基于特征增强的快速红外目标检测
2023-02-18郭勇,张凯
郭 勇,张 凯
(1.福建信息职业技术学院 物联网与人工智能学院,福建 福州 350003; 2.厦门大学 信息学院,福建 厦门 361005)
0 引言
红外探测系统利用物体热辐射收集目标信息,具有隐蔽性好、抗干扰能力强和受气候、光线、烟雾影响小等特点,已广泛应用于军事侦察、视频监控和伪装防护等领域[1]。目标检测作为红外探测系统的核心技术,主要完成目标定位与分类,受到国内外研究人员的深度关注。
近年来,基于卷积神经网络的深度学习目标检测算法在性能上取得了巨大突破。以深度学习为基础,文献[2-6]将卷积神经网络的思想引入红外目标检测,探索出了一系列高效准确的检测算法。但此类方法主要集中于以复杂的模型结构来提高目标检测精度,忽略了检测速度的重要性。当前,红外系统逐渐小型化,常被搭载于无人驾驶汽车、无人机等智能设备上完成探测任务,对检测精度和速度均提出了较高要求,因此在硬件资源有限的条件下,实现检测精度与速度的最佳均衡是一项实践意义重大的研究工作。
基于以上分析,结合实际红外应用场景特点,本文设计了基于特征增强的红外目标检测(Infrared Object Detection based on Feature Enhanced YOLO,FEID-YOLO)模型。FEID-YOLO属于轻量级快速检测模型,以YOLOv3[7]为基础框架,利用ResVGG-5主干网络替代原来的DarkNet53,降低模型计算量和提升检测速度的同时,提取输入图像不同层次的特征,在此基础上通过阶梯式特征融合技术获取鲁棒和完备的预测特征图,为末端目标预测提供有力支撑。在训练阶段,通过多尺度训练和数据增强提升模型对复杂背景和不同尺度目标的适应能力。在FLIR ADAS红外数据集上的实验结果表明,FEID-YOLO模型的检测精度可达57.31% mAP,且保持了每秒检测帧数(Frames per Second,FPS)68.93的检测速度,为模型在小型系统端的部署打下了基础。
1 红外图像特性分析
目前,基于深度学习的目标检测算法大多始于可见光领域,若要将其高效引入红外图像领域,对比可见光图像与红外图像特性,并依此构建适合红外场景的目标检测模型十分重要。相较于可见光图像,红外图像的质量较低且目标特征有限,导致红外目标的探测灵敏度、对比度和分辨率较低[8]。如果将在可见光领域中表现优异的深度学习检测模型直接用于红外图像目标检测,势必会导致性能急剧下降。因此,分析红外图像与可见光图像特性,针对二者差异辅以特殊的特征处理手段是增强红外目标检测系统性能的有力措施。
不同场景下配准好的可见光与红外图像如图1所示。通过对比可见光与红外的原图像可以看出,可见光图像中包含丰富的场景细节信息,且各类目标(车辆、行人和飞机)的几何轮廓完整、纹理细节丰富、颜色多样,易于检测识别。反观红外图像,不仅场景模糊、信噪比低、分辨率差,而且所包含目标的细节特征较弱、几何结构缺失严重(如图1 场景B红外图像中的飞机),导致红外目标可利用的特征较少。由可见光与红外图像的三维分布图可以看出,低温目标(如图1场景A中的车辆)在可见光图像中更加突显,而高温目标(如行人和飞机尾翼部分)在红外图像中更加突显,因此如何提取高鲁棒性的目标特征是提升红外多目标检测性能的关键。分析二者的直方图可以看出,相较于可见光图像,红外图像的对比度更低,且其灰度分布与目标反射特性无线性关系,这无疑增加了目标检测的难度。
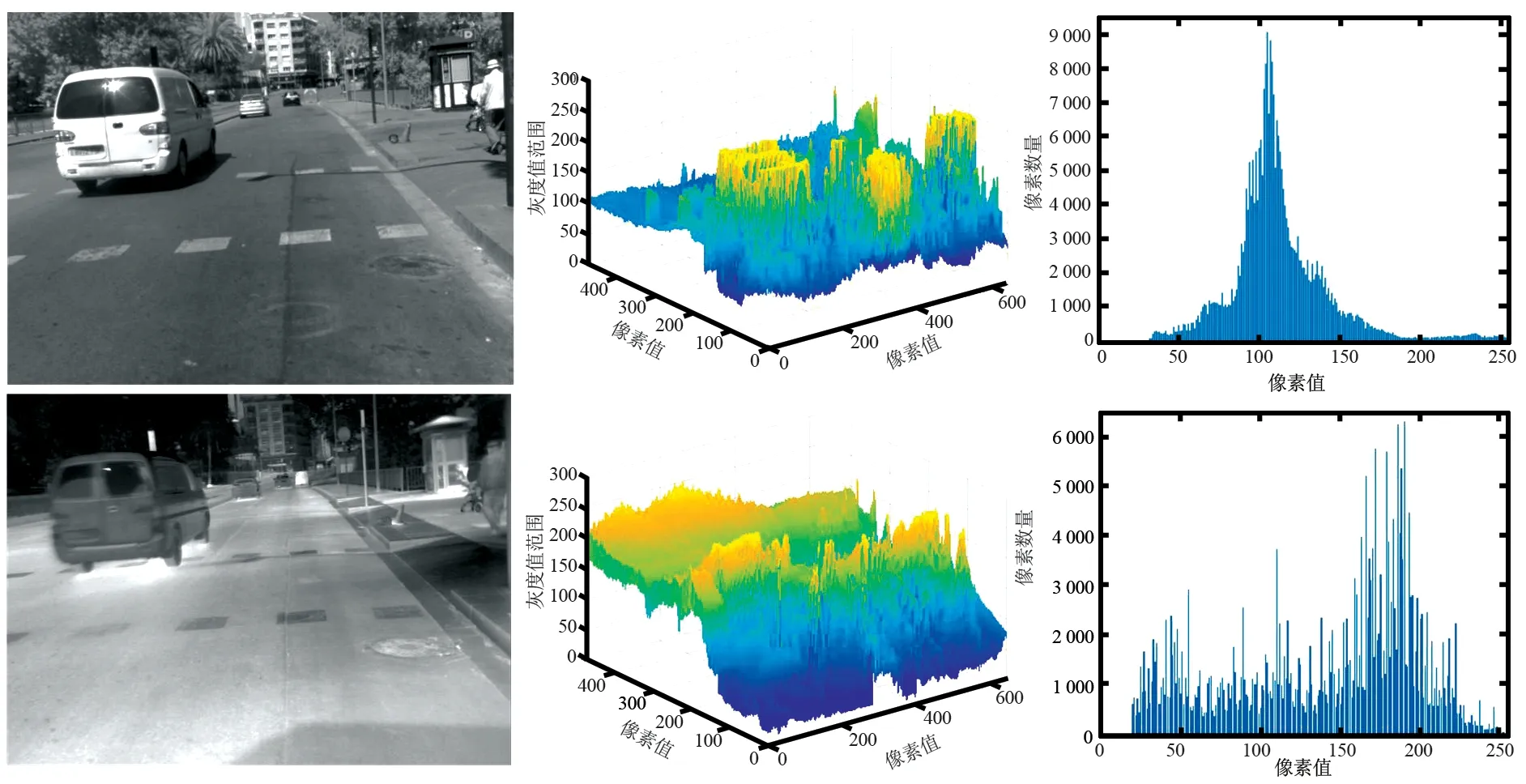
(a) 场景A可见光图像与红外图像对比

(b) 场景B可见光图像与红外图像对比图1 不同场景下的可见光图像(子图左上)、红外图像(子图左下)及其三维分布图(子图中)和直方图(子图右)Fig.1 Visible images (upper left of sub-images), infrared images (lower left of sub-images) and 3D distribution maps (middle of sub-images) and histograms (right of sub-images) under different scenes
红外图像的特性使得主流的目标检测模型在应用于红外场景时表现不佳,而实时目标检测将更具挑战性。分析红外图像特性可知,红外目标主要呈现出几何结构缺失、纹理细节不佳和像素强度分布较广等特点。因此,构建的检测模型必须具备鲁棒且完备的目标特征提取能力,才能满足后端的分类与定位需求。
2 FEID-YOLO目标检测模型
基于前期分析,本文提出了FEID-YOLO红外目标检测模型,主要由3部分组成:输入端、特征提取网络和目标预测网络,其结构如图2所示。输入端利用多尺度训练和数据增强技术提高网络训练效率;特征提取网络完成不同层次的特征提取;目标预测网络首先对特征进行融合,而后输入YOLO检测层完成目标分类和定位。

图2 FEID-YOLO目标检测网络Fig.2 FEID-YOLO object detection network
2.1 输入端设置
输入图像的尺寸对检测模型的精度影响相当明显,而多尺度训练是提升检测精度最有效的方法之一[9]。在特征提取网络中,随着网络层的加深,原始图像往往会被下采样数十倍,导致小尺寸目标在特征图中的响应有限,从而不易被检测器捕获。在训练过程中,通过输入更大、更多尺寸的图像,不仅能够增大小尺寸目标的特征响应,还能够在一定程度上提高检测模型对目标尺度的鲁棒性。因此,在训练阶段FEID-YOLO每迭代10轮,即从{384,416,448,480,512,544,576,608}中随机选择一个新的数值作为下个10轮的图像输入尺寸。
为了提升检测模型的泛化能力,在训练阶段FEID-YOLO还引入了Mosaic[10]和PuzzleMix[11]两种数据增强技术。Mosaic数据增强通过随机缩放、随机裁剪和随机排布的方式将4幅图像拼接成一幅图像作为新的训练数据,不仅丰富了图像背景,并且变相提高了训练过程中的批量大小(Bach_size),节省了计算资源,整个过程如图3所示。PuzzleMix数据增强首先随机选择2幅图像并计算显著性区域,通过裁剪出其中一幅图像的显著性区域并将其与另一幅图像按比例相加混合,再经精细优化后构建出新的训练数据,整个过程如图4所示。由于PuzzleMix加入了显著性分析,因此避免了裁剪块来源于原始图像的非重要区域或者目标图像的重要区域被裁剪块遮挡等问题,保证了新生样本的有效性,提升了训练效率。

图3 Mosaic数据增强Fig.3 Data augment by Mosaic

图4 PuzzleMix数据增强Fig.4 Data augment by PuzzleMix
2.2 特征提取网络
特征提取网络作为检测模型的主要组成部分,通常包含较深的网络层数,以此来提升模型的拟合能力,进而提取输入图像不同层次的特征图[12]。但是随着网络的加深,其计算量也愈发庞大,进而影响检测速度。因此对于实时目标检测模型,在保证一定检测精度的前提下减少网络深度、降低计算量是特征提取网络设计的关键。
基于以上分析,设计了一个轻量级特征提取网络ResVGG-5,其是在VGG[13]基础上改进的5层卷积结构。ResVGG-5相当于将ResNet[14]中的精华思想应用到了VGG中,即在VGG网络中加入了恒等映射(Identity)和卷积核为1×1的卷积(Conv 1×1)残差分支,三者的比较如图5所示。待检测图像输入ResVGG-5后,共经历5个阶段的处理,每一阶段由卷积和残差以不同的结合方式组建,输出特征图的尺寸为输入的1/2,同时为了保留更多的特征信息,其通道数增加一倍。
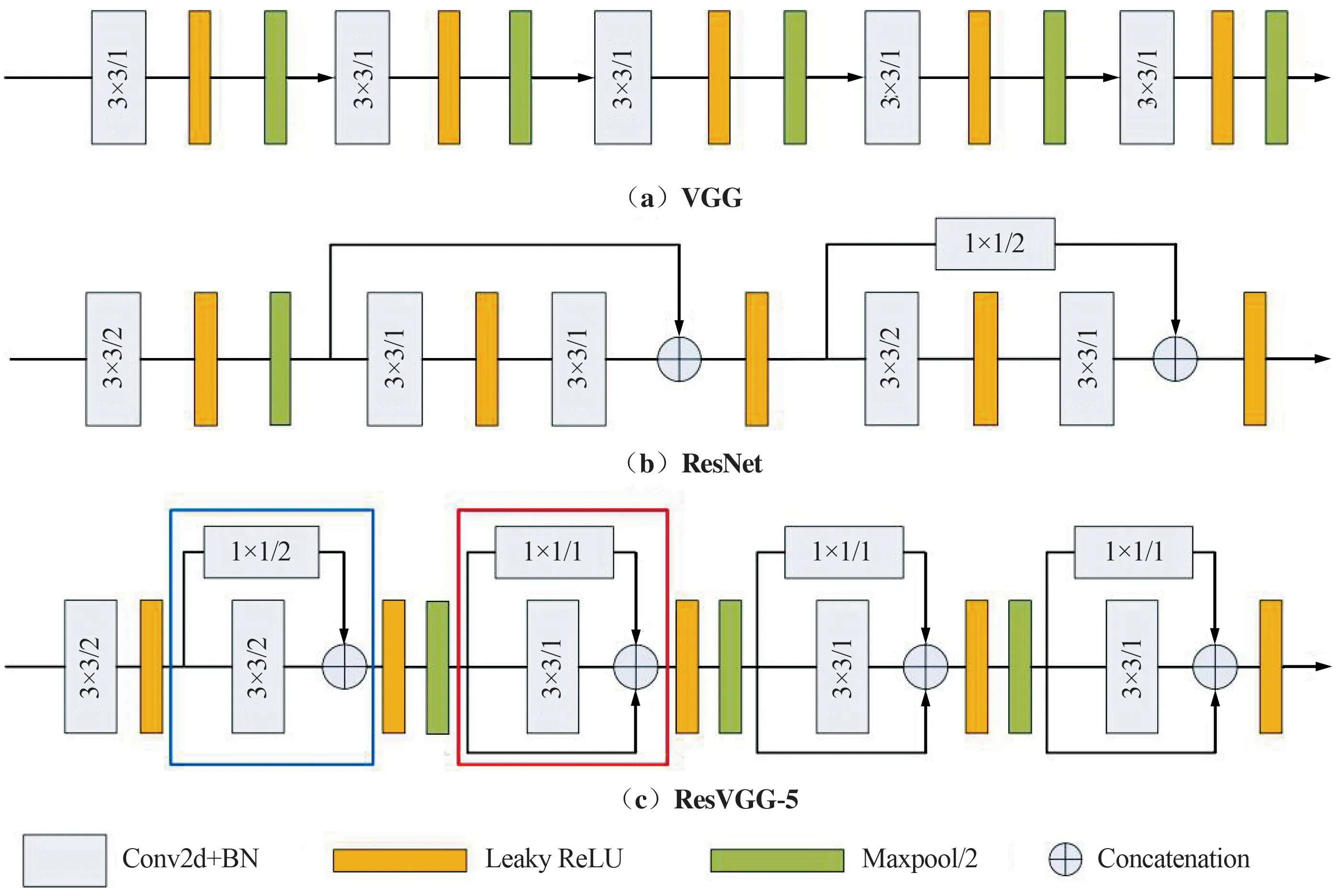
图5 VGG,ResNet和ResVGG-5结构Fig.5 The structures of VGG, ResNet and ResVGG-5
VGG在各特征提取阶段均采用卷积核为3的卷积操作(Conv 3×3)提取图像特征,Conv 3×3利于硬件部署和节省计算资源。ResNet在不同的特征提取阶段分别引入了Identity和Conv 1×1两种残差块,不仅解决了梯度消失问题,而且增强了特征重用和特征图的完备性。相较于ResNet,ResVGG-5的残差块并没有跨层,且整个网络包含2种残差结构,如图5(c)中的蓝框和红框所示,蓝框中的残差结构仅仅包含Conv 1×1残差分支,红框中不仅包含Conv 1×1残差分支还加入了Identity残差分支。多分支的残差结构相当于给网络增加了多条梯度流动路径,训练一个这样的网络,类似于训练了多个网络,并将多个网络融于一体,有利于提取更深层次、更加鲁棒的特征表达。
2.3 目标预测网络
在实际工程应用中,红外系统探测的目标尺寸通常分布比较广[15]。如果仅依据特征提取网络的最高层特征图来预测目标,虽然高层语义信息充足利于目标分类,但此时下采样率为32,小尺寸目标的特征响应有限,甚至只占据特征图的几个点,进而影响目标定位精度。如果降低下采样率,利用包含空间信息更加丰富的浅层特征图进行目标预测,则会导致语义信息不足,进而影响目标识别精度。因此,为了充分利用高层特征的语义信息和浅层特征的空间信息,目标预测网络在目标检测之前首先进行特征融合,具体过程如图6所示(图中输入图像尺寸为416 pixel×416 pixel)。特征融合采用的是阶梯式(Stairstep)结构[16],共需依次完成2组融合。由于每一组融合涉及到了不同尺度和通道数的2个阶段的特征图,因此每一组融合需要经历3个步骤。第1步,高阶特征图经由一个Conv 1×1实现通道数量减半;第2步,通道变换后的高阶特征图通过步长为2的上采样(Upsampling)实现尺度增倍;第3步,尺度和通道数相同的高低阶特征图以叠加方式完成融合。通过2组融合,最终得到尺寸为输入图像1/8(下采样率为8)的融合特征图,实现高低阶特征图在语义和空间上的结合,进一步增强了特征图的表征能力。
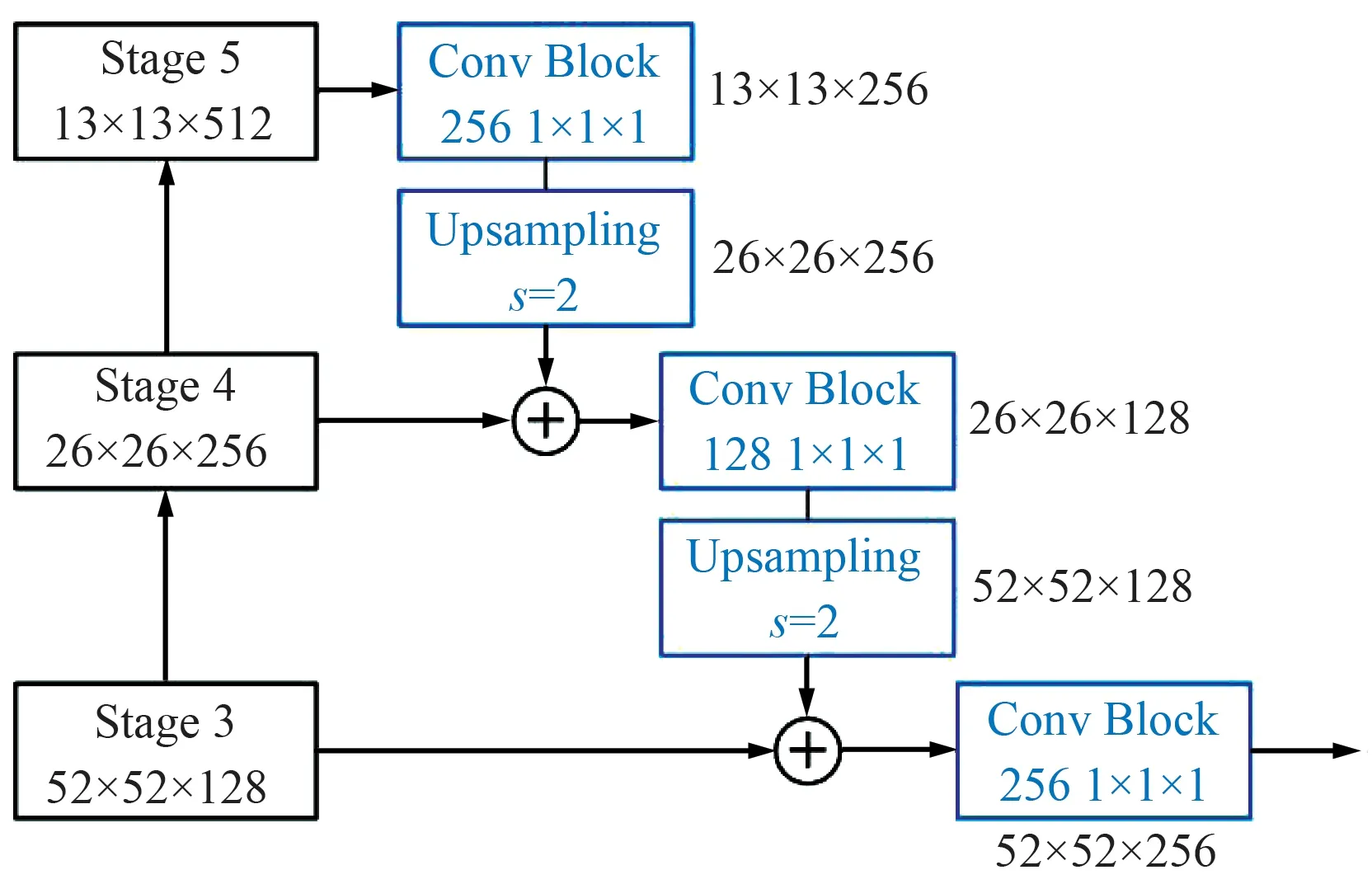
图6 Stairstep特征融合方式Fig.6 Stairstep feature fusion method
为了实现多尺度目标检测,YOLOv3在3个不同尺度(下采样率分别为8,16和32)的预测特征图上独立进行目标检测,虽然提高了多尺度目标检测的精度,但极易造成标签重写和无效边框计算,从而影响检测速度。因此,FEID-YOLO只保留了下采样率为8的预测特征图来进行目标检测。此外,特征提取网络中的双残差结构和目标预测网络中的stairstep特征融合方式可汇总不同尺度目标的特征信息,保证了预测特征图的鲁棒性和完备性。最后,预测特征图经由2层Conv 3×3后输入YOLO检测头得到包括目标位置坐标、边框置信度和分类概率的预测结果。训练阶段,FEID-YOLO采用的损失函数与YOLOv3相同。
在预测特征图上实现红外目标检测的基本原理如图7所示。其中,tx,ty,tw,th分别表示舰船目标边框的中心点横纵坐标、宽度和高度,Pobj表示边框置信度,Pk表示目标分类概率,k是目标类别索引。待检测图像输入特征提取网络之前首先调整尺寸至416 pixel×416 pixel,经特征提取和特征融合后输出分辨率为52 pixel×52 pixel的预测特征图,其每个像素点对应输入图像8 pixel×8 pixel大小的区域,以每个像素点为锚点产生6种锚框,根据锚框在特征图上的特征映射计算出边框坐标、置信度以及分类概率,从而得到目标预测结果,再将预测结果映射至原始图像完成目标检测。

图7 目标检测原理Fig.7 Principle of object detection
3 实验与分析
3.1 数据集
FLIR ADAS红外数据集[17]由FLIR公司于2018年发行,该数据集共包含14 452张图像,其中9 214张含有目标标注框,场景为白天(60%)和夜间(40%)的加利福尼亚州圣巴巴拉市街道和公路,目标类别主要由人(28 151个)、汽车(46 692辆)和自行车(4 457辆)3类组成。实验中选用11 152张图像样本作为训练集,选用3 000张图像样本作为测试集。
3.2 实验设置
算法基于Pytorch深度学习框架实现,并在搭载Ubuntu操作系统、E5-2630v4 CPU、NVIDIA GTX1080Ti GPU (11 GB显存)和64 GB RAM的硬件平台上进行训练和测试。网络训练时,设置初始学习率为0.001,Batch_size为8,训练轮次为150,并采用动量为0.9的Momentum算法优化训练过程。
为定量评估检测模型性能,本文使用单类别的平均精度(Average Precision,AP)、平均精度均值(Mean Average Precision,mAP)和FPS三项指标对模型进行评估。
3.3 检测性能对比分析
通过与Faster R-CNN[18],YOLOv3,YOLOv3-Tiny[19]进行比较来验证所提模型的有效性。各检测模型在FLIR ADAS红外数据集上的检测结果定量比较如表1和图8所示。
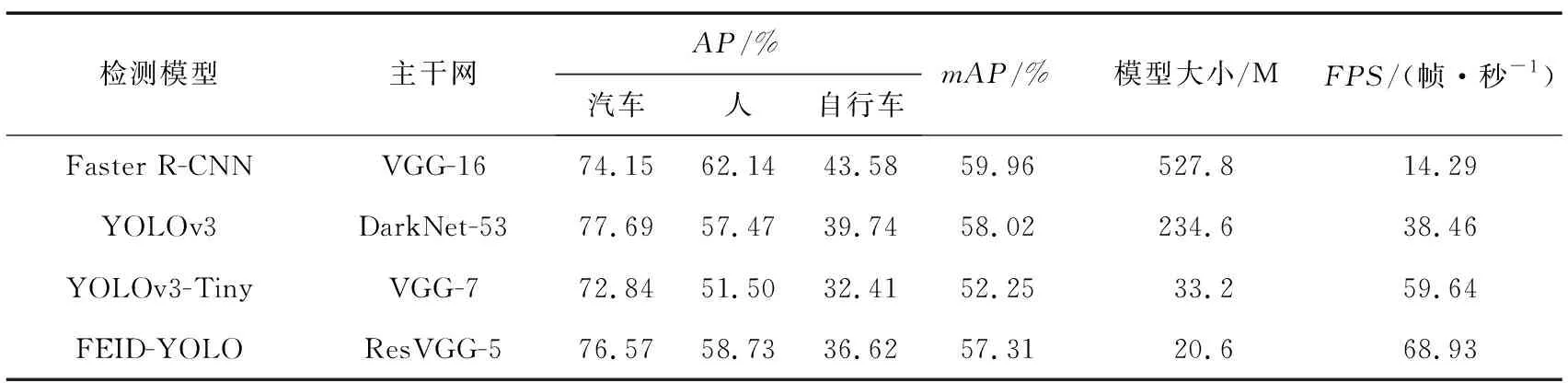
表1 基于FLIR ADAS数据集的不同检测模型实验结果Tab.1 Experimental results of different detection models based on FLIR ADAS datasets
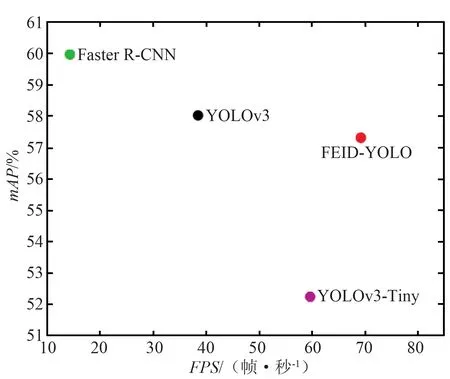
(a) 所有类别
(b) 汽车

(c) 人
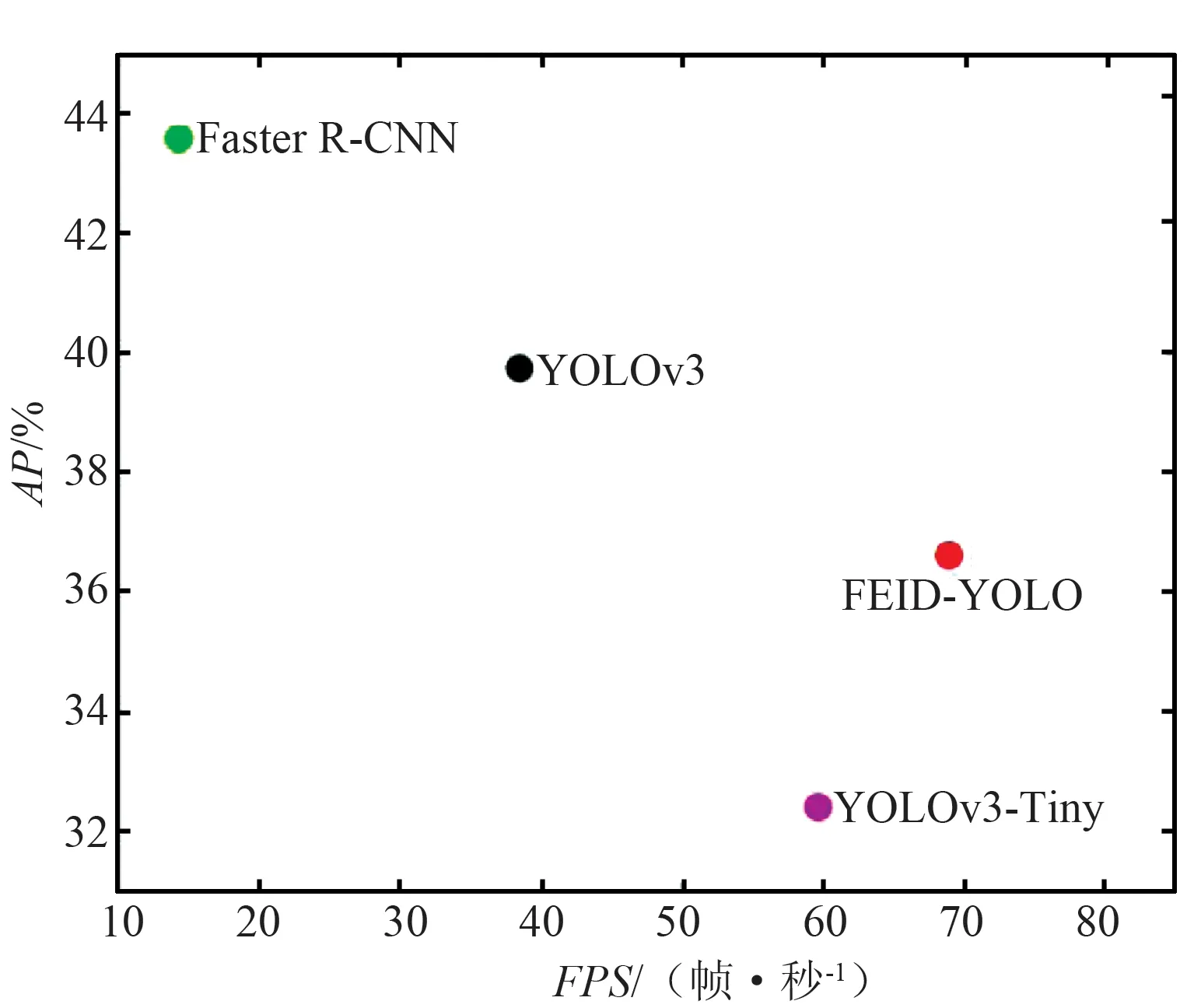
(d) 自行车图8 不同检测模型的各类别检测精度与速度结果Fig.8 Detection accuracy and speed results of various categories of different detection models
由各检测模型的性能定量比较可知,应用广泛的基准模型Faster R-CNN的mAP值达到了59.96%,YOLOv3的mAP值较前者略低,达到了58.02%,但由于Faster R-CNN采用的是二阶检测模式,相比于YOLOv3的一阶检测模式,其在计算量和检测速度上并不占优势。YOLOv3-Tiny在YOLOv3的基础上简化了主干网和检测头,模型尺寸更小,检测速度得以大幅提升,较YOLOv3其mAP值降低了5.77%,检测速度提升了21.18帧/秒。FEID-YOLO的mAP值为57.31%,检测速度达到了68.93帧/秒,与Faster R-CNN和YOLOv3相比,其在检测精度上有一定损失,但是考虑到计算量的巨大差距(模型尺寸仅为Faster R-CNN的1/26,YOLOv3的1/12),因此该损失是可以接受的。此外,与同类检测模型YOLOv3-Tiny相比,FEID-YOLO的mAP值提高了5.06%,检测速度提升了9.29帧/秒,整体检测性能提升幅度较大。
3.4 消融实验
为了理解FEID-YOLO中采用的ResVGG-5双残差结构和stairstep特征融合方式对检测效果的影响,表2给出了逐步增加相关模块的消融实验。其中,FEID-YOLO(VGG-5)的主干网络为以VGG方式构建的5层卷积,且利用最高层输出作为预测特征层,其mAP值为42.72%,检测速度为78.21帧/秒。FEID-YOLO(ResVGG-5)以文中所提的ResVGG-5为主干网络,较前者mAP提升了8.62%,说明ResVGG-5的双残差结构通过增加高低层的链接路径,提升了特征图的表征能力和鲁棒性。在此基础上,FEID-YOLO将stairstep特征融合结构引入检测模型,mAP提升了5.96%,验证了基于stairstep结构的特征融合可有效融合特征提取网络的高层语义信息和浅层空间信息,为后端目标检测提供完备的特征依据。

表2 基于FLIR ADAS数据集的消融实验Tab.2 Ablation experiment based on FLIR ADAS dataset
3.5 可视化检测结果
为了进一步验证FEID-YOLO模型在实际应用中的效果,图9给出了不同场景下的目标检测可视化结果。得益于较强的特征提取和处理能力,尽管各类目标处于不同的背景中呈现出不同的红外特性,甚至存在遮挡问题,所提模型能正确地识别和定位出图像中存在的绝大多数目标。但由于FLIR ADAS数据集的场景复杂度较高,在背景噪声比较大且目标比较小的情况下,还是存在背景被识别为目标的问题,此外当目标呈密集分布时,也存在少量的虚警和重复检测。总而言之,FEID-YOLO模型在68.93帧/秒的检测速度下,能达到可观的检测效果,为模型在小型系统端的部署打下了基础。




图9 红外目标检测可视化结果Fig.9 The visualization results of infrared object detection
4 结束语
为了满足小型红外探测系统实时检测的应用需求,提出了一种基于特征增强的快速红外目标检测模型。在实现过程中,为了降低模型计算量和提高检测速度,设计了轻量化特征提取网络,并利用双残差结构提升特征图的鲁棒性;针对现实中红外目标尺度分布广的问题,采用基于stairstep结构的特征融合方式充分融合高低层特征图的语义信息和空间信息,提升预测特征图的完备性。网络训练阶段,还采用了多尺度训练和数据增强技术来进一步提升模型的检测性能。在FLIR ADAS红外数据集上进行测试,与工业界广泛应用的快速检测模型Tiny-YOLOv3相比,提出的模型在检测精度提升了5.06%的情况下,检测速度提升了9.29帧/秒,验证了其有效性和实用性。
