基于双分支多尺度融合网络的毫米波SAR 图像多目标语义分割方法
2023-02-18丁俊华袁明辉
丁俊华,袁明辉*
1上海理工大学太赫兹技术创新研究院,上海 200093;
2上海理工大学光电信息与计算机工程学院,上海 200093
1 引言
随着毫米波技术的发展,毫米波安检方案越来越成熟[1-2],与传统的安检技术相比,如X 射线安检、红外线安检、金属探测仪安检等,毫米波安检成像不仅可以检测出织物下隐匿的金属物,还可以检测出塑料枪支、陶瓷刀具、炸药等危险品,最重要的是,毫米波具有非电离性,对人体不会造成伤害[3-5]。毫米波安检能获得清晰的图像信息,可大大降低虚警率,因而毫米波成像设备在人体安检场合得以广泛应用。
近几年,随着人工智能的发展,深度卷积神经网络在图像分类[6-7]、目标检测[8-9]、图像分割[10-15]等领域都获得取得重大突破。因此,许多高效的深度学习算法被应用到毫米波图像的隐藏目标检测中。然而,这些算法一般检测的目标都是RGB 图像与高分辨率图像,这与毫米波图像存在着较大的差异。毫米波图像普遍为灰度图像,且分辨率较低,同时由于毫米波探测器性能以及成像算法的影响,毫米波图像的信噪比远低于光学图像,图像对比度低,物体成像不完整。现有的研究已经证明,这些问题严重干扰了隐藏目标的识别与定位,降低了毫米波图像的检测性能[16]。因此,一些针对SAR (millimetre-wave synthetic aperture radar)成像特性的毫米波图像检测的深度学习方法被陆续提出。Liu 等人[17]将毫米波图像与额外的空间深度图结合,并设计了一个新的损失函数,提高了对违禁品的检测率,但检测类别只有一个。Sun 等人[18]设计了具有两种不同注意力机制的多源聚合Transformer,能有效提升隐藏目标的检测性能。然而,上述研究只能检测出违禁品在人体表面的位置,无法对违禁品的种类进行识别,这导致安检人员需要进行二次检查,确定违禁品种类,以对违规人员进行处置。如果能直接对违禁物品进行识别,将会大大提升安检效率。Pang 等人[19]使用了YOLO v3 算法,对被动毫米波图像的人体隐蔽金属武器进行实时检测。他们主要针对手枪和人进行识别,两个目标形状差异明显,便于深度学习网络识别,但识别种类较少,识别精度和误报率仍有进一步改进的空间。
上述方法都是基于锚框的目标检测方法。锚框中不仅包含检测目标,还有背景噪声,这会影响目标的识别。同时,由于毫米波图像的可读性差,只用锚框框出检测目标,不利于安检人员的查看。语义分割方法则可以解决此类问题,它不同于目标检测和识别,语义分割可以实现图像像素级的分类。“语义”指具有人们可用语言探讨的意义,“分割”指图像分割。语义分割能够将整张图的每个部分分割开,使每个部分都有一定类别意义。与目标检测不同的是,目标检测只需要找到图片中目标,打上框然后分出类别。语义分割是将图像中的所有像素点分类,然后以描边的形式,将整张图不留缝隙地分割成各个区域。每个区域是一个类别,没有类别的默认为背景(background),这大大避免了背景噪声的干扰,可以将整个违禁品分割出来进行种类划分,同时上色,即便在可读性差的毫米波图像中,安检人员也可轻易地看出物体的形状,快速获取因违禁品的信息,以便后续的处理。Wang等人[20]通过扩展卷积来提高感受野,以用来提高检测性能,并且在实验用取得良好的结果。Liang 等人[21]通过选定连接U-net 网络结合生成对抗网络,实现在人体中分割出违禁物品。然而,目前SAR 图像检测的研究重心主要是目标成像问题和背景干扰问题,但SAR 图像检测还存在多目标间的相互干扰、小目标如何检测等问题。因此,要实现SAR 图像中隐藏目标的精确识别与定位还存在着一些挑战。针对以上难点,本文主要贡献有:1) 提出双分支特征提取网络(DBPFEN,dual-branch parallel feature extraction network),该网络为双分支并行输出的结构,两个分支之间建立双边连接,进行重复的信息融合,能够大大减小模型复杂度,同时提高模型对成像不完整的目标、相互阻挡的目标和小目标的识别能力;2) 提出一个多尺度融合模块(MSFM,multi-scale fusion module)。该模块能够将多个不同层的高分辨率特征图融入低分辨率特征图中,从而去获得更多的位置细节信息以增加对目标的检测能力。
2 基本原理
2.1 双分支多尺度融合网络(DBMFnet)
在本文中,我们提出了DBMFnet 语义分割模型来识别SAR 图像中的违禁品,该网络为Encoder-Decoder 结构。在Encoder 阶段,我们采用双分支并行特征提取网络(DBFEN),在特征提取的过程中一个分支保持高分辨率不变,另一个分支通过多次下采样操作提取丰富的语义信息,两个分支之间建立双边连接,进行重复的特征融合。在Decoder 阶段,为了增加对目标的检测能力,低分辨率分支特征图、高分辨率分支特征图以及通过Skip 连接层获得的更高分辨率的特征图同时引入多尺度融合模块(MSFM),实现多个不同分辨率特征图之间的相互融合。之后通过上采样二倍恢复原图大小后输出预测图。其网络结构如图1 所示。
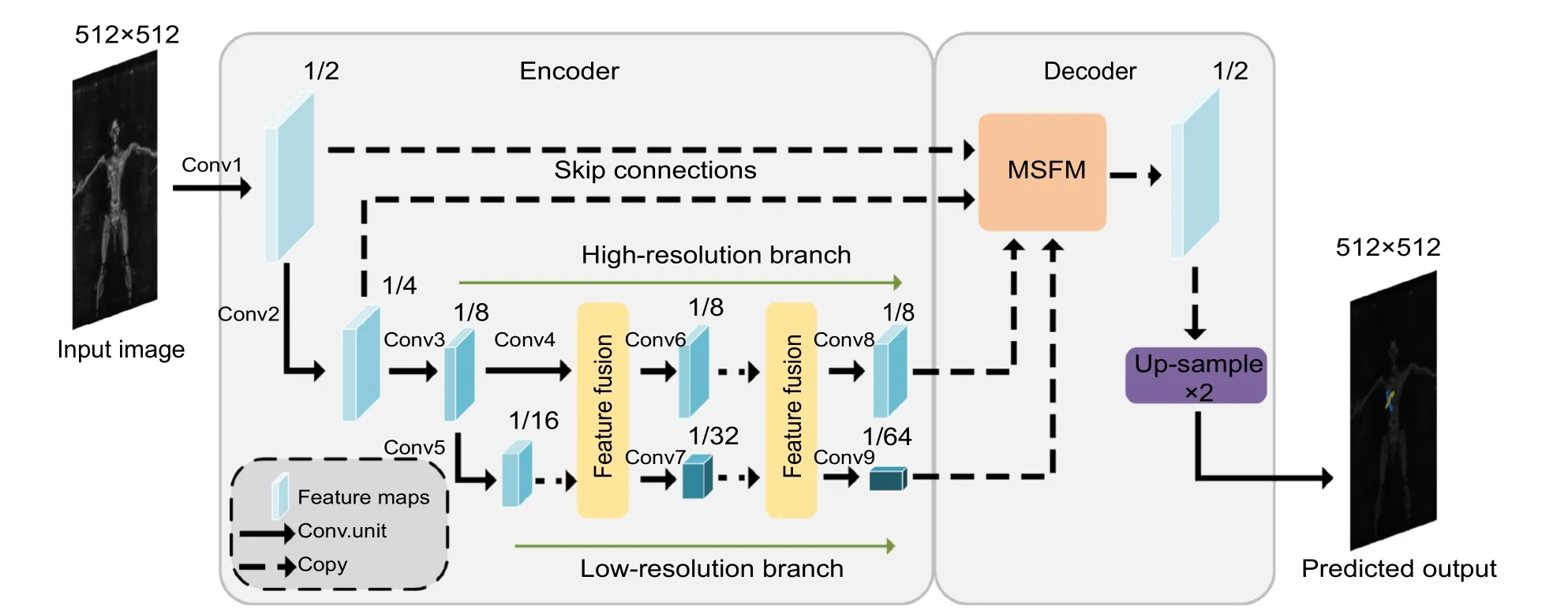
图1 DBMFnet 网络结构图Fig.1 DBMFnet network structure diagram
双分支并行特征提取网络具体实现流程如图1的Encoder 阶段所示,输入图片大小为512×512,经过两个卷积核大小为3×3、步距为2 的卷积层,变为输入分辨率的1/2 与1/4。1/4 分辨率的特征图经过2个堆叠的basic block 残差模块,通道数翻倍,分辨率降为输入图像的1/8,得到高分辨分支的初始特征图。将高分辨率分支的初始特征图同样经过2 个堆叠的basic block 残差模块,通道数翻倍,分辨率降为输入图像的1/16,得到低分辨率分支的初始特征图。两个分支的特征图进行特征融合,其具体融合过程如图2所示,高分辨率分支的特征图Fh通过一个卷积核大小为3×3 步距2 的卷积层来降低分辨率与改变通道数,之后与低分率分支的特征图相加得到F′h。同样地,低分辨率分支的特征图Fl需要通过双线性插值与一个卷积核大小为1×1 步距为1 的卷积层来提高分辨率与改变通道数,之后与高分辨分支的特征图相加得到F′l,融合完成后输出F′h与F′l。后续重复此过程,高分辨率分支分辨率保持不变,低分辨率分支不断地进行下采样。低分辨分支的特征图分辨率分别为输入分辨率的1/16、1/32 和1/64,对应的通道数为256、512 和1024,高分辨率分支的特征图分辨率则保持为输入分辨率的1/8,通道数为128,具体细节如表1 所示。
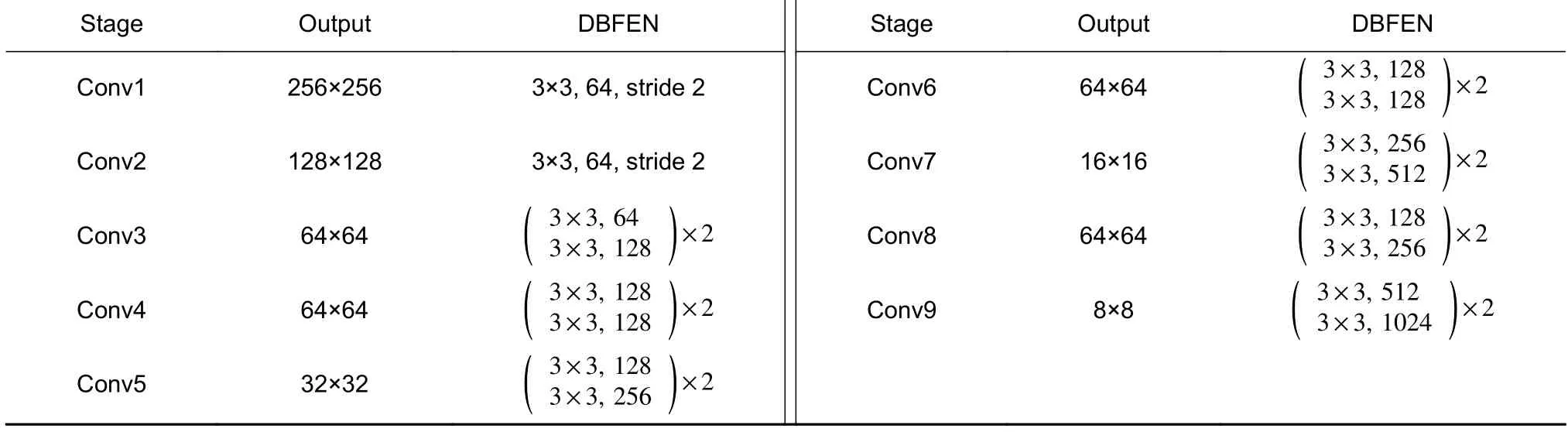
表1 双分支特征提取网络结构Table 1 Architectures of DBFEN
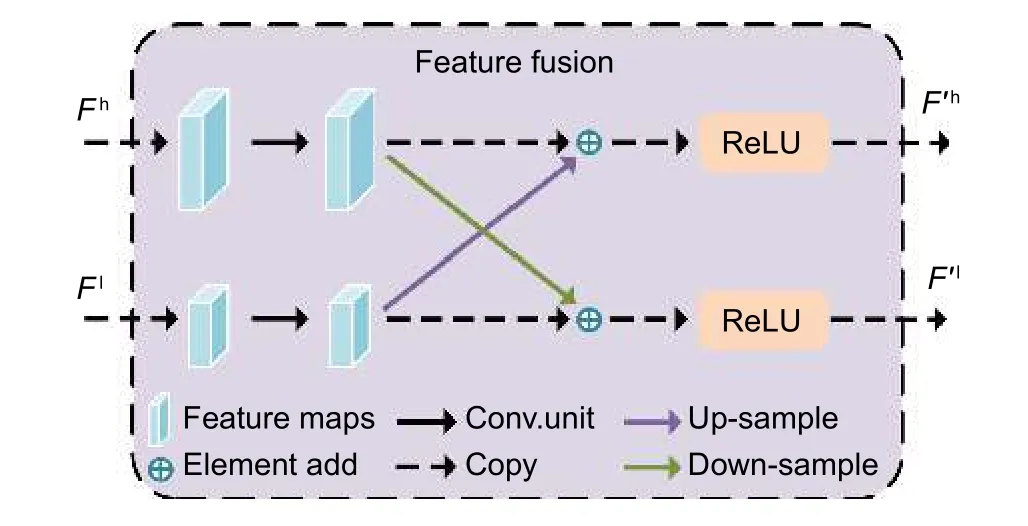
图2 特征融合过程Fig.2 Feature fusion process
2.2 多尺度融合模块(MSFM)
语义分割的解码器阶段需要将低分辨率的特征图逐步恢复到原始图像的分辨率。常见的操作是在恢复的过程中通过skip connections 融合下采样过程中的特征图,U-net 和DeeplabV3+使用拼接(FCM)的方式融合特征图,如图3(a)所示,而FCN 则是使用相加(FDM)的方式融合特征图,如图3(b)。然而,这些方式忽略了不同分辨率的特征图之间的不对齐,可能会丢失许多的语义信息,导致目标边界上的分割性能较差。在DBMFnet 中,高分辨分支与低分辨分支分别输出为输入分辨率1/8 的特征图与1/64 分辨率的特征图,二者尺寸相差过大。如果用传统线性插值的方式上采样再进行融合,则会丢失许多的语义信息。同理,高分辨分支特征图的分辨率与原图特征图的分辨率也相差过大,直接上采样同样会丢失许多的语义信息。为了提高对目标的检测能力,提出一种多尺度融合模块(MSFM),如图3(c)所示。该模块由特征对齐模块(FAM)构成[22],它将高分辨率特征图Fh与低分辨率特征图Fl作为输入,分别经过一个1×1 的卷积改变为相同通道数,将高分辨特征图与经过双线性插值上采样的低分辨率特征图进行拼接,然后拼接后的特征图经过一个3×3 的卷积层得到与Fh相同大小的偏移场。在数学上,上述步骤可以写为

图3 不同的特征融合方式。(a) FCM;(b) FDM;(c) MSFM;Fig.3 Different feature fusion methods.(a) FCM;(b) FDM;(c) MSFM
其中:upsample(.)为双线性插值上采样,cat(.)代表拼接操作,conv(.)代表3×3 的卷积层。在获得偏移场后,低分辨率特征图将被扭曲(warp)为高分辨率特征图,偏移场的每个点(Xh,Yh)都 需要被Fl中的点(Xl,Yl)映射,公式如:
其中:Δx和Δy表示点(Xh,Yh)可学习的2-D 变换偏移,N表示高低分辨率相差的倍数,然后,通过可微分双线性采样机制使用(Xl,Yl)的四领域插值来获得扭曲的高分辨率特征图U(Fh(Xh,Yh),)的位置。数学表达式为
其中:Hl和Wl表示低分辨率特征图的大小。整个FAM 的数学表达式如下:
在MSFM 中,引入低分辨率分支、高分辨率分支与通过skip connections 获得的输入分辨率1/4 的特征图,分别为,引入skip connections 获得的输入分辨率1/2 的特征图为,将多个不同层的高分辨率特征图融入低分辨率特征图中,得到输入分辨率1/2 的高分辨率特征图。所提出的多尺度融合模块,增加了对目标的检测能力。
3 实验与分析
3.1 数据集
基于实验室的MIMO-SAR 架构的主动式毫米波人体安检成像系统,构建了毫米波SAR 人体安检图像数据集,命名为HM-SAR,数据集共1100 张图片,其中90%的图片用于训练,10%的图片用于测试。该系统为平扫系统,工作频率为35 GHz,天线阵列放置于X轴,系统沿Y轴上下扫描,可同时对人体正面和背面进行扫描,成像效果如图4(a)、4(b)所示。扫描成像以jpg 格式保存,每个图像固定为200×400像素。数据集中的图像使用Labelme 进行标记,对不同的目标赋予不同颜色的标签,剩下未标记的全部被归为背景类。在数据采集过程中,目标物被随机隐藏在人体表面与身体边缘。我们使用了四种违禁品作为识别目标,分别为扳手、锤子、手枪和小刀。
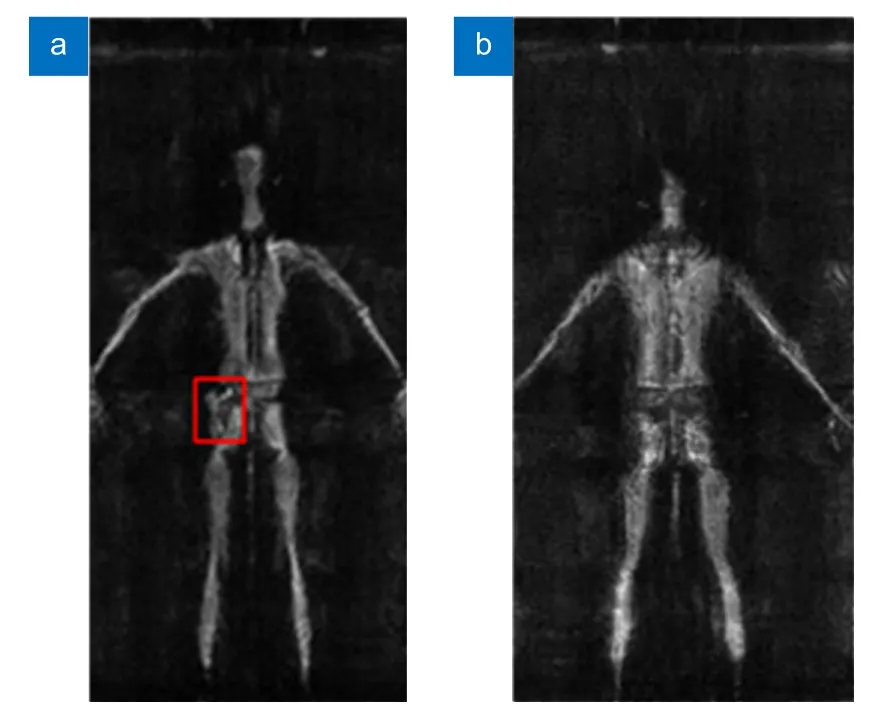
图4 HM-SAR 安检图片。(a) 背面扫描的人体图片;(b) 正面扫描的人体图片Fig.4 HM-SAR security images.(a) Back scanning image of the human body;(b) Frontal scanning image of the human body
3.2 评价指标
为了进行定量评估,测试网络性能参数主要为平均像素准确率(MPA)、平均交并比(mIoU)、F1。
上述式中,k表示像素类总数,pii表示原本为i类被预测为i类的像素点数量,pij表示原本为i类被预测为j类的像素点数量,pji表示原本为j类被预测为i类的像素点数量。MPA表示对所有类别的CPA的平均值。mIoU表示对所有类别的IoU 的平均值。mIoU的值越高,表示模型的预测值和真实值的重合度更好,说明模型的分割性能越好。Precision为精确率,Recall为召回率,F1 是精确率和召回率的调和平均值,TP是 将正类预测为正类数,FP是将负类预测为正类数,FN是将正类预测为负类数。本文中的所提出的模型是在Pytorch 1.12.0 框架中实现的,Cuda版本为11.6,采用VOC2007 格式的数据集,并使用Adam 优化器对网络进行端到端的训练,初始学习率为5×1 0−4,最小学习率为5×1 0−6。所有实验均在具有单张NVIDIA GeForce RTX 3090 GPU 台式电脑上进行,迭代训练次数为300,批量大小为8,输入图片大小为512×512。
3.3 热力图分析
为了进一步了解DBMFnet 模型网络结构中各个步骤特征图变化情况,我们对整个网络进行热力图分析,我们将网络中各个步骤输出的特征图提取出来,并进行可视化展示,展示结果如图5 所示,图中颜色越偏向红色的区域表示网络越关注的区域,即权重值越高,预测为藏匿物的概率也就越大。从图中可以看出,高分辨率分支为浅层特征图,其中语义信息较少,目标位置相对比较准确,图中第一行浅层特征图几乎都能清晰看出人体轮廓。而低分辨率分支为深层特征图,其中语义信息比较丰富,目标位置比较粗略,图中第二行的深层特征图已经几乎看不清楚人体的位置信息,这导致其检测小目标的能力较弱。在DBFEN中,我们不断地将浅层特征图和深层特征图进行融合,从而让浅层特征图获得更多的语义信息。在MSFM 中,让最深的特征图依次融合来自不同层的浅层特征图,从而去获得更多的位置细节信息以增加对目标的检测能力,图中可以看出特征图经过MSFM后,网络最关注区域变为藏匿物的存在的区域。
3.4 有效性评估
为了评估DBMFnet 模型的有效性,选择U-net、Pspnet、FCN-8s、Deeplabv3+和HRnet-v2 作为模型性能的对比对象,这些都是语义分割领域的经典模型,且都有很大的影响力。根据表2 中的数据,我们提出的DBMFnet 具有最好的分割性能,MPA、mIoU 和F1 值分别为85.01%、75.44%、85.21%。模型的mIoU 值越高,说明目标的预测掩码越贴近ground truth,模型的MPA 值越高,说明对目标的定位就越准确,模型的F1 值越高说明模型对目标识别的精度越好。

表2 各模型在HM-SAR 数据集中的分割性能比较Table 2 Comparisons of the segmentation performance of each model in the HM-SAR dataset
表3 显示了各模型对不同目标的分割结果。我们的模型无论是目标的精确率(Pre)还是交并比(IoU),都优于其他的模型。锤头的精确率和交并比相对于其他模型分别提高了1.17%~5.42%和1.98%~7.35%,扳手的精确率和交并比相对于其他模型分别提高了1.34%~5.42%和3.40%~9.09%,手枪的精确率和交并比相对于其他模型分别提高了2.18%~12.44%和1.09%~6.79%,小刀的精确率和交并比相对于其他模型分别提高了0.88%~3.96%和4.14%~6.75%。结果表明DBMFnet 对比与其他模型,不同目标的精确率和交并比均有提升,这是因为多尺度融合模块的引入,提升了我们模型检测小目标和物体轮廓的能力,从而提高了检测性能。

表3 各模型在HM-SAR 数据集中的目标分割性能比较Table 3 Comparisons of the objects segmentation performance of each model in the HM-SAR dataset
我们选取五张图像的分割结果来更直观地说明各个模型的分割效果。图6 显示了各个模型在HMSAR 数据集中的测试结果,图中第一行,手枪与安检系统扫描平面垂直,只能成像出手枪的握把,部分模型出现了分割错误的情况。图中第二行,小刀完全融入了人体轮廓,部分模型同样出现了分割错误的情况。图中第三行,手枪的握把非常的细,只有Unet与DBMFnet 能正确的将手枪的握把分割出来,并且DBMFnet 还能够分割出扳手的开口。图中第四行,测试图中的目标之间有重叠的区域,这会增加分割的难度,从分割结果可看出,其他模型都存在错误分割或分割不完整,只有DBMFnet 的分割结果最接近Ground truth。图中第五行,锤头几乎看不清,大部分模型出现分割错误或没有检测出来的情况,仅有DBMFnet 分割出来且类别正确。以上实验结果说明本文模型具有更准确的像素分类能力以及识别小物体轮廓的能力。

图6 各模型测试结果,每一行代表相同图片测试的结果,每一列代表同一模型的测试结果。黑色像素表示背景,红色像素 表示锤头,绿色像素表示扳手,黄色像素表示手枪,蓝色像素表示小刀Fig.6 Test results of each model.Each row represents the test results of the same picture,and each column represents the test results of the same model.Black denotes the background,green denotes the wrench,yellow denotes the pistol,red denotes the hammer,and blue denotes the knife
除了测试模型精度外,我们还对模型复杂性和推理速度进行测试,如表4 所示。这里使用参数量、浮点运算(GFLOPs)量和FPS (frames per second)来评估模型的复杂性。本文中,所有模型均通过单尺度推断进行评估,输入图像分辨率为512×512。表4 中,我们提出模型的参数量和浮点运算量最小,因此本文模型对硬件性能的要求较低,可以很容易地部署在各种安检系统中。在推理速度方面,与其他模型相比,本文模型没有优势,这是因为:1)在特征提取阶段的特征融合过程中,低分辨率分支需要等待高分辨率分支计算完成后才能进行融合,在等待同步需要花费时间;2)在特征融合阶段多尺度融合模块中,低分辨率特征图依次向上融合,高分辨特征依然要等待下级特征图融合完成后才能继续向上融合,等待过程中也会花费时间。然而,在保证检测精度的前提下,我们模型的检测速度已经可以满足实际的安检需求。
3.5 消融实验
在本文中,双分支特征提取网络用于编码器来提高特征提取性能;多尺度融合模块用于解码器来提高分割精确度。为了验证所提出的模块有效性,我们分别对其进行了消融实验,所有实验均在数据集HMSAR 上进行。
我们首先评估双分支特征提取网络的性能,我们使用没有解码器的DBMFnet,即双分支特征提取网络作为比较基线(Baseline),将双分支特征提取网络的高分辨率分支输出与低分辨率分支上采样8 倍后的结果直接进行拼接,然后再上采样8 倍得到预测结果,如图7 所示。随后引入解码器模块逐步恢复边界,将Baseline 中拼接后的结果上采样2 倍后与1/4 输入分辨率的特征图进行融合,再上采样2 倍与1/2 输入分辨率的特征图进行融合,再上采样2 倍得到预测结果。解码器分别以FCM(图3(a)所示)、FDM (图3(b)所示)和MSFM (图3(c)所示)的方式进行特征融合。结果如表5 所示,未加入解码器的Baseline 模型性能已经优于带解码器的Deeplabv3+和FCN-8s 网络的性能。在加入解码器之后,各个模型的mIoU 相对于基线模型均有提升,计算量也有所增加,而MSFM 方式的特征融合达到了最好的平衡,在增加少许计算量(GFLOPS)的同时,性能提升最多,并且参数量还有所降低。
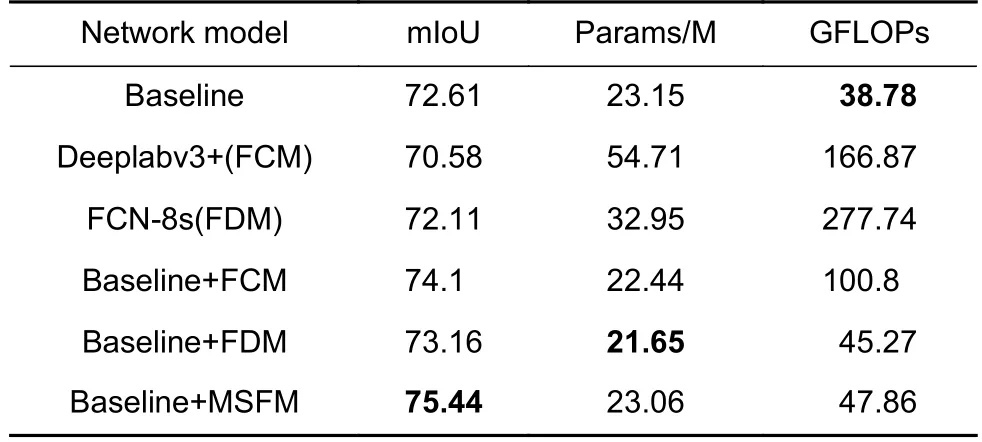
表5 使用不同解码器模块的模型性能对比Table 5 Comparisons of models using different decoder modules
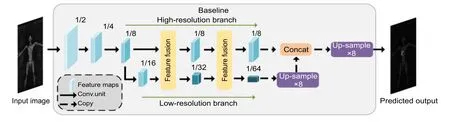
图7 基线模型Fig.7 Baseline model
4 总结
针对安检系统SAR 图像中违禁品的检测,提出一种语义分割方法DBMFnet,该方法能够精确定位和识别SAR 图像中多种小目标的违禁品。该方法包括双分支并行特征提取网络和多尺度融合模块。并行输出结构能够在特征提取过程中不断融合交换高分辨率特征和低分辨率特征的信息,减少下采样过程中的特征损失,有利于小目标和相互重叠目标的识别,同时双分支结构大大减少了模型复杂度,降低了部署的硬件成本。使用HM-SAR 数据集测试时,我们所提出的模型与现有的表现最好语义分割模型相比mIoU提升了2.54%。消融实验表明,所提出多尺度融合模块均可有效提升mIoU 值。我们的方法可以拓展到其他遥感场景,比如检测船舶、土地分类、水体检测等。在未来的工作中,我们期望将实例分割应用到SAR图像的检测中,能利用SAR 图像中尽可能多的信息,促进SAR 图像目标识别的研究。
