基于网络结构特征的大规模虚假评论群组识别
2023-03-02魏瑾瑞王若彤
魏瑾瑞, 王若彤, 王 晗
(1.东北财经大学 统计学院,辽宁 大连 116025; 2.北京师范大学 统计学院,北京 100000)
0 引言
近年来,随着电子商务的迅速发展,虚假评论的规模越发壮大,甚至形成虚假评论群组协同作案,因此,如何恰当识别虚假评论具有重要的现实意义[1]。李璐旸等系统综述了国内外虚假评论识别的现状,对比总结了特征设计、模型方法、数据集合评价指标等方面,探讨与展望了未来的识别研究方向[2]。虚假评论群组是指以共同目的协同发布虚假评论的个体组成的群体,相比虚假评论者个体影响力更大、隐蔽性更强,对检测方法的要求更高[3]。目前识别虚假评论的方法主要是参照评论内容的文本特征[4,5]和评论者的行为特征[6,7],但是文本特征的模仿成本较低,单纯依靠文本特征的识别已被证明效果有限;而依靠评论者行为特征的识别则需要有大量的历史行为数据支撑,对于只发表一条评价的用户,传统模型不能有效解决冷启动问题。事实上,大量虚假评论并非个体行为,而是有潜在组织的集体行为,评论者、目标商品和关联商品构成一个巨大的网络,因此,有不少研究开始转向对虚假评论群组的识别[8~15]。按识别方法的不同,可以区分为监督识别方法和非监督识别方法,其中,监督识别方法主要采用基于评论内容特征的识别方法[5],而非监督识别方法则根据识别特征不同可以分为单个虚假评论者特征、虚假评论群组特征[9,16]、时间序列特征[17]、评论模式特征[6]、行为分布特征[18]等。传统识别虚假评论群组主要利用评论内容的相似性和文本特征[8,9,12,14],也有学者开始转向结合群组结构分析的虚假评论群组检测[11,13,15]。例如,利用虚假评论者的网络足迹选择目标产品,进而通过挖掘目标产品背后所有评论者的评论信息来达到检测虚假评论群组的目的[11]。事实上,虚假评论群组与目标产品之间已然形成了一定的特殊关系,对于目标产品的选择并不是随机的,而是虚假评论群组背后的组织者经过深思熟虑后的决策。因此,尽管现实中很多评论内容和行为都可以伪造与模仿,但是用户之间的关系以及用户与产品之间的关系都存在某种确定的联系,本文尝试通过分析评论者的网络行为发现目标产品背后的虚假评论群组。
本文的改进之处在于:(1)基于评论者与产品之间的网络结构特征挖掘评论者的行为轨迹,通过构造2-hop子图生成模型识别虚假评论群组。(2)利用多次迭代的方式将相似性满足阈值的评论者放入对应的候选群组,从而在有效固定网络结构的动态变化的同时更加准确地识别潜藏较深的虚假评论群组。(3)采用两步探测方法,先筛选可疑目标产品所对应的高度相似的虚假评论者,再对剩余评论者聚类合并识别潜藏较深的虚假评论群组,这种做法在提高虚假评论识别精度的同时可以有效减少识别时长与复杂度。
1 网络结构特征
完美的虚假评论与真实评论无限接近,令反虚假系统无法识别。最新研究发现真假评论最大的区别在于网络层面的关系模式。虚假评论由于其有组织性会呈现出一定的统计规律。本文重点研究评论者-产品组成的评论网络中虚假评论者的网络结构特征,通过构造网络行为得分(Network Behavior Score)识别虚假评论群组,基于评论者与产品的关系计算PageRank值,根据得分高低识别无向图中节点之间的异常行为。本文提到的节点中心性是基于度中心性(Degree Centrality)和PageRank中心性(PageRankCentrality)的度量方式得出的结果,目的是利用这两项指标分别使用局部和全局信息量化无向图中各个节点的重要程度,进一步通过信息熵与散度量化评论者及评论产品的可疑性。
1.1 相邻节点的多样性
评论者-产品评论网络G包含了m个评论者节点U,n个产品节点p及连接它们的评论关系E,即G=(U,P,E)。评论者包括真实评论者和虚假评论者,产品包括目标产品和非目标产品,二者通过评论文本进行边的建立。假定一个评论者以文本方式对多个产品进行评论,不论是否真实均为有效评论。即在真实评论网络中,一个评论者可以对多种产品进行同一评论,也可以对一个产品进行多种评论,评论者与产品之间行为和对应关系是交错的,真实评论网络的相邻节点不应过分彼此依赖,基于相邻节点多样性可以分析评论者的相似性。当一组评论者的中心性值骤降至一个极小的区间时是非常可疑的。
对于一组给定的产品,为了量化它们相邻节点多样性的中心性,先将产品对应的评论者所有中心性的值分解,然后通过直方图来创建其密度的非参数估计,最后采用信息熵计算直方图的偏度,信息熵的计算公式为:
(1)
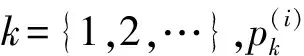
1.2 网络结构的自相似性
真实评论网络本身的自相似性决定了评论网络的部分内容往往拥有整个评论网络的相似属性。因此,可以利用这一结构特征测量虚假评论造成的分布失真。评论者中心性的直方图密度之间的KL散度可以表示为:
(2)
其中,P(i)表示产品的评论者的中心直方图分布,Q表示所有评论者的中心直方图分布。使用计算P(i)的方式来计算Q,通过自相似性结构特征指标中得到评论者的两个得分指标来分别表示中心性,分别为KLdeg(i)和KLpr(i)。分数越高,对应产品越可能是虚假评论的目标产品。
1.3 构造网络行为得分
为了量化产品受到虚假评论攻击的影响,利用累积分布函数整合Hdeg(i)、Hpr(i)、KLdeg(i)和KLpr(i)等四个得分指标。假设一组产品中心性的信息熵得分为Hc,则一个特定的Hc(i)经验累积分布函数可以表示成:
f(Hc(i))=P(H≤Hc(i))
(3)
同理有,
f(KLc(i))=1-P(KL≤KLc(i))
(4)
进而有,
f(H(i))=f(Hdeg(i))2+f(Hpr(i))2
(5)
f(KL(i))=f(KLdeg(i))2+f(KLpr(i))2
(6)
(7)

2 虚假评论群组识别
前一节通过计算一组产品i的网络行为得分来测量可疑目标产品的异常性。为了进一步反向识别虚假评论群组,我们建立一个包括最高网络行为得分的顶级产品P1、对应的评论者R及其评论的产品P2的子网,通过诱导以上k个可疑目标产品的所有评论者及其评论的产品得到一个2-hop子图。该2-hop子图可以用一个p×u的邻接矩阵A来表示,其中|P2|=p,|R|=u。
在判断虚假评论群组的存在性后,采用GroupStrainer算法[11]识别虚假评论群组。该算法通过重新组织所有成员识别虚假评论群组,能够有效降低识别失误率。值得注意的是,为了在提高识别精度的同时减少聚类算法负荷,我们先筛选出高度相似的虚假评论群组再进行聚类。由于整个识别过程中虚假评论群组数目未知,我们借助层次聚类方法将评论者反复迭代后合并成更大的群组并得到其嵌套层次结构。朴素层次聚类方法在每次迭代只能合并两个评论者,分析大规模评论数据效率低,因此采用局部敏感哈希算法(Locality Sensitive Hashing Algorithm)提高迭代过程的效率。本文通过选择多种哈希函数进行映射变换将数据点散列成签名矩阵,接着再散列签名矩阵,得到每个数据点被最终散列到相应的存储桶中,这样既能够确保原始数据点之间的相似性与他们签名相等的可能性成正比,也能够完全控制这种状况发生的概率。因此,两个数据点之间相似性越高,生成的签名匹配的可能性越大,被分散到相同存储桶中的概率也就越大。对于不同的相似性函数,局部敏感哈希算法会使用不同且适当的哈希函数。为减少哈希表的空间储存,运用Jaccard相似度的最小散列法和Cosine相似度的随机投影法。
3 实验与评价
3.1 实验设置
为了客观评估上述虚假评论群组识别算法的效果,采用亚马逊数据集进行实验分析。该数据集来源于大型电子商务平台亚马逊(https://www.amazon.cn/)在中国市场的实际评论,采集窗口是2010年1月1日至2013年12月31日,包括15个一级产品类别的525619个产品的产品信息、1424596个评评论者信息以及7202921条评论的评论信息。该数据集的每条评论样本都包含以下13个字段:评论者ID、产品ID、评论等级、一级类别ID、一级类别名称、二级类别ID、二级类别名称、评论日期、产品名称、评论标题、评论内容、评论标题长度和评论内容长度。
实验分析数据采集窗口期内前四类最畅销的产品,包括图书音像类、手机数码类、美妆个护类和家居生活类等四类。数据清洗时,如果原始数据中的评论者ID、评论等级、产品名称、评论标题和评论内容等这些关键字段有缺失、含异常值或为重复样本,则将其剔除。
将上述两类算法分别应用于四个数据集,计算对应所有产品的网络行为得分,根据网络行为得分的大小可以判断该产品是否为虚假评论群组所攻击的目标产品。以目标产品为种子诱导出评论网络的2-hop子图,再通过GroupStrainer算法识别评论网络中的虚假评论群组。
3.2 对比实验
为量化虚假评论群组的评论行为,引入虚假评论者共谋得分(Spammer Collusion Score)和虚假评论者共谋平均得分(Spammer Collusion Average Score):
(8)
(9)
其中,g表示数据集中的一个虚假评论群组,ri,rj分别为群组g中的两个虚假评论者,p(ri),p(rj)分别表示虚假评论者ri和rj攻击的目标产品,n为群组中虚假评论者的总数。虚假评论群组的共谋平均得分SCAS越高时,该群组的成员之间共谋性越强。
为了使实验更具说服力,本文使用HDBSCAN算法[19,20]、DBSCAN算法[20,21]、KMeans算法[21]以及GroupStrainer算法进行对比实验,结果表明四种聚类算法识别出的虚假评论群组个数以及共谋均分变化趋同,说明识别结果具有较好的稳健性。图1展示了四类产品数据集在四种不同方法下识别出的虚假评论群组个数以及各个产品数据集的共谋平均得分。以HDBSCAN算法的实验结果为例,四个数据集中隐藏的虚假评论群组的数量分别为7个、15个、40个和14个。
从各个产品类别的群组个数上来看,图书音像类产品是亚马逊平台的主导产品,评论者以及评论数量是最多的,但是虚假评论群组的数量却是最少的;相比较而言,美妆个护类产品的虚假评论群组反而是数量最多的,该类产品作为日耗品,主要面向女性消费群体,具有种类多、更换频率快、使用周期短等特征,因而其潜在市场价值高于图书音像类产品。同时,真实评论数量明显多于虚假评论,这符合我们对网络评论中虚假评论行为的基本预期:大多数评论还是真实可靠的。
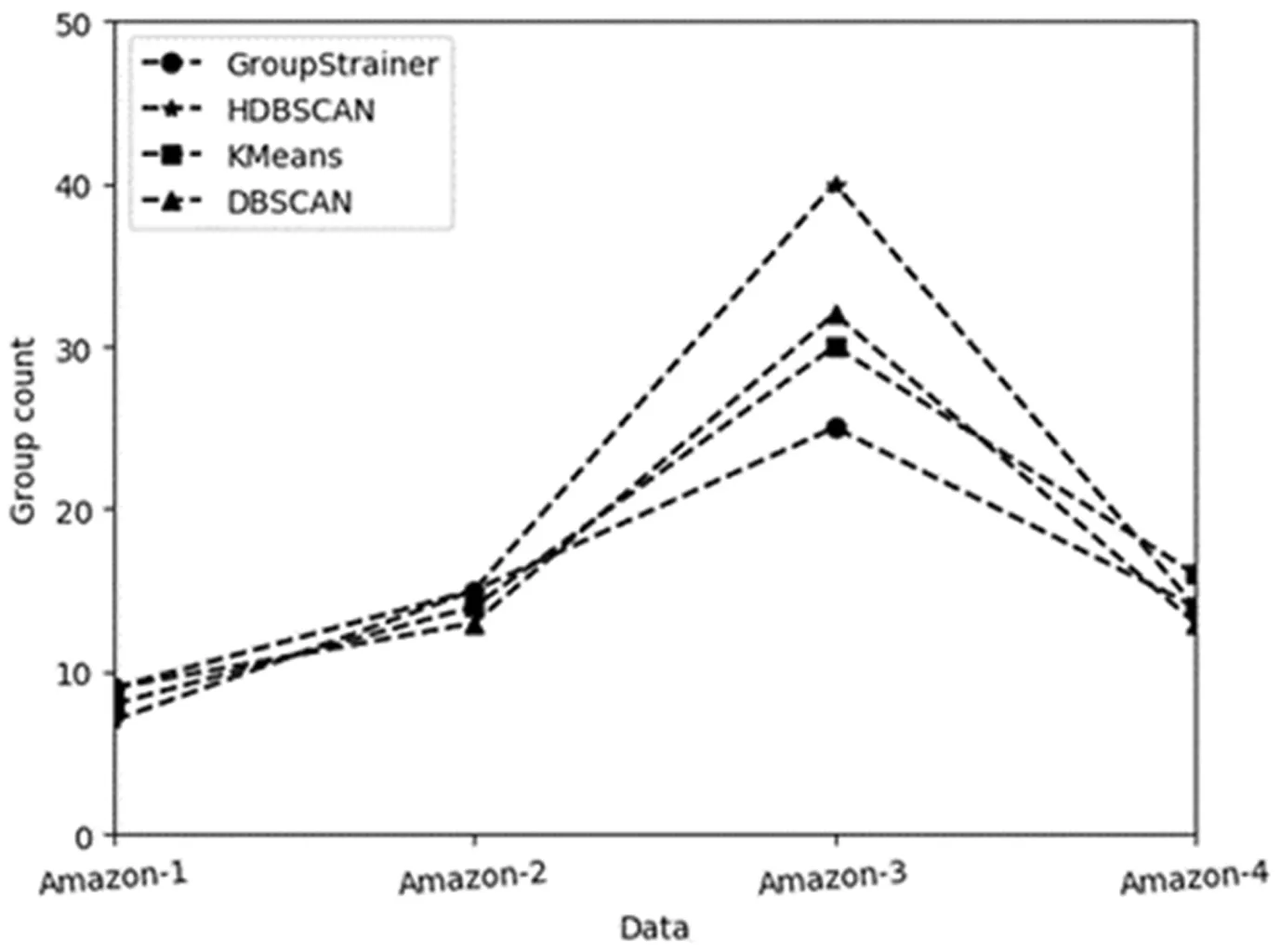

图1 四种聚类算法的比较
图2为四个数据集中产品信息熵与散度的关系,方框内为正常点,圆圈内为异常点,点与产品一一对应。以图书音像类产品为例,图2(a)和(b)分别表示其度中心性和PageRank中心性的信息熵与散度的关系,当KL散度越大且信息熵越小时,对应产品月的可疑性越高。同理,图(c)和(d)、(e)和(f)、(g)和(h)分别为手机数码类、美妆个护类和家居生活类产品的信息熵与KL散度的关系。综合来看,图书音像类与手机数码类产品中异常点明显多于其他两类产品,出于隐藏虚假评论行为的考虑,产品数量更多的类别可能存在更多可疑目标产品。进一步,以顶级产品P1为种子从前文建立的子网中诱导出2-hop子图。图书音像类和美妆个护类产品的共谋均分在0.57左右,说明这两类产品更受消费者青睐,虚假评论群组通过攻击部分非目标产品进行伪装以获得经济利益。手机数码类和家居生活类产品的共谋均分更高,伪装度更低,分别为0.83和1.00。
为进一步验证模型的准确性和稳健性,在前文的模型对比实验基础上,回溯并比较真假评论的统计特征差异。下图3为虚假评论与真实评论统计特征。评论等级为好评比例,评论日期是同时发布评论的比例,产品名称是目标产品占总产品数量的比例,重复评论是重复评论占所有评论的比例。此外,定义评论集中度为评论者与产品数量的比值,表示同一评论者评论同类产品的频率。可以发现,虚假评论的评论集中度是真实评论的3.3~5.7倍,其中手机数码类产品差异最大。该类产品变迁快,消费者盲区多,说明虚假评论群组偏好攻击消费者陌生的领域。从评论日期和重复评论来看,虚假评论的同质性非常明显,其中,图书音像类产品差异性最小。值得注意的是,虚假评论的评论等级与真实评论趋同,即虚假评论群组并非直接刷高评论等级,而是通过文本好评吸引消费者。事实上,价格相近的同种产品,如果店铺的好评率过高反而容易引起消费者怀疑。相比产品评论等级,消费者更青睐参考评论文本。此外,通过对比真假评论的网络结构可以发现,虚假评论的群组特征比真实评论更明显,呈现出有组织的网络结构。二者的区别在于评论者之间是否存在以目标产品为媒介的紧密关联。
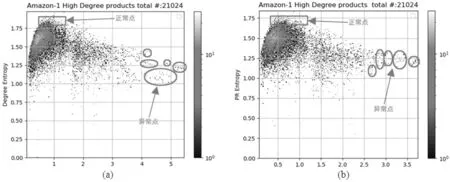



图2 四个数据集的信息熵与KL散度关系图

图3 虚假评论与真实评论统计特征对比
4 结论
随着购物评论生产的日益专业化和商业化,评论作为个人行为非常容易被模仿,因此基于个体层面的文本或行为特征识别往往容易引起误判。事实上,现实中识别虚假评论的目标并非止于单条评论的是非判断,而是追踪到虚假评论背后的组织者(被雇佣者)以及目标产品(雇佣者),从源头上予以警告和打击。不同于普通的社交网络,专业化的虚假评论是并发的集体行为,其目标产品选择不是随机决策,因此基于评论者与产品的网络结构特征可以很好地识别虚假评论群组,而且虚假评论群组的识别过程也可以一并筛查出其攻击的目标产品,可操作性更强。
根据样本的评论行为计算其所对应产品的相邻节点多样性与自相似性,通过累积分布函数估算二者概率将其综合为网络行为得分,基于此对虚假评论群组攻击的目标产品进行筛选,进而以可疑产品为种子建立2-hop子图作为后续识别虚假评论群组的子样本数据,结合局部敏感哈希算法的层次聚类识别评论样本中的虚假评论群组。基于亚马逊评论数据集检验了该方法的识别能力,发现该方法能够有效识别隐藏较深的大规模虚假评论群组,且虚假评论群组对目标产品的攻击模式存在产品类别差异;最后将算法得出的虚假评论与真实评论进行对比,虚假评论的同质性非常明显,评论日期更加紧凑,评论者集中度较高,虚假评论群组的目的也并非简单直接刷高评论等级,而是倾向于通过文本好评来吸引消费者。不足之处在于,识别过程中未能充分利用评论样本的文本及行为特征,未来可以考虑将其作为辅助信息提升识别精度。
