基于U-Net和特征金字塔网络的秸秆覆盖率计算方法
2023-03-07万传峰汪玮韬吴才聪
马 钦 万传峰 卫 建 汪玮韬 吴才聪
(1.中国农业大学信息与电气工程学院, 北京 100083; 2.农业农村部农机作业监测与大数据应用重点实验室, 北京 100083)
0 引言
保护性耕作是东北黑土地保护利用的有效途径[1],其中包括秸秆深埋还田、覆盖还田等方式,统称为秸秆还田[2]。秸秆还田是一种保护水土肥力的重要措施,不但可以减少秸秆焚烧带来的环境污染以及资源的浪费,对于改善土壤结构、保留土壤水分、增加土壤养分起到重要作用[3]。
秸秆覆盖率是评价免耕还田程度的一个重要指标,但是传统秸秆覆盖人工统计方法如拉绳法、采样法、目测法需要消耗更多的人力物力且效率低,更容易受主观因素的影响。图像处理方法和机器学习算法可以实现秸秆检测及其覆盖率计算。文献[4]提出一种基于多阈值的多目标秸秆图像自动分割优化算法(DE-AS-MOGWO),提高了图像分割的准确性和处理速度。文献[5]采用神经网络和纹理特征结合的方式提取秸秆,方法耗时较长,无法满足实际作业需求。文献[6]提出了一种随机决策森林算法对土壤中的残留物进行分类,使用简单的像素比较和具有训练偏移量的邻近像素对单个像素进行分类。文献[7]将快速傅里叶变换和SVM相结合对秸秆图像进行识别,设计多尺度占比滤波器,对图像中的噪声和空洞进行修补,算法适用于多种情况。文献[8]提出一种Sauvola和Otsu算法相结合的方式进行图像的阈值分割来检测秸秆覆盖率,对于干扰因素较多的区域检测效果不理想。文献[9]通过K-means聚类和秸秆图像分区寻优方法结合进行图像分割,为秸秆覆盖率在线计算提供一种新方法。文献[10]依据图像行平均灰度标准差对图像进行分类,针对有秸秆图像进行分块,使用Otsu阈值分割计算秸秆覆盖率,提高检测方法的适用性。但是传统阈值分割方法受背景因素、光线因素、阴影等噪声的影响较大,晒干的秸秆颜色和土壤相近,难于区分秸秆和土壤。农田秸秆形态多样,对于分散的细碎秸秆识别困难。随着深度学习的发展,图像语义分割技术已经成为当下的研究热点,语义分割是图像在像素级别的分类操作。目前,语义分割技术主要应用在遥感图像[11-12]、自动驾驶[13-14]、医学影像[15]等领域。文献[16-17]利用遥感图像进行秸秆检测,标准误差分别为4.846%和8.46%。文献[18]利用低空无人机获得现场图像,用改进的U-Net(ResNet18-U-Net)建立语义分割算法进行覆盖率检测。文献[19-20]基于语义分割的DSRA-UNet算法检测秸秆覆盖率,一定程度上能解决图像中的阴影问题。但是无人机航拍图像数据需要单独采集,无法和农机播种的其他作业环节相结合。
针对田间秸秆细碎分散、形态多样、秸秆和土壤受光照影响难以区分等难点,本文使用车载相机采集秸秆图像数据,对复杂秸秆图像进行图像预处理,筛选有效识别区域,以U-Net网络和特征图金字塔网络作为基础结构进行改进,以提高细碎分散秸秆和阴影区域秸秆的识别能力。
1 整体设计
1.1 秸秆检测流程
秸秆覆盖率检测主要采用计算机视觉的方法,通过车载相机设备采集农田秸秆图像数据集。结合农田秸秆形状多样的特点,针对农田场景有逆光或光照遮挡导致的阴影问题,先对秸秆图像进行图像裁剪,获取相机拍摄的正前方有效区域,去除农田外的干扰背景后进行图像投影变换,减少相机拍摄时产生的透视畸变。使用Labelme标注得到真值,使用数据增强技术进行数据集扩充。在模型设计阶段为了提高秸秆在复杂场景下的提取能力,使用ResNet34加深模型的网络层数;在模型层数增加的情况下为了避免产生网络梯度消失现象,在模型中加入残差结构;同时使用改进的特征金字塔网络和多分支非对称空洞卷积块,利用不同的感受野,增加不同形状尺寸秸秆和细碎秸秆的提取能力;最后用快速上卷积进行特征图上采样,避免网络上采样过程中出现过多的无效数据。由网络模型输出得到预测图,结合手动标注的真值图像,使用平均交并比、像素准确率和运行时间等指标进行模型评估。检测流程如图1所示。

图1 秸秆检测流程图Fig.1 Flow chart of straw detection
1.2 图像采集
由于免耕播种有作业补贴,需要进行作业面积监测,同时无人机采集数据要单独作业,难以区分农田的边界和识别地块归属,所以选择在播种机作业时,使用播种监控设备上的摄像头进行秸秆图像数据的采集。本文所用秸秆图像数据为2020年5月采集于黑龙江省齐齐哈尔市龙江县,由北京德邦大为科技股份有限公司的车载监控设备采集得到,所用农机为DEBONT2BMG-2型播种机,监控设备包括显控终端、北斗定位终端、红外补光摄像头等,使用前后双摄像头拍摄,后摄像头主要监控作业情况,需要拍摄到农具,前摄像头拍摄范围为车前20 m以上,图像分辨率为640像素×480像素。从13块作业田块中选取200幅有效图像进行试验,训练集和验证集共150幅,测试集图像50幅。通过图像翻转、缩放、对比度增强等数据增强技术将训练集和验证集图像共扩增到1 250幅图像,其中训练集图像为1 000幅,验证集图像250幅。图2所示为不同覆盖等级下的秸秆图像数据,由图2e可知,田间的细小秸秆较多时,秸秆之间会有空隙(放大图中的椭圆框区域),这些像素点对应的是土壤,在进行秸秆检测时容易识别成秸秆区域,给秸秆覆盖度检测带来困难。

图2 不同覆盖等级的秸秆拍摄图像Fig.2 Shooting images of straws with different mulching levels
1.3 图像变换
由于不同农机相机安装位置、角度不同,导致图像拍摄视角产生差异,会有天空、房屋、树林等其他干扰背景存在,在图像预处理阶段,人工判定田块区域占整幅图像区域3/4以上为有效图像,并以此标准进行图像裁剪,去除天空区域。先使用图像行像素和的方式查找有效区域,天空区域对应的像素灰度大部分为230~250,田内土壤的像素灰度大部分在150以下,两者差异较大。根据图像的行像素和变化规律可知,一般情况下,水平分界线从天空区域到田内的过程中,行像素灰度总和逐渐减少,当有树林等其他干扰因素时,行像素和局部上升,临近分界线时像素和快速减少,因此图像的像素行数在[0,120]范围内,判断田内和田外分界处的一个条件就是当行像素灰度和连续下降且下降的差值最大时,对应的水平线位置就是分界处,结果如图3a~3c黄线所示,分界线识别流程如图4所示。
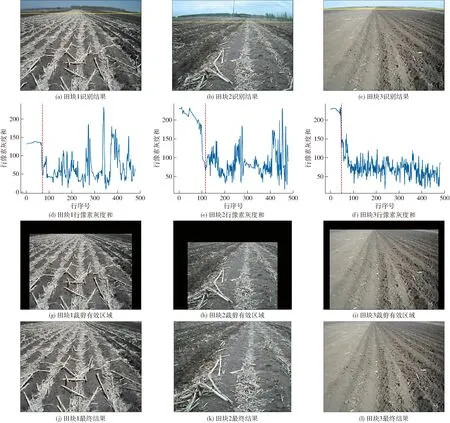
图3 图像裁剪过程Fig.3 Process of image cropping
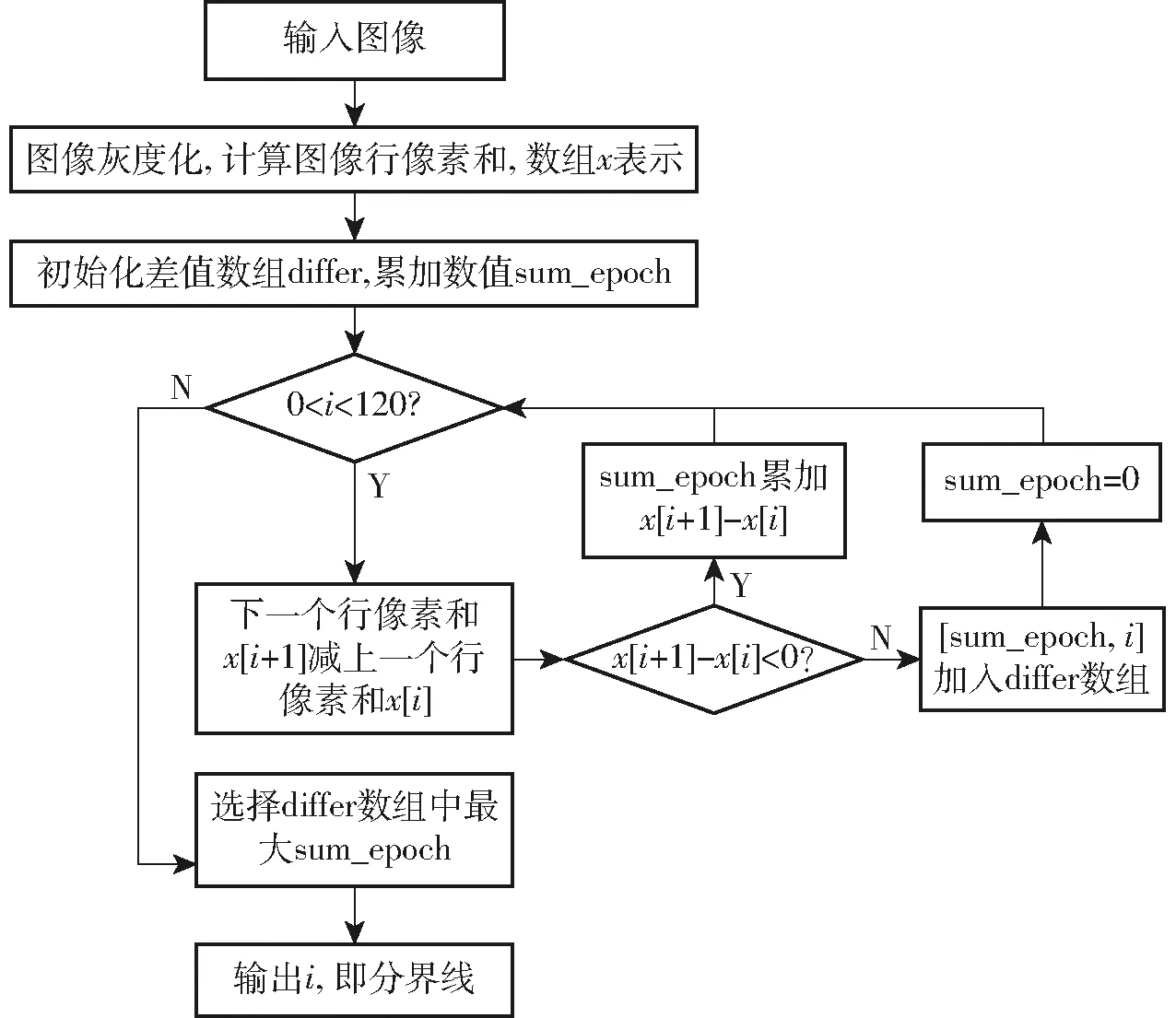
图4 分界线识别流程图Fig.4 Flow chart of dividing line recognition
由图3e可知分界线位置(红色虚线),计算分界线下方区域的高与图像高的比例,对图像的宽进行等比例裁剪见图3h,最后将裁剪图缩到原尺寸得到结果图。
车载相机在采集图像数据时,秸秆图像存在近大远小的透视畸变,为了改善这种情况,文中采用图像透视变换[21]进行处理,如图5所示,可以在一定程度上减小误差,投影变换公式为

图5 图像投影变换结果Fig.5 Result of image projective transformation
(1)
式中T——转换矩阵
(u、v)——图像像素坐标
(x、y)——转换之后归一化的图像坐标
(x′、y′、z′)——转换后未归一化的图像坐标
1.4 图像标注
图像行灰度和检测到的有效区域图像,进行人工标注,生成标注图像作为真值,来评估语义分割模型的性能。使用Labelme标注工具,将图像分为土壤、秸秆两类,标签图中黑色表示土壤,红色表示秸秆。将图像中的物体按照不同的类别分别圈选并做好标记,用Python脚本语言生成标注图,结果如图6所示。

图6 图像标注结果Fig.6 Result of image annotation
2 模型框架
2.1 模型概述
U-Net网络是一种有编码器和解码器结构的网络,通过跳跃连接将编码器阶段的特征图和解码器阶段的特征图信息进行融合。本文基于U-Net和FPN提出新的网络结构,如图7所示,其中特征图下方标注了该特征的尺寸和通道数。
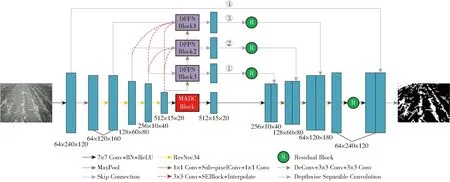
图7 改进U-Net + FPN算法网络架构Fig.7 Network architecture of U-Net + FPN algorithm
网络模型包含特征编码器模块、最高语义信息层特征提取模块和特征解码器模块。编码阶段采用ResNet34的前4层网络结构,先进行卷积核尺寸为7×7的卷积和池化核为2×2的最大池化,然后通过多层串联的残差网络结构进行4次特征提取。最高语义信息层特征提取模块在密集空洞卷积[22]的基础上提出多分支非对称空洞卷积块(Multibranch asymmetric dilated convolutional block,MADC Block),使用多个分支的非对称空洞卷积对特征图进行不同尺度的信息提取。特征解码模块使用快速上卷积块代替普通上采样进行位置信息的恢复,同时用跳跃连接获取编码阶段同一层级的特征信息。跳跃连接中对编码阶段的特征信息通过密集特征金字塔网络(Dense feature pyramid networks,DFPN)模块获取不同尺度的特征图信息,前3次跳跃连接的DFPN模块之后使用标准残差块保持网络的收敛性,避免网络训练过程中的梯度消失现象。经过4次上采样得到的特征图通过残差块运算后与第4次跳跃连接得到的特征图进行融合,最后进行1次反卷积得到与输入图像相同尺寸的结果图。
2.2 编码-解码结构
FCN网络模型[23]提出了编码-解码结构,用卷积层替换传统卷积神经网络最后的全连接层,使用跳跃连接进行特征融合,摆脱了输入图像尺寸的限制。在FCN之后,同样使用编码-解码结构的U-Net[24]和SegNet[25]网络在此基础上进行了相应的改进。编码-解码结构主要是在网络中包含一个编码器模块和一个解码器模块,编码器模块主要负责图像的特征提取,图像从空间信息转换到深层的语义类别信息,并记录每一个类别像素点的位置;解码模块对编码块输出的信息进一步优化,根据像素点的类别信息和位置信息进行复原,并将特征图放大到原输入图像的尺寸。
2.3 多分支非对称空洞卷积模块(MADC Block)
MADC模块根据空洞卷积[26-27]思想,加入非对称空洞卷积(Asymmetric dilated convolution,ADC)进行秸秆信息识别,目的是为了扩大感受野同时,不降低图像分辨率且不引入额外参数量,非对称结构在不改变感受野的条件下,增强秸秆边缘关键点提取能力,提升对秸秆图像识别的鲁棒性。结合Inception[28-29]结构思想进行多尺度不同感受野的秸秆信息的获取,在增加网络宽度和深度的同时减少参数量,如图8所示,大感受野更好地提取大片覆盖秸秆信息并生成更抽象的特征,小感受野可以更好地提取小范围细碎秸秆信息。模块共有5个分支,第1个分支使用3×3卷积核,设置扩张率为1;第2个分支使用扩张率为3的3×3非对称卷积,之后进行扩张率为1的1×1卷积;第3个分支先使用扩张率为1的3×3卷积,后跟扩张率为3的3×3非对称卷积,再进行扩展率为1的1×1卷积;第4个分支依次使用扩展率为1的3×3卷积、扩张率为3的3×3非对称卷积、扩张率为1的5×5非对称卷积和扩张率为1的1×1卷积;第5个分支使用原始输入特征图;MADC模块中每次卷积之后都采取ReLU函数保持非线性。

图8 MADC模块结构图 Fig.8 Diagram of MADC module structure
2.4 残差块(Residual Block)
在一定范围内,网络深度越深,拥有越好的性能,能够更好地提取秸秆特征,但是随着网络深度的增加,会导致梯度消失、梯度爆炸等问题出现[30],ResNet34[31]使用的残差网络可以缓解梯度消失现象,通过增加一条捷径学习融合原始特征信息,在增加网络非线性的同时保持网络的原有特征,以增强表达能力。网络结构如图9所示。

图9 卷积残差块结构图Fig.9 Diagram of residual block
2.5 密集特征金字塔网络(DFPN)
特征金字塔网络[32](Feature pyramid network, FPN)主要是为了解决目标尺寸差异较大时的检测缺陷,细小秸秆的像素信息较少,在网络下采样过程中容易丢失,在上采样过程中无法恢复,导致最后识别不成功。FPN网络通过将语义信息较强的低分辨率特征图和空间信息更多的高分辨率特征图进行融合,构建多尺度的特征金字塔结构。在FPN的基础上,本文提出密集特征金字塔结构,如图10所示。网络结构通过稠密连接的方式,将下采样过程中的所有特征图都使用到特征图的上采样过程中,从而更充分地利用秸秆图像的细节信息。以第2次上采样过程为例,不同通道数的输入特征图(x1,x2,x3)使用3×3卷积转换到相同通道数。x2、x3卷积生成的低分辨率特征图使用SE[33]模块(Squeeze-and-Excitation block,SEBlock)增强秸秆信息的特征,然后上采样到x1特征图的相同尺寸。将得到的3个特征图进行拼接,再用多尺度的深度可分离卷积进行秸秆信息提取,以应对秸秆形状多样的问题,之后使用1×1卷积进行通道数转换生成特征图F1。最后将前一个上采样过程中生成的特征图x4依次进行深度可分离卷积改变通道数和上采样改变特征图尺寸,与生成特征图F1相加。
其中SE模块先在通道维度进行全局池化,得到通道的全局特征,然后使用全连接层和激活函数来获取通道之间的关系。第1个全连接层起降维的作用,降低模型的复杂度并且可以提升网络的泛化能力,后面跟ReLU激活函数,第2个全连接层负责将通道数恢复到原特征图的维度,后面使用Sigmoid函数激活,将各个通道的特征值缩到0~1之间,最后将各个通道的激活值乘以x2、x3卷积生成低分辨率特征图,提取每个通道中的主要信息。SE模块基于通道注意力机制的方式,得到通道权重,来增强特征图中的秸秆特征,抑制其他干扰因素的特征。
2.6 快速上卷积块(FUC Block)
常见的上采样方法有插值法、转置卷积和反池化。插值法在上采样时没有考虑图像边缘的信息,缩小了特征图不同特征边界处的差异,导致图像的边缘模糊。转置卷积会导致生成的图像中产生棋盘效应。反池化原理是特征图的下采样过程中,最大池化时记录最大值的索引位置,在上采样时将特征值填入记录的位置,并将其余位置补零,来增大特征图的尺寸,但是这种方法因为引入大量0,在后续的卷积过程中大多计算是无效的。本文使用快速上卷积块[34](Fast up-convolution block,FUC Block)进行特征图的上采样,结构如图11所示。对于原始特征图,反池化之后会增加75%的0值,后续使用3×3卷积计算时,相当于对原始特征图进行2×2、2×1、1×2和1×1的有效参数计算。因此本文分别使用2×2、2×1、1×2和1×1的卷积核对原始特征图进行卷积,然后将生成的4个特征图拼接,并使用子像素卷积将拼接图的每个通道对应位置元素重新组合,生成尺寸比原始特征图增大一倍的特征图,来替代普通的上采样方法,在达到相同效果时,快速上卷积块比普通上采样方法计算量更小,加快了运算速度。
3 训练
3.1 损失函数
损失函数反映了模型预测值和真实值之间的差距,深度学习模型训练过程中使用损失函数进行模型评估和监测[35-36],本文使用二分类的交叉熵损失函数,在进行梯度下降计算时可以避免网络出现梯度弥散的现象,加快网络的学习深度,定义为
(2)
式中n——像素点总量
i——像素点序号
y——像素点真实值,若像素点为秸秆,取1,否则取0
a——像素点被预测为秸秆的概率,取0~1
3.2 训练超参数
网络模型使用Adam优化器,在每一个epoch中计算损失函数的梯度,从而进行参数更新;学习率为10-4;batch size设置为10;训练迭代周期为200,激活函数使用ReLU函数。
4 试验结果
4.1 评价指标
为了检验模型识别秸秆的准确性,使用秸秆图像分割平均交并比(Mean intersection over union,MIOU)、像素准确率(Pixel accuracy,PA)和单幅图像平均处理时间等来衡量算法性能。
4.2 改进网络结构评估
本文使用的模型预测平台GPU配置为Tesla V100 32GB,训练时间约5 h,为了更好地比较各个修改结构的效果,以U-Net为基础,使用控制变量法,逐步添加改进的结构,在训练集上进行模型训练,并通过验证集的指标准确率来比较模型的效果,如表1所示。

表1 编码阶段不同网络结构的准确率Tab.1 Accuracy results of different network structures in encoding stage %
为了更具体地比较每个结构对模型改进的效果,进行了5组不同模型结构的试验,结果如表2所示。试验1为初始网络U-Net,试验2将U-Net编码阶段的网络结构替换为ResNet34,试验3表示在试验2的基础上加入MADC Block,试验4在试验3的基础上添加了DFPN模块,试验5在试验4的基础上,将上采样时的反卷积结构替换为FUC Block。各网络结构在验证集上进行准确率比较。

表2 添加不同模块后效果对比Tab.2 Comparison of effects after adding different modules
由表2可知,使用U-Net网络进行农田秸秆分割,MIOU为82.19%,本文改进网络的MIOU提高2.59个百分点,达到84.78%,由于网络结构中加入了MADC、DFPN等模块,增加了训练参数,导致模型参数量和运行时间有所增加。对比试验2、3可以看出,MADC模块可以更好地获取特征图中秸秆的空间信息,比未使用MADC模块时的MIOU提高1.53个百分点。对比试验3、4可以看出,DFPN模块可以将深层特征图语义信息和浅层的空间信息相结合,其中包含通道注意力机制用来减少干扰信息,进一步提高网络的特征提取能力,网络模型的MIOU提高0.81个百分点。对比试验4、5可以看出,加入快速上卷积模块比试验4的MIOU提高0.19个百分点,主要原因是FUC Block使用多个尺寸不同卷积核对特征图进行卷积,并使用子像素卷积进行特征图的信息融合,对于特征图的边界信息提取得更加准确。
对于DFPN结构中的SEBlock,其中第1个全连接层起降维作用,降维系数r是一个超参数,为了找到合适的降维系数,以及在降维过程中避免信息丢失,本文将超参数取值2、4、8、16进行试验对比,结果如表3所示。由表3可知,当r取值8时,模型准确率最高,在提高模型泛化能力同时可以加快模型的运算速度,因此本文SE模块选择r=8作为超参数。

表3 不同超参数取值的准确率Tab.3 Hyperparameters of running results of different algorithms
为了更直观地展示网络模型改进效果,选择表2中的试验1、3、4、5共4组网络模型,分别代表U-Net网络,以及U-Net编码阶段替换为ResNet34后依次添加MADC Block、DFPN Block、FUC Block结构,选取不同环境下的田间图像进行预测,以Labelme工具标注得到的二值图像作为真值,结果如图12所示。

图12 不同覆盖率下网络预测效果对比Fig.12 Comparison of network prediction effects in different situations
由图12可知,在有阴影干扰情况下,原始U-Net网络的识别不够精细,阴影区域的秸秆识别不够完整,但是改进后的U-Net网络能够更精确地识别出秸秆位置,在一定程度上解决由阴影所带来的干扰。在秸秆覆盖率50%~100%时,改进的U-Net网络和原始U-Net识别结果相差不大,主要区别在秸秆和土壤的边界处分割更加精细。在秸秆覆盖率处于30%~50%时,改进网络对远处离散的秸秆区域识别的更加准确。当秸秆覆盖率为0~30%时,秸秆主要以细碎分散的秸秆为主,改进网络对于细碎秸秆的分割更接近真实情况,对秸秆覆盖区域中夹杂的土壤区域也能分离出来。由以上分析可以看出,本文改进的算法在大部分情况下都能比原始U-Net更好地完成分割任务。
4.3 与其他网络效果对比
本文通过和其他算法运行结果相比来评估本算法的性能。使用卷积核为3×3的U-Net算法、加入注意力机制的Attention-U-Net算法、CE-Net[22]算法、CPF-Net[37]算法进行了对比,结果如表4所示。

表4 不同算法运行结果比较Tab.4 Comparison of running results of different algorithms
由表4可知,本文算法MIOU和PA指标高于其他算法,在细碎秸秆识别上更加精细,网络通过增加非对称空洞卷积和特征图金字塔网络结构,增强了网络的特征提取能力。由于网络结构中参数多,模型复杂度高,网络对图像处理时间更长,是相对于其他网络,但整个模型对640像素×480像素 的图像平均处理时间在3 ms以下,满足实际作业需求。
4.4 实际覆盖率计算对比
使用人工测量和本试验算法对6个不同田块秸秆的覆盖率进行计算,计算方式为识别结果图中秸秆像素点除以整个图像的像素点,对比结果如表5所示,误差率为真实覆盖率和预测覆盖率之间的差值绝对值。由表5可知,算法预测的覆盖率和人工测量的覆盖率相近,最大误差率为3.8%。
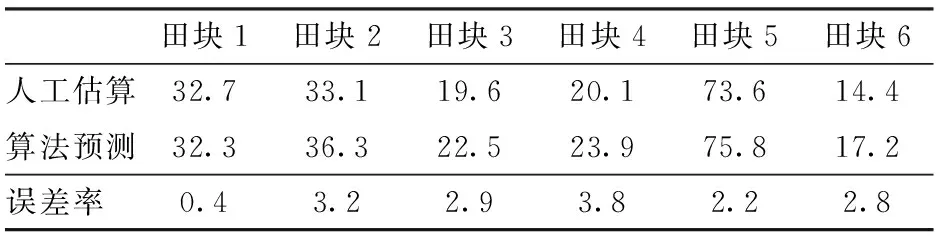
表5 不同田块的覆盖率计算Tab.5 Calculation of coverage rate of different fields %
试验另外随机选取验证集中的136幅秸秆图像数据,分别按覆盖率等级进行划分,划分为0~10%、10%~20%、20%~30%、30%~50%、50%~100% 5个集合,结果如图13所示。其中0~10%等级共27幅图像,10%~20%等级共36幅图像,20%~30%等级共34幅图像,30%~50%等级共28幅图像,50%~100%等级共11幅图像。根据结果可知,不同覆盖等级下,算法识别的准确率和人工标注测量的覆盖率大致相等,算法识别准确率的折线图在人工测量折线图上下波动,误差较小。
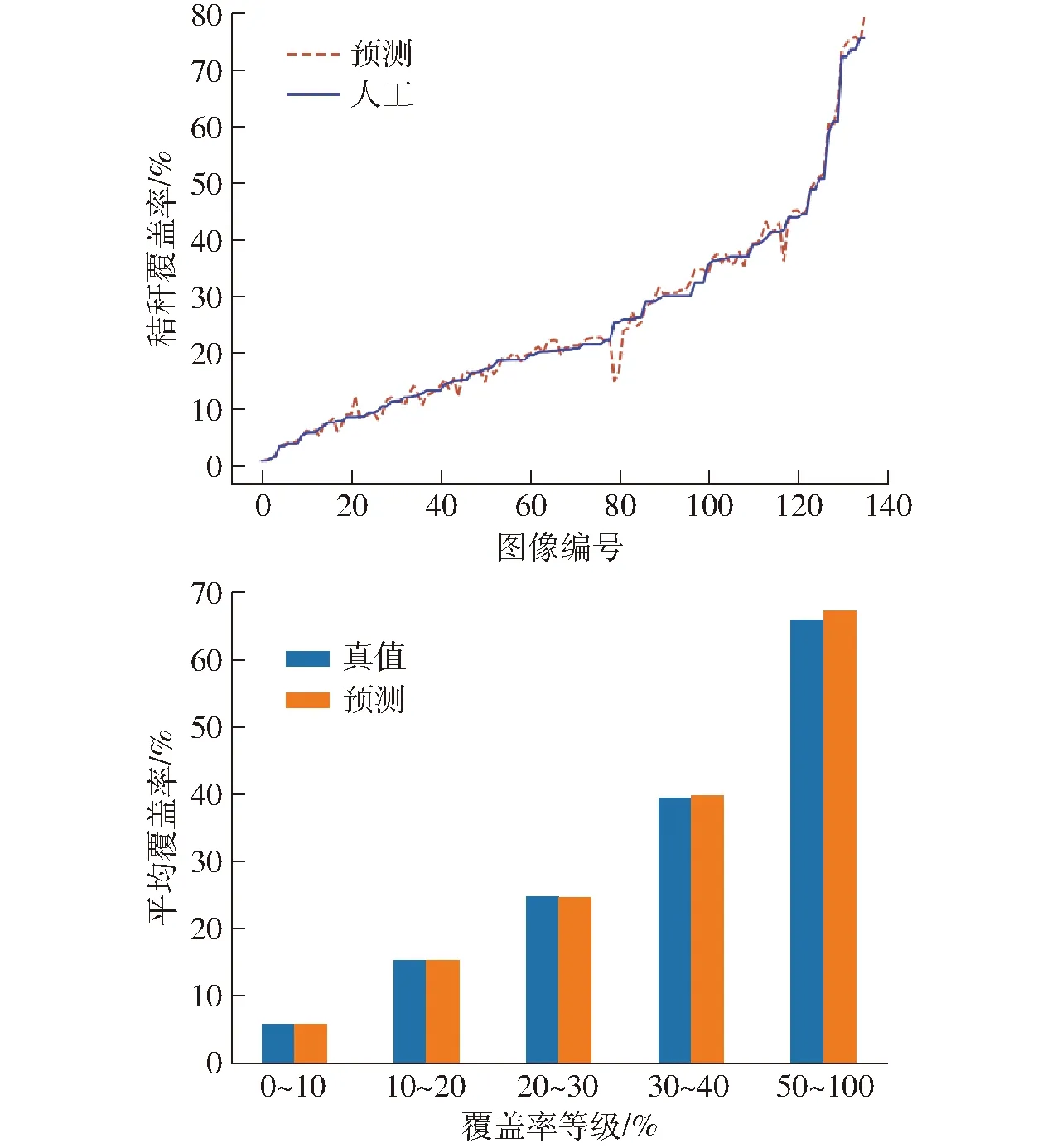
图13 不同覆盖率等级效果对比Fig.13 Comparison of effects of different coverage levels
5 结论
(1)将编码阶段网络结构替换为ResNet34结构,通过残差连接加深网络层数,避免网络训练中梯度消失问题,增加网络复杂度,提升秸秆特征提取能力。
(2)在网络最高语义信息层使用多分支的非对称空洞卷积,空洞卷积提高卷积核的感受野,非对称结构增强了秸秆局部关键点的权重,提高了模型鲁棒性。
(3)结合FPN网络,提出密集特征金字塔网络,结合高层特征图和底层特征图信息,对不同尺寸秸秆的识别能力更强。
(4)使用快速上卷积模块替换普通上采样方式,避免网络训练过程中的无效参数运算。
(5)提出的改进U-Net,结合改进的FPN网络等结构,提高了网络的分割精度,分割MIOU为84.78%,相较于原U-Net提高2.59个百分点,平均处理时间低于3 ms,符合农机正常作业时秸秆覆盖检测的要求。
