基于DBSCAN和BP_Adaboost的农机作业地块划分方法
2023-03-07李亚硕王长伟徐名汉伟利国庞在溪
李亚硕 赵 博 王长伟 徐名汉 伟利国 庞在溪
(1.中国农业机械化科学研究院集团有限公司, 北京 100083;2.土壤植物机器系统技术国家重点实验室, 北京 100083)
0 引言
随着农业机械化作业的普遍推广、农业机械化水平的提升,物联网技术在农机生产管理中的作用日益突出。目前,通过机载物联网设备和无线通信技术,监管人员可以实时获取农机作业位置、作业状态和作业效率,并通过监管平台进行任务分配和补贴结算等,满足了农机监管部门和农机合作社管理人员对所属农机的实时监管和作业规划需求[1-4]。农机管理人员按时间或工作量给机手发放工资,按地块面积向农户收取费用或向相关部门申请补贴,因此地块的精准划分是工资发放、费用收取、补贴申请、面积计算、效率评估等的基础。深松作业可以根据深松机入土深度判断是否在田间作业,但其它如收获、植保、打捆等作业难以根据机载传感器判断作业状态。无法强制农机驾驶员只在田间才打开机载设备,其他时间关闭设备。因此需要根据得到的轨迹点信息自动判断农机轨迹点状态和划分地块。
使用机载定位设备可以记录作业轨迹信息,实时发送后端处理,得到行驶轨迹和作业分布。根据上传的农机行驶轨迹,可在监管平台的地图中人工划分地块。但一台农机每天作业多个地块,每天多台农机同时作业,一个作业季的地块数量非常多,人工划分耗时耗力,并且由于地图精度问题,人工标记边界容易出现误差。
地块划分的前提是农机轨迹点状态的确定。目前,轨迹点数据处理多采用聚类算法,根据轨迹点聚簇判断状态和划分地块。田间作业轨迹点密集,道路行驶轨迹点稀疏,利用这一特点通过DBSCAN聚类的方法区分田间作业和道路行驶轨迹[5-6]。但聚类方法的邻域半径和邻域点数不易确定,不同农机、不同地形作业轨迹相差很大。有研究人员利用时空信息对轨迹进行密度聚类[7-9],由于轨迹点具有时序性,将时间作为聚类信息对准确率的提升作用不大。利用空间索引和网格密度聚类[10-11],有效提升了运行速度,但网格尺寸和密度阈值参数敏感。尽管聚类方法对农机田间作业轨迹效果较好,但对道路转移行驶轨迹容易误识别,因此单纯依靠聚类方法,很难提升农机轨迹点状态识别率。
根据轨迹点单个特征设定阈值,容易遗漏深层的内部相互关系。依靠神经网络等深度学习方法进行训练,在多维特征组成的高维空间寻找有效的内部关联性,进而有效识别农机轨迹点状态,再根据时序关系划分地块。但训练样本的标记耗时太大,并且有新农机作业轨迹识别需要重新标记训练,推广性不强。
本文结合农机空间运行轨迹的特点,选择农机轨迹点经度、纬度、速度、近邻点相互关系等作为特征,先用DBSCAN算法进行聚类,得到初步的聚类结果和类别标记;利用BP_Adaboost算法对轨迹点进行训练和识别;将田间与道路交界处附近轨迹点标记为道路轨迹并添加到训练样本中重复训练,直至训练样本无新增。以期解决海量数据标记困难、不同地块轨迹差异大、田间与道路交界处轨迹点易误识别等问题。
1 农机作业地块划分
通过安装在农机上的北斗定位接收装置自动记录农机运行全过程轨迹,获取农机经纬度位置信息、速度信息等。农机在行进和停车时,机载定位设备都会发送位置信息,因此,农机行驶轨迹点分道路行驶轨迹点、田间作业轨迹点和停车点。农机从车库行驶至目的地块以及在两地块间转移时,一般沿道路单向行驶,速度较快,轨迹点稀疏;在田间作业时,在地块内往返行驶,速度偏慢,轨迹点密集;当农机因故停车时,轨迹点以农机为中心,在小范围内呈散点簇分布。划分地块的依据是区分田间作业轨迹点和道路行驶轨迹点,因此需先处理停车点和其他干扰轨迹点。再根据农机轨迹点的特性,对不同轨迹点信息进行分析试验,选取有用特征。
1.1 数据预处理
由于定位精度原因,农机在停车时,轨迹点不是集中在一个点,而是散落在农机附近小范围内,称为农机停车散点,速度为0或者很小值。当定位偏差过大或者设备故障导致多个轨迹点未发送时,连续接收到的两点间距过大,称为漂移点。停车散点和漂移点如图1所示。

图1 停车散点和漂移点Fig.1 Parking scatter and drift point
有效农机行驶轨迹点是道路行驶轨迹点和田间作业轨迹点,农机停车散点和漂移点会影响轨迹状态识别,在数据处理前应去除。为保持图像数据完整性,本文在数据处理时不计算停车散点和漂移点,在地图中,将这两类点标记为道路行驶点。为了防止将田间作业过程中临时停车轨迹点误删除,停车散点判断依据设置为:连续很多点的速度小于某一阈值。将漂移点的上一轨迹点作为前段轨迹终点,下一轨迹点作为下段轨迹起点。
由于采集器故障、信号差、断电等原因,会造成连续两轨迹点之间间隔很远。当某一轨迹点与前一轨迹点距离较大,而与下一轨迹点间隔正常时,认为两轨迹点之间存在轨迹点丢失。将上一轨迹点作为前段轨迹终点,下一轨迹点作为下段轨迹起点。
1.2 特征选取
农机行驶轨迹点包含时间、经纬度、速度等信息,农机田间作业轨迹和道路行驶轨迹交叉,依据轨迹点属性信息,可利用阈值设定、聚类、分类等方法区分轨迹点状态,找到有效的属性信息是取得理想效果的前提。图2为轨迹点近邻点数差异图,其中近邻区域半径为当日轨迹点平均距离的3倍。

图2 轨迹点近邻点数差异柱状图Fig.2 Histogram of difference in number of adjacent points of track points
以轨迹点为中心、以r为半径的圆范围内近邻轨迹点的个数,田间作业轨迹点多于道路行驶轨迹点。研究发现,当r为每天农机作业轨迹点平均距离3倍时,田间作业轨迹点和道路行驶轨迹点在r范围内的近邻点数量区分性最好。当r过小时,田间作业轨迹点近邻点数量急剧下降,当r过大时,道路行驶轨迹点近邻点数量增加,都会造成两类轨迹点近邻点数量重合部分增加。如图2所示,田间作业轨迹点周围轨迹点数量集中在7~9个之间,道路行驶轨迹点周围轨迹点数量集中在4~6个之间,有较好的区分性。因此该特征可以用于判断轨迹点状态。以速度和近邻点平均距离等为特征,不同状态轨迹点分布如图3所示。

图3 不同特征下轨迹点分布Fig.3 Distribution of trajectory points under different characteristics
由图3可以看出,田间作业轨迹点速度慢且与附近点距离小,虽然有一定的区分性,但是重叠交叉部分也很多,依靠某一、两个特征难以达到预期效果。在一定半径范围内,田间作业轨迹点附近轨迹点数要多于道路行驶轨迹点附近轨迹点数。当选用速度、近邻点数和近邻点平均距离作为特征时,轨迹点分布如图3c所示,虽然仍有部分重叠,但区分性较单个特征要好。在多特征组成的高维空间内,田间作业轨迹点和道路行驶轨迹点更具区分性。但单纯依靠阈值作为判断依据,普适性不强,且阈值不易确定。应在有效特征选取的基础上,自学习内部关联性,进而判断轨迹点状态。
本研究选取轨迹点经纬度、速度、近邻点平均距离、近邻点数、轨迹点与近邻点距离作为特征,利用BP_Adaboost训练模型识别轨迹点状态。样本标记工作量过大,先利用DBSCAN聚类方法得到初步类别标记,再进行训练。
1.3 DBSCAN聚类
密度聚类算法[12-14]假设聚类结构能通过样本分布的紧密程度确定,从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇以获得最终的聚类结果。农机田间作业轨迹点紧密,道路行驶轨迹点稀疏,利用密度聚类方法不仅可以区分田间作业轨迹和道路行驶轨迹,还可以将不同地块的轨迹点聚为不同类。DBSCAN基于“邻域”参数(ε,NminPts)来判断轨迹点数据的紧密程度,ε为以每个轨迹点为中心的长度范围,NminPts是轨迹点要成为一个簇中心,周围轨迹点距离小于ε的最少个数。DBSCAN可以去除噪声点,并且不必提前规定聚类个数,聚类步骤如下:
(1)从数据集中任意选取一个轨迹点p。
(2)如果对于参数ε和NminPts,选一个轨迹点p,找到所有密度可达的核心对象,生成聚类簇。
(3)如果选取的轨迹点p是边缘点,选取另一个轨迹点。
(4)重复步骤(2)、(3),直到所有轨迹点被处理。
农机道路行驶轨迹一般为单向,田间作业为往返行驶,具有明显的区分性,因此DBSCAN方法对这种轨迹状态区分有不错的效果。但部分道路区段由于农机折返行驶、转向、减速等原因导致轨迹点密度变大,使该处轨迹被误识别为田间作业轨迹。不同农机行驶速度和轨迹不同,田间作业轨迹间隔也不同,DBSCAN算法对于输入参数ε和NminPts是敏感的,使用固定的ε和NminPts不能很好解决所有农机轨迹状态识别问题。
1.4 类别不平衡处理
利用分类器训练模型,再对轨迹点进行识别,可以避免聚类算法中ε和NminPts不易确定的问题。但在农机行驶轨迹中,田间作业轨迹点数量要远多于道路行驶轨迹点数量,特别情况下比例可达10∶1。用同样数量田间作业轨迹点数据进行训练,样本数量不足;田间作业轨迹点选用过多,会造成类别不平衡,都影响识别准确率,因此需要增加道路行驶轨迹点数据量。SMOTE算法[15-17]是在少数类样本和其近邻的少数类样本之间进行随机线性插值生成新样本,来达到平衡数据集的目的。算法原理如下:
(1)对于每一个少数类样本Xi(i=1,2,…,n),根据欧氏距离计算出最近邻的k个少数类样本(Y1,Y2,…,Yk)。
(2)从k个最近邻样本中随机选择若干个样本,在每个选出的样本Yi和原样本Xi之间进行随机线性插值,生成新样本Snew。插值方法计算式为
Snew=Xi+rand(0,1)(Yi-Xi)
(1)
式中 rand(0,1)——(0,1)区间内的随机数
(3)将新生成的样本加入原数据集中。SMOTE 算法是对随机过采样的一种改进方法,它简单有效,并且避免了过拟合的问题。根据选取的特征,对新的数据样本利用BP_Adaboost训练模型。
1.5 BP_Adaboost算法
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的弱分类器,然后把这些弱分类器集合起来构成一个更强的分类器, 而在 BP_Adaboost中弱分类器即BP神经网络[18-19]。
BP神经网络由输入层、隐含层和输出层构成[20],是一种从输入到输出的映射,通过用已知的模式对网络进行训练,就会得到一个能反映输入到输出之间精确映射关系的网络,特点是信号前向传播,误差反向传播。
建模过程中,初始学习率设置为0.000 1,既可以保证快速顺利找到损失函数的最小值,又不致于产生过大反复振荡。
其中,输入层为轨迹点特征,包括轨迹点经纬度、速度、半径r内近邻轨迹点个数、与近邻点平均距离和到近邻点的距离。由于各输入变量的单位不一致且数值范围相差较大,提前依据最大最小原则进行归一化。
输出层包含2个神经元,分别对应轨迹点状态。输出层中某神经元输出为1时,代表农机在田间作业,输出为-1时代表农机在道路行驶。
确定隐含层神经元个数[21]计算式为
(2)
式中h——隐含层神经元个数
n1——输入层神经元个数
n2——输出层神经元个数
a——可变系数
由式(2)可确定隐含层神经元个数为8。Adaboost算法本身是通过改变数据分布来实现的,它根据每次训练集中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改过权值的新数据集送到下层分类器进行训练,最后将每次得到的分类器融合在一起,作为最后的决策分类器。
开始时,每个样本对应的权重是相同的,即其中n为样本个数,在此样本下训练出第1个弱分类器,对于分类错误的样本,加大其对应的权值,而对于分类正确的样本,降低其权重。从而得到一个新的样本分布,再次对样本进行训练,得到第2个弱分类器,以此类推,T次循环得到T个弱分类器。最后将弱分类器联合起来,使用加权的投票机制代替平均投票机制。让分类效果好的弱分类器具有较大的权重,而分类效果差的分类器具有较小的权重。
算法步骤如下:
(1)从样本空间中随机选择m组训练数据,初始化测试数据的分布权值
(3)
根据确定好的神经网络结构,初始化BP神经网络权值和阈值。
(2)用训练数据训练BP神经网络并且预测训练数据输出,得到预测序列g(t)的预测误差和et,et的计算公式为
(4)
式中g(t)——预测分类结果
y——期望分类结果
(3)根据步骤(2)中得到的et,计算序列的权重αt,权重计算公式为
(5)
(4)调整下一轮训练样本的权重,调整公式为
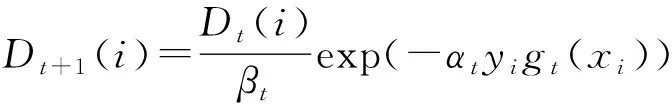
(6)
式中βt——归一化因子
保证在权重比例不变的情况下使分布权值和为1。
(5)用BP神经网络训练T轮后得到T组弱分类函数f(gt,αt),由T组弱分类函数f(gt,αt)组合得到了强分类函数h(x)。
选取农机运行轨迹点经纬度、速度、近邻点平均距离等作为特征,对作业轨迹点进行标记,选取80%作为训练样本,利用BP_Adaboost算法得到训练模型,对所有轨迹点进行识别。BP_Adaboost算法对轨迹点识别效果要好于只依靠经纬度信息聚类的DBSCAN算法,但农机多,工作时间长,产生的轨迹点多,对轨迹点标记耗时耗力,容易出错。不同农机不同作业地块行驶轨迹不同,对新的农机轨迹识别需要重新标记,推广适用性不强。
1.6 DBSCAN+BP_Adaboost算法
研究大量农机作业轨迹数据发现,由于农机在道路行驶过程中折返行驶、转向、减速等原因导致轨迹点密度变大,使该处轨迹被误识别为田间作业轨迹,另外部分田间轨迹与道路轨迹交界处也容易将道路行驶轨迹点识别为田间作业轨迹点。总体而言,聚类算法的误识别集中在将道路轨迹误识别为田间轨迹。DBSCAN方法对大多数轨迹点分类准确,利用聚类得到的类别信息,通过BP_Adaboost集成弱分类器训练,并将类别变换处附近轨迹点权重设置一个小的置信值,得到分类器模型后对轨迹点状态进行识别。再对得到的轨迹点进行处理后重新训练,直至识别结果不发生变化。
1.7 地块划分
将识别后带类别标记的轨迹点按时序遍历,当轨迹点类别标记为田间作业轨迹时,放入地块序列,查找后续轨迹点,若类别标记不发生变化,放入同一个序列;若类别标记发生变化,查找到下一个地块标记轨迹点,放入新的地块序列。当下一地块轨迹点距离超过5倍平均距离时,说明遇到轨迹点丢失,将下一轨迹点放入新地块序列。
遍历完所有轨迹点后,得到多个地块序列,每个序列内的轨迹点属于同一个地块。为防止同一地块因出现断点或轨迹点状态识别错误导致被误分成多个地块,计算各地块轨迹点与其他地块轨迹点距离最小值,若小于3倍平均距离,将2地块合并为同一地块。直至地块数量无变化。
具体步骤如下:
(1)按时序遍历所有带状态标记的轨迹点。
(2)找到第1个地块标记轨迹点,放入地块序列中。
(3)将其后所有地块标记轨迹点放入同一序列,直至查找到道路标记轨迹点。
(4)继续遍历,查找到下一个地块标记轨迹点,计算该点到上一地块序列轨迹点最小距离是否小于3倍平均距离,若小于,则将该点放入上一地块序列;否则,放入新地块序列。
(5)重复步骤(3)、(4),直至遍历完所有轨迹点。
(6)计算某一地块序列内轨迹点与其他地块序列轨迹点距离最小值是否小于3倍平均距离,若小于,按时序合并2个地块序列。
(7)重复步骤(6),直至地块序列数量不发生变化。
2 实验
2.1 数据获取
实验采用某县50台农机在2020年10月15—26日期间所有作业数据作为数据集,作业地块数量为5 304。在农机上安装采集设备,每5 s采集一次作业点数据,总轨迹点数为5 196 782,通过无线通信发送至后端服务器。每个轨迹点包含农机作业点经纬度、速度等信息。实验采用经纬度、速度、3倍平均距离内近邻点数量、轨迹点周围20个点距离作为特征,利用DBSCAN对轨迹点聚类,将得到的特征及类标记用BP_Adaboost算法训练模型,识别农机运行状态。
2.2 轨迹状态识别及地块划分
将获取到的轨迹点数据进行如下步骤处理:
(1)将采集的轨迹点做预处理,并提取特征。
(2)使用DBSCAN算法对轨迹点聚类,得到道路轨迹和田间轨迹。
(3)将前后标记发生变化的轨迹点及前后10个轨迹点权重减半。
(4)使用smote方法增加道路行驶轨迹点样本数量。
(5)选取80%轨迹点作为训练样本,全部轨迹点为测试样本。
(6)选取轨迹点经纬度、速度、3倍平均距离内近邻点数量、轨迹点周围n个点距离作为特征,利用BP_Adaboost训练数据集,并对测试样本进行轨迹状态识别。
(7)将识别的每天轨迹点中前后标记发生变化的轨迹点及前后10个轨迹点标记为道路轨迹点,并放入训练样本中。
(8)重复步骤(6)、(7),直至训练样本数量不发生变化。
(9)根据时序关系和轨迹点类别划分地块。
对数据采用本文方法和DBSCAN方法分别做实验,将轨迹点加载到地图中,根据地图中轨迹点位置和行驶轨迹,人工对轨迹点状态进行标记。总轨迹点数为5 196 782,其中田间作业轨迹点数量为3 162 468,道路行驶轨迹点数量为2 034 314。轨迹点状态识别结果如表1所示,其中田间作业轨迹点记为T,道路行驶轨迹点记为D。
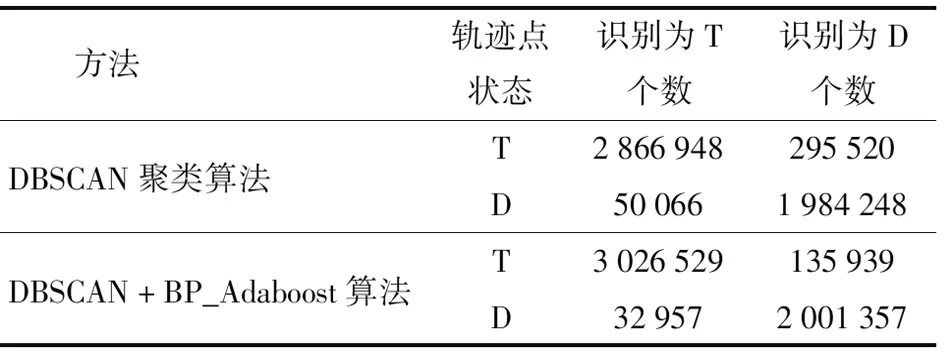
表1 轨迹点状态各方法识别结果Tab.1 Recognition results of each method of track point state
轨迹点识别正确的数量为田间轨迹点识别为田间轨迹点个数与道路轨迹点识别为道路轨迹点个数之和。轨迹点状态识别准确率P为
(7)
式中T11——田间作业轨迹点识别正确数量
T22——道路行驶轨迹点识别正确数量
T——轨迹点总数量
用DBSCAN算法对轨迹点状态识别准确率为93.35%,用DBSCAN+BP_Adaboost算法对轨迹点状态识别准确率为96.75%。因此本文算法得到的轨迹点状态识别准确率高于DBSCAN算法。
当DBSCAN算法选取不同参数时,轨迹点识别准确率如图4所示。
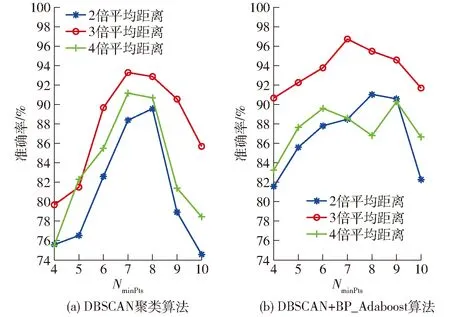
图4 不同参数下两算法轨迹点识别准确率Fig.4 Accuracy of two methods for track point recognition under different parameters
由图4可以看出,本文方法依托于DBSCAN算法,走势和DBSCAN算法有相关性,整体优于DBSCAN算法,并且准确率变化受参数影响小于DBSCAN算法。
使用密度聚类方法识别轨迹点状态的同时,根据点簇聚集关系划分不同地块。使用本研究方法得到轨迹点状态后,需再按照地块划分步骤进行划分,得到地块划分效果如图5所示。

图5 不同算法划分地块效果图Fig.5 Effect drawing of dividing plots by two methods
图5中灰色点表示道路行驶轨迹点,彩色点表示田间作业轨迹点,不同颜色表示不同地块。由 图5a 可以看到,部分道路行驶轨迹点被识别为田间作业轨迹点,下方绿色区域多个不同地块被聚类成一个地块。由图5b可以看到,使用本文方法划分地块,准确率高于只用DBSCAN算法。个别地块紧邻,由于阈值设置原因,DBSCAN算法无法将两地块区分。用本方法能识别出两地块间转移行驶轨迹,进而可以很好地精细划分地块。
地块划分错误分为4种类型:非地块误识别为地块、地块未被识别出、多个地块被识别成一个地块和一个地块被识别成多个地块。
其中,多个地块被识别成一个地块可以归为地块未被识别出;一个地块被识别成多个地块,可以归为非地块误识别成地块。
因此地块识别准确率R为
(8)
式中T0——识别正确的地块数量
Tf——总地块数量
错误识别量为
En=T1+T2
(9)
式中T1——非地块误识别成地块和一个地块被识别成多个地块的数量
T2——地块未被识别出和多个地块被识别成一个地块的数量
另外
Tf≤T0+T1+T2
(10)
由于错误识别的数量和作业地块的数量没有关联性,因此地块识别的准确程度由地块识别准确率和错误识别个数组成。两算法划分地块结果如表2所示。

表2 不同算法划分地块结果Tab.2 Results of dividing plots by two methods
由表2可知,由于非地块区域为道路行驶轨迹点,将道路行驶轨迹点误识别为田间作业轨迹点会错分成地块,而道路行驶轨迹点识别正确仍旧是轨迹点而不是地块,因此不存在非地块识别为非地块的数量。通过DBSCAN算法得到地块识别准确数为5 072,准确率为95.63%,误识别个数为592;通过DBSCAN+BP_Adaboost算法得到地块识别准确数为5 184,准确率为97.74%,误识别个数为339。因此在识别准确率和误识别个数方面,DBSCAN+BP_Adaboost算法都优于DBSCAN聚类算法。
本文提出的先通过DBSCAN算法得到轨迹点类别,再对轨迹点通过BP_Adaboost算法训练,轨迹点状态识别准确率高于只使用DBSCAN算法,且省去了大量人工标记的时间。后期有新农机作业轨迹识别,可以直接使用本方法,适用性较强。地块的划分准确率高于基于密度聚类方法,且错分的地块数量也少于基于密度聚类的方法。
3 结论
(1)分析了农机作业轨迹特征及轨迹点有用信息,选取农机轨迹点经纬度、速度、近邻点关系等作为特征,实验证明特征有效。
(2)利用DBSCAN算法对农机轨迹点聚类,得到带类别标记的田间作业轨迹点和道路行驶轨迹点;再用BP_Adaboost算法建立训练模型对农机轨迹点进行识别;将容易误识别的道路和田间交界处附近轨迹点标记为道路行驶轨迹点,并添加到训练样本中重复训练,直至训练样本不再增加。轨迹点状态识别准确率达到96.75%,较DBSCAN算法有很大提升。
(3)本文算法划分地块较DBSCAN算法聚类后得到的地块更准确,错分的地块数量更少。无需对样本标记,节省大量人力,并且对新农机作业轨迹有适用性。
