农作物遥感识别与单产估算研究综述
2023-03-07赵龙才李粉玲常庆瑞
赵龙才 李粉玲 常庆瑞
(西北农林科技大学资源环境学院,陕西杨凌 712100)
0 引言
粮食安全的首要关注点是粮食播种面积与产量。对农作物生长状态的实时动态监测与产量信息的快速准确把握,不仅对于国家粮食安全相关政策决策的制定、市场价格宏观调控、农村经济发展、以及对外粮食贸易等具有重要价值,同时还对农田生产的智能化管理、农业保险的精准服务等具有现实意义。
遥感技术凭借其快速、宏观、无损以及客观等特点,在快速获取与解析作物类型、种植面积、产量、长势、灾害等信息方面具有独特优势。农作物遥感识别是实现农田作物信息提取和解析的前提与基础,在一定程度上决定和影响其它信息解析的可行性和准确性,因此农作物遥感识别的精度和效率是农业遥感关注的核心问题之一。其次,基于遥感的作物单产估算已经成为获取大区域尺度粮食产量信息的重要方式,对分析国家粮食安全形势等具有重要作用,也是农业遥感的重要研究内容之一。本文从农作物遥感识别与农作物单产估算两方面进行总结,系统分析发展现状、存在的问题及未来发展方向。
1 农作物遥感识别研究
农作物遥感识别主要以监督学习为主,其基本过程是以遥感影像所表达出的不同作物的特征分布模式为基础,利用分类算法对特征分布模式进行判别,从而实现作物类型识别(图1)。因此,分类算法和遥感识别特征是农作物遥感识别的两个决定性组成部分。其中,识别特征是表达类别间差异的媒介,其决定了不同作物间的可分离性的理论上限,识别算法则是在最大程度上识别这种特征分布差异并逼近该理论上限。因此,对于农作物遥感识别精度而言,识别特征相较于识别算法具有更重要的地位。本文分别从遥感识别特征与识别算法两方面对农作物遥感识别进行总结。

图1 农作物遥感识别基本流程图
1.1 作物遥感识别特征研究
1.1.1光谱特征研究
不同作物的植株形态、冠层结构、生理生化特性等导致其在不同光谱波段上具有不同的光谱反射特性,从而使得光谱特征具备区分不同的农作物的能力,也是农作物遥感分类应用最广泛和最基本的识别特征。
(1)多光谱特征
利用多光谱特征进行农作遥感识别是农业遥感领域的基础应用之一,基于光谱特征的植被类型自动分类技术最早可以追溯到1970年。最初的基于多光谱特征的农作物遥感分类以目视解译为主,即解译人员凭借影像上所表现出的亮度、色调、空间位置、几何结构与形状,亮度明暗变化所形成的纹理等特征识别农作物类别。从参与农作物遥感识别的多光谱特征种类来看,多光谱特征的发展和应用与多光谱卫星传感器的发展高度相关,最典型的特征组合是3个可见光波段(蓝、绿、红)与近红外波段的组合;随着多光谱传感器加入红边波段、短波红外波段,红边及短波红外特征在农业遥感监测与识别中应用越来越广泛。基于光谱特征识别的作物类型基本涵盖了所有主要粮食作物,例如小麦、水稻、玉米、大豆、棉花、甘蔗及其他经济作物[1-5]。
由于“同物异谱、异物同谱”现象的广泛存在,直接使用多光谱特征进行遥感识别的精度越来越不能满足现实需要。在此背景下,大量由人工知识参与的遥感植被指数特征被设计出来,它们通常是基于两个或两个以上的原始光谱特征进行特定的数学变换而得到。遥感植被指数通常综合两个及两个以上的原始光谱特征,可以反映植被在某一方面的特性从而对农作物遥感识别表现出更加重要的作用。例如归一化植被指数(NDVI)和绿度植被指数(VI green)经常被用于农情遥感监测,即监测农作物长势和生长过程[6];土壤调整型植被指数(SAVI)可以在缓解土壤背景影响的基础上有效提高对不同作物的识别精度[7]。目前,常用的遥感植被指数已经发展到了一百多种,是农作物遥感识中多光谱特征的一个重要组成部分[8]。目前,农作物遥感识别常用的多光谱数据源见表1[9-13]。
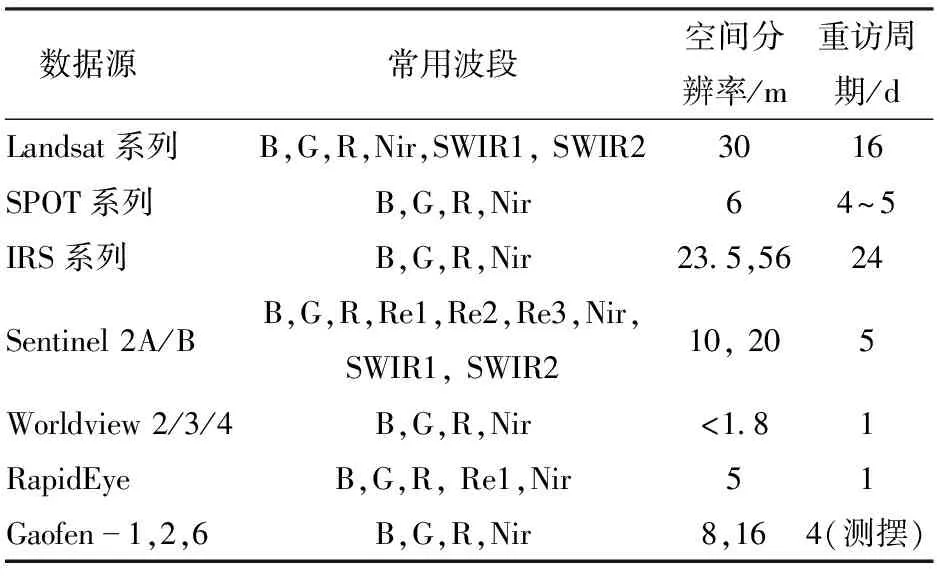
表1 农作物遥感识别常用的多光谱遥感数据源
(2)微波散射特征
可见光至短波红外范围内的光谱特征均是由传感器被动接收并记录地表反射的电磁波能量,而该波长范围的电磁波辐射传输过程极易受到大气状况影响,从而在一定程度上影响多光谱数据的可用性。合成孔径雷达(SAR)以微波频率发射和接收能量,由于其工作波段波长较长,不易受到大气影响,从而具有了“全天时全天候”可用的特性。SAR传感器记录的后向散射电磁波能力很大程度上取决于目标的几何结构和介电性能。不同作物具有的不同冠层结构、植株形状、土壤背景等均随着作物的生长而变化,SAR数据对这些结构差异及具有不同介电性能的土壤背景具有非常好的响应[14],因此微波散射特征也被用于农作物遥感识别[15],并有研究已经证明微波散射特征对作物生物物理参数,如叶面积指数[16]、生物量[17]、冠层高度[18]等,具有良好的敏感性。尽管多光谱遥感特征已经广泛应用于农业遥感领域,但SAR应用研究的不断发展以及不同频率和极化条件下SAR数据的可用性提高了它在农业遥感领域中的地位。目前,在农作物遥感识别领域中,SAR数据多用于识别水稻,常用数据类型见表2。

表2 基于微波散射特征的作物识别
一般情况下,SAR数据在作物生长中后期的识别精度高于作物生长的前期,作物生长前期,冠层覆盖度较低,雷达后向散射能量中有相当一部分是背景土壤的贡献。因此,利用SAR数据进行早期作物类型识别存在一定困难。除此之外雷达数据受到噪声的影响大,数据获取成本较高,数据处理相对复杂,同时受极化方式的影响,微波遥感在识别农作物方面依然存在着很大的潜能。
(3)高光谱数据特征
高光谱成像仪光谱波段非常窄,辐射分辨可以达到纳米数量级,光谱通道数通常多达数十甚至数百个,而且各光谱通道间往往是连续的,成像光谱仪的波段范围通常可以覆盖紫外、可见光、近红外和短波红外(350~2 500 nm)。光谱分辨率的提高大幅增加了对地物的分辨识别能力。在农业应用方面,由于高光谱数据的电磁波波长范围更广,光谱分辨率很高,能探测到农作物在光谱特征上的微小差异,从而被广泛用于作物类型精确识别,叶片或者植株的生物物理及生物化学特性的探测,监测作物胁迫、作物疾病等。在利用高光谱数据进行作物识别方面,有研究基于SDA技术从高光谱数据选择了最佳频段区分观赏植物、豆类和油菜作物,结果表明:在近红外和中红外波段,具有鉴别豆类作物的4个最佳波段,即750、800、940、960 nm;在油菜作物的区分过程中主要取决于550、690、740、770、980 nm;而在花朵的区分过程中420、470、480、570、730、740、940、950、970、1 030 nm波段表现出非常良好的区分性[24]。即使在作物种植情况比较复杂的条件下,高光谱数据对于区分作物类型同样表现出良好的可用性[25]。除作物识别应用外,有研究表明高光谱反射率数据在区分作物品种(基因型)方面同样有良好表现,充分体现了高光谱特征的光谱分辨率的优势[26-27]。
高光谱数据虽然具有明显的光谱优势,但是其缺点也较为突出。一方面,高光谱数据包含特征波段太多,各波段之间具有明显相性,信息冗余现象较为严重,直接使用全部波段数据会导致模型分类精度出现“不升反降”的现象(特征维数灾难)。此外,由于不同作物之间光谱相似性更高,由此可能导致协方差矩阵的奇异性,严重影响农作物分类识别的精度[28]。因此,高光谱数据降维方法研究成为必然,典型降维方法包括:主成分分析(PCA)、均匀特征设计(保留光谱形状信息但减少特征维数)、小波变换以及结合人工神经网络的特征选择[29-30]。另一方面,高光谱数据在具有高辐射分辨率的同时,其空间分辨率往往较低,光谱遥感影像上混合像元问题较为突出,难以实现精细空间尺度的农作物类型识别。以上两点在一定程度上限制了高光谱数据在农作物遥感识别中的广泛应用。
1.1.2空间纹理特征研究
随着遥感数据空间分辨率不断提高,地物几何细节信息得到越来越充分的表达,不同地物之间的空间细节差异在影像上表现明显。因此,利用高空间分辨率光学影像或SAR 影像(QuickBird、GeoEye、TerraSAR-X、RADARSAT-2 等)进行农作物遥感识别时,除了光谱特征及微波散射特征外,空间细节信息也是表达不同作物差异的重要特征源。因此,用于表达空间细节差异的空间纹理特征在遥感分类中发挥着越来越重要的作用。
目前,国内外学者发展了多种纹理度量方法,可以总结为4类:基于统计方法的纹理特征、基于结构方法的纹理特征、基于模型的纹理特征、基于数学变换的纹理特征[31-34]。其中,遥感应用中最常用的是基于统计方法的灰度共生矩阵(Grey level co-occurrence matrix,GLCM)纹理特征和基于地统计学的特征纹理。
GLCM可以同时反映图像的灰度分布特征和相同(相似)灰度像元的空间位置分布特性,是影像灰度变化的二阶统计特征[35]。基于 GLCM 的纹理特征在遥感分类中被广泛应用[36-37]。例如,在分析不同纹理特征对遥感分类精度影响的研究中发现:纹理特征和光谱特征的结合可以提高分类精度,相比于仅使用原始光谱特征的分类结果,纹理特征的加入使分类精度提高9%~17%[38]。在基于高分辨率影像的植被类型分类研究中,纹理特征与原始光谱特征的结合使分类精度提升8%以上[39]。地统计学一般用于解释空间相关性问题,常被用于空间数据插值、空间抽样方法估计、空间预测模型构建等。在遥感分类领域中也有越来越多的研究利用其作为一种纹理计算方法[40],并将其与原始光谱特征相结合来改善遥感分类精度。相关研究表明基于地统计学的纹理测量方法可以提供比基于GLCM 纹理更好的分类结果[41-42]。除上述两种常用问题特征外,基于小波变化的纹理特征、Gabbor纹理特征进行农作物遥感分类识别,识别精度同样得到提升[43-45]。
上述研究多数集中在将纹理特征和原始光谱特征结合使用,证明纹理特征的加入使分类精度提高,但有关纹理特征之间的相关性以及它们各自是如何影响分类结果的研究较少,即这些研究往往不能单独表明具体纹理特征对遥感分类的精度及对分类精度的改善。由于高空间分辨率遥感数据通常包含较少光谱波段,其空间信息丰富度高于光谱信息丰富度,在地物几何信息得到加强、“异物同谱”现象得到抑制的同时,“同物异谱”问题变得突出,即相同地物内部差异变大。此外,高空间分辨率遥感影像易受阴影的影响,引起分类精度的降低。另外纹理特征随着研究目标和遥感影像而变化,纹理特征的提取方法、所使用的基础波段、滑动窗口尺寸等因素都将影响纹理特征的有效性,因此纹理特征很难标准化并提供稳定的有效性。
1.1.3数据融合特征研究
综合利用不同类型(平台)传感器所获取的数据是对利用单一数据源进行农作物遥感分类识别的一种补充。多源遥感数据融合可充分利用不同数据的优点,达到提高分类识别精度的目的[46]。典型的多源遥感数据融合应用包括光学数据与雷达数据融合、高空间分辨率数据与低空间分辨率数融合应用[47-49]。有研究表明综合利用雷达与光学数据对作物类型的识别精度远高于仅使用雷达数据或者仅使用光学数据[50]。融合使用多波段SAR数据的农作物识别研究表明,利用 X 和 C 两个波段的 SAR 数据进行农作物分类,取得优于单波段SAR 数据的分类效果,整体精度提高约10%[51]。多极化SAR数据的融合使用同样被证明可以有效提高农作物遥感识别精度,例如综合使用PalSAR的水平极化(HH)与交叉极化(HV)数据、ASAR的垂直极化数据(VV)、以及 TM 多光谱数据进行农作物精细分类的研究中,发现双频多极化SAR 数据对不同作物间潜在差异的表达能力较强,不同类型作物在该特征上的可分离性较高,有利于提高作物类型的整体识别精度[52]。众多前人的研究结果都表明雷达数据融合多光谱数据在农作物类型识别中具有较大的优势[53]。不同多光谱数据的融合使用,可以有效地缓解单一数据源可能面临的关键时相数据缺失的情况,在提高数据可用性的同时,提高农作物遥感识别精度。例如,Sentinel-2数据与Landsat 8数据具备良好的协同使用条件,同时在地块尺度上的农作物遥感识别应用中取得了良好的精度,验证了不同多光谱遥感数据协同使用的优势[54-55]。
数据融合特征的优势在于可以综合两种及以上类型数据的优势,融合后的特征空间对不同作物间的潜在特征差异表达能力更强,有利于提高农作物遥感识别精度;但同时不同遥感数据融合操作易受到数据融合方法、融合尺度等因素的影响,从而影响融合数据在实际应用中的稳定性。
1.1.4时相变化特征研究
农作物生长是一个缓慢变化的动态过程,其植株形态、冠层结构、生理生化参数都随着作物生长而缓慢变化,从而导致其冠层反射率随作物生长过程而缓慢动态变化(如NDVI时间序列曲线,图2)。不同作物在其生长周期中会表现出不同的变化趋势,而单一时相的数据只捕捉了地表物体在一瞬间的电磁波反射信息,受“同物异谱,异物同谱”现象影响,单一时相特征对地物的辨别能力有限,在某些情况下分类识别精度不高[56]。随着在轨卫星及传感器数量的增加,对于地面同一位置的重复观测频率越来越高,因此如何利用时间序列遥感数据来表达作物生长过程中丰富的季节性变化特征并将其用于农作物遥感识别,已经成为一个研究热点。

图2 农田NDVI时间序列(2000—2020年)
当前,利用时相变化特征进行农作物遥感识别主要是基于植被指数时间序列数据。即利用不同时相的多光谱遥感数据计算植被指数,然后将植被指数序列作为分类算法的主要输入来完成作物类型的识别[57-58]。这种直接使用植被指数时间序列的识别方法对于具有明显的独特时相特征的作物来说是简单、有效的,例如利用时间序列数据进行水稻的识别[59-61]。但是此类方法没有考虑时间序列遥感数据中的相对位置(时间)关系,从而导致时间序列中包含的重要作物生长过程信息没有被充分利用。为了充分利用植被指数时间序列信息、提高作物识别的精度,最直接的方法是从植被指数序列中提取时相或者物候特征。研究表明,相比于简单直接利用植被指数时间序列数据,使用基于统计或阈值分割方法提取到的包括植被指数最大值、植被指数峰值时间点、植被变绿(作物返青)时间点等在内的特征可以提高作物识别的精度[62-64]。其次,基于特定的数学变换、预定义的数学模型从时间序列数据中提取时相及物候特征的方法同样被广泛应用于多时相数据的分类识别和作物物候研究。其代表性方法包括傅里叶变换[65-66]、小波变换[30,67]、SG滤波[68-69]、卡尔曼滤波[70]、线性回归[71]、样条拟合函数[72-73]、隐含马尔科夫模型[74]以及多种人工定义的曲线形状特征提取算法等[75-76]。众多的研究结果已经表明随着参与作物分类识别的时相数量增加,识别精度总体上呈现上升趋势,表明不同时相特征可以有效地表现出不同作物生长过程变化趋势不一致的特点,有利于农作物遥感识别[77-78]。因此,有许多研究使用了完整的时间序列进行作物识别研究,期望用完整的时间序列数据来详细描述作物生长过程,实现区分作物类型的目的[79-83]。但是,农作物的生长周期较短,再考虑到云雾天气影响和卫星重访周期等因素,获取同一地区的2~3个关键时相的高质量遥感数据存在一定困难,使得多时相遥感数据失去了提高农作物遥感识别精度的优势[84]。尽管时间序列数据可以更加完善地表征不同作物的生长变化过程特征,但是构建完整的时间序列数据通常需要相关重建方法[85-86],导致时间成本更高,时效性相对较低,即不能在作物生长的早期、中期及时地识别作物的类型[87-88]。此外,在地物变化不明显的区域中,时间序列数据会存在冗余和高度相关的现象,这限制了时间序列数据的应用[89-92]。
目前,在实际应用中如何选择最适合且最有效的时间序列特征提取方法依旧是技术难题,面临的主要问题有:①人工设计模型或算法进行时间序列特征提取高度依赖于专家经验及先验知识。通用的特征提取方法对于一些特定目标的识别效果一般或无效。②人工特征工程是非常耗时且低效的,通常需要人为干预来应对变化的环境和天气状况,而且人类的知识很难同时考虑类内相似性、类间差异性、大气条件、辐射传输机制等多种复杂因素[93]。③固定的数学模型或相关假设在一定程度上限制了特征提取算法的灵活性和可行性[94]。
1.2 农作物遥感识别算法
农作物遥感识别的基本过程是根据遥感数据所表现出的特征差异进行类别属性信息的判断与提取,其本质是分类问题。在农作物遥感识别领域中,分类算法的发展可以概括为3个阶段(图3):早期的强学习方法;基于弱学习方式的集成学习方法;以神经网络为代表的深度学习方法。本文将早期的强学习方法与集成学习方法统一归纳为传统机器学习方法,以便与当前的研究热点——深度学习方法形成对照。

图3 农作物遥感识别算法发展历程
1.2.1基于传统机器学习方法的作物遥感识别
早期的强学习方式是基于概率统计方法构建单一分类器完成分类任务的过程,典型算法包括最小距离法、最大似然法、决策树方法、支持向量机等。最大似然法(Maximum likelihood)是最常使用的监督分类方法之一,它假设数据近似服从正态分布,利用训练数据集求出均值、方差以及协方差等特征参数,从而建立各类别的先验概率密度函数,实现待分像元的归属概率计算从而完成分类。由于最大似然法简单易实施,且将贝叶斯理论和先验知识融入分类过程,在农作物遥感分类识别中应用广泛[95-96],且与其他传统分类方法相比,最大似然法综合表现最优[97]。但是该方法适用于特征波段较少的多光谱数据,在高光谱图像分类中的效果较差。决策树(Decision tree)是一种归纳推理的分类方法,通过对遥感图像光谱、颜色、空间等信息定义和不断更新规则来完成不同层次节点划分,直到节点不可再分为止。决策树类算法采用分层分类的形式,易于理解,可操作性高,能够处理多输出问题,从而被广泛应用于农作物遥感识别[98-101],但其缺点是泛化能力较差,在处理高维数据时表现不佳。支持向量机(SVM)以结构风险理论、二次优化理论、核空间理论为基础,在高维特征空间中求解最优分类超平面,从而解决复杂数据的分类及回归问题。SVM在农作物遥感分类中较为稳定、分类精度较高,但其在解决多类目标分类问题、特征空间维度较高时表现较差,且如何正确选择核函数也没有相关的理论依据[102-103]。
集成学习算法将一系列独立或非独立的弱学习器的结果按照一定策略进行整合得到最终的结果,从而获得优于单个学习器的学习结果。其构建过程包括:基础分类器的生成和分类结果合并策略。其中,基础分类器生成过程中最常用方法是基于不同训练数据集生成一系列同质分类器,主要方法有 Bagging和Boosting。Bagging方法采用随机有放回抽样技术构造不同训练数据集用于生成分类器;Boosting方法首先为不同的样本赋予相同的权重,然后在训练过程中,降低正确分类样本的权重,增加错分类样本的权重,使得学习算法持续聚焦于错分样本,最后通过加权组合方式获得最终模型。集成学习的优势主要表现为:①统计学方面:多学习器可以获得一个相对稳定的假设空间,以减少泛化误差。②计算复杂度方面:集成学习可以有效降低算法陷入局部最优的可能性。③假设空间方面:多学习器可以让假设空间有所扩大,更有利于学到更好的近似。在农作物遥感分类识别中,应用最为广泛的机器学习方法是随机森林[104-107]、Adaboost[108-109]、梯度提升树[110-111]等。
虽然传统机器学习方法能够较好地完成不同地区不同作物的遥感识别,但在识别过程中主要使用浅层的直接观测特征和人工设计特征,对遥感数据中的深层次特征以及不同类型特征的协同学习能力较差。
1.2.2基于深度学习的作物遥感识别
深度学习(Deep learning)作为机器学习领域中的一个分支,其目标在于建立模拟人脑进行分析学习的神经网络,采用海量训练数据驱动深度神经网络学习更有用的深层次特征,最终提升分类准确性。深度神经网络模型具有大量的参数,一方面使得模型具有足够的复杂性,另一方面使得模型具备从端到端的数据中学习特征的能力,替代了基于人类经验和先验知识的手动特征工程[112]。近年来,以人工神经网络为基础的深度学习在包括遥感在内的机器学习和数据挖掘领域中取得一系列突破性进展,主要是得益于深度学习在特征表示方面的灵活性、不依赖于专家知识的端到端特征学习方式、自动化以及计算效率[113-119]。
卷积神经网络(CNN)是最成功的深度学习网络架构之一。CNN的学习过程计算效率高,并且对图像数据中空间关系敏感,使得CNN网络成为识别图像中2维(2D)特征模式的最有效模型[120]。在遥感领域中,2D CNN已被广泛用于提取空间特征,从而实现基于高分辨率图像的目标检测和语义分割[121-125]。CNN的另一个主要应用是高光谱图像分类,即分别利用1D、2D、3D CNN进行光谱特征、空间特征、“空-谱”特征的提取[115,126-129]。在农作物遥感分类应用中,研究表明空间域中的2维卷积操作比光谱域中的1维卷积操作能取得更好的精度,将不同生长期的多光谱影像拼接起来,然后在光谱域中运用1维卷积操作同样可以提升地物分类的精度[130-131]。虽然卷积操作可以很好地在空间域、光谱域或同时在“空-谱”域中提取有效特征,但是CNN很少用于时间域特征的提取,即无法有效地提取时间序列遥感数据中的时间变化特征。
循环神经网络(RNN)是专门用于处理时间序列数据的另一类深度学习网络模型[132-133],由于可以捕捉长序列数据中的前后依赖关系,已在众多遥感应用中取得了成功。例如,RNN已经被成功用于多光谱数据中空谱相关性以及波段差异变换趋势[115];将CNN与RNN进行结合进行图像分类,即使用CNN生成从浅到深的多级卷积特征图,然后使用RNN作为解码器递归收集多尺度特征图并按顺序聚合形成高分辨率语义分割图像[134]。RNN网络有许多改进的模型用于提高学习效率,其中最著名的改进网络是长短期记忆网络(LSTM),主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。相比于普通RNN,LSTM在基于长时间序列的变换检测[135]、农作物分类[82,136]等方面有更好的表现。此外,将CNN与LSTM相结合,一方面通过使用2D卷积操作提取影像中的空间特征信息,另一方面使用LSTM机制捕捉时间序列数据中的时间依赖关系,取得了比传统方法更好的结果[137-138]。有研究对比分析了LSTM模型和传统机器学习之间的表现,结果表明LSTM模型在提取时间序列特征方面全面占据优势地位。例如,LYU等[135]发现在多个实验中,LSTM的准确率约95%,而支持向量机(SVM)和决策树的准确率分别约80%和约70%;MOU等[137]同样进行了一系列对比试验发现,将CNN和LSTM联合使用,准确率可以达到98%,精度优于SVM(约95%)和决策树(约85%);RUβWURM等[139]通过构建多时相的LSTM模型取得了90.6%的准确度,略高于CNN(89.2%),远高于SVM(40.9%)。
以长短时记忆网络(LSTM)为代表的循环神经网络在处理时间序列遥感数据方面具有较大的优势,但是以门限机制为基础的循环神经网络在处理长时间序列数据或长程依赖问题上容易出现梯度消失,无法捕捉长距离信息依赖的情况。为此,以自注意力机制为基础的Transformer网络应运而生。目前,Transformer模型及其变种已经成为处理序列问题的主流方法,在基于时间序列遥感数据的农作物分类识别领域取得了成功[140-142],成为当前研究的热点。
1.3 讨论
目前,对于大区域尺度农作物遥感识别存在的核心问题是:
(1)识别特征方面,当前所使用的主要特征类型以浅层特征为主,且作物生长过程中的时间信息、空间纹理特征、光谱反射特征(“时-空-谱”特征)协同表达不够充分,且具体作物类型与作物识别特征缺乏知识关联,导致以监督学习为主的农作物类型识别高度依赖于当季真实样本,间接影响了农作物遥感识别的时效性和大区域作物类型识别的可用性。
(2)在作物的识别特征与具体作物类型缺乏知识关联的背景下,通过增加识别模型复杂度提升农作物识别精度,一方面可以提升识别精度,另一方面模型训练所需的样本量急剧增加,进一步导致了识别过程对当季已知样本的依赖、识别结果滞后,制约农作物遥感识别结果服务于现实应用。
在此背景下,应重点研究如何根据历史的时间序列遥感数据及对应样本数据,提取面向具体作物的“时-空-谱”特征知识,形成面向作物类型识别的知识图谱,实现从数据到知识的转化。一方面摆脱识别过程对当季真实样本的依赖,另一方面提高识别精度与效率,提升农作物遥感识别的现实服务价值。
2 作物遥感估产
农作物产量的形成过程极为复杂,受到品种、气候环境、土壤养分和田间管理措施等多种因素的综合影响。作物遥感估产是农业遥感的基础应用之一,其大致经历了经验模型、半经验模型、物理估产模型3个阶段。早期的经验模型没有充分考虑作物产量形成过程中的各种复杂因素,仅利用作物冠层光谱反射特征或气象条件与地面实测产量数据进行回归建模,实现作物单产遥感反演。经验模型缺少机理约束,时空泛化能力差,而作物生长模型则从机理上模拟了作物生长的全过程,机理性更强,但只能模拟点位尺度的情况。不同模型各具特点,在实际应用时各有优劣。
2.1 统计模型
基于统计方法的作物单产估算大体可以分为3类(图4),其中遥感指数模型和产量三要素模型的总体思路是直接建立遥感数据与作物实测产量或产量形成要素之间的关系模型进而完成单产估算;农业气象模型则是通过评估农业生产过程中的气象因素影响,实现作物单产估算。
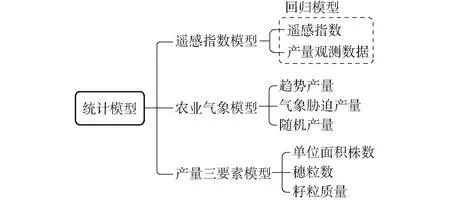
图4 基于统计模型的单产估算方法
2.1.1遥感指数模型
农作物冠层光谱反射特性与其地上部生物量/产量之间存在密切联系,特别是红色和近红外波段由于包含超过90%的植被信息[143-144]而被用于监测绿色植被、估算产量[145-146]。早期的作物单产估算统计模型是寻求建立单一遥感波段或多波段反射率数据与地面观测产量数据之间的线性/非线性回归模型,是一种比较简单有效的作物单产统计估算方法。例如在利用Landast TM影像进行水稻单产估算研究中发现,蓝波段、近红外、中外红外波段的反射率与实际产量之间具有良好的相关性,可通过多元线性回归模型较好地预测水稻产量[147];在玉米、大豆估产研究中同样发现各波段反射率数据与大豆和玉米作物产量之间具有良好的相关性,并据此建立了包括线性、对数、指数和幂模型[148]等在内的经验模型,取得了较好的估产效果。
植被指数通常综合了两个及以上的原始波段信息和专家知识,被广泛应用于研究植被健康和作物生产力[149-152]。其中,归一化差值植被指数(NDVI)[153]作为最常用的植被指数被大量单产估算研究采用。一种方式是选择作物生长季内最佳时期的NDVI(如作物生长最旺盛时期)与地面观测产量数据进行回归建模,但选择最佳时相与估产的生态区位、气候条件、作物类型等多种因素有关,且无定律可循[154-155]。另一种方式是使用作物生长周期内的NDVI时间序列数据进行作物估产,例如建立NDVI时间序列积分与产量的线性关系或者从NDVI时间序列中提取作物活力值、生长峰值、生长率、衰老率、及曲线面积等更高级特征参数与产量进行多元回归建模来估算[156-158]。除了NDVI之外,不同传感器数据、不同类型的植被指数被广泛用于全球不同地区的作物单产估算,作物类型涵盖了水稻、玉米、大豆等。同时,随着估产模型中变量类型的增加,单产估算的精度在提高,且多时期复合模式估产精度要优于单一生育期估产[159-161]。
单纯基于原始遥感波段或植被指数建立经验模型进行作物估产,在特定区域特定作物类型上能取得较好的估算精度,但是经验统计模型缺乏机理约束,导致模型的时空泛化能力差。为此,有研究在回归模型中加入独立的气象变量进行条件约束,用于提高估产精度[162-163]。此类,条件约束变量既可以直接测量,也可以通过遥感反演,例如降雨量、ETa(实际蒸发蒸腾量)或土壤水分等农业气象参数。研究表明将降雨量、温度数据与NDVI数据同时用于建立普通最小二乘回归模型对小麦单产的早期预测精度较好,表明将降雨量和温度因子纳入作物单产估算模型对干旱少雨的地区更为重要[164]。引入额外生物气候变量的谷物产量回归模型比仅使用遥感指数的模型具有更高的相关性和预测能力[156];将基于CWSB模型计算出的ETa和土地覆盖加权NDVI(CNDVI)作为自变量与玉米产量进行多元线性回归来预测肯尼亚玉米产量,模型精度(R2)达到0.83[165]。但值得注意的是通过遥感反演得到的生物、气候指标并不独立于遥感植被指数,因此,将他们和光谱参数协同建模时,应考虑并纠正不同输入变量的相关关系。
近10年,随着传感器的发展,红边植被指数、太阳诱导叶绿素荧光(SIF)等新的波段或植被指数在遥感估产方面展现了巨大的潜力[166-167]。在单产估算建模方法方面,除了经典(多元)线性回归、偏最小二乘回归(PLSR)或主成分回归(PCR)等统计方法之外[168],模糊数学和机器学习算法也被用于估产模型构建,例如随机森林算法(RF)、自适应神经模糊系统(ANFIS)和深度学习[169-172]。
总体而言,基于经验模型来估算作物产量的方式简单、易实施,在特定区域针对特定作物的估产可以达到较高的精度。但经验统计模型一方面缺乏理论机理支撑,另一方面受限于特定地理区域的环境特征、数据集,难以将已校准的估产方法推广到其他地区或其他尺度,模型的扩展性与移植稳定性差。此外,经验模型构建时需要大量地面真实产量数据作为支撑,对于大面积估产来说费时费力,经济性与时效性均不能满足实际应用的需求。
2.1.2农业气象模型
农业气象模型主要思想是将作物产量划分为趋势产量(潜在产量)、气象胁迫产量(胁迫产量)与随机产量3部分,故又称潜在-胁迫模型。趋势产量是由作物生理结构、农田管理措施等非环境因素所形成的产量,即作物在正常生长环境下的产量;气象胁迫产量则是由于气温、降水、日照等气象条件导致的产量波动部分;随机产量是由自然或者人为灾害导致的不确定部分,一般只能在模型外进行处理。农业气象模型通过分离趋势产量与气象产量、外推趋势产量、预测波动产量、修正预测误差等工作来进行作物产量估算。
农业气象模型在我国应用广泛,中国科学院开发的全球农情遥感速报系统(Cropwatch)中也运用了农业气象模型进行产量预测[173],实现了以作物产量预报业务系统为主体,农业气象情报和遥感应用系统为辅助的作物产量预报综合技术支持体系,对全球主要粮食产区进行跟踪监测、评价和产量预测[174]。
2.1.3产量三要素模型
产量构成三要素方法将作物产量表示为单位面积作物株数、每株平均粒数与籽粒质量的乘积。在对产量三要素与作物光谱之间关系的研究中发现小麦的株数与植被绿度相关性非常高;穗粒数主要取决于环境因子, 特别是拔节至灌浆初期温度因子; 籽粒质量则主要取决于灌浆期的长短,可以使用绿度的变化速率来表征[175],而垂直植被指数(PVI)与单产三要素均具有较强的相关性[176-177]。利用遥感信息反演产量构成三要素进而估算作物单产,思路简洁明确,在对冬小麦进行估产时精度达到了95%以上[178]。但是,产量三要素模型的空间扩展能力较弱且估产精度不稳定,主要原因是产量三要素的遥感反演模型主要是经验模型。
总体而言,无论是遥感指数模型、农业气象模型还是产量三要素模型,其本质均是通过大量地面实测的产量数据与相应遥感数据进行统计分析与建模,所建立的经验模型在特定空间范围内对特定作物的单产可以进行高精度估算,且模型运算量小、计算简单易实行,具有一定的实际应用价值。但是经验模型一方面缺乏机理约束,另一方面高度受限于气候条件的制约,在具有不同气候条件的其他地理区域,模型稳定性与空间外推能力差。
2.2 净初级生产力模型
作物最终产量的形成是植株光合作用积累干物质以及干物质在不同器官分配的结果,因此可以通过计算植被净初级生产力(NPP)并结合收获系数估算作物产量,基于该原理的作物单产估算模型统称为NPP模型。NPP模型分为统计模型、过程模型、参数模型3种[179]。其中,统计模型是根据光谱指数与作物地上部分干物质量之间的相关关系而建立的估算模型,对遥感数据及实测数据要求较高。过程模型理论严谨、精度高,如BEPS模型[180]等。虽然过程模型具有一定的物理意义和理论基础,但是所需参数种类及数量较多,数据处理过程复杂,且往往难以直接观测。参数模型又称遥感光合模型,是对过程模型的简化。其基本思路是:首先计算植被光合有效辐射吸收比例(FAPAR),即植被吸收的光合有效辐射(APAR)与地球表面的瞬时光合有效辐射(PAR)之比;其次,植被光合有效辐射乘以光能利用率得到NPP;最后,将作物整个生长季的NPP进行累加,然后乘以收获指数(HI)得到作物最终产量(Y)[181]。其中FAPAR与LAI、植被冠层反射率以及NDVI密切相关。研究表明FAPAR与LAI呈指数关系、与NDVI呈现出良好的线性关系,据此可以对FAPAR进行遥感反演[182]。PAR为入射辐射总量,常用日照百分率结合经验公式计算得到。εb是指单位面积的土地上植被通过光合作用产生的有机物所包含的能量占对应土地上所接受的太阳能的比例。在理想状态下,植被所吸收的光合有效辐射转化为有机物的效率存在理论最高值,即存在最大光能利用率εmax,其主要利用通量观测数据计算或者根据先验知识得到[183],每一种植被类型的最大光能利用率是恒定的。然而真实情况下,作物受各种外界因素(水分因素、温度因素等)胁迫,实际光能利用率会产生波动变化,其实际值的确定通常需要对作物生长环境胁迫因子(如温度、降水)进行综合考虑。遥感光合模型具有生态物理学基础,所需参数较少,估算结果精度较高,在实际生产中得到了广泛的应用,代表性模型有CASA、GLO-PEM、C-FIX模型等[184]。基于遥感光合模型的单产估算模型在区域尺度上对玉米、小麦等主要粮食作物的估产中取得良好的效果[185-186],凭借较好的时间及空间泛化能力,NPP模型也被成功应用于农田生产力时空变化格局分析[187]。
虽然利用遥感光合模型进行农作物估产的应用越来越多,但是相比于农作物估产,遥感光合模型在计算草地和森林生物量时具有更好的精度,可能原因是遥感光合模型未能考虑人为管理因素对农作物产量的影响。相比于统计模型,遥感光合模型有一定生物物理基础,模型时空泛化能力强。但利用该模型进行作物单产估算时需要输入作物生长周期内完整的长时间序列遥感数据,且不同区域不同作物的真实光能利用率以及收获指数的精确估算还需进一步深入研究,这在一定程度上影响了此类模型的实际应用。
2.3 作物生长模型
自荷兰瓦赫宁根大学DE WIT于1965年率先提出作物生长模拟理论以来[188],全世界多个研究组开始从事作物生长模拟模型的研究,建立了各种作物的生长模拟模型。随着计算机科学技术以及作物生长理论的研究深入,作物生长模型的研究也取得了巨大的进展,成长为一门成熟的科学[189]。目前,典型作物生长模型有:美国的DSSAT(Decision support system of agricultural technology transfer)[190],包括针对42种以上作物的模拟模型(自4.7版起)以及辅助工具,其中CERES-Maize和CERES-Wheat模型是作物模型发展的典型代表;澳大利亚的APSIM(Agricultural Production Systems sIMulator)系统[191];荷兰的WOFOST(World food studies)模型[192]等。
作物生长模型通过初始化模型参数信息(作物参数、土壤参数等)模拟作物一定时间步长内(每日、每旬、每月等)对驱动变量(气象参数、田间管理等)的响应从而更新模型状态变量(发育阶段、各器官干重、叶面积指数等),再现农作物生长发育及产量形成过程。作物生长模型的优势主要体现在以下方面:①模型按照固定时间步长对输入数据进行反映并更新状态变量,是动态连续的。②模型允许对不同区域、不同作物、不同生长情况进行模拟,机理性强,易于空间外推。③模型是多功能模块的集成系统,综合性强,可以进行不同应用的定量分析,如气候效应对农作物影响的定量研究、土壤水肥模拟、生产力预测预警、农业生态评估等。
作物生长模型可以定量描述作物生长发育和产量形成过程及其与气候因子、土壤环境、品种类型和技术措施之间的关系,为不同条件下作物生长发育及产量预测、栽培管理、环境评价以及未来气候变化评估等提供了定量化工具。但是,作物生长模型是对点位尺度的模拟,在区域尺度应用时,由于空间尺度增大而出现的地表、近地表环境非均匀性问题,导致模型中一些宏观资料的获取和参数的空间化方面存在困难,从而使得作物生长模型模拟结果存在较大不确定性。遥感信息则凭借其宏观、快速、连续的观测特点可以在很大程度上弥补作物生长模型的不足,因此,作物生长模型与遥感数据的结合应运而生,具体结合方式见表3。

表3 遥感数据与作物生长模型的结合方式
数据同化指在考虑数据的时空分布和观测场、背景场误差的前提下,在模型的动态运行过程中融合新观测数据的方法。其主要目标是利用多源观测数据不断校正与优化模型的模拟过程,使得模型的估算更加符合客观生物物理化学状态,进而改善模拟的估计精度,提高模型的预测能力。遥感耦合作物生长模型进行数据同化的方法主要包括连续数据同化和顺序数据同化,具体见表4。

表4 遥感数据与作物生长模型同化方法
早期的遥感数据与作物生长模型的同化主要基于优化算法。对冬小麦单产估算的研究表明,将不同遥感数据源反演得到的LAI分别与CERES-Wheat、EPIC等作物生长模型进行同化,均取得了良好的精度[194-195]。LAUNAY等[196]将甜菜模型SUCROS与SAIL耦合,然后把SPOT影像数据和航空摄影数据同化到耦合后的模型中,通过调整模型中的部分敏感性参数,提高了产量预测的精度,均方根误差由原来的20%下降到10%。基于优化算法的同化方案在实际应用易于实现,但需要极大的计算量,效率较低。基于变分法和滤波算法的同化方法则具有更高的效率,在近几年得到更多研究。例如在冬小麦的单产估算中,利用集合卡尔曼滤波算法(EnKF)将MODIS数据反演LAI和ET与SWAP模型进行同化,显著提高了小麦单产的预测精度[197]。黄健熙等[198]首先基于S-G滤波算法重构MODIS LAI时间序列;其次,通过构建地面观测LAI与3个关键物候期Landsat TM植被指数构建回归统计模型计算得到区域尺度的TM LAI数据;然后融合上述两种不同空间尺度的LAI数据生成尺度转换LAI。最终利用EnKF算法将这3种不同时空分辨率的LAI数据同化到PyWOFOST模型中,研究结果表明同化尺度转换LAI获得最高的同化精度,潜在模式下的模拟产量均方根误差由602 kg/hm2下降到478 kg/hm2,证明了遥感数据与作物模型的EnKF同化方法在区域作物产量估算中的有效性。王鹏新等[199]将遥感反演的条件植被温度指数VTCI与CERES-Wheat模型模拟的土壤浅层含水率相结合,运用四维变分同化算法(4D-VAR)实现冬小麦主要生育期旬尺度VTCI的同化,运用多种决策分析方法分别建立了同化前后的VTCI单产估测模型,结果同样表明应用同化后的VTCI构建的估测模型精度明显提高。
基于作物生理学建模的定量遥感估产方式是目前的研究热点。将遥感数据与作物生长模型相结合进行作物单产估算是理论性更完备的方式之一,因为遥感能够对作物生长状况进行概括性量化,而作物生长模型能够描述整个生长季作物的生长过程。随着作物生长模型的不断完善,其模拟精度不断提高,但是所需参数多难以准确获取,此外作物生长模型需要输入整个生长期的驱动数据,无法进行产量的提前预测。因此,如何更进一步充分发挥遥感与作物生长模型的各自优势,提高对作物产量的估算精度和估算的时效性还有待深入研究。
2.4 问题与展望
总体来看,当前的农作物单产遥感估算模型也是形式繁多,在推广应用中明显存在泛化能力不足、监测时效滞后、单产制图不够精细等问题,难以满足当前智慧农业对于农作物单产估算时效性和空间精细程度的要求。
随着高分辨率、高光谱分辨率、高时间分辨率遥感数据的增加,以及深度学习等技术的发展[200],研究如何耦合深度学习与作物生长模型,构建针对大区域范围的可扩展和高效移植的精细尺度农作物单产遥感动态估算模型是潜在的研究方向之一。充分利用作物生长模型模拟不同点位尺度、不同生境情况下的作物生长情况,捕捉作物生长规律,充分利用深度学习方法对复杂情况的学习与建模能力,完成空间外推,实现用机理做约束,用深度学习做外推。
3 结束语
作物类型遥感识别与产量估算是农业遥感领域中的基础应用。当前农作物遥感识别特征与具体作物类型缺乏知识关联,导致识别过程过度依赖于当季样本、识别结果滞后的问题;单产估算模型则面临着估算精度较低、时空泛化能力较弱的问题。随着更高空间分辨率、更高光谱分辨率、更短重访周期数据的普及,以及深度学习技术的发展,同步学习农作物生长过程中的“时-空-谱”特征知识,并基于与特征知识构建面向作物识别的知识图谱,实现从数据到知识转变,从而提高农作物遥感识别的精度和时效性。农作物单产遥感估算的潜在重点是深度协同作物生长模型和深度学习,以作物生长模型模拟的不同生境下作物生长状况为基础,驱动深度学习模型完成复杂种植结构、复杂生长环境下的建模学习,最终实现用机理做约束,用深度学习进行空间外推的作物单产估算模式。
