基于LEBERT-BCF的电子病历实体识别*
2023-02-23吴广硕樊重俊陶国庆贺远珍
吴广硕,樊重俊,陶国庆,贺远珍
(上海理工大学管理学院,上海 200093)
0 引言
电子病历是指医务人员在医疗活动过程中,使用医疗机构信息系统生成的数字化信息,并能实现存储、管理、传输和重现的医疗记录[1]。由于电子病历通常为非结构化文本,高效提取电子病历中数据信息成为了推进智慧医疗发展的关键点。
中文医疗命名实体识别与其他领域不同,医疗实体通常具有长度较长、专业性强的特点,因此中文医疗命名实体识别对文字语义特征提取和实体边界准确识别的要求较高。BERT[2]在输入时以字符为基本单位,字符之间的相互割裂导致BERT 在医疗命名实体识别任务中产生了以下问题:
⑴ 中文字符的词汇信息学习不充分。在中文NER 任务中每个字符更希望和其相近并能够组成词语的字符特进行特征融合,而且字符作为基本输入浪费了词汇中的实体边界信息。
⑵ 对于嵌套实体的识别效果不佳。如在实体‘原发性肝癌’中,BERT 在输入时由于缺乏全局观,解码时通常会将长度较短的‘肝癌’单独识别为实体导致实体类别预测错误。
⑶神经网络训练不稳定导致模型鲁棒性差。神经网络由于很容易受到线性扰动的攻击,细微的扰动也能使模型预测错误。
针对上述问题本文提出了基于外部词典增强和对抗训练的实体识别模型LEBERT-BCF,LEBERT 相比较BERT 引入了外部词典,优点是可以借助词典匹配出输入文本中的潜在词汇学习词信息。比如实体“原发性肝癌”,LEBERT 输出层在输出字符“癌”对应特征向量时,会考虑到“癌”字对应词“肝癌”、“原发性肝癌”的语义信息,防止了模型将“肝癌”单独识别为实体。而且LEBERT 另一个优点是允许在BERT 不同Transformer Encoder 层注入词信息,对研究NER 特征增强发生在预模型底层或是高层有一定的现实意义,本文同时引入对抗训练作为正则化,提高了BERT 在长实体NER任务中的鲁棒性和泛化能力。
1 相关研究
命名实体识别方法主要分为三大类:第一类是基于规则的方法,通过构建实体知识库去匹配句子中的单词是否为实体。第二类是传统的机器学习方法,主要有HMM、CRF 等。第三类是深度学习方法。通过神经网络将NER 看做序列标注任务。随着对NER 研究的深入,目前的主流方法为深度学习和机器学习相结合模型,深度学习负责学习字符之间的语义信息并解码输出标签,机器学习负责学习标签之间的转换关系,前者使用神经网络训练,后者基于统计学习规则优化。针对中文NER 任务中缺少词信息的问题,Zhang 等人[3]提出Lattice-LSTM 首次在中文NER 任务中引入了词信息。Gui等人[4]在LR-CNN 中对Lattice-LSTM 进行了改进,使用CNN 对字符特征进行编码并堆叠多层获得multi-gram 信息。Sui 等人[5]提出了CGN 模型构建图网络,图网络中三种不同的建图方式融合字词信息。Zou 等人[6]提出LGN 将每个字符视作节点并在节点周围做匹配,匹配到单词则构成边融合信息。Li等人[7]提出的FLAT引入了相对位置信息,字符可以直接与其所匹配词汇间的交互。Liu 等人[8]提出了WC-LSTM 模型为每个字符引入静态固定的词汇,解决了Lattice-LSTM 无法并行化计算的缺点。Ding 等人[9]提出了利用实体词典引入词汇信息的Multi-digraph 模型。Ma 等人[10]提出了Simple-Lexicon模型,该模型设计了三种不同的字词信息融合方法。Zhu 等人[11]提出了LEX-BERT 模型,通过引入实体类型type 信息提高了NER 性能。Liu 等人[12]提出了LeBERT 将词信息注入模型底部提升实体识别性能。在中文医疗实体识别的任务中,罗凌等人[13]提出了基于笔画ELMo 和多任务学习的命名实体识别模型,以笔画序列为特征输入到ELMo 学习向量表示。唐国强等人[14]提出了一种将BERT 输出和注意力机制相结合进行特征增强的方法。王星予等人[15]提出一种在输入层融合实体关键字特征的实体分类模型。
综上所述,在中文医疗实体识别任务中多数模型都是将词信息注入到模型末端或者将笔画信息注入模型的Embedding 层,没有直接将词信息注入到模型内部与字信息进行交互以及考虑到模型的鲁棒性。本文在BERT内部以直观形式引入每个字符在该段输入文本中所匹配到的多个词信息,探讨将词信息注入到BERT 不同Transformer Encoder 层[16]中对模型性能的影响,最后通过对抗训练提升了模型的鲁棒性。
2 LEBERT-BCF模型
本文提出的LEBERT-BCF 模型结构上主要分为三部分,第一部分是使用LEBERT 引入词信息并将每个字符进行向量化表示。Tencent AI Lab开源的中文词典覆盖面广泛,包了各领域的专业词汇并且已经训练得到了对应的词向量,故使用Tencent AI Lab 的开源词典为外部词典。根据外部词典为每个字符建立词典树,在输入每一条电子病历时,根据词典树自动为每个字符匹配出潜在词汇构建字符-词语对输入到模型进行训练,在此过程中达到模型学习词信息和实体边界信息的目的。第二部分是BiLSTM 学习电子病历的上下文特征。第三部分是CRF 学习实体标签的上下文约束,防止出现不合理的标签预测序列。图1给出了LEBERT-BCF模型的主要结构。
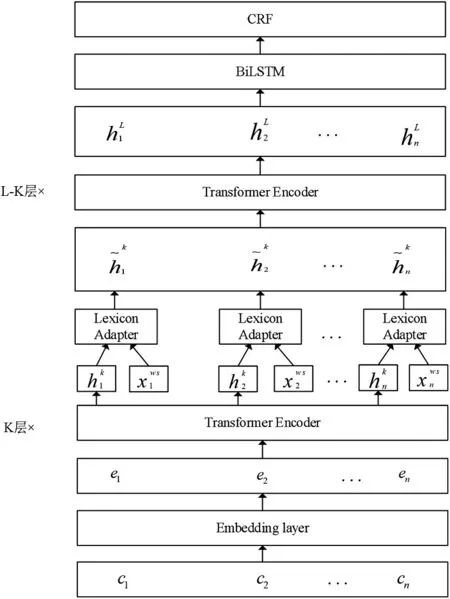
图1 LEBERT-BCF模型
2.1 LEBERT
LEBERT 在BERT 的基础上通过Lexicon Adapter模块融合电子病历中的词信息,因此在NER 过程中具有学习词信息和实体边界信息的能力。
2.1.1 BERT
BERT 模型通常由12 个Transformer 的Encoder模块叠加而成,在模型的微调过程中,每个字符的特征向量会根据下文变化而变化,是一种动态的字向量表示。
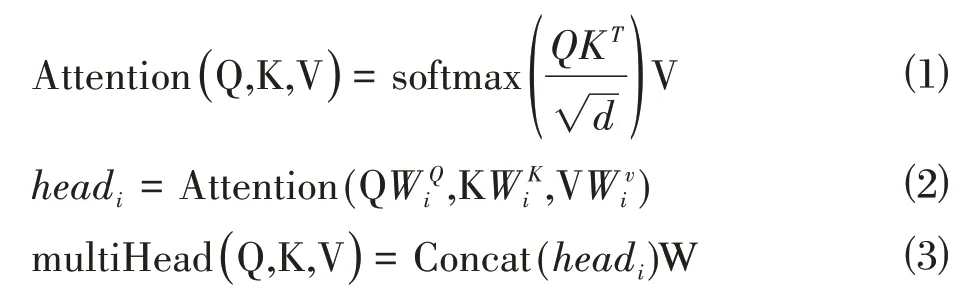
BERT 模型内部的多头注意力机制有助于每个字符动态融合其他字符的语义信息。在多头注意力机制的过程中,Q、K、V 分别为查询矩阵,键矩阵,值矩阵,WQ、WK、WV、W为线性变换矩阵。
2.1.2 Char-Words Pair Sequence
根据给定的中文句子sc={c1,c2…cn} 利用事先根据外部词典构建好的词典树匹配出句子中每个字符ci在该文本中对应的潜在词汇。在匹配到的词汇中,每个字符和包含该字符的词汇组成字符-词语对集合,表示为scw={(c1,ws1),(c2,ws2),…(cn,wsn)}。其中wsi表示包含字符ci单词组成的字符-词语对。如图2 中,输入文本为“原发性肝癌”,通过词典树匹配,得到“癌”字符的字符-词语对为(癌,[原发性肝癌,肝癌,<PAD>]),其中<PAD>为填充,限制每个字符对应3 个词语。
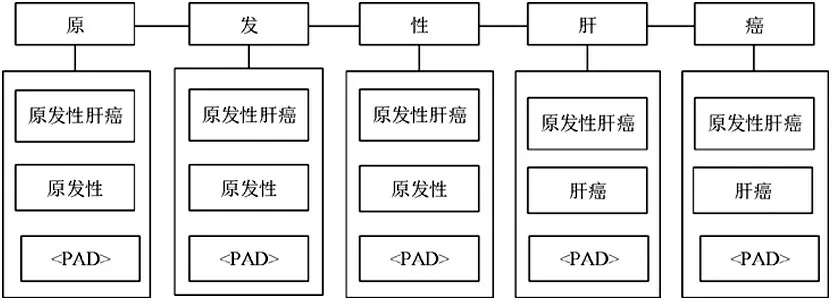
图2 字词对序列
2.1.3 Lexicon Adapter
通过Lexicon Adapter 模块将词汇信息注入到BERT 中,对于给定的ci将其构造出字符-词语对向量表示为表示为第i 个位置的字向量表示为字符i 所对应第m 个词汇的词向量。由于外部词典词向量和TransformerEncoder 输出的字向量维度不一致,首先通过非线性变换将字向量和词向量进行向量维度对齐:

使用hci为query 向量,其对应的词向量集合Vi为key和value,计算注意力分数:

Wattn为权重矩阵。利用注意力分数αi对value 进行加权求和,得到ci对应所有词汇融合后的词特征:

具体流程如图3所示。
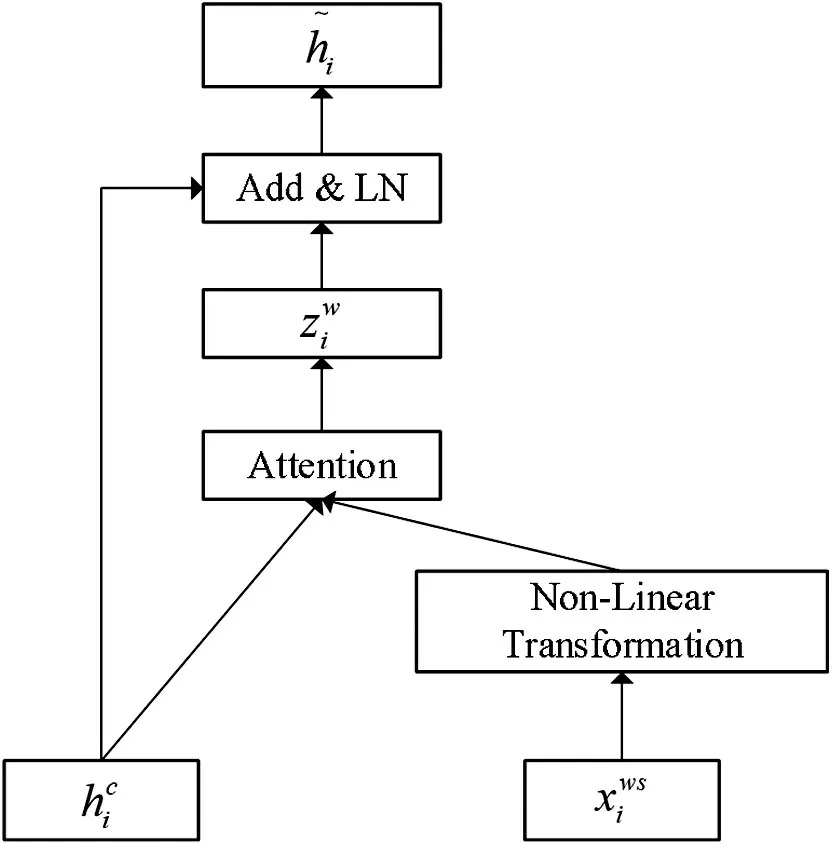
图3 Lexicon Adapter模块
2.1.4 词信息注入
假设第k 层Transformer Encoder 的输出为Hk=,利用Lexicon Adapte 模块将词汇信息注入到第k层与第k+1层Transformer Encoder之间:

LA 为Lexicon Adapte 模块,在第k 层,得到具有字词特征信息的特征向量集合
2.2 BiLSTM
LSTM 通过增加遗忘门、输入门与输出门三部分增强RNN 的学习能力,缺点是只能利用上文已经出现过的语义信息,在NER 任务中忽视了数据的前后依赖性。本文使用BiLSTM 将前向LSTM 隐藏层的输出和后向LSTM 隐藏层的输出拼接得到含有双向语义信息的向量做标签预测。
2.3 CRF
CRF 是给定一组变量X 的条件下,另外一组随机变量Y的条件概率分布的模型。在NER任务中,S(X,y)表示输入句子序列X被标记为序列y的得分值:

分别表示第句子序列X 中第i 个字符的发射分数和转移分数,输入句子序列X 被标记为序列y的概率为:

其中YX代表了所有的标签预测集。
2.4 FGM
FGM 是对抗训练的常用方法之一,假设LEBERTBCF输入文本的embedding矩阵为x,根据LEBERT-BCF模型第一次反向传播得到x 对应的梯度∇xL(x,y,θ)得到输入文本的对抗扰动radv:

ε为超参数。将对抗扰动加到x 矩阵得到对抗样本xadv:

在原始样本损失函数增大方向得到对抗样本,将对抗样本再次输入模型训练可以寻找到更健壮的参数值。
3 实验
3.1 实验数据
实验数据集来自中文医疗数据集CCKS 2019,将数据集划分为训练集、验证集、测试集,分别是800、200、379条。数据集中共包含6种实体,各个实体在数据集的分布如表1。

表1 CCKS 2019 数据集实体类别及数目
3.2 参数设置
在本文命名实体识别实验中,使用Python和Pytorch搭建实验环境,对LEBERT、BiLSTM、CRF 三个模块采用差分学习率。模型详细参数见表2。

表2 LEBERT-BCF模型超参数设置
3.3 评估指标
本文采用的评价指标有准确率P,召回率R 和F1值,均采用严格评判标准,只有当模型所识别的实体边界与真实边界一致且实体类别一致时才被判定为一次正确识别。
准确率P计算公式为:

召回率R计算公式为:

F1 值为准确率和召回率的加权调和平均值,计算公式为:

3.4 实验结果及分析
为验证本文所提出LEBERT-BCF 模型在医疗命名实体识别有效,在同样的实验环境下采用多种模型对比的方法,使用本文模型与BiLSTM,BiLSTM-CRF,BERT-BiLSTM-CRF,LEBERT-BCF*(各模块学习率相等)在准确率,召回率,F1 指标上做对比实验,对比结果如表3所示。

表3 模型对比实验结果
由表3可知,由于BERT模型引入了自注意力机制,在实体识别效果上相对于BiLSTM-CRF 有较大提升,在P,R,F1 指标上分别提升了7.93%,8.67%,8.31%。BERT-BiLSTM-CRF 与BERT-CRF 相比较引入了BiLSTM 学习文字方向性信息,在P,R,F1 指标上分别提升了0.47%,1.17%,0.82%,对比发现在BERT 模型后引入BiLSTM 在NER 任务中各项指提升效果并不明显,原因在于BERT 模型在下游任务中通常具有较强的拟合能力,堆叠一层同样是字符为输入单位BiLSTM 模型对中文医疗实体识别性能影响较小。LEBERT-BCF*与BERT-BiLSTM-CRF相比较在P,R,F1 指标上分别提升了2.1%,2.97%,2.53%,充分验证了BERT 内部引入Lexicon Adapter 模块和embedding层引入FGM 可以提升模型的实体识别性能,有效解决了字符模型BERT 在NER 任务中的词信息损失、实体边界信息浪费和模型鲁棒性较差的问题。通过对模型的不同模块单独设置学习率,LEBERT-BCF相比较LEBERT-BCF*在P,R,F1 指标上分别提升了0.98%,0.85%,0.92%,证明了预训练模型在下游任务微调时只需要设置较小的学习率就可以迅速收敛,而其他模块通常设置相对较大学习率才可以收敛。
为了更加直观的显示在BERT 的NER 任务中引入词信息和FGM 可以提高实体识别性能,图4 为BERT-BiLSTM-CRF与LEBERT-BCF在CCKS 2019测试集上各个实体的F1值。

图4 F1值对比
由图4 可知LEBERT-BCF 在各个实体的识别效果均优于BERT-BiLSTM-CRF 证明了本文模型在专业性较强和实体较长的中文医疗数据集上可以更好的提取特征信息。
通过在LEBERT 底层和高层引入词信息,探讨不同Transformer Encoder 层进行特征增强对模型实体识别的影响,对比结果如表4所示,推断出在模型底层引入词信息可以高效地进行特征增强,而在模型末端引入词信息的增强效果最低。
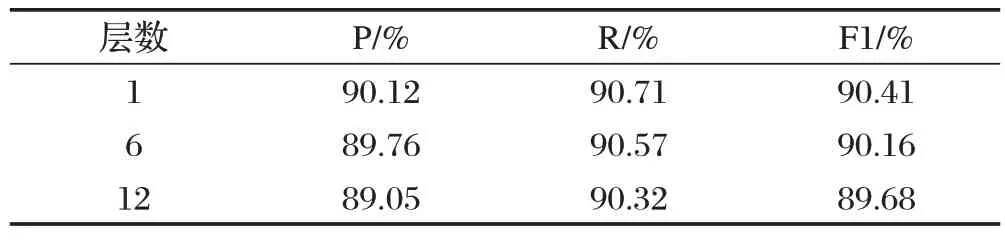
表4 注入层数对模型的影响
4 结论
在对电子病历的数据挖掘过程中,BERT 不能充分利用中文词信息和边界信息这些重要特征进行NER 任务,而且神经网络训练不稳定导致模型鲁棒性较差。针对这些问题本文提出了一种基于词典匹配和对抗训练的中文电子病历实体识别模型LEBERTBCF。经过实验证明,该模型在CCKS 2019 数据集上实体识别效果优于BERT-BiLSTM-CRF,有效解决了BERT 在实体识别过程中的词信息损失问题和实体边界浪费问题,提升了模型的鲁棒性。LEBERT-BCF的缺点一方面是需要依靠词典匹配得到每个字符在文中所对应的词汇,而本文所使用的词典为通用型词典,因此在今后的工作中会研究专业性医疗词典匹配对模型的影响;另一方面缺点是FGM 需要两次反向传播,计算量大,训练时间长。
