基于YOLOv5s的SIM卡壳缺陷检测方法研究
2023-02-24王兴智欧阳八生
王兴智,欧阳八生
(南华大学机械工程学院,湖南衡阳 421001)
0 引言
随着电子市场的需求不断拓展,SIM卡座连接器成为电子设备不可或缺的重要配件。SIM卡座连接器是常用的手机和电脑中的组件,目前国内SIM卡座的生产环节已经基本实现无人化,但在检测环节仍然不够完善,外观检查在很大程度上仍然严重依赖人工来完成。人工检查主要是由工人用肉眼鉴别元器件破损、缺失等情况。在高强度的流水线上工作,这就需要操作人员具有丰富的经验以及大量的时间和耐心,在检测过程中准确性难以得到保证。并且对于一些小的缺陷检测效果很差。
随着机器视觉技术的讯速发展,已经有许多行业采用传统的机器视觉技术来检测缺陷[1]。如朱健[2]结合连接器结构特点及SURF算法提出了一种配准速度和精度都有很大提升且适用于连接器图像的配准方法。对连接器的塑胶多胶、破损、刮伤、端子缺失、歪斜等缺陷进行检测,整体的缺陷识别准确率达83%左右,处理的平均时间在0.8 s左右。郑中华等[3]设计了一套基于Labview机器视觉的SIM卡槽缺陷检测系统。对卡槽的引脚缺失、折弯、变形、露铜、包胶等缺陷进行检测,对160个产品进行检测,实现了平均检测时间在0.75 s。陈永清等[4]提出了一种基于机器视觉的连接器非接触自动检测方法,该方法通过卷积滤波获得高质量图像,使缺陷特征与背景产生较大差异;最后,采用基于边缘线建立坐标系的方法,采用Otsu阈值分割自动定位和检测有效区域,消除了产品的位置误差;统计目标像素的数量并检测目标。检测到的缺陷类型有连接器的漏针、堵孔、缺针、翘针、本体刮伤。此方法对预处理要求比较严格。谭台哲[5]设计一个基于机器视觉的电子连接器缺陷检测系统。在Canny算法的基础上,设计一个将Canny边缘检测与亚像素相结合的视觉检测算法。对pin脚之间的间距和pin脚整体平整度进行检测,检测效果良好,但具有针对性。郭羽鹏等[6]提出了一种基于机器视觉原理的连接器检测方法。对采集到的连接器图像先后进行边缘点检测和双阈值Blob提取操作,将划痕缺陷更准确提取出来,实现了对连接器划痕缺陷的检测。对划痕这一单一检测效果能达到94%。
虽然传统机器学习方法对连接器的缺陷检测效率能够有所提高,但存在着实验产品数少、缺陷类型单一等不足,且传统的机器视觉检测往往离不开复杂的预处理,此外在耗时方面还大大提高了成本,难以满足工业上的实时需求。
本文以SIM卡壳为研究对象,鉴于上述问题,提出了一种基于YOLOv5s网络模型的SIM卡外壳缺陷检测方法。
1 基于YOLOv5s模型的缺陷检测
目标检测算法对输入的RGB图像分析功能是本文缺陷检测方法的关键一步。缺陷检测模型的好坏直接影响到SIM卡外壳缺陷识别准确度及识别速度,因此,采用由多种trick的集成,并且开源了一套快速训练、部署方案的YOLOv5s模型能更有效的达到预期。
1.1 整体设计
本文整体的工作任务基于图1所示流程循序进行。

图1 模型训练流程
1.2 YOLOv5s网络模型
YOLOv5模型是Ultralytics公司在2020年6月9日公开发布的。YOLOv5模型是YOLO系列的最新版本,YO⁃LOv5引进了马赛克数据增强,能有效解决模型训练中难以获取的微小对象。在检测速度和精度上都更胜一筹,在某种程度上YOLOv5已经成为YOLO系列算法中的SO⁃TA(StateOfTheArt)[7]。YOLOv5包含了4种版本的目标检测网络,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型。虽然YOLOv5正式发布距离YOLOv4不到50天,但与YOLOv4相比,YOLOv5锚定框是基于训练数据自动学习的不是预先设定的,相对于YOLOV4采用的Darknet框架,YOLOv5的Pytorch框架更容易投入生产。此外比起YOLOV4模型245 M的模型尺寸,YOLOv5中的YOLOv5s模型尺寸非常小,仅有27 M,降低部署成本,有利于模型的快速部署。故本文以YOLOv5中的YO⁃LOv5s模型为训练模型。
YOLOv5s模型主要由输入端、Backbone、Neck以及Prediction组成。在Backbone部分,把初始图像输入Fo⁃cus结构,经过切片转变为特征图,然后再经过一次32个卷积核的卷积操作,变成最终的特征图[8]。此部分还使用了CSP1_X跨阶段局部网络[9]。其解决了其他大型卷积网络结构中的重复梯度问题,减少模型参数和FLOPS。这对YOLO有重要的意义,即保证了推理速度和准确率,又减小了模型尺寸。Backbone部分主要进行输入图像特征提取,Neck采用了CSP网络设计的CSP2_X结构,对图像特征进行融合[10]。Yolov5s采用其中的GIOU_Loss做Bounding box的损失函数,解决边界不重合问题,并使用非极大值抑制NMS进行后处理,以便更好地识别多目标选框,提高模型检测精度[11]。网络模型结构如图2所示。

图2 YOLOv5s网络结构
2 数据采集及处理
2.1 数据集的采集
通过江苏苏州某SIM卡壳生产厂家,收集所需缺陷产品。通过自主打光,架设工业相机(CCD)一共收集到1000张含有不同类型缺陷的SIM卡壳图像。由于视野足够,在同样的光照条件下只需一次拍照就可显现所有缺陷。对存在有外观缺陷的图像样本进行人工分类。本文中,将SIM卡壳的外观缺陷共分为以下4类:针脚缺失、弹片翘起、圆孔变形、外壳金属断裂,统计样本库中各类缺陷的样本数量,若后期训练样本不够,可通过复制图像后的随机数据增强方法来扩充样本得到分类相对均衡的训练样本库。
由于SIM卡壳的实际规格为:25mm×18 mm,为了获得完整的图像,设置视距FOV的值略大于产品实际规格,设置为:30 mm×20 mm。根据厂家所提WD为250 mm,选用型号为MV-CE120-10GC的1200万CMOS彩色相机,选择50 mm镜头,该配置像素精度为0.008 mm,分辨率为4 000×3 000,由于产品外壳为不锈钢材质,为了克服表面反光造成的干扰,光源选用同轴光。采样平台如图3所示,选型如图4所示。

图3 采样平台
图4 视觉硬件选型
2.2 数据集的预处理
图像预处理的作用是为了提高特征信息的可检测性从而使数据尽可能有序。数据预处理方法一般包括图像灰度化、几何变换、图像增强3大类方法。其中,灰度化就是将彩色图的RGB三个通道的数值仅用一个数值来表示,该数值称为灰度值,对彩色图3个通道依次进行处理,时间开销将会很大。所以,机器视觉中在不影响检测结果的情况下,为了达到提高整个应用系统的处理速度的目的,需要减少所需处理的数据量,即灰度化。在图像处理中,常用的灰度化方法:分量法、最大值法、平均值法、加权平均法。图像几何变换又称为图像空间变换,包括平移、转置、镜像、旋转、缩放等操作。用于改正图像采集系统的系统偏差和仪器位置的随机偏差。图像增强包括亮度、对比度、锐化、平滑、滤波等调节方法;其目的是为了提高图像的视觉效果,根据图像的具体应用场合,有意识地突出图像的整体性或局部特点,从而使原始不清晰的图像清晰。
Halcon是由德国MVtec公司开发的一套完整的标准机器视觉算法包,拥有广泛的机器视觉集成开发环境。是一套图像处理库,由1 000多个独立的功能和底层数据管理核心组成[12]。囊括了各种基本的几何和图像计算功能,如滤波、颜色和数学、几何变换、校正、形态学分析、形状搜索等,应用范围几乎无限,这些功能大多不是为特定工作设计的,因此只要对图像处理有需求,Halcon强大的计算和分析能力就可以用来完成工作。本文使用Halcon算法包里的emphasize算子对获取的数据集进行数据增强,提高缺陷的对比度,使缺陷突出,有益于提升模型工作速度。该算子计算与释义如下,产品原图与4种缺陷类型标记图及预处理前后缺陷图如图5所示。

图5 预处理前后缺陷图
算子原式:emphasize(Image:ImageEmphasize:MaskWidth,MaskHeight,Factor:)
按如下公式进行计算:res:=round((origmean)*Factor)+orig
Image:指定需要增强的图片名;ImageEmphasize:处理后的图片名;
MaskWidth:均值滤波的宽度;MaskHeight:均值滤波的高度;
Factor:对比度因子res:新的像素值;
orig:滤波前某点的像素值;
mean:滤波后所有点的平均像素值;
round:取整函数;
整体释义:用原始图像某点的像素值减去滤波后所有点平均像素值,然后对这个结果近似取整,再把这个值加上原来这点的像素值,得到这个最终结果去替换原来这点的像素值。实现图像对比度增强。
2.3 数据标注
训练YOLOv5s模型前需要对数据类型进行标注,将1 000个样本按4∶1分为训练集和测试集,使用Label Img数据标注工具对图片进行标注,并将图片的标注的图片格式转换成YOLOv5s的格式。缺陷标注类别分为4类,分别是SIM卡外壳的针脚缺失、弹片翘起、圆孔变形、金属断裂,代号为0~3,标注完成后,每张图片会对应生成一份txt标注文件,该文件中的每一行分别代表着不同类别缺陷目标的位置信息,x、y、w、h为该缺陷相对于整张图片的具体位置,介于0~1之间。x、y分别代表标注的尺寸框的中心点在x轴及y轴方向上的坐标;w、h则代表尺寸框的宽度和高度。具体的标注展示如表1所示。

表1 标注文件展示
3 实验与结果分析
3.1 实验条件
实验采用Ubuntu18.04操作系统与Pytorch架构[13],深度学习框架为Pytorch1.8.0使用计算机语言Python3.7,本实验的测试平台采用CPU为AMD-Ryzen7-2700-Eight-Core CPU、内存16 GB、显存11 GB,显卡类型为GeForce GTX 1080Ti,满足深度学习模型训练的硬件配置要求。
3.2 模型训练
网络学习模型的训练基于Pytorch的深度学习框架,训练部分参数设置:输入图片大小为640×640,预先设置总迭代次数为200,实验大概在100次迭代后,损失值逐渐趋于稳定,模型收敛。
YOLOv5s网络的损失函数共包含3个部分:obj_loss为置信度损失函数,反映了网络的置信度误差;box_loss为定位损失函数,用于衡量预测框与标定框之间的误差;cls_loss为分类损失函数,计算锚框与对应的标定分类是否正确。模型在训练过程中的损失变化如图6所示。

图6 损失函数变化
3.3 模型评价
分别通过测试精度(precision,P)、召回率(Re⁃call,R)和LoU为0.5时的mAP来评价模型的性能[14]。P表示检测模型预测的正样本确实是正样本的概率;R是检测模型预测的实际正样本数;A P是每个类别所有图片的P对R的积分,mAP是各种A P的平均值,用于评估检测模型的整体性能。表2所示为SSD[15]、YOLOv3、YO⁃LOv4三种模型以及本文所选模型YOLOv5s在训练中的性能对比。由表可知:YOLO系列的模型性能在本研究中比起SSD模型更有优势,P、R、mAP值都有提升,就本文选取的这3个YOLO系列模型来说,YOLOv5s模型比起YOLOv3与YOLOv4模型性能优势明显更优,特别是准确率比起YOLOv3提升了4.8%,比起YOLOv4提升了3.3%性能更佳。

表2 模型性能对比
3.4 检测结果
同样地,为了更好地显示出YOLOv5s模型的优势,保持训练平台信息配置和训练数据集不变,分别使用SSD、YOLOv3、YOLOv4三种模型与本文所选模型YO⁃LOv5s对4种缺陷进行检测比较,检测实验在CPU上进行,结果如表3所示。由表可知:4种模型对于不同的缺陷都有着高于87%的准确性,但从表中可以看出YO⁃LOv5s模型对4种缺陷的准确率稳定性和平均准确率值都是最优的,此外在检测速度上也有明显的优势,单张图片检测时间比SSD快了0.156 s,比YOLOv3快了0.116 s,比YOLOv4快了0.178 s,说明无论从检测准确率还是从检测速度上来说YOLOv5s模型具有更优性。
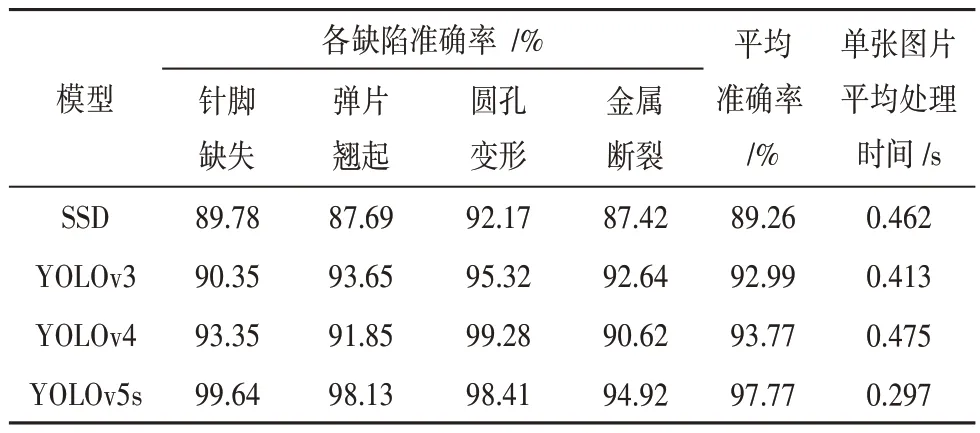
表3 不同模型检测结果比较
4 结束语
为了实现对SIM卡壳在实际流水线上检测速度与准确性的提升,本文提出了一种可以对SIM卡外壳在生产中造成的多种缺陷(外壳针脚缺失、弹片翘起、圆孔变形、金属断裂)进行检测的方法,该方法基于现有的YOLOv5s模型进行深度学习,通过实验检测,该模型的平均准确率可达97.8%,在CPU上检测单张图速度能达到297 ms,能满足工业的实时性要求,为当前工业大环境下检测SIM卡外壳缺陷提供了一种新思维。对于该研究的扩展,可以继续收集不同的SIM卡外壳缺陷类型的数据集进行训练,使模型更具兼容性,将模型应用到更多不同场合。
