融合Transfomer和多尺度并行注意的结直肠息肉分割算法
2023-02-18梁礼明何安军朱晨锟
梁礼明,何安军,阳 渊,朱晨锟
(江西理工大学 电气工程与自动化学院,江西 赣州 341000)
0 引言
在各种癌症中,结直肠癌是最常见的恶性肿瘤之一,其发病率和死亡率均位于世界前三[1]。最新发布的数据显示,2020年世界结直肠癌新发病数约为193万,占全部恶性肿瘤的10%,且晚期结直肠癌死亡率高达90%[1]。因此,定期通过结肠镜筛查结肠是预防结直肠癌的有效方法。尽管结肠镜检查被认为是结直肠癌筛查的金标准,但这项检查很大程度取决于内镜医生的工作经验和个人能力,导致息肉检查的漏检率高达14%~30%[2]。因此,在临床环境下设计一种自动准确分割的结直肠息肉算法变得十分重要。
传统的息肉分割方法主要是通过提取颜色、纹理和形状等特征,然后使用分类器来区分息肉和其周围环境。如Gupta等[3]采用一种基于边缘算法,通过检测不同区域的像素值或梯度变化显著的区域,从而分割出目标区域。Vala等[4]提出了一种基于阈值的算法,利用图像灰度值计算一个或多个阈值,并通过比较图像的灰度值与所得阈值,进而从背景中分割出目标区域。然而息肉与周围粘膜之间对比度低,且息肉在大小、颜色和形状上各异,导致传统分割方法分割性能低、泛化性能差、漏检率很高。
近年来,随着深度学习在计算机视觉领域的不断发展,已经被证明明显优于传统机器学习分割方法。比如,Brandao等[5]首先使用全卷积网络(Fully Convolution Network,FCN)和预训练的VGG[6]模型在结肠镜图像中识别和分割息肉,实现了端到端的逐像素分割。Zhou等[7]在原U-Net[8]的基础上添加了一系列嵌套的密集跳跃路径,形成了一个具有深度监督密集连接的编码器解码器网络U-Net++。Jha等[9]提出了ResUNet++,以ResNet[10]作为骨干网络,结合残差块、空洞空间金字塔池化和注意力模块,对息肉分割的部分区域具有很高的准确率,但对边界处理还存在模糊和缺失等问题。Fan等[11]提出了PraNet,使用一个并行解码器来聚合高级特征,然后使用一个反向注意模块来建立区域和边界之间的关系,从而纠正一些错误位置的边界预测。Nguyen等[12]提出了CCBANet利用级联上下文模块来提取局部和全局特征,并提出平衡注意模块来增加对前景、背景和边界区域的注意。尽管上述方法与传统方法相比,息肉分割性能有了较大的提升,但仍然存在一些问题,例如息肉与周围粘膜之间对比度较低的区域分割精度低、分割边界存在伪影、分割图像内部不连续以及错分割和分割不足等问题。
为了解决上述问题,实现更高的边界分割精度,本文提出了一种融合Transfomer和多尺度并行注意网络(Fusion of Transfomer and Multiscale Parallel Attention Networks,FTMPA-Net)的结直肠息肉分割算法,主要包括以下几点工作:① 在跳跃连接处引入多尺度感受场模块(Multiscale Receptive Field Block,RFB)和高效通道注意力机制,以重新加权编码器的特征,增强分割任务的关键特征,同时抑制背景颜色的响应;② 在译码部分采用并行解码模块来聚合不同尺度的特征,有效地将上下文信息进行高效融合;③ 提出了一种新的高效多头注意力机制(Efficient Multi-Head Self-Attention Module,EMHSA),将经过不同模块的深层特征、浅层特征和全局上下文特征相融合,减少各特征之间的语义鸿沟,细化边缘信息,构建局部与全局的联系,提升分割精度。
1 息肉图像基本分割框架
1.1 FTMPA-Net网络结构
由于息肉在形状、大小和位置上有很大的差异性(类内不一致)以及在运动模糊和光反射等条件下,息肉和周围背景具有高度的相似性(类间不一致),为了克服类内不一致和类间不一致,本文以改进的密集网络(HarDNet)作为基本主干,提出了FTMPA-Net,其主要结构包括改进的密集网络、RFB、高效通道注意力机制、并行解码模块和EMHSA。
FTMPA-Net的网络结构如图1所示。首先将数据增强后的图像输入到改进的密集网络编码器中,逐层提取息肉图像的语义信息和空间细节。其次,在编码器和解码器之间的跳跃连接部分引入RFB和高效通道注意力机制,利用不同的感受野去捕捉变化尺寸的待分割目标,进而加强空间和通道相关性信息的表征能力。然后,通过并行解码模块逐层恢复特征,生成初始预测分割结果图用于后续深层监督。最后,利用EMHSA以逐像素点的方式完善边缘结构信息,建立局部与全局的依赖关系,得到最终预测分割结果图。其中,在生成初始预测分割结果和最终预测分割结果前,都先使用1×1的卷积进行特征提取并通道压缩,然后采用8×8的双线性插值上采样操作使其恢复至原始图像大小。
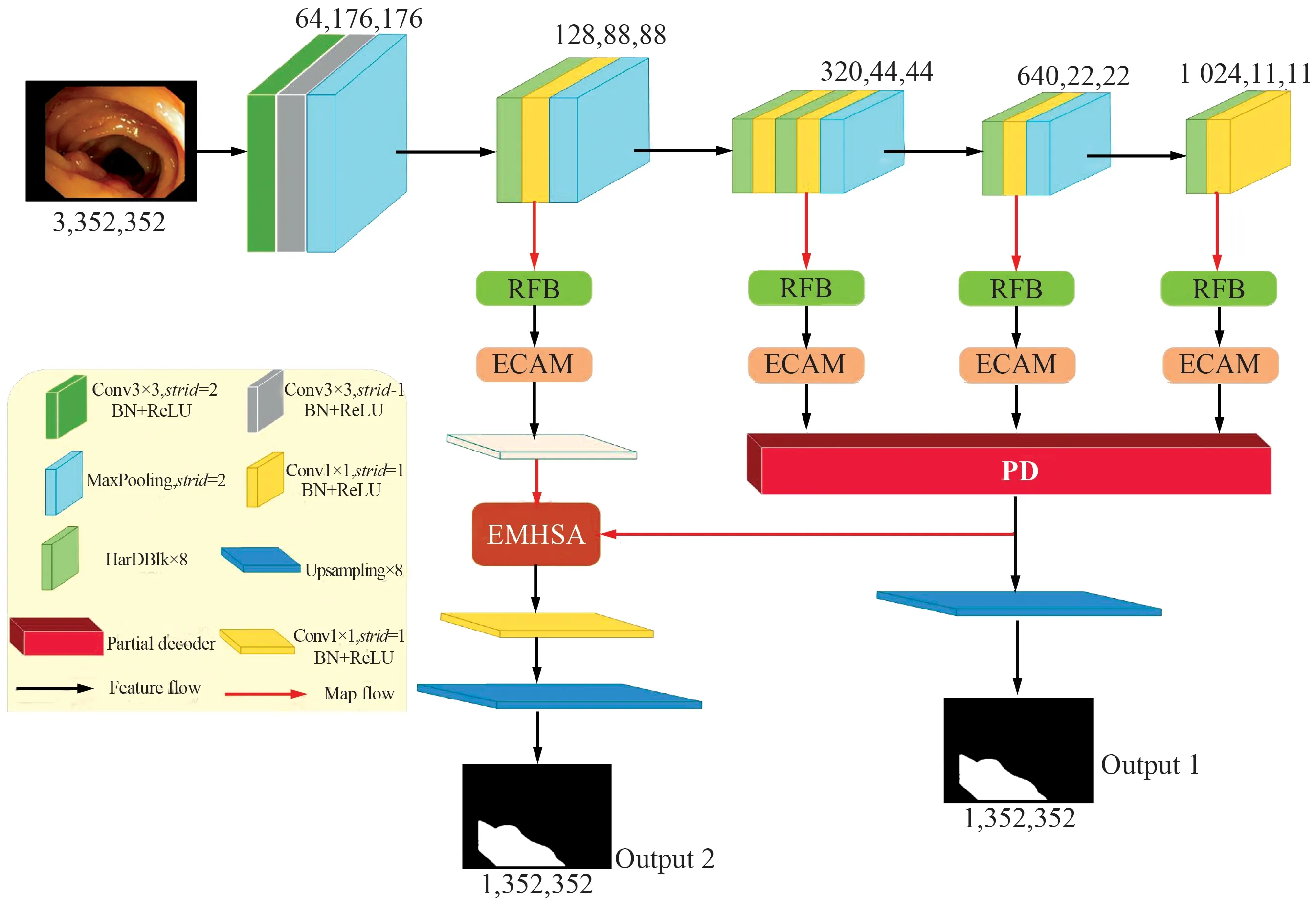
图1 FTMPA-Net网络模型结构Fig.1 FTMPA-Net network model structure
1.2 RFB
由于息肉图像中待分割的目标区域与周围环境具有高度的相似性,单一尺度的特征学习往往忽略了上下文语义信息,不能建立局部与全局的依赖关系,最终影响分割性能。本文使用RFB[13],用不同的感受野来提取目标区域特征信息,并根据目标区域的大小动态分配不同的学习权重,进而提高特征学习的表征能力和构建全局与局部的联系。RFB如图2所示。

图2 RFBFig.2 Multi-scale receptive field block
包含4个并行的分支:第1个分支采用1×1的卷积操作;第2个分支采用堆叠的1×3,3×1和3×3卷积操作;第3个分支采用堆叠的1×5,5×1和3×3卷积操作;第4个分支采用堆叠的1×7,7×1和3×3卷积操作。在每一个3×3和1×1的卷积后面都加入非线性激活函数(ReLU)和一个批量归一化(BN)操作,最终每个分支获得的感受野分别为1,3,5和7。为了保证每条支路特征之间的相关性和完整性,最后将4条支路提取到的多尺度特征进行Concatenate操作。
1.3 高效通道注意力模块
注意力机制是可以嵌套在机器学习算法中的一种轻量级结构,它可以为其感兴趣的区域分配更大的权重,帮助模型重新校准权重的分配。为了捕获空间和通道特征的相关性信息,同时抑制不相关区域的特征激活,本文使用高效通道注意力模块(Efficient Channel Attention Moudle,ECAM),沿着通道维度进行注意,有效地修剪特征响应,增强共性特征激活,使模型能准确地定位待分割区域,提高不同尺度特征的适应能力。ECAM是一个轻量级通用模块,它可以无缝地集成到任何卷积神经网络架构中,而且可以忽略计算开销,并且可以与基本卷积神经网络骨架一起进行端到端训练[14]。
ECAM如图3所示。图中,C为特征图的通道数,H为特征图的高度,W为特征图的宽度。首先,对输入特征图采用全局平均池化(AvgPool)和全局最大池化(MaxPool)操作聚焦特征图的空间信息,得到平均池化特征描述符(FAvgPool)和最大池化特征描述符(FMaxPool)。然后,将这2组特征图输送到一个权重共享的多层感知机网络(Muti-Layer Perceptron,MLP)。多层感知机网络包括了1×1卷积(降维操作,减少计算量)、ReLU激活函数(增加非线性元素)和一个恢复到与输入分辨率相同的升维操作(1×1标准卷积操作实现)。再后,将这2个通道注意力映射图进行和操作。最后,利用Sigmoid激活函数将特征值压缩到0和1之间,获得最终的通道相关矩阵。通道相关矩阵Mc为:

图3 ECAMFig.3 Efficient Channel Attention Moudle
Mc=S{σReLU[MLP(FMaxPool)]+σReLU[MLP(FAvgPool)]},
(1)
式中,S表示Sigmoid激活函数;σReLU表示ReLU激活函数;F为输入特征图;Mc∈RC×1×1。
为了增强通道信息的表征能力,将原始特征图F和经过Sigmoid激活函数获得的通道相关矩阵Mc进行元素乘法,最终获得具有空间和位置信息的高效注意力特征图,其计算式为:
MF=Mc⊙F,
(2)
式中,⊙表示矩阵乘法。
1.4 并行解码模块
现有的分割网络都是编码器解码器结构,比如U-Net,ResUnet和TGA-Net,这种结构通常聚合卷积神经网络中提取的所有多层次特征,这使得模型计算量偏大,严重消耗计算机资源。为了减少计算资源,加快推理速度,本文采用如图4所示的并行部分解码模块(Parallel Decoding Module,PD)[15]。图中,MF5,MF4和MF3为编码器后3个阶段经过RFB和ECAM的输出特征图。PD具体来说主要由2个级联部分组成。第一部分,深层特征重构,首先将高级特征图MF5进行2×2的双线性插值上采样操作使其与特征图MF4具有相同的分辨率,然后通过2个3×3的卷积单元进行特征映射,分别得到F5-1和F5-2,接着将特征映射图F5-1和特征图MF4进行矩阵乘法,并将乘积结果与特征映射图F5-2进行和操作,最后使用3×3的卷积来平滑连接特征,最终得到融合特征图F5-4,其过程计算式如下:
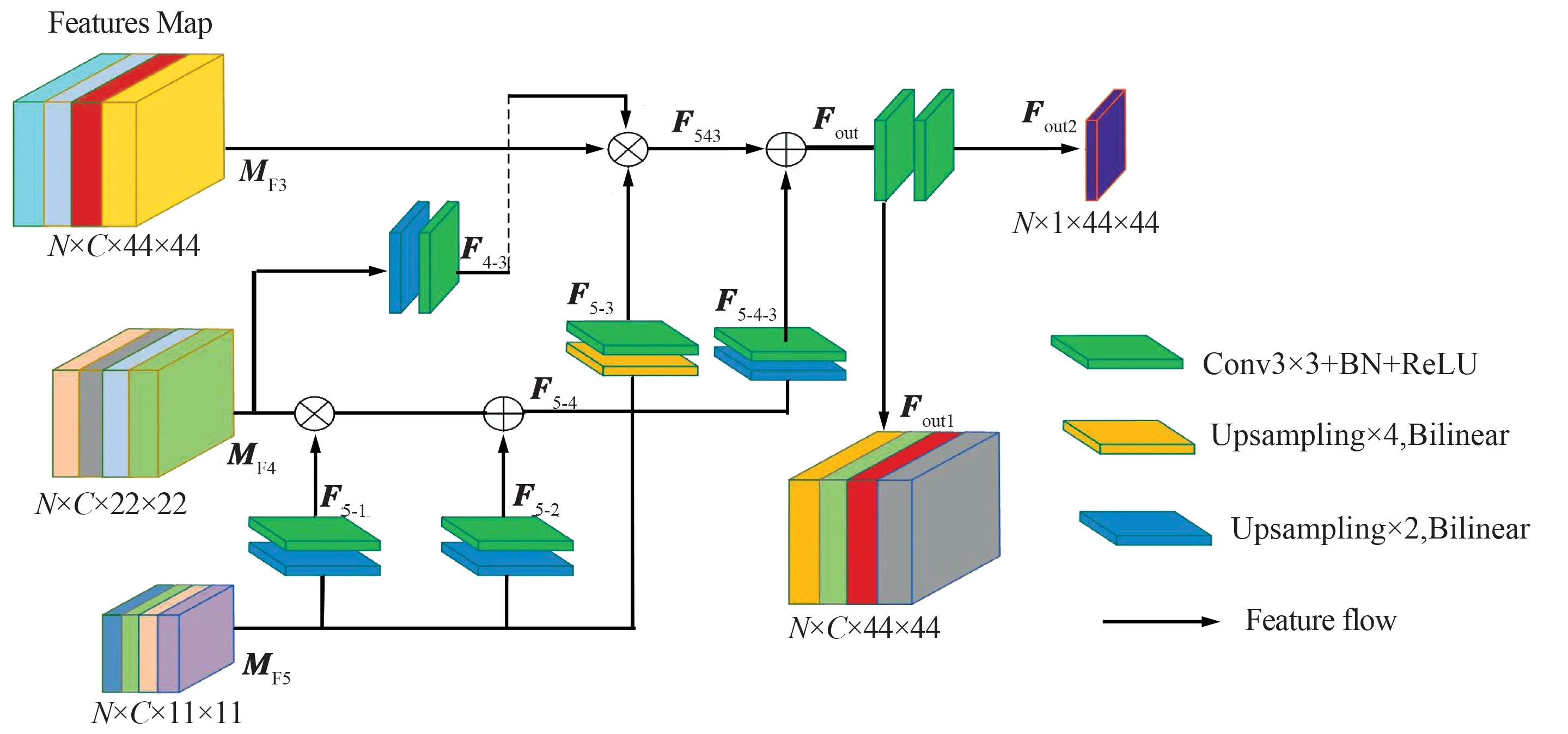
图4 并行解码模块Fig.4 Parallel decoding module
F5-4=Conv{Conv[up1(MF5)]}⊙MF4+Conv[up1(MF5)],
(3)
式中,Conv表示3×3的标准卷积;up1表示2×2的双线性插值上采样;⊙表示矩阵乘法。
第二部分跟第一部分的过程类似。浅层特征与深层特征的高效融合。首先将特征图MF5,MF4,F5-4分别进行上采样操作,使其分辨率与特征图MF3的分辨率相同,并分别利用3×3卷积单元将特征图平滑处理,得到特征映射结果F5-3,F4-3和F5-4-3。然后将平滑处理得到的特征映射结果F5-3,F4-3与特征图MF3三者进行矩阵乘法,得到F543,接着将映射结果F543和平滑处理得到的特征图F5-4-3进行相加,最后将累加得到的特征映射结果依次经过2个3×3的卷积进行降维操作。该操作一方面用于生成初始预测结果,另一方面用于后续边界监督。该过程计算式如下:
Fout=Conv{Conv[up2(MF5)]⊙Conv[up1(MF4)]⊙
MF3}+Conv[up1(F5-4)],
(4)
式中,Conv表示3×3卷积;up1表示2×2的双线性插值上采样;up2表示4×4的双线性插值上采样;⊙表示矩阵乘法。
1.5 EMHSA
由于图像是高度结构化的数据,在局部高分辨率特征图中大多数像素除了边界区域外都具有相似的特征。因此,在所有像素之间成对注意计算是非常低效和冗余的。从理论角度来看,长序列自我注意本质上是低秩的,这表明大部分信息集中在最大奇异值上。受这一发现以及文献[16-17]的启发,提出了EMHSA以高级位置信息作为边界监督,逐步细化边缘信息,从不同的维度上建构区域与边界之间的关系。
EMHSA如图5所示,其中Fout1和MF2分别是并行解码模块的输出特征图和编码第二阶段经过ECAM的输出特征图,C为特征图的通道数,H为特征图的高度,W为特征图的宽度。首先,将输入特征图Fout1和MF2分别采用1×1的标准卷积进行投影映射得到3个特征向量Q,K,V。为了减少计算量,加快收敛速度,采用双线性插值下采样操作对特征向量K,V进行空间尺寸收缩,其中收缩尺寸大小为8×8。其次,为了获得绝对的上下文语义信息以及添加相对应的高度和宽度信息,本文使用二维相对位置进行位置编码。假设像素i=(ix,iy),像素j=(jx,jy),则i,j之间的相对位置编码计算式为:

图5 EMHSAFig.5 Efficient multi-head self-attention module
(5)
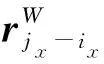
为了将位置编码信息嵌入到高级语义信息特征图中,首先将特征向量Q与含位置编码信息特征图T进行矩阵乘法,并与特征向量Q和降维后的映射键矩阵K′相乘的结果进行矩阵加法,得到对应的计算权重值,然后通过Softmax函数将权重值自适应归一化,在把归一化得到的结果沿着降维键矩阵V′的方向进行加权求和,从而得到EMHSA的输出,计算式为:
(6)
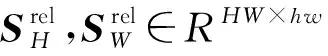
2 实验结果分析与讨论
2.1 数据集及预处理
为了验证本文算法的有效性,实验采用了CVC-ClinicDB[18]数据集和Kvasir-SEG[19]数据集。CVC-ClinicDB数据集为2015年由医学图像与计算机辅助国际会议发布的公开数据集;Kvasir-SEG数据集于2020年用于计算机辅助胃肠道疾病检测。各个数据集的细节如表1所示,为了方便模型的训练和测试,将CVC-ClinicDB数据集和Kvasir-SEG数据集的图像统一裁剪成352 pixel×352 pixel。根据文献[20],将CVC-ClinicDB数据集和Kvasir-SEG数据集按照8∶1∶1划分为训练集、验证集和测试集3个部分,为了让模型能学习到某些细微的特征,在进行模型训练之前本文对这2个数据集的原始图像以及对应标签都同时进行数据归一化操作。

表1 数据集细节描述Tab.1 Detailed description of datasets
2.2 实验设置
本文实验环境基于开源的PyTorch框架,所有实验都是在Ubuntu16.04操作系统Inter Core i7-6700H CPU 16 GB内存上进行,显卡为NVIDA GeForce GTX2070 GPU 8 GB。在模型训练过程中采用的网络损失函数是加权交并比(IoU)损失和加权二值交叉熵(BCE)损失之和,Adam优化器,批量处理大小设置为12,网络迭代次数epoch设置为60,学习率设置为0.000 1。
2.3 评估指标
为了评估本文算法的分割性能,采用医学领域上常用的5个性能指标来对模型分割结果的准确性进行定量分析。
① 平均交并比(MIoU):指模型预测分割结果与金标准分割图像的重叠范围来度量被检测图像的准确度,最后对每一个类别取平均值,计算式为:
(7)
② 平均相似性系数(Mean Dice Similariy Coefficient,MDice):用于评估网络模型分割结果与金标准图像之间的相似度,计算式为:
(8)
③ 精确度(Precision):其含义是在实际为正的样本中被预测为正样本的概率,计算式为:
(9)
④ 召回率(Recall):其含义是在被所有预测为正的样本中实际为正样本的概率,计算式为:
(10)
⑤ 平均绝对误差(MAE):逐像素比较指标,表示模型预测值与真实值之间绝对误差的平均值,计算式为:
(11)
式中,TP表示正例被正确判断成正例的样本数;FN表示正例被错误判断成负例的样本数;TN表示负例被正确判断成负例的样本数;FP表示负例被错误判断成正例的样本数;GT为专家标注标签;SR为网络分割结果。
2.4 实验结果分析
为了评估本文提出的FTMPA-Net算法的性能,在CVC-ClinicDB和Kvasir-SEG数据集上将本文算法对息肉图像分割结果分别与Unet,Unet++,PraNet,ColonSegNet[21]和DDA-Net[22]算法对肠息肉的分割结果进行了对比,最终得到的性能指标对比结果如表2所示,其中加粗表示此项为最优值。从表2中的结果可以看出,本文提出的FTMPA-Net分割算法的MDice, MIoU, Recall, Precision和MAE五项指标均取得了最优的结果,在CVC-ClinicDB数据集上,这5项指标分别达到了95.58%,91.70%,95.86%,95.52%和0.007 2,比经典U-Net网络的分割结果分别提高了4.41%,6.45%,4.16%,2.99%和降低了0.008 2。与先进CologSegNet网络相比,在MDice和MIoU上分别提高了3.62%和4.65%。在Kvasir-SEG数据集上,这5项指标分别达到了92.34%,86.77%,95.01%,91.29%和0.021 8。比经典PraNet网络在MDice, MIoU, Recall, Precision上分别提高了1.41%,1.56%,1.27%和0.74%。实验结果表明,本文算法能有效地提升息肉分割精度,可以进一步提升医生诊断的效率和准确率,减少医生的误诊率。

表2 数据集CVC-ClinicDB和Kvasir-SEG在不同算法下的实验对比数据Tab.2 Experimental comparison of datasets CVC-ClinicDB and Kvasir-SEG under different algorithms
图6和图7分别给出了本文算法与其他分割算法在CVC-ClinicDB数据集和Kvasir-SEG数据集上的分割结果对比。其中,图6和图7中的(a)~(h)分别对应的是原图、真实标签、U-Net、U-Net++、ColonSegNet、DDA-Net、PraNet和本文算法的分割结果图。图6中第1幅和图7中第1幅图存在息肉和周围黏膜对比度低的现象,U-Net,U-Net++,ColonSegNet,DDA-Net和PraNet的分割结果出现了明显的错分割和漏分割情况,而FTMPA-Net可以捕获更多的空间细节特征,高效精准定位息肉,从而使分割结果更能接近金标签。图6中第2幅和第3幅图像存在局部过度曝光的情况,U-Net,U-Net++和ColonSegNet抑制背景颜色干扰能力较差以及精准定位息肉能力较弱,导致分割结果依然存在错分割和漏分割的现象。DDA-Net和PraNet能有效地抑制干扰因素,但是在局部过度曝光区域边界出现了伪影以及漏分割的情况。FTMPA-Net可以构建全局与局部的联系,细化边缘特征,使分割结果在边界处能平滑连接。图7中第2幅和第3幅图息肉附近的背景颜色与待分割的息肉颜色几乎一致,背景颜色的干扰容易导致息肉定位不准确,同时也影响息肉边界分割,使目标区域难以区分。FTMPA-Net丰富的特征提取和强大的边界处理能力使其在具有极致颜色干扰的背景时也能有效地精准定位息肉,也能在边界处平滑分割,减少漏分割和错分割的现象,而其他算法不同程度地出现了分割结果内部不连贯、分割边界模糊、漏分割和错分割问题,从而进一步说明本文算法的优越性和鲁棒性。
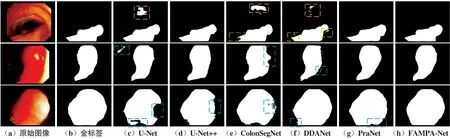
图6 CVC-ClinicDB数据集分割结果Fig.6 Segmentation results of CVC-ClinicDB dataset

图7 Kvasir-SEG数据集分割结果Fig.7 Segmentation results of Kvasir-SEG dataset
2.5 与其他先进算法对比
为了进一步验证本文算法的分割性能,表3给出了不同的息肉分割方法在Kvasir-SEG数据集的MIou, MDice, Recall和Precision值,数据来自2017—2022年相关文献,加粗表示此项为最优值。
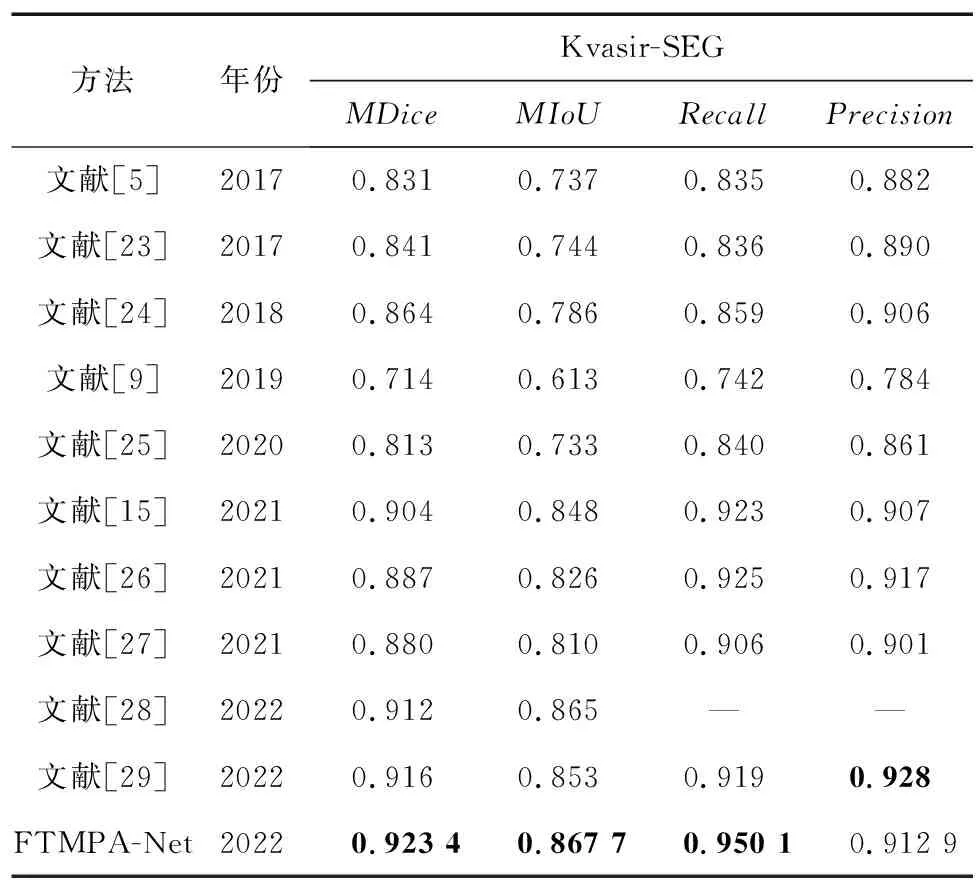
表3 Kvasir-SEG数据集算法对比Tab.3 Comparison of algorithm indexes in Kvasir-SEG dataset
从表3可知,现有的息肉分割算法在Kvasir-SEG数据集上的MIoU, MDice, Recall均低于本文算法,进而说明本文算法可以更好地定位息肉位置,细化边缘信息,减少分割结果图像中内部不连贯、错分割和分割不足问题。文献[15]采用编码器解码器结构,在跳跃连接处引入多尺度感受块来减少编码与译码之间的语义鸿沟问题,利用级联解码结构来恢复更多的空间细节,但该算法并没有充分利用浅层特征,导致解码部分提取特征能力不足,在Kvasir-SEG数据集上指标明显低于本文算法。文献[29]以ResNet50作为编码器,在跳跃连接处采用一种混合通道空间注意模块对编码器提取的特征进行重新加权,在译码部分采用全局上下文金字塔特征提取模块来捕获多尺度接受阈的特征信息。最后利用特征融合模块,融合高级信息、低级信息和全局上下文信息,来减少语义差异,完善边缘细节,提高分割精度。在Kvasir-SEG数据集上精确度最高,比本文算法高了1.51%,而MIoU, MDice和Recall均比本文低1.47%,0.74%和3.11%。文献[25]使用2个U型结构的网络,在网络中增加了SE模块[30]来进一步增强对通道和空间信息的依赖性,同时在译码和解码之间的底部采用ASPP模块来提取多尺度信息,能很好地定位息肉,减少分割结果内部不连贯问题,获得较好的分割性能,而本文算法在对比的4项指标上均高于文献[25],进一步说明本文算法的优越性和准确性。
2.6 消融实验
为了验证实验中每个模块的有效性,并研究其在息肉分割上的实用性,本文使用控制变量方法在CVC-ClinicDB数据集上进行了消融实验。FTMPA-Net1以密集型网络为主干,在编码器和解码器之间的跳跃连接部分加入RFB和ECAM,解码部分采用并行解码模块来聚合多尺度信息。FTMPA-Net2在FTMPA-Net1的基础上将解码部分中的并行解码模块替换成EMHSA。FTMPA-Net3和FTMPA-Net4与最终模型FTMPA-Net的区别在于跳跃连接处是否引入RFB和ECAM。定量消融分析结果如表4所示,展示了每个模块对息肉分割精度的影响,其中加粗表示此项为最优值。从表4可以看出,FTMPA-Net1和FTMPA-Net的MDice分别为93.76%和95.58%,MIoU分别为89.44%和91.70%,明显提高算法的MDice和MIoU,说明EMHSA模块能进一步细化边缘信息,构建局部与全局的联系。FTMPA-Net2在FTMPA-Net的基础上去掉了PD,使得MDice和MIoU下降了1.3%和1.96%,从侧面反映PD模块能有效地融合多尺度上下文信息,增强通道和空间特征的表征能力。FTMPA-Net3和FTMPA-Net4在FTMPA-Net的基础上去掉了RFB和ECAM,实验结果表明RFB能利用不同的感受野去适应的不同大小的分割目标,ECAM能提高各特征之间的空间细节联系,抑制背景颜色特征的响应,使得MDice, MIoU和Recall分别提高了0.64%和0.66%,0.55%和0.52%,0.08%和0.73%。本文算法在并行解码模块的基础上加入了EMHSA,在提高交并比的同时能权衡召回率和精确度。

表4 CVC-ClinicDB数据集消融指标对比Tab.4 Comparison of ablation metrics in CVC-ClinicDB dataset
消融结果对比实验分割图如图8所示。从图8中可以看出,EMHSA能细化边缘信息,建立局部与全局的关系。对比图8(c)和图8(d)的分割结果,图8(c)分割效果精度更高,边缘细节更加清晰,然而图8(d)的分割结果中出现了伪影、错分割和分割不足现象。高效通道注意力机制,能有效地修剪特征响应,增强共性特征激活,使模型能准确地定位待分割区域,提高不同尺度特征的适应能力。对比图8(c)和图8(e)的分割结果,图8(e)的分割结果中出现了内部不连贯问题,分割边界出现错分,而图8(c)能更好地表征通道维度的信息,区分背景与前景,使其分割结果与真实标签更接近。并行解码模块,能聚合多层次语义信息,减少各特征信息之间的语义差异。对比图8(c)和图8(f)分割结果,图8(c)有更好的边缘特征、更多的细节信息,没有出现分割结果不连续问题。RFB利用不同的感受野去学习不同大小的待分割目标,使其保留更多的空间细节,增强有效信息的权重。对比图8(c)和图8(g)的分割结果,图8(g)的分割结果中边缘细节分割不准确,出现了少部分错分割和漏分割的问题。综合上述分析,最终FTMPA-Net在分割结果边界处与金标签更为接近,且在分割结果边界外部不存在图像伪影和图像内部不连贯问题。

图8 CVC-ClinicDB数据集消融结果对比Fig.8 Comparison of ablation results in CVC-ClinicDB dataset
3 结束语
针对结直肠息肉精细分割,提出了一种端到端的医学图像分割算法FTMPA-Net,引入了4个功能模块来解决结直肠息肉分割结果精度低、存在伪影、错分割和分割不足问题。其中,RFB和ECAM能提取更多的细节特征信息,并建立各信息之间的长期依赖关系,同时有效地抑制背景颜色的响应,提高网络的性能。PD通过逐层聚合由高效通道注意力机制得到增强特征图,使各层次之间的特征信息进行有效交互,减少语义差异,最终生成初始预测分割图,用于后续深层监督。其次,提出的EMHSA去融合高级语义信息和多尺度语义信息,以解决目标肠息肉尺寸大小不一和边界分割模糊问题,进一步细化边缘特征,使分割边界处能平滑连接。在CVC-ClinicDB数据集和Kvasir数据集上评估FTMPA-Net算法的分割性能。实验结果表明,本文算法的整体分割性能均优于目前先进分割算法,具有重要的临床参考价值。
