向量包含6个分量,表示为利用皮尔逊相关系数得到的6个重要的环境因素分量(测风塔风速10 m、30 m、50 m、气压、湿度);其次,利用式(3)计算每种环境影响因素的关联系数,关联系数表示为该日与预测日对应的环境影响因素的相关程度;最后,为了综合衡量该日与预测日之间的相似性,利用式(4)将式(3)计算出的每一种环境影响关联系数进行相乘,得到该日与预测日之间的相似度。同理,分别计算出预测日与春季每一天的相似度,将计算出的相似度按照从大到小进行排序,选取相似度较高的前几日作为春季的训练样本。夏、秋、冬季同理筛选出相似度高的几日作为训练样本。
3 预测模型理论基础
3.1 CEEMDAN分解算法
CEEMDAN[15]是基于经验模态分解算法(empirical mode decomposition,EMD)改进得到的算法,适合分析高频波动信号。EMD是根据自身的时间尺度规律将复杂的数据信号分解成若干个内模态分量(intrinsic mode function,IMF),分解得到的IMF分量符合以下2个特点:
1) 在1条时间轴线上,极点个数和过零点个数的总和要大于等于1;
2) 在所有时刻内,包络线上下的平均值等于0。
CEEMDAN分解过程中,在每次IMF分解迭代中自适应添加白噪声,求解平均值,同时不断迭代,克服EMD出现的模态混叠的现象,对非线性信号具有适应强的特点。
定义Ij(·)作为EMD分解过程中出现的第j个IMF分量;Sj为添加的高斯白噪声;Xj(t)为原始数据信号W(t)通过CEEMDAN分解得到的第j个内模态分量,分解过程为:
步骤1在原始数据信号W(t)中加入白噪声W(t)+λ0Sj(λ0为白噪声控制参数)。该信号利用EMD分解M次得到M个内模态分量XM1,然后对M个内模态分量XM1之和求平均值,计算得到第一个CEEMDAN分解的分量,即:
(5)
步骤2分解得到的IMF1分量的残差分量为:
R1(t)=W(t)-Xj(t)
(6)
步骤3在R1(t)中添加白噪声R1(t)+λ1I1(Sj(t)),利用EMD对原始数据信号分解M次,计算获得第2个IMF子分量和剩余的分量为:
(7)
步骤4经过d次迭代,根据步骤2、3的计算结果得到d+1内模态子分量:
(8)
步骤5不断经过步骤4,直到剩余的子分量函数不能分解为止。
(9)
则原始数据信号W(t)表示为:
(10)
3.2 小波阈值去噪
小波阈值去噪方法在去除复杂信号噪声的同时能有效保留信号特征信息,避免信号出现失真现象。影响小波阈值去噪的效果主要取决于阈值计算规则的选取,阈值计算规则主要分为4类:
1) 无偏估计阈值计算规则(rigrsure)。即基于Stein无偏似然估计准则(stein unbiased risk estimate,SURE)的自适应阈值去噪方法,通过计算阈值最小的风险对应值,风险越小,越符合要求。
2) 固定式阈值计算规则(sqtwolog)。利用式(11)计算固定阈值:
(11)
式中:δn定义为噪声的标准方差;N定义为信号尺度;
3) 启发式阈值计算规则(heursure)。以无偏估计阈值为启发改进得到的,实质上是无偏和固定阈值的集合。若信噪比小,则利用无偏估计阈值去噪,反之,利用固定阈值去噪;
4) 极大极小值阈值计算规则(minmaxi)。利用极大极小准则确定合适的阈值,以得到最小均方极值。
3.3 极限核学习及算法
KELM是在极限学习机(extreme learning machines,ELM)的基础上改进而来,以核映射的方式取代随机映射,将低维并且繁杂的空间问题转变成高维空间中的求内积运算的问题,与ELM相比,其泛化能力更强。
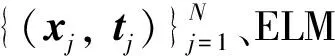
Hβ=T
(12)
(13)
式中:H定义为隐藏层向量矩阵;β定义为权值向量矩阵,;
ELM学习过程实质上相当于采用最小二乘法计算最优参数解,同时为了提升模型的泛化能力,加入正则参数C,求解出最小二乘参数解,即
(14)
式中:H+定义为H的广义阵。
核矩阵表示为:
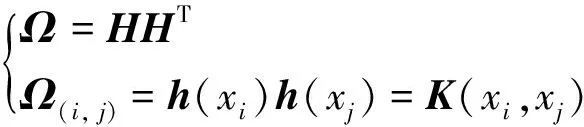
(15)
式中:K(·)定义成核函数,文中选择的核函数为高斯函数。
(16)
式中:g是核参数。
因此,得出KELM的预测函数为:
(17)
式中:I为单位向量矩阵。
3.4 粒子群算法优化核极限学习机
粒子群优化算法[16](particle swarm optimization,PSO)利用粒子个体间的信息交互实现对复杂问题的求解,具有搜索速度快、效率高和实现简单的优点。利用PSO算法优化KELM网络,确定最优输出权值,以提升KELM算法的预测性能。
步骤1选取风力发电实测数据,利用皮尔逊相关系数定量分析出与风电输出功率密切相关的六种环境因素,并进行数据预处理,划分训练集和测试集;
步骤2选取KELM的核函数为径向基函数(radial basis function,RBF)核,代入第一步预处理的训练集,得到初始的输出权重;
步骤3对粒子群参数进行初始化,包括粒子群规模数,粒子的初始位置和速度;
步骤4对粒子群进行寻优,计算粒子的适应度值,将训练集中的预测值和真实值的均方误差作为适应度函数,更新粒子的速度、位置,确定粒子个体的自身和全局最优位置。通过不断迭代,确定最优输出权值;
步骤5将寻优后得到的输出权重代入KELM进行预测。
4 数据预处理
4.1 CEEMDAN分解结合小波阈值去噪
为了降低环境因素的非平稳性,提高模型对风电功率的预测效果,采用CEEMDAN分解并结合小波阈值去噪的方式。CEEMDAN弥补了EMD存在的模态混淆和EEMD分解(改进的EMD)中辅助噪声带来重构误差的缺点[17],但CEEMDAN分解获得的模态分量含有一定的噪声,故通过对各个分量的自相关函数和原信号自相关函数的相关系数来计算分量和信号的相关度。相关度越小,分量含噪声越多,采用小波阈值去噪的方式对含噪声多的分量进行去噪。这里以测风塔10 m风速为例,计算结果如表1所示。

表1 测风塔10 m风速若干分量的相关度
由表1可知,测风塔10 m风速序列经CEEMDAN分解后得到的IMF1分量的相关度远小于其他分量,因此采用小波阈值去噪法对其去噪。同理,计算其他环境因素变量分解后各分量的相关度,通过计算各环境因素的相关度的结果发现,分解后的第一模态分量的相关度远小于其他分量。同时,尽管有极少数的分量有一定的噪声,但远低于第一分量,对KELM算法的预测效果影响较小,因此未进行去噪。
图3为部分测风塔10 m风速的CEEMDAN分解结果,表2的数据为不同环境因素经CEEMDAN分解得到的IMF分量,共计82个,共82维特征子序列构成新的序列集合。
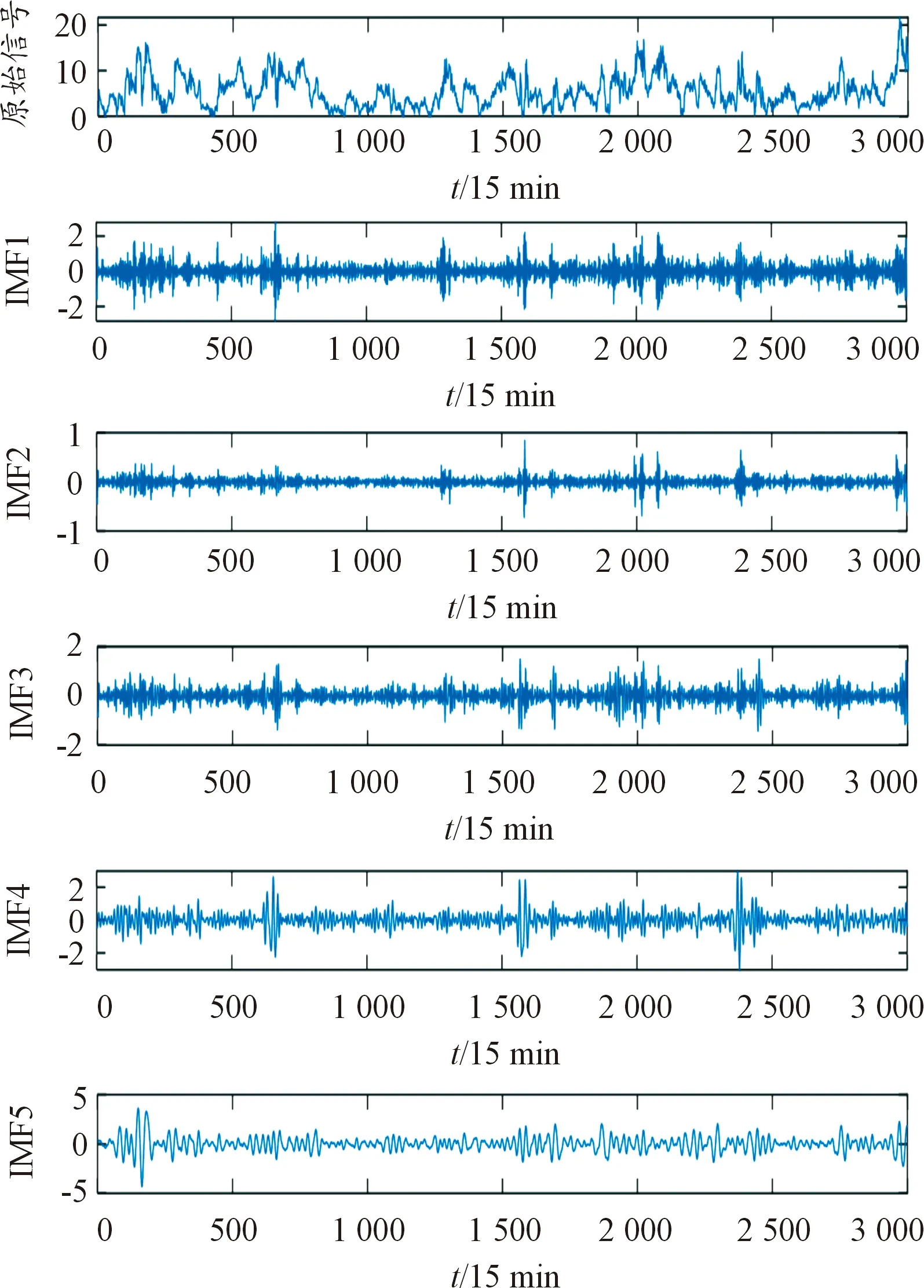
图3 CEEMDAN分解结果

表2 CEEMDAN分解后的不同环境因素分量个数
针对CEEMDAN分解结果中第一模态分量含噪声较多的问题,采用阈值去噪方法对其去噪。阈值去噪过程中,选取阈值函数为软阈值函数,小波分解层数为5,小波基为sym8,采用不同的阈值准则对第一模态分量去噪,并通过均方根误差(root mean squard error,RMSE)和信噪比(signal noise ratio,SNR)评价不同方法的去噪效果。去噪效果如表3所示。
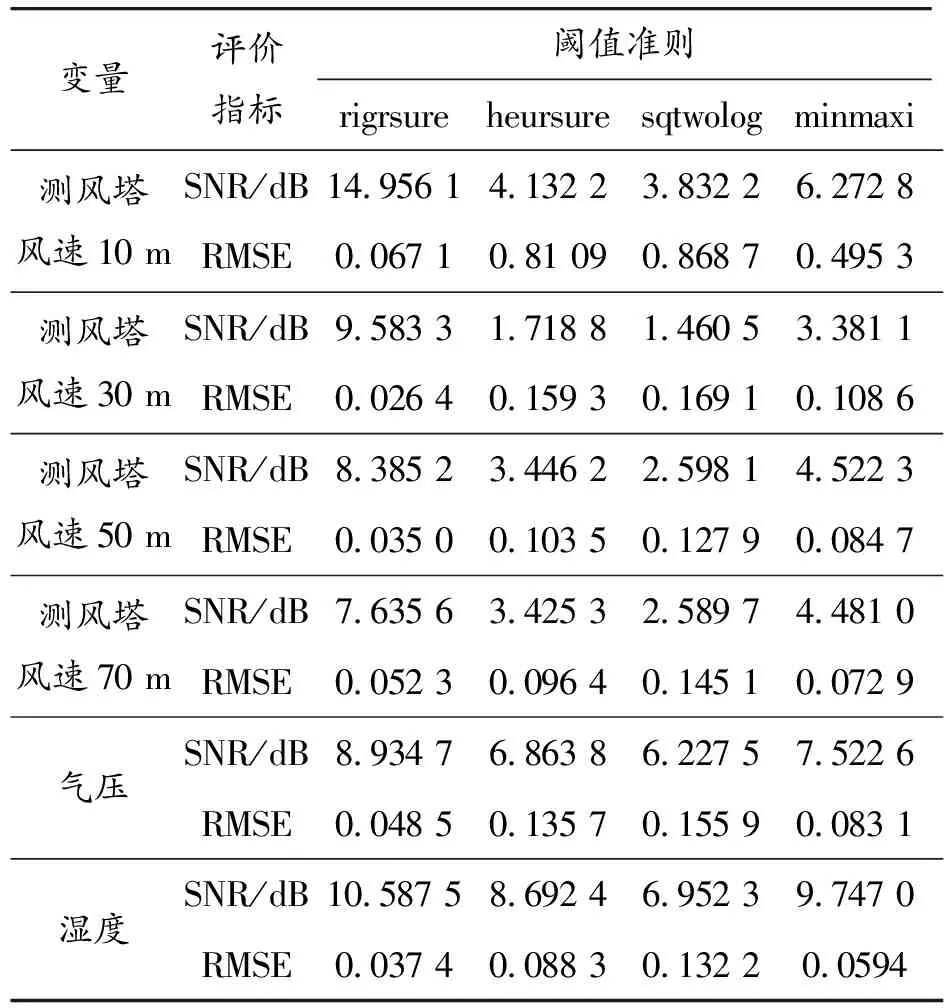
表3 不同阈值准则去噪效果
由表3可知,对不同环境因素的第一模态分量采用rigrsure准则去噪,SNR值最高,RMSE值最小,去噪效果表现最好,说明采用rigrsure准则的软阈值去噪法更适合处理不同环境因素经CEEMDAN分解后第一模态分量含噪声较多的问题。以测风塔风速10 m去噪对比结果为例,测风塔风速10 m的IMF1分量去噪前后如图4所示。可以看出,采用rigrsure准则的软阈值去噪法不仅能对IMF1分量有较好的去噪效果,还保留了IMF1分量的有效特征信息。
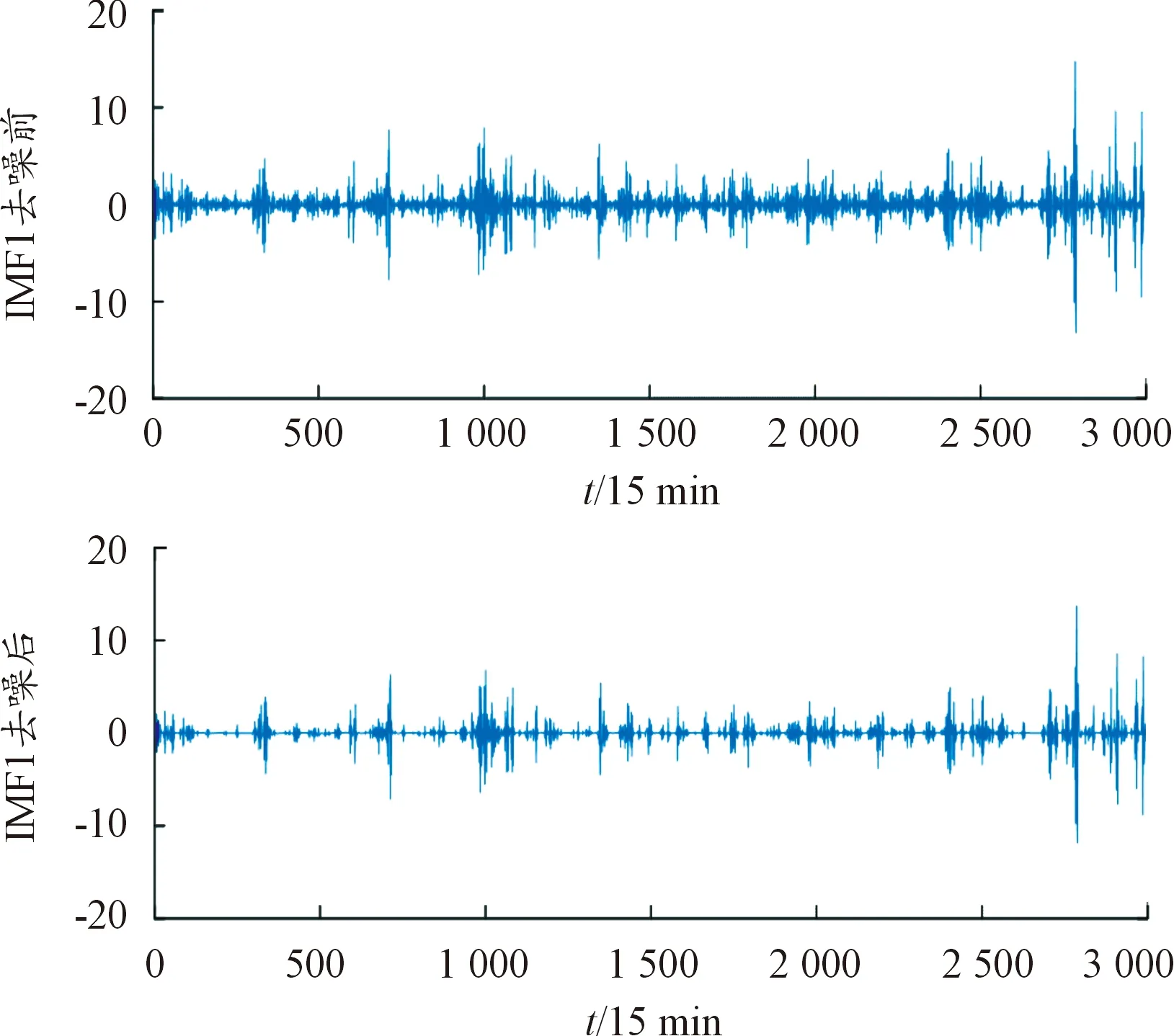
图4 去噪前后IMF1分量
4.2 预测模型评价指标
选取平均绝对百分比误差(mean absolute error,MAE)、均方根误差 RMSE、平均绝对误差(mean absolute percentage error,MAPE)为网络模型评价指标,定量分析模型预测结果。计算表达式分别为:
(18)
(19)
(20)
式中:p为预测功率值;y为实际功率值;N为数据样本总量。
5 仿真实验分析
选取的数据集是河北张家口某风力发电场从2017年3月至2018年3月的实测数据,每间隔 15 min采样1次,随机在春季、夏季、秋季、冬季选择1 d作为预测日。根据相似日选取原理,在春、夏、秋、冬的实测数据集中,分别选取相似度最高的 11 d作为春季的训练集,同理夏季为13 d,秋季为 17 d,冬季为19 d。考虑预测结果数据量较大,预测结果选择预测日中的20∶00—22∶30(共150 min)的时间段进行展示,选取测风塔10 m风速、测风塔30 m风速、测风塔50 m风速、测风塔70 m风速、气压、湿度6种环境因素作为风电功率预测模型的输入变量。
在仿真实验分析时,采用的智能优化算法为PSO算法,利用4种预测模型进行对比实验,包括反向传播(back propagation,BP)算法、KELM、CEEMDAN +小波阈值去噪+KELM 、CEEMDAN+小波阈值去噪+PSO+KELM共4种预测模型,其中BP和KELM为单一预测模型,而另外两种组合模型在KELM的基础上增加CEEMDAN+小波阈值去噪的数据预处理方法,提高KELM的预测效果。为了进一步提高KELM的预测性能,利用PSO优化KELM输出权重参数。BP算法的预测效果受BP的参数学习率影响较大;KELM算法的预测效果受KELM参数中的输出权重影响较大。 BP参数学习率一般设置为0.002,但对KELM算法而言,输出权重参数无法通过经验选取,因此利用粒子群智能优化算法对KELM预测算法的输出权重参数进行寻优,获得最佳的输出权重。优化过程在3.4小节描述。分别对不同季节的风电功率进行预测,计算不同预测模型的MAE、RMSE和MAPE值,同时对预测的结果进行对比分析。图5为在不同季节下的风电功率预测结果。

图5 不同季节下的预测结果
由图5可知, 在春季的预测结果曲线局部出现突变凹的地方,如20∶30—20∶40时间段,与相邻时间段相比,该处的风电功率波动较大,主要原因是气候变化大,风速波动性和随机性大,致使模型的预测结果出现了陡峭的趋势。但是可以看出本文预测方法与真实值的拟合程度最高,说明本文方法在这种极端环境下预测效果依然表现最好,适应性强。同理,在夏季的预测结果曲线中出现风电功率波动较大的时间段为20∶30—20∶40,秋季预测结果曲线波动较大的时间段为20∶30—20∶40,冬季预测结果曲线波动较大时间段为 20∶20—20∶30和20∶40—20∶50,在风电功率波动较大的情况下本文方法预测效果均表现最好,验证了本文预测方法的优越性。
在四季场景中,利用4种预测模型进行风电功率预测,通过对比不同模型的预测曲线发现,除本文方法以外,其他3种预测模型都实现了对风电功率的预测,但预测效果不理想。考虑四季受当地气候的变化影响不同,风速的波动范围也不同,预测结果的波动性变化和突变的情况也不同。冬季受当地气候的影响最大,风速波动范围最大,因此预测模型的预测曲线局部出现凸和凹的频率次数最多,程度最大;其次是春季,然后是秋季,最后是夏季。另一方面,通过对比表4的误差指标值发现,冬季的预测结果误差最大,其次是春季,然后是秋季,最后是夏季,验证了四季受当地气候的影响不同,预测精度也不同。其中,冬季的预测误差最大,其次是春季,然后是秋季,最后是夏季,因此可以利用预测结果曲线局部出现凸和凹的频率次数和程度,结合模型的预测误差结果比较区分春、夏、秋、冬四季。

表4 不同季节下的模型预测结果
由表4可知,传统的单一预测模型BP、KELM得到的预测精度要低于组合预测模型;对于KELM和CEEMDAN+小波阈值去噪+KELM两种预测模型而言,后者的预测误差更小,说明了所提出的数据预测处理方法降低环境变量因素的平稳性对风电功率的预测精度有一定的提升。相比于CEEMDAN+小波阈值去噪+KELM,所提出的CEEMDAN+小波阈值去噪+KELM预测模型在春、夏、秋、冬季下的MAE值下降了0.482 2%、0.275 9%、0.270 6%、2.387 3%;RMSE值分别下降了0.196 7%、0.369 9%、0.227 4%、0.239 3%;MAPE值分别下降了0.147 8%、0.059 3%、0.216 4%、0.462 3%,说明在对KELM的输出权重优化之后,风电功率的预测精度有进一步提升,验证了所提出预测模型的有效性。
6 结论
1) 利用CEEMDAN分解结合小波阈值去噪,降低6种环境因素的非平稳性,克服了传统EMD算法的模态混淆和EEMD存在的重构误差的缺点,同时解决了CEEMDAN分解结果中第一模态分量含噪声较多的缺点。
2) 考虑到季节性变化对风力发电输出功率的影响,在春、夏、秋、冬四季的场景下,采用不同的预测模型对风电功率进行预测。春、冬两季受当地气候原因的影响,风速波动范围较大,波动性较强,所提出的组合模型的预测精度最高,预测效果最好,说明该组合模型适合风速波动性较大、突变较多的极端环境。
