基于预训练模型的中文电子病历实体识别
2023-02-21李晓林胡泽荣
李晓林,胡泽荣
(武汉工程大学 计算机科学与工程学院,湖北 武汉 430205)
0 引 言
早期,基于规则和词典的命名实体识别方法工作量巨大,基于统计的实体识别方法依赖于大量的人工标注语料[1]。Lample等[2]针对传统命名实体识别方法严重依赖手工标注的问题提出了两种基于神经网络的命名实体识别方法,一种是将BiLSTM与CRF相结合,另一种是基于过渡的依赖解析方法,取得了较好的性能。目前,命名实体识别的方法主要是基于神经网络。在中文电子病历命名实体识别方面,张华丽等[3]提出一种基于注意力机制的BiLSTM-CRF实体识别方法,证明注意力机制显著优化了电子病历的实体识别效果。但是,基于神经网络的电子病历实体识别方法大部分都使用Word2Vec训练词向量,缺点是词和向量是一一对应的关系,无法解决一词多义,最终导致实体识别准确率不高[4]。针对这个问题,Peters等[5]提出了基于双层双向LSTM结构的ELMo学习并且训练词向量与上下文的关系。Radford等[6]提出OpenAI GPT模型,使用Transformer代替 LSTM获取长距离信息。Devlin等[7]提出基于双向Transformer编码的BERT模型可以提取文本更深层的语义信息,但无法充分利用显性的词和词序信息。Cui等[8]提出了BERT-wwm模型,引入全词Mask预训练任务,但存在以下问题:①BERT-wwm模型中LTP分词方法对本文病历文本分词性能不高,导致掩码效果不佳;②由于医疗实体结构的复杂性和特殊性,BERT-wwm的掩码策略和机制不适用于本文;③基于BERT-wwm的识别模型没有关注到不同的语义特征重要性不同。
针对上述问题,本文提出了一种基于BERT-iwwm预训练模型的实体识别方法,显著提高了医疗命名实体识别的准确率。本文的主要工作如下:①在医疗实体标注方面,本文提出了动态词长的逆向最大匹配算法减少标注歧义;②为增强语义向量表示,在输入向量层中加入字向量和注意力机制,关注不同字向量的全局语义特征;③在预训练模型方面,采用PKU分词并构建用户自定义词典以提高分词性能;改进掩码策略和Mask机制增强模型提取语义特征的能力;根据本文电子病历数据单句训练的特点,去掉了预训练模型的下一句预测任务。
1 标注歧义
本文电子病历数据存在据前后标注不一致的问题,主要有两种情况:①同一个医疗实体分别被标注为实体和非实体;②同一个医疗实体被标注为两种或多种实体类别,如图1所示。

图1 标注歧义
由图1可看出,同一个医疗实体“糖尿病”分别被标记为非医疗实体O和“疾病”类医疗实体,“两肺支气管肺炎”分别被标记为“疾病”类和“身体”类。
针对上述问题,本文提出了动态词长的逆向最大匹配(DRMM)算法对数据集进行标注纠错,减少标注歧义。定义词表A为所有医疗实体集合, A={实体,label}, 其中label为该实体的标签类别。词表B为待处理医疗文本的实体集合, B={实体,start,end,label}, 其中start和end分别是该实体在文本中的起止位置,且B属于A。动态词长逆向最大匹配算法流程如图2所示。

图2 DRMM算法流程
其中,C为待处理文本S的最后一个字符。如果在词表A中找到候选字符串C,则从S中去掉C并且将实体C和其在S中起始位置以及其在A中的标签加入词表B,否则继续向左匹配。相比于固定最大词长的逆向最大匹配算法,DRMM算法可以动态的根据候选医疗实体的词长进行匹配,一定程度上提高了算法的效率。
2 基于预训练模型的医疗实体识别模型
本文实体识别模型主要针对传统预训练语言模型提取语义特征能力不足以及忽略不同语义特征对模型的影响程度不同的问题。模型的整体结构如图3所示,包括字注意力机制层、输入向量层、预训练层、BiGRU层和CRF层。

图3 电子病历命名实体识别模型结构
2.1 输入向量层
分词的质量会直接影响Mask模型预训练的效果,进而影响模型提取文本语义特征的能力。针对BERT-wwm模型的分词方法在中文电子病历文本分词效果较差,本文采用PKU分词方法对预训练数据进行分词。因为PKU分词模型包含多种不同领域:新闻领域、网络领域、医药领域和混合领域等,其中医药领域与本文电子病历文本契合度更高。并结合经过标注纠错后的5类医疗实体构建的用户自定义词典进一步提高分词性能。
考虑到分词效果的提升有一定的局限性,并且在预训练过程中字向量可以辅助词向量提取上下文信息,所以本文在输入向量层加入了字向量,并加入位置向量区分每个字在序列中的位置,如图4所示。

图4 电子病历命名实体识别词向量模型结构
其中,词向量是经过PKU分词后每个词在词表中对应的词向量表示,字向量是预训练数据经过word2vec生成的相应的字向量表示,位置向量主要表示每个词在预训练序列中的位置。最终输入预训练模型中向量是由词向量、字向量和位置向量进行拼接后的向量。
2.2 注意力机制层
为了充分考虑序列中每个字之间的语义联系,本文在字向量后加入注意力机制,计算每个字与其上下文之间的语义相似性,得到每个字的增强语义向量表示。
对于文本中的每一个序列si={x1,x2,…,xN}, 其中xi表示单词。单词xi经wordvec处理后得到的特征向量为hi, 将其输入注意力机制层。然后计算当前词xi与序列中其它词xj(j=1,2,…,i-1,i+1,…N) 的相关性,即权重。各个单词之间的权重bij的计算如式(1)所示
(1)
其中,f(xi,xj) 的计算如式(2)所示,表示是位置j输入和位置i输出之间的关系
f(xi,xj)=tanh(waw′t-1+uahj)
(2)
式中:wa表示状态w′t-1的权重,ua表示特征向量hj的权重。对特征向量hj进行加权求和,得到单词xi关于序列的全局特征如式(3)所示
(3)
由注意力机制层得到的字向量是基于全局信息的字向量,融合了该字上下文语义信息,可以更好辅助词向量提取语义特征。
2.3 预训练层
改进的预训练层BERT-iwwm模型结构由多层双向的Transformer编码器组成[9],主要是对输入序列随机掩盖15%的词,然后模型通过学习这些词的上下文信息去预测这些词。本文中文电子病历文本经过标注歧义处理后各类医疗实体的平均长度见表1。

表1 各医疗实体平均长度
由表1可以看出,各类医疗实体的平均长度相差较大。本文输入最大序列长度为256,包含115个词,掩盖15%的词即17个词,其中14个词(80%)被[Mask]掩码替换,3个词被随机替换和保留原词。可以看出,保留原词的个数非常少。对于“治疗方式”这类平均长度较长的实体来说,预训练过程中若[Mask]过多,会使模型对其关注过多,无法确保模型的预测趋于正确。本文旨在增加随机替换和保留的词个数,使模型对每个词具有更多的可见性。以最大序列长度所覆盖的词为基准,每次增加一个被替换和被保留的词,但是不能超过总词长的一半,即被掩码词的个数分别为:12、10、8。
为了在预训练时充分利用上述Mask后的样本以及在迭代时提取更多样性的语义特征,本文预训练时将原始数据输入模型时候再随机。同时,在预训练迭代次数较多的情况下可以节约大量时间。BERT-wwm模型先对原始数据随机Mask然后再进行预训练,当迭代多次的时候每一种Mask方式会被使用多次,无法保证一种Mask方式只使用一次。随着迭代次数的增加,相同的Mask方式被使用的次数越来越多。本文数据7835条、迭代100 000次,上述Mask机制会造成重复的Mask方式过多,样本利用率低并且训练时间较长。针对本文电子病历文本都是单句的特点,本文去掉了下一句预测预训练任务。因为下一句预测主要是判断句子B是否是句子A的下一句,用于理解句子之间的关系。但是本文电子病历各个句子之间都是相互独立的,即不需要预测句子之间的相关性。
2.4 BiGRU-CRF层
为了进一步学习序列隐含特征,本文在预训练模型后接BiGRU模型,最后通过CRF模型解码得到最终序列标注。单词xi的隐含特征向量hi计算过程如式(4)~式(6)所示
(4)
(5)
(6)

(7)
y*=argmaxS(X,y)
(8)
其中,Ayi,yi+1就代表标签yi到标签yj的转移得分,oi,yi表示第i个词在第yi个标签下的输出得分。预测时采用维特比算法求解最优的输出序列。
3 实验与分析
3.1 实验数据
本文使用CCKS2018的医院电子病历数据集。其中训练集和测试集包含病人的症状、身体部位、治疗方式、医学检查和疾病等实体。各类实体统计见表2。

表2 CCKS2018实体个数统计
3.2 标注策略
本实验使用BIO标注模式,待预测的标签一共有11种,见表3。

表3 BIO命名实体标签
本文使用精确率P、召回率R和F1值作为命名实体识别的衡量指标,其定义如式(9)~式(11)。其中Tp是预测结果中正确识别的实体数量,Fp是预测结果中识别出的错误实体数量,Fn为标准测试集中正确的实体但是预测结果没有识别出来的数量
(9)
(10)
(11)
3.3 实验设置及参数
为了验证模型的有效性,本文设置了3组对比实验:①BERT-BiLSTM-CRF:基于BERT模型,该模型属于基线模型;②BERT-wwm-BiLSTM-CRF:与①作对比实验,验证BERT-wwm预训练对模型识别性能的影响;③BERT-wwm-BiGRU-CRF:与②作对比实验,验证BiGRU网络对模型性能的影响;④BERT-iwwm-BiGRU-CRF:与③进行对比,验证BERT-iwwm模型的改进效果。
各对比模型的公共参数设置如下:注意力头数12,隐藏层数768,模型学习率2e-5,drop率0.5,最大序列取256,train_batch_size采用16。本文实验的环境配置如下:①操作系统为Ubuntu 18.04;②CPU型号为Intel Xeon E5-2665;③GPU型号为GTX 1080Ti;④内存为64 G;⑤显存为11 GB;⑥Python版本为3.6.8;⑦Tensorflow的版本为1.13.1。
3.4 实验结果及分析
对文本“高血压病史11年糖尿病11年”进行标注歧义处理后的结果如图5所示。

图5 标注歧义处理结果
由图5可以看出,经过标注歧义处理后将“糖尿病7 9疾病”加入词表,并将其标注类别由“O”纠正为“DISEASE”,说明DRMM算法可以有效减少已标注文本中的标注歧义,提高文本的标注准确率。
为了验证本文输入向量层加入字向量以及经过注意力机制处理后的字向量对预训练模型性能的影响,在中文电子病历验证集上进行实验,结果见表4。

表4 不同输入向量的实验结果
由表可知,加入经过注意力机制处理后的增强语义字向量预训练模型在验证集的F1值达到了88.2%,高于原始字向量输入。实验说明,注意力机制有效的使字向量表示融合了全局语义特征,从而提高了预训练模型的性能。
为了验证医疗实体字典对分词结果的影响,本文以默认词典和用户自定义词典进行对比,验证不同的分词方法以及词典对预训练任务的影响。实验结果见表5,评估标准是正确Mask的准确率和正确预测下一句的准确率。

表5 不同分词方法的Mask结果
从实验结果可以看出,基于默认词典的PKU分词的mask_acc比LTP高0.9%,并且均比THU和CRF分词方法高。同时,基于用户自定义实体词典的masked_acc比基于默认词典的高。其中,next sentence_acc始终为1是因为在下一句预测预训练任务中没有涉及到对句子关系的预测。实验验证,本文构建的自定义医疗实体词典通过提高分词质量可以进一步提升模型预训练任务的效果。
以PKU方法结合自定义医疗实体字典进行分词的前提下,采用不同掩码词长的Mask策略进行预训练,以验证集的P、R和F为评价标准,实验结果见表6。
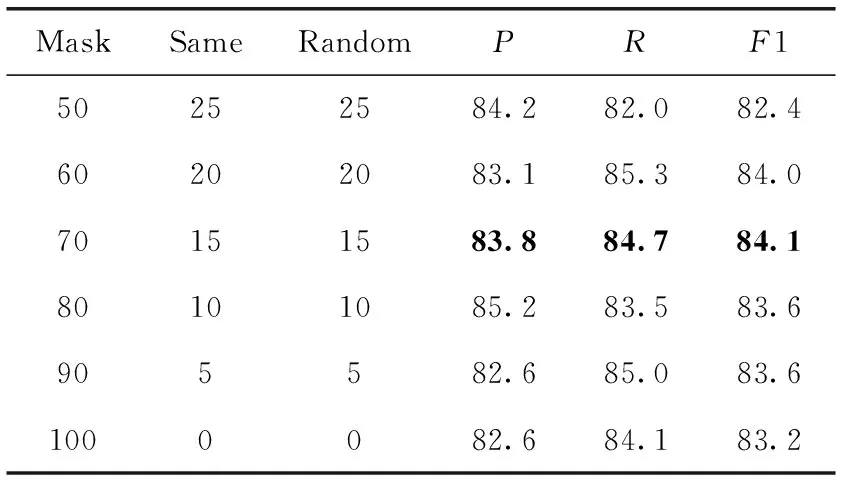
表6 不同Mask比例对比结果/%
Mask策略为50%、60%、70%分别对应本文最长序列掩码8、10、12个词。由上表可知,Mask比例为70%取得了最高F1值为84.1%。当Mask比例超过80%,F1值会逐渐降低,而低于60%识别率会大幅降低,说明本文医疗文本适合按70%的掩码策略进行预训练。
现以70%的Mask比例为基础调整Mask机制和去掉下一句预测进行预训练,结果见表7。

表7 改进预训练任务实验结果
对比1、3和2、4可以看出,改进的Mask机制提升了模型性能。对比1、2和3、4可以看出,去掉下一句预测任务后模型的性能进一步提升。实验验证,本文的改进一定程度上可以增强模型提取语义特征的能力。
本文模型与各个对比模型的实验结果见表8。

表8 不同模型识别结果
歧义处理前,本文模型的F1值达到90.03%,远高于其它4种模型,说明改进的预训练模型和Attention机制整体增强了语义特征提取能力从而提高了模型实体识别性能。歧义处理后,本文模型较歧义处理前F1值提高了0.54%,说明减少预训练数据的标注歧义可以进一步提高模型的识别准确率。同时,本文模型的训练时间较其它模型大幅缩短,可见BiGRU模型在训练成本上要优于BiLSTM。
为验证本文模型的有效性,将其与目前主流命名实体识别模型进行对比,实验结果见表9。
从表9可以看出,本文基于BERT-iwwm的电子病历命名实体识别模型的F1值均高于其它主流模型,说明BERT-iwwm提取语义特征的能力更强。相较于其它几种主流模型,本文模型加入注意力机制学习每个字的全局语义特征,提高了重要语义特征的权重,进一步增强了预训练模型提取语义特征的能力,提高了医疗实体识别效果。

表9 本文模型与主流模型的结果对比
4 结束语
本文提出了一种基于改进预训练模型和注意力机制的医疗实体识别方法。该方法结合PKU与用户自定义实体字典提高了分词准确率;为了提高模型学习语义特征的能力,模型在输入向量层加入注意力机制融合序列上下文语义特征,改进了预训练模型掩码策略和Mask机制,并去掉了下一句任务避免冗余训练;针对标注歧义问题,提出动态词长逆向最大匹配算法。实验结果表明,本文模型较主流模型的医疗实体识别性能有较大提升。如何进一步提高电子病历医疗实体的识别率将是下一步的重点研究工作。
