基于小样本学习的降雨云分类及天气预测
2023-03-11徐铭美
徐铭美,方 睿,罗 鸣,雷 蕾
(成都信息工程大学,四川 成都610225)
1 引言
天气与人们的生活息息相关,但由于其变化莫测的特性,长期以来都有许多专家和学者投身于气候和天气预测的研究当中。目前,国内外对降雨预测的研究大多都局限于卫星云图的数据。但由于传统的天气预测方法存在很多弊端,如需要的数据量大,计算时间久,代价大,专业性高等,越来越多学者开始关注运用其它的自然天气数据来进行预测研究。其中,一些科研人员提出了利用云朵图片进行分类和检测识别,如张飞等提出的基于深度卷积神经网络的云分类算法[1],从而能够快速简单的获取有价值的天气信息。
随着人工智能的不断发展,在气候研究方面也取得了较好的成果。如张敏靖等提出的基于对抗和迁移学习的灾害天气卫星云图分类[2],以及李冰洁等提出的气象卫星系统的云图自动分类识别研究[3],均运用了深度学习算法对天气进行预测。其中,降雨作为最为常见的天气之一,也成为了天气预测的重点。如高利峰提出的降雨量预测方法研究[4]。但是,由于目前关于云朵图像的标准公开数据集较少,所以在进行天气预测时,面临着数据集缺乏的问题。大部分的深度学习算法都需要大量的相关数据进行训练,才能得到较好的准确度。因此,目前利用深度学习框架对降雨云图像进行分类存在着以下两个问题:浅层的卷积神经网络不能充分地提取降雨云图像的特征信息;降雨云图像数据样本小导致深层卷积网络在训练过程中容易过拟合。
针对本次实验的研究内容,本文采用小样本学习的方法,即仅利用少量样本就可以训练得到不错的效果,从而解决了上述问题,并得到一种更加简单,便捷,代价小,专业性要求较低的天气预测方法。本文提出的元基线改进模型Distillation-Meta-Baseline(后简称为D-MB模型)的实验结果也表明,其能够在少样本数据的条件下,实现较好的分类效果。从而为天气预测提供了一种有效地,新颖的,实时性强的辅助决策方法。
2 数据获取
2.1 数据集的构建与预处理
本文所采用的自建降雨云图像数据由世界气象组织(World Meteorological Organization,简称WMO)提供,其对应的相关降雨信息也均来自WMO官网。由于世界气象组织所提供的数据包含了所有类型的云图像,所以本文需要对其进行二次整合,从而得到一个较为标准的降雨云图像数据集。同时,为了避免数据样本数量分布及内容上的差异而导致的一些问题,本文首先对图像进行增强和归一化处理,通过随机旋转,偏移等操作提高样本数量。并且依照世界气象组织提供的降雨云分类标准,以及不同的降雨云类型将数据集分为6类:高层避光云,高积堡状云,积雨鬓状云,积雨秃状云,雨层云,以及钩卷云。如表1所示。
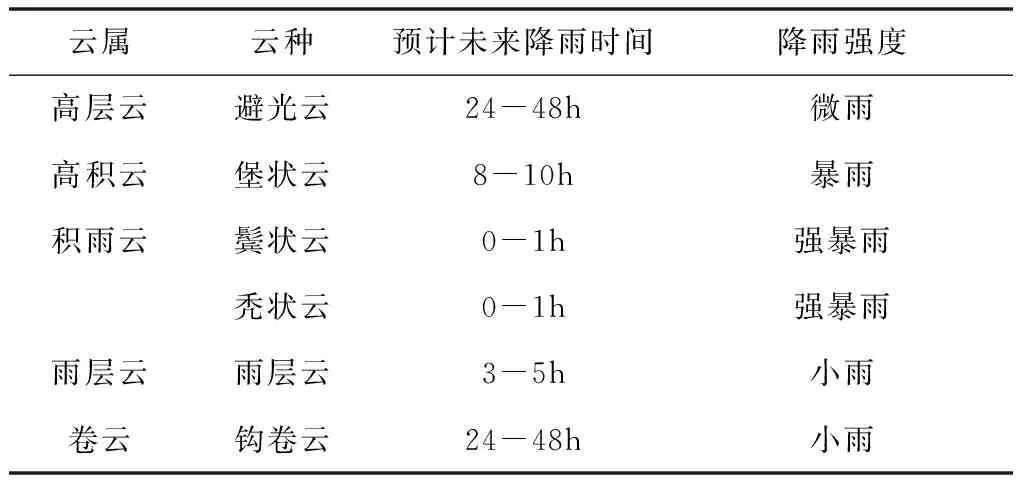
表1 降雨云数据信息表
每类图像20张,数据集的总样本数量为120张,部分降雨云样本如图1所示。

图1 降雨云图像
3 研究方法与模型构建
3.1 研究方法
小样本学习与传统的监督学习不同,它的目标是使模型通过训练学会学习,而不是着重于让机器识别训练集中的图片并泛化到测试集上。与此同时,随着小样本学习领域的快速发展,元学习作为小样本学习中最主要的一类方法,也涌现出了大量的新算法。常见的元学习框架可以大致分为3类:基于记忆的元学习方法,基于优化的元学习方法,以及基于距离度量的元学习方法。
基于记忆的元学习方法即在原本的元学习框架中添加记忆机制,使得模型能够对学习到的知识进行总结提取,并辅助后面的学习任务。Ravi和Larochelle在2017年便提出将LSTM与元学习相结合的优化算法[9]。
基于优化的元学习方法是指通过元学习模型在支持集上进行优化操作。基于优化的元学习方法有很多,其中包括了选择初始化参数,采用不同的梯度更新算法等。例如Finn等人在MAML[10]中就提出通过为每个训练任务提供一个更好的初始化参数,从而达到更佳的训练效果。
基于距离的元学习方法通过度量特征之间的距离来进行网络的训练。在距离度量的元学习模型中,通过计算比较询问集和支持集样本特征之间的距离来实现分类。如Vinyals等人在2017年发表的Matching Network[11]就提出了一种快速学习样本间度量方式的框架。
尽管上述的元学习算法已经取得了许多优异的成绩,但是近年来一些对预训练分类器性能的研究,如Gidaris和Komodakis[12]提出的余弦度量分类器训练方法,以及Yinbo Chen[7]等人基于元基线提出的优化方法,表现出的效果更优于之前的几种元学习方法,尤其是在面对跨域问题时。
因此,本文提出的D-MB模型将分类器基线和元学习的优点相结合,并引入知识蒸馏的思想,使得模型性能优于以往的方法,并将其应用于降雨云图像的分类和天气预测。
3.2 模型建立
基于小样本的D-MB模型训练主要分为两个阶段:分类器训练阶段和元学习阶段。对于分类器训练阶段,需要使用大量带标签的基类(Cbase)数据训练出一个分类器,从而为后面的元学习模型提供性能优异的特征提取器(或称为编码器encoder)。然后,将新类(Cnovel)图像数据输入到到元学习框架中进行训练和学习。其中,值得注意的是本文采用的基类数据来自于公开数据集cifar100,新类数据为本文自建的降雨云数据集。
3.2.1 分类器模型
传统的分类器模型是通过使用大量的数据独立训练而成的,其训练结果的好坏通常都是通过与数据标签进行对比得到的。但是数据标签包含的信息量往往较少,只能反映出结果的对错。所以,有学者提出在训练分类器模型时,引入一个预训练好的复杂模型(或称为教师模型)来进行辅助,此时被训练的分类器模型称为学生模型。具体而言,即使用教师模型中的softmax层输出来作为另一种“标签”,Hinton[13]将其称为soft target,与学生模型的输出进行比较,从而获得更加丰富的反馈信息。种训练的过程就被称作为“知识蒸馏”。值得注意的是,如果在实验过程中soft target的数值方差太大,则引入教师模型的意义就不大了,所以在这里需要引入温度参数T来控制教师模型对学生模型的影响,具体可见式(1)。

(1)
其中zi表示分类器模型中softmax层的输出,zj表示其它模型的输出,qi表示zi与zj之前的关联度。温度参数的值是根据具体实验的要求进行人为设置的,常设为1。另外,T如果太大了,会导致正确项的数值与错误项的数据差距太小,无法区分出哪个是正确的选项;T如果太小了,模型在“蒸馏”过程中会弱化soft target的作用,从而失去了蒸馏的意义。
根据Hinton[13]的研究表明,可以根据自身的实验需求进行教师模型的选择,不一定要是一个复杂的网络模型。最后,会得到一个网络层数更浅,运行更快,但准确度堪比同类型复杂网络的分类器模型。分类器蒸馏训练的具体流程如图2所示。
3.2.2 元学习模型

图2 分类器蒸馏实验流程
在进行元学习模型训练之前,需要先将蒸馏过后的分类器网络去掉全连接层,并将其作为元学习模型中的encoder。同时,将Cnovel的数据划分为支持集(support set)和询问集(query set)。
元学习的主要特点是以task作为基本单位进行网络训练,即将整个网络的训练过程分为多个小任务进行。在每个task中,需要在支持集上的N个类各抽取K张的降雨云图像(即N-way K-shot)输入到编码器fθ中,从而提取出各类数据的特征,同时在询问集中也要抽出一定数量的图片进行特征提取。然后分别计算出询问集数据与支持集中各类数据之间的相似度,最后将计算结果与询问集中抽取的数据标签进行对比,计算出loss。其中,相似度的计算可以选用L2或者COS来度量两者之间的距离。具体的元学习模型框架如图3所示。
3.2.3 损失函数
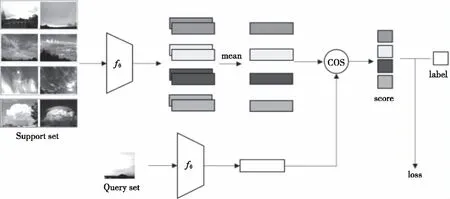
图3 元学习模型算法流程
a) 分类器模型的损失函数
本文的蒸馏实验采用标准交叉熵作为分类器训练的损失函数,其loss通常包括了两个部分:一个是学生模型与教师模型输出之间的loss1,另一个是学生模型与数据标签之间的loss2。具体的损失函数见式(2)
loss=loss1+loss2
(2)
其中,loss1的具体计算可见式(3)
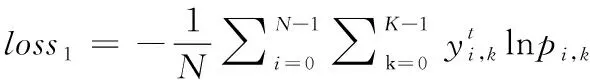
(3)
loss2的具体计算可见式(4)
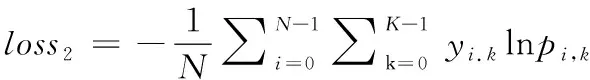
(4)
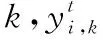
b) 元学习模型的损失函数
由于整个元基线模型的损失函数是由每个训练任务的损失一起构成的,所以需要计算每个任务的损失。首先,在支持集中计算N个类的质心,这些质心定义在式(5)中。
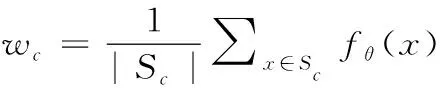
(5)
然后,用式(6)计算定义的查询集中每个样本的预测概率分布。
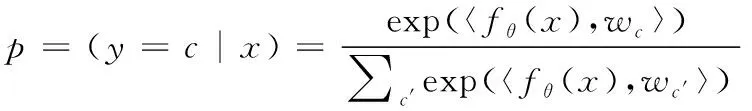
(6)
其中,S为支持集,Sc为在c类别的选取的数据,wc为计算出的特征平均值(类中心),fθ为编码器函数,x为输入的图像样本数据,p为计算出的余弦相似度。
损失是由p和查询集中样本的标签计算的交叉熵损失,具体可见式(7)
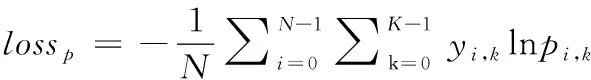
(7)
值得注意的是,将每个任务都视为训练过程中的数据点,每个batch可能包含多个任务,并计算平均损失。
4 数据结果与分析
本文的实验环境为Linux操作系统,采用英伟达(NVDIA)显卡,CUDA10.0,Pytorch版本为3.7,显卡内存为12G。
实验主要分为了三部分:运用知识蒸馏的思想训练分类器模型,并与未经蒸馏训练的模型进行对比;构建一个基于小样本的元学习分类模型实现降雨预测,并对比不同深度的分类器网络对整个元学习模型准确度的影响;与目前主流的元学习模型进行效果对比。
4.1 分类器模型的训练结果分析与对比
通过运用知识蒸馏的思想,本文选择ResNet110作为预训练的教师模型。同时考虑到不同网络深度的encoder对D-MB模型分类效果的影响,分别选择ResNet12,ResNet18,ResNet34,ResNet50作为学生模型,在cifar100数据集上进行训练对比。
本小节的实验主要分为两个部分。首先,对上面所提及的4个学生网络分别进行了随机初始化独立训练。然后,再对同样的4个学生网络进行蒸馏实验。训练的基本设置为迭代200次,批处理数量为128,学习率为0.1,权重递减1e-4,学习动量为0.9,优化器选用Adam。两次的具体结果如下表2所示。

表2 分类器模型结果对比
从上表可以观察到,随着网络的加深,学生模型的准确度越来越高。且通过蒸馏实验训练出的模型准确度均高于独立训练的模型。由此可见,运用知识蒸馏的思想可以明显提高分类器网络的性能。
4.2 D-MB模型实验结果的分析
本次实验采用的数据集为自建的降雨云数据。为了体现D-MB模型在跨域分类方面的有效性,本文将该数据集(共6个类,120张)中的4个类划分为支持集(80张),剩下的2个类划分为询问集(40张),然后分别将shot数设置为1和5进行训练和测试。
在进行D-MB实验之前,需要将蒸馏后的学生网络去掉全连接层作为元基线模型的encoder。在接下来的实验中,分别采用ResNet12,ResNet18,ResNet34,ResNet50作为元基线模型的encoder进行实验对比,挑选出性能最佳的主干网络模型。训练的基本设置为迭代20次,每个task的batch为4,学习率为0.001,权重递减1e-4,优化器选用Adam。具体的模型准确度测试结果如表4所示。

表4 D-MB模型实验结果
由上表观察可得,ResNet12在降雨云数据集上的分类效果最佳,因此本文采用ResNet12作为元基线模型的encoder。D-MB模型训练精度如图4和图5所示。

图4 ResNet12的1shot训练准确度
从图中可以看出,D-MB模型的1shot和5shot的训练精度分别可以达到57%和74.78%。
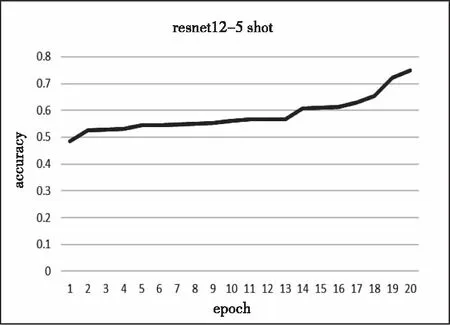
图5 ResNet12的5shot训练准确度
4.3 与目前主流的元学习模型的对比分析
目前,元学习模型方法大致可以分为基于记忆的元学习方法,基于优化的元学习方法,以及基于距离度量的元学习方法这3类。在本小节中,本文主要选择两种应用较为广泛且效果得到了学界认可的元学习模型——Prototype Network和Matching Network。在进行对比实验时,对于Prototype Network和Matching Network模型训练的基本设置均为迭代80次,采用随机梯度下降法,学习率为0.001。最后的实验对比结果如下表5所示。
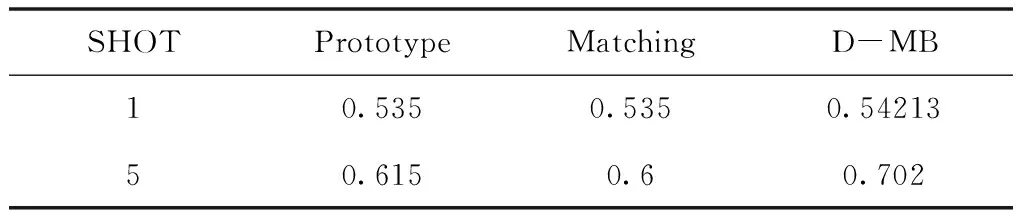
表5 元学习模型实验结果对比
从表中可以看出,本文提出的D-MB模型相比于Prototype Network和Matching Network模型在自建的降雨云数据上表现出了更高的预测准确度。
5 结语
本文根据世界气象组织提供的资料,建立了一个新的降雨云图像数据集,其中包括了6类降雨云,各类20张,共120张图片。并在此基础上提出了一种基于小样本学习的降雨云分类模型(D-MB模型),进行天气预测。整个模型分为了两个部分:分类器模型和元学习模型。其中,在分类器模型的训练过程中引入知识蒸馏的思想,使得相比于传统独立训练出的分类模型准确率要高。利用降雨云数据集训练出的元学习模型的1shot和5shot测试精度高达54.2%和70.2%。相比于目前常见的元学习分类模型拥有更好的跨域性和更高的准确性。通过各类降雨云对应的降雨信息,在一定程度上可以实现实时有效地天气预测。
