基于轻量化YOLOv4的轮毂内部缺陷检测算法
2023-03-01王明泉张俊生曹鹏娟朱榕榕
范 涛,王明泉,张俊生,曹鹏娟,朱榕榕
(1.中北大学仪器科学与动态测试教育部重点实验室,山西 太原 030051;2.太原工业学院电子工程系,山西 太原 030008)
0 引言
铝合金轮毂因具有重量轻、散热快等优点,而被广泛应用于汽车行业。在低压铸造工艺下,铝合金轮毂容易产生一些常见的铸造缺陷,如气孔、缩孔、缩松和裂纹[1],严重影响产品质量。为了保证轮毂质量能够满足工业检测标准,需要在出厂前使用X射线对其进行无损检测[2]。传统手动检测法具有检测结果主观性强、效率低等缺点,已经逐渐被淘汰。21世纪以来,随着计算机视觉技术快速发展,使用深度学习算法来实现DR图像缺陷的自动判定和实时检测成为工业界研究的热点[3]。Ferguson等[4]从模型的数据管理问题作为切入点,指出当前深度神经网络模型训练缺乏标准化方法,提出一种基于预测模型标记语言来优化模型训练过程中的分割问题。Mery[5]评估了用于检测铝铸件缺陷的8种最先进的深度目标检测方法(基于YOLO、RetinaNet和EfficientSet),提出了一种使用少量的铸件无缺陷X射线图像,同时叠加模拟缺陷来训练网络,并得到了很好的结果。蔡彪等[6]提出了一种基于Mask R-CNN的铸件 X 射线DR图像缺陷检测算法对铸件缺陷进行分类分级。王陶然等[7]提出Mask R-CNN卷积网络识别轮毂缺陷并将不同缺缺陷标注出来并进行分割,从而实现了轮毂缺陷的自动分割目标。Jiang等[8]针对深度监督网络需要大的数据集来提高精度这一难题,提出了一种基于卷积神经网络和注意力引导数据增强的X射线图像铸件缺陷检测方法,该方法引入新的数据增强方法来解决训练图像数量少的难题。
上述方法对工业铸件射线图像进行了缺陷识别,但是在模型上普遍都存在参数量过大、难以训练的问题。为此,本文提出一种轻量化YOLOv4的轮毂内部缺陷检测算法。
1 网络选择及原理
1.1 MobileNet网络
MobileNet是由Google提出的轻量级卷积神经网络。MobileNetV1是一种应用深度可分离卷积搭建的一种网络。深度可分离卷积结构如图1所示,它将1个标准卷积分解为深度卷积和1个1×1的点卷积。相对于标准卷积,这种分解方法可以大大减少计算量和模型大小。

图1 深度可分离卷积结构
假设输入特征图为DW×DH×M,其中DW、DH、M和N分别为特征图的宽、高、输入通道数和输出通道数。对于1个DK×DK的标准卷积,共有N个DK×DK×M的卷积核,参数量P1为
P1=DK×DK×M×N
(1)
每个卷积核经过DW×DH次计算,其计算量Q1为
Q1=DK×DK×M×N×DW×DH
(2)
深度卷积参数量P2为
P2=DK×DK×M+M×N
(3)
深度卷积计算量Q2为
Q2=DK×DK×M×DW×DH+M×N×DW×DH
(4)
深度可分离卷积模块与标准卷积参数量的比值R1为
(5)
计算量比值R2为
(6)

MobileNetV1网络在训练过程中存在两大局限:一是卷积核权重数量小;二是网络中没有使用残差连接。这样导致网络训练结果精度低。MobileNetV2在V1的基础上使用了Inverted residuals block结构,如图2所示。

图2 Inverted residuals block结构
MobileNetV2在输入与输出维度相同时,引入ResNet中的残差连接将输入与输出直接连接。这种在内部保持一个高纬度特征空间,输入和输出保持一个低维度的紧密连接的倒残差的结构特点,可以有效解决MobileNetV1网络训练的局限问题。
MobileNetV3[9]在V2的基础上进行了优化,网络使用一个3×3的标准卷积和多个bneck结构提取特征,bneck结构如图3所示。MobileNetV3包括Large和Small这2种结构,本文使用Large结构。为适应轮毂缺陷识别任务,将输入的图片大小设为416×416。bneck结构种引入轻量级注意力模块增加特征提取能力强的通道权重,并且使用深度可分离卷积和残差结构同时构建网络模块。
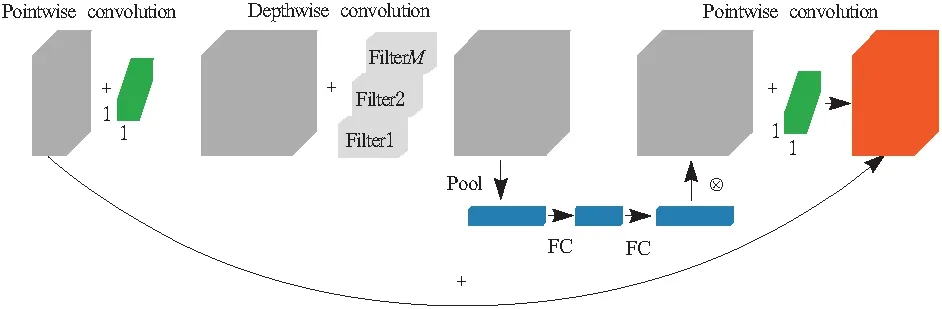
图3 bneck结构
在主干模块和SE模块中分别使用h-swish和h-sigmoid激活函数代替swish和sigmoid,减少了网络的计算量。h-swish和h-sigmoid的计算公式为:
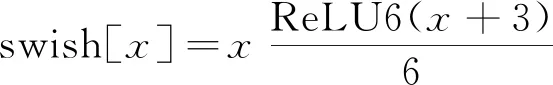
(7)
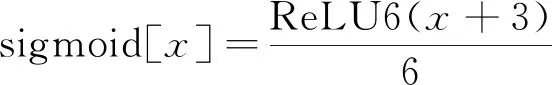
(8)
1.2 YOLOv4目标检测算法
YOLOv4[10]是目前比较先进的目标检测算法之一,它将定位和分类任务集成到一个网络中,实现端到端的目标检测。YOLOv4是在YOLOv3[11]的基础上对主干网络特征提取网络、特征融合网络、激活函数和损失函数等进行了优化。YOLOv4采用Darknet53中的跨级部分网络(CSParknet53)来构建CSPDarknet53主干网[12]。主干网从输入图像中提取特征并将激活函数替换为Mish函数,在降低计算量的同时保证了算法的精确度。颈部网络采用空间金字塔池化(SPP)和路径聚集网络(PANet)[13]生成特征金字塔,来替换YOLOv3采用的特征金字塔FPN。SPP+PANet将低层空间特征与精确位置信息相结合,高层语义特征与高语义信息相结合,实现了双向融合。检测部分延用了YOLOv3中的检测头。
1.3 通道注意力模块
图像经过卷积得到的特征图每个通道都保持相同的权重,利用通道注意力模块可以对目标检测有用信息的通道赋予更高的权重并抑制权重低的特征,增强特征之间的表达[14],如图4所示。输入为特征图X,经过卷积变换后得到特征信号U,其维度为RH×W×C。接着对特征图U沿着空间维度(RH×W)通过全局平均池化(Fsq)来对其进行压缩,生成1个R1×1×C维度的向量,即

图4 注意力机制的权重分配
(9)
再将zc通过激励,即可得到
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1,z))
(10)
δ为ReLU函数;W1和W2为训练权重。
2 轻量化YOLOv4算法
2.1 网络整体结构
YOLOv4被广泛应用于基于深度学习的目标检测领域,但其骨干网络CSPDarknet53内存消耗较大,有29个卷积层,大约2 800万个参数。在颈部网络使用标准卷积也会产生大量的卷积运算,这不仅对设备的性能要求更高,而且还会大大增加计算时间。为了达到工业上实时检测轮毂缺陷的目的,本文提出了一种轻量化YOLOv4的轮毂内部缺陷检测算法。整体网络结构如图5所示,在YOLOv4目标检测算法的基础上,使用去掉分类以及输出层的MobileNetV3网络替换原有YOLOv4主干网络,并利用深度卷积对PANet模块中的传统卷积进行了替换。SPP(spatial pyramid pooling)模块分别使用13×13、9×9、5×5、1×1不同大小的卷积核对前层特征进行最大池化处理。处理后的结果保留了浅层特征的同时也增加网络深度。PANet模块对主干网络提取的特征结果首先进行上采样,将上采样融合之后的特征图输入通道注意力模块,从深层和浅层特征融合之后的信息中选择对目标检测有用的信息进行增强,抑制那些无用的信息,减少冗余特征的重复传递和运算,接着完成下采样操作。通过PANet结构会得到3个大小分别为52×52、26×26、13×13的特征层。YOLO Head 将输入图像划分为对应大小的网络,分别实现对不同大小的缺陷目标的检测。
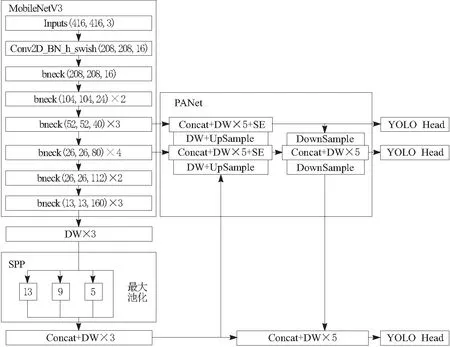
图5 改进的YOLOv4网络模型
2.2 k-means++目标框优化
YOLOv4算法在PASCALVOC数据集通过边框聚类预设了9个目标框(Anchor box),分别用于不同尺度的YOLO检测头预测。不同数据集中目标框的位置与大小均存在一定差异,而预设框选取的准确性对于网络模型性能影响较大,所以原始的预设框并不适用于轮毂内部缺陷识别任务。为了网络能够更好定位到目标位置,采用k-means++算法对本文的缺陷数据集边框进行聚类,得到的Anchor box宽和高为(9,17)、(11,29)、(29,43)、(58,79)、(81,93)、(94,155)、(124,160)、(132,70)、(157,234),单位为像素。
2.3 损失函数
损失函数是模型训练的基准。本文算法采用损失函数包含边界框回归损失、置信度损失和分类损失。其中边界框回归损失使用CIoU描述位置损失。CIoU损失公式为:
(11)
(12)
(13)
Bt、Bp为标记样本中的真实框和预测框;SIoU为2个锚框之间的交并比;wt、ht、wp和hp分别为真实框的宽高和预测框的宽高;C为包含Bt和Bp的最小外接矩形的对角线长度;ρ2(Bp,Bt)为预测框与真实框中心的欧氏距离;ν为测量预测框和真实框之间宽高比的一致性的参数。
总损失函数Lobject公式为
Lobject=LCIoU+Lconf+Lclass
(14)
置信度Lconf损失为
(15)
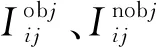
类别损失Lclass为
(16)

3 模型训练与结果分析
3.1 数据集
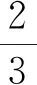
3.2 实验环境
本文实验的相关配置如表1所示,本文采用TensorFlow 框架来实现轻量化目标识别算法。

表1 相关配置
3.3 模型训练
模型训练分为2个阶段:第1阶段在公开数据集VOC2007上进行预训练,将训练好的参数作为初始权值,然后冻结主干网络的权值,对颈部和头部网络的参数进行训练和优化;在第2阶段根据第1阶段网络权值对所有参数进行训练和优化。模型训练共进行140个epoch,第1阶段和第2阶段各进行70个epoch。2个训练阶段的批数分别设置为4和2,学习速率分别设置为0.001和0.000 1。
3.4 评价指标
取平均精度pA给定类别pmA的平均值、调和均值F1对检测精度进行评价,定义为:
(17)
(18)
(19)
P(R) 为当召回率(recall)为R时一个类的精度;C为数据集中类别总量。召回率和精确度定义为:
(20)
(21)
Tp为检测正确的目标数量;FN为漏检数量;Fp为检测错误的目标数量。
3.5 测试结果及分析
训练140个epoch后,每训练一个epoch后保存一次模型参数。训练过程中,模型在100个epoch之后维持在较低水平。
本文在控制对YOLOv4所做的PANet特征加强网络改进和目标框优化不变的条件下,选取Darknet53(YOLOv3骨干网络)、CSPDarknet53(YOLOv4骨干网络)、MobileNetV1、MobileNetV2和MobileNetV3 这5个骨干网络进行试验对比,验证它们对网络的影响,对比结果如表2所示。
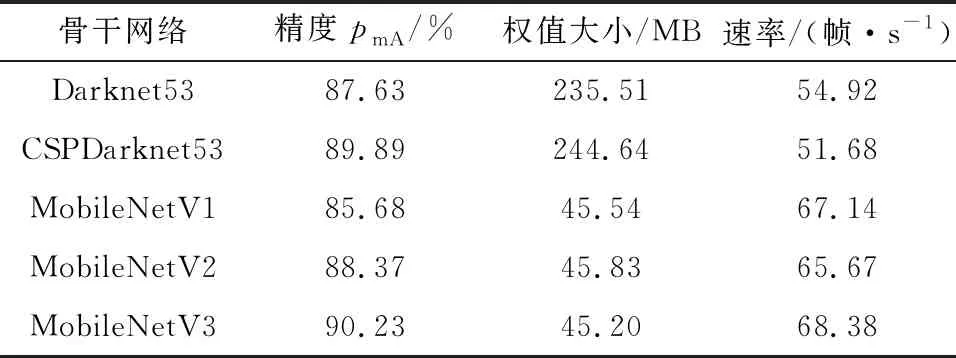
表2 不同骨干网络的性能
由表2可知,在5个骨干网络中,MobileNetV3的权值文件最小为45.20 MB,检测精度最大90.23%,并且FPS比较结果显示,MobileNetV3的检测速率最高为68.38帧/s。综上所述,作为骨干网络MobileNetV3具有明显的检测优势。
为进一步验证本文算法在检测轮毂内部缺陷时是否具有更高的精度和更快的检测速度,将YOLOv4-Tiny、轻量化YOLOv4 和YOLOv4目标检测算法对4种不同的缺陷进行检测,结果如图6所示。

图6 缺陷识别结果对比
由图6可以知道,YOLOv4-Tiny算法对轮毂DR图像中的缺陷检测效果不佳,本文的轻量化YOLOv4和YOLOv4算法对轮毂数据集的缺陷检测精度相差不大,但是YOLOv4模型参数量过大且检测速度比较慢,难以完成实时监测的任务。
同时为了验证算法的普适性,在VOC2007数据集上做了同样的试验,得到的结果基本与本文自建数据集结果一致。综上所述,轻量化YOLOv4算法更适合检测轮毂内部缺陷。
4 结束语
针对当前模型在工业铸件射线图像缺陷识别上存在参数量大、难以训练和对计算机算力要求高的问题。本文基于YOLOv4 算法结合MobileNetV3 提出了一种应用于轮毂内部缺陷实时检测的轻量化算法。 使用自制的数据集,采用k-means++ 聚类对目标样本进行锚定框大小的优化。 通过实验证明改进的算法权值文件为45.2 MB,平均每秒检测速度达到了68.38帧/s,在检测轮毂缺陷方面成功率达到90.23%,完全能够实现轮毂内部缺陷的实时检测,且降低了对于计算机硬件的要求。
