基于自适应森林优化算法的特征选择算法
2023-02-21黄君策顾玉宛庄丽华徐守坤
黄君策,石 林,顾玉宛,李 宁,庄丽华,徐守坤
(常州大学 计算机与人工智能学院 阿里云大数据学院 软件学院,江苏 常州 213164)
0 引 言
对数据进行压缩主要有两种方法,数据降维是映射方法,通过主成分分析(PCA)[4]、独立成分分析(ICA)[5]等数学方法,将高维度数据映射到低维度数据。特征选择是挑选方法,在原数据集中挑选若干特征,组成一个满足某种评价准则的最优特征子集[1-3]。
近年来,在特征选择领域,通常使用元启发式算法对搜索空间进行随机搜索。Zhu等将遗传算法和局部搜索算法结合提出了FS-NEIR算法[6],该算法提出了一种新的特征评价准则,称为领域有效信息比率(NEIR),根据评估准则使用贪婪选择算法进行特征子集的选择;Xue等基于粒子群算法提出了PSO(4-2)算法[7],在初始化策略中加入了前向后向搜索的思想,在更新机制上,将分类准确率和维度约简两方面考虑添加其中;Tabakhi等在对蚁群优化算法研究的基础上,将其应用到特征选择中,提出了UFSACO算法[8],该算法采用滤波器方法,搜索空间被表示为一个完全连接的无向加权图。
Ghaemi等受自然过程影响,提出了森林优化特征选择算法(feature selection using forest optimization algorithm,FSFOA)。在进行分类时,FSFOA不需要过多的计算资源,同样能获得较好的分类效果;同时,FSFOA算法能保证良好的泛化性能[9]。FSFOA算法仍有一些不足:其一,FSFOA算法生成初始解空间时,随机地从n维特征中选择t维特征构成初始特征子集;其二,全局播种阶段,FSFOA算法使用固定值设置参数GSC(global seeding change),不能充分地发挥FSFOA算法的全局搜索能力;其三,在本地播种阶段,FSFOA算法根据LSC(local seeding change)参数进行本地播种,未考虑树的优劣情况。
针对原算法的不足,本文中提出了一种自适应的森林优化特征选择算法(adaptation feature selection using forest optimization algorithm,AFSFOA)。①将特征权重评估算法和初始化策略相结合,提升了初始森林的质量;②参考反馈机制,提出了自适应的GSC参数选择策略;③本地播种过程中,引入贪心算法,寻找更好的特征子集。在10个UCI中的数据集中,将AFSFOA与FSFOA以及近年来提出的其它较为高效的特征选择算法进行比较,实验结果表明,AFSFOA算法显著提高了分类器的分类性能。在维度约简方面,同样表现较好。
1 FSFOA算法概述
受大自然森林演变过程的启发,Ghaemi于2014年提出森林优化算法(forest optimization algorithm,FOA),该算法能够解决连续搜索空间问题。2016年,Ghaemi等将森林优化算法推广到离散搜索空间,应用在特征选择问题中,取得了不错的效果。FSFOA算法包含初始化森林、本地播种、种群限制、全局播种以及更新最优树等5个阶段。其具体流程如图1所示。
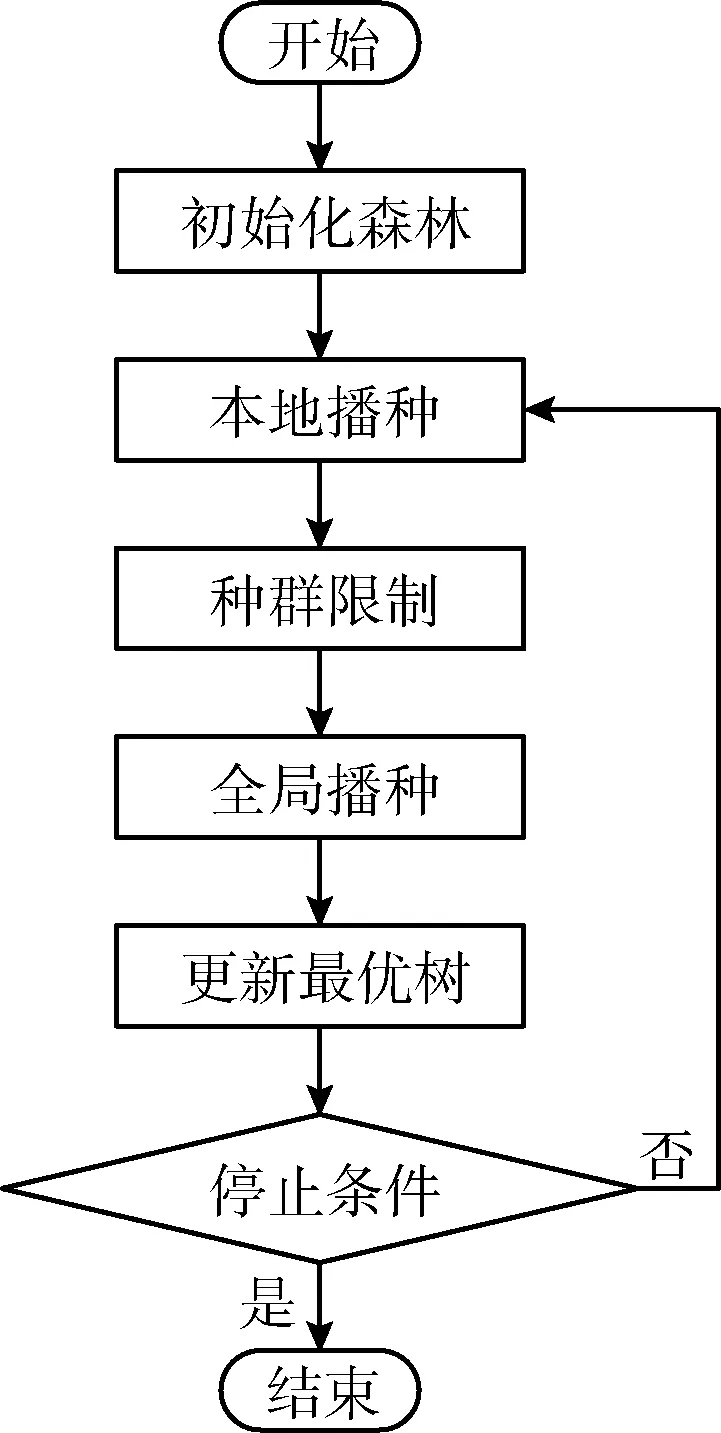
图1 FSFOA算法流程
初始化森林(initialize trees)阶段,算法生成初始森林(初始解空间)。树由特征选择集和树龄(Age)构成;特征选择集是一个n维的{0,1}向量,“0”表示在当前特征子集中,这个特征未被选择,“1”表示这个特征被选择,初始化阶段,这些值随机产生;树龄是树在解空间内存在的时间,在初始化阶段,所有的树的树龄都被设置为0。
本地播种(local seeding)阶段,算法对森林中年龄为“0”树进行局部搜索。将Age为0的树复制LSC(local seeding change)棵,然后随机改变这些树中的某一个特征选择与否,将树龄设置为0,放入森林中。
种群限制(population limiting)阶段,算法控制森林中树木数量。先淘汰树龄大于年龄上限(life time)的树木;然后依据树适应度值(fitness)淘汰超出规模上限的树。淘汰的树放入候选森林。
全局播种(global seeding)阶段,算法进行全局搜索。根据转移率(transfer Rate)从候选森林中选择部分树,然后根据GSC(global seeding change)值,改变这些树GSC位特征选择与否,将树龄设置为0后加入到森林中。
更新最优树(update the best tree)阶段,算法更新当前最优树。算法依据树的适应度值以及维度缩减选择最优树,将当前最优树树龄置为0后重新放入森林。
2 AFSFOA算法
2.1 初始化策略
FSFOA算法在初始化森林时,使用随机方式生成初始解空间。随机生成的森林中部分树品质较低,对后续的搜索造成不利影响。本文考虑在初始化阶段对特征进行一些预处理操作,生成高质量的初始解。
特征的最佳子集高度包含与标签具有强相关性的特征,在初始化时,选中强相关特征能够有效提升初始解空间的质量。与标签相关性较弱的特征在分类时,对分类的贡献较小,引入最终最佳特征子集的可能性较小。参考最近的相关研究[10],本文提出了一种结合了特征相关性的初始化策略。初始化阶段,首先对所有特征的特征相关性ω进行评价,依据一定的选择策略选择特征集中强相关的特征作为优质特征。在生成初始森林时,随机生成一些树,然后将这些树的优质特征全部选中。从而构建出对于后续算法搜索过程友好的优质树。
本文使用了特征权重评估算法[10]对特征相关性ω进行计算,特征权重评估算法在计算特征权重时,不仅考虑特征之间相关性,也会考虑特征和类别之间的相关性。算法从数据集D中随机选择一个样本xi,搜索xi的同类最近邻样本xi(s)和异类最近邻样本xi(d)。然后调整特征对应的同类、异类差异度值,并根据特征差异度相应地调整特征权重。迭代后得到所有特征的相关性权重。
在样本x1与x2上,两者在特征维度fj上的差异度diff(x1,x2,j) 为
(1)
xi选择r个同类最近邻和异类最近邻调整特征fj的权值

(2)
特征权重评估算法:
输入:数据集D,子集维数n。
输出:特征权重ω(1,…,n)。
(1) 初始化数据集D中特征权重ω(1,…,n)=0;
(2) for i = 1 tondo
(3) 随机获取一个实例xi;
(4) 搜索xi的同类最近邻xi(s)和异类最近邻xi(d);
(5) for j=1 tondo
(6) 根据权重调整式(2)调整权重ω(j)
(7) end for
(8) 更新特征权重ω(1,…,n)
(9) end for
对特征进行挑选时,特征的权重越大,表示该特征的分类能力越强,反之,表示该特征分类能力越弱。对于优质特征的选择,参考文献[10],如果特征的相关性满足
(3)
则将特征视为优质特征。其中α是接受不相关特征被误认为相关特征的概率,m为样本的实例个数。
2.2 自适应全局播种策略
全局播种阶段,算法修改GSC个特征的选择与否,GSC参数控制了树木形态的改变。固定的GSC参数限制了树木形态的调整,无法达到全局搜索以跳出局部最优的目的。本文改进GSC参数的生成策略,充分利用算法的全局搜索机制,跳出局部最优,搜索最优特征子集。
在候选森林中,树的形态并不一致:部分树生成时相对劣质,对于这些劣质树,其对应的特征集合与最优特征子集差别较大,与分类标准的要求并不相符,需要对这些树的特征集合做出较多改变;部分树自身特征集合相对优秀,其对应的特征集合趋近于最优解,这些树的特征集合需要的改变较少。
本文改变GSC参数值的生成方式,由固定参数值改为自适应生成GSC参数值。由自动控制理论的启发,本文引入了反馈调节机制,根据树的适应度值(树的质量)“Fitness”确定GSC参数值。树的适应度值为当前树确定的特征子集分类准确率。劣质树调整较多特征的选择与否,设置较大的GSC值;优质树调整较少特征,设置较小的GSC值。同时将全局播种策略与局部播种策略区分,设置了GSC参数的上下限。
自适应全局播种策略中,GSC参数值是树适应度值的函数
numGSC=f(Fitness)
(4)
对树质量进行评判时,不仅需要考虑当前树的质量,也要考虑理想树的质量,才能对树质量做出恰当的评判。本文对当前树质量Fitnessnow和理想最优树质量Fitnessbest进行比较,确定当前树的质量。在确定树的质量时,如果Fitnessnow和Fitnessbest两者差距较大,保守地对树质量做出评价;差距较小时,激进地对树做出评价。由于理想最优树的适应度值难以确定,本文使用当前最优树来近似替代理想最优树。树质量函数为
(5)
得到当前树的质量后,需要将其映射到需要修改的特征个数。当前树的质量与需要修改的特征个数之间是呈正比关系的。即
numchange∝Fitness
(6)
确定GSC参数值时,从当前数据集的特征个数n得到需要修改的特征个数。首先控制全局播种过程中特征改变个数的范围,设定参数GSC的上界为0.5n;GSC值为1时,全局播种的搜索范围和本地播种一致,全局播种则退化为本地播种,为了将全局播种过程与本地播种相区别,设定GSC值的下界为2。则2≤numGSC≤0.5n。 由此,GSC参数值的确定公式如下

(7)
全局播种过程本质是一种全局搜索策略,自适应调整的GSC值,能充分利用全局播种辅助寻优的特性,扩大全局播种的搜索范围,避免算法陷入局部最优情形。更容易找到相对优秀的搜索子空间,收敛到最优解。
2.3 贪心搜索策略
本地播种过程中,FSFOA算法对所有树龄为“0”的树进行局部搜索,限制了算法寻优性能。本文对本地播种过程做出改进,充分利用局部搜索效果,寻找最优特征子集。
本地播种过程中,年龄为“0”的树形态不一致。劣质树的特征和理想最优树的特征差异度较大,对其进行局部搜索时,改变个别特征,无法寻找到优质树;优质树的特征子集和理想最优特征子集相差较小,对其进行局部搜索时,搜索的次数越多,寻找到更好特征子集的可能性越大。
本文对本地播种策略略作调整,对局部搜索树增加了更多的限制,同时增加了局部搜索的搜索范围。
本文在选择局部搜索树时,首先选中森林中树龄为“0”的树,然后根据树的质量进行进一步选择。受贪心策略的启发,在进一步挑选时,选择优质树进行后续的局部搜索过程,减少劣质树的局部搜索,减少森林中的劣质树。仅选择适应度值最高的树,森林中树缺少多样性,算法可能陷入局部最优情形,选择森林中一半的树可以保证森林里树的多样性。判断树的质量时,将树龄为“0”的树根据其适应度值从高到低排序,适应度值排名前一半的树标记为优质树,继续后续的局部搜索过程;适应度值排名后一半的树则为劣质树,不进行后续的局部搜索。在选择树时,选择原算法一半的树进行后续局部搜索过程。
对优质树进行局部搜索时,扩大其搜索范围。FSFOA算法在局部搜索时,其搜索范围是由LSC参数值控制的。算法的LSC值与数据集特征个数n相关,其值为

(8)
在选择局部搜索树时,本文选择原算法一半的树进行后续局部搜索过程;在搜索时,本文将搜索范围扩大一半,将LSC值设为
(9)
在能够搜索到更好的特征子集同时,也保证了算法的运行效率。
本地播种过程是一个局部搜索过程,是一个“优中寻优”的过程。调整后的本地播种过程,充分利用了局部搜索“优中选优”的特性,去除了对劣质树的局部寻优,增加了优质树的寻优范围,更容易收敛到最优特征子集。
3 实验结果与分析
本文实验平台为一台CPU为Intel i7-6800K、操作系统为Linux(Ubuntu 16.04)的计算机。实验使用语言为python3,此外还使用了著名的机器学习工具包scikit-learn。
3.1 数据集
本文在10个不同规模的UCI数据集上进行了对比实验。根据文献[9],按照数据集规模,选择了特征数量在[0,19]之间的6个低维度数据集(Glass、Wine、Heart、Cleveland、Vehicle、Segmentation);特征数量在[20,49]之间的2个中维度数据集(Dermatology、Ionosphere);特征数量在[50,∞]之间的2个高维度数据集(Sonar、SRBCT)。选择不同维度的数据集,能够看出算法在不同情形下的表现。数据集的具体信息见表1。表中n为数据集总的特征个数,m为数据集实例个数,labels为数据集类别数目。
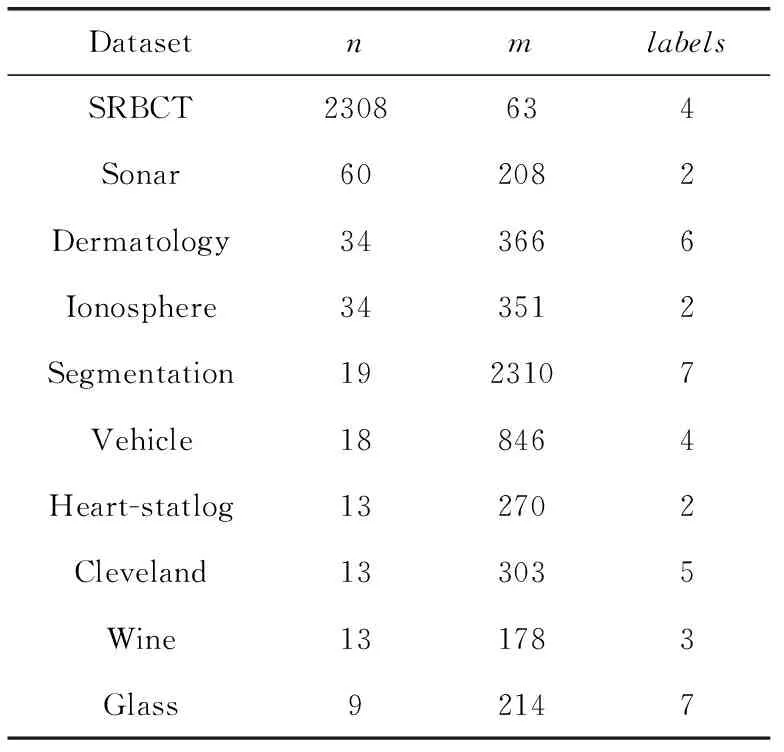
表1 数据集概述
3.2 评价指标
本文在对实验结果进行对比时,使用了两种评价指标对算法进行评价。
第一种评价指标为算法的分类准确率CA(classification accuracy),分类准确率反映最优特征子集在分类器上的表现。其具体定义如下
CA=CC/AC
(10)
其中,CC表示了能够正确分类的实例数,AC(all classifica-tion)则是参与分类的实例总数。
第二种评价指标为算法的维度约简率DR(dimensio-nality reduction),维度约简率是对最优特征子集特征个数的评价。其具体定义为
DR=1-(SF/AF)
(11)
其中,SF(selected features)是在特征集中被选择的特征个数,AF(all features)是数据集的特征总数,即n。
3.3 参数设置
实验过程中,AFSFOA算法的参数设置规则为:参数设置方法未改进,依据参考文献[9]中的设置方法,设为与FSFOA算法相同的参数值,确保实验公平性;参数设置方法有调整,依据本文方法重新设定参数值。未做修改的参数设置中,固定参数的设置由表2给出。

表2 AFSFOA算法固定参数信息
3.4 实验结果对比分析
本文在进行对比实验时,在比较AFSFOA算法与原算法FSFOA表现的基础上,拓展了算法的比较范围,选择部分近年来表现出色的特征选择算法进行对比。
进行比较的特征选择算法包括过滤式特征选择算法和嵌入式特征选择算法。过滤式特征选择算法有:FS-NEIR、SVM-FuzCoc[12]和NSM[13],这类算法使用具体评价准则给每个特征打分,运算效率较高。嵌入式特征选择算法为UFSACO和PSO(4-2),这类算法构建学习器,根据预测精度对特征子集进行评价,分类准确率较高。
在进行对比实验时,主要使用了DT分类器和KNN分类器。为了保证实验的可靠性,部分实验使用了10折交叉验证。实验结果见表3。
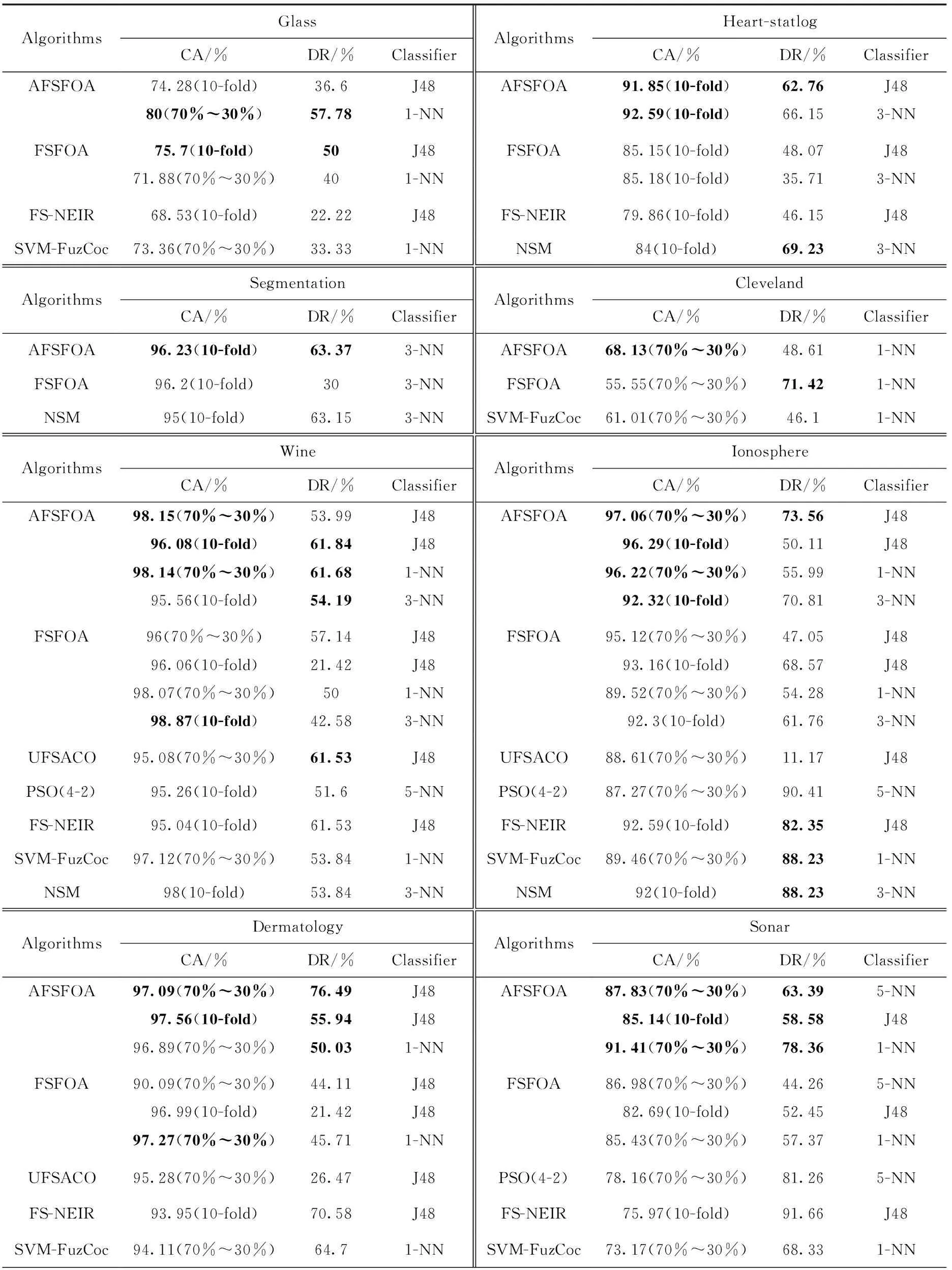
表3 实验结果
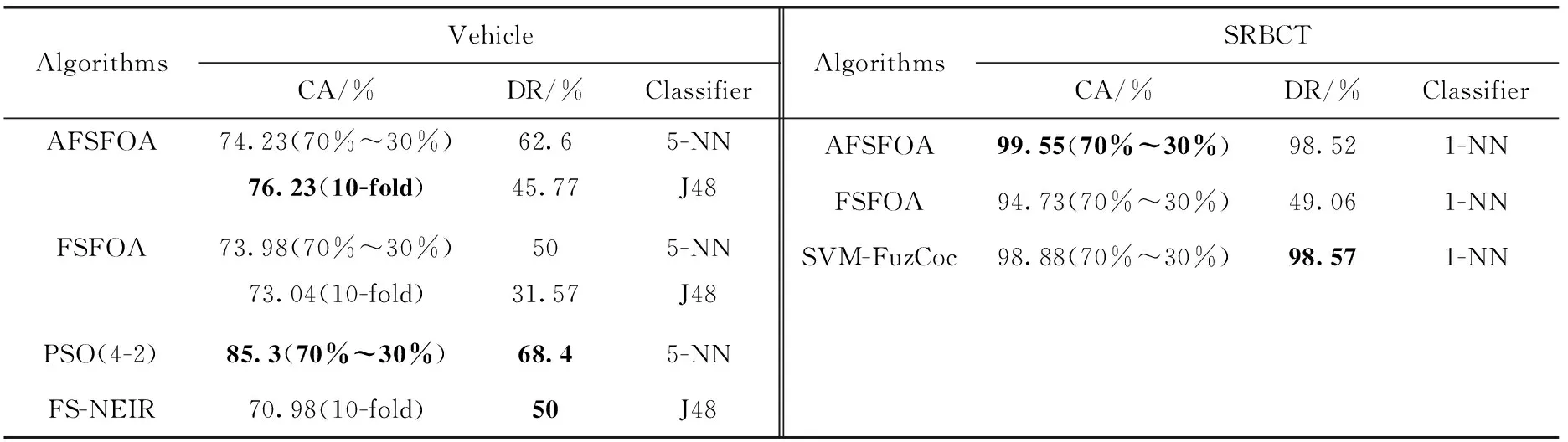
表3(续)
比较AFSFOA算法在不同分类器中的表现,在Glass、Heart-statlog和Sonar这些数据集中,算法在KNN分类器中的表现优于DT分类器。在特征选择后,最优特征子集已包含所有有效信息。KNN学习器在分类时,使用了所有特征来进行分类;而DT学习器分类时,会丢弃少量信息。因此,KNN学习器的分类精度较DT分类器高。
将AFSFOA算法与FSFOA算法实验结果对比,可以看到改进后的AFSFOA算法确有成效。在Sonar、Heart-statlog、Segmentation、SRBCT等数据集上,AFSFOA算法在不同的分类器中,分类准确率以及维度缩减率都有提高;在Cleveland、Ionosphere等数据集上,AFSFOA算法在不同分类器上的分类准确率有明显提升;在Vehicle、Wine、Glass、Dermatology这些数据集中,AFSFOA算法在部分分类器中分类性能略低于FSFOA算法,但维度缩减率提升较多;其中Wine数据集在使用3-NN分类器时,分类准确率相差较大,准确率低了约3%,但维度约简提升了约20%。
比较在不同维度数据集下,AFSFOA算法的表现。在高维度的两个数据集Sonar和SRBCT中,AFSFOA算法较FSFOA算法有着明显的提升,分类准确率均提高了5%~10%,同时维度约简也有着明显的提升;在中维度数据集Ionosphere、Dermatology中,除Dermatology在1 NN分类器中的表现略逊于FSFOA算法外,其它分类器上,本文算法仍有着较好的表现;低维度数据集中,AFSFOA算法在绝大多数的分类器中表现良好,仅有部分分类器较FSFOA算法未有提升,但在这些分类器中,维度约简有着明显的提高。对不同维度的数据集进行比较,可以看出AFSFOA算法在中高维度的数据集中表现优异,而在低维度数据集中,表现同样具有竞争力。对于不同维度的数据集,AFSFOA算法都能得到较好的结果,具有良好的泛化能力。
与其它算法进行对比时,AFSFOA算法在分类准确率上仍有很强的竞争力。使用相同的学习器对数据集训练,仅在Vehicle数据集中,使用5-NN分类器时,表现不如PSO(4-2)算法,在分类准确率上,AFSFOA算法的准确率比PSO(4-2)算法低约10%;在其它数据集中,AFSFOA算法仍占有优势。
在维度约简能力上,和FSFOA算法相比,AFSFOA算法的维度约简能力有着明显的提升,但和其它算法相比,AFSFOA算法表现一般。但在两个高维数据集Sonar和SRBCT中,与同类算法对比,AFSFOA算法的维度约简能力均能达到最高的水准。在Sonar和Segmentation这两个数据集中,和FSFOA算法以及其它算法对比,AFSFOA算法在保持分类准确率的同时,有着优秀的维度约简能力。在Glass和Cleveland这两个数据集中,本文算法的维度约简率不如FSFOA算法,且差距较大,且在Glass数据集中,本文算法在分类准确率上上同样低于FSFOA算法。和其它算法的维度约简能力相比,AFSFOA算法仍然有着不小的进步空间;在Vehicle和Ionosphere这两个数据集中,AFSFOA算法的维度约简与其它算法相比均有较大差距。
4 结束语
通过对森林优化特征选择算法(FSFOA)的研究与分析,本文针对其不足之处做了3点优化。在FSFOA算法的初始化阶段,本文加入了特征权重评估算法,优化搜索起始点,便于后面算法进行高效搜索;在全局播种阶段,本文加入了参数自适应生成策略,通过对树“Fitness”值的分析,自动生成全局搜索参数(GSC);在算法的局部播种阶段,加入了贪婪策略,增加对年龄为“0”的优质树的局部搜索。将AFSFOA算法在10个UCI数据集中进行测试,并与其它特征选择算法进行对比,实验结果表明,AFSFOA算法显著地提高了分类准确率;同时在部分数据集中,能够生成维度更少的特征子集。
