基于植物电子病历多类型数据融合的作物病害诊断方法
2023-03-07丁俊琦张领先
丁俊琦 李 博 乔 岩 张领先
(1.中国农业大学信息与电气工程学院, 北京 100083; 2.北京信息科技大学经济管理学院, 北京 100083;3.北京市植物保护站, 北京 100029)
0 引言
为了帮助农户减少作物病害损失,植物诊所(由国际农业和生物科学中心(CABI)领导的全球性计划Plantwise在全球30多个国家开设植物诊所,建立了由专业植物医生管理的全球植物诊所网络)通过为农民提供植物健康咨询服务,对亚洲、非洲和美洲3 100多万用户的生活产生了积极影响。经过专门培训的植物医生对作物疾病进行诊断,并为前来咨询的农民提出建议。这些诊疗活动细节被记录为植物电子病历(Electronic medical record, EMR),输入植物智慧(Plantwise)知识库中。植物电子病历记录了农户在农作物种植过程中遇到的病虫害问题及植物医生提供的诊疗建议。通过制定结构化病历模板,植物诊所实现病历数据的规范化书写和数据采集。这些数据以结构化和非结构化文本的形式储存了大量病害症状、作物情况和环境特征的信息,并且带有植物医生的诊断标签,为病害的智能辅助诊断研究提供了完整样本[1],如何对其进行有效挖掘以实现智能辅助诊断是一个亟待解决的问题。
在农业领域,信息管理系统在植物病害防治机构中还未普及,植物电子病历还没有得到足够重视。而在医学领域,已有大量利用电子病历实现计算机辅助疾病诊断的研究[2-4]。在不同的疾病诊断上,将疾病诊断问题转换为不同疾病病历的分类问题,这些研究证明了电子病历在辅助诊断方面的价值,为探索基于植物电子病历的病害智能诊断提供了方法参考。先前工作利用决策树[5-6]、支持向量机[7]、贝叶斯网络[8]、词嵌入和各种神经网络模型[9]来挖掘病历信息,进而实现分类。但这些方法存在难以区分词语多义性或者需要学习大量参数的问题,基于预训练的深度学习模型可以有效地解决这一问题[10],如语言模型词向量(Embeddings from language models,ELMo)[11]、生成式预训练(Generative pre-training,GPT)[12]、基于Transformer的双向编码器表示(Bidirectional encoder representations from Transformer,BERT)[13]等。另一方面,植物电子病历需要由专业植物医生标记和录入,样本量较少且缺乏公开数据集。针对此问题,预训练语言模型无需人工标签,可以从海量的语料中学习到通用的语言表示,在公开数据集较少的农业病害领域非常适用。如,杨国峰等[14]将BERT用于作物病害问答系统,李林等[15]将BERT与堆叠式长短期记忆网络(Long short term memory networks,LSTM)模型结合用于解决农业病虫害问句分类的语料稀缺问题。
但植物电子病历不是简单的文本描述,而是经过科学设计的、符合植物病理学中病害诊断基本原理的规范结构,包含结构化的地理、时间、环境、分布等特征。研究证明,病害发生的环境特征、时空分布等信息对病害的准确识别意义重大,但是这些信息在病害智能诊断的研究中尚未得到有效利用[16-17]。如果仅聚焦于植物电子病历中的单一类型数据,仅对问诊记录文本进行特征抽取,将会造成大量多类型结构化数据的信息损失。
综上,植物电子病历缺乏公开数据集,样本量较少,且包含多种数据类型。针对这些特点,本文提出一种基于多类型数据融合的病害诊断模型(BERT-MPL data fusion model based on attention mechanism,BM-Att),通过预训练模型和不同数据分支的特征融合,多维度、全方位地对植物电子病历中的信息进行抽取,进而实现病害准确诊断。
1 数据描述与处理
1.1 数据来源
本文植物电子病历样本来源于北京市植保站所建立的115家植物诊所线上诊断系统。植物诊所依托合作社、绿控基地、专业化防治组织等社会化主体,覆盖北京市昌平、延庆、顺义、平谷、密云、房山、通州、大兴、怀柔、海淀等10个区。
植物诊所采用公益性的农作物病虫诊断与咨询服务模式,由具备资质的植物医生为农户提供病虫害诊断和防治技术服务并记录开方。所有植物电子病历经过“植物医生填写录入——区级数据管理员初步协调验证——市级数据管理员二次协调验证”的三级数据验证程序导入数据库(图1)。
1.2 数据分析
植物诊所开具的电子病历记录了农户在农作物种植过程中遇到的病虫害问题及植物医生提供的诊疗建议,包括问诊农户、植物诊所、作物和症状的详细信息,以及诊断结果和病虫害防治建议等内容。其中不仅有结构化的信息,如就诊时间、诊所位置、发病时间、发病面积等,还包括非结构化的自由文本信息,如主要症状、检查所见、诊断结果、治疗建议等,如图1所示。本文收集了2017年11月到2021年7月期间约44个月的数据,共44 000余条作物病害电子病历。本文获取的样本共包含89种病害,涉及46种植物。初步分析数据发现,北京市种植植物种类和病害种类繁多,但是大多数作物及相关病害的数量占总样本量比例在1%以下,样本量仅几十条,属于冷门作物或不常见病害。从过少的样本中无法提取足够的有效信息以支持智能诊断,因此本文选择常见作物的常见病害为研究对象。常见的种植作物包括番茄、黄瓜、生菜和西瓜,共占全部样本的95.68%。其次,在这4种作物的相关病害中选择样本量大于400条的病害,共15种,占全部样本的74.69%。具体包括:番茄晚疫病、番茄病毒病、黄瓜霜霉病、番茄灰霉病、黄瓜角斑病、黄瓜白粉病、番茄线虫、番茄早疫病、番茄叶霉病、西瓜炭疽病、生菜线虫、黄瓜灰霉病、生菜霜霉病、黄瓜线虫和西瓜线虫。其中番茄病害6种、黄瓜病害5种、生菜病害和西瓜病害各2种。相比原始数据,这样的选择尽可能地覆盖了北京市常见作物病害,同时极大减缓了样本过少导致的误诊问题。
1.3 数据预处理
研究中未获取原始植物电子病历中涉及个人隐私的信息,例如农户姓名、手机号、身份证号码等。此外,由于数据存在冗余、缺失等问题,剔除了部分缺失率过高的记录和字段,对冗余记录进行了去重处理。
对于电子病历的非结构化数据部分,采用正则表达式、字符匹配等方法提取了问诊记录中的主诉部分,并且对空格、换行等字符进行清理。对于电子病历的结构化数据部分,进行删除重复值、缺失值处理、一致化处理和异常值处理等操作。
经过上述清洗和筛选,最终获得22 842条数据。每种病害的具体数据统计结果如图2所示。其中,番茄晚疫病和番茄病毒病为较大样本病害,数量超过4 000条;黄瓜霜霉病、番茄灰霉病、黄瓜角斑病和黄瓜白粉病次之,数量在1 000条以上;番茄线虫、番茄早疫病、番茄叶霉病、西瓜炭疽病、生菜线虫、黄瓜灰霉病、生菜霜霉病、黄瓜线虫和西瓜线虫为小样本病害,数量在1 000条以下。

图2 数据统计结果Fig.2 Statistical results
利用分层抽样的方法,选取60%的数据作为训练集来训练模型,20%作为测试集,20%作为验证集。数据处理流程如图3所示。

图3 数据处理流程图Fig.3 Data pre-processing flowchart
2 病害诊断方法
2.1 模型结构
为了融合不同类型结构的数据,提出了一种用于病害诊断的多类型数据融合深度学习模型BM-Att。通过结构化和非结构化数据之间优势互补,可以使融合后的效果超过任意单一类型数据能够达到的效果。其主要包含:文本数据处理模块和结构化数据处理模块。模型整体架构如图4所示,文本数据处理模块采用预训练语言模型对电子病历中的问诊记录进行建模。结构化数据处理模块基于电子病历中的作物种类、主要症状、生长阶段、发病部位、发病时间、地理位置、田间分布和严重程度等结构化数据进行建模,鉴于结构化数据的维度远低于文本数据,模型中加入多层感知器(Multi-layer perceptron, MLP)对结构化信息进行抽取,并将其扩增到适当的维度。最后进行基于注意力机制的特征融合,综合了结构化数据分支和文本分支获得的关键特征进行预测。
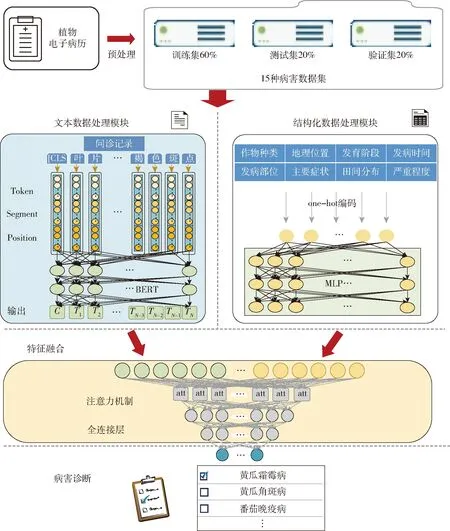
图4 基于多类型数据融合的病害诊断模型框架Fig.4 Framework of a disease diagnosis model based on fusion of multiple types of data
2.2 文本数据处理分支
植物电子病历问诊记录描述了病害的主要症状和外界环境,其中包含了大量信息,采用合适的算法对这些记录关键信息进行提取有利于更好地诊断作物病害。但是受限于植物电子病历数据数量的不足,难以获得足够信息实现有效的语义信息抽取。预训练语言模型的发展将自然语言处理(Natural language processing,NLP)领域的研究提升到了一个新的阶段,即无需人工标签,可以从海量的语料中学习到通用的语言表示,并显著提升下游的任务[18]。BERT是2018年谷歌人工智能(Google AI)团队提出的在大规模通用领域语料库预先训练的语言模型,通过对下游任务进行微调的方式,在各种文本分类任务上有着明显的改进[19-20]。
BERT是由双向变换器(Transformer)模型组成的编码结构。Transformer用作特征提取器,它比LSTM特征提取功能更强大。同时,多层双向Transformer可以提取上下文的文本特征[21]。相比使用单向 Transformer的GPT和双向LSTM编码的ELMO,BERT通过使用双向变压器编码器提取上下文特征,该编码器具有更深的层次和更好的并行性[13]。多头注意力机制是Transformer层的核心,其主要思想是通过计算词与词之间的关联度来调整词的权重,反映了该词与这句话中所有词之间的相互关系以及每个词的重要程度。首先,输入序列T,通过线性变换得到目标矩阵Q、上下文矩阵K以及原始矩阵V。然后通过计算放缩点积求得自注意力(Self-attention)的分数值,该分数值决定了当模型对一个词进行编码时,对输入句子的其他词的关注程度,具体计算公式为
(1)
式中dk——输入维度
最后,将经过i次计算的Self-attention分数值进行拼接和线性变换,最终获得一个与原始字向量长度相同的增强语义向量,作为多头注意力层的输出,具体计算公式为
MultiHead(Q,K,V)=Concat(h1,h2,…,hi)W0
(2)
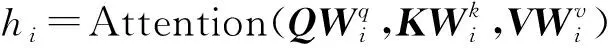
(3)
式中hi——多头注意力层的输出



W0——附加的权重矩阵
BERT已在多个下游NLP任务(例如机器翻译,命名实体识别、文本分类、阅读理解和问题解答)中取得了显著的效果。在本文的实验中, 使用了谷歌发布的中文预训练模型“BERT-Base, Chinese”。该模型采用了12层的Transformer, 输出为768维度的向量, 多头注意力的参数为12, 模型总参数量为110 MB, 共包含约2万个中文简体字和繁体字, 含有部分英文单词和数字。将模型载入后, 可以直接输出训练好的字向量或句向量。本文使用该模型获取句向量并将其作为后续网络模型的部分输入。
2.3 结构化数据处理分支
针对结构化的数据,首先对其进行独热编码,即1位有效编码。独热编码使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且其中只有1位有效。本文对电子病历中的作物种类、主要症状、生长阶段、发病部位、发病时间、地理位置、田间分布和严重程度等特征完成独热编码。例如,将生长阶段属性对应的苗期、生长期、开花期、结果期、成熟期、收获期共6个阶段转换为6位的标签值。具体编码内容如图5所示。

图5 编码鱼骨图Fig.5 Fishbone diagram of data coding
对植物电子病历中的结构化数据完成编码后,得到107维的向量。与文本分支得到的768维向量相比,维度差异较大。为了避免低维度的信息被高维度的信息淹没,减少数据融合前的信息损失,需要在数据融合之前增加低维模态[22-23]。因此,本文进一步采用MLP来扩增结构化数据向量表示的维度。
本文所使用MLP网络共有107个输入节点,512个输出节点,以及3层包括512个隐藏节点的隐藏层。通过输入层、隐藏层、输出层进行前向传播得到预测值,利用均方误差(MSE)损失函数来衡量真实值和预测值之间的误差。MSE损失函数利用梯度下降的方法来不断更新权重参数和偏置参数,不断缩小误差,最终获取和真实值最接近的预测结果。
2.4 特征融合
对于文本数据,BERT将每条问诊记录转换为768维向量作为特征表示。同时,为了确保不同数据可以在相同尺度上被融合,结构化数据处理模块将107维的结构化数据扩增到512维进行特征表示。得到每种类型数据的向量表示之后,一般而言,有多种进行向量融合的方法,例如相加、相乘、拼接等。由于向量拼接能够最大程度地保留不同向量中的信息,因此选择拼接的方式。拼接后形成1 280维向量。然后,使用注意力机制和3层全连接层抽取重要的特征,同时对向量进行适当压缩。最后使用一个带有Sigmoid激活函数的神经元对作物病害进行判断。本文使用的注意力机制是在拼接向量fij的基础上,计算每一个元素的概率权重αij,即uij和fij之间的映射。
uij=tanh(Wfij)
(4)
(5)
(6)
式中W——参数矩阵,需要从训练数据里学习
c——最后注意力,由权重和相应的键值进行加权求和得到
uij——隐藏表示
uw——上下文向量,需从训练数据里学习
3 实验设计与结果分析
3.1 实验环境
本研究分类模型实验是基于Pytorch的深度学习库实现的。所有模型都采用NVIDIA Quadro P2000 GPU(5GB)训练。
文本数据处理分支里对输入文本进行长截短填,将输入数据的最大文本长度(Pad-size)设定为80。若文本真实长度小于Pad-size,则用0填充;若文本真实长度超出Pad-size,则截断至Pad-size。为了防止过度拟合,加入了0.1的Dropout。
训练过程中使用随机梯度下降法,经过多次参数调整,最终将学习率设置为3×10-5。训练共进行4个Epoch(每个Epoch约900次迭代),批量大小设置为16,并对所有的参数应用权重衰减为0.01的L2正则化。
3.2 评价指标
由于作物病害诊断数据集的不平衡性,准确率作为评价指标容易产生误导,F1值(F1-score)更适用作为不平衡数据集分类任务的模型评价指标。因此,本文采用精确率(Precision)、召回率(Recall)、F1值和准确率(ACC)来评价模型对不同病害的分类效果,并使用宏平均法来评估模型的整体性能。此外,还使用混淆矩阵来检查每种作物病害诊断正确率。
3.3 实验结果
3.3.1消融实验
本研究构建的BM-Att模型核心在于文本数据和结构化数据的特征提取和融合,通过添加处理结构化数据的MLP模块和特征融合阶段的注意力模块改进基于BERT的原始诊断模型。为了验证提出的BM-Att病害诊断模型的有效性,在15种病害数据集上进行了消融实验研究,并使用测试集评估模型性能。在模型训练中,使用仅处理文本数据的BERT作为基线模型,分别通过添加结构化数据处理分支和注意力机制方式优化BERT模型,得到BERT-MLP和BERT-Att 2个优化模型。最后,通过在处理文本数据的BERT模型之外,同时添加处理结构化数据的MPL模块和数据融合后的注意力机制获得BM-Att(BERT+MLP+Att)。表1为不同模型诊断结果的准确率、精确率、召回率和F1值。

表1 各模型消融实验结果对比Tab.1 Comparison of each model in ablation studies %
结果表明,消融实验中的各个模型结果的F1值都优于仅处理文本数据的原始BERT,并且本文提出的BM-Att模型准确率最高。
相对于BERT模型,BERT-MLP模型的准确率、精确率、召回率和F1值分别提高1.16、1.27、2.28、1.91个百分点,主要由于结构化数据带来的不同于文本数据的信息,为病害诊断特征融合模型提供了有效基础。
相对于BERT模型,BERT-Att模型的精确率、召回率和F1值分别提高1.23、0.22、0.22个百分点,但是准确率略有下降,整体变化不大。主要由于BERT预训练语言模型的Transformer层包含多头注意力机制,能够有效提取文本语义特征,并在下游分类任务上实现很好的效果,额外添加注意力机制没有太大变化。
相对于BERT模型,BM-Att模型的准确率、精确率、召回率和F1值分别提高1.59、2.8、3.5、3.38个百分点,F1值宏平均值达到95.85%,主要由于添加了MLP结构化数据处理模块和在特征融合阶段添加注意力机制能够有效改进融合效果。
3.3.2单文本分支影响
植物电子病历中的文本数据包含了大量重要信息,能否对其进行有效提取是实现病害智能诊断的关键。为了验证提出的BM-Att模型在文本信息提取方面的有效性,比较多种具有代表性的文本数据处理模型。在15种常见作物病害数据集上,对比了BERT语言模型同其它处理文本数据的常见模型:CNN、RCNN、带有注意力机制的RNN(AttRNN)、FastText、Transformer和ERNIE。表2为不同模型诊断结果的精确率、召回率、F1值和准确率。

表2 文本分支模型结果对比Tab.2 Comparison of model results of text branches %
结果显示,本文提出的模型在所有指标上均取得了最好的结果,在测试集的准确率、精确率、召回率和F1值的宏平均值分别达到95.82%、96.38%、95.48%和95.85%,准确率比ERNIE高出1.49个百分点,F1值比BERT高出3.38个百分点,这证明了结构化数据的加入有助于诊断准确率的提升。
在其它模型中,基于预训练的深度学习模型BERT和ERNIE取得了最好的效果。具体来说,BERT取得了更高的精确率和F1值,分别达到93.58%和92.47%,而ERNIE取得了更好的召回率和准确率,分别达到92.44%和94.33%。预训练语言模型可以从海量的语料中学习到通用的语言表示,并显著提升深度学习在下游NLP任务中的表现[18]。
3.3.3结构化数据影响
经过one-hot编码,植物电子病历中的结构化数据转换为一维数据。为了验证所提出的BM-Att模型对一维数据信息提取的有效性,比较了结构化数据的不同处理方式对模型效果的影响。所提出的BM-Att模型在结构化数据处理分支采用的是MLP模型,将其与具有代表性的一维数据分类模型进行比较,包括一维ALEX、一维卷积神经网络(1dCNN)、一维长短期记忆网络(1dLSTM)和基于注意力机制的一维长短期记忆网络(1dAttLSTM)。在实验中,选择文本分支中效果较好的2种预训练模型BERT和ERNIE作为基础模型,添加上述5种处理方式的结构化数据分支,对比不同数据融合模型的诊断效果。表3为BERT-ALEX、BERT-1dCNN、BERT-1dLSTM、BERT-1dAttLSTM、BERT-MLP、ERNIE-ALEX、ERNIE-1dCNN、ERNIE-1dLSTM、ERNIE-1dAttLSTM、ERNIE-MLP等模型在测试集上的准确率、精确率、召回率和F1值。
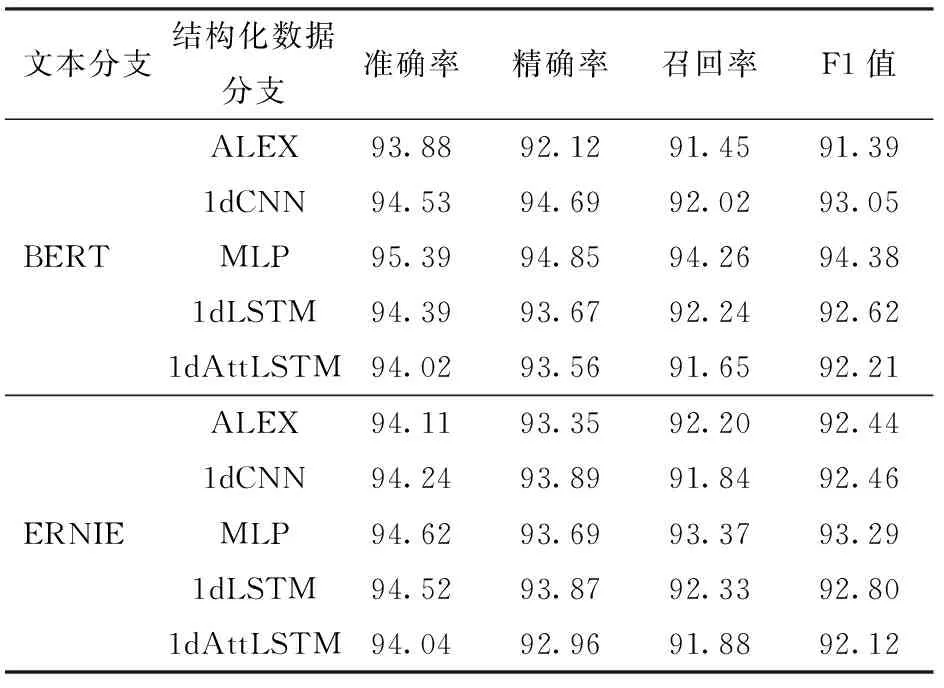
表3 结构化数据分支模型结果对比Tab.3 Comparison of model results for structured data branches %
结果显示,不管文本处理分支采用的是BERT还是ERNIE,相比ALEX、1dCNN、1dLSTM以及基于注意力机制的1dLSTM(1dAttLSTM),MLP均取得了最好的结果。尤其是BERT-MLP,F1值和准确率分别为94.38%和95.39%。对于植物电子病历,结构化数据分支处理的是低维度数据。一般来说,MPL简明的结构适用于一维数据并且在高噪声条件下表现良好,在医学诊断领域有着广泛应用[24-26]。
3.3.4注意力机制影响
表4为注意力机制对模型的影响。在数据融合阶段,BM-Att模型引入注意力机制提取重要特征,以优化特征融合效果。结果显示,注意力机制在各项指标上均提升了模型的分类效果。相比没有添加注意力机制的模型,在数据融合阶段增加注意力层的模型在大多数病害类别上达到了更好的分类效果。尤其是对于生菜、西瓜等小样本病害,诊断效果有了明显的改进,将西瓜线虫诊断的F1值从90.64%提高到100%。从整体上看,F1值的宏平均值提高1.47个百分点,F1加权平均值和准确率分别提高0.42、0.43个百分点。相比加权平均值,宏平均值更加注重模型对不平衡数据集中较小样本的分类效果。注意力机制通过权重分配融合全局信息,选择性地强调关键特征,发掘模型对不同类别数据特征的关注点,改进了模型的重要特征提取能力[27-28]。在数据融合阶段添加的注意力机制让模型对于小样本病害投入了更多的关注,这对病害智能诊断的实际应用具有重要意义。

表4 注意力机制影响对比Tab.4 Comparison of effects of attentional mechanisms %
4 结论
(1)针对电子病历中的文本数据部分,采用预训练BERT语言模型提取深层语义特征。对比CNN、RCNN、带有注意力机制的RNN、FastText、Transformer、ERNIE和BERT模型,发现与传统深度学习模型相比,基于预训练的BERT语言模型取得了好的效果,F1值达到92.47%。原因是预训练语言模型可以从海量的语料中学习到通用的语言表示,能更好地提取文本中的重要信息。
(2)针对电子病历中的结构化数据部分,对比不同处理方式对模型效果的影响,结果显示,不管文本处理分支采用的是BERT还是ERNIE,在结构化数据分支采用MLP均为最佳选择。相比ALEX、1dCNN、1dLSTM以及基于注意力机制的1dAttLSTM等复杂网络,MPL的多层全连接层结构对于编码形成的低维度数据更加简明有效。
(3)在数据融合阶段添加注意力机制,通过权重分配强调关键信息特征,发掘模型对不同类别数据特征的关注点,改进了模型对重要特征的提取能力,将F1值宏平均值提高1.47个百分点。更重要的是,注意力机制能显著改进模型对小样本类别的分类效果,将西瓜线虫诊断的F1值从90.64%提高到100%,对于病害智能诊断的实际应用具有重要意义。
(4)综合来看,本文提出的方法在基于植物电子病历的15种常见作物病害的诊断任务上结果最佳,在所有指标上均取得了最好的结果,F1值宏平均值和准确率分别达到95.85%和95.82%,表明本文模型能够实现作物病害的有效诊断。
