基于决策边界优化域自适应的跨库语音情感识别
2023-02-24傅洪亮陶华伟
汪 洋,傅洪亮,陶华伟*,杨 静,谢 跃,赵 力
(1.粮食信息处理与控制教育部重点实验室(河南工业大学),郑州 450001;2.南京工程学院 信息与通信工程学院,南京 211167;3.东南大学 信息科学与工程学院,南京 210096)
0 引言
情感是人类智能的重要组成部分,赋予计算机从人类的语音信号中识别情感状态的能力,是当前人工智能、模式识别、认知科学等领域的研究热点[1]。目前大多数语音情感识别方法都是在单一语音库上进行,然而在许多实际应用中,测试语音数据的语种、发音风格、录制环境等,往往与训练语音数据存在极大的差异,导致训练过的模型在测试数据上识别性能下降[2],这是典型的跨库语音情感识别问题。因此,开发更具鲁棒性的、能更好适应测试数据变化的语音情感识别系统至关重要。
近年来,研究者们从特征处理以及特征分布对齐角度,提出了许多跨库语音情感识别算法,Zhang 等[3]提出一种迁移稀疏判别子空间学习(Transfer Sparse Discriminant Subspace Learning,TSDSL)方法,引入判别性学习和范数惩罚,学习不同语音库间的域不变特征,并利用最近邻图以减小域间差异;Luo 等[4]介绍了一种基于非负矩阵分解(Nonnegative Matrix Factorization,NMF)的跨库语音情感识别方法,使用最大均值差异(Maximum Mean Discrepancy,MMD)同时最小化两个语料库的边际分布和条件分布差异;Zhang等[5]提出了一种联合分布自适应回归(Joint Distribution Adaptive Regression,JDAR)方法,联合考虑训练和测试语音数据之间的边际和条件概率分布来学习回归矩阵,降低不同库之间的特征分布偏差。随着深度学习的发展,相关方法被提出,用于学习源域和目标域间的可鉴别特征:Deng 等[6]提出了半监督自编码器进行共性情感特征学习,提升跨库语音情感识别性能;Gideon 等[7]使用对抗域自适应的方法,让模型在不同数据集中学到的表征相近,提高模型的泛化能力;Lee[8]提出一个基于三联体网络的新框架来学习跨多个语料库的更广义的特征;Abdelwahab 等[9]使用对抗性多任务训练来提取训练域和测试域之间的共同表示;Liu 等[10]基于深度卷积神经网络的特征提取模型和MMD 算法提取更具鲁棒性的语音特征,以获得更好的跨语料库识别性能。上述方法虽取得了一定的效果,但仍存在部分问题。在传统降维方法中,对于情感变化缓慢的语音信号,易丢失情感信息,而深度域自适应方法则会导致无标签的目标域语音库样本可鉴别性降低,致使模型决策边界数据密度大,降低识别性能。
通过对以上问题的分析,本文提出了一种基于决策边界优化域自适应(Decision Boundary Optimized Domain Adaptation,DBODA)的跨库语音情感识别方法。首先,在特征处理阶段,使用一维卷积神经网络(One-Dimensional Convolutional Neural Network,1D-CNN)作为特征处理网络,在保留特征原有情感信息的同时,深入挖掘相邻情感特征之间的潜在相关性,提升特征表征能力;其次,提出一种基于最大化核范数及均值差异(Maximum Nuclear-norm and Mean Discrepancy,MNMD)的域自适应算法,在减小域间差异的同时,可以有效缓解深度域自适应方法面临的决策边界数据密度较大的问题,增强无标签数据的可鉴别性,继而提升跨库语音情感识别性能。
1 基于决策边界优化域自适应的跨库语音情感识别
1.1 跨库语音情感识别模型
基于决策边界优化域自适应(DBODA)的跨库语音情感识别模型整体框架如图1 所示。使用卷积神经网络进行特征处理,经过softmax 层获得样本属于各个类别的概率,利用源域分类损失反向传播训练模型。为了让模型从源域迁移到目标域,减小域间差异,将经过卷积神经网络处理的源域特征和目标域特征送入MNMD 模块,执行特征分布对齐操作,最后利用源域分类损失和特征分布对齐损失联合回传,对模型进行优化,在1.2 节和1.3 节对特征处理和最大化核范数及均值差异进行详细介绍。

图1 基于决策边界优化域自适应的跨库语音情感识别框架Fig.1 Cross-corpus speech emotion recognition framework based on decision boundary optimized domain adaptation
1.2 特征处理
现有研究[11-12]显示,相较于传统降维方法或深度神经网络(Deep Neural Network,DNN),卷积神经网络在保留特征原有情感信息的同时能有效提升特征表征能力,因此本文采用一维卷积神经网络对语音特征进行处理,网络模型如图2所示。
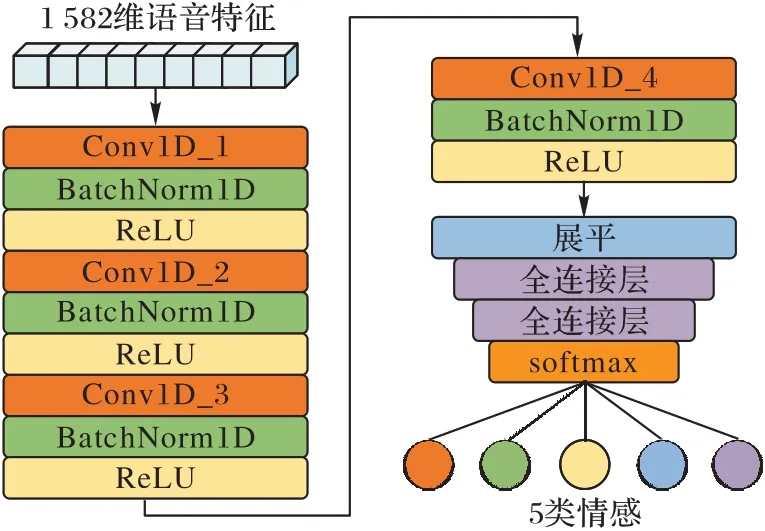
图2 一维卷积神经网络框架Fig.2 Framework of 1D-CNN
使用4 个一维卷积层构成前端特征处理网络,由于降采样层的使用会存在特征信息丢失的风险,因此仅在每个一维卷积层之后加入BatchNorm 层,将源域语音库和目标域语音库的特征分布归一化,防止网络过拟合的同时能提升特征表征的泛化性,使用ReLU(Rectified Linear Unit)激活函数,在简单的网络结构设置下进一步提升特征处理速度。与传统降维方法或DNN 相比,卷积神经网络对全局特征进行处理,且单个卷积层上的多卷积核提取了多个局部表示,深入挖掘相邻特征间的关联性,更好地保留了情感信息。网络中各层的参数如表1 所示(n为卷积核数,k为卷积核尺寸,s为步长,b为批次,f为特征维度);经全连接层将特征维度映射为情感类别后,应用softmax 层将五类情感的预测输出为[0,1]的概率,将源域的分类结果与标签做交叉熵,得到源域的分类损失为:

表1 一维卷积神经网络模型参数Tab.1 Model parameters of 1D-CNN
其中:B表示训练过程中的批次大小;yic取值为1 或0,当样本属于第c类情感类型则yic取1,否则取0;表示样本属于第c类情感类型的预测概率。
1.3 最大化核范数及均值差异
经过有效的特征处理,跨库语音情感识别仍面临一个核心问题,即减小源域语音库和目标域语音库间的特征分布差异,在相关研究[4-5,10,13]中,MMD 方法已被广泛用于域间差异度量,将源域和目标域特征映射到样本空间上的连续函数,求两个特征分布映射后的函数值均值,作差得到两个分布对应函数的均值差异,可表达为如下形式:
其中:H 为再生核希尔伯特空间,Φ为映射函数,Ds代表源域的特征分布,Dt代表目标域的特征分布。
然而最新研究[14]表明在利用MMD 进行域级特征分布对齐时,会使得特征一般化,丢失类间特性,大量的目标域样本在经过特征分布对齐后,聚集在模型的决策边界上,导致目标域特征的可鉴别性下降。为了提升目标域特征的鉴别性,受批核范数最大化[15]工作的启发,本文提出了最大化核范数及均值差异(MNMD),改进后的损失函数可以表示为:
其中:F表示特征处理网络;xs和xt分别表示源域和目标域样本特征;‖·‖*代表求解核范数。
将两个域的特征映射函数Φ相减,得到的特征分布差异回传,促进模型从源域迁移至目标域。在此过程中,对于有标签的源域语音库,最小化其分类损失,以优化特征处理网络。在无标签的目标域语音库上,最大化情感预测概率矩阵的核范数,优化模型决策边界。目标域情感预测概率矩阵P∈RB×C可以表示为如下形式:
其中:Pi,j为将样本i预测为情感类型j的概率;B为批次大小,C为情感类别数,B和C也分别代表了预测概率矩阵P的行数和列数。
MNMD 通过最大化P的核范数,约束其Frobenius 范数[16],以使得其香农熵减小,消除预测不确定性,提升目标域样本可鉴别性,其约束关系如下:
其中:‖P‖*、‖P‖F、H(P)分别表示情感预测概率矩阵的核范数、Frobenius 范数和香农熵。最大化核范数时,可以降低香农熵,使得情感预测概率Pi,j趋近于0 或1 时,则预测的不确定性下降,模型决策边界得到优化。
此外,MNMD 能够在提升目标域情感特征鉴别性的同时保证预测的多样性,情感预测概率矩阵的秩可以近似为其预测类别数,其核范数为矩阵秩的凸包络[15],则最大化其核范数可以有效保证情感预测的多样性,避免了熵最小化导致的模型优化偏移。因此MNMD 很好地缓解了模型从源域语音库迁移到目标域语音库过程中,低鉴别性的目标域样本高密度堆积于决策边界上的问题。
2 实验设置及结果分析
2.1 语音情感库及语音特征提取
2.1.1 语音情感库
为了评估所提模型的性能,选用Berlin 语音情感库[17]、eNTERFACE 语音情感库[18]和CASIA 汉语语音情感库[19]进行了大量的实验。Berlin 库是由柏林工业大学录制的德语情感语音库,也是语音情感识别中使用最为广泛的语音库之一,由10 位演员对10 个语句进行7 种情感的模拟得到,经过听辨测试后保留了535 条最为有效的语音;eNTERFACE 库是一个视听情感数据集,包含6 种情感,由来自14 个国家的42位受试者用英语进行录制,共有1 287 条语音;CASIA 汉语情感语料库由中国科学院自动化所录制,共包括4 个专业发音人,1 200 条公开语音,6 种情感。
2.1.2 语音特征提取
参考文献[3,5]的实验设置,选取IS10 情感挑战赛的规定特征集[20]作为模型输入,其中共有1 582 维特征,包含34个基本的低级描述符(Low-Level Descriptors,LLDs),即梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)、线谱对(Line Spectrum Pair,LSP)和34 个相应的delta 系数,基于这些低级描述符,应用21 个统计函数得到1 428 维特征,此外,对4 个基于音高的低级描述符与其相应的delta 系数,应用19 个统计函数,得到152 维特征,将音高的开始与持续时间作为最后2 个特征,构成1 582 维语音特征。为了保持和其他研究者的一致性以及实验的可复现性,本文使用openSMILE 开源工具[21]对原始语音进行特征提取。
2.2 实验设置及评价指标选取
实验根据3 个语音情感库设计了6 组跨库语音情感识别任务,每组跨库语音情感识别任务选取训练语音库和测试语音库的共同情感进行评估,具体任务设置如表2 所示。

表2 跨库语音情感识别任务设置Tab.2 Cross-corpus speech emotion recognition task setting
在6 个任务中,将e2B、B2e、C2e、e2C、C2B、B2C 的学习率和batchsize 分别设置为{0.001,0.01,0.01,0.01,0.01,0.001}与{16,16,16,16,16,16},迭代轮次设置为2 000。采用非加权平均召回率(Unweighted Average Recall,UAR)作为评价指标,对不同模型的识别效果进行评估。
2.3 实验结果及分析
2.3.1 香农熵验证实验
为了验证模型是否降低了预测概率矩阵的香农熵,有效提升预测样本鉴别性,将MMD 和MNMD 在6 组跨库识别任务中迭代训练1 000 轮的熵值变化绘制如图3。
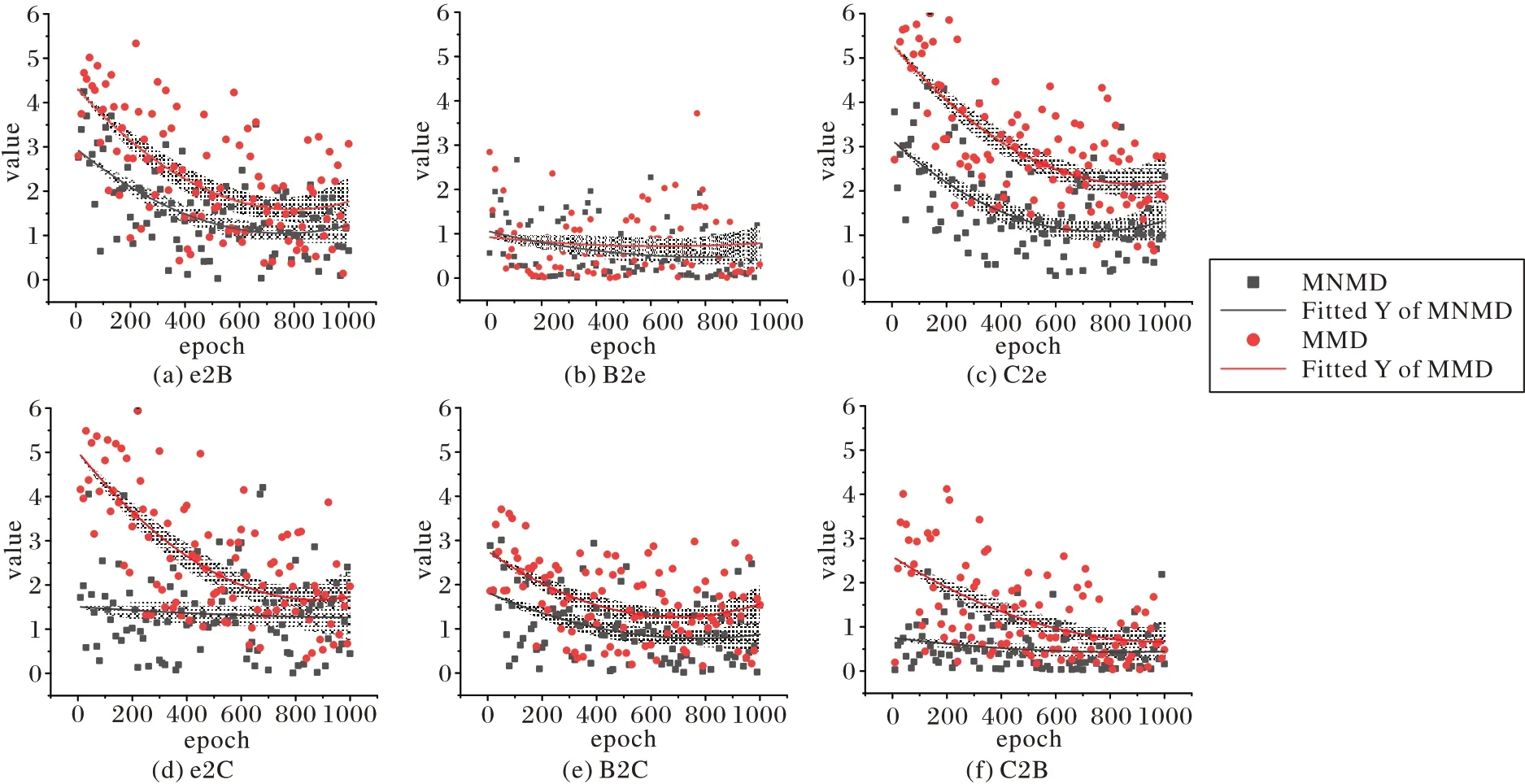
图3 MMD和MNMD在迭代训练中的香农熵变化比较Fig.3 Comparison of Shannon entropy change of MMD and MNMD during iterative training
图中阴影部分和曲线分别表示熵值变化的95%置信区间与其拟合曲线。从图中可以看出,在6 组跨库识别任务中,相较于MMD,MNMD 都有效降低了预测概率矩阵的香农熵,特别是在e2B、C2e 和B2C 任务中,极大地提升了目标域样本的鉴别性,降低了预测的不确定度,证实了最大化核范数能有效缓解决策边界目标域样本密度高的问题。
2.3.2 消融实验
为了进一步验证模型的合理性,清晰地观察所提域自适应方法的效果和对MMD 改进后的提升,实验设置了消融模型进行对比,分别为:
1)O-CNN(Only CNN):不使用任何域自适应手段,直接将源域训练后的模型应用于目标域。
2)CNN+MMD:使用1D-CNN 和原始的MMD 分别进行特征提取和源域目标域的特征分布对齐。
3)CNN+MNMD:即所提模型DBODA。
将各个模型在实验中迭代训练得到的准确率(UAR)绘制成箱形图,如图4 所示。
通过图4 中对各消融实验模型在不同任务中的识别率分析可以看出,在全部的6 个跨库语音情感识别任务中,相较于原始的深度学习方法,使用MMD 减小域间差异,都获得了一定的性能提升;同时,所提MNMD 经过对MMD 的改进在各任务上都获得了最优的识别结果,在e2B 任务中获得了最大的识别率均值提升,并在e2B、B2e 和C2B 任务中显著提升了模型识别的稳定性。将消融实验中各模型的准确率列于表3,可以看出,所提模型的识别性能在6 个跨库识别任务中均获得了最优表现,平均识别率相较于其他消融实验模型分别领先5.42 和4.29 个百分点,消融实验结果证实了DBODA的合理性。为进一步说明所提MNMD 在对MMD 进行优化后,能够有效降低决策边界上的数据密度,在e2B 和B2e 任务中,将CNN+MMD 模型和DBODA 模型训练后的特征使用t-SNE 绘制为特征分布图如图5,可以看出DBODA 模型处理后的特征获得了更好的特征分布对齐效果,类间数据密度低,实现了对决策边界的优化。

表3 消融实验中各模型的UAR 单位:%Tab.3 UAR of each model in ablation experiment unit:%
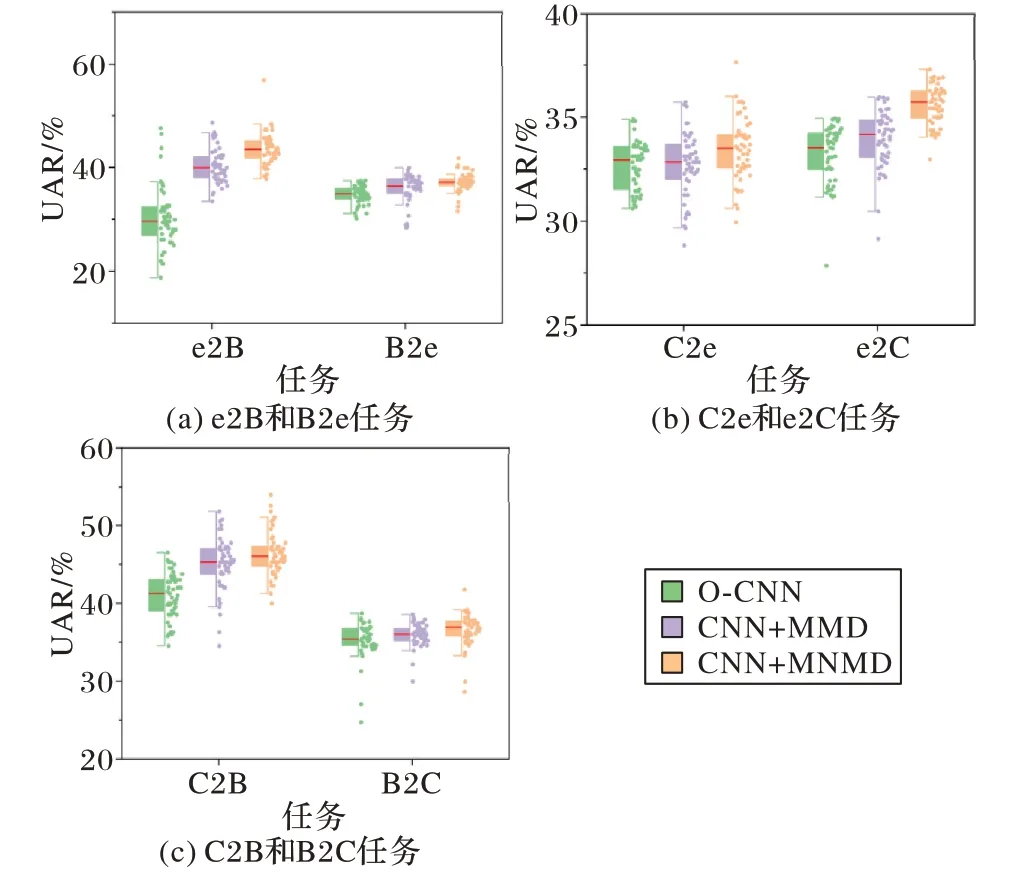
图4 不同任务中各模型的箱形图Fig.4 Box plots of each model in different tasks

图5 e2B和B2e任务中的特征分布Fig.5 Distribution of features in tasks e2B and B2e
2.3.3 与其他算法对比
为了验证所提模型在跨库语音情感识别领域的先进性,将它与基线及最新算法进行性能对比,这几种算法分别为:
1)支持向量机(Support Vector Machine,SVM)。选择线性核函数,C值设置为0.1。
2)迁移稀疏判别子空间学习(TSDSL)[3]。引入鉴别性学习和ℓ1,2范数正则化,学习鉴别性特征并构造了最近邻图作为距离度量手段,以提升源域和目标域的相似度。
3)联合分布自适应回归(JDAR)[5]。通过联合考虑训练语音与测试语音间的边际概率分布和条件概率分布来学习回归矩阵,缓解特征分布偏差。
4)域对抗神经网络(Domain Adversarial Neural Network,DANN)[9]。特征提取器采用了四层隐层DNN 结构,情感分类器和域鉴别器均使用两层隐层DNN结构。
5)深度域自适应卷积神经网络(Deep Domain⁃Adaptive Convolutional Neural Network,DDACNN)[10]。模型采用经典LeNet架构,尝试在不同全连接层使用MMD以对齐特征分布,最终在第一层全连接层纳入MMD获得了最优识别结果。
6)深度自编码器子域自适应(Depth Autoencoder Subdomain Adaptation,DASA)[22]。使用自编码器进行特征处理,在编码和解码阶段均使用五层隐层DNN 结构,并结合子域自适应实现细粒度的特征分布对齐。
将与传统算法及特征降维算法的识别精度(UAR)对比列于表4,与深度域自适应算法的识别精度(UAR)对比列于表5。
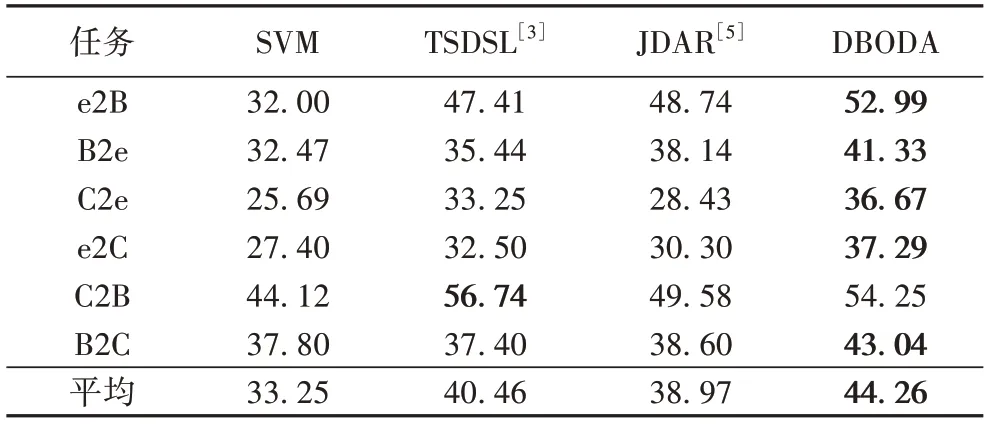
表4 与传统算法及特征降维算法的UAR对比 单位:%Tab.4 UAR comparison with traditional and feature reduction algorithms unit:%

表5 与深度域自适应算法的UAR对比 单位:%Tab.5 UAR comparison with deep domain adaption algorithms unit:%
可以看出,在全部的6 个任务中,相较于传统算法及特征降维算法,所提模型在e2B、B2e、C2e、e2C 和B2C 任务上的识别率分别领先了4.25~20.99、3.19~8.86、3.42~10.98、4.79~9.89、4.44~5.64 个百分点,平均识别率领先3.8~11.01 个百分点,展现出了卷积神经网络良好的特征处理能力。相较于深度域自适应算法,所提模型在e2B、B2e、C2e、e2C 和B2C 任务上的识别率分别领先了0.32~3.06、1.22~6.82、4.58~7.5、0.69~5.39、0.15~4.94 个百分点,平均识别率领先1.68~5.48个百分点,体现了所提算法经过对原有域自适应算法改进后,跨库语音情感识别模型的泛化性得到了提升。但在C2B任务中识别率低于最先进算法,从图3(b)中也可看出,使用MMD进行域对齐,也能在该任务上有效降低香农熵,实现与MNMD相近的效果,说明MNMD 的普适性需进一步优化。总体而言,所提决策边界优化域自适应模型在对齐源域和目标域特征分布的同时,缓解了使用MMD进行域对齐带来的鉴别性丧失问题,提升了目标域样本的鉴别性,优化了模型决策边界,提升了模型识别性能。
3 结语
为了解决跨库语音情感识别问题,本文提出一种新的基于决策边界优化域自适应(DBODA)模型,旨在将源域语音库学习到的知识转移到目标域语音库,新的域自适应方法MNMD 在进行源域与目标域特征分布对齐的同时,考虑了目标域样本的鉴别性和预测多样性,在3 个基准数据集上进行的实验验证了模型的性能提升。在后续的研究中,将针对域自适应导致目标域样本鉴别性下降的问题,进一步改进域自适应算法,增强泛化性,将模型应用于更多的语音情感库中。
