伪标签细化引导的相机感知无监督行人重识别方法
2023-02-18程思雨
程思雨,陈 莹
江南大学轻工过程先进控制教育部重点实验室 物联网工程学院,江苏 无锡 214122
1 引言
行人重识别(Re-identification,Re-ID)旨在通过不重叠的相机检索特定行人的图像,在智能监控和公共安全领域拥有重要的应用价值[1]。近年来,随着深度学习技术的蓬勃发展,有监督的行人重识别方法取得了显著的性能提升。然而,这些方法依赖于大量的数据标注,标注工作耗时耗力,使得它们难以在实际场景中部署和应用。因此,无监督的行人重识别方法逐渐受到研究者们的关注。
无监督行人Re-ID 可大致分为两大类:无监督领域自适应(unsupervised domain adaptation,UDA)方法和完全无监督学习(unsupervised learning,USL)方法。USL 方法需要的未标记行人图像很容易通过目标检测技术从监控系统中获得,相比于UDA 方法更加灵活和易于部署。
近年来,对比学习方法在无监督视觉表征学习领域表现出色。其核心思想是在特征空间中缩小正样本对之间的距离,同时扩大负样本对之间的距离。这一思想也被成功地应用于USL 行人重识别任务。根据内存字典设置的不同,对比学习方法在USL 行人重识别中可分为两类:实例级和聚类级方法。实例级方法将每个图像视为一个单独的类,主要利用每个样本本身的自监督信息,而不太考虑样本间的结构或者相关性。例如,Zhong 等人[2]提出将目标域中每张图片视为单独的类别,通过构建一个样本存储器,存储所有目标图像的最新特征,进而在目标域中实施样本不变性,相机不变性和邻域不变性三种约束。聚类级方法则通过聚类算法生成伪标签,根据输入图像与集群中心特征之间的相似性来构建对比损失。这类方法将同一集群内的样本视为正样本,而将其他集群的样本视为负样本。例如,Ge 等人[3]提出了一种自步对比学习框架,将每个集群和离群值视为单一类,并计算集群级别的对比损失。然而,由于聚类大小和采样的随机性,导致每个集群的更新过程不一致。为解决这一问题,Dai 等人[4]提出了聚类级对比学习机制,并在聚类级别更新内存字典。
这些方法将每个集群视为一个伪身份类,侧重改善类间差异,而忽略了由相机间风格差异引起的类内差异。最近一些方法探索了这一问题。Tian 等人[5]提出采用StarGAN[6]将样本迁移到每个相机。其他一些方法采用相机内和相机间的联合训练方式,在相机内训练阶段,为每个相机设置一个分类器,所有的分类器共享一个主干网络。在相机间训练阶段,现有的方法设计了不同的策略统一从不同相机中学到的知识:Yang 等人[7]提出了相机感知的元学习算法,将训练数据根据相机标签拆分为元训练和元测试部分,并进行梯度交互,以迫使模型学习相机不变的特征表示;Xuan 等人[8]提出使用实例归一化(instance normalization,IN)和批处理归一化(batch normalization,BN)的组合提高分类器的泛化能力;Wang 等人[9]提出将单一的聚类集群根据相机视角分成多个子集群,并设计了相机内和相机间的对比学习模块;Li 等人[10]提出了一种相机风格分离模块,以明确地从特征图中分离出特定的相机信息从而减少类内方差;Lee 等人[11]提出一种基于摄像头的课程学习(CaCL)方法,利用相机标签逐渐将从有标签的源域训练的模型推广到无标签的目标域,目标域数据集根据相机标签分为多个子集,模型最初使用单个摄像头捕捉的图像进行训练,然后根据调度规则逐渐利用更多的子集进行训练,调度规则考虑每个子集与源域数据集之间的最大均值差异(MMD),以确保在课程中较早地利用更接近源域的子集。
不同相机拍摄的图像受到视角、光照、背景等环境因素的影响,导致来自不同相机的同一身份标签之间的图像具有较大的特征差异。这使得聚类算法也很难将同一身份的样本准确地聚类到同一集群中,生成的伪标签也不可避免地含有噪声。伪标签中的噪声严重降低了无监督行人重识别方法的性能,为解决这一问题,Ge 等人[3]采用了自步对比学习方案逐步获得更可靠的簇,用于对伪标签进行细化。Ge 等人[12]和Zhai 等人[13]提出采用相互教学的方法,以相互监督的方式生成更加可信且鲁棒的伪标签。Zhang 等人[14]引入了一种基于聚类共识矩阵的标签传播方案,以降低标签噪声,并鼓励连续两次迭代的聚类结果之间保持一致。Cho 等人[15]使用人体全局特征和部分可靠特征之间的互补关系来进行伪标签细化。Wu 等人[16]提出一种多质心存储器,自适应地捕获集群内的不同身份信息,并通过选择适当的正负质心来有效缓解标签噪声问题。Chen 等人[17]提出使用成对相似度得分作为软伪标签,增强实例之间的一致性,从而减轻标签噪声。Lan 等人[18]提出一种噪声标签净化模块,旨在利用教师模型的知识缓解聚类过程中引入的标签噪声。Chen 等人[19]提出一种双聚类协同教学网络,利用两个网络提取的特征,通过不同参数的聚类分别生成两组伪标签,每个网络都采用其对等网络生成的伪标签进行训练,通过增加两个网络的互补性从而减少噪声的影响。
虽然上述方法在缓解伪标签噪声方面已经取得了显著的性能,但主要关注图像对间的相似性或具有复杂的网络架构,未充分考虑不同相机之间的域转移,也忽略了相机风格影响和噪声伪标签这两个问题之间的内在联系。为探索这一问题,Pang 等人[20]提出了一种新的聚类方法(DBSCAN-NN)来缓解类内相机多样性不足的问题,并对特征进行聚类,以提高伪标签的精度。Wang 等人[21]设计了一种动态相机自适应聚类模块来对目标域的全局特征进行分组,通过自适应补偿相机间隙来缩小相机内样本对和相机间样本对之间的特征分布间隙,从而提高伪标签的质量。为了充分利用相机之间的相似性,Li 等人[22]提出一种伪标签细化框架,采用相机内局部聚类结果细化相机间的聚类结果,并采用细化后的可靠伪标签训练模型。与上述方法不同,本文提出了一种伪标签细化引导的相机感知无监督行人重识别方法,重点研究伪标签噪声对相机感知对比学习方法中正负样本选择的干扰,以及如何通过细化伪标签来减轻这种影响,以指导模型的学习过程。本文的主要贡献如下:
1)通过计算特征空间中训练实例之间的相似性,为每个实例确定邻域集合。然后通过将模型对邻域内样本的预测标签与实例原始聚类结果进行加权组合来细化传统的one-hot 伪标签。这种方法不仅鼓励模型将实例靠近其所属的集群中心,还将其与可能包含其身份信息的最近邻样本建立联系。该方法能够有效地提高模型对噪声标签的鲁棒性,同时减轻过拟合的风险。
2)提出采用细化伪标签指导的相机感知对比学习方法。采用细化伪标签动态地关联实例可能属于的集群中心,而不再依赖于单一的集群中心,同时剔除可能存在的假阴性样本,从而降低噪声伪标签对相机感知的误导。
3)将本文方法在三个大规模公开数据集上进行实验验证,结果表明所提方法较基准方法提升明显且优于目前同类先进方法。在Market-1501[23]、MSMT17[24]、Personx[25]数据集上mAP/Rank-1 分别达到了85.2%/94.4%、44.3%/74.1%、88.7%/95.9%。
2 本文方法
2.1 网络整体框架

图1 网络整体框架Fig.1 The overall framework of our method
2.2 最近邻伪标签细化
无监督行人重识别模型的性能高度依赖于聚类结果生成的伪标签,但是在聚类过程中不可避免地出现错误,比如将多个行人的图像合并到一类中,或将一个行人的图像分配到多个类中。使用这些被错误分配的伪标签进行训练,网络很容易对训练数据过拟合并过度适应噪声标签。传统的one-hot 标签更加重了这一问题,因为one-hot 标签仅用元素1 表示所属类别,其他元素都为0,每个类别之间是相互独立的。而无监督本身聚类不准确,one-hot 标签会导致信息的严重丢失,因为它忽略了类别之间的相似性和关联性。但在实际场景中,行人图像可能存在跨类别的共享特征,例如不同行人可能穿着相似的衣服或处于相似的环境中,因此传统的one-hot 标签会导致模型无法充分捕捉这些重要的共享信息,限制了模型的性能。
受到标签传播思想[27]的启发,本文提出了一种基于最近邻细化的伪标签指导网络训练的方法。标签传播通常采用每个数据点与其相邻节点的相似性来分配标签。这种相似性通常是基于特征的相似性计算的,比如欧氏距离、余弦相似度等。不同于传统的onehot 标签,标签传播生成的标签通常为软标签,表示每个数据点属于每个类别的置信度或概率。在本文中,存储在内存字典Mclu中的中心特征与每个类别的语义信息密切相关,它们代表了不同类别的关键特征。将这些中心特征作为分类层的权重矩阵有助于提高模型分类的性能,并降低模型对噪声数据过拟合的风险。为了进行有效的训练,本文使用了交叉熵损失,如式(1):
其中:zi表示分类器对图像xi的特征向量的预测标签,分类器由一个全连接层和一个softmax 函数组成。b表示mini-batch 的大小,ℓ(·)表示交叉熵损失。
为了确定每个样本的邻域,使用余弦相似度来计算样本在特征空间中的两两相似性,如式(2):
其中:vi表 示图像xi的特征向量,‖·‖表示L2 范数。余弦相似度的值越大,表示两个实例在特征空间中的相似性越高。
采用余弦相似度最高的前n个样本作为xi的最近邻。然后,利用这些最近邻样本进行伪标签细化,如式(3):
其中:zj∈N(xi,n)表 示实例xi邻域中的第j个样本的预测标签,1/n表 示每个预测标签zj的权重,α是控制原始伪标签yi和其预测标签之间的插值程度。
如图2 所示,X1,X2和X3三张图像为同一个身份,外观相似的图像Y实际为另一身份。由于外观及视角的相似性,聚类算法错误地将X1和Y分为了一类。这些噪声伪标签造成的错误会在训练过程中不断被放大,阻碍特征的学习。为了有效减轻噪声伪标签的影响,本文在特征空间中采用余弦相似度计算样本之间的相似性,找到X1的 邻域,包括Y,X2,X3三张图像。根据模型给出的邻域内样本的预测标签,利用式(3)对原始的one-hot 标签进行细化,细化伪标签以概率分布的形式呈现了样本属于不同类别的可能性,能够在训练过程中为模型提供更加丰富的类别信息,并指导相机感知对比学习中正负样本的选择。

图2 邻域伪标签细化模块Fig.2 Neighborhood pseudo label refinement module
采用细化伪标签进行交叉熵计算,修改后的交叉熵损失公式为
2.3 细化伪标签引导的相机感知对比学习
为降低不同相机之间视角、光照等因素造成的类内差异,Wang 等人[9]提出相机感知对比学习方法,进一步将聚类后的集群按照相机标签细分为多个子集群,使模型能够更好地捕捉不同相机下的微小特征差异。对于每个图像xi,分别计算相机内和相机间对比损失。相机内对比损失的目标是将xi向同一相机中的正类别中心靠近,同时将其与同一相机中其他类别中心推远。相机间对比损失则考虑了xi与所有相机中的类别中心之间的关系,其目标是将xi向所有相机中的正类别中心靠近,同时将其与在所有相机中挖掘出的困难负类别中心推远。
然而,这种方法易受到伪标签噪声的干扰。由于聚类结果的不准确性,可能会出现以下情况:推开假阴性样本对或者拉近假阳性样本对。如图3(a)所示,橙色标记的圆形实例在聚类阶段被错误地分配到了三角形类别中,原始的相机内对比损失将其靠近类别中心B1、远离类别中心A1,但实际应将其靠近类别中心A1、远离类别中心B1。这种情况会使模型受到严重的误导,混淆相机内不同类别之间的差异性信息。在相机间对比学习中,这一问题会更加严重,如图3(c)所示,橙色标记的圆形实例会被错误地拉近或者推远到多个不正确的类别中心。
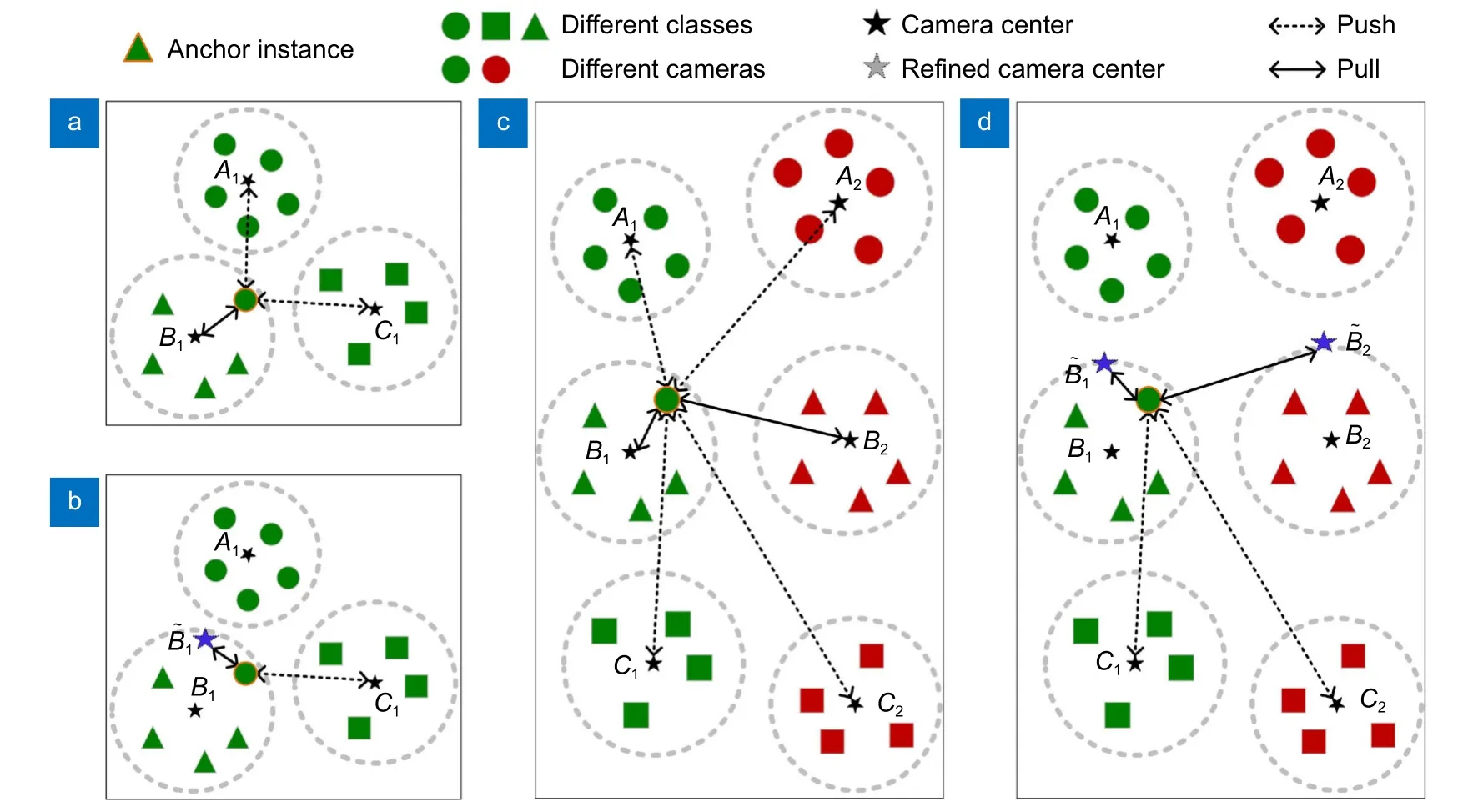
图3 细化伪标签引导相机感知示意图。(a) 原始相机内对比;(b) 校正后相机内对比;(c) 原始相机间对比;(d) 校正后相机间对比Fig.3 Schematic diagram of camera-aware guided by refined pseudo-labels.(a) Original intra-camera contrast;(b) Corrected intra-camera contrast;(c) Original inter-camera contrast;(d) Corrected inter-camera contrast
因此,本文提出了一种细化伪标签引导的相机感知对比损失。具体做法为,首先使用相机标签和伪标签构建相机感知内存字典Mcam∈RC×d,其中C表示所有相机中心的总数,d表示特征维度。以第i个集群为例,具有相机标签j的中心cij计算如式(5):
其中:Hij表示集群i中相机标签为j的实例集合,表示该集合中的实例总数。
然后采用细化伪标签动态地选取实例的正负样本集合,而不再依赖传统的one-hot 噪声标签选取。与实例xi具有相同伪标签的正类别中心计算如式(6):
其中:Si表 示根据细化伪标签中的类别概率选取的xi的前m个相似类的类别中心的集合,cj表 示xi的第j个相似类的类别中心。wj=softmax(top_m(y˜i))表 示xi的第j个相似类类别中心的权重,其中 top_m(y˜i)表示根据xi的细化伪标签得到的前m个相似类的概率,softmax()表示归一化函数。
如图3(b)所示,在相机内对比学习中,橙色标记的圆形实例不再被错误地靠近类别中心B1,而是向平衡后的类别中心靠 近,同时不再远离类别中心A1。计算公式如式(7):
相机间对比学习采用类似的操作,如图3(d)所示,橙色标记的圆形实例不再被错误地靠近类别中心B1和B2,而是向平衡后的类别中心和靠近,同时也不再远离类别中心A1和A2。计算公式如式(8):
平衡后的相机中心对噪声伪标签没有那么敏感,修正了正负样本的选择,有助于提高模型的稳健性。细化伪标签引导的相机感知对比损失公式为
其中,λ是控制相机内和相机间损失平衡的权重参数。
2.4 损失函数
本文方法的整体损失函数是对聚类对比(CC)损失、细化伪标签引导的相机感知(RPG-CAC)损失以及改进后的交叉熵(CE)损失的加权和:
其中,β是控制相机感知对比损失重要性的权重参数。
3 实验结果与分析
3.1 数据集与评价指标
为了评估模型效果,本文使用三个规模行人重识别公开数据集进行了一系列实验,分别是Market-1501、MSMT17、Personx。Market-1501 数据集是在清华大学校园中采集的,包含了来自6 台相机、1501 名行人的32668 张图像。MSMT17 数据集包含了来自15 台相机(3 台室内相机、12 台室外相机)、4101 个行人的126411 张图片。Personx 数据集包含了来自6 个相机、1266 个行人的45792 张图像。
本文采用累计匹配特性(cumulative matching characteristics,CMC)以及平均准确率均值(mean average precision,mAP)作为评价指标。CMC 用于衡量前K幅图像匹配成功的概率,本文采用的是前1 幅、5 幅、10 幅图像匹配成功的概率,分别记为Rank-1、Rank-5、Rank-10。每个查询图像的平均准确率是通过准确率-召回率曲线计算得出的,mAP 则表示所有查询图像平均准确率的均值。
3.2 实验设置
本文进行实验的硬件环境如下:操作系统为Ubuntu16.04,使用2 张NVIDIA 1080TI GPU 显卡,每张显卡拥有12 GB 显存。使用Pytorch 框架搭建整个网络,以在ImageNet[28]上预训练的ResNet50[29]网络作为特征提取的主干网络,但删除了第4 层之后的所有层,然后添加了广义平均池化(generalized mean pooling,GeM)层和使用BNNeck 的全连接层。
在训练过程中,将数据集的图像大小调整为256×128,然后执行了随机水平翻转、像素填充、随机裁剪和随机擦除多项数据增强操作。Batch size 设置为128,每个批次包含16 个伪身份,每个身份包含8 个实例。采用权重衰减为 5×10−4的Adam 优化器更新模型梯度。总共进行50 个epoch 的训练,初始学习率设置为3 .5×10−4,然后每20 个epoch 将学习率缩减为之前的1/10。每个epoch 开始时,使用DBSCAN 算法和基于k-相互近邻的杰卡德距离[30]进行聚类以生成伪标签,并使用与文献[3]相同的参数设置。相机感知InfoNCE 损失中温度系数 τintra、τinter分别设置为0.05、0.07,困难负相机中心数Nneg设置为50。改进后交叉熵损失中邻域大小n设置为7,控制伪标签细化程度的参数α 设置为0.3。损失平衡参数λ、β分别设置为0.6、0.5。以上参数的实验设置分析见3.3.4 节。测试时,仅对图像大小进行调整,并使用GeM 池化层的特征来计算距离。
3.3 实验结果
3.3.1 与最新方法的比较
为了验证本文方法的有效性,本文将实验结果与近几年最新的方法进行了比较,包括UDA 方法和USL 方 法。Market-1501、MSMT17 和Personx 三 个数据集上的比较结果如表1 所示,其中最优结果加粗表示,次优结果加下划线表示,“-”表示原论文中没有该项结果,其中SPCL[3]和MMT[12]方法在Personx数据集上的结果是基线方法CC[4]复现的结果。
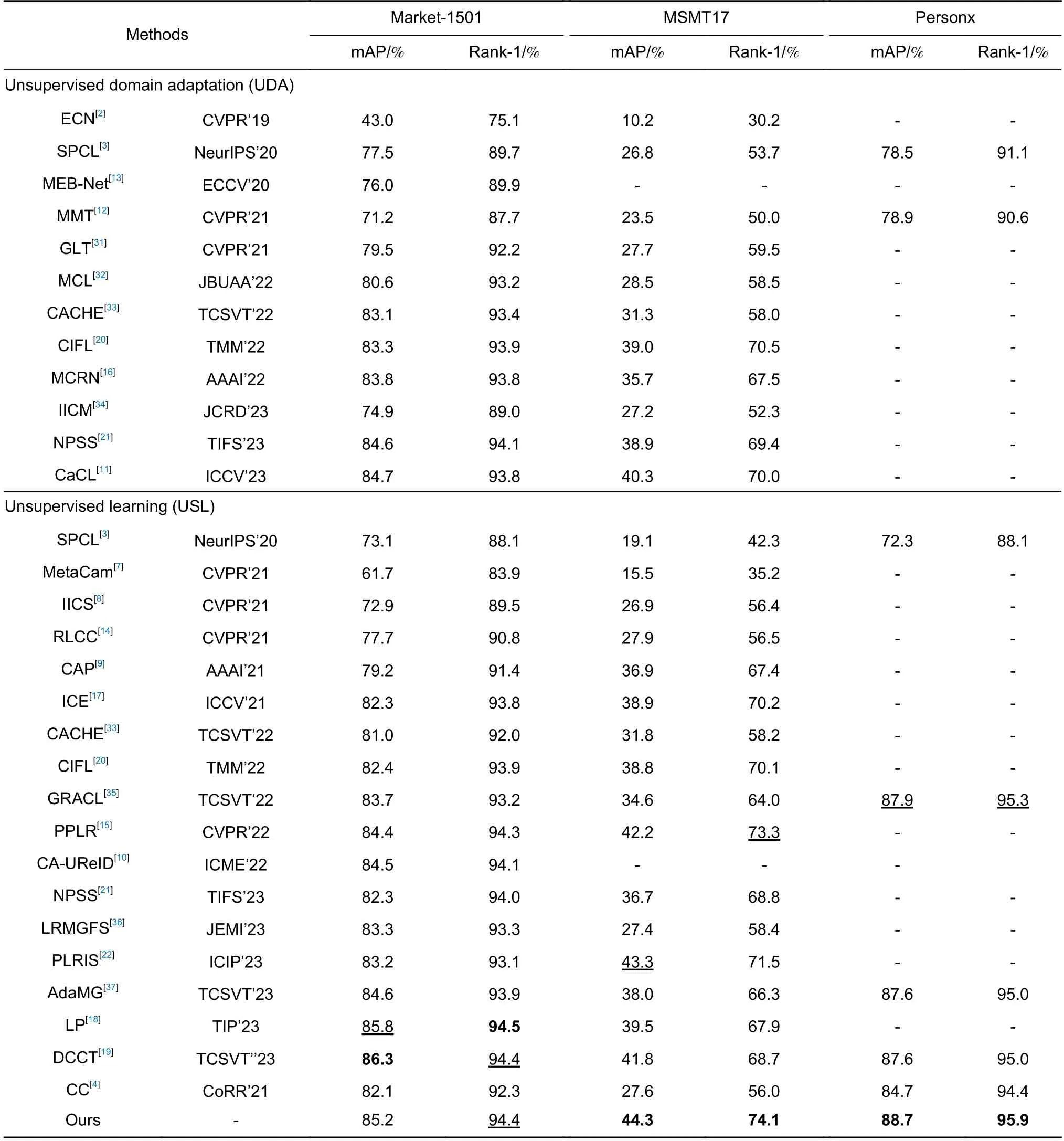
表1 本文方法与最新方法的比较Table 1 The comparison between the our method and the latest methods
如表1 上半部分所示,即使没有使用额外的标记源域数据集,本文方法也在3 个数据集上取得了优越的性能。相较于次优模型CaCL[11],对于mAP 和Rank-1 指标,本文方法在Market-1501 上分别提升了0.5%、0.6%,在MSMT17 上分别提升了4.0%、4.1%。表1 下半部分提到的CC[4]是本文的基线论文,本文使用的参数设置与基线论文存在一些差异,主要是Batch size 的大小、显卡的数量和型号。尽管存在这些差异,本文方法在三个数据集上的性能表现都超过了大部分USL 方法,但在Market-1501 数据集上略低于LP[18]和DCCT[19]方法。Market-1501 数据集中每个身份出现较少相机中且数据集总体规模相对较小,降低了相机差异的挑战性,尽管本文方法着重处理相机间的差异问题,但也因此提升较小。而MSMT17 数据集涵盖了更多的相机视角和环境,其身份更加容易在多个相机中重叠,即同一身份出现在更多的相机中。由于本文着重于处理相机间的差异问题,因此在MSMT17 数据集上取得了更为显著的性能提升,这表明本文方法在处理更具挑战性的场景,尤其是涉及相机视角和环境差异的情况下,具有更强的泛化能力。
与同样专注于解决相机风格影响的MetaCam[7]、IICS[8]、CAP[9]、CA-UReID[10]、CaCL[11]方法相比,本文方法具有明显的优势。与MetaCam[7]相比,本文模型在Market-1501 上mAP 和Rank-1 分别提升了23.5%、10.5%,MSMT17 上mAP 和Rank-1 分别提升了28.8%、38.9%。与模型IICS[8]相比,本文模型在Market-1501 上mAP 和Rank-1 分别提升了12.3%、4.9%,MSMT17 上mAP 和Rank-1 分别提升了17.4%、17.7%。与模型CAP[9]相比,本文模型在Market-1501 上mAP 和Rank-1分别提升了6.0%、3.0%,MSMT17 上mAP 和Rank-1 分别提升了7.4%、6.9%。与模型CA-UReID[10]相比,本文模型在Market-1501上mAP 和Rank-1 分别提升了0.7%、0.3%。与模型CaCL[11]相比,本文模型在Market-1501 上mAP 和Rank-1 分别提升了0.5%、0.6%,MSMT17 上mAP和Rank-1 分别提升了4.0%、4.1%。总体而言,本文所提方法在处理场景复杂的大规模数据集MSMT17上表现出较明显的性能提升,体现了以细化伪标签引导相机感知对比学习在处理相机差异方面的优越性。
与同样进行伪标签细化工作的SPCL[3]、MMT[12]、MEB-Net[13]、RLCC[14]、PPLR[15]、MCRN[16]、ICE[17]、LP[18]、DCCT[19]相比,本文方法性能显著提升。与其中综合泛化性能较好的模型PPLR[15]相比,本文方法在Market-1501 上mAP 和Rank-1 分别提升了0.8%、0.1%,MSMT17 上mAP 和Rank-1 分别提升了2.1%、0.8%。与DCCT[19]相比,本文方法在MSMT17 上mAP 和Rank-1 分别提升了2.5%、5.4%,Personx 上mAP 和Rank-1 分别提升了1.1%、0.9%。
与同时考虑相机影响和伪标签噪声两个问题的方法CIFL[20]、NPSS[21]、PLRIS[22]相比,本文也具有显著的优越性。与PLRIS[22]相比,在Market-1501 上mAP 和Rank-1 分别提升了3.0%、1.3%,MSMT17上mAP 和Rank-1 分别提升了1.0%、2.6%。
3.3.2 消融实验
本文在Market-1501 和Personx 数据集上进行了一系列消融实验,来证明本文网络中各个模块的有效性,实验结果如表2 所示。其中,“M1”表示基线模型CC[4]的结果,“M2”、“M3”、“M4”、“M5”分别表示在基线模型CC[4]上添加本文所提方法中各个模块后的消融实验结果,“M6”表示本文完整方法,即在基线模型CC[4]上同时添加三个损失的结果。将“M6”与“M1”进行对比,可以看出,本文方法相较于基线模型CC[4]表现出显著的性能提升。具体来说,最近邻伪标签细化模块在Market-1501 数据集上将mAP 和Rank-1 分别提升了2.6%、1.9%。这表明最近邻伪标签细化方法成功地减轻了噪声标签的不利影响,有效地提升了模型性能。在Personx 数据集上也将mAP 和Rank-1 分别提升了2.8%、1.1%,证明了该模块的有效性。
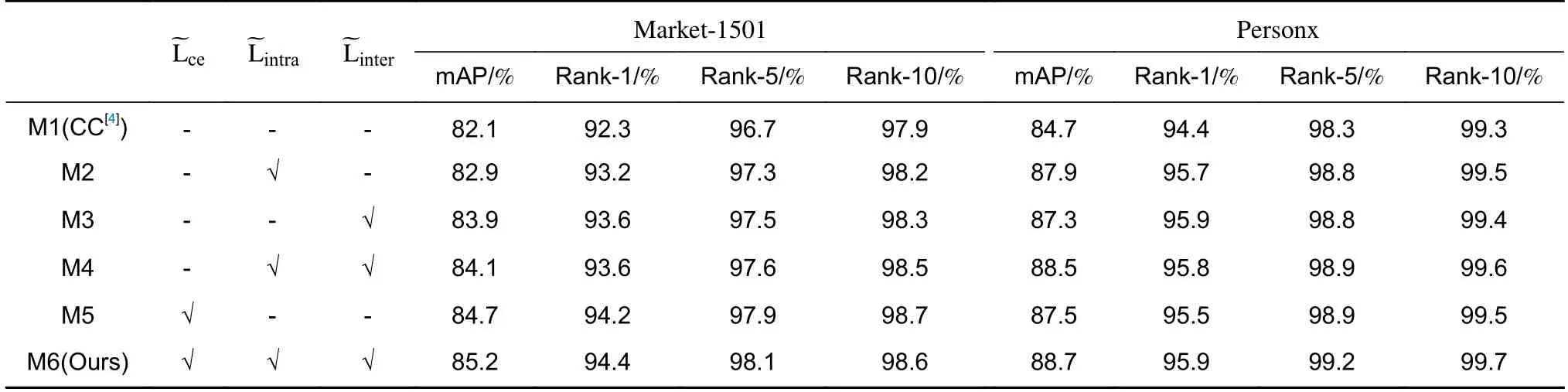
表2 Market-1501 数据集上消融实验结果Table 2 Results of ablation studies on Market-1501
相机内对比学习模块在Market-1501 数据集上将mAP 和Rank-1 分别提升了0.8%、0.9%,在Personx数据集上将mAP 和Rank-1 分别提升了3.2%、1.3%,这证明了相机内对比学习相较于全局对比学习对噪声标签的敏感性较低,因此表现出更好的性能。相机间对比学习模块在Market-1501 数据集上将mAP 和Rank-1 分别提升了1.8%、1.3%,在Personx 数据集上将mAP 和Rank-1 分别提升了2.6%、1.5%,证明了它能够通过充分利用相机间的相关性来改善行人重识别模型,不仅可以使正相机中心更加聚集,从而降低类内方差,还能够使困难负相机中心更加分散,解决了类间行人图像的相似性问题。整体相机感知对比学习模块在Market-1501 数据集上将mAP 和Rank-1分别提升了2.0%、1.3%,在Personx 数据集上将mAP 和Rank-1 分别提升了3.8%、1.4%。
3.3.3 可视化分析
为了更直观地分析本文模型的检索效果,在Market-1501 数据集上进行了Rank-10 可视化排序实验。如图4 所示,随机选择了6 张查询图像,分别在基线模型CC[4]、最相关方法CAP[9]、最先进方法PPLR[15]以及本文模型上进行了可视化实验,其中没有边框的图像代表查询图像,带有绿色边框的图像表示正确匹配的图像,而带有红色边框的图像则表示错误匹配的图像。从图4(a-c)中可以观察到,当不是同一身份的行人具有相似的外观时,基线模型容易发生错误检索,特别是第3、4、6 个查询实例,其模型检索结果绝大部分都是错误的,而本文提出的模型显著地改善了这一情况。如图4(d)所示,本文模型更能有效地区分在视觉上相似的行人图像,从而提升了检索性能,这证明了本文方法的有效性。

图4 不同方法在Market-1501 数据集上Top-10 排序列表的比较。(a) Baseline 方法;(b) CAP[9]方法;(c) PPLR[15]方法;(d) 本文方法Fig.4 Comparison of Top-10 ranking lists between on Market-1501 dataset among different methods.(a) Baseline method;(b) CAP[9] method;(c) PPLR[15] method;(d) Our method
为体现本文方法的有效性,采用T-SNE 方法可视化了基线模型CC[4]、最相关方法CAP[9]、最先进方法PPLR[15]以及本文模型学习到的特征表示。图5 展示了在Market-1501 数据集中随机抽取的10 个行人的图像特征分布图,其中不同颜色表示不同的行人,不同形状表示不同的相机。通过观察图5 可以看出,基线模型CC[4]、CAP[9]方法和PPLR[15]方法均不能很好地区分身份标签为43、62、64、67 的行人,尤其是CAP[9]方法,而本文模型能更好地区分这些身份。此外,对于身份标签为15 和17 的行人,基线模型CC[4]和PPLR[15]很明显地将身份标签为17 号相机标签为5 号的图像错分为15 号,而本文模型则显著地改善了这一情况。这表明本文模型显著提高了类内样本的紧凑性和类间样本的可分性,从而减少了由相机风格差异引起的类内差异。表1 中的实验结果也验证了这一点,完整的本文模型相较于基线模型在Market-1501 数据集上将mAP 和Rank-1 分别提升了3.1%、2.1%,在MSMT17 数据集上将mAP 和Rank-1 分别提升了16.7%、18.1%,在Personx 数据集上将mAP和Rank-1 分别提升了4.0%、1.5%。针对MSMT17数据集这个更加复杂的场景,本文模型提升尤为明显,该数据集涵盖了更多的场景和行人外观变化,表明了本文模型在处理严重类内差异和标签噪声方面的优越性。

图5 不同方法在Market-1501 数据集上特征T-SNE 可视化结果。(a) Baseline 方法;(b) CAP[9]方法;(c) PPLR[15]方法;(d) 本文方法Fig.5 Feature T-SNE visualization results of different methods on Market-1501 dataset.(a) Baseline method;(b) CAP[9] method;(c) PPLR[15] method;(d) Our method
3.3.4 超参数分析
为了深入研究超参数对模型性能的影响,本文在Market-1501 数据集上进行了一系列实验。在仅添加伪标签细化模块的实验设置下,本文观察了在 α的不同取值下,最终标签的来源对模型性能的影响,实验结果如图6(a)所示。当α=0.3时,模型取得较好结果,mAP 为84.7%,Rank-1 为94.2%。这表明合理地结合原始聚类结果得到的伪标签和最近邻的平均预测标签有助于提高模型的性能,伪标签细化的必要性和有效性。此外,本文还研究了邻域大小n对模型性能的影响。实验结果如图6(b)所示,当n=7时模型取得最好的性能。若n过小,模型难以捕捉相邻样本的类别信息;若n过大,则可能会从标签信息中引入更多的干扰。

图6 各超参数在Market-1501 数据集上对本文模型的影响。(a) α ;(b) k ;(c) τintra ;(d)τinterFig.6 The impact of each hyperparameter to our model on Market-1501.(a) α ;(b) k ;(c) τintra ;(d)τinter
在实验中,本文还重点分析了相机感知InfoNCE损失中的温度系数对模型性能的影响。先前的研究Wang 等人[38]提出对比损失函数具有困难负样本自发现的性质,即对于那些已经远离的样本,不再继续将它们推离,而更注重如何使那些靠近但是被错误匹配的困难负样本推离正样本,以使表示空间更加均匀。在这个背景下,温度系数起到了关键的作用,它决定了对比损失对困难负样本的关注程度。温度系数越小,损失越关注与正样本相似但是被错误匹配的困难负样本,从而给予这些困难负样本更大的梯度,将它们与正样本分离。相机域特征空间的偏移导致相机内与相机间匹配的平均成对相似度不一致。具体而言,相机内负样本对比相机间正样本对更容易聚集在一起。在这种情况下,相机内的困难负样本应该受到更多的关注,这也与本文的实验结果相符。实验结果如图6(c)所示,当相机内对比损失的温度系数 τintra取0.05 时,模型表现最佳;如图6(d)所示,当相机间对比损失的温度系数 τinter取0.07 时,模型性能最佳。
4 结论
本文提出了一种伪标签细化引导的相机感知无监督行人重识别方法。该方法首先根据训练实例在特征空间中的相似性,为每个实例确定邻域集合。然后将模型对邻域内样本的预测标签与实例原始聚类结果进行加权组合,以细化传统的one-hot 伪标签。最后采用这些细化后的伪标签指导相机感知对比学习,动态地关联实例可能属于的多个正类别中心,而不再依赖于单一的集群中心,同时过滤可能存在的假阴性样本,从而减少噪声伪标签对相机感知的误导。通过在三个大规模数据集上进行与现有方法的对比实验,证明了本文方法的优越性。
