基于多尺度特征的视盘分割方法
2023-03-09曹娅迪黄文博
燕 杨, 曹娅迪, 黄文博
(长春师范大学 计算机科学与技术学院, 长春 130032)
精准分割眼底图像中的视杯和视盘是诊断眼底疾病(如青光眼)的重要因素[1-3].利用眼底图像中视盘(optic disc, OD)区域和视杯(optic cup, OC)区域的形态学变化是筛查青光眼的早期特征之一, 因此分割OD/OC区域, 并计算杯盘比(cup to dis ratio, CDR)是诊断青光眼的重要因素.OD/OC目前仍需医生手工分割, 这种方法过于依赖医生经验, 不同医生对同一病例可能有不同的判断, 不利于医疗水平较差区域的青光眼筛查.同时, 手工分割效率较低, 很难实现大规模筛查.视杯盘自动分割算法辅助青光眼诊断筛查, 相对更客观、更高效.
视杯盘自动分割算法目前主要有阈值分割方法[4]、超像素分类法[5]、水平集法[6-7]和主动形状建模法[8-9]等, 这些方法虽然可准确分割OD/OC, 但存在CDR偏小时分割误差大、需设定恰当参数、过度依赖对比度强的特征及分割效率低等问题.随着深度学习的广泛应用, 使用深度学习方法解决OD/OC分割任务的研究已备受关注.如Fu等[10]研究表明, OD/OC分割中的难点在于前背景像素不均衡, 针对该问题, 提出了视盘和视杯联合分割的深度学习方法, 首先对输入图像进行极坐标变换并采用多尺度输入, 同时对每个尺度的输入产生相应的输出, 实现对网络的深层监督, 最终将多个尺度的输出特征图拼接为最终输出.该方法充分利用了“视杯包含于视盘内”这一先验知识, 使用多标签分类, 解决了眼底图像中属于“视盘”类像素过少的问题, 实现了视盘和视杯的自动分割, 但该网络是在极坐标下进行的, 最终结果并非直接分割所得, 而是经过坐标转换后再进行圆拟合所得, 损失了分割精度;董林等[11]提出了一种端到端的基于区域的深度卷积神经网络(R-DCNN)用于视盘和视杯的自动分割, R-DCNN由残差网络(residual network, ResNet)ResNet34作为主干网络进行特征提取, 同时, 为提取更密集的特征, 在ResNet34中引入了密集原子卷积.视盘建议网络(disc proposal network, DPN)根据主干网络提取的特征, 给出多个可能的视盘区域, 并将其与经过感兴趣池化(ROI pooling)处理的特征联合, 送入分类器, 产生最终的视盘分割结果.该方法利用视盘和视杯的包含关系, 产生视盘分割结果后, 将特征图中相应区域通过盘注意力模块进行裁剪, 作为视杯分割的输入.虽然通过密集原子卷积降低了卷积池化过程中过滤的特征信息导致的影响, 但由于ROI pooling的量化误差导致了精度损失.
现有算法虽然能实现自动分割视盘、视杯, 达到辅助青光眼诊断的基本目的, 但仍存在很多不足.由于成像条件不同及个体差异会导致视盘、视杯区域颜色、大小、形状不同, 现有分割方法由于缺少丰富的感受野, 无法利用更多的尺度特征, 很难捕捉尺寸差异大的目标, 在分割时易出现欠分割问题.而多样的感受野可为网络引入丰富的上下文信息, 降低其他病变区域对视盘、视杯分割的影响.基于此, 本文提出一种基于多尺度特征的视盘分割方法, 以一种更轻型的U型网络(U-Net)——轻型U型网络(UNet-Light)[12]为主干网络.U型网络在上采样过程中将其结果与原特征图拼接, 融合更多尺度, 同时将UNet-Light与金字塔池化模块[13]相结合, 以进一步丰富感受野, 充分利用上下文信息, 使网络更好地捕捉大小不同的目标, 同时兼顾局部特征和全局特征, 增加可利用的空间信息, 从而完成视盘自动精准分割.其结构如图1所示.
1 视盘分割方法设计
1.1 U-Net
由于彩色眼底图像数据集所包含的图像数量小, 单张图像尺寸较大, 因此用原始图像作为输入会加大训练难度.U-Net[14]是全卷积神经网络(fully convolution net, FCN)的一种, 其采用Overlap-tile策略将输入图像分割为多个图像块再进行训练, 处理后再拼接多个图像块作为最终输出结果, 从而在提高分割精度的基础上加快训练速度.因此, U-Net在彩色眼底图像分割中性能优于其他方法.
U-Net主要由两部分组成: 收缩路径用于获取上下文信息; 扩张路径完成精准分割.收缩路径和扩张路径同样拥有大量的特征通道, 允许网络将上下文信息传播到更高分辨率层.因此, 两条路径呈对称状态.收缩路径通过池化操作降低特征图分辨率, 其特征提取由重复卷积完成, 每层卷积结束后对特征图进行最大池化操作, 使得在提取特征过程中特征图尺寸不断减小, 通道数增加.扩张路径则会将来自对应收缩路径的高分辨率输出和扩展路径输出进行拼接, 该过程实际上是将多尺度特征进行融合, 使网络可提取多个尺度的特征.
对于一张输入特征图, 要经过两次卷积核大小为3×3的卷积操作, 为防止出现过拟合现象并提高网络泛化能力, 在每次卷积后使用退出层, 使一定概率的神经元不再传播, 再用ReLU激活函数进行激活.对于输入的X, 若X>0, 则ReLU激活函数将保留其值;若X<0, 则将其赋值为0.计算公式为
ReLU(X)=max{0,X}.
(1)
然后对特征图进行最大池化操作, 输出特征图的宽和高将会减少至输入图像的0.5倍, 通道数增加2倍.图像将通过上述层序列多次, 直到分辨率降为合适大小.在上采样层添加2×2的上采样操作, 使其宽和高提升至原来的2倍, 并将其与对应下采样层的输出进行融合.
1.2 UNet-Light
为缩短在较大数据库中对算法进行再训练所消耗的时间, 本文引入改进的UNet-Light作为主干网络.与原始U-Net相比, UNet-Light减少了所有卷积层上的滤波器, 但用于降低分辨率的滤波器数目并未减少.从而不会降低任务的识别质量, 在参数数量和训练时间方面使体系结构变得更轻量级, 使网络模型性能得以提高.其结构如图2所示.
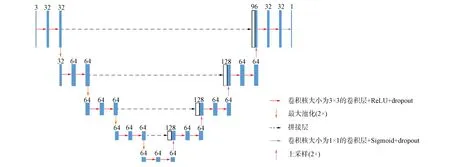
图2 UNet-Light网络结构Fig.2 UNet-Light network structure
在视盘分割任务中, 由于视盘仅占眼底图像的较小区域, 导致了前背景像素严重不均衡的问题, 训练时损失函数易陷入局部最小值, 产生更重视背景部分的网络, 前景部分常会丢失或仅被部分分割.为解决上述问题, 本文模型损失函数设计为
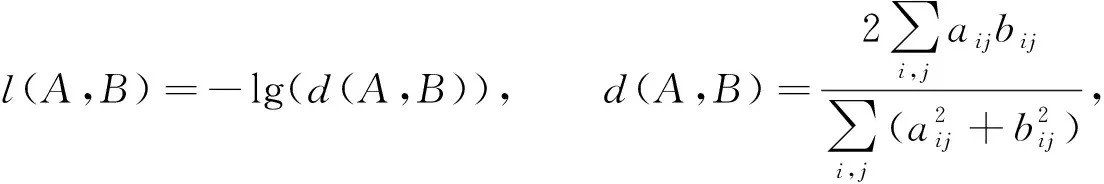
(2)
其中:A为网络输出的概率图;B为专家手工标注的真实标签, 包含每个像素及其所属的类;aij和bij分别表示A和B中的某一像素;d(A,B)是Dice损失函数[15], 取值范围为[0,1].该函数计算概率图与真实标签的相似度, 使网络不会在前景占比较小时, 为追求更小的损失将图像全部分割为背景像素, 而是更重视对前景的分割.
1.3 金字塔池化模块
眼底图像中视杯尺寸在不同患病阶段有较大差异, 针对这种变化, 本文引入如图3所示的金字塔池化模块(pyramid pooling module, PPM), 通过设计多个不同大小的感受野检测不同大小的目标, 以减少视杯大小变化导致的分割错误.同时, 金字塔池化模块也使网络获得了更丰富的多尺度特征, 这些极具区分度的多尺度特征对OD/OC精准分割至关重要.
金字塔池化模块中采用最大池化操作, 本文通过1×1,2×2,4×4和8×8四个不同大小的感受野收集特征图的上下文信息并对其编码, 池化后得到4个不同大小的特征图.对每个特征图进行1×1的卷积操作, 将其通道数降为一维, 以减少计算权重产生的消耗.为将池化结果聚合, 先使用双线性差值方法对其进行上采样操作, 池化后大小不一的特征图被扩张至原始特征图大小, 并与原始特征图进行拼接.最后, 对拼接的特征图采用1×1卷积操作, 将通道数恢复至原特征图大小, 最终的输出特征图尺寸与输入特征图尺寸相同.
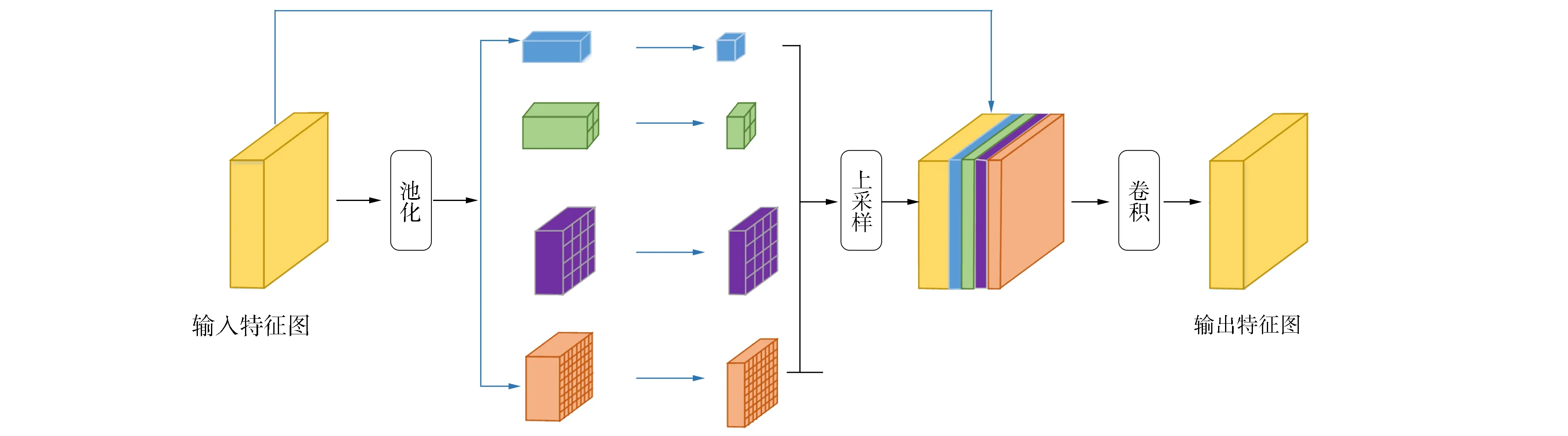
图3 本文金字塔池化模块Fig.3 Proposed pyramid pooling module
若输入特征图F, 则产生最终特征图的过程如下:
其中MaxPooln×n表示卷积核大小为n×n的最大池化操作, Conv1×1表示卷积核大小为1×1的卷积操作, UpSamble表示上采样操作, ⊕表示对不同尺度的特征图进行链接,P为最终输出的特征图.
2 实 验
2.1 数据集图像预处理
在公开彩色眼底视盘、视杯分割数据集RIM-ONE v.3[16]中, 利用本文方法在视盘、视杯分割任务中进行多组对比实验, 以验证本文方法的性能及泛化能力.数据集RIM-ONE v.3由159张彩色视网膜图像组成, 分为健康眼、青光眼和疑似青光眼两类.每张图像的视盘和视杯均由眼科专家进行分割, 作为分割标准.
在进行网络模型训练前, 先对输入图像做预处理.预处理采用对比度受限自适应直方图均衡化(contrast limited adaptive histogram equalization, CLAHE)方法以增强对比度, 避免放大噪声及图像失真.CLAHE方法将眼底图像分为多个子域, 对每个子域分别进行直方图均衡化, 同时限制每个子域的对比度.设对比度阈值为T, 对原始直方图高度超过T的部分从顶部开始裁剪, 为保证整个直方图最终面积不变, 将裁剪掉的部分均匀地分布在整个像素范围内, 使整个直方图上升L, 最大值为T+L, 重复该过程直到L可忽略不计.CLAHE方法表达式为
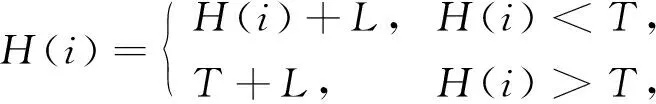
(4)
其中H(i)表示直方图在i处的高度.
均衡后采用双线性插值法消除子域边界产生的伪影.设均衡后的图像为f(x,y), (xi,yi)为其中某像素点, (xi,yi)在原图像中最邻近的4个像素点为Q11=(xi,yi),Q12=(x1,y2),Q21=(x2,y1),Q22=(x2,y2),f(x,y)在这些像素点的值已知, 则双线性插值结果为
为防止过拟合, 还需对图像进行随机缩放、随机水平偏移、随机垂直偏移和随机旋转等预处理操作.
2.2 评估标准
本文采用Dice系数、平均交并比(mean intersection over union, MIoU)和均方误差(mean square error, MSE)作为算法评估标准.
Dice系数用于计算预测结果与真实标签的相似度, 公式为
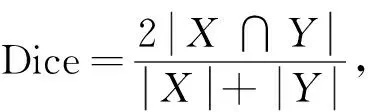
(6)
其中X是真实标签图像,Y是预测结果图像.平均交并比MIoU用于计算预测结果与真实标签的交并比, 公式为
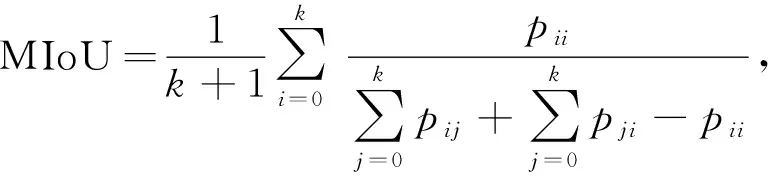
(7)
其中k为类别数量, 本文k=1,i表示前景类,j表示背景类,pij为将前景分割为背景的概率.均方误差MSE用于计算预测结果与真实标签的偏差程度, 其值越小, 分割性能越好, 公式为
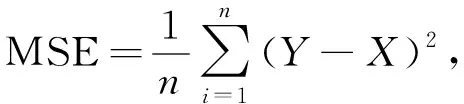
(8)
其中X为真实标签图像,Y为预测结果图像,n为图像包含像素的数量.
2.3 实验结果与分析
本文方法与其他方法对比实验结果列表1.由表1可见, 本文方法的平均交并比MIoU由0.896提升至0.908, Dice系数由0.951提升至0.958, 均方误差MSE则降低了0.001, 证明了本文方法的有效性.

表1 不同方法在数据集RIM-ONE v.3上的对比结果
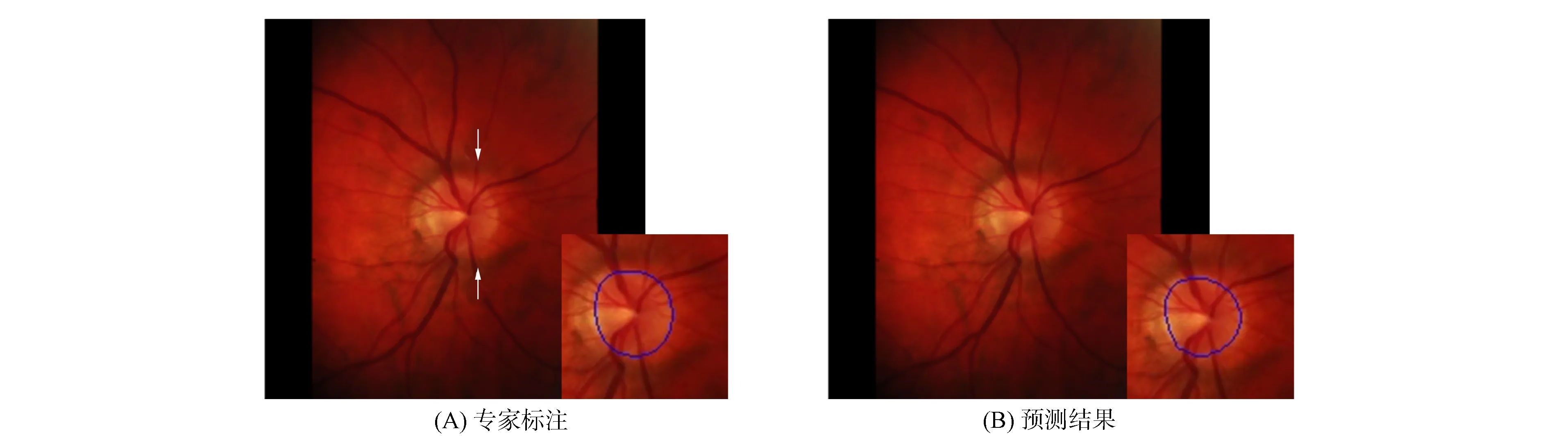
图4 视盘分割示例Fig.4 Examples of OD segmentation
眼底图像采集光照不均及眼底病变和渗出物的干扰都会加大视盘分割难度, 图4为视盘分割示例.由图4可见, 视盘左侧边界不清晰, 且箭头所指处存在阴影, 被阴影包围区域与阴影产生明暗对比.若算法仅关注局部特征, 则很容易误认为阴影中全是视盘, 导致误分割.由于本文方法兼顾了全局与局部特征信息, 因此在边界模糊且有阴影干扰的情况下, 仍实现了视盘区域精准分割.
视杯包含在视盘内部, 基于该先验知识, 本文在进行视杯分割前先根据视盘分割结果对眼底图像进行裁剪.图5为一个视杯分割示例.图5(A)为数据集中的原始图像和经过裁剪后的输入图像, 由图5(A)可见, 视杯和视盘拥有极相似的特征, 很难区分.同时, 视盘中心汇聚的大量血管结构也对视杯分割产生干扰, 增加了分割难度.由图5(B),(C)可见, 本文方法实现了视杯区域精准分割, 验证了本文网络模型的特征提取能力.图6和图7展示了更多的可视化结果, 验证了本文方法准确率不受目标大小变化的影响.
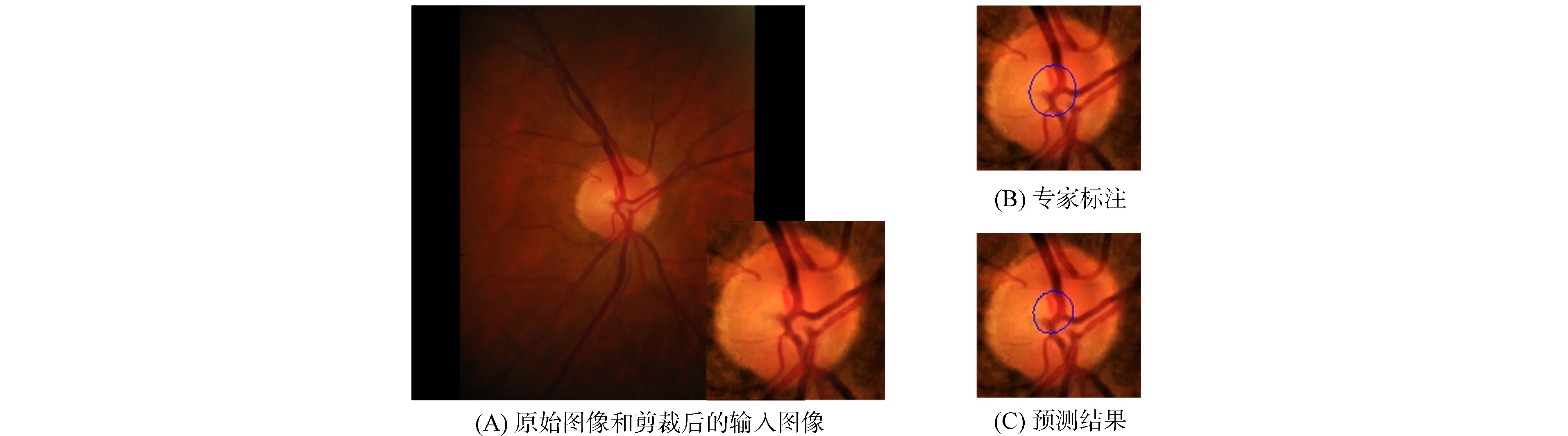
图5 视杯分割示例Fig.5 Examples of OC segmentation
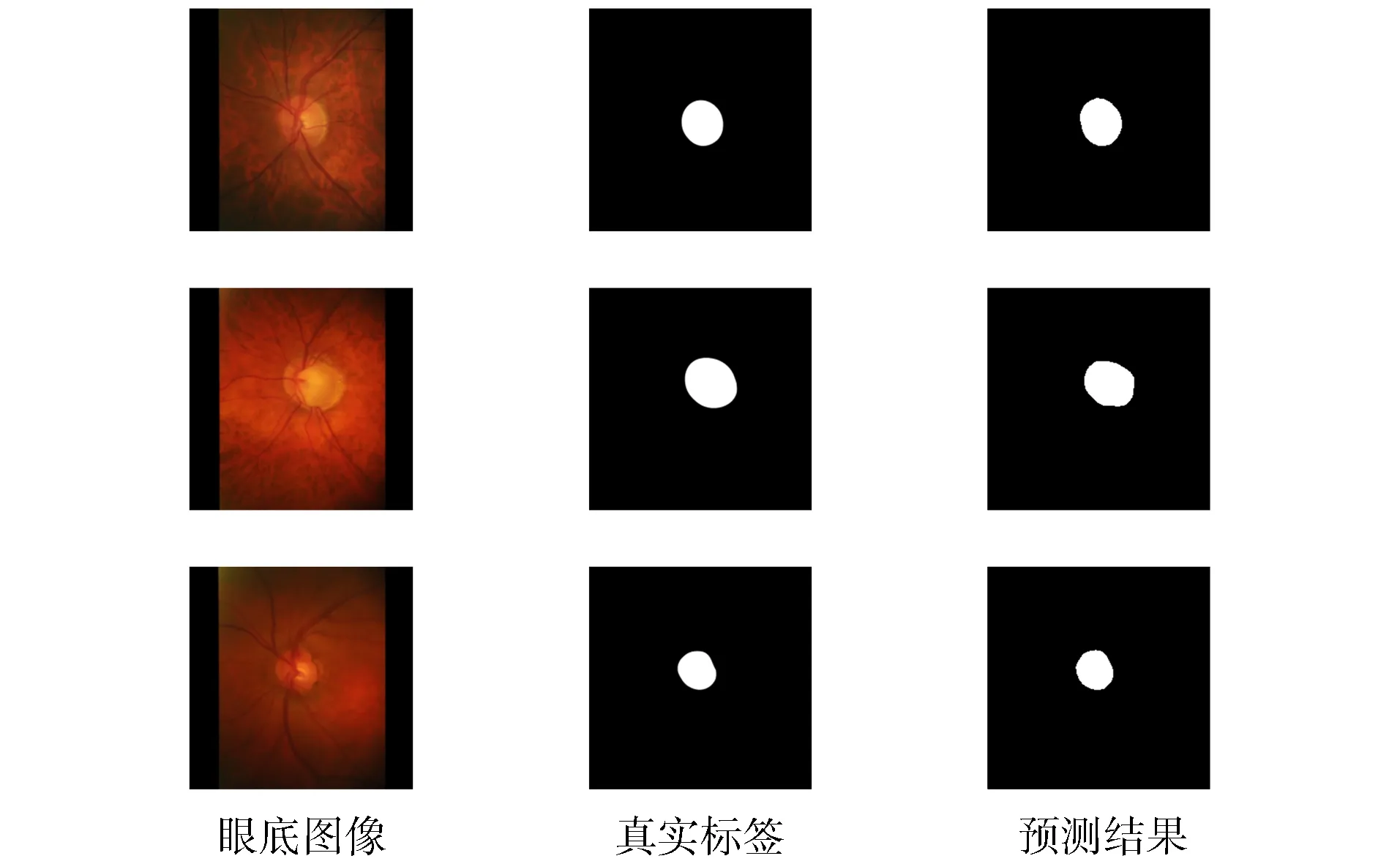
图6 视盘分割在数据集RIM-ONE v.3上的结果Fig.6 Results of OD segmentation on RIM-ONE v.3 dataset
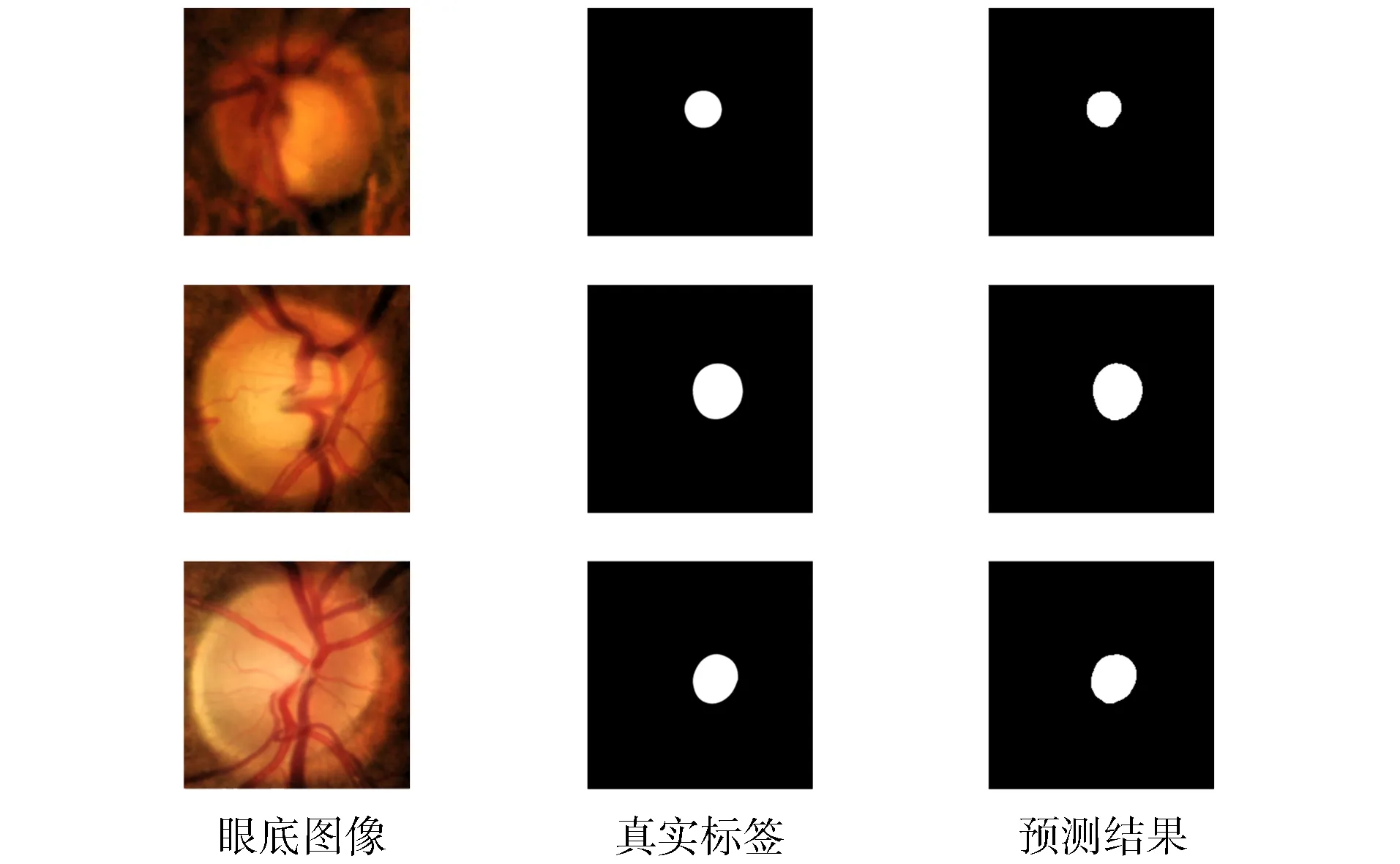
图7 视杯分割在数据集RIM-ONE v.3上的结果Fig.7 Results of OC segmentation on RIM-ONE v.3 dataset
综上所述, 本文以UNet-Light作为主干网络, 通过在其中加入金字塔池化模块, 降低病变等噪声对视盘和视杯分割的干扰, 丰富多尺度特征, 有效提高了网络特征的提取能力, 使网络在分割时不受目标大小形状变化的影响.针对视盘和视杯分割两个任务, 在公开数据集RIM-ONE v.3上进行了多组对比实验, 结果表明, 本文方法在两个任务中的分割精度均优于原始网络, 且在处理病变区域、视杯特征不明显等分割困难区域, 比现有算法各项指标均有显著提高.
