基于改进SAC算法的移动机器人路径规划
2023-02-24李永迪李彩虹张耀玉张国胜
李永迪,李彩虹,张耀玉,张国胜
(山东理工大学 计算机科学与技术学院,山东 淄博 255049)
0 引言
在移动机器人自主导航中,路径规划是一个重要的组成部分,可以描述为在一定的约束条件下,寻找一条从起点到目标点的最优路径。常见的路径规划方法有人工势场法[1]、A*算法[2-3]、蚁群算法[4-5]、遗传算法[6]、粒子群优化算法[7]等。这些算法大都需要建立地图模型,工作在已知环境下;另外在复杂环境中存在运算时间长、迭代次数多以及在未知环境下实时性差或者容易陷入局部最优等问题。
近年来,深度学习(Deep Learning,DL)[8]和强化学习(Reinforcement Learning,RL)[9]成为机器学习领域重要的研究热点,将深度学习和强化学习相结合的深度强化学习(Deep Reinforcement Learning,DRL)[10]算法在移动机器人路径规划中得到了广泛使用。深度强化学习具有深度学习的感知优势和强化学习的决策优势,其中,深度学习负责通过传感器获取周围环境信息来感知机器人当前的状态信息,而强化学习负责对获取的环境信息进行探索、做出决策,从而实现移动机器人路径规划的智能化需求。
SAC(Soft Actor-Critic)算法是Haarnoja 等[11]提出的一种稳定高效的DRL 算法,适用于现实世界的机器人技能学习并能与机器人实验要求高度契合,能够满足实时性的需求;Haarnoja 等[12]在SAC 算法中加入了熵权重的自动调整,在训练前期熵的权重较大,在后期逐渐衰减熵的权重,让智能体收敛更加稳定;De Jesus 等[13]将SAC 算法应用到ROS(Robot Operating System)环境下,实现了移动机器人在不同环境下的局部路径规划,但算法存在训练时间长和环境奖励稀疏的问题;肖硕等[14]引入智能体通信机制,有效降低了环境不稳定性对算法造成的影响,但样本利用率低、收敛慢;单麒源等[15]优化了算法的状态输入,改善了训练次数越多奖励值越低的问题,但应用场景简单,面对复杂环境算法效率无法保证;胡仕柯等[16]通过在原有算法中引入内在好奇心机制,提高智能体探索能力与样本利用效率,同样存在应用场景简单且收敛速度较慢。
针对上述算法的不足,本文对SAC 算法进行了改进,首先,提出的PER-SAC 算法使用三层全连接神经网络,通过雷达传感器获取环境信息和目标点信息,并且令环境中障碍物的距离信息、机器人的角速度和线速度、机器人与目标点之间的距离和角度,作为网络的输入,输出为机器人的角速度和线速度;进而结合优先级经验回放(Prioritized Experience Replay,PER),对经验池中不同样本的重要程度进行区分,使重要程度较高的样本更频繁地回放,进一步提高了原始算法中样本的利用率,从而进行更有效的学习,提高算法的收敛速度;然后设计改进的奖励函数,克服环境奖励稀疏的缺点;此外,设计了不同的仿真环境(无障碍物、离散障碍物和特殊障碍物),提高算法的泛化性;考虑到在不同障碍物环境下实验的重复性,引入迁移学习,将收敛后的无障碍物模型作为离散型障碍物与特殊障碍物环境的初始化模型,加快算法收敛。
1 SAC算法
SAC 算法使用了AC(Actor-Critic)体系结构[17]。传统强化学习的目标是使奖励的期望最大,而SAC 使奖励期望和熵值同时最大化:
其中:E是当前状态的回报期望,r是当前状态的回报值,ρπ为t=0 到T所有的状态和动作的集合,H是当前动作的熵,τ是温度系数,π是通过网络得到的当前状态的所有动作概率。
SAC 算法为了减小值函数的估计误差,在Actor-Critic 体系的基础上增加了价值网络,由1 个Actor 网络(策略网络)和4 个Critic 网络构成,分别是状态价值估计V和TargetV网络,由VCritic 表示;动作-状态价值估计Q0和Q1网络,由QCritic 表示。SAC 算法网络构架如图1 所示。
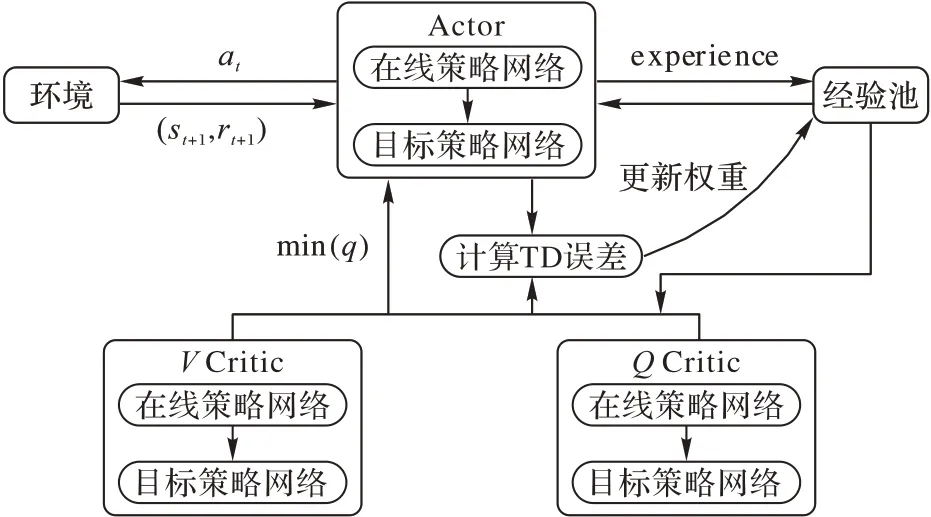
图1 SAC算法网络构架Fig.1 Network framework of SAC algorithm
已知一个状态st,通过Actor 网络得到所有动作概率π(a|st),依概率采样得到动作at∈a,将at输入到环境中得到st+1和rt+1,获得1 个experience:(st,at,st+1,rt+1),放入到经验池中。
在QCritic 网络中,从经验池中采样出数据(st,at,st+1,rt+1),进行网络参数ω的更新,将动作at的q(st,at)值作为st的预测价值估计,根据最优Bellman 方程得到作为st状态的真实价值估计:
其中Eπ为当前状态的累计回报期望。
用均方损失函数作为损失,对QCritic 网络进行训练,损失函数定义为:
其中B为从经验池中取1 个batch 的数据。
在VCritic 网络中,从经验池采样出数据(st,at,st+1,rt+1),进行网络参数θ的更新,Vcritic 网络输出的真实值为:
其中:为Actor 网络的策略π预测的下一步所有可能动作;lnπ(,θ)为熵。
根据真实值计算Vcritic 网络的损失:
在Actor 网络中,进行梯度下降训练的损失函数定义为:
强化学习通过时序差分(Temporal-Difference,TD)误差衡量算法修正幅度,采用计算TD 误差的形式对策略选择的动作at进行评估:
其中:Q为Critic 的状态价值,γ为折扣因子。
2 改进SAC算法
为提高训练速度和稳定性,本文设计了PER-SAC 算法,将优先级经验回放引入SAC 算法中,使从经验池中等概率随机采样变为按照优先级采样,增大重要样本被采样的概率。利用重要性采样权重来修正优先回放引入的误差,并更新网络的损失函数,减少模型的错误率。PER-SAC 算法包含了网络结构、奖惩函数、连续的状态空间和动作空间的设计。
2.1 网络结构
PER-SAC 算法所采用的神经网络有14 个输入和2 个输出,如图2 所示。
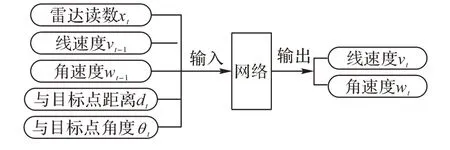
图2 网络的输入和输出Fig.2 Network input and output
网络的输入包括:雷达10 个方向上的读数xt,机器人的线速度vt-1和角速度wt-1,机器人的相对位置与目标点的标量距离dt和角度θt;网络的输出为机器人的线速度vt和角速度wt。
SAC 网络结构包括策略网络(Actor)、Q网络(QCritic)和价值网络(VCritic)三个部分,如图3 所示。
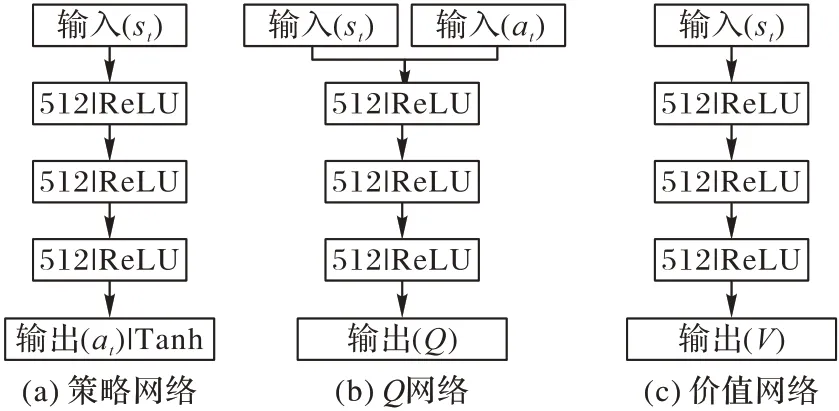
图3 SAC网络结构Fig.3 SAC network structure
策略网络的输入是机器人在环境中的当前状态;隐藏层是3 个具有512 个节点的全连接层;输出层生成发送给机器人要执行的动作。
Q网络、价值网络和策略网络的隐藏层相同。Q网络给出机器人当前状态和动作的Q值,而价值网络预测当前状态值。
2.2 结合优先级经验回放
优先级经验回放赋予每个样本一个优先级。从经验池采样时,使优先级越高的样本被采样的概率越大,提高训练速度,并引入SumTree 来存储样本的优先级。
样本的优先级用TD 误差定义。TD 误差越大,优先级越高。TD 误差δt的计算如式(7)所示,样本抽取的概率定义为:
其中:a用于对优先程度的调节;pi=|δi|+ε是第i个样本的优先度,δi是第i个样本的TD 误差,加入ε用于避免概率为0。
计算TD 误差时要考虑SAC 算法中3 个网络的情况,由于Q网络和价值网络输出的值远大于策略网络的值,将3 个网络的误差直接相加将导致策略网络的误差对总误差影响较小,因此引入调整系数Tα和Tβ对Q网络和价值网络的值进行调整:
由于优先级经验回放改变了样本采样方式,因此使用重要性采样权重来修正优先回放引入的误差,并计算网络进行梯度训练的损失函数,减小模型的错误率。重要性采样权重计算如下:
其中选取了样本j的权重wj,并进行归一化处理,方法是除以所有样本中权重最大的样本i,用maxi(wi)表示;N为样本容量;β是wj的调整系数。
最后使用重要性采样权重对Q网络和价值网络的损失函数进行更新。对式(3)和(5)的更新如下:
2.3 连续的动作空间和状态空间设计
设计恰当的连续状态空间和动作空间作为神经网络的输入和输出,通过传感器返回周围环境信息。
状态空间是对智能体所处环境的反馈,是智能体选择动作空间的依据。机器人搭载的激光雷达,探测范围为360°,探测距离为3.5 m。考虑到机器人不后退、雷达数据多和计算量大的问题,只使用机器人前方180°的探测范围和10 个方向上的雷达数据。激光雷达数据的采集方向设置结构如图4 所示。
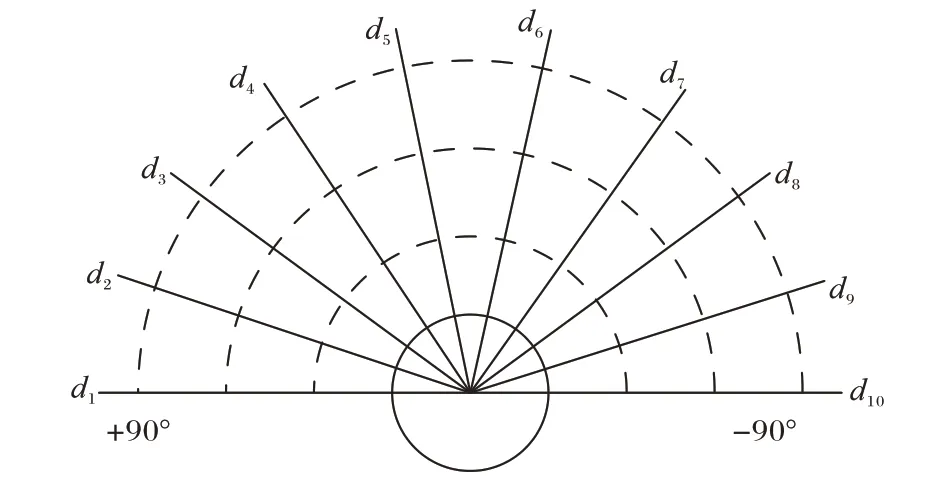
图4 激光雷达数据采集结构Fig.4 Lidar data acquisition structure
机器人的位姿信息由10 个方向雷达返回的最近障碍物的距离信息di以及机器人与目标点之间的距离Dg和角度θg组成,所以移动机器人状态空间sj定义为:
机器人运动学模型使用的是Turtlebot3 的Burger 版本,运动参数包含线速度[vmax,vmin]、角速度[wmax,wmin]、最大加速度a。线速度的取值范围为[0.0,2.0],单位m/s;角速度的取值范围为[-2.0,2.0],单位rad/s。动作空间定义为线速度v和角速度w。
2.4 奖惩函数设计
奖惩函数的设计决定在某一状态下移动机器人执行一个动作的好坏程度。通过设计一种连续性奖惩函数来解决奖励稀疏问题。奖惩函数如下:
其中:rarrival表示到达目标点的正向奖励;dt表示当前时刻机器人到目标点的距离;dt-1表示上一个时刻机器人到目标点的距离;cd表示到达目标点的阈值,小于此值代表到达了目标点;rcollision表示碰到障碍物的负奖励;minx表示激光雷达的最小距离;co表示碰撞障碍物的安全距离,低于这个值表示触碰障碍物;cr1和cr2是设置的两个奖励参数。
如果机器人通过阈值检查到达目标,则给予正奖励;如果通过最小距离读数检查与障碍物碰撞,则给予负奖励。两种情况都足以结束训练。否则,奖励是基于从目标到最后一个时间步的距离差(dt−1−dt)。如果差值是正的,奖励等于经过的距离乘以参数cr1,否则乘以参数cr2。这种措施激励移动机器人更接近目标位置,并鼓励其避开环境中的障碍物。
2.5 迁移学习
局部路径规划中的大部分任务存在相关性,在不同地图环境中利用参数迁移来初始化相关任务中的参数,可以加快移动机器人在不同场景下策略的学习。
首先加载预训练模型,获取全部的模型参数。通过随机初始化训练获得趋向目标点的模型参数ωi,将ωi初始化为离散场景ωs和特殊障碍物场景的模型参数ωt,完善避障规则vs与vt,实现局部路径规划。本文所设计的迁移学习框架如图5 所示。

图5 迁移学习结构Fig.5 Transfer learning structure
3 算法仿真
基于Python 语言,验证所设计的PER-SAC 算法完成移动机器人局部路径规划任务的有效性。在ROS 平台上利用Gazebo 搭建4 种仿真环境(无障碍物、离散型障碍物、一型障碍物和U 型障碍物环境)来进行PER-SAC 算法和原始SAC 算法的对比实验。
为了更清晰地观察仿真结果,将绘制两种算法训练的每轮平均回报值对比图。在Rviz 中,机器人初始位置为起点,方框代表目标点,圆柱体代表障碍物,实线代表机器人的运行轨迹。实验模型部分参数设置如表1 所示。

表1 仿真参数设置Tab.1 Simulation parameter setting
3.1 无障碍物下的仿真
Gazebo 中无障碍物仿真环境和移动机器人如图6 所示,在5 m×5 m 的范围内随机生成目标点进行训练。
图6 无障碍仿真环境Fig.6 Obstacle-free simulation environment
根据设定的参数,移动机器人初始阶段在无障碍物环境中训练,达到预设训练次数后,抽取批量经验进行学习,在探索率上升到预设峰值后,探索率保持不变,继续训练到预训练次数,输出每轮的平均回报值(一轮中的回报值除以本轮步数),如图7 所示。从图7 中可以看出,PER-SAC 算法的平均回报值在30 轮左右开始上升,说明算法开始收敛,收敛速度明显快于原始SAC 算法,而收敛后的PER-SAC 算法相较于原始算法更稳定。

图7 无障碍环境下每轮的平均奖励对比Fig.7 Comparison of average reward per round of obstacle-free environment
用两种算法收敛后模型进行路径规划,起点为(1,0.6),终点为(1.2,1.2),并且在Rviz 中绘制路径,规划结果分别如图8(a)和(b)所示。PER-SAC 算法从起点到终点所用步数为115,原始SAC 算法为118,两种算法的路径基本一致,PER-SAC 算法路径略短。
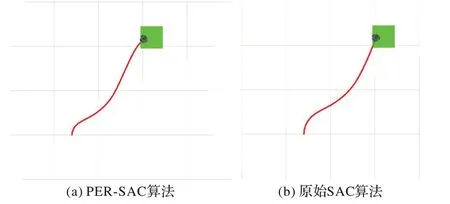
图8 无障碍环境下的路径规划Fig.8 Path planning in obstacle-free environment
3.2 离散障碍物下的仿真
Gazebo 中离散障碍物环境和移动机器人如图9(a)所示,在Rviz 中如图9(b)所示。起点为机器人初始位置,坐标为(-2,-2),目标点坐标为(2,1)。

图9 离散障碍物仿真环境Fig.9 Discrete obstacle simulation environment
利用迁移学习将两种算法在无障碍物环境下训练好的模型迁移到7 m×7 m 的离散障碍物环境中作为初始训练模型,各进行200 轮,每轮500 步的训练后,输出每轮平均回报值,如图10 所示。
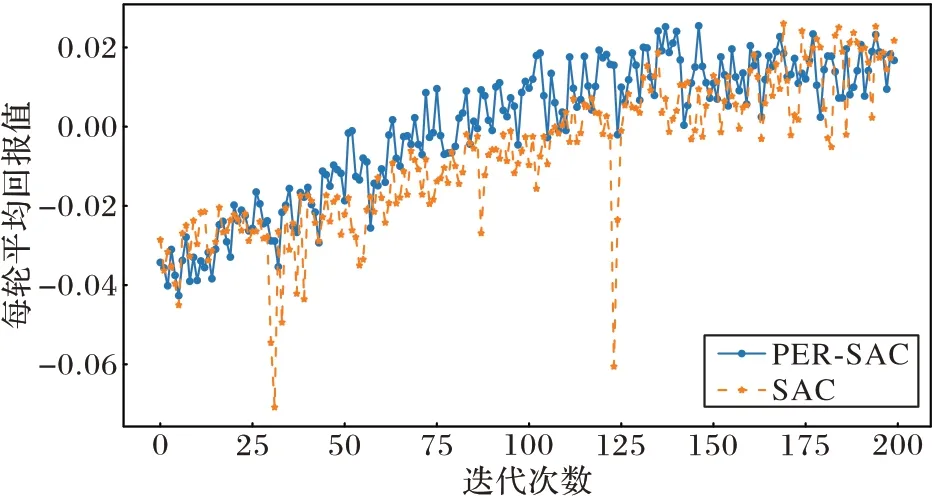
图10 离散障碍环境下每轮的平均奖励对比Fig.10 Comparison of average reward per round in discrete obstacle environment
PER-SAC 算法在30 轮后每一轮的平均回报值明显比原始SAC 算法高,说明PER-SAC 算法每轮中机器人到达目标点的次数更多,并且在140 轮左右模型开始收敛。相较于原始SAC 算法,PER-SAC 算法收敛后每轮的平均回报值波动范围小,更加稳定。
用两种算法收敛后的模型进行路径规划,规划结果如图11 所示。PER-SAC 算法从起点到终点所用步数为248,原始SAC 算法为257。相较于原始SAC 算法,PER-SAC 算法能够规划出趋向目标点的相对更短路径。

图11 离散障碍环境下的路径规划Fig.11 Path planning in discrete obstacle environment
3.3 U型障碍物下的仿真
如离散障碍物下的训练过程,同样利用迁移学习将两种算法在无障碍物环境下训练好的模型迁移到5 m×5 m 的U型障碍物环境中作为初始化训练模型。Gazebo 中U 型障碍物环境和移动机器人如图12(a)所示,在Rviz 中如图12(b)所示。起点为机器人初始位置,坐标为(-1.2,0),目标点坐标为(1.2,0)。
图12 U型障碍物仿真环境Fig.12 U-shaped obstacle simulation environment
两种算法各进行200 轮,每轮500 步的训练后,同样输出平均回报值,如图13 所示。

图13 U型障碍环境下每轮的平均奖励对比Fig.13 Comparison of average reward per round in U-shaped obstacle environment
PER-SAC 算法在25 轮后每一轮的平均奖励明显比原始SAC 算法高,说明每一轮机器人到达目标点的次数更多;PER-SAC 算法在140 轮左右收敛趋于稳定,而原始SAC 算法在180 轮左右,模型的训练和收敛速度更快。
用两种收敛后的模型进行路径规划,并且在Rviz 中绘制路径,分别如图14(a)和(b)所示。PER-SAC 算法从起点到终点所用步数为274,原始SAC 算法为298。相较于原始SAC 算法,PER-SAC 算法能更快走出障碍物,规划出趋向目标点的相对较优路径。
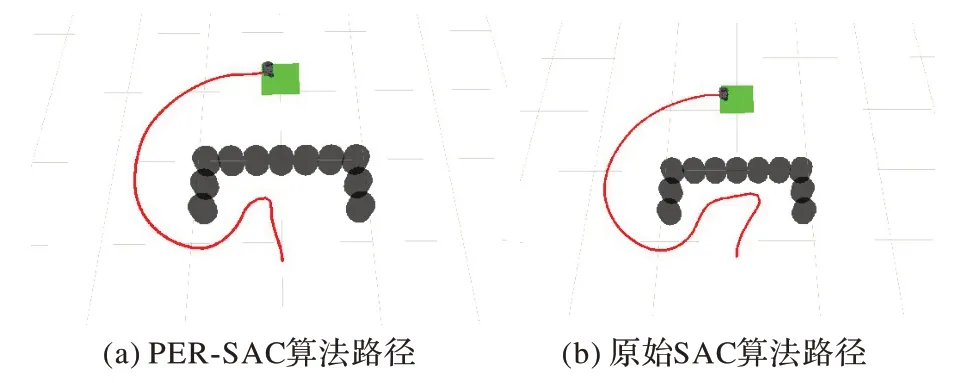
图14 U型障碍环境下的路径规划Fig.14 Path planning in U-shaped obstacle environment
3.4 一型障碍物下的仿真
Gazebo 中一型障碍物环境和移动机器人如图15(a)和(b)所示。起点为机器人初始位置,坐标为(-1.2,0),目标点坐标为(1.2,0)。
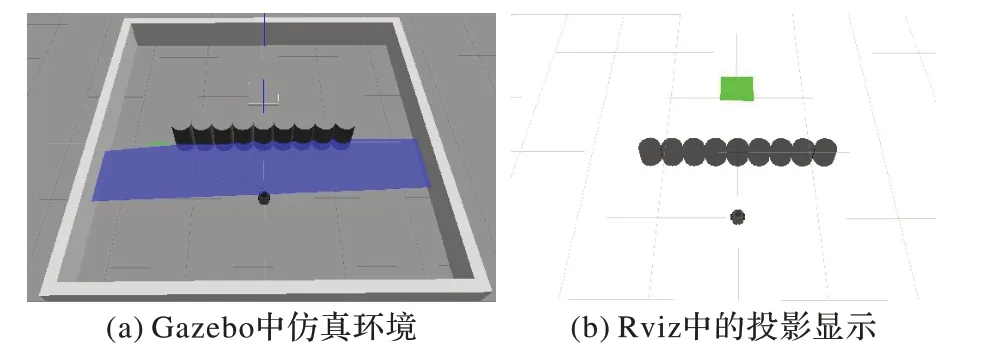
图15 一型障碍物仿真环境Fig.15 1-shaped obstacle simulation environment
U 型障碍物是特殊的一型障碍物,使用3.3 节中U 型障碍物环境下训练好的模型进行路径规划,检测已经训练好的算法的泛化性。如图16 所示,在U 型障碍物环境下训练好的算法同样适用于一型障碍物环境,不需要重新训练即可很好地完成路径规划任务。PER-SAC 算法从起点到终点所用步数为183,原始SAC 算法为226。PER-SAC 算法表现较好,在U 型环境中二者的模型就表现出选择动作的差异,在一型障碍物中表现得更加明显,机器人能更快绕出障碍区域。
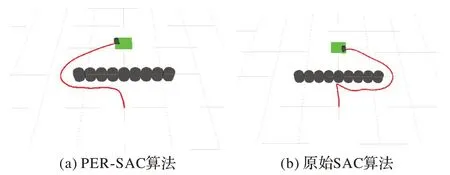
图16 一型障碍环境下的路径规划Fig.16 Path planning in one-shaped obstacle environment
3.5 混合障碍物算法模型验证
搭建两个混合障碍物环境对算法进行验证,混合障碍物是离散型、一型和U 型三种障碍物的组合。
混合障碍物环境一和移动机器人如图17(a)和(b)所示。起点为机器人初始位置,坐标为(-2.2,-2.5),目标点为(1.8,1.3)。

图17 混合障碍环境一Fig.17 The first mixed obstacle environment
使用3.3 节中经过迁移学习从无障碍物到离散障碍物、再到U 型障碍物环境下训练好的模型进行路径规划,如图18所示,同样不需要重新训练即可很好地完成路径规划任务,并且PER-SAC 算法规划的路径较优。PER-SAC 算法从起点到终点所用步数为271,原始SAC 算法为304。
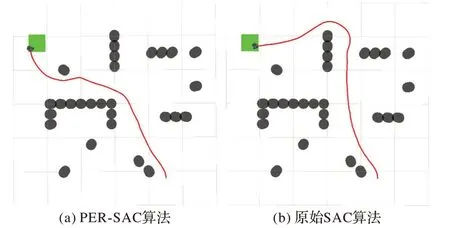
图18 混合障碍环境一下的路径规划Fig.18 Path planning in the first mixed obstacle environment
混合障碍物环境二中,调整了障碍物和目标点的布局,使移动机器人更容易经过U 型障碍物,如图19(a)和(b)所示。起点和目标点分别为(-2.2,-2.5)和(1.25,2)。
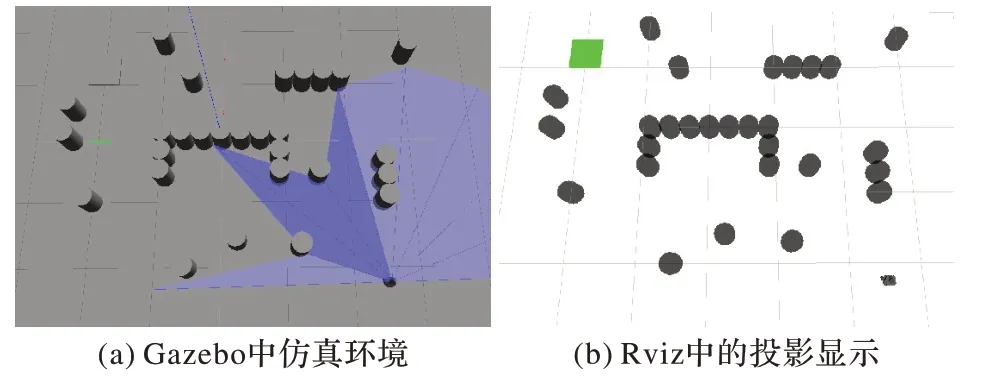
图19 混合障碍物环境二Fig.19 The second mixed obstacle environment
路径规划结果如图20(a)和(b)所示。PER-SAC 算法从起点到终点所用步数为279,原始SAC 算法为310。PER-SAC 算法规划的路径较优,能较好地规避障碍物。

图20 混合障碍环境二下的路径规划Fig.20 Path planning in the second mixed obstacle environment
PER-SAC 算法经过迁移学习后训练得到的模型,能够在不同的环境中规划一条从起点到目标点的路径,算法具有一定的泛化能力,同时验证了算法的有效性。
最后将两种算法在上述三种仿真环境下的训练时间进行汇总,如表2 所示。从表2 中可以看出,在每种环境下,所设计的PER-SAC 算法训练或收敛时间更快。
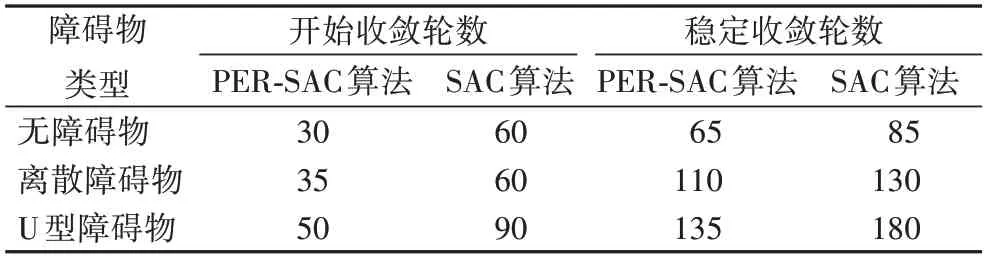
表2 算法收敛时间Tab.2 Algorithm convergence time
再对5 个仿真环境中路径规划时从起点到目标点的步数进行汇总,如表3 所示。从表3 中可以看出,在每种障碍物运行情况下,PER-SAC 算法均比原始SAC 算法所用步数少。

表3 到达目标所用步数Tab.3 Number of steps reaching target
4 结语
对于未知环境下的移动机器人局部路径规划问题,本文提出了一种基于SAC 和优先级经验回放的PER-SAC 算法,并且在不同的仿真环境中与原始算法进行了对比实验,验证了新算法的有效性。PER-SAC 算法具有以下特点:
1)优先级经验回放机制使经验池中的每个样本拥有了优先级,增加了重要程度较高的样本被采样的频率,提高了训练效率和稳定性。
2)在线运行时间和训练时间没有关联,并且充分训练后得到的收敛模型,实际运行时不需要再进行训练。机器人通过传感器实时感知当前环境信息,经训练模型可以求出一条合理的局部规划路径,满足运行的实时性需求。
3)利用参数迁移初始化不同障碍物环境下的模型参数,缩短训练进程,加快模型收敛,模型的泛化性增加。
PER-SAC 算法目前还存在一些局限性,在计算网络的损失函数时直接将重要性采样权重与损失函数相乘,可能导致训练的信息不够充分。下一步的研究方向将考虑优化损失函数,进一步提升算法的性能,使机器人在更加复杂的环境下(多U 型、高混合型)实现局部路径规划任务。
