一种面向口腔移植骨分割的SA-UNet 网络
2023-02-28徐常鹏丁德锐
徐常鹏,赵 宇,丁德锐
(上海理工大学光电信息与计算机工程学院,上海 200093)
0 引 言
在口腔种植领域,新骨体积量是判断能否进行分期种植的主要依据。 近年来,由于低剂量、成像质量高、价格低廉等优点,锥束计算机断层扫描(Convolutional Block Attention Module,CBCT)几乎占据牙科领域的市场[1-2]。 在口腔医学图像分割中,移植骨区域的体积分割面临较大考验[3]。 究其原因是临床使用的骨移植材料有个体差异,同时在新骨生成改建过程中伴随有移植材料的吸收,使得CBCT 图像中移植骨区边缘与周围组织很难清晰辨识[4-5],从而影响医生对移植骨区域准确性的判断。对口腔移植区的勾画通常要求临床医生手工勾勒靶区的轮廓边界。 一个标准的CBCT 图像通常包含几百张切片,传统的手动勾勒需要耗费大量的时间和人力。 不同医生对同一植体区域的勾画也有可能存在一定的差异,这些差异会影响治疗计划的质量与优化。 另一方面,CBCT 图像的质量也会受到多种因素影响[6],如CBCT 成像对移植体区域的图像分辨率不高、图像对比度低等。 因此,要想获得比较精确的分割结果,仍然面对巨大的挑战。
基于深度学习技术的图像分割方法具有操作方便、准确性高等诸多优势,在口腔医学领域有着广泛的应用前景和很高的经济价值[7-8]。 目前,卷积神经网络被广泛用于医学图像分割任务中。 例如,Long 等学者[9]提出全卷积(Fully Convolutional Networks,FCN)网络结构。 FCN 采用反卷积层对特征图上采样,使其恢复到输入图像相同的尺寸,实现了像素级的分类。 Ronneberger 等学者[10]提出了U-Net 网络结构。 该网络采用U 型编码解码结构,通过跳跃连接实现不同尺度特征图低级细节与高级语义的结合,成为了医学图像分割的基准网络。Oktay 等学者[11]提出Attention U-Net。 该模型以U-Net 为基础,在解码器部分通过注意力门(Attention Gates)控制特征的重要性,抑制不相关背景区域的影响。 Zhou 等学者[12]提出U-Net ++网络,通过不同深度的U-Net 的有效集成来缓解未知的网络深度,通过深度监督进行共同学习。 Alexey等学者[13]提出Vision Transformer (ViT)网络。 这是首次将自然语言处理中的Transformer 模型用于计算机视觉中,并且在大规模数据集中取得较好效果。Chen 等学者[14]提出TransUnet,通过Transformer 的全局注意力弥补了U-Net 远程建模依赖关系的局限性。
针对口腔CBCT 图像,尤其是对于口腔骨移植区分割任务[15],传统的实施方案主要依赖于医生手动的线性勾勒,目前并无成熟的口腔移植骨分割网络模型。 同时,移植区位于牙槽骨内部或表面,体积相对较小,因此口腔移植骨图像具有样本不均衡,边缘模糊等特点。 虽然U-Net 网络通过多尺度特征提取和跳跃连接层保留低层信息的特性,在网络医学图像中有许多成功的应用,但由于低级特征层和高级特征层的语义差距较大,U-Net 应用跳跃连接来合并低级别和高级别的特征层,不仅容易导致特征映射模糊,而且还易导致过度和欠分割的目标区域。 此外,由于口腔移植骨CBCT 图像数据集具有标记的数据量较少,加之样本不均衡、边界模糊等问题,U-Net 网络分割方法会出现模型特征提取能力较差、边界分割效果差等问题,导致网络分割结果精度有限。
针对上述难点,本文提出一种基于U-Net 和注意力机制的新型网络(SA-Unet),以提高口腔移植骨分割的准确率。 具体地,使用U-Net 网络作为主体框架,将跳跃连接层简单地复制操作改进为Depthwise 卷积,以锐化低级特征层并减轻特征拼接引起的语义差距。 其次,通过在解码器部分特征拼接之后嵌入CBAM[16]模块,增强模型对于特征的提取能力,使得模型更加关注目标区域的细节信息(如边缘、纹理等),并抑制其它无用信息。 最后为解决数据正负样本不均衡以及简单困难样本不均衡的问题,论文设计了新型的联合损失函数。
本文主要贡献如下:
(1)提出基于U-Net 和注意力机制的编码解码网络(SA-UNet),以实现口腔移植骨的精准分割。在跳跃连接层设计的锐化操作不会引入任何额外的可学习参数。
(2)设计一种轻量级的Sharp-Attention 模块。通过引入带锐化卷积核的Depthwise 卷积和CBAM模块,增强了图像的细节信息,平衡了不同层间语义差距。 本模块也适用于其他语义简单的医学图像,也可集成到其他U 型网络结构中用以提升模型性能。
(3)采用新型联合损失函数,缓解正负样本比例失衡带来的影响。 在制作的口腔CBCT 图像数据集上验证本文提出模型的有效性。
实验结果表明,相比其他方法,本方法在IoU、Dice系数、HD距离三个指标上均取得了最佳评分。
1 相关工作
由于U-Net 网络结构在生物医学图像分割中的良好表现,通常被作为医学图像分割的基准网络,并且陆续推出了基于U-Net 改进的系列成果。 受到残差连接的启发,Xiao 等学者[17]提出了Res-UNet 用于视网膜图像的分割。 Guan 等学者[18]提出了Dense-UNet,将UNet 的每一个子模块分别替换为密集连接的形式,并设计Fully Dense UNet 模型用于去除图像中的伪影。 Alom 等学者[19]提出了循环卷积网络(RU-Net)和循环残差卷积网络(R2UNet)。 这2 种网络分别用循环卷积层(RCLs)和带有残差的循环卷积层(RCLs)代替正向卷积层。Çiçek 等学者[20]基于U-Net 提出了3DU-Net,实现了对于3D 图像的医学分割。 Milletari 等学者[21]在3DU-Net 的基础上提出了V-Net,用卷积代替池化,通过转置卷积上采样,实现了基于体积的分割方法。
注意力机制的基本方式是通过启发式搜索对卷积特征进行选择,即通过学习要强调或抑制的特征来有效帮助信息在网络内的流动。 Jaderberg 等学者[22]提出了Spatial Transformer Network,空间注意力主要关注图像的空间位置信息,生成空间特征图保存关键信息。 Hu 等学者[23]提出了SENet,通道注意力可以有选择性地关注具有更多信息的特征通道,并对无用特征进行抑制。 Zhao 等学者[24]提出了PSANet。 该方法只计算每个像素与其同行同列、即十字上的像素的相似性,通过进行循环间接计算得到各像素间的相似性,有效降低计算复杂度。 Wang等学者[25]提出一种可堆叠的残差注意力网络(Residual Attention Network)。 Vaswani 等学者[26]提出自注意力(Self-Attention)机制,不使用RNN 或CNN 等复杂的模型,仅仅依赖于Attention 模型就可以实现训练并行化且拥有全局信息。 Woo 等学者[16]提出了轻量级的卷积注意力机制模块(CBAM),CBAM 模块会依次沿着通道和空间维度推断注意力图,而后将注意力图与输入特征图相乘以进行自适应特征优化。
2 方法
2.1 SA-UNet 网络整体结构
本文以U-Net 为基准网络,通过设计一种Sharp-Attention 机制,同时融入CBAM(Convolutional Block Attention Module)注意力模块,提出了一种改进的SA-UNet 模型。 该模型是一种多尺度的对称U 型结构网络,如图1 所示。

图1 SA-UNet 网络结构Fig. 1 The structure of SA-UNet
设计的SA-UNet 网络由编码器、跳跃连接层、解码器三个部分组成。 具体地,编码器部分包含了卷积、池化、下采样等模块;跳越连接层部分在浅层引入了Sharp 模块[27];解码器部分包含双线性上采样、CBAM 模块、卷积和池化模块。 此外,针对口腔移植骨图像边界模糊、样本不均衡的特点,网络的训练采用了一个新设计的联合损失函数,用以提升图像分割质量。
在细节上,编码器部分与传统的U-Net 类似,由5 个模块组成,每个模块包含2 个3×3 卷积层和一个ReLU 激活层,随后连接一个2×2 的最大池化层,且第5 个模块不包含池化层。 分别使用32、64、128、128、256 和512 个卷积核,即在每个模块之后,特征图通道的数量都增加了一倍。
在U-Net 型网络结构中,编解码器网络中的跳跃连接层对于恢复预测的细粒度细节方面起着至关重要的作用。 传统的对浅层信息直接复制的跳跃连接方式在融合低层和高层不同的语义特征时,由于较大的语义差异容易导致模糊的特征映射,从而降低了分割精度。 为此,本文改进了这一连接方式,在前2 个模块的跳跃连接层中引入了Sharp 模块,使用带锐化卷积核的Depthwise 卷积,从而在每个特征通道上对特征图进行沿通道的卷积操作。Depthwise 卷积操作锐化了浅层特征以加强特征细节,使得在特征拼接时平衡了不同层间语义差距,同时也有助于减少早期阶段在整个网络层中传播的高频噪声成分。 值得一提的是,Sharp 模块不会引入任何额外的可学习参数。
解码器部分通过嵌入CBAM 模块,结合空间和通道的注意力机制,提高了模型对于感兴趣区域的关注程度。 解码器部分同样由5 个模块组成,每个模块包含一个2×2 的反卷积(即对特征进行上采样)、特征拼接、CBAM 模块,然后是2 个带有ReLU激活的3×3 卷积层,且第5 个模块有一个额外的1×1 卷积层实现特征降维。 解码器模块的卷积层分别用256、128、64 和32 个卷积核,即每个模块之后特征通道数减半,最后输出与输入图像同等分辨率的输出图像。 输出是对于每个像素类别的预测。 接下来将进一步阐述所设计网络核心模块。
2.2 Sharp-Attention 模块设计
如前所述,本文的创新性工作之一是将Sharp模块与CBAM 模块结合,提出了Sharp-Attention 模块,并应用于U-Net 网络跳跃连接与解码器部分。该模块主要由2 个部分组成,如图2 所示。 一部分是Sharp 模块,通过带锐化卷积核的Depthwise 卷积操作,对不同尺度的特征图实现锐化操作;另一部分是CBAM 模块,该模块包含一个通道注意力单元和空间注意力单元,用来对不同特征图赋予不同的关注程度。 对此拟做阐释分述如下。

图2 Sharp-Attention 模块图Fig. 2 Sharp-Attention block
(1)Sharp 模块。 模块中的Depthwise 卷积操作是在特征融合之前使用锐化卷积核对每个通道的特征图独立地进行卷积。 锐化卷积核是图像拉普拉斯算子[28]的近似,是一个二阶导数算子,能够在任何方向上响应强度跃迁。 例如,带有如下卷积核的一个拉普拉斯高通滤波器,考虑了输入图像中参考像素的所有8 个临近值,如式(1)所示:
显而易见,该卷积核的功能是增加了中心像素相对于相邻像素的强度。 进而,设I是输入图像,则锐化图像S为:
其中,“∗”表示卷积。
由于编码器的特征层是多维的,一般大小为W × H × C,其中W、H和C分别表示编码器特征映射的宽度、高度和通道数。 因此,本文使用基于拉普拉斯滤波器核K的锐化空间核沿通道对每一个特征层进行卷积,即Depthwise 卷积操作。 具体地,使用C个滤波器,输入特征图的每个通道分别与核K进行卷积,步幅为1。 每一个卷积操作都产生一个大小为W × H ×1 的特征图。 为了保持输出维度与输入的维度相同,在特征拼接的过程中执行填充操作。 稍后,将这些特征图堆叠在一起获得了尺寸为W × H × C的输出。 由于锐化卷积核K没有可调参数,因此在模型优化过程中没有参数更新,不会产生额外的计算成本。
(2)卷积注意力模块(CBAM)。 是一种简单而有效的注意力模块,如图3 所示。

图3 CBAM 模块图Fig. 3 CBAM block
在解码器部分,把拼接之后的特征图输入到CBAM 模块,此后沿着通道和空间维度依次推断注意力图,然后将注意力图与特征图相乘后的结果进行自适应优化。 给定大小为W × H × C的特征图,CBAM 依次推断出大小为1×1×C的一维通道注意图Mc和大小为H × W ×1 的空间注意图Ms。 具体地,通道注意力将输入的特征图Finput分别经过基于高度和宽度的全局池化和平均池化,而后再分别经过多层感知器、element-wise 加和操作、Sigmoid激活,最终生成通道注意力特征图Mc。 通道注意力特征图与输入特征图做元素相乘生成空间注意力模块所需的输入Fout1,数学定义如下:
空间注意力模块包括全局池化和平均池化、拼接、卷积操作、降维以及Sigmoid激活而生成空间注意力特征图Ms。 同样地,与输入特征图Fout1相乘得到CBAM 模块的输出特征图Fout2,其数学表达式为:
其中,“ ⊗”为对应像素值相乘。
对于一个特征图来说,通道注意力模块压缩了输入特征图的空间维数,用于聚集空间信息。 空间注意力模块是利用特征的空间关系来生成一个空间注意图。 空间特征更多关注目标的位置信息,与通道注意力互为补充。 本文认为Sharp 模块对编码器特征的每个通道独立地进行卷积操作,能够增强浅层特征图的细节信息,同时有助于减少早期阶段整个网络层中传播的高频噪声成分。 进而,在解码器部分高层与低层特征图拼接之后嵌入的CBAM 模块,使得通道注意力模块能够更加有效地关注经过Sharp 模块增强的浅层特征通道的信息,从而加强对于浅层信息的提取,更好地平衡高层和浅层的语义差距。
2.3 损失函数
加权交叉熵常用来解决医学图像中的类别不平衡问题。 通过对每个类别加上适当的权重,从而抵消了数据集中存在的类不平衡。 进而,为了降低易分样本对损失函数的贡献,Lin 等学者[29]通过引入难易区分权重,使模型更加专注难分样本的区分,得到了Focal Loss(FL):
其中,β表示类别平衡因子,γ是难易样本平衡因子。 通过对β参数的调整,可解决正负样本不均衡的问题;通过(1- pi)γ参数的调整,可改善难易样本不均衡问题。
Hausdorff Distance(HD) Loss 可用于优化分割的最大距离误差[30]:
其中,Ω表示图像定义的网格;q,p分别表示预测图与groud-truth;dq,dp分别表示预测图与ground-truth 的距离变换图; “◦” 表示对应元素相乘。HDLoss 不是只关注最大的分割误差,而是使用α作为惩罚因子,平稳地对于较大的分割误差给予惩罚。
在医学图像分割任务中,类别不均衡问题很常见,即正负样本比例失衡。 口腔移植骨图像也是如此,背景像素约占95%以上,数据集具有显著的正负样本比例不平衡特征。 同时,由于二维图像中移植骨区域较小,对于较小的样本容易产生误判。 考虑到基于边界的损失函数能够通过对最大距离的约束有效地减小误判的产生,本文设计一种联合FL与HDLoss 的损失函数,其定义如下:
这里,参数λ平衡了HDLoss 在训练中的权重,以实现更好的分割性能。 经过实验发现,γ参数设置为2,β设置为0.8,α值在1.0 和3.0 之间实验结果较好。 本文的实验中,α设置为1.5,λ设置为0.2。
3 实验及结果分析
3.1 实验环境与参数设置
本文实验使用Python 编程语言,Pytorch 框架,硬件配置如下:处理器为Inter(R)Core(TM)i9 -10900X CPU @3.7 GHz,内存(RAM)为64.0 GB,GPU 为NVIDIA GeForce RTX 3090 24 GB 显存,计算机系统为Linux 操作系统Ubuntu 18.04。
在训练过程中,采用自适应动量估计( adaptive moment estimation,Adam) 优化器和反向传播算法对网络进行优化与梯度更新。训练批次(batchsize) 设为16,初始学习率( learning rate) 设为0. 001,每100 个周期学习率下降0.2 倍,动量值设为0. 9,训练次数设置为500。
3.2 实验数据集建立
本实验的CBCT 数据集来自上海交通大学医学院附属第九人民医院,由不同年龄阶段的10 例健康患者在术后经同一台CBCT 扫描仪扫描得到(伦理批号:SH9H-2022-TK53-1),剔除无关部位的扫描切片后,共计505 张图片。 扫描时的参数设置:电压120 kV、电流5 mA、扫描时间16 ~20 s、voxel size:0.25 mm;FOV: 25 cm(D)×17 cm(H) 分辨率,图像矩阵为651×651×651 体素。 考虑到人工标注的骨移植区域作为标注金标准的可信度和深度学习的可解释性,对于每张原始CBCT 图像,口腔移植骨区域由经验丰富的口腔专科医生手工标注,并将最终标注结果以NIFTI 格式进行存储。 为了提升模型泛化能力,采取旋转、偏移、裁剪、水平翻转、随机旋转等操作进行数据集扩充,最终得到尺寸为224×224的图片1 830张。 进而可得,训练数据集为1 464张图片,测试数据集为366 张图片。
3.3 评价指标
为了定量评估分割效果,本文使用Jaccard 指数(Intersection-over-Union,IoU)、 Dice 相似系数(Dice Similarity Coefficient,DSC)、 Hausdorff 距离(Hausdorff Distance,HD)、召回率(Recall)、精确率(Precision) 作为评估指标。 对于各评估指标的数学定义及表述详见如下。
(1)IoU。 给定2 个集合G和P,对应表示真实标签和预测标签,IoU定义为:
其中,G∩P为真实标注区域与预测输出区域的交集,G∪P为真实标注区域与预测输出区域并集。 Jaccard 系数的范围从0 到1,这里1 表示真实标签和预测标签之间的完全匹配,而0 表示真空标签和预测标签之间的完全不匹配。
(2)DSC。 定义为:
同样地,DSC的值在[0,1]范围内。 其值越大表示网络的预测输出与真实标注之间的重合率越高。
(3)召回率(Recall)。 定义为所有预测输出像素中被正确预测出来的比例。 数学定义公式为:
其中,TP +FN表示数据集中的所有正例。
(4)精确率(Precision)。 表示在所预测的正样本中,预测正确的正样本所占的比例,其计算公式为:
(5)Hausdorff 距离。 是用来度量2 组点集的相似程度。 假设有2 组集合A ={a1,…,ap} 和B ={b1,…,bp},则这2 个点集合之间的HD为:
其中,
其中,‖·‖表示点集A和点集B间的距离范式。HD值越小,表示A、B之间的重叠度越高,分割性能越好。
3.4 消融性实验
为了评估的SA-UNet 模型中不同模块(即Sharp 模块和CBAM 模块)和不同损失函数(即LossFL和LossHD,记作FL和HD) 在口腔移植骨分割任务中的性能,本节设计了7 组不同实验来进行对比。 表1 给出了在不同模块组合下的不同模型对移植骨的平均分割性能。 从表1 不难看出,不同模块的组合都能在一定程度上提升网络模型的性能,且SA-UNet 网络在性能上达到了最佳,DSC值达到0. 923 6,Hausdorff 距离为0.566 3。当同时考虑提出的联合损失函数时,DSC值达到0.926 2,Hausdorff距离为0.509 2,在性能上进一步提升了0.28%和10.08%。
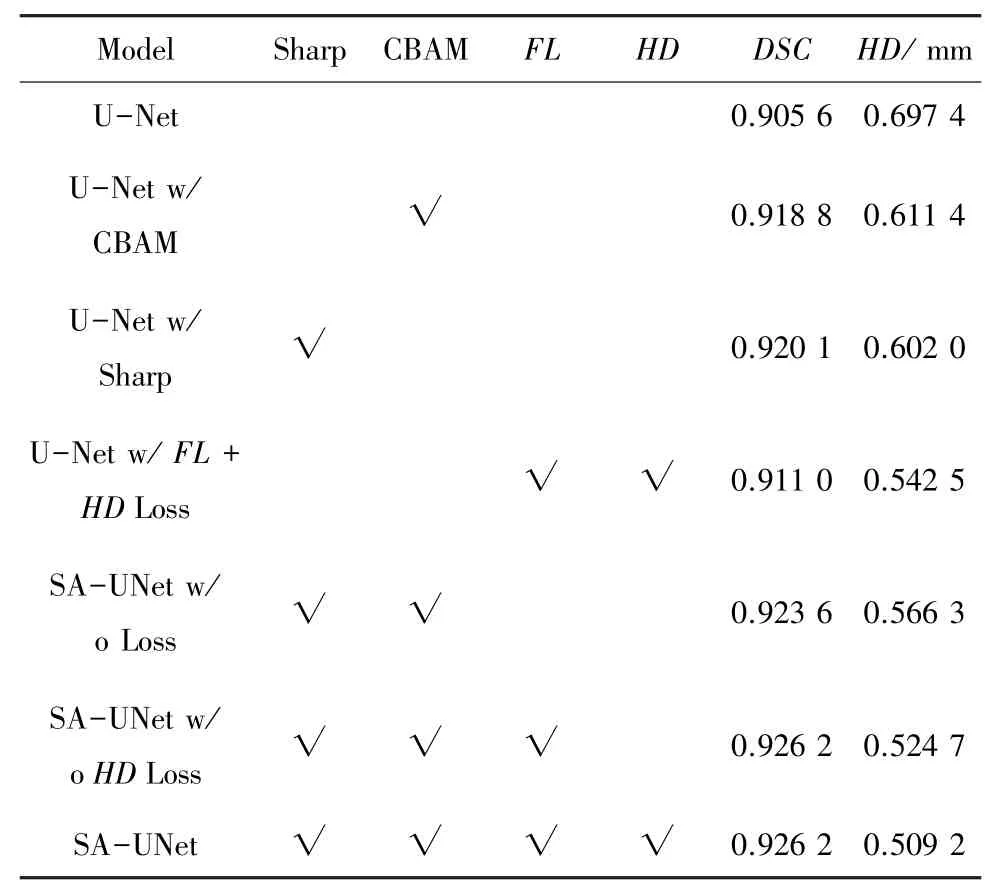
表1 不同改进方案下的网络性能Tab. 1 The performance of network with different improved strategies
3.5 网络模型对比实验
本节将通过与U-Net、UNet ++、DeepLabV3、Attention U-Net、ResUNet 等当前主流分割模型进行对比分析,进一步验证提出模型的准确性和有效性。表2 给出了不同网络模型在测试集上指标IoU、DSC、Recall、Precision与Hausdorff 的得分情况。
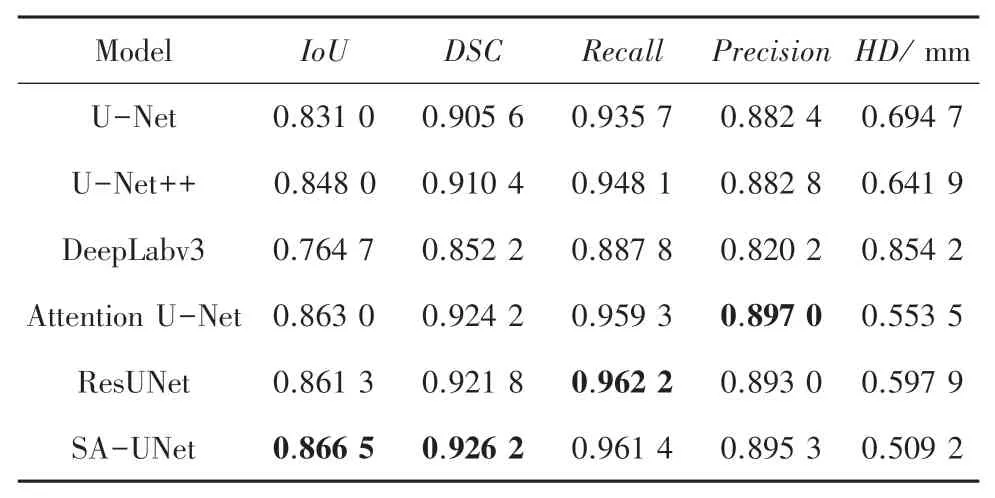
表2 不同网络模型对比Tab. 2 Performance comparison of different network modules
根据表2 不难看出,本文提出的SA-UNet 在IoU、DSC、 Hausdorff 距离三个性能指标皆达到最优,其值分别为0.866 5、0.926 2、0.509 2。分别领先位于其后的Attention U-Net 网络0.41%、0.22%和8.0%。ResNet 网络的Recall指标最优为0.962 2,Attention U-Net 网络的Precision指标在所有模型结果中最优为0.897 0。 本文的SA-UNet 性能皆位居第二,略低0.08%和0.19%。 DeepLabv3 模型由于网络层数较深,模型参数量较大,难以有效关注到图像低层的细节信息,导致分割效果较差,从而反映了U型网络中跳跃连接的重要性,侧面验证本文通过跳越连接层的改进与注意力机制的结合,加强图像细节信息而提高分割结果的合理性和优越性。
3.6 模型复杂度实验
为了进一步检验模型的复杂度,本节将SAUNet 与 U - Net、 U - Net ++、 Attention U - Net、DeepLabv3[31]、ResUNet 等5 种经典分割网络模型的参数量和浮点运算量进行了分析,结果见表3。 结合表2 可以看出,与基准网络U-Net 相比,本文提出的SA-UNet 参数量只增加了0.03 M,计算量只增加了0.4 G,而IoU指标提升了4.27%,DSC指标提升了2.27%。 也就是说,在几乎没有增加开销的情况下,图像分割精度得到了有效的提升。 进而,相比于Attention U-Net,本文研究的模型参数量减少了0.06 M,计算量降低了1.53 G,而IoU指标提升了0.41%,DSC指标提升了0.22%,网络的分割精度和计算效率也得到了有效的改善。 这进一步验证了Sharp 模块没有额外可学习参数,CBAM 模块只有极少数的额外参数。 因此,SA-UNet 作为轻量级的模型在小样本医学图像数据集中更加适用。

表3 模型参数Tab. 3 Model parameters
3.7 可视化分割结果分析
本节将给出不同网络模型对口腔CBCT 图像移植骨分割的可视化结果,如图4 所示。 图4(a)中第1~5 列分别表示来自5 位不同病人的口腔CBCT 图像,(b)为移植骨的真实标签,(c) ~(h)分别为U-Net、U -Net ++、DeepLabv3、Attention U - Net、ResUNet、SA-UNet 的分割结果。
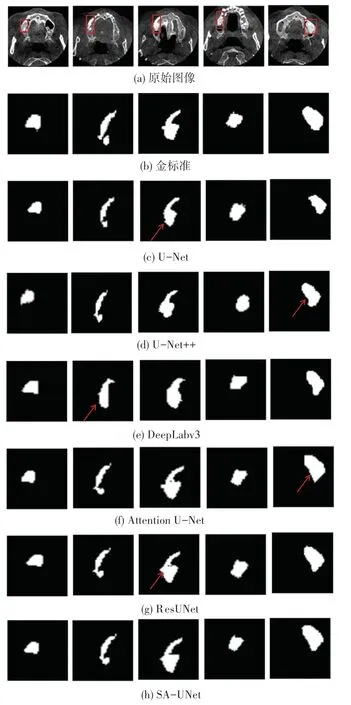
图4 不同患者口腔CBCT 图像的分割结果Fig. 4 Segmentation results of CBCT images from different patients
U-Net 和U-Net++网络能够基本实现对移植骨的分割。 但是U-Net 只是通过跳跃连接实现低层特征信息和高层特征信息的拼接,忽略了二者较大的语义差距带来特征信息的丢失;U-Net++网络通过大量的短连接实现多尺度特征信息的整合,但并没有加强低层特征的重要性。 由图4(c)、(d)可以发现,在U-Net 与U-Net++网络模型的分割结果中,容易发生欠分割,并且对于移植骨凸出的边缘分割效果不佳。 DeepLabv3 模型由于网络层数较深,且在解码部分使用多次的双线性采样。 由图4(e)可以看出,该模型难以捕捉到移植骨图像的细节信息(如图像的边缘,纹理信息),分割边缘过于平滑,整体分割效果较差。 ResUNet 通过残差连接的方式保留低层特征信息,Attention U-Net 通过注意力门的方式抑制不相关的区域,但仍然有特征学习不充分,在分割区域内有少量噪声产生。 由图4(f)、(g)可知,2 个网络对于移植骨的整体轮廓分割效果较好,但依然有噪声的残留(见第三列),并且对于移植骨凸出部分分割不够平滑,过于尖锐(见第五列)。 与这些网络模型相比,本文提出的SA-UNet可以获得更优的分割性能,在分割中能够更准确地捕捉边界信息过滤分割区域中的细小噪声(见图4(h)中的第二列、第三列);此外,本文网络还能够平滑地处理模糊边界的情况,获得更为精细的分割结果(见图4(h)中的第四列、第五列)。
4 结束语
本文提出了一种基于U-Net 和注意力机制的新型编码解码网络模型,该模型通过构建Sharp 模块改进跳跃连接简单的复制操作,增强低层图像细节信息,平衡拼接操作产生的语义差距,通过在解码器部分的每一层嵌入CBAM 模块,通过注意力机制分配不同权重使得模型更加关注重要信息,抑制无用信息。 通过实验表明,本文提出的SA-UNet 网络结构能够通过Sharp 模块的锐化操作增强低层特征,并通过注意力机制提高对于图像细节信息的关注度,同时设计了联合损失函数对不平衡数据集进行优化,在移植骨图像分割结果中有较好的性能。在模型复杂度方面,与U-Net 相比,几乎没有增加计算开销,并且参数量远小于其他医学模型,同时分割精度与U-Net 相比在IoU,Dice系数两个指标上分别提高了0.035 5,0.020 6;在分割精度方面,与现有的主流分割模型对比,在IoU、Dice系数、Hausdorff 距离三个评价指标上的表现最佳,得分达到了0.866 5、0.926 2、0.509 2。 由于本模型能够有效提升图像细节信息的特征提取能力,且模型参数相对较少,因此同样适用于语义简单、结构固定的其他小样本医学图像数据集的分割以及辅助诊断应用。
