一种车联网辅助积极性感知的空间众包任务分配框架
2023-02-18乔少杰杨国平林羽丰翁越男吴凌淳高瑞玮
王 鑫,乔少杰,杨国平,林羽丰,翁越男,吴凌淳,陈 琴,高瑞玮
(成都信息工程大学 软件工程学院,四川 成都 610225)
0 引言
随着配备通信装置和感知设备智能车辆的迅速演进,用户信息的复杂化导致资源分配必需的高计算力和高准确率愈发得不到保证,移动用户对匹配服务质量的需求成为亟待解决的问题。而车联网(Internet of Vehicles,IoV)技术旨在加速车辆、用户、基础设施以及云端网络之间的信息收集与交换[1],在物理距离以及网络距离上更接近用户,能够迅速处理用户在短时间内产生的大规模数据。IoV技术不仅具有较低的通信成本,还可以通过利用高数据传输性能保证大批量数据被实时处理[2]。
与此同时,一种新型众包技术应运而生——空间众包(Spatial Crowdsourcing,SC)。在SC场景下,工人被要求亲自前往特定地点,完成指定的时空任务,获取相应的奖励报酬[3]。SC平台中有许多应用程序,涉及旅游、情报、灾害响应、新闻跟踪和城市规划等多个领域,同时推进了一系列行业的成功,如视频拍摄、天气信息收集、城市噪音水平计算和车流量计算等。目前,众包平台的主流任务模式为以平台服务器为中心(Server Assigned Tasks, SAT)的模式。在SAT模式下,众包平台不会直接将空间任务分配给众包工人,而是需要众包工人将位置上传到服务器,当服务器收集到所有在线众包工人的位置后,再为众包工人分配合适的任务[4]。
在SC的一般场景下,待完成的任务量往往太大以至于不能在短时间内找到足够的专业工人,并且这些任务不能利用计算机代替真人来完成。将IoV技术集成到众包平台的任务分配中,构建一个分布式的SC平台,是实现高效任务分配的有效措施,也是SC研究的发展新方向之一。任务分配问题被描述为最大系统利用率问题(如任务完成数量、任务完成质量和任务完成时间等),现有研究主要集中在工人或是任务的时空可用性上,工人的主观意愿往往很容易被忽视,很大程度上没有解决工人主观意愿与高效任务分配之间平衡的问题。服务全球化的激烈竞争导致供应链市场饱和,工人成本迅速提升,因此,快速感知工人积极性并实现有效任务分配是众包平台至关重要的任务之一,利用IoV技术辅助SC完成任务分配是提高系统效率的有效手段。
为了解决上述问题,本文提出了一种利用IoV技术辅助积极性感知的SC任务分配框架(Task Allocation Framework in Spatial Crowdsourcing Based on Internet of Vehicles Assisted Positivity Sensing,IOV-SCA)。具体来说,该模型分为2个阶段:积极性感知阶段和任务分配阶段。积极性感知阶段旨在实时感知工人对任务的积极性,本文使用加入注意力机制的双向长短期记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)捕捉工人的潜在状态,计算工人的工作停滞时间,并与给定的时间阈值进行比较,以此判断工人的积极性。任务分配阶段在积极性感知的基础上,将任务分配问题转换为加权二部图最大匹配问题。本文提出了一种基于积极性感知的SC任务分配算法,旨在高效地将任务分配给工人,实现系统效益最大化。
综上所述,本文的主要贡献包括:
① 利用IoV技术辅助实现SC任务分配问题。
② 利用加入注意力机制的BiLSTM模型感知工人的积极性。
③ 提出了一种基于积极性感知的SC任务分配算法,实现了系统效益与工人主观感受之间的权衡。
④ 在大规模真实数据集上评估了IOV-SCA模型,其效率和有效性均优于其他代表性方法。
1 相关工作
与传统的任务分配方法不同,本文所提出的框架需要利用IoV技术辅助计算众包工人工作期间的积极性,提升上下文感知性能。本文主要涉及IoV技术和SC两个方面,下文中将分别介绍这两方面的研究现状。
1.1 IoV
近年来,IoV技术受到了广泛关注,通信传感是IoV技术的主要组成部分之一,它需要将每个车辆捕获的移动资源与其他平台或终端进行数据传输。高绅等[5]提出了一种多信道模型下C-V2X模式4的通信性能分析模型,该方法通过分析C-V2X模式4对不同传输功率、不同编码方案以及不同信道模型中存在的问题进行建模,表明车辆在频繁传输资源时,需要完善的资源分配方案以保证数据传输的通信性能。王哲等[6]提出了一种混合交通场景下的轨迹预测算法,用于规避手动驾驶车辆可能存在的危险行为,该算法在使用去中心化的无线集群学习保护用户隐私数据的同时,还利用车与车之间的无线通信系统感知附近手动驾驶车辆的历史轨迹信息并预测轨迹。张勇[7]提出了一种改进的VANET路由协议,该模型用于提升丢包率的计算速度,提高网络传输的准确率,通过提升网络传输性能可有效缩短预警系统发布警告的时间,从而确保驾驶员及时获取险情信息,降低交通事故的发生率。
1.2 SC
随着移动智能设备的发展,SC被广泛应用于智慧城市中提供信息资源,利用人群的潜在能力完成计算机不能完成的任务。Dutta等[8]研究了SC在环境传感方面的应用,提出人群可以利用便携式移动环境传感器通过蓝牙将其ID和测量的空气质量数据发送到最近的智能设备中,接收到的数据被处理后会上传到云服务器。在云服务器上,服务提供商会将数据聚合、分析并存储,按照用户的要求发送当地空气质量指数。Cianciulli等[9]研究了SC在公共交通系统中的应用,提出了一种基于Beacon3技术的SC应用程序,该程序利用安装在公交车和公交车站上的蓝牙信标发射器,计算公交车的位置以及到达不同站台的大致时间。当登录该程序时,用户的智能设备会接收到最近公交站点ID并上传至云服务器,而公交车会定期上传位置信息到云服务器。云服务器会计算公交车到达指定站点的时间并通知用户。Huang等[10]提出了一种及时预测城市异常情况(如噪音污染、城市基础设施故障等)的模型,该算法要求用户将投诉信息上传至云服务器,云服务器根据异常数量以及时间向量通过贝叶斯推理模型对城市区域进行聚类。最后,根据各区域的相关性以及目标区域的异常历史,利用马尔科夫模型对每个区域的异常情况进行预测。
IoV技术和SC都已经取得一些研究成果,但是上述方法都需要用户上传数据至云服务器,不满足实时感知工人积极性的低时延性和及时反馈性,如何将IoV技术的优势应用到SC中的任务分配问题是需要进一步研究的内容。本文所提模型的创新性在于利用IoV技术辅助感知工人的积极性,并且在此基础上提出基于积极性感知的任务分配算法。与已有研究相比,本文提出的框架响应更为迅速,任务分配结果更优。
1.3 总体框架
模型总体框架如图1所示。IOV-SCA模型主要包含3个实体单位:云服务器、路侧单元及车辆。云服务器负责汇总信息并分配任务;路侧单元是IoV技术中的基础设施,主要负责与车辆通信,并利用快速数据处理能力计算工作停滞时间;车辆即表示载有众包工人的工人车辆,主要利用车载移动智能设备负责工人实时数据的收发。模型分为2个阶段:第1阶段在路侧单元上搭建基于BiLSTM的积极性感知模型(Positivity Sensing Model Based on BiLSTM,Bi-PSM),旨在根据工人的实时感知数据以及历史任务轨迹数据计算工作停滞时间,从而判断工人的积极性。具体来说,Bi-PSM模型需要将车辆收集到的感知数据汇总成工人的隐性状态,其中包括任务的报酬、工人到任务点所需的时间距离和空间距离、2个相邻任务点之间的时间距离和空间距离。将工人的隐性状态输入Bi-PSM模型,计算出工作停滞时间,并给定时间阈值,若工作停滞时间超过阈值,则该工人被认定为消极工人;反之,若工作停滞时间低于阈值,则该工人被认定为积极工人。

图1 模型总体框架Fig.1 Framework of the proposed model
第2阶段在云服务器上搭建基于积极性感知的SC任务分配算法(Task Allocation Algorithm Based on Positivity Sensing,PS-TAA),旨在实现路侧单元与云服务器之间的交互,保证工人有高积极性、高参与度和高满意度的工作状态,并在云端合理分配任务。具体来说,PS-TAA算法优先考虑消极工人,为消极工人分配价值更高的任务,如更高收益的任务、物理距离更近的任务和匹配度更高的任务等。
2 问题表述与模型
2.1 基本概念
定义1SC任务:由以下五元组的形式进行定义,t=
定义2SC工人:由以下五元组的形式进行定义,w=〈lw,dw,mw,tw,sw〉,其中lw表示众包工人w当前的地理位置,dw表示众包工人w能到达指定任务地点的范围半径,mw表示众包工人w在同一时刻内能接受的最大任务数量,tw表示工人w的工作停滞时间,即表示工人完成第i个任务到接受第(i+1)个任务的时间间隙,sw表示众包工人w具备的技能集合。在本文的工作中,云服务器首先判断工人是否符合任务要求,工人只能匹配符合技能要求的任务,即st∩sw≠Ø。当云服务器将任务分配给工人时,该工人将会被视作脱机状态,直到该任务被完成再重新回到联机状态,即一名众包工人在同一时刻内最多只能接受一项任务,因此,在本文的模型中mw设置为1。
定义3消极工人:给定一个时间阈值δ,当tw≥δ时,则认定该工人为消极工人。
定义4积极工人:给定一个时间阈值δ,当tw<δ时,则认定该工人为积极工人。
定义5基于积极性感知的任务分配问题:在SC平台下,当给定一组SC任务T以及一组SC工人W时,本文的目标是找到一组任务分配A并且满足以下目标:
① 任务分配A的效益最大化,形式化表达为:

② 任务分配A需要以众包工人为中心,即lt要在以lw为中心、dw为半径的区域内。
③ 提升众包工人工作时的积极性,即最小化工作停滞时间tw,为消极工人分配收益更高的任务。
2.2 基于BiLSTM的积极性感知模型
Bi-PSM模型为本文提出的积极性感知模型,即采用融合注意力机制的BiLSTM混合神经网络模型来提取工人的工作停滞时间。Bi-PSM模型包含输入层、BiLSTM层、注意力机制层、全连接层以及输出层,模型结构如图2所示。

图2 Bi-PSM模型结构Fig.2 Structure of Bi-PSM
2.2.1 输入层
文献[11]的研究表明,可以利用时空行为数据提取到多角度有价值的信息。根据这一基本原理,将时空行为数据转换为一系列行为特征来表示工人的隐性状态,通过这些行为特征来计算工作停滞时间。因此,引入状态特征向量作为Bi-PSM模型的输入:对于工人w,状态特征向量表示为(r,lo,la,ds,tb,te,ts),其中r表示当前众包任务的奖励报酬,lo表示当前众包任务的经度,la表示当前众包任务的纬度,ds表示相邻任务之间的物理距离,tb表示当前众包任务的起始时间,te表示当前众包任务的截止时间,ts表示相邻任务之间的时间距离。Bi-PSM模型是基于BiLSTM的模型,本文将时间步长设置为30,即输入实例由30个状态特征向量组成。
2.2.2 BiLSTM层
文献[12]的研究表明,LSTM网络执行连续数据分类任务的效果是比较出色的,区别于其他神经网络,LSTM网络可以保存从历史输入中获取的重要信息。本文将工人的状态特征向量视为序列数据,即工人的潜在状态具备连续性。因此,利用LSTM单元中3个门来执行记忆功能和遗忘功能,可以有效捕捉上下文信息应用于潜在状态分析。计算过程如下:
① 遗忘门ft负责过滤工人的过去周期信息,因为并非工人在执行任务期间所采取的每一项行动都会对其积极性产生影响。通过过滤对积极性感知无用的信息,可以减少操作时间和存储大小,计算如下:
ft=σ(Wf·[ht-1,xt]+bf) ,
(1)
式中,ft表示遗忘门的内容,将状态特征向量xt和从上一时刻到t-1时刻筛选得到的状态特征向量进行串联作为t时刻的输入;Wf表示遗忘门中的权重矩阵;bf表示遗忘门中的偏置项;σ表示Sigmoid函数作为激活函数。

it=σ(Wi·[ht-1,xt]+bi) ,
(2)
(3)
(4)
式中,it表示输入门的内容;Wi和Wc表示输入门中的权重矩阵;bi和bc表示输入门中的偏置项;σ表示Sigmoid函数作为激活函数。
③ 输出门ot负责筛选对积极性感知有重要影响的隐性状态信息,并在时刻t输出最终隐性状态信息ht,用于后续的工作停滞时间计算:
ot=σ(Wo·[ht-1,xt]+bo) ,
(5)
ht=ot·tanh(ct) ,
(6)
式中,ot表示输出门的内容;Wo表示输出门中的权重矩阵;bo表示输出门中的偏置项;σ表示Sigmoid函数作为激活函数。
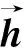
(7)
H={h1,h2,…,ht,…,hT} ,
(8)
式中,H表示T时刻隐藏层内连接向量的集合作为注意力机制层的输入。基于LSTM的工人隐性状态获取单元结构如图3所示。
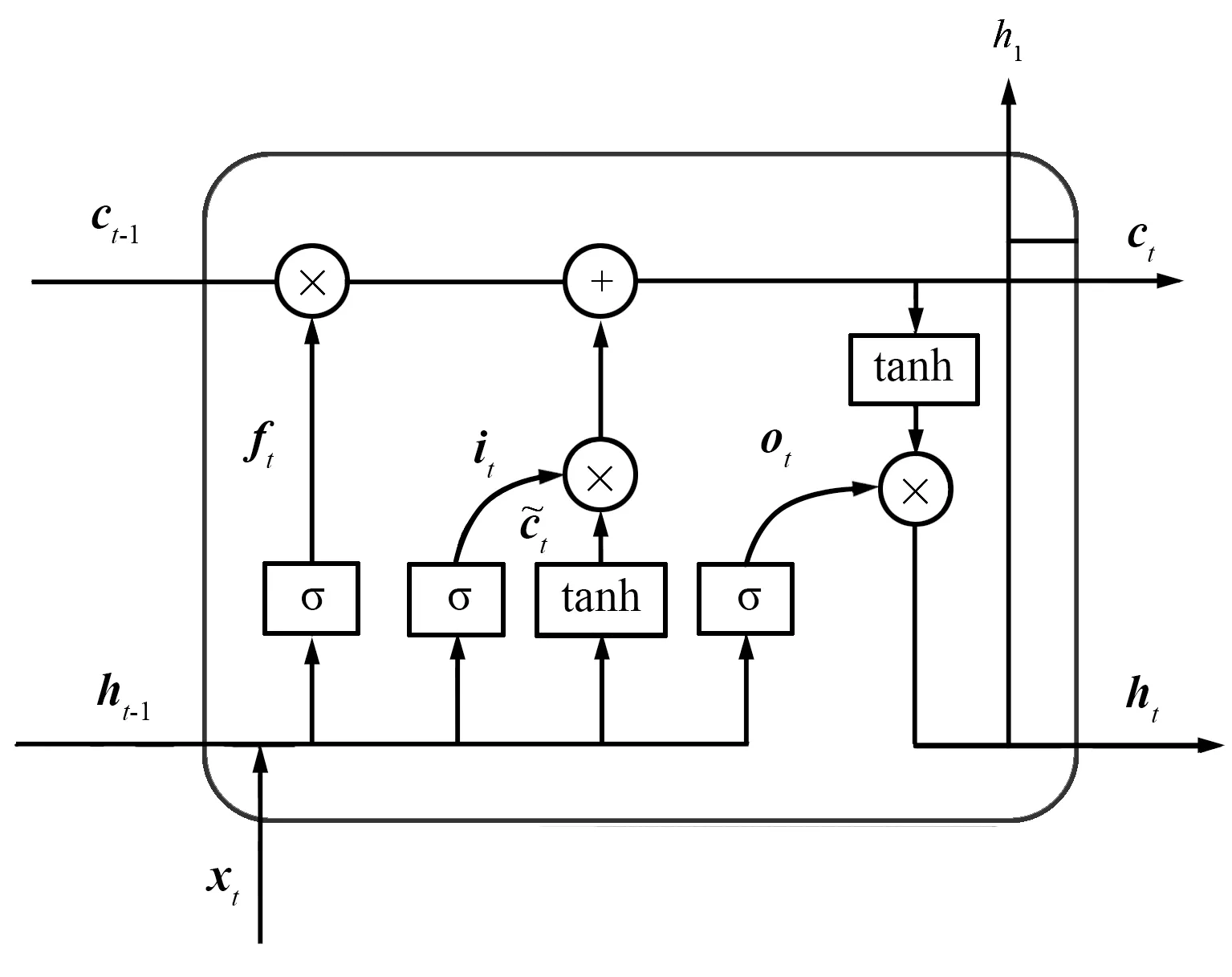
图3 工人隐性状态获取单元结构Fig.3 Structure of recessive state acquisition unit
2.2.3 注意力机制层
由于特定时间段内的特定行为对工人积极性变化产生的影响力不同,因此用注意力机制量化这些行为对积极性感知的影响程度[13]。利用注意力机制,可以为不同的特征分配不同的权重,从而降低无关部分的作用,可以提升工人隐性状态的提取效率,计算如下:
m=tanh(Wm·H+bm) ,
(9)
a=Softmax(m) ,
(10)
R=H·αT,
(11)
式中,m表示每个隐藏层向量的评分,即其对输出结果的影响程度;Wm表示注意力机制层的权重矩阵;bm表示注意力机制层的偏置项;α表示用Softmax函数对评分m归一化得到的权重系数;R表示权重分配完成后注意力机制的输出结果。
2.2.4 输出层
经上述操作后,将输出结果R通过全连接层,输出为感知到的工作停滞时间tw:
tw=tanh(Wt·R+bt) ,
(12)
式中,Wt表示输出层的权重矩阵;bt表示输出层的偏置项。此时,给定一个时间阈值δ,当tw≥δ时,认定工人w为消极工人;反之,当tw<δ时,认定该工人为积极工人。
2.3 基于积极性感知的SC任务分配算法
在现实生活中,工人的积极性是动态变化的,这就要求设置于云服务器的众包平台作出迅速响应,因此,找到SC中任务分配问题的全局最优解是具有挑战性的。本文将任务分配问题转化为带权二部图中的最优匹配问题,旨在最大化当前分配权值,为消极工人提供更高的优先级并为其分配价值更高的任务。
通过一个动态场景下SC的任务分配示例来描述工人积极性和系统效用之间的权衡,该示例包含6名工人(用数字编号)和6个任务(用字母编号),如图4所示。图4(a)表示在约束条件下满足要求的可能性分配结果;图4(b)为对应的加权二部图;图4(c)表示侧重工人主观性的任务分配,但是这种分配方法导致工人2和任务a未被分配,因此系统效益被降低;图4(d)表示侧重系统收益的任务分配,该方法旨在最大化平台利益,但可能会产生不合适的匹配结果,持续对分配任务不满意的工人很大几率会离开平台,对平台造成显著的不利影响[14]。基于此,本文提出的PS-TAA算法旨在实现系统效用最大化的同时尽可能为消极工人提供高权重的配对。

(a) 约束条件下的分配
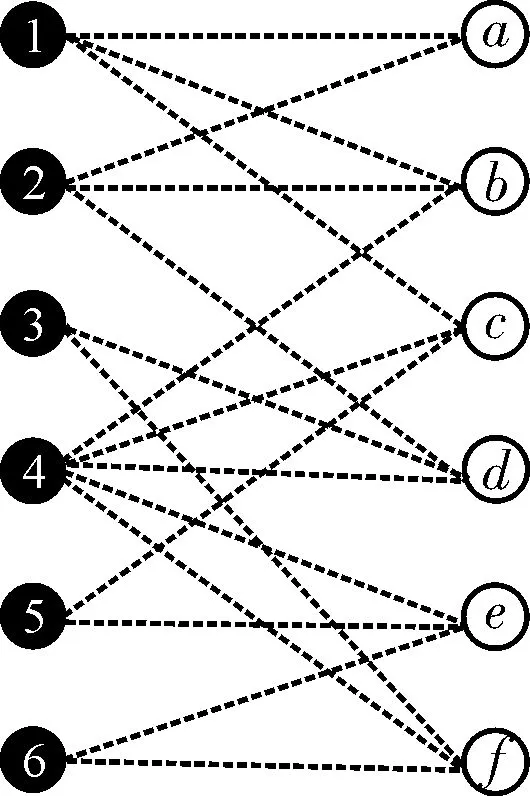
(b) 对应的加权二部图

(c) 侧重主观性的分配

(d) 侧重收益的分配图4 动态场景下SC任务分配示例Fig.4 Example of spatial crowdsourcing task assignment in dynamic scenarios
定义G=(V,E)表示加权二部图,其中V表示顶点的集合,E表示边的集合。给定一组待命工人W={w1,w2,…,wi}和一组可分配任务A={a1,a2,…,aj},基于此,顶点集V为工人顶点子集VW和任务顶点子集VA的并集,且VW∩VA=;顶点V的数量为(i+j),边的数量为其中mw表示众包工人w在同一时刻内能接受的最大任务数量,与工作停滞时间tw呈正相关。
为了更好地理解本文所提算法,首先介绍增益路径查找算法,通过增益路径查找算法进行迭代更新,以获得具有最大系统效用的分配结果。其中,迭代过程是在工人与任务的配对中查找增益路径P={p1,p2,…,pk},并且增益路径p的2个端点不能配对,它的边和已有配对不重复。当找到(2l+1)条增益路径p时,意味着当前配对得分已经到达最大值,即可作为最终结果返回。从当前未被分配任务的工人wi开始,如果工人wi可以与未分配的任务tj直接匹配,则立即得到长度为1的增益路径pk;否则,寻找下一个未分配的任务给该工人。对于每个这样的任务t,通过扩展当前路径来创建一个新的增益路径,并递归地重复相同的过程,并且递归深度不能超过上限λ。
增益路径P查找算法的详细过程如算法1所示。

算法1:增益路径P查找算法输入:加权二部图G输出:增益路径P1. 初始化系统参数;2. Forwi∈Wdo3. If 工人wi未被分配任务且任务tj未分配 then4. 将任务tj设置为待分配状态;5. value ←工人节点wi权值-任务节点tj权值;6. Ifvalue == 0 then

7. P ← pk;8. If |P| == 2l+1 then9. End If10. ReturnP;
PS-TAA算法的首要目标是根据感知到的工人积极性进行任务分配。首先,利用Gale-Shapley算法[15]中提出的延迟接受机制,在给定的工人和任务之间找到一个稳定的匹配;然后利用增益路径查找算法进行迭代更新;最后获得满足系统效益最大化的分配结果。PS-TAA算法的详细过程如算法2所示,给定由工人顶点集W和任务顶点集T组成的二部图,根据wi的工作停滞时间按降序对每个任务的可用工人进行排序,通过增益路径查找算法递归查找有效匹配,按照邻居节点的积极性排序顺序访问,将任务分配给消极工人,降低平台的损失。

算法2:PS-TAA算法输入:工人集W,任务集T输出:任务分配结果S1. 初始化系统参数;2. For each wi∈Wdo3. 计算工作停滞时间tw;4. Iftw≥δdo5. 认定该工人为消极工人;6. For each aj∈Ado7. 设置任务aj为待支配状态;8. 查找所有可被任务aj支配的工人;9. For each available wi∈Wdo10. 调用增益路径P查找算法进行迭代;11. If 增益路径P被查找到do12. i=i+1,j=j+1;13. 将pk存储到当前wi的分配结果中;14. Else15. Break16. End For17. End For18. ReturnS;
3 实验结果与分析
3.1 实验设置
为了评估IOV-SCA模型的性能,在2组真实数据集上进行对比实验,分别为包含193 294名用户在283 298个地点2 427 149条附带时间戳的签到记录的Gowalla数据集以及包含来自428 236名用户在582 362个地点3 829 629次附带时间戳的签到记录的Foursquare数据集。为了使用户数据更具有代表性,将签到记录少于10次的用户进行过滤处理,并假设用户表示众包工人,签到位置表示众包任务,则签到记录表示接受该任务。为了避免实验结果的偶然性,按照时间顺序将数据集划分为训练集和测试集,其中,80%的签到记录用于训练,其余20%用于测试,经处理后的实验数据集规模如表1所示。
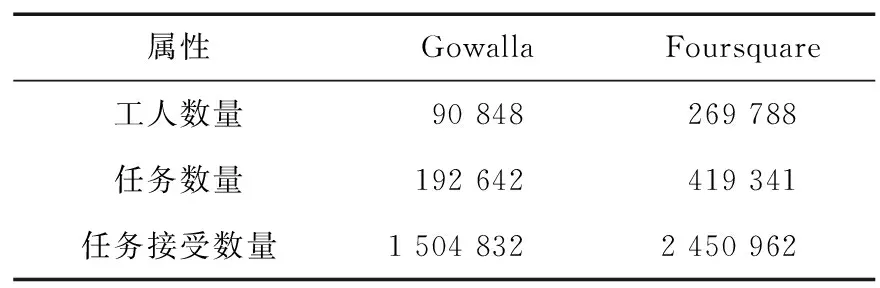
表1 实验数据集描述Tab.1 Description of experimental datasets
本文的实验环境如下:操作系统为Windows 10,CPU为AMD Ryzen7 5800H,GPU为NVIDIA GeForce RTX3060,系统内存为32 GB DDR4@3 200 Hz,Python版本3.6.8,深度学习框架使用PyTorch,模型运算在CUDA上进行。
本文使用2个指标来评估IOV-SCA模型的有效性以及效率:① 总体质量分数,用于衡量分配策略的整体质量;② 分配消耗的CPU时间,指标通过Python记录的分配算法开始前后时间求差值计算得到。
3.2 基准方法
为了说明IOV-SCA模型的性能,引入以下基线方法进行比较:
① Greedy-SAT模型[16]将任务根据价值从高到低排序,每个任务在可用工人集中选择距离最近的工人进行分配。
② Random-SAT模型[17]随机从任务集中选择一个任务,并分配给可用工人集中随机一名工人。
③ D&C-SAT模型[18]基于分治法的任务分配模型,该模型将一个可用任务集分割成一系列规模较小的任务集,然后分配给距离最近的工人。
3.3 结果分析
图5比较了任务规模变化下IOV-SCA模型和其他基准方法的总体质量分数差别,其中任务规模由1 000增加到6 000。由图5可以看出,随着任务规模的扩大,4种模型的总体质量分数都在提升,本文所提IOV-SCA模型在任务规模变化时优于其他算法,这是因为IOV-SCA模型考虑了工人的积极性,在有限的任务内寻求最优匹配以减少消极怠工的工人并提升总体效益。Greedy-SAT模型总体质量分数提升幅度较小,这是因为贪心算法注重局部最优,迭代次数较少,导致其性能低于D&C-SAT模型。D&C-SAT模型的总体质量分数较高,这是因为该模型通过分治法在不同区域内寻找到质量较高的匹配,但其性能低于本文所提IOV-SCA模型,是因为IOV-SCA模型内的工人顶点被赋予积极性特征,即工人顶点与其他任务顶点匹配的方式更多,从而提升了系统的整体效益。

(a) Gowalla数据集
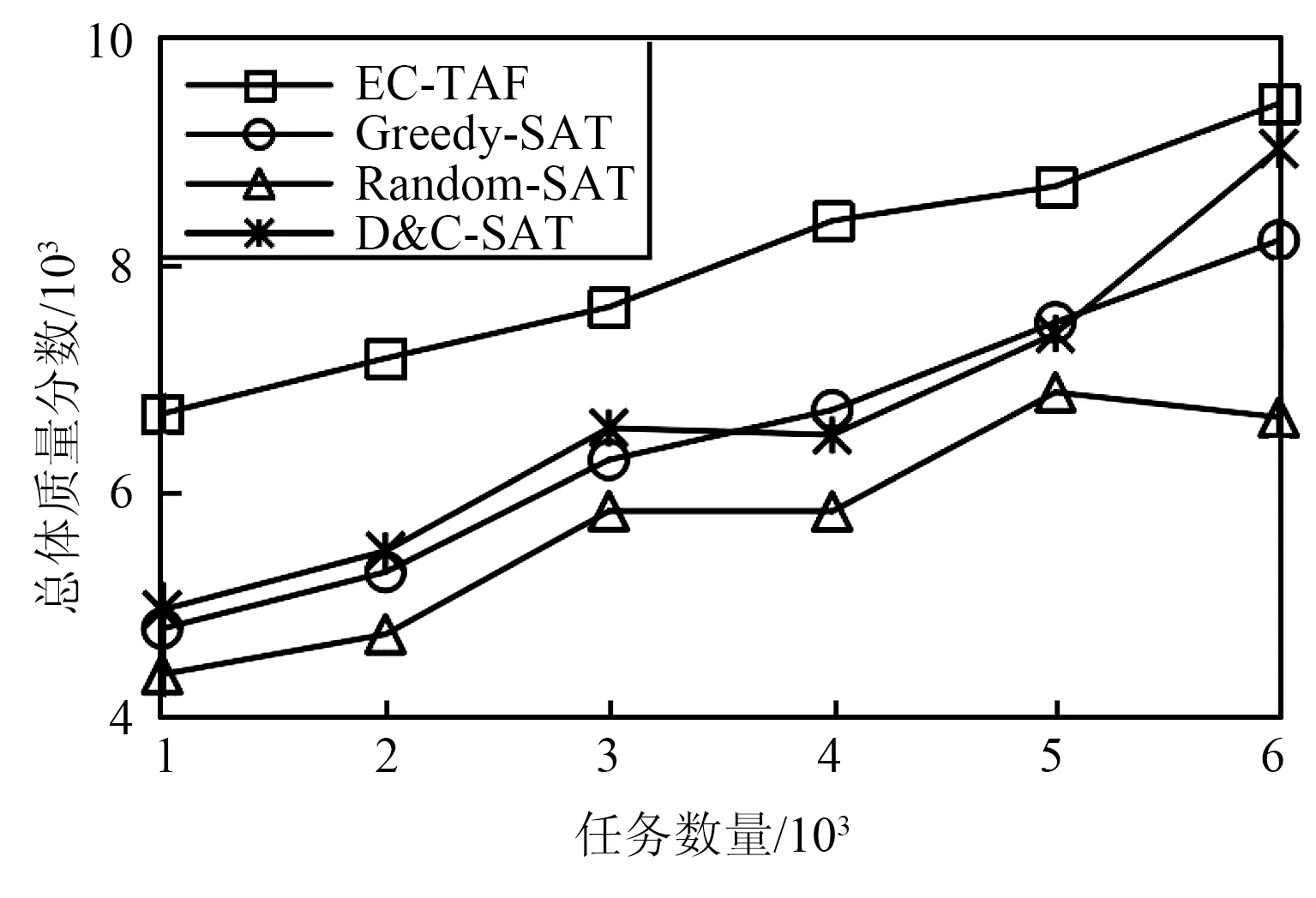
(b) Foursquare数据集图5 不同任务规模下总体质量分数Fig.5 Overall quality score under different task scales
图6比较了任务规模变化下IOV-SCA模型和其他基准方法的CPU消耗时间的差别,其中任务规模由1 000增加到6 000。由图6可以看出,随着任务规模的扩大,Greedy-SAT模型和D&C-SAT模型的CPU消耗时间的增长趋势相对稳定,而IOV-SCA模型的CPU消耗时间增长相对明显,这是因为当工人数量确定时,任务规模的扩大会导致工人内部竞争的扩大,从而可能会有较多不合适的匹配对产生,造成部分工人的积极性降低,增加了算法的迭代程度。而Gowalla数据集和Foursquare数据集的主要差别在于数据集的规模上,对于规模较大的Foursquare数据集,所有任务分配模型消耗的CPU时间都会增长,IOV-SCA模型的增长趋势更为明显。举例来说,当IOV-SCA模型检测到工人甲为消极工人时,此时模型试图给工人甲分配任务,而当前任务已经被分配给工人乙,则模型会寻找下一个任务,这种情况增加了模型迭代次数,从而导致CPU消耗时间的增加。Random-SAT模型的分配时间是最快的,这是因为该模型随机选择任务和工人进行匹配,没有考虑最大化质量分数。

(a) Gowalla数据集
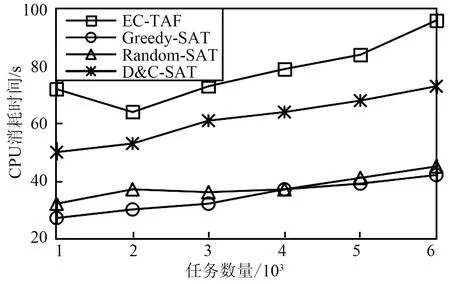
(b) Foursquare数据集图6 不同任务规模下CPU消耗时间Fig.6 CPU consumption time under different task scales
图7比较了工人规模变化下IOV-SCA模型和其他基准方法的总体质量分数差距,其中工人规模由1 000增加到6 000。由图7可以看出,随着工人规模的扩大,所有模型的总体质量分数都稳定增加,这是因为在任务数量确定的情况下,工人数量越多,工人与任务的匹配对也越多,与之对应的总体质量分数也会提高。在数据集规模较大的Foursquare数据集上,所有模型的质量分数都要高于Gowalla数据集的结果,这是因为工人数量增加导致可用分配的增加,从而二部图中任务顶点所对应的边也会增多,因此总体质量分数会有明显的区别。IOV-SCA模型较D&C-SAT模型总体提升约5.6%,较Random-SAT模型约提升10.2%,较Greedy-SAT模型约提升18.6%。
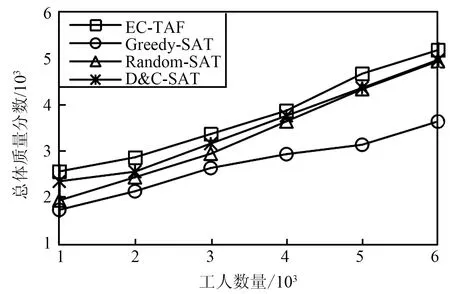
(a) Gowalla数据集
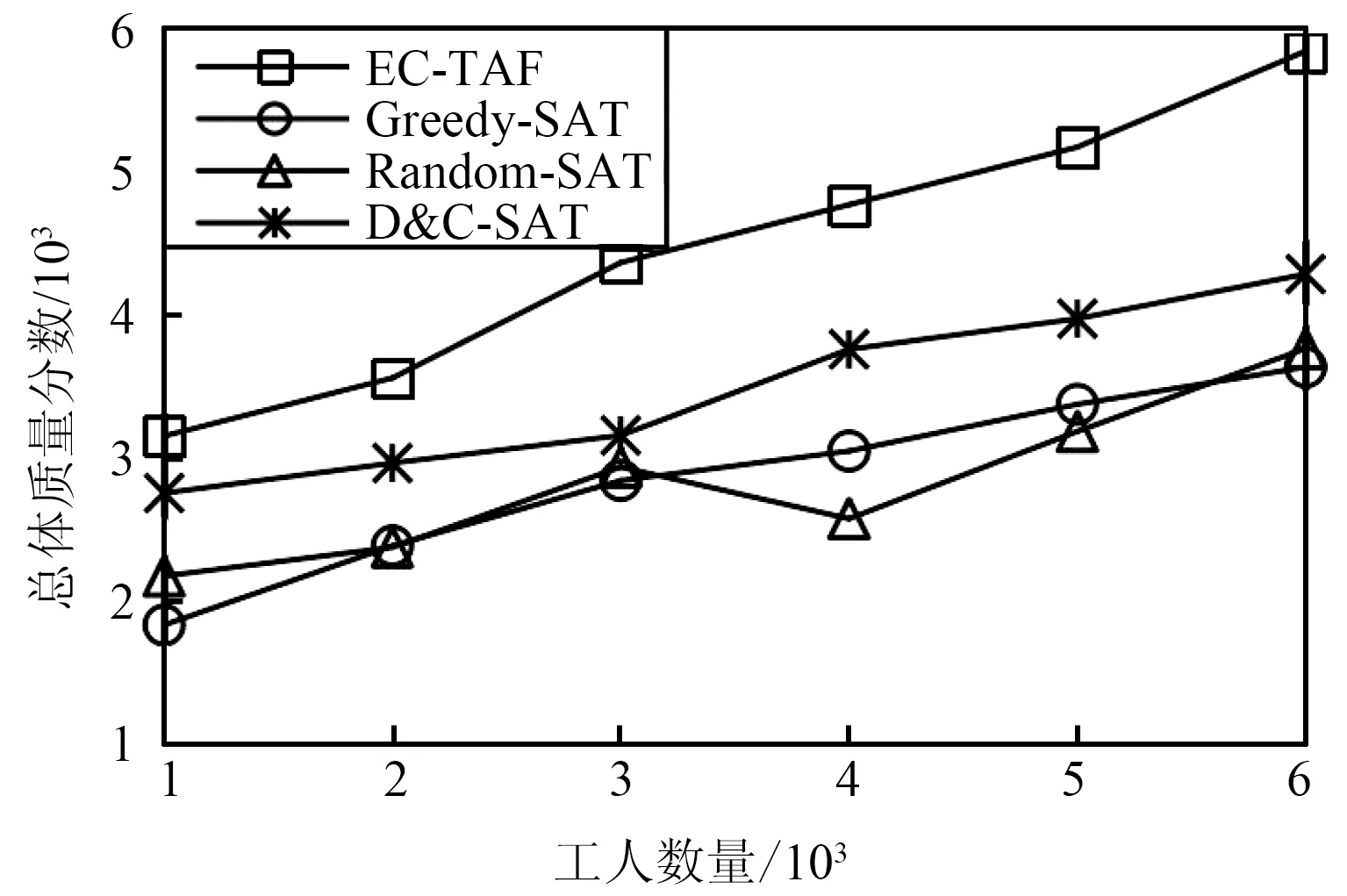
(b) Foursquare数据集图7 不同工人规模下总体质量分数Fig.7 Overall quality score under different worker scales
图8比较了工人规模变化下IOV-SCA模型和其他基准方法CPU消耗时间的差别,其中工人规模由1 000增加到6 000。由图8可以看出,由于工人选择范围更广泛,导致获得更高质量分数的同时也会增加CPU的处理时间。与之前的结果类似,Greedy-SAT模型和Random-SAT模型所需要的时间开销更少,同样是因为这2种算法只能保证获得局部最优,并没有考虑平台效益的最大化。虽然IOV-SCA模型的CPU消耗时间高于D&C-SAT模型,但是其总体性能在任何变化下都有更优的表现。另外,当工人的数量增加时,工人内部的竞争会变激烈,从而增加消极工人出现的可能性,因此IOV-SCA模型在分配任务时需要多次迭代,增加了CPU消耗时间。
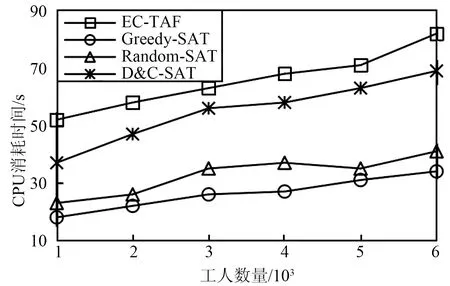
(a) Gowalla数据集

(b) Foursquare数据集图8 不同工人规模下CPU消耗时间Fig.8 CPU consumption time under different worker scales
4 结束语
本文提出了一种IoV辅助积极性感知的SC任务分配框架,并且按照功能分为2个阶段:第1阶段在路侧单元上搭建Bi-PSM积极性感知模型,而Bi-PSM模型旨在根据工人的历史任务轨迹数据计算工作停滞时间,从而判断工人的积极性;第2阶段在云服务器上搭建PS-TAA算法,实现了路侧单元与云服务器之间的交互,在云端为工人合理分配任务,确保平台效益最大化。本文在真实数据集上评估了不同模型的性能,实验结果表明,IOV-SCA模型的总体质量分数均优于其他基准方法。未来将进一步利用IoV技术,通过车车交互的方式感知工人的积极性,并且将消极工人的应付式行为纳入考虑,进一步改进任务分配算法,以提高平台的整体效益。
