基于网页图像分类的自动化网页正文抽取模型
2023-02-21李晓戈穆诤辉
秦 龙,李晓戈+,穆诤辉,李 涛
(1.西安邮电大学 计算机学院,陕西 西安 710121;2.西安邮电大学陕西省网络数据分析与智能处理重点实验室,陕西 西安 710121)
0 引 言
在网页文本信息提取领域,已经有大量的研究工作和成熟的方法。Chen等[1]针对网页结构特征进行抽取,在内容分析算法的基础上改进网页抽取模型。Yi等[2]利用机器学习的思想将支持向量机和DOM重心半径相结合抽取网页正文;Zhou等[3]将支持向量机和文本密度结合提取网页正文;Ye等[4]采用向量空间模型作为文本的描述,提出一种基于Bean优化特征提取算法。Luo等[5]提出一种基于特征的Web数据抽取算法,该算法根据网页的特征相似度将网页聚类在一起,并将其它动态网页与所识别的网页的模板进行对比抽取网页正文。Liu等[6]采用文本密度和标签路径覆盖率结合的抽取算法;Wang等[7]提出一种多特征融合的正文抽取算法。Chen等[8]采用长短期记忆网络的深度学习方法进行网页正文提取。王辉等[9]将知识图谱引入信息抽取系统进行数据抽取。
以上算法大都针对文章类型网页,而当今网页形式多样,单一类型的网页抽取已经无法满足海量数据自动采集的需求。本文将网页分为列表网页和文章网页,提出基于截屏网页图像分类的自动化网页正文抽取模型。该模型利用神经网络将截屏网页图像进行分类,然后根据网页类型分别采用改进的基于多特征融合的网页正文抽取算法。该算法不需要人工配置,不依赖网页模版,实现数据抓取和网页正文抽取自动化。
1 模 型
1.1 自动化网页抽取模型
自动化网页正文抽取模型如图1所示。
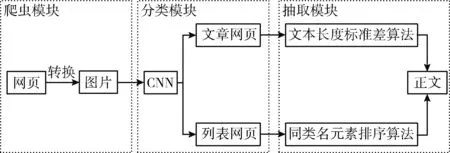
图1 自动化网页正文抽取模型
模型分为爬虫模块—分类模块—正文抽取模块。爬虫模块采用网络爬虫技术将网页HTML源码抓取保存并利用Phantomjs将网页截图;分类模块利用卷积神经网络将网页截图分为文章网页和列表网页;正文抽取模块根据网页类型分别采用基于相同深度的文本长度标准差算法和基于相同深度的同类名元素排序算法抽取网页正文内容。
1.2 分类模块
CNN是一个多层感知器神经网络,从输入数据中提取特征,并使用神经网络的反向传播算法进行训练。图像分类中使用了很多CNN架构:AlexNet、GoogLeNet、DenseNet[10]、VGGNet、ResNet和EfficientNet。LeNet-5模型的提出为使用卷积神经网络进行图像分类研究奠定了基础。Kayed等[11]将LeNet-5应用于电子商务领域,解决服装分类问题;Chen等[12]将其应用在雷达辐射源个体识别。ResNet[13]利用残差网络解决深度增加后网络退化的问题,很多研究者在其它图像领域进行应用,如为了解决化学试剂标签图像分类问题,Xu等[14]引入迁移学习方法,在ResNet-101基础模型上进行微调,训练化学试剂分类模型;Zhou等[15]将ResNet-101模型应用在列车高度阀故障检测中。
本文将网页分为文章网页或列表网页,采用网页截屏图像作为训练数据。网页截屏图像不同于其它公开的图像分类数据集,一张图像的大小在10MB左右,因此图像特征要多于其它通用数据集,并且因为网页的特殊性,文章网页图像和列表网页图像的特征存在重复。文章网页和列表网页如图2和图3所示。接下来简单介绍本文的图像分类模型。

图2 文章网页
图3 列表文章
本文在LeNet-5模型上对截屏网页图像进行分类,具体模型如图4所示。
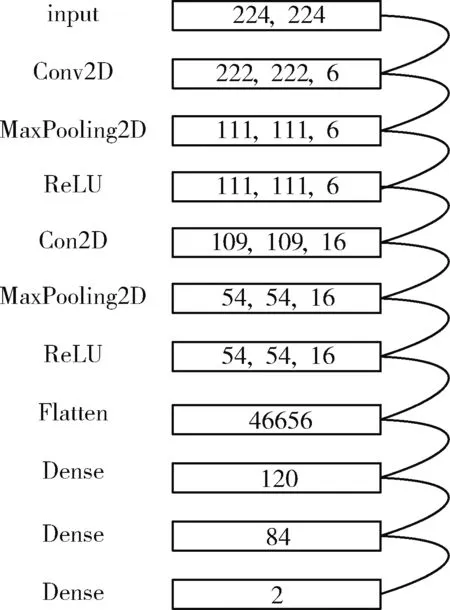
图4 LeNet模型
输入层:如图4所示,输入层为224×224的图像。
Conv2D:这幅图像经过第一个卷积层,该层有6个尺寸为3×3的卷积核,步长为1。图像尺寸将从224×224×1变成222×222×6。
MaxPooling2D:该池化层经过2×2的卷积核,步长为2,最终图像减少为111×111×6。
ReLU:激活函数层。
Conv2D:第二个卷积层为16个大小为3×3,步长为1的卷积核,图像变为109×109×16。
MaxPooling2D:第二个池化层同第一个池化层一样,将图像变为54×54×16。
ReLU:激活函数层。
Flatten:将数据拉直,得到46 656个特征参数。
Dense:最后三层为全连接层,特征参数分别为120、84和2。得到代表网页类型的文章网页和列表网页的概率,将最大值作为分类结果输出。
本文不但在常见的分类模型上对网页截屏图像研究,还采用迁移学习的思想,通过微调ResNet-101和EfficientNet[16]预训练模型进行研究,比较模型训练参数和训练的准确率。ResNet-101的核心思想来自于残差网络,残差网络由一系列残差块组成。一个残差块如图5所示。
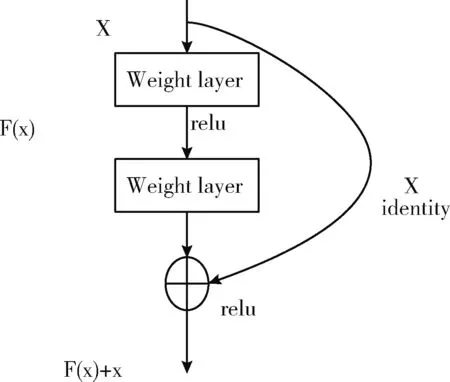
图5 残差块
残差块分为直接映射和残差部分。X是直接映射,反映在图中曲线部分;F(x)是残差部分,一般由两个或者3个卷积操作构成,即图中左侧包含卷积操作的部分。
如图6所示,采用迁移学习的思想,通过微调ResNet-101预训练模型,训练网页图像分类模型。在模型微调的过程中,严格遵守常见的做法,即冻结所有内部层的权重,只对预测文章网页和列表网页这两个类的最终逻辑层进行再训练。即去掉原ResNet-101后面的全局平均池化和全连接层,然后在模型后加入两个全连接层,节点数分别为1024和2。Batch_size大小为16,epochs为30次,学习率为0.0002。采用Adam优化器,损失函数为交叉损失函数(categorical cross entropy),公式如下
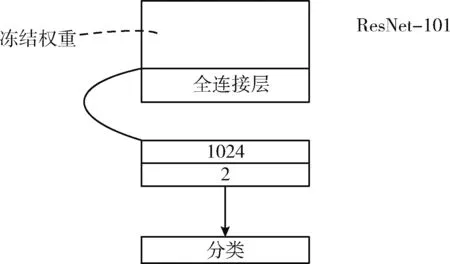
图6 迁移学习微调ResNet-101模型
(1)
其中,y为期望的输出,a为神经元的实际输出。
通过微调EfficientNet预训练模型,在训练过程中只训练最后10层,并加入全局平均池化,将最后的节点数改为2,其它参数同ResNet-101模型。在学习率设置上,本文采用学习率随epochs进行动态变化的方法,其计算公式分别如下
LR=(LRmax-LRst)/LRre*epoch+LRst
(2)
LR=(LRmax-LRst)*LRed**
(epoch-LRre-LRse)+LRmin
(3)
其中,LR代表不同的学习率, LRst=0.00001, 代表初始化学习率,LRmax=0.0004, 代表最大学习率,LRmin=0.00001, 代表最小学习率, LRre=15, 代表学习率上升过程的epochs个数, LRse=0, 代表学习率保持不变的epochs个数, LRed=0.8, 代表指数衰减因子。在前14个epoch采用式(2)设置学习率,第15个epoch学习率最大,在剩下的epoch中采用式(3)来设置。
1.3 正文抽取模块
解析:网页正文信息抽取技术大多是在网页解析的基础上进行的,从DOM生成效率和遍历HTML文档中的节点两个方面考虑,本文采用python中Pyquery库对HTML进行解析和查找。
去噪:为了提高处理效率,减少噪音对正文抽取算法的影响,将源文件中的噪音数据清洗。经过对数据集的研究发现,在文章类型的网页中,噪音数据包含脚本信息 , 样式信息 [17], 链接信息多存在于 标签中,导航栏信息 , 因为正文信息包含在body体中,头部信息 也属于噪音信息。在将原始html网页利用Pyquery转换为Dom后,直接删除,见表1。
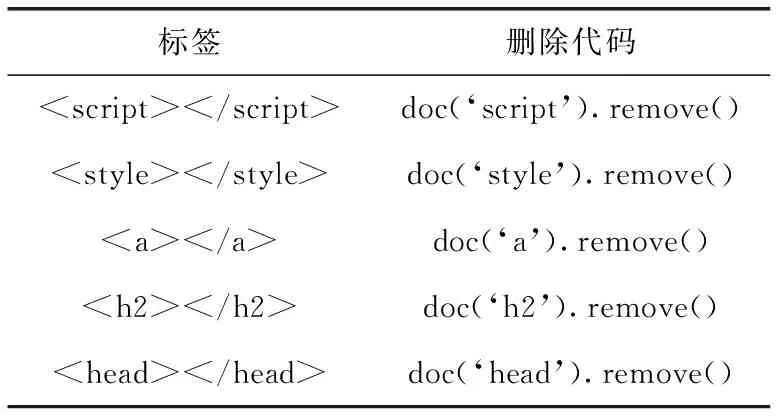
表1 文章类型网页噪音及删除
在列表类型网页中,噪音信息大多为广告链接信息,存在于 , 脚本信息 。 见表2。
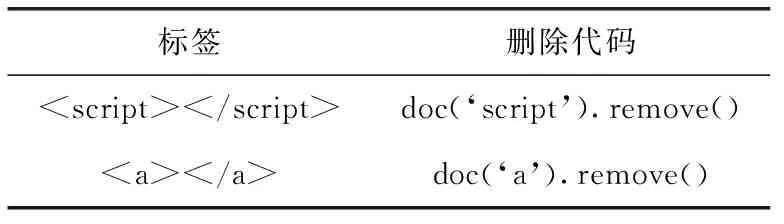
表2 列表类型网页噪音及删除
网页正文提取方法:根据网页类型将其分为文章网页和列表网页,针对文章网页,提出基于相同深度文本长度标准差的正文抽取算法。针对列表网页,提出基于相同节点深度的同类名元素排序的抽取算法。以下对节点深度进行叙述:
元素节点深度经过解析后的html网页如下:
自动化网页正文抽取
HTML解析库性能的比较
假定html标签的元素根节点深度为1,依次标记每一个元素,得到每个元素在网页中的元素节点深度,如图7所示。
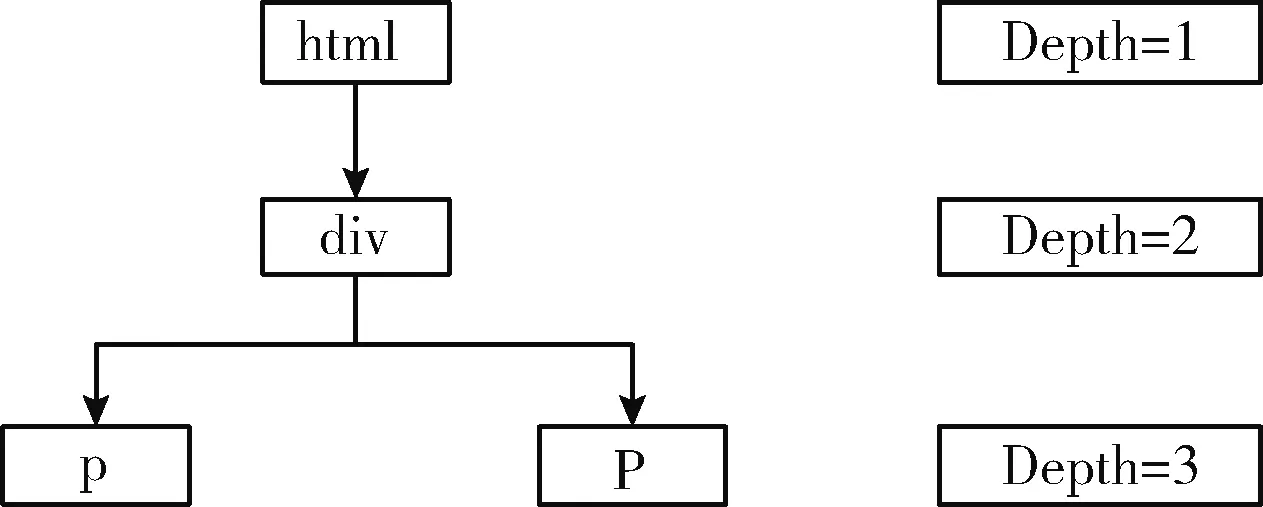
图7 元素节点深度标记示例
2 算法实现
算法1:文章网页正文抽取算法
文章类型网页的正文通常包含在一个网页元素中,另一种情况是网页正文信息分块存在于多个连续的元素中,每个包含正文信息的元素块代表正文的一个段落,其文本长度不一。对于第一种情况,通过比较网页内容存在的元素和其同级别元素中文本的长度得到具有正文信息的元素。对于第二种情况,将文本长度大致相等的元素的父元素作为网页正文信息抽取的节点。算法的伪代码如下所示:
伪代码:基于相同深度文本长度标准差的文章网页正文抽取算法
输入:element
输出:text
(1)function ArticleExtract(element)
(2) childEle=element.allChild //查找每一个元素的子元素个数
(3) if childEle,length==0 then //如果子元素个数为0, 则返回该节点的父节点的文本
(4) return element.parent.text
(5) if childEle.length==1 then //如果子元素数量为1, 则递归查找子元素
(6) return ArticleExtract(childEle)
(7) m1,m2=getTwoMax(childEle) //得到子元素中最大的两个子元素
(8) lm1=wordcount(m1.text) //求两个子元素的文本长度
(9) lm2=wordcount(m2.text)
(10)stdDev=calcStdElv(childEle) //求所有子元素的文本长度标准差
(11) if(lm1-lm2)>stdDev then
(12) if(lm1-lm2)>100 then //如果lm1和lm2的差值小于100, 则输出元素Element的文本
(13) if m1 before m2 then //如果m1元素位置靠前, 则输出m1的文本
(14) return m1.text
(15) return m2.text0 //反之, 输出m2的文本
(16) return element.text
(17)return ArticleExtract(m1) //如果lm1和lm2的差值小于文本长度标准差, 则继续递归找子元素
算法2:列表网页正文抽取算法
在列表网页中,网页的正文内容通常存在于深度级别相同的元素中,通常它们还拥有相同的类名,并且该元素无子节点,将深度级别相同并且类名也相同的元素作为一个衡量单元。而网页正文信息所在的元素在网页中文本长度可以作为一个特征来衡量该元素是否为正文的节点,因此通过对每一种元素节点所拥有的文本长度进行比较,就可以确定含有网页正文信息的元素节点。因为在网页中,类名的种类通常较多,如果对每一个类名都统计出现的深度、次数和文本长度,将需要较大的存储空间开销。因此,在实际的算法中,需要将统计的衡量单元限定在n=15。
列表网页采用基于相同节点深度的同类名元素排序抽取算法,该算法通过对具有相同类名和深度级别的元素进行排序来识别正文内容,并且只抽取1种包含正文内容的元素。该算法的伪代码如下:
伪代码:基于相同节点深度的同类名元素排序的列表网页抽取算法
输入:element
输出:text
(1) global variables
(2) idCount // IDs出现的次数
(3) idText//IDs中的文本
(4) end global variables
(5) function UpdateInfo(element,level)
(6) id=combine(level,element.className) //将类名和深度级别对应起来, 形成一个新的id
(7) idCount[id]=idCount[id]+1
(8) idText[id]=idText[id]+element.text
(9) function RetrieveEle(element,level)
(10) UpdateInfo(element,level)
(11) for child in element.child do
(12) UpdateInfo(child,level+1)
(13)function ListViewExtract(element,n) //主函数,element: HTML的第一个元素, n: 表示考虑的候选类的数量
(14) RetrieveEle(element,0) //递归迭代HTML中所有元素, 检索每个类出现的次数和其文本
(15) idR=calaRScores(idCount,idText) // 统计每个id出现的次数和其文本长度
(16) topNId=getTop(idR,n) // 计算排序特征值R和平均文本长度TL, 并取前n个结果
(17) predicedId=getMaxTL(topNId) //获取前n个结果中的第一个进行文本抽取
(18) return predicedId.text
根据ID的出现次数O和来自相应ID的文本长度L来计算排名分数R
(4)
根据上式计算出R值并用该值对ID进行排序,按照顺序取前n个列表中每个ID的平均文本长度TL值
(5)
3 实验与分析
3.1 数据集
为了验证本文提出方法的可行性,选择网易、新浪、国家税务总局、中国商务部、广东省人民政府、中国科学院、新华网、中国网、人民网、凤凰资讯、中国新闻网、知乎专栏、简书、豆瓣影评、天涯论坛、百度贴吧等16个网站手动构造了图像分类数据集和正文抽取数据集。
将TensorFlow花朵数据集中的雏菊和玫瑰数据作为验证数据集来验证分类模型。两个数据集具体见表3和表4。
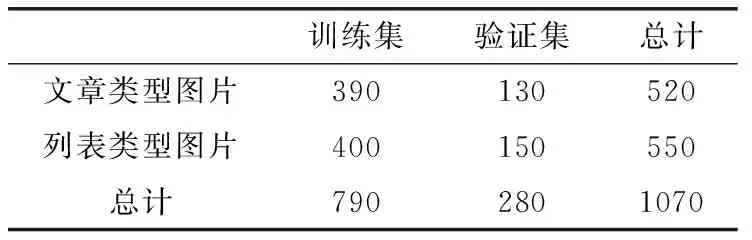
表3 网页分类数据集
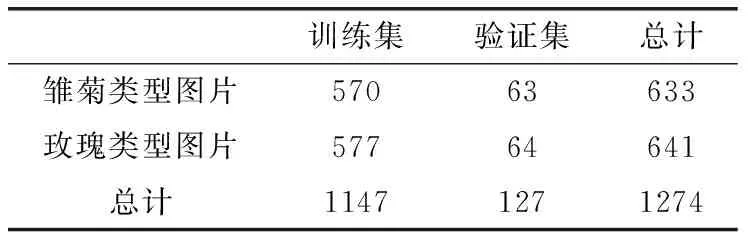
表4 花朵分类数据集
在验证正文抽取算法时,选取910个网页作为验证集,其中文章类型520个,列表类型390个。
3.2 实验结果与分析
3.2.1 图像分类实验
研究不同图像分类模型在网页图像数据集上的性能,得到准确率见表5。
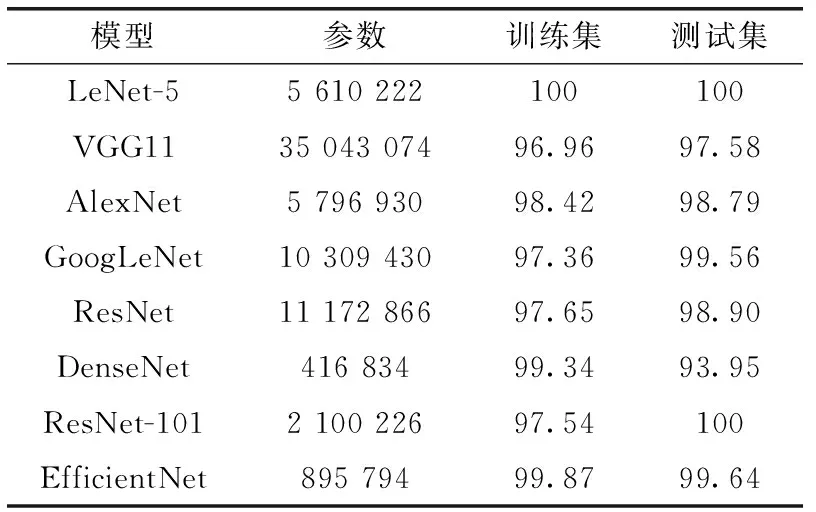
表5 网页图像分类模型结果
从训练参数和准确率考虑,截屏网页图像在最简单的图像分类模型LeNet-5上取得最优的性能。考虑截屏网页图像的特殊性,因此研究通用图像数据集是否也会有类似的结果,利用花朵数据集在LeNet-5和预训练模型ResNet-101以及EfficientNet模型上进行对比。其结果见表6。
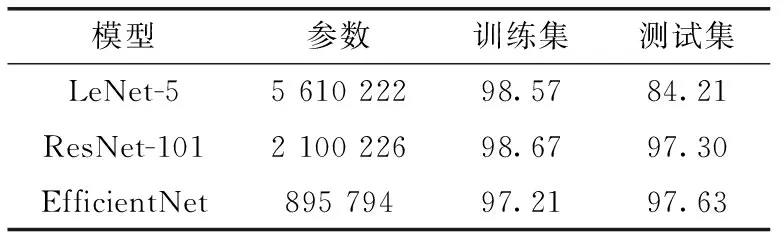
表6 花朵数据集分类模型结果
从结果可以知道,因为截屏网页图像样本的特殊性,该数据集在简单图像分类模型上的性能优于复杂网络。而通用数据集,则在复杂图像分类模型上的效果更好,因为复杂模型能更好提取特征,减少梯度消失等问题。
考虑到输入图像的大小,我们在花朵数据集上研究不同输入大小在ResNet-101、LeNet-5和EfficientNet模型上的不同表现,结果如图8所示。
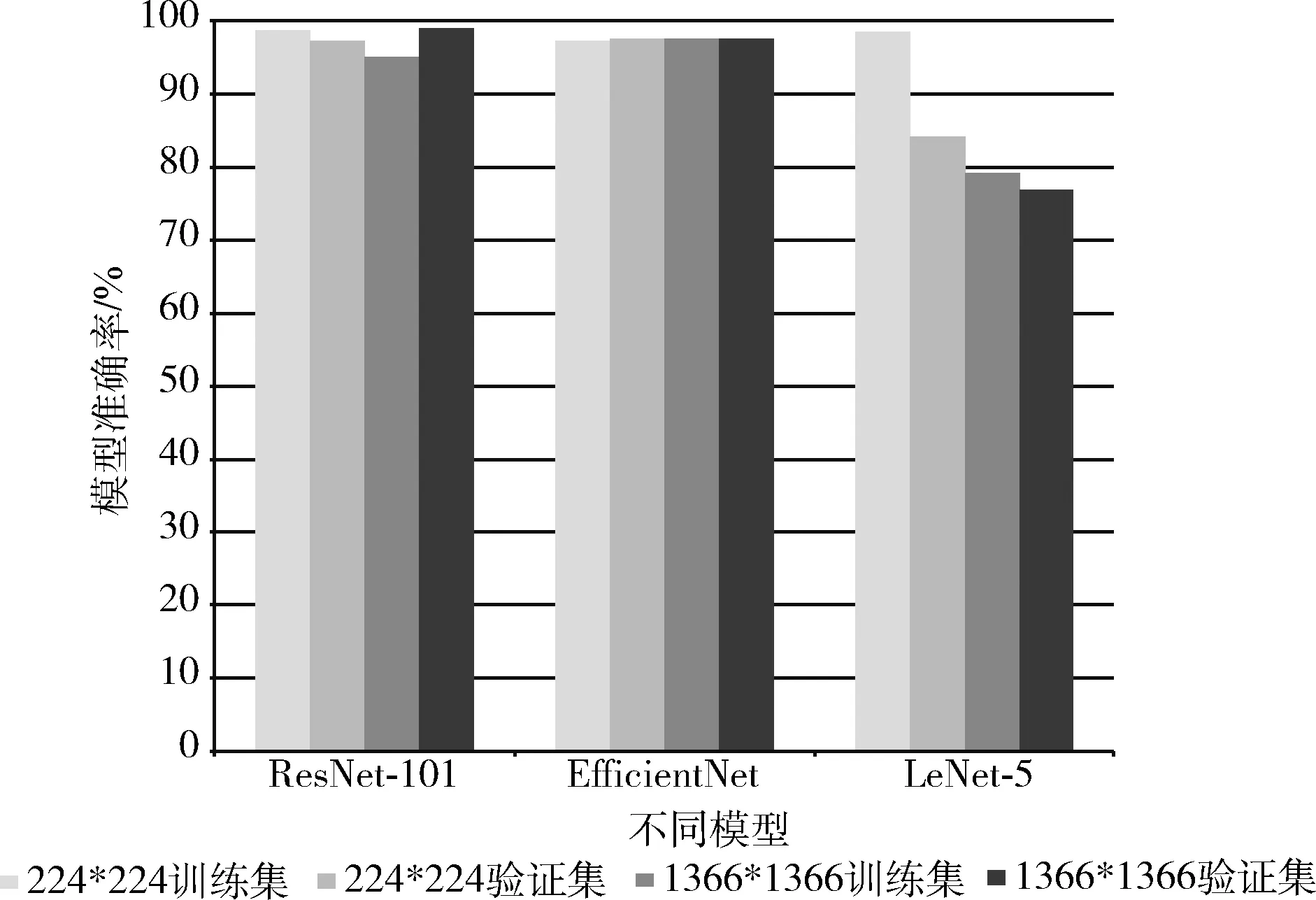
图8 不同模型不同输入对比
在通用数据集上,将图像输入大小改变后,在复杂模型上改变输入大小准确率有明显提升,其中ResNet-101模型在测试集上的准确率提高1.8%。说明在将输入大小变大后,模型提取特征效果优于之前。
将上述结果迁移到网页截屏图像,研究提高输入图像的大小对网页截屏图像是否有提升,在ResNet-101模型上进行对比实验,得到结果如图9所示。
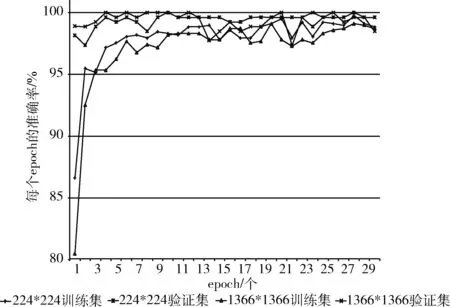
图9 不同输入在ResNet-101模型上的结果
从对比结果来看,针对网页截屏图像,与图像输入大小为224*224相比,1366*1366在测试集上的表现更好,在第4个epoch上就已经达到100%的正确率,而明显在30个epoch上1366*1366的结果优于224*224。这和普通数据集的结果一致,说明在增大输入后,特征提取优于之前。
3.2.2 抽取模型实验
采用查全率和查准率来表示抽取结果,其数学公式分别如下
(6)
(7)
其中,P表示查准率,R表示查全率。C1表示所有网页的总数,C2表示所有网页中提取正确的个数,C3表示正确网页数中完全提取的网页数。
为了验证模型的可行性,计算模型抽取的内容和手工抽取的网页正文内容是否一致,采用汉明距离计算文本相似度。规定汉明距离小于30为提取正确,汉明距离小于10为完全提取正确。
在框架抽取模块,考虑以后随着网页分类复杂化和多种化,在对比各类模型后,从训练参数和准确率方面考虑,选择了ResNet-101模型作为截屏网页图像分类模型。ResNet-101在正文抽取框架中图像分类的准确率为98.68%,其中文章类型准确率为100%,列表类型网页准确率为96.92%。
将I-AWCE模型和Boilerpipe(https://code.google.com/p/boilerpipe)正文内容提取库进行对比,评价指标采用查全率和查准率。Boilerpipe模型采用开源的python版本。表7和表8是两个模型进行对比的结果。研究对比I-AWCE模型和Boilerpipe模型在两种网页上正文抽取的效果,在文章网页数据上,I-AWCE模型在查准率和查全率上优于Boilerpipe模型;在列表网页数据上,I-AWCE模型在查准率和查全率上达到95%以上。
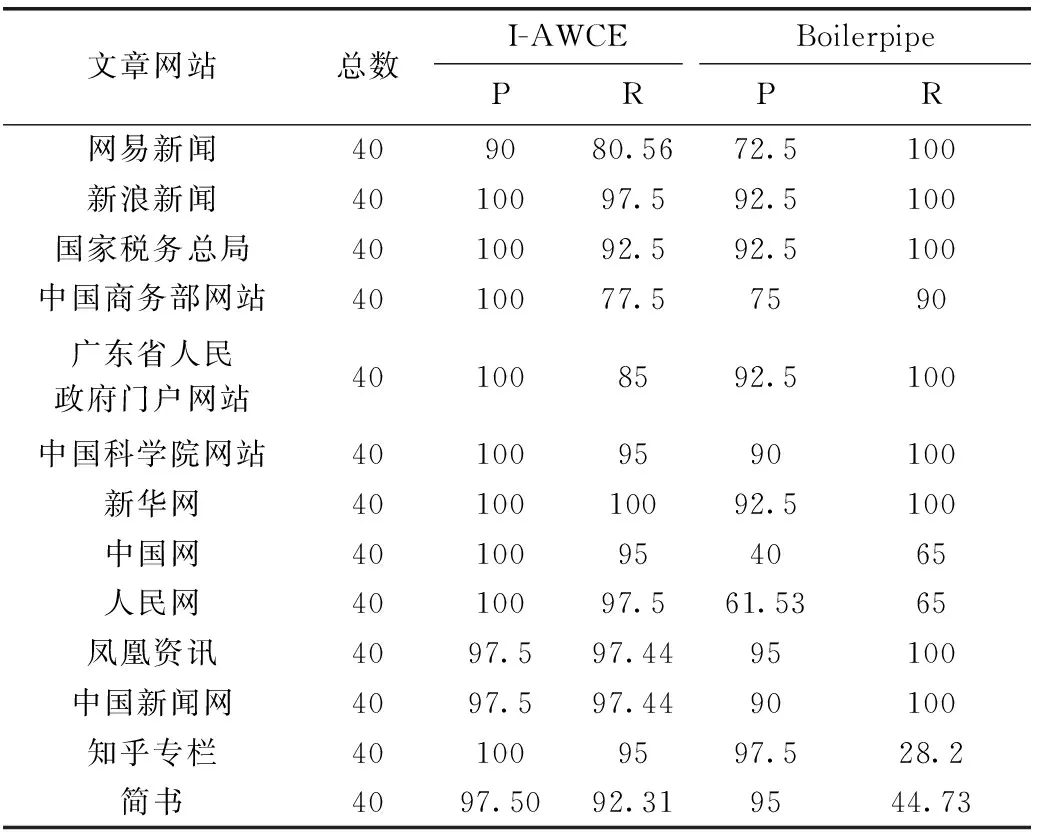
表7 文章类型网页正文抽取对比
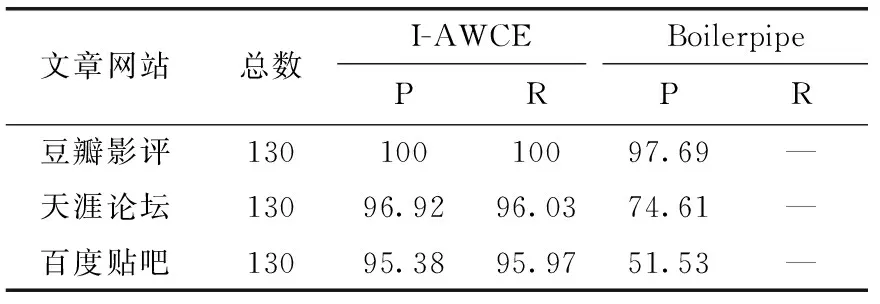
表8 列表类型网页正文抽取对比
4 结束语
本文提出一种基于图像分类的自动化正文抽取模型,该模型利用卷积神经网络对截屏网页图像进行类型判断,并根据不同网页类型分别改进多特征融合的统计学正文抽取模型,这两种算法根据文本长度和节点深度两种特征进行正文抽取,不依赖于大量数据集进行训练。实验结果表明,本文提出的I-AWCE模型可以满足网页自动化抽取的实际需要。
在针对截屏网页图像分类领域,对比各类图像分类模型,结果显示在LeNet-5模型上和预训练模型上训练时间和准确率优于其它模型;在通用数据集上,增大图像特征输入,在复杂模型上有提升效果,其中在ResNet-101模型上测试集准确率提高了1.8%。在网页截屏图像上,对比不同输入大小,增大输入后模型在测试集上的效果显著提升。
随着网页不断发展,网页类型不局限于列表类型和文章类型并且网页中其它非正文信息越来越多。因此在针对网页图像分类模块,随着网页类型增多,加入图像注意力机制可以适应网页分类增多的情况。噪音数据太多会影响抽取结果,因此加入网页分块提取网页正文可以减少噪音数据的影响。这两点是以后工作研究的重点。
