结合ERNIE2.0 的医疗中文命名实体识别模型
2023-02-23张付领
张付领
(解放军总医院 医疗保障中心,北京 100039)
随着医疗电子病历的广泛应用,如何利用自然语言处理中的命名实体识别技术对其进行有效分析,逐渐成为研究热点[1-2]。
词向量技术将离散的医疗文本转化为计算机能够处理的数字向量,是深度学习技术应用于文本处理的前提。传统的词向量模型如Word2Vec[3]和Glove[4],忽略了词所处句子的位置信息,导致无法表示多义词。动态词向量模型如ELMO[5](Embedding from Language Model)、BERT[6]等,其训练过程结合词的具体上下文语境,能够有效地解决单一向量无法表示多义词的问题,提升了词的语义表征能力。ERNIE[7]模型引入了持续增量多任务学习策略,结合外部知识和实体信息,提高了模型在句法和语义上的表征能力。
命名实体识别主要有机器学习方法和深度学习方法。文献[8]提出了基于SVM 的英/美文本分类方法,取得了较好的分类精度,机器学习方法需要大量的人工特征工程,并且无法确保所得特征的全面性和准确性。随着深度学习的发展,基础模型如LSTM、CNN等被广泛应用于医疗命名实体识别领域。文献[9]提出了基于BERT-IDCNN-MHA-CRF 的医疗电子病例命名实体识别模型,BERT 用于学习词的动态向量表示,有效地提升了实体识别效果,但IDCNN 模块仅捕获了文本局部特征。文献[10]针对中文医疗病历命名实体识别问题,提出了ALBERT-BiLSTMCRF 模型,提高了识别精度,但BiLSTM 模块训练速度较慢。以上模型对得到的高维特征赋予了相同的权重,未能聚焦于对识别结果影响较大的关键特征。
针对目前研究存在的不足,文中提出了结合ERNIE2.0 的医疗中文命名实体识别模型,引入了ENRIE2.0 模型将医疗文本向量化,提升词的语义表示质量,解决静态词向量无法表示多义词的问题;针对BiLSTM 等循环模型训练效率低的问题,使用了双向简单循环单元[11](BiSRU)学习医疗文本的上下文序列信息,提高模型整体训练效率;采用了软注意力机制[12]计算每个高维特征对分类结果的影响权重,赋予模型聚焦于关键特征的能力。
1 ERNIE2.0-BiSRU-AT-CRF模型
1.1 模型整体结构
结合ERNIE2.0 的医疗中文命名实体识别模型(ERNIE2.0-BiSRU-AT-CRF)整体结构如图1 所示。该模型主要由预训练模型ERNIE2.0、二次语义提取层BiSRU、软注意力机制层(AT)和条件随机场(CRF)构成。预训练模型ERNIE2.0 负责将医疗文本向量化,学习词的动态语义表示;BiSRU 用于捕获词的高维序列特征;软注意力机制计算每个词的权重大小,由条件随机场解码输出序列标注结果。

图1 整体模型结构
1.2 预训练模型ERNIE2.0
预训练模型ERNIE2.0结构如图2所示。e={e1,e2,…,en}为输入向量,T={T1,T2,…,Tn}为经模型通过参考词的特定上下文语义学习到的动态词向量表示,作为BiSRU 二次语义提取层的输入。

图2 预训练模型ERNIE2.0结构
1.3 二次语义提取层BiSRU
简单循环单元摆脱了对上一个时间步输出的依赖,提高了模型的并行计算能力,同时保持了较好的序列建模能力,与LSTM 模型相比较,参数量明显降低[13]。单层SRU 计算公式如式(1)-(4)所示:

其中,rt和ft分别表示SRU 中的重置门和遗忘门;⊙代表矩阵对应元素的乘法运算;Wt、Wr、W、bf、br、vf和vr均为可学习参数矩阵。由式(4)可知,当前状态ht计算不再依赖上一个时间步输出,极大地提高了SRU 模型的并行计算速度。将前向和后向SRU 的输出ht合并,得到BiSRU 输出Ht。
1.4 软注意力机制层
BiSRU 层得到的高维序列特征输出H是软注意力机制层的输入,计算每个时间步输出Ht对应的权重At,加权求和之后得到注意力特征A,其计算过程如式(5)-(7)所示:

其中,tanh()为非线性函数,exp()代表指数运算,W0和b0为可学习参数。
1.5 条件随机场(CRF)
条件随机场是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,常用于序列标注问题,比如命名实体识别等[14]。根据给定的字符序列x={x1,x2,…,xn},xi表示第i个字符特征组成的输入向量;x对应的标签序列为y,y(x)表示x的全部可能标签。给定字符x,对应序列标签为y的概率公式定义如式(8)所示:
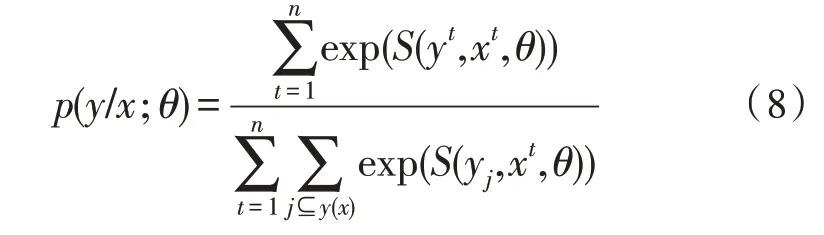
其中,S(yt,xt,θ)为势函数,θ为可调节的超参数。
2 实验结果分析
2.1 数据集和评价指标
为验证文中提出的ENRIE2.0-BiSRU-AT-CRF模型在医疗文本命名实体识别任务的有效性,使用医渡云公开的电子病例数据集[9],该数据集共2 500条病例文本数据,其中1 500 条已标注数据,1 000 条无标注数据。该数据集存在药物、手术、检查、检验、疾病诊断和解剖部位共六个类别的实体词,分别使用字母A-F 表示。按照8∶1∶1 将数据集划分为训练集、测试集和验证集。
实验采用准确率(Accuary)、精确率(Precision)、召回率(Recall)和F1 分数作为模型性能评价指标,其计算过程如式(9)-(12)所示。

2.2 训练环境与模型参数设定
为验证文中模型的有效性,采用版本为1.7.1 的深度学习框架Pytorch 和Numpy 等第三方库进行模型搭建和训练,使用GTX3090 显卡加速训练和预测。模型参数设定影响性能表现,经多次参数调优,得到参数设置如下:BiSRU 模型隐藏层大小为256,层数为2。为防止模型出现过拟合问题,设置随机失活概率为0.3,医疗文本最大序列长度为200,批处理大小为64,初始化学习率为0.000 01。采用RAdam[15]优化器,其能自动调整学习率大小,避免了复杂的学习率调整过程,提升模型训练效果。损失函数为交叉熵函数,训练轮次为5 次。
2.3 对比实验设计
为验证文中模型对医疗电子病例文本命名实体识别的有效性,选取经典深度学习模型和近期表现较好的深度模型作为对比。为降低随机误差,固定随机种子数,取5 次冷启动实验结果的平均值作为最终结果。对比实验设计如下。
1)Word2Vec-BiSRU-CRF:采用词向量维度为300 的Word2Vec(Word to Vector)模型[16]将医疗文本向量化,通过BiSRU 学习文本序列特征,由CRF 解码输出。
2)ELMO-BiSRU-CRF:使用基于BiLSTM 的动态词向量模型ELMO 进行文本向量表示,BiSRUCRF 用于命名实体识别。
3)ERNIE2.0-BiSRU-CRF:文中提出的使用知识增强的ERNIE2.0 模型提取词的动态语义表示,再由BiSRU-CRF 进行命名实体识别任务。
4)ALBERT-BiLSTM-CRF[10]:文 献[10]提出的ALBERT-BiLSTM-CRF 模型使用轻量级ALBERT 模型获取词向量,BiLSTM 学习文本全局特征,CRF 输出解码。
5)BERT-IDCNN-MHA-CRF[9]:文献[9]提出 的BERT-IDCNN-MHA-CRF 模型使用BERT 模型获取词向量,IDCNN 提取文本的高维局部特征,CRF 输出解码。
2.4 结果分析
2.4.1 BiSRU与BiLSTM的训练效率比较
图3 为ERNIE2.0-BiLSTM-CRF 和ERNIE2.0-BiSRU-CRF 每个轮次的训练时间对比图。由图3 可知,模型ERNIE2.0-BiSRU-CRF 平均轮次训练时间更短,计算效率更高,BiSRU 参数量更低。

图3 模型每轮训练时间对比
2.4.2 模型实验结果分析
各个模型实验结果如表1 所示。由表1 可得,与近期基于预训练模型的ALBERT-BiLSTM-CRF 和BERT-IDCNN-MHA-CRF 相比,文中提出的ERNIE 2.0-BiSRU-AT-CRF 模型F1 分数分别提升了1.18%和3.21%,证明了ERNIE2.0 结合BiSRU-AT-CRF 模型的有效性,能更有效地识别文本中的实体词。

表1 模型评估指标对比
为验证采用预训练模型ERNIE2.0 提取动态词向量的有效性,将其与Word2Vec-BiSRU-CRF、ELMO-BiSRU-CRF 和ERNIE-BiSRU-CRF 进行对比,ERNIE-BiSRU-CRF 取得了最高的F1 分数。静态词向量Word2Vec 模型缺乏词的语境位置信息,无法表示多义词;ELMO 和ERNIE2.0 均结合当前词的具体上下文关系,从而得到词的动态语义表示。ELMO 使用双向BiLSTM 作为特征抽取器,ERNIE2.0模型使用特征学习能力更强大的Transformer 编码器,训练效果更佳。同时ERNIE2.0 引入了外部知识和多任务增量学习方法,提高了在句法和语义方面的表达能力,因此应用效果优于ELMO。
设置ERNIE2.0-BiSRU-CRF 和ERNIE2.0-BiS RU-AT-CRF 模型作为对比,由表1 结果可知,加入软注意力机制的ERNIE2.0-BiSRU-AT-CRF 模型的F1 分数提升了1.23%,证明了软注意力层能够赋予模型关注到对命名实体识别结果影响更大的关键特征,有效地提升实体识别性能。
为验证BiSRU 模块的有效性,设置ERNIE2.0-BiLSTM-CRF 和ERNIE2.0-BiSRU-CRF 作对比,两者F1 分数相差较小,证明BiSRU 在降低训练时间的同时,保持较强的建模能力。
图4 为各模型在六个类别实体词上的F1 值。由图4 可知,文中模型在各个类别的实体词中F1 值均高于其他对比模型,证明了文中模型在医疗命名实体识别任务的有效性。

图4 各个实体词类的F1值对比
3 结论
针对医疗中文命名实体识别问题,文中提出了基于ERNIE2.0-BiSRU-AT-CRF 的医疗中文命名实体识别模型,有效地提升了实体识别的准确率。采用ERNIE2.0 预训练模型学习词的动态特征向量表示,解决了相同词在不同上下文中语义不一致的问题,其应用效果优于实验对比的其他词向量模型。为提升训练效率,引入了BiSRU 模块,以保持高效序列建模能力,降低参数量;软注意力机制赋予了模型关注重点特征的能力,提升了分类性能。在未来研究中将考虑进一步降低模型的参数量,提升训练速度和推理速度,同时尝试使用更多词向量模型,得到语义表示质量更高的词向量。
