基于YOLOv5s 的导盲系统障碍物检测算法
2023-02-28刘昕斐张荣芬刘宇红程娜娜
刘昕斐,张荣芬,刘宇红,刘 源,程娜娜,杨 双
(贵州大学大数据与信息工程学院,贵阳 550025)
0 引 言
根据世界卫生组织(WHO)的调查,全世界约有2.85 亿人患有视力疾病[1]。 目前,国内约有500 万盲人,且盲人数量正在以每年约40 万的速度增加[2]。视力障碍人群对日常生活辅助服务的需求不断加强。
视力障碍人士在独自出行的过程中需要足够外部环境信息提示以避免发生碰撞,这些信息包括路面凸起(如石头)、隔离桩、随意停放的自行车和摩托车等障碍物,以及斑马线、盲道、路面坑洼等路面情况,由于很多城市在建设过程中没有充分考虑盲人的出行需求,因此当前存在盲道设置不科学与盲道维护不及时的问题,这就在一定程度上限制了盲人在室外独自出行的活动。 而当前导盲辅助服务、如专人陪同或导盲犬对使用者的经济水平有较高要求。 传统的盲人出行辅助器材大多基于超声波、红外传感器,很难满足当前的盲人出行需求,随着深度学习技术的迅速发展,基于计算机视觉领域的目标检测研究为导盲算法提供了新的发展方向。
2012年,Krizhevsky 等学者[3]在ImageNet 图像分类竞赛中使用了深度卷积神经网络(CNN)模型,大幅度超越了传统的机器学习算法,这也成功标志着深度学习在计算机视觉领域的应用开始进入快速发展的阶段。 2015年,Girshick 等学者[4]提出了RCNN 模型,该模型使用基于候选的方法,显著提高了目标检测的准确率。 随后,各种优秀的算法如Fast RCNN[5]、Faster RCNN[6]、Mask RCNN[7]等模型算法相继被提出。 在2016年,Redmon 等学者[8]首次提出了YOLO(You Only Look Once)检测模型,使得目标检测算法的精度进一步上升,且模型运行的计算量需求有了大幅度下降。
2018年,李林等学者[9]使用MobileNet 网络基于迁移学习方法对盲道障碍物图片进行分类。 2022年白俊卿等学者[10]使用ECA 注意力结合YOLOv4进行无人机障碍物检测。 刘力等学者[11]使用YOLOv4 模型对铁路上的入侵障碍物进行检测,取得了良好的效果。
本文针对视力障碍人群在出行时可能碰到的各种情况,提出了一种改进型YOLOv5s 障碍物检测算法,来解决导盲系统使用过程中的障碍物感知问题。
1 YOLOv5s 目标检测模型及改进
1.1 YOLOv5 网络介绍
YOLOv5 是目前流行的目标检测算法之一,YOLOv5 的网络结构如图1 所示。 YOLOv5 针对不同的部署环境提出了4 种模型结构,分别是YOLOv5s、YOLOv5m、YOLOv5l 和YOLOv5x,其中YOLOv5s 网络参数量最少,另外3 种网络以此为基础进行不同程度的加深加宽,精度相应地有一定的提升,但是对计算资源的需求也逐渐提高。
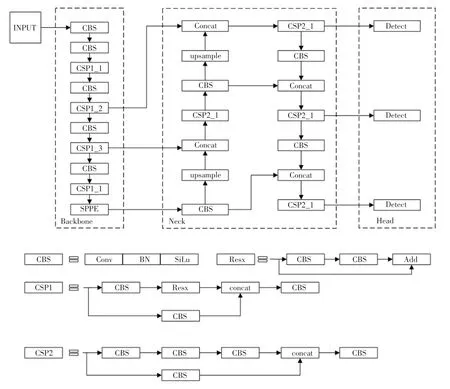
图1 YOLOv5 网络结构Fig. 1 YOLOv5 network architecture
YOLOv5s 网络结构主要分为3 个部分:主干网络(Backbone)、颈部(Neck)和检测头(Head)。 其中,Backbone 主要负责提取特征,由CBS、CSP1 和SPPF 三部分组成。 研究可知,CBS 是由卷积(Conv)、批量归一化(Batch Normalizetion,BN)和SiLU 激活函数构成;CSP1 是一种残差结构[12],可以使计算过程中的参数量变小,速度更快,并且通过残差模块可以控制模型的深度,CSP1_X,CSP2_X 的X表示该模块使用的串接次数、即深度;SPPF 的作用是对特征图进行多次池化,对高层特征提取并融合,比SPP -Net 拥有更快的推理速度。 Neck 采用PANet[13]结构,主要作用是进行特征融合,PANet 由CBS、上采样(Upsample)、CSP2 组成。
1.2 改进后的模型整体网络
本文使用MobileNetV3[14]网络替换YOLOv5s 的主干特征提取网络,以减少参数量,降低计算量,提高运算速度。 在主干特征提取网络和特征融合网络中插入CA 注意力,使模型更好地聚焦于有效特征。使用EIoU 边界框损失函数替换原网络的CIoU 边界框损失函数,提高了模型的回归精度。 改进后的模型整体网络结构如图2 所示。
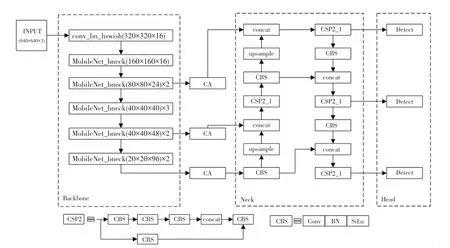
图2 改进后的模型整体网络结构Fig. 2 The overall network structure of the improved model
1.3 MobileNetV3 轻量化计算网络
MobileNetV3 是由Google 团队在2019年提出的一种轻量级卷积神经网络,被广泛应用于移动设备等计算资源有限的场景中。 相比于以前的版本,MobileNetV3 在速度和精度上都有着显著提升。
MobileNetV3 的设计思路主要有3 个:减少计算量和内存占用、优化神经网络架构、增加非线性变换。 MobileNetV3 的在具体实现上表现在3 个方面。
(1) MobileNetV3 引入了“深度可分离卷积”(Depthwise Separable Convolution)来代替标准的卷积操作,减少了网络的计算量。 深度可分离卷积将标准卷积分解为逐通道和逐点卷积两层,前者用于在通道维度上处理输入特征图,后者用于在空间维度上处理特征图。 通过使用深度可分离卷积,MobileNetV3 可以显著减少参数量和计算量,并提高网络的运行速度。 MobileNetV3 的block 组成如图3所示。
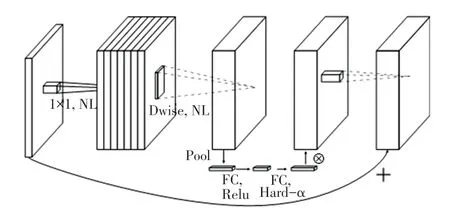
图3 MobileNetV3 block Fig. 3 MobileNetV3 block
在深度可分离卷积中逐通道卷积是通过一个一维的卷积核对一个通道进行卷积操作后再对卷积后的结果进行汇总,如图4 所示。 一张三通道的彩色图片通过逐通道卷积运算后可以得到3 张特征图,因此在逐通道卷积的过程中无法提高通道数,可以使用逐点卷积对逐通道卷积后的信息进行整合。
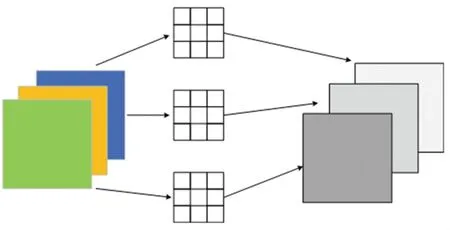
图4 逐通道卷积Fig. 4 Channel by channel convolution
逐点卷积的卷积核大小为1×1×M,其中M为输入数据的维度,逐点卷积可以通过加权组合的方式对逐点卷积形成的特征图进行信息提取并生成新的特征图,如图5 所示。 一张3 通道的彩色图片用4个1×1×3 的逐点卷积进行计算后可以形成4 个新的特征图。
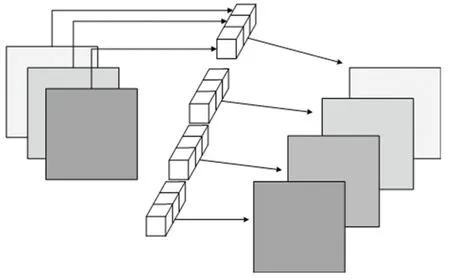
图5 逐点卷积Fig. 5 Point by point convolution
在使用标准卷积计算的情况下,设输入数据为DF ×DF ×M,卷积核为DK ×DK ×N,卷积步长为1时,标准卷积的参数量为:
对应的计算量为:
在同样的情况下使用深度可分离卷积时对应的参数量为:
此时的计算量为:
因此,深度可分离卷积与标准卷积的参数量与计算量之比均为:
因此可知,使用深度可分离卷积可以极大地降低参数量与计算量。
(2) MobileNetV3 使用了非线性激活函数h -swish和h - sigmoid,能够显著减少模型的计算量,同时保持较高的准确率。h -swish是一个可微的连续函数,其形式类似于ReLU激活函数,但是比ReLU要更加平滑,从而可以减少梯度爆炸和梯度消失的问题。 而h - sigmoid则是对sigmoid函数的一种变体,可以减少运算量并提高网络的计算效率。
(3) MobileNetV3 使用了Squeeze and Excitation(SE)注意力模块,可以自适应地对不同的通道、进行加权,加强重要的通道而减弱不重要的通道。 通过使用SE 模块,MobileNetV3 可以更加有效地利用有限的计算资源,提高网络的精度和效率。
1.4 CA 注意力机制
Hou 等学者[15]在2021年提出了CA(Coordinate Attention) 注意力机制。 CA 注意力模块结构如图6所示。 CA 注意力机制可以在基本没有增大计算开销的情况下插入神经网络中,提高网络检测性能。CA 注意力机制相比当前流行的SE[16]、CBAM[17]有显著的优点,既关注了通道维度又关注了空间维度、且解决了长距离依赖问题。
CA 注意力机制可以对网络中的任意中间特征张量:
进行转化后输出同样尺寸的张量;
CA 注意力机制对通道关系和空间关系进行编码的过程可以分为坐标信息嵌入和注意力生成两个阶段。 在进行坐标信息嵌入时,对输入的特征图在X和Y两个方向进行池化操作,用以保留特征图的空间结构信息。
因此高度为h的第c个通道可以表示为:
同样,宽度为w的第c通道输出可以写成
接着,X和Y方向的特征图进行拼接,再对其进行卷积操作,使其维度降低为原来的,然后将经过批量归一化处理的特征图F1送入Sigmoid激活函数得到形如的特征图f,计算公式如下:
在此基础上,将特征图f按照输入数据的高度和宽度进行的卷积,分别得到通道数与原来一样的特征图Fh和Fw,经过σ激活函数后分别得到特征图在高度和宽度上的注意力权重gh和在宽度方向的注意力权重gw。 其数学公式可写为:
经过上述计算后将会得到输入特征图在高度方向的注意力权重和在宽度方向的注意力权重。 最后,在原始特征图上通过乘法加权计算,得到最终在宽度和高度方向上带有注意力权重的特征图,如式(13)所示:
1.5 边界框损失函数改进
在YOLOv5s 网络中,边界框回归损失函数使用的是CIoU损失函数,CIoU Loss虽然考虑了边界框回归的重叠面积、中心点距离、纵横比,但是通过在计算过程中只考虑了纵横比的差异,而忽略了宽高分别与其置信度的真实差异。 针对这一问题,本文使用EIoU[18]边界框损失函数替代原模型使用的CIoU边界框损失函数,用来加快模型的收敛速度,提高模型的精度。EIoU损失函数的公式为:
其中,LossEIoU为EIoU损失函数的值;b,bgt为预测框和真实框的中心点;ρ为计算2 个中心点之间的欧氏距离;w为框的宽度;h为框的高度;c为能够同时包含预测框和真实框的最小外接矩形的对角线距离;ch、cw为以2 个中心点构成的矩形的高和宽。
2 实验与结果分析
2.1 实验数据集
本文针对盲人出行时常见的障碍物数据集进行收集,具体包括3 种类型的障碍物,分别是:路面情况,如因年久失修造成的路面坑洼;人为设置的路面的障碍,如隔离桩、三角锥和石墩等;以及路面上出现的随机障碍,如随意停放的自行车、路上的行人或街道上常见的猫、狗等。 本文的数据集从互联网、实地拍摄人行道的障碍物以及VOC 等公共数据集上进行收集,并对收集的图片采用labelimg 图像注释工具进行数据标注。 实验数据集将检测障碍物分为20类,共计26 872 张图片。 各类别具体数量见表1。 训练集和验证集按9 ∶1 的比例随机进行划分。
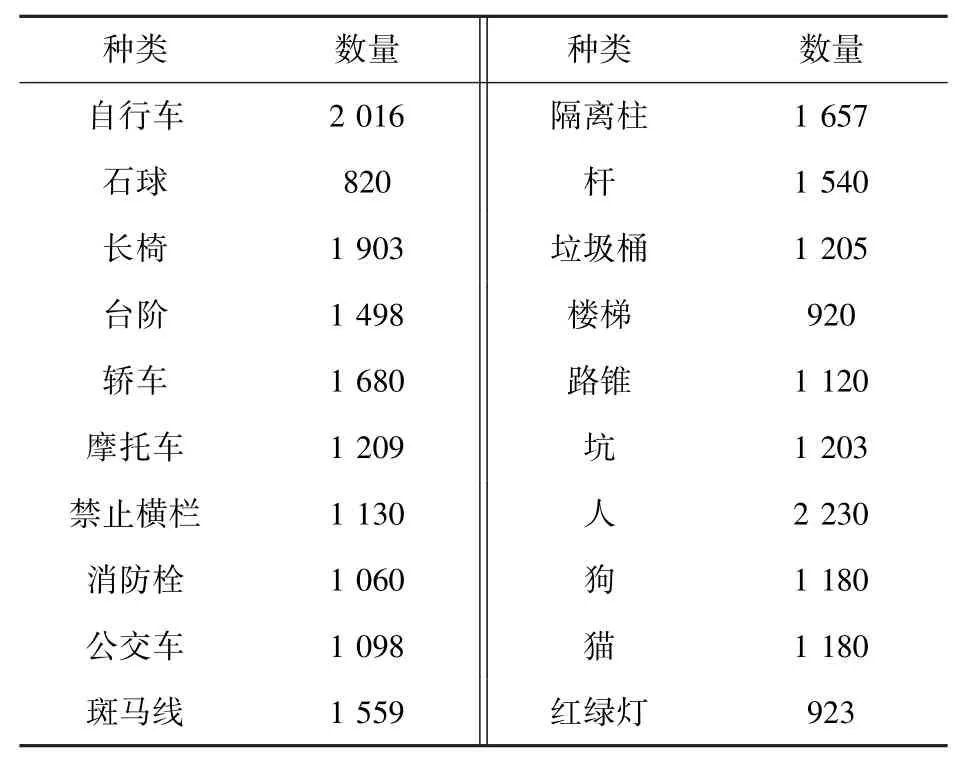
表1 数据集的种类与数量Tab. 1 Types and quantity of datasets
2.2 实验细节
本文实验均在服务器Ubuntu 20.04 操作系统下运行,计算机处理器型号为AMD 3900X,显卡型号为NVIDIA GTX 3090,内存为24 G。 采用Pytorch 1.7.1框架,所使用的编程语言Python 3.7。 模型训练时使用sgd 优化器,设定batch size 为32,初始学习率为0.01,最小学习率为0.000 1,动量因子为0.937。设置训练轮数为300。
2.3 实验结果分析
2.3.1 实验评价指标
本文采用准确率P(Precision) 和召回率R(Recall)计算出所有检测类别的平均精度(mAP)来对模型的检测效果进行评估,使用计算量(Flops)和参数量(Params)两个指标来整体评估模型对计算资源的占用程度。
其中,AP与mAP的计算公式为:
其中,TP、FP、FN分别表示正确检测的数量、错误检测的数量、没有检测出的数量。
2.3.2 不同模型实验数据对比
为了验证本文算法的检测性能,将Faster RCNN[19]、 Centernet[20]、 YOLOv3[21]、 YOLOv4[22]、YOLOv5s 和本文算法在同一数据集下进行对比实验,结果见表2。

表2 不同算法对比Tab. 2 Comparison of different algorithms
2.3.3 消融实验
为验证本文改进算法的有效性,对本文算法的改进部分,分别进行消融实验得到表3。 由表3 的实验结果可知,使用MobileNetV3 轻量化主干特征提取网络之后计算量和参数量明显下降,计算精度轻微下降,表明采用MobileNetV3 轻量化主干网络可以有效实现网络的轻量化,在添加CA 注意力与改进边界框损失函数后,计算精度有所上升,表明CA 注意力机制可以使模型有效地聚焦于被检测目标的有效特征,与此同时计算量和参数量轻微上升。
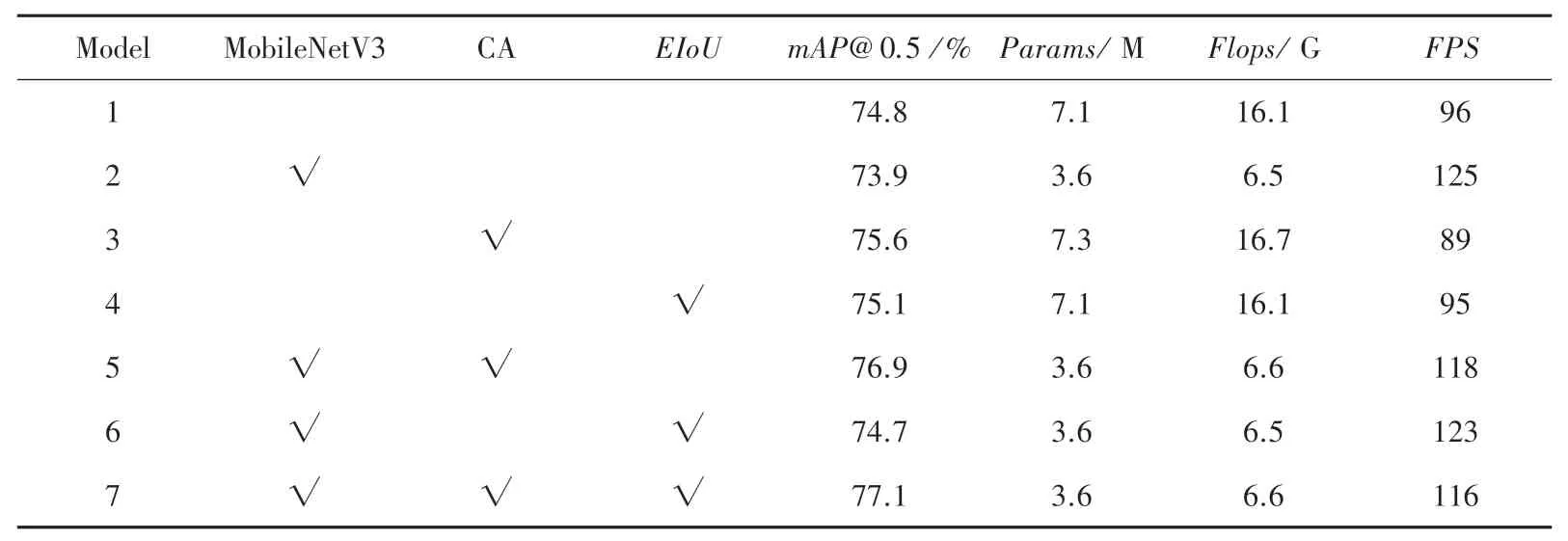
表3 不同模块对模型整体影响Tab. 3 The overall impact of different modules on the model
由对比实验与消融实验可知,在盲人出行道路障碍物检测精度上可以达到77.1%,本文模型精度上优于Faster RCNN、Centernet、YOLOv4、YOLOv5s等模型,参数量和计算量明显小于对比算法,计算速度有所提升。
2.3.4 模型运行效果图
改进前与改进后的模型检测效果如图7 所示。改进后的模型检测精度有所上升,在被检测物体之间存在遮挡情况下,因为改进后模型的特征提取能力较强,可以检测到原模型的部分漏检情况。

图7 YOLOv5s 模型与改进后的模型检测效果对比Fig. 7 Comparison of detection performance of YOLOv5s model and improved performance model
3 结束语
为了解决导盲系统的实际需求,本文提出了一种基于YOLOv5s 的改进模型。 通过将主干特征提取网络替换为MobileNetV3,显著降低了网络的计算量和参数量,在网络中融入CA 注意力机制,有效地提升了检测模型的精度;采用EIoU边界框损失函数,使得对目标的定位更加精准。
实验结果表明,本文算法在速度上满足了实时检测的需求,检测目标的准确率也优于现有的YOLOv4、YOLOv5s 等算法,mAP达到了77.1%,单张检测速度达到了116 FPS。
由于条件有限,本文的研究还有部分不足之处。一,数据集多为光照条件良好时拍摄的照片,因此模型在夜晚的识别能力有所下降;二,模型算法仍需要6.6 GFlops 的计算量,对部分算力不高的边缘计算设备仍存在一定的压力。 后续将对数据集扩充部分夜间拍摄的图片,以及采用模型剪枝、知识蒸馏等措施对模型进行进一步压缩,实现算法在边缘计算设备上的流畅运行。
