基于改进SqueezeNet模型的多品种茶树叶片分类方法
2023-03-07孙道宗刘锦源谢家兴王卫星
孙道宗 丁 郑 刘锦源 刘 欢 谢家兴 王卫星
(1.华南农业大学电子工程学院(人工智能学院),广州 510642;2.广东省农情信息监测工程技术研究中心,广州 510642)
0 引言
据中国农业科学院茶叶研究所数据统计,茶叶饮品已经成为消费量仅次于水的一类世界性饮品[1]。中国是世界茶树的原产地[2],是茶叶生产国和消费国[3],亦是茶叶出口大国。国际茶叶委员会[4]统计显示,2019年中国茶叶产量为2.799×106t,居世界第一,出口3.67×105t,居世界第二。在长期制茶过程中,我国产生了众多茶叶品种,其中一些品种是同一种茶树的不同变种,外观差异极小,使茶叶的分类识别复杂化,传统的感官审评方法采用的审评术语并不完善[5]。因此,目前对于茶叶的分类识别主要依赖于专业人员的观察和对成品茶的品鉴来分类,流程复杂,需要较高人力成本,同时还存在较大的主观因素影响,导致一致性差、差错率高、量化难[6];寻找一种可以高效无损地识别茶树叶片种类的方法是我国茶产业发展需要解决的重要问题之一[7]。
在茶叶生产领域,光谱学、数字图像处理等技术的研究和应用逐渐增多。CHEN等[8]利用VGG-16模型和自编码网络获取多光谱特征实现对新鲜茶芽成熟度的估计。徐向君等[9]基于激光诱导击穿光谱(Laser-induced breakdown spectroscopy, LIBS)技术,结合主成分分析提取特征量并利用支持向量机进行建模。陈辉煌等[10]采集9种鲜茶叶数据,通过预处理计算24种光谱指数,用SVM-RFE选择特征,最后将线性SVM和随机森林分类效果进行比较。通过光谱获取特征虽然可以用于分类,但是存在局限性,如相关仪器及操作繁琐复杂、成本较高等,不利于在农业领域推广应用。因此具有精度高、效率高、无需接触且成本较低等优点的机器视觉技术被逐渐应用于农产品分类识别中[11],成为农业分类识别的热门研究方向。方敏等[12]利用数字图像处理技术将提取的茶叶图像频谱特征作为支持向量机的输入,建立茶叶种类自动识别模型。孙丽萍等[13]将树木叶片的特征融合后作为分类依据,采用深度信念网络进行训练、识别和分类。上述方法虽然结果精度不低,但是需要人为提取特征,只支持有限参数量,设计的模型在鲁棒性方面不理想,在大数据时代,人工提取数据特征的方式已逐渐被取代[14]。卷积神经网络(Convolutional neural networks, CNN)作为图像分类算法的重要分支,具有识别精度高、检测速度快等优点,并自动提取和学习特征,近年来在各个领域的分类、检测等方面广泛应用。文献[15-19]采用的深度学习模型虽然在各自研究领域的分类效果显著,但是存在网络模型结构复杂、参数庞大、运算量要求高等不足,受限于内存开销小、计算资源有限等问题,不利于实际应用。而且目前卷积神经网络用于茶叶分类的研究主要集中于熟茶的分类和鲜叶的芽叶品级分选[20],对于鲜叶种类的识别较少。本文将在前人研究的基础上进一步探索茶树叶片识别卷积网络模型的轻量化研究。基于SqueezeNet卷积神经网络,通过对网络架构进行分析,结合改进和优化步骤构建一个能够区分6种茶树叶片的深度学习模型,旨在开发一种高效、精确、客观、轻量的鉴别模型,实现对复杂背景和环境下茶树叶片的分类,实现多人多设备实时使用,同时应用于资源受限的嵌入式实时系统。
1 数据集构建与分类方法
1.1 试验材料
于2021年6—10月对广东省广州市柯木塱农业技术推广中心种植的6种成熟茶树,分别在白天光照充足和阴雨天气的环境条件下使用iPhone11手机自带相机拍摄复杂背景下的茶树叶片图像,主摄像头为索尼IMX503型(1 200万像素)。
拍摄的数据集由铁观音、黄枝香、英红九号、老仙翁、鸡笼刊和鸭屎香6种不同茶树叶片所构成,其中每个种类的图像包含茶树单片成熟叶片、芽叶和多叶片树枝,各个种类的图像为200幅。该数据集茶树叶片包括不同亮度、背景、角度图像,较好地还原了茶树叶片在种植环境中的实际场景,能更好地训练模型和证明模型的泛化能力,具有更强的适用性。
1.2 分类方法
1.2.1数据预处理
深度学习属于监督学习,与传统计算机视觉方法不同,是使用卷积神经网络通过数据驱动使模型自动学习特征,不需要借助人工手段提取和筛选特征。由于卷积神经网络包含大量参数,所以存在过拟合的风险。因此,对于卷积神经网络需要提供大量的样本数据进行训练,避免网络出现过拟合问题。由于本研究所获取的原始数据集只有1 200幅图像,无法满足卷积网络的训练学习要求,为了避免出现过拟合问题,提高网络模型的鲁棒性,本文对现有数据集进行数据增强来扩大训练数据集。
将数据集进行数据增强,增强方法包括水平镜像翻转、随机旋转、增加高斯噪声和改变图像对比度等。将增强后数据集按4∶1的比例划分为训练集和测试集,其中训练集每种茶树叶片图像数量为800幅,剩余图像为测试集。经过划分后的训练集图像数量达到4 800幅。图1为不同茶树叶片增强前后的图像对比,从左到右的4幅图像分别进行了水平镜像翻转、改变图像对比度、增加高斯噪声、随机旋转处理。

图1 数据增强前后对比
1.2.2经典SqueezeNet模型
近年来硬件的快速升级,推动了深度学习的蓬勃发展,研究者对卷积神经网络的层数不断增加,同时残差网络等技术的出现更是让卷积神经网络的层数进一步上升,从经典的7层卷积神经网络AlexNet逐渐发展到现在152层的ResNet网络,甚至出现上千层的复杂网络,网络的识别、检测性能确实得到了显著提高,但是效率却受到影响[21]。在效率上,过于复杂的网络所包含的参数量过大,在模型的预测计算中导致计算缓慢,这些问题会导致所研究的网络无法被广泛应用到资源有限的实际环境中。当前存在两种研究方向解决网络复杂化的问题,一是对复杂模型的简化,主要是将训练好的模型进行压缩,减少模型所包含的参数,从而解决内存和计算速度的问题;二是通过设计更高效的“网络计算方式”从而使网络参数减少的同时不过多损失网络性能,本文所改进的网络模型SqueezeNet就是通过设计高效计算方式而创造出轻量级卷积网络,该试验在经典SqueezeNet模型基础上进行改进,以实现网络模型轻量化的同时保证茶树叶片分类的准确度。
SqueezeNet模型是2016年由IANDOLA等[22]提出的一个轻量型网络模型,能在保证识别精度的同时,将原始的AlexNet参数压缩至原来的1/50左右,使模型内存占用量只有4.8 MB。Fire模块是SqueezeNet模型的核心构件,如图2所示,该模块由一个Squeeze层和一个Expand层构成,其中C和S分别表示Squeeze层的输入和输出通道数,E1和E2分别表示Expand层中1×1和3×3卷积核的输出通道数。

图2 Fire模块结构
由图2可知,Squeeze层通过1×1的卷积核对输入张量进行压缩,把输入通道数从C减小到S,目的就是通过降低通道数减少网络的计算量;Expand层包含1×1和3×3两种卷积核,分别将Squeeze层输入的S通道数扩张成E1和E2,然后将2种卷积核卷积所得特征图进行拼接,最终输出通道数为E1+E2的特征图。
为引入非线性并使深度学习模型产生强大的表示能力,模型中在每个卷积层后都添加了线性整流函数(Rectified linear unit, ReLU)。为了避免网络过拟合,对全连接层引入了随机失活(Dropout),即在网络前向传播时,让部分神经元的激活值以一定的概率停止工作,这样可以使模型泛化性更强。
1.2.3SqueezeNet模型改进设计
1.2.3.1批归一化算法
由于输入每个批次的图像数据可能存在分布广泛、随机性大的问题,导致训练出现波动大和收敛慢,因此在网络中添加批归一化(Batch normalization, BN)[23]处理,算法过程如下[24]:首先计算每个批次n个样本的均值μ与方差σ,然后再将数据归一化,得到均值为0、方差为1的数据。为避免数据归一化破坏特征分布,需要通过重构变换来恢复原始的特征分布。
(1)
yi=γii+βi
(2)

(3)
βi=E[xi]
(4)
xi——样本值
yi——尺度变换和偏移后样本值
γi——尺度变换值βi——偏移值
Var——方差函数
E——均值函数
可以发现当式(3)、(4)成立时,重构变换能够完全复原原始数据。通过对Fire模块的Squeeze层和Expand层的输出进行批归一化处理,实现对SqueezeNet的改进。
1.2.3.2深度可分离卷积
通过采用深度可分离卷积操作替代标准卷积操作,既能保证模型的性能,同时还可以大幅降低网络的参数量。因此,深度可分离卷积的出现,对研究轻量型卷积网络具有里程碑意义[25]。深度可分离卷积就是将标准卷积操作划分为逐通道卷积和逐点卷积[26]。
标准卷积操作如图3所示,由于上一层一般具有多个通道,因此在卷积时一个滤波器必须具有对应通道数的卷积核,因此一次卷积操作是多个卷积核与上一层对应通道的特征图进行卷积后再相加;若同时需要得到多个通道的特征图,则需要对应该通道数的滤波器。

图3 标准卷积
由图4可知,深度可分离卷积就是将需要卷积操作的特征图拆分通道数,然后进行单通道卷积再堆叠(逐通道卷积),然后将所得特征图用与上一层通道数相同的1×1卷积核组成的滤波器进行卷积,滤波器数与生成特征图通道数相同(逐点卷积)。该试验将SqueezeNet模型中Fire模块Exapnd层的3×3标准卷积核替换为深度可分离卷积,降低网络的参数量,以实现网络轻量化的目标。

图4 深度可分离卷积
1.2.3.3注意力机制
由于该试验的主要研究方向是基于卷积神经网络的多品种茶树叶片分类,茶树叶片图像在获取深层特征时会存在一定的特征冗余,同时受限于模型规模和复杂背景的限制和影响,因此模型的分类性能会受到影响。因此试验尝试将注意力机制[27]引入到网络中,实现对特征信息进行选择。注意力机制模仿人的视觉注意力模式,每次只关注与当前任务最相关的目标信息,能够强化重要信息和抑制非重要信息,同时注意力机制可以缓解卷积神经网络传统卷积操作的局部感受野因缺乏全局信息层次的理解能力而导致特征差异性的问题,提升网络的特征提取能力。
Fire模块中引入的注意力模块如图5所示,通过将通道注意力和空间注意力串行组成,其中通道注意力机制主要聚焦于有意义的特征,而空间注意力主要聚焦于输入图像有效信息丰富的部分,特征提取器提取的特征向量先输入通道注意力模块,根据各通道的重要程度得到通道权重矩阵并将矩阵输入空间注意力模块,获得空间权重矩阵,再经过训练后,注意力模块可以从输入特征图中“裁剪”出特征信息更精细的特征图以提升分类性能,最终改进的Fire模块如图6所示。

图5 注意力模块

图6 改进Fire模块结构
2 模型训练
2.1 试验平台
试验平台由计算机硬件和开发平台两部分组成。计算机硬件配置为AMD锐龙5800H CPU,16 GB内存,RTX3060显卡。开发平台为Windows 10 操作系统上的Pytorch深度学习框架,编程语言为Python。
2.2 超参数选取
采用批量训练的方法将训练集与测试集分为多个批次(Batch size),通过对比后选择每个批次训练8幅图像。遍历一次训练集中的所有图像作为一次迭代(Epoch),经试验后可知模型迭代130次网络损失值已经收敛至平稳阶段,因此将迭代次数设置为130。采用随机梯度下降(Stochastic gradient descent, SGD)算法优化模型,通过比较后选择设置学习率为固定学习率0.01,为防止过拟合将权值衰减(Weight decay)设置为1×10-5。
2.3 模型评价指标
因为本文研究目的之一是实现模型的轻量化,所以模型将参数量和浮点运算量作为模型的评价指标之一,试验统一采用开源的Python包thop计算改进模型和对比模型输入单幅图像的参数量和浮点运算量。测试集的分类速度也是衡量模型性能的指标,用平均单幅图像分类消耗时间作为分类速度指标。该试验通过计算各模型在测试集的分类时间来比较模型的分类效率。
此外,衡量模型性能的指标还包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值(F1 score)。
3 结果与分析
3.1 改进网络模型对比
试验属于单变量试验,改进模型的训练均在同一平台环境下完成,在训练完成后通过对比模型在测试集的准确率和参数量对改进效果进行分析。
图7为SqueezeNet模型和改进后模型在训练集上的损失值和在测试集上的准确率随迭代次数变化曲线,其中损失值每20个迭代周期输出一次,准确率每1个迭代周期输出一次。SqueezeNet_bn是增加批归一化处理后的改进模型,SqueezeNet_bn_dw是将第1次改进模型中Fire模块的3×3标准卷积替换为深度可分离卷积后的改进模型,SqueezeNet_a_bn_dw是在每个Fire模块中引入注意力机制后的最终改进模型。从图7可以看出,SqueezeNet模型从训练开始在训练集上的损失值出现较大波动,并且损失值的收敛速度最慢,这是由于不同批次茶树叶片图像的数据分布差异较大,每一个批次训练都需要大幅调整参数,之后损失值下降速度相较于改进后模型也较慢,反映在测试集上的准确率也在初始时出现较大波动,迭代130次后准确率只有82.8%,低于改进后的3个模型。
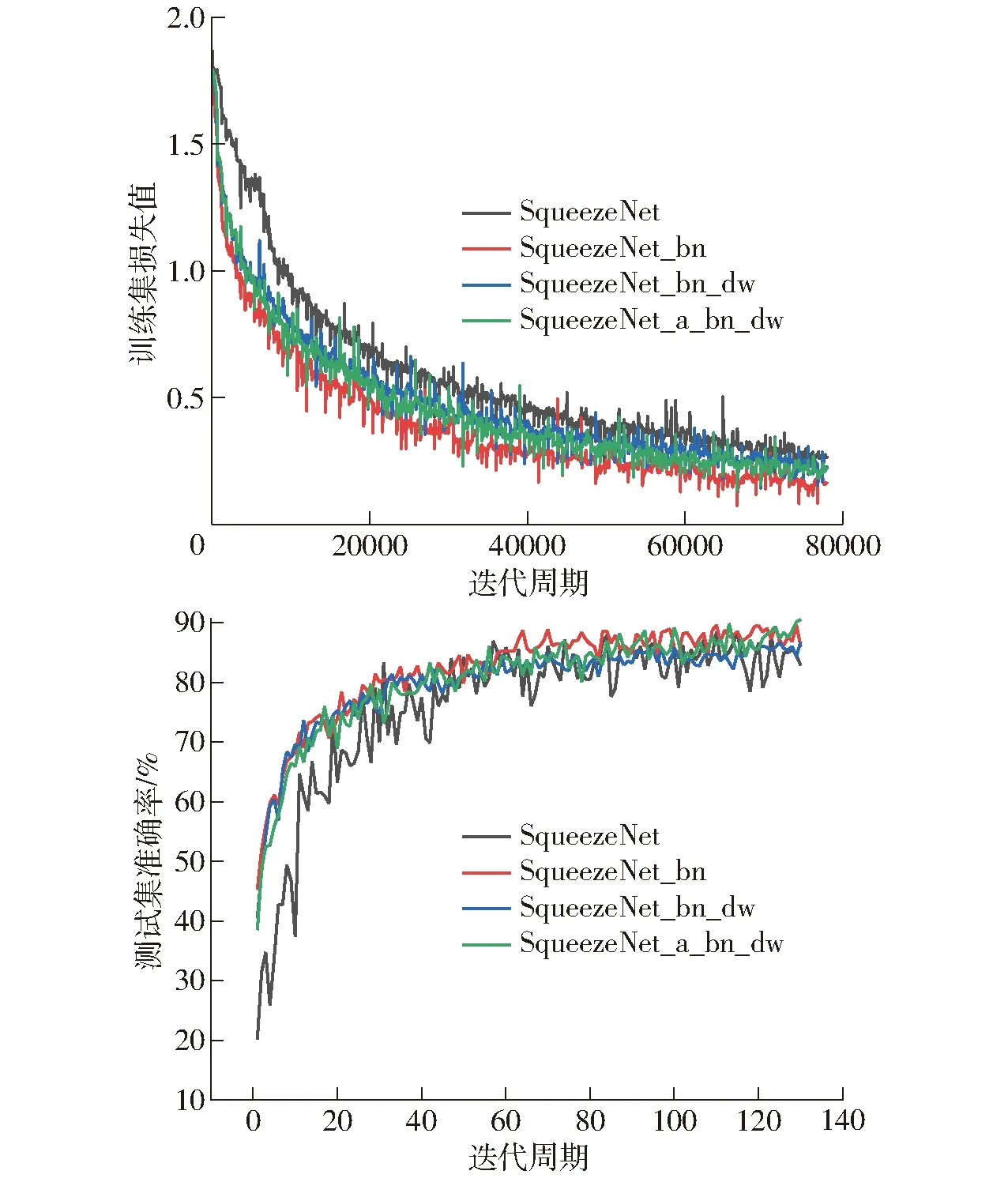
图7 训练集损失值和测试集准确率变化曲线
由图7可知,通过增加批归一化处理,使得每个批次的图像数据分布统一,改进模型SqueezeNet_bn在训练集上的损失值相较于原始模型没有显著波动,并且逐渐收敛,经过130次的迭代训练已经下降至0.16左右,测试集的准确率曲线在60个迭代周期后基本稳定在改进模型中的最高值,最终准确率达到86.0%,相较于原始网络,茶树叶片分类效果显著提升。
为了研究模型的轻量化,将Fire模块中Expand层的3×3卷积核替换成深度可分离卷积,在确保精度的前提下,实现网络的进一步轻量化。可以从图中看出,第2次改进的模型在6种茶树叶片的分类训练中损失值和准确率的变化和未替换深度可分离卷积的模型相似,深度可分离卷积可以保证在该模型性能没有显著变化的前提下实现模型参数的下降。为了保证模型分类性能的进一步提升,试验对模型进行了第3次改进,引入注意力机制,从图7中可以发现添加注意力机制后模型在训练集上的损失值收敛速度优于原始模型SqueezeNet和第2次改进模型SqueezeNet_bn_dw,仅次于第1次改进模型SqueezeNet_bn,同时在测试集的分类准确率上相较于第2次改进模型有一定提升。
从表1可以看出,经过130次迭代训练后的改进模型SqueezeNet_a_bn_dw在测试集的准确率为90.5%,为4种模型中最高,相较于原始模型SqueezeNet,测试集准确率提升7.7个百分点,参数量减少3.56×105;而相较于第2次改进模型SqueezeNet_bn_dw,测试集准确率提升3.7个百分点,参数量仅增加1.23×105,实际分类速度也与改进前基本相同,在没有明显提升模型部署资源需求的同时提升了轻量化模型的性能。由表1可知,SqueezeNet_a_bn_dw模型的综合性能优于对比模型。

表1 改进模型效果对比
3.2 不同网络模型对比
表2为改进模型(SqueezeNet_a_bn_dw)和4种经典卷积神经网络模型在6种茶树叶片数据集上经过130次迭代训练后的分类效果对比,训练软硬件平台和超参数选取均保持一致。从表2中可以看出,同样是轻量化网络的MobilenetV3_Small[28],分类效果和轻量化表现都明显优于未改进的SqueezeNet网络,但是相较于SqueezeNet_a_bn_dw模型在分类准确率和参数量上都存在差距,其在测试集上的准确率仅有86.9%,在实际分类速度方面也明显慢于SqueezeNet_a_bn_dw模型。ShuffleNetV2[29]同样也是为在移动设备上运行而设计的轻量化网络,其表现同样优于SqueezeNet,但是落后于SqueezeNet_a_bn_dw,仅在测试集的平均分类速度上有极小的领先。经典网络AlexNet[30]的效果一般,在测试集的准确率为88.4%,参数量高达5.702 8×107,测试集的分类速度为0.099 s/幅,在实际茶树叶片分类应用中准确率、模型参数量和分类速度均不及ResNet18[31]和SqueezeNet_a_bn_dw。ResNet18在测试集准确率上最高,达到92.3%,高于改进模型1.8个百分点,但是本试验所研究的SqueezeNet_a_bn_dw所需参数量仅有3.69×105,远低于ResNet18的1.117 2×107,测试集平均分类速度也仅为0.109 s/幅,综合准确率、模型大小和分类速度3个指标来看,SqueezeNet_a_bn_dw模型在实际部署和应用中优于ResNet18模型。

表2 不同模型效果对比
3.3 种类识别结果可视化分析
对网络模型在测试集上的识别结果进行混淆矩阵分析,如图8所示。从图8可以看出,预测分类的最大值都在对角线上,可以验证改进模型对茶树叶片分类可行性。根据混淆矩阵可以计算出改进模型在各品种茶树叶片的准确率、召回率和F1值3个指标,如表3所示。
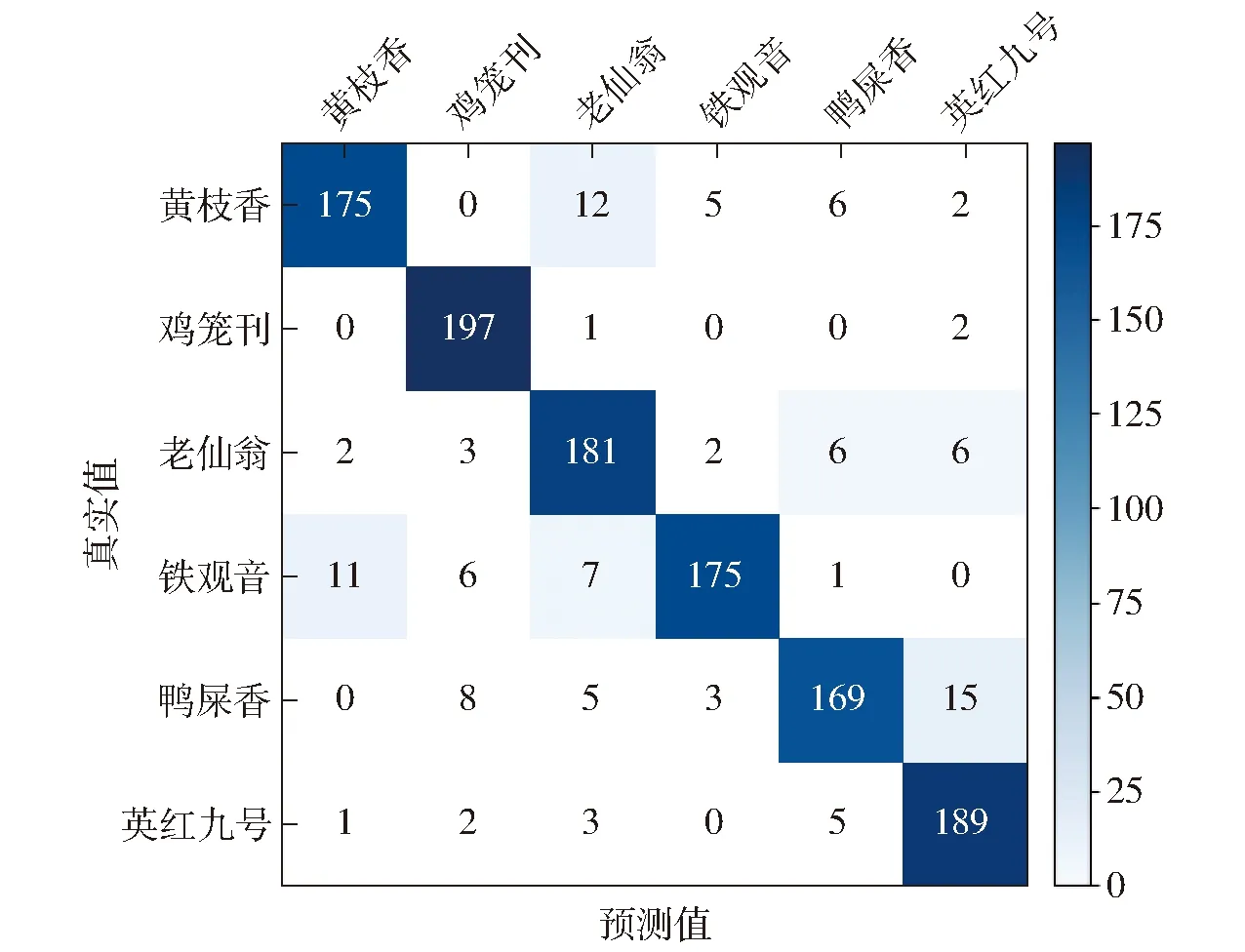
图8 测试集混淆矩阵
由表3可知,本文模型在茶树叶片测试集上的准确率、召回率和F1值都比较高。但是从准确率可以发现,模型将其它品种茶树叶片识别为英红九号和老仙翁的可能性相对明显。此外,对鸭屎香的分类效果存在一定偏差,召回率较低,从图8可知,本文模型将鸭屎香图像误分为鸡笼刊和英红九号较多,该现象可能是由于鸭屎香与鸡笼刊、英红九号的特征如颜色、纹理和形状等出现了混淆,也可能是由拍摄、光照以及复杂背景的影响造成。虽然存在一定的误分类问题,但是模型测试集的整体分类准确率达到90.5%,且各类茶树叶片分类结果的F1值保持在90%左右,说明模型分类性能较好,能够适用于复杂背景下多品种茶树叶片分类识别。
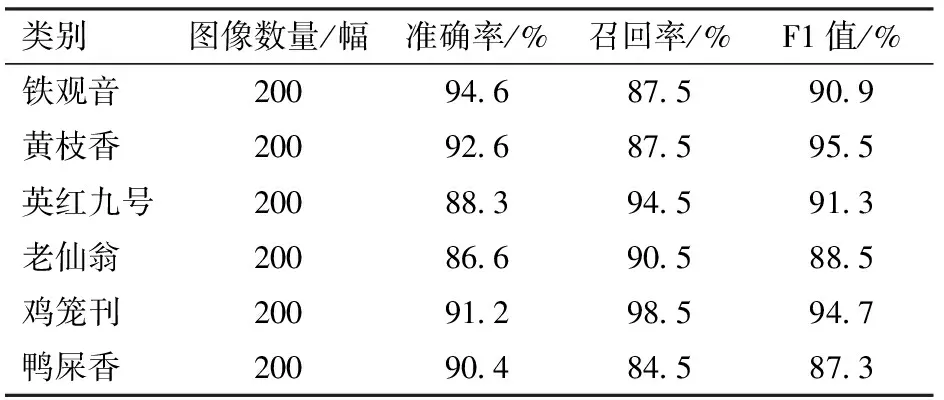
表3 茶树叶片分类测试试验结果
3.4 改进模型可视化分析
类激活图(Class activation map, CAM)有助于分析卷积神经网络做出最终分类决策的依据,反映图像不同位置对该类别的权重。图9以铁观音(上图)和老仙翁(下图)图像为例,通过类激活热力图可视化比较注意力机制的改进效果。

图9 热力图
图9分别展示了SqueezeNet_bn_dw和SqueezeNet_a_bn_dw模型在最后一层卷积层的决策依据,通过比较可以发现,未添加注意力机制的模型在对铁观音和老仙翁的分类决策中受到较严重的背景影响,尤其对铁观音图像中叶片的有效特征提取效果极差,对主要叶片几乎没有关注。而通过引入注意力模块,模型对图像有效信息的提取更加准确,受到复杂背景信息的影响更小,决策影响重心都与中心叶片明显关联,显著提升模型的决策可行性,与改进目的和试验结果相符合。
4 结论
(1)在单次验证方法下,选用包含复杂背景和天气环境的茶树叶片图像数据集,经过数据增强后对改进SqueezeNet模型进行训练,通过比较确定超参数,学习率为0.01、批量大小为8;对茶树叶片的分类准确率可达到90.5%,相比经典SqueezeNet模型提高7.7个百分点,模型参数量下降到3.69×105,比经典SqueezeNet模型减少49.1%,同时改进后模型的计算量减少59.2%。
(2)通过和其他经典网络对比,AlexNet和ResNet18在本文试验条件下分类准确率分别为88.4%和92.3%,测试集分类速度分别为0.099 s/幅和0.183 s/幅,参数量分别为5.702 8×107和1.117 2×107,比较分析可以得到本文模型基本与其他经典高精度网络保持同一水平的情况下,对参数内存的需求有显著优势;同为经典轻量化模型的MobilenetV3_Small和ShuffleNetv2,在参数量和茶树叶片的分类准确率两个标准下均明显优于经典SqueezeNet,但是不及改进后的SqueezeNet_a_bn_dw模型。
(3)改进SqueezeNet模型较好地平衡了参数内存需求、网络准确率和分类速度3个指标,在大幅减少模型参数内存要求和模型计算量的同时使模型的性能提升到了一个较高的水平,这有利于将卷积神经网络模型部署在移动终端等嵌入式资源受限设备上,有助于实现对茶树叶片的实时准确识别,为茶树种类的识别提供了一个简洁高效的方法,也为深度学习在茶叶领域的进一步应用奠定了基础。
