拟合化处理不完整数据缺失序列插补算法仿真
2023-03-11姚迎乐
姚迎乐,李 建,2,孙 滨
(1. 郑州工业应用技术学院信息工程学院,河南 新郑 451150;2. 河南大学数学与统计学院,河南 开封 475001)
1 引言
在大数据时代,经常会遇到因多种干扰因素而使数据呈现不完整的情况,或是数据在收集时就是缺失状态。若丢失的是较为重要、有价值的信息,那么数据分析将变得困难,导致对信息的分析和判断失去准确度,因此,需要对不完整数据实行缺失插补。
针对缺失数据的插补方法有很多,杨弘[1]等人研究出一种混合缺失插补法,通过模拟数据的不同缺失比例,利用不同数据填补方法,通过错分比例形式,对缺失数据进行填补,在正则化均方误差的基础上,验证数据的插补结果,对数据的填补结果较为理想,但遇到数据变量较大的情况,则会出现较大的误差;刘佳星[2]等人研究出一种基于缺失率的数据插补算法,针对数据集合中各个样本数据不同程度的缺失率,通过将随机森林和马尔科夫法相结合,计算数据的缺失平均值对数据进行缺失插补,通过验证插补误差,确定方法的可行性,但该方法并未考虑数据的噪声干扰问题,因此数据插补过程中分辨数据的时间较长。
为此,利用随机森林模型,建立决策树来对不完整数据进行缺失预测,前期通过对数据的预处理,减少数据参数不均和噪声现象,剔除异常数据,使数据中有效信息更加清晰,利用不完整数据内有价值信息进行预测,通过多维度和多迭代的插补计算,得到最终的数据插补值,在一定程度上提高了缺失数据插补效率和精度。
2 不完整数据缺失插补算法
2.1 随机森林插补模型构建
将大量的已有数据去重抽样[3],假设原始的数据训练样本集包含N个数据样本,从中随机抓取n个数据样本,为了方便研究,设定每一个数据样本容量与训练集合中样本个数是相同的,利用提取出来的n个数据样本构建控制决策树分类模型,通过{h(X,θk),k=1,2,…,n}来具体表示,将数据样本带入到集合中可以得到n个数据分类结果,在此基础上,根据得出的分类结果,通过决策树的投票机制决定最终的分类结果。随机森林决策过程如图1所示。
随机森林针对不完整数据的缺失插补算法,在进行去重随机抽样时,如果数据训练样本集中包含的样本个数N足够多,利用重要极限推导法可以具体计算出集合中每个样本未被随机抓取抽中的概率是:
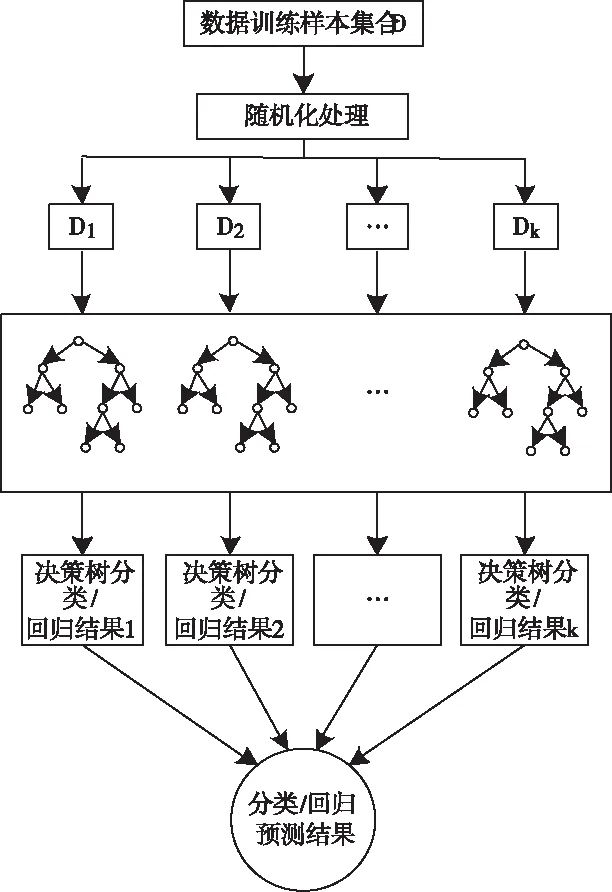
图1 随机森林示意图
P=(1-1/N)N
(1)
经过概率收敛后得出:
1/e≈36.8
(2)
这个概率说明原始的数据训练样本集中约等于36.8%的数据样本,在进行去重随机抽样时不会被抽取到,将这些数据样本统称为袋外数据,这类袋外数据可以有效降低随机森林模型的泛化误差[4]。
利用随机森林模型对不完整数据进行缺失插补计算时,由于充分利用了数据集合的原始信息,基本不会受到数据分布的影响和限制,依据原始的数据训练样本完成相应的数据缺失预测,通过森林中多棵决策树的联合作用,使算法得出的插补效果更加准确有效。具体的模型构建流程如图2所示。

图2 数据缺失插补模型构建流程图
2.2 数据预处理
在收集数据的过程中,不可避免地会存在一些异常数据节点,为了减少和避免这些异常数据对后续数据缺失插补结果产生影响,利用阈值函数对不同的数据特征设定对应的评估阈值,当数据中的特征超过了所设定的评估阈值时,算法认为该数据属于异常数据,并从数据样本集中剔除[5,6]。在此基础上,将数据样本集中的连续完整段数据复制,分别用于实验和结果验证,实验过程中将样本集中的数据点进行随机连续删除,再利用时间间隔来模拟插补段[7]。
通过遍历法明确数据在确定时间间隔内的缺失个数,选取若干个缺失点作为随机森林预测自变量,对训练特征建立预测处理值,用来优化数据样本。在采集的数据过程中,由于噪声掩盖了部分有效信息,使得数据缺失,假设数据{xo,y}中xo部分存在干扰噪声,通过计算获得数据内噪声位置的共享特征[8]uo,可以在数据回归的基础上得到降噪后的数据
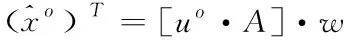
(3)
式中,w表示对数据干扰的降噪系数,T表示处理周期,A表示随机变量数据。
3 不完整数据缺失插补算法
假设待插补的数据样本集中样本的维度为p,将第i个数据样本在第j维的具体数据表示为xij,那么所获得的n×p维数据样本集合可表示为

(4)
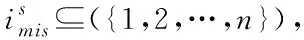
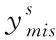
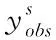
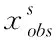
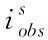
当列向量Xs是多变量矩阵时,对不完整数据的缺失插补与单变量基本相同,针对数据样本集合矩阵X中的缺失数据,按照数据所在不同维度,以及不同的缺失程度对数据进行升序排列,通过均值插补有效填充缺失数据,可以得到初始的填补后数据矩阵,利用伪代码函数算法对数据进行迭代插补[9],随后将插补结果更新并组建新的插补矩阵。
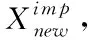
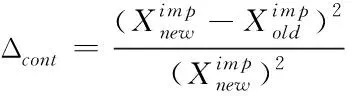
(5)
考虑到随机森林中的独立决策树在生成阶段容易出现过拟合现象,利用最大生长层原则限制随机森林中决策树叶片节点个数,实现决策树成长层的优化[12,13]。为了使模型对缺失数据的插补更加精确,应在一定层面上减少数据的干扰噪声,通过融合集成算法随机回放抓取数据样本,随机抽取g组数据样本作为原始数据的插补训练集合,对应的建立g个与数据并行但独立的弱评估器[14],在此过程中独立决策树会在各个分支节点处,对随机变量A实行平均绝对误差最小化处理[15],通过计算与决策树上任意父节点b相对应的子节点U1、U2的平均绝对误差值,同时计算当这两个值处于最小时所对应的父节点和变量变化,判断具体评估结果,具体计算如下

(6)
式中,c1和c2分别表示U1、U2两个子节点对应的输出均值,xi表示输入到决策树中的样本点,yi表示经过决策树决策后的输出值。
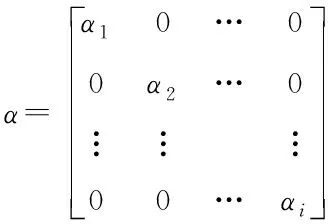
f(α)=αB
(7)
利用最小二乘估计法求解函数式可得
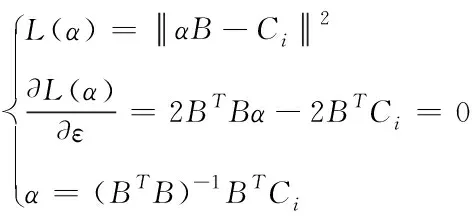
(8)
式中,L表示数据输出残差平方函数值。
数据缺失插补经过训练得到插补权重后,利用序列插补法对数据预测点实行逐一拟合化处理,前一个数据经过拟合后将作为下一个数据的拟合输入值,最终生成最佳的权重矩阵插补。
4 仿真研究
为验证所研究的基于随机森林的不完整数据缺失插补方法是否可靠有效,首先对于缺失数据的参数优化及预处理效果,进行相关的验证,将ntree和mtry作为综合参考因素,以标准均方根误差数值最小作为最佳参考因素,设定随机森林模型中子树数量为ntree=10,20,30,…,400,一个子树产生的分枝为mtry=2,4,6,8,在此基础上,对缺失数据实行300次的ntree和mtry综合因素迭代,此时可以得出随机森林对不完整数据的插补算法中,ntree和mtry两个综合因素对准均方根误差以及算法时间的具体影响关系,实验的具体结果如图3和图4所示。
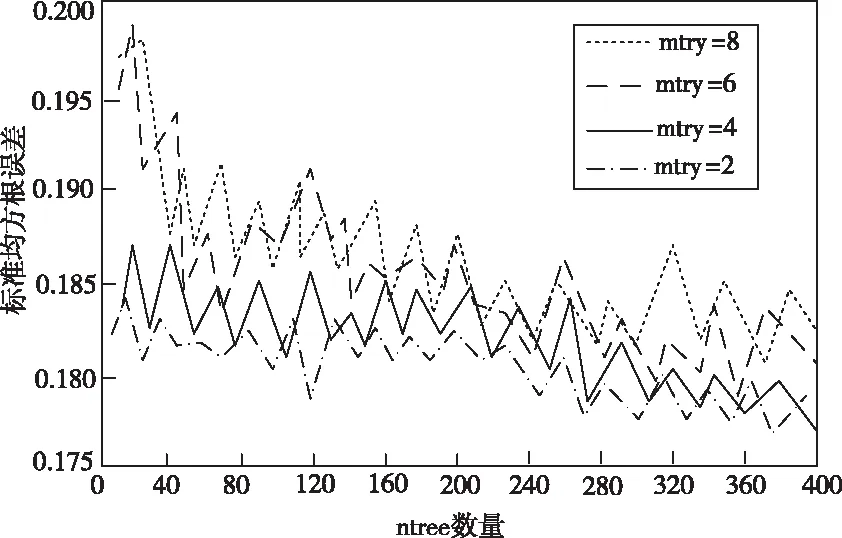
图3 ntree和mtry综合因素对标准均方根误差的影响
从图3和图4中可以看出,随机森林对不完整数据进行缺失插补的过程中产生的插补误差,主要受到ntree参考因素的影响,随着ntree数值的增大,随机森林算法数据缺失插补的误差会逐渐减小,证明插补结果在此过程中变得越来越准确。而插补算法所耗用的时间则会随之增加,mtry参考因素对随机森林算法的插补误差影响并不是很大,主要影响的是算法运行时间,当ntree数值逐渐大于200时,对插补误差产生的影响也在逐渐缩小。这一点证明了所提算法不会产生过度拟合的情况,随着决策树数量的不断增加,误差情况逐渐收敛,得到最优的算法综合参考因素为ntree=200,mtry=2。
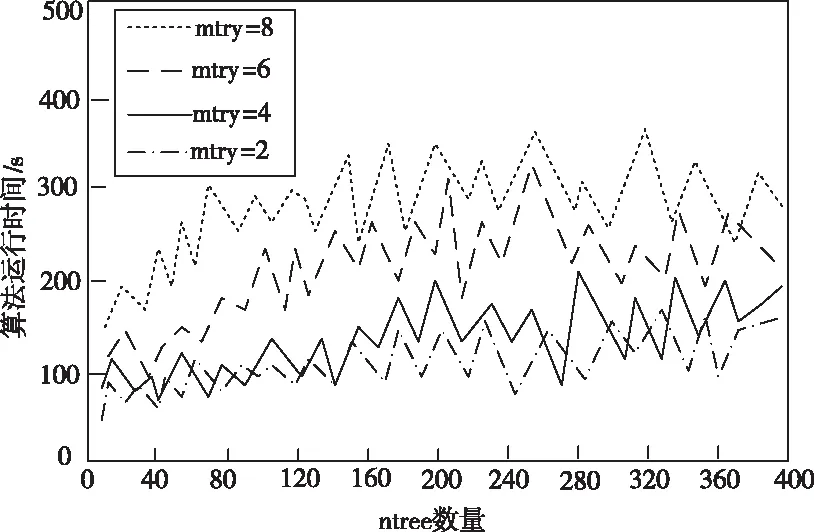
图4 ntree和mtry综合因素算法运行时间影响
令混合缺失插补法、缺失率插补法和本文方法在相同数据环境下,进行不完整数据的缺失插补计算时间对比,结果如图5所示。
从图5中可以看出,混合缺失插补法由于通过错分几种插补方法的计算比例,来实现对不完整数据的插补,其在计算数据缺失情况时,所需时间比缺失率插补法和所提算法要长,相对应的插补速度略慢;由于缺失率插补法是根据数据间不同的缺失率情况来进行插补,在对不完整是数据进行初始计算阶段,需要消耗时间来分析数据的缺失程度,当掌握到缺失规律后,插补速度开始加快,但是随着数据量的增多,插补速度仍旧不占优势。而所提算法利用随机森林实行不完整数据插补计算,在计算时间上耗费更少,插补速度更快,效率相对更高。
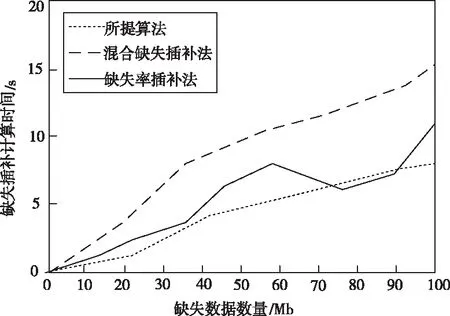
图5 不同方法缺失数据插补计算速度
大多数情况下,不完整数据的插补是在大数据环境下完成,其数据体量相对比较庞大,并不能单纯因为某个算法的计算时间短、效率高就判断该种方法更加优秀,对不完整数据的缺失插补目的是得到相对完整的数据,便于对相关事件更好的分析和判断,因此,数据插补的精度尤为重要,因此对三种不同算法的插补精度进行仿真对比实验,来证明所提插补算法的性能,具体结果如图6所示。
从图6中可以看出,随着数据缺失率的不断增长,原始数据中可利用的有效信息含量越少,这对不同插补算法的影响是相同的,算法的准确度都会随之下降,但经过比较混合缺失插补法、缺失率插补法和所提算法的仿真结果可知,当缺失率保持在30%以内时,混合缺失插补法和缺失率插补法对不完整数据的缺失插补准确度均保持在75%以上,插补效果较好,但当缺失率30%之后,这两种方法的插补准确度下降较为明显,无法在有效信息较少的情况下很好地预测插补值,而所提算法在数据完全缺失的情况下,插补准确度能够保持在50%以上,对缺失数据的预测能力更好。
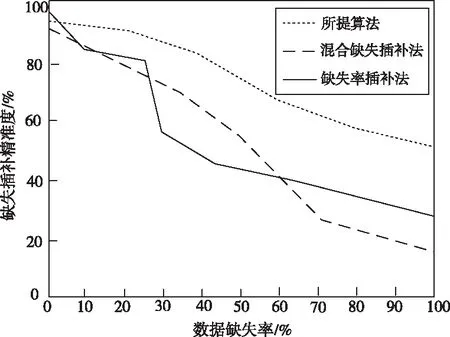
图6 不同方法缺失数据插补精准度
5 结论
本文提出的基于随机森林的不完整数据缺失插补算法,通过建立随机森林模型并拟定独立决策树,经过减少数据参数不均、处理噪声等相关预处理操作后,使原始数据不受外力干扰,能够清晰呈现有效信息,通过多角度和多迭代的插补计算,得到最终的数据插补值,有效处理高维数据。经过仿真证明,所提算法弥补了数据的不确定性,插补准确度较高,在不影响算法准确度的同时提高了插补运算的效率,能够提取到数据中的辅助变量信息,鲁棒性好,更加适合大数据背景下的不完整数据处理和分析。
