文本聚类技术综述
2023-02-18都云程施水才
范 缜,都云程,施水才
(北京信息科技大学 计算机学院,北京 100101)
0 引言
目前,Twitter、雅虎、新浪微博、腾讯新闻、学习强国等互联网应用广泛普及,文本数量激增,发掘文本中有价值的信息对研究用户喜好具有重要意义。处理文本常用的技术包括自动化文本分类和聚类。其中,文本分类属于有监督学习方法,需要对文本进行标记,同时要对语料库模型进行训练;文本聚类(Text Clustering,TC)则属于无监督学习方法,无需标记文本,只需将距离相近的文本聚类到同一个簇中[1],因此被广泛应用于新闻信息聚合、垃圾邮件过滤、客户问题分析、假新闻识别等领域。
为了进一步分析文本聚类技术,本文将分别对文本聚类的流程、聚类评价标准、文本聚类数据集、文本聚类算法等方面进行详细介绍。
1 文本聚类流程
图1 为文本聚类流程,具体包括待聚类文本、数据预处理、文本表示、选择合适的文本聚类算法4 个步骤。其中,数据预处理步骤中通常使用分词及去停用词操作;文本表示步骤中包含特征提取、权值计算等操作。
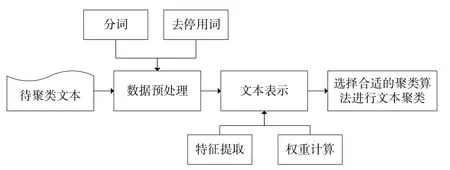
Fig.1 Text clustering flow图1 文本聚类流程
1.1 数据预处理
数据预处理步骤中通常使用分词及去停用词操作。由于文本是一种非结构化数据,需要先将其转化为数字量化的结构化数据。
在分词过程中,中、英文文本存在明显差异,英文文本可使用空格切分各单词,但中文文本只能依靠分词器[2]。现阶段常用的分词器包括jieba、httpcws、盘古分词、IKAnalyzer、Ansj、Paoding、清 华 大 学 的SEGTAG、中 科 院NLPIR 等[3]。
分词后会进行去停用词操作,该操作也是数据预处理的重要环节,可提升待聚类文本特征的质量,降低文本维度,提升文本聚类准确率。目前较为常见的停用词通常为冠词、介词、代词、连词等,在中文文本中表现为“这”“你”“我”“的”“就”“什么”等,在英文文本中表现为“the”“a”“an”“so”“what”等。
1.2 特征提取
特征提取目的是对数据集进行降维,即从数据集中提取出代表性子集。常用的特征提取算法包括TF-IDF、Word2Vec、Doc2Vec[4]等。其中,TF-IDF[5]为一种加权计算,表示某个词在文本中的重要性,TF 表示词在文本中出现的频率,TF 值越大,表示该词越代表性越强。例如,在以“手机”为主题的文本中,“手机”为高频词,具有很强的代表性,但“的”“你”“我”等常用词出现的频率也较高。因此,仅通过TF 值无法准确衡量某个词在文本中的重要程度。为此,本文引入IDF 对词进行衡量,当某个词在当前文本使用次数多,而在其它文本中使用较少时,IDF 的值偏大,说明该词对当前文本更为重要,具体数学表达式为:

其中,Wi代表第i个特征词的重要性,Wi较大说明该特征词为当前文本的高频词,对当前文本较为重要,但并非通用词。此外,在使用TF-IDF 算法进行文本特征提取时,可设置阈值W获取所需特征词。
然而,在实际特征提取过程中,TF-IDF 未考虑词语语义与语境等因素造成的影响,具有一定的局限性。为了解决该问题,Church 等[6]提出利用Word2Vec、Doc2Vec 算法基于语义与语境关系来提取文本特征。
2 文本聚类评价指标
文本聚类评价指标包括纯度(Purity)、兰德指数(Rand Index,RI)、调整兰德指数(Adjusted Rand Index,ARI)、准确率(Precision)、召回率(Recall)、F 值(F-Score)、聚类精确度(Accuracy,AC)[7]等。
其中,准确率、召回率和F 值常用于评价文本分类结果,也适用于对文本聚类结果进行评价,具体计算公式如式(2)-式(4)。
准确率P计算公式如下:

其中,Sa表示待聚类文本集合中包含文本a的集合,Sb表示聚类结果中包含文本a的集合,准确率P表示聚类结果正确的百分比。
召回率R取值范围在[0,1]区间,当R趋近1 则说明同类数据聚到同一个簇中。计算公式如下:

F值是综合P、R的评估指标,当准确率P与召回率R矛盾时,可利用F值对结果进行评价,计算公式如下:

纯度是一种易于理解的评价指标,具体计算公式如下:

其中,N为样本总数,π={w1,w2,w3…,wk},wi表示第i个聚类簇,C={c1,c2,c3…,ck}表示文本集合,Purity的值位于[-1,1]区间,当该值越趋近1,代表聚类越准确。
调整兰德指数ARI 取值范围在[-1,1]区间,当ARI 的值趋近1,则说明同类数据聚到同一个簇中,具体计算公式如下:
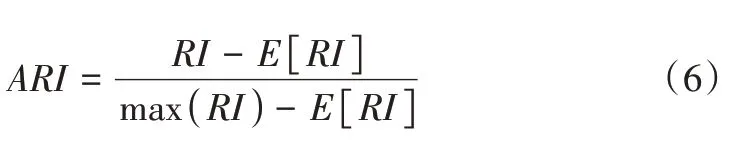
其中,E[RI]为RI的期望。
兰德指数RI将聚类定义为一系列的决策,具体计算公式如下:

其中,TP为将两个相似文本归入同一簇的正确决策,TN为将两个不相似的文本归入不同簇的正确决策,N表示文本数。
3 文本聚类数据集
数据集是驱动文本聚类快速发展的重要因素,但目前尚未形成统一标准的数据集,通常使用文本分类数据集进行测评。常见的文本聚类数据集如表1 所示。其中,最具代表性且被广泛使用的数据集为20 Newsgroup、Sougou、THUCNews[8]等。

Table 1 Common text clustering data sets表1 常见文本聚类数据集
20Newsgroup 数据集由18 828 篇文章组成,包括20 种话题,包含训练集与测试集,被广泛应用于文本分类与文本聚类;Sougou 数据集来源于Sougou Labs,包括搜狐新闻数据和全网新闻数据(SogouCA),涵盖2012 年6-7 月国内国际的体育、社会、娱乐等18 个频道的新闻数据,其中新闻文章数量共计1 245 835 个,能够基本满足中文文本聚类测评;THUCNews 是清华大学开源的文本数据集,由微博RSS 频道2005-2011 年历史数据筛选而成,包含金融、地产、科学、家装、社会新闻等14 个类别共74 万篇新闻文本,相较于20Newsgroup 数据集和Sougou 数据集,THUCNews不仅能够实现文本聚类测评,还能提供demo 程序、运行参数、程序接口等,受到了研究人员的广泛使用。
4 传统文本聚类算法
传统文本聚类算法包括层次聚类算法、划分聚类算法、密度聚类算法、网格聚类算法、模型聚类算法、图聚类算法、模糊聚类算法[9-10]等。
4.1 层次聚类算法
层次聚类分为凝聚型层次聚类与分裂型层次聚类,此类算法的目的是将数据聚类成一颗以簇为节点的树,分别从下向上,自上而下实现层次聚类[11]。常见的层次聚类算法包括BIRCH(Balanced Iterative Reducing and Clustering Using Hierarchies)算法、CURE(Clustering Using Representative)算法等。其中,BIRCH 算法基于聚类特征树(Clustering Feature Tree,CF-Tree)进行聚类,聚类过程中首先将样本依次读入建立树结构,然后去除异常点(例如稀疏数据)得到较优的树,最后根据质心进行聚类;CURE 算法属于凝聚型聚类,可对大规模、多种形状的文本数据进行聚类,并能够检测离群点。
4.2 划分聚类算法
划分聚类的常用文本聚类算法包括K-Means、K-Medoids等,此类算法的思想是经过数次迭代重定位将待聚类数据划分为指定数目的簇。
K-Means 算法简单易懂、聚类速度快、操作便捷,但也存在以下不足:①需要用户自行指定簇的数目;②无法处理非球形等不规则数据;③对离群点(噪声)敏感;④结果不稳定,不同输入顺序或初始质心的选取都会造成聚类结果不稳定。
为了解决以上问题,Krishnapuram 等[12]提出K-Medoids 算法,相较于传统K-Means 算法对噪声的鲁棒性更强,但运行速度较慢,时间复杂度高,因此只适用于数据量较小的文本聚类任务。
4.3 密度聚类算法
密度聚类算法包括DBSCAN 算法、OPTICS 算法、DENCLUE 算法[13]等,此类算法认为能够通过待聚类数据整体分布的紧密程度来确定聚类结构。
DBSCAN 算法聚类速度快,可用于大规模数据聚类,无需手动设定簇的个数,但该算法对参数距离阈值和邻域样本数阈值较为敏感,当数据规模过大时,内存占用大,处理时间较长;OPTICS 算法通过对数据集合中的对象进行排序以得到有序的列表提取信息,生成数据聚类;DENCLUE 算法的思想是利用数学函数形式模拟每个数据对象,该算法在面对噪声数据时仍具有良好的聚类效果,但对参数非常敏感。
4.4 网格聚类算法
网格聚类算法包括STING 算法、CLIQUE 算法、Wave-Cluster 算法[14]等,此类算法的思想是将数据空间划分为网格单元,将对象映射到各单元中,并根据单元中对象的密度划分不同的簇。
STING 算法将数据对象空间划分为矩形单元,形成一个层次结构,使用自顶向下方法删除每层中不相关的网格单元,以此实现数据聚类,具有运算效率高,时间复杂度低的优点,但聚类效果常受网格最底层数据粒度的影响,并且容易忽略网络单元间的联系;CLIQUE 算法适用于高维数据聚类,通过设置网格步长和密度阈值划分空间和密集网格;WaveCluster 算法以处理多维信号的方式聚类数据对象,首先将数据空间划分为网格结构,然后通过小波变换数据空间,最后在变换空间中对密集区进行簇划分。
4.5 模型聚类算法
模型聚类算法包括高斯混合模型(Gaussian Mixture Model,GMM)、自组织映射算法(Self Organized Maps,SOM)[15]等,此类算法的思想是为每个簇构建一个模型,通过数据对象的分布情况计算模型参数,使用合适的模型完成聚类。
GMM 根据样本数据概率密度函数将其划分为独立的簇,各个簇均根据特征混合高斯概率密度分布,基于相应的模型实现数据聚类。该算法以样本分属于不同类别的概率来展示聚类结果,但不同初始值会导致聚类簇数目不一致。
SOM 算法属于一种无监督的神经网络算法,通过自动寻找文本的内在规律与属性,自适应地调整网络结构参数,可获得较高质量的聚类结果,但计算复杂度较高。
4.6 图聚类算法
图聚类算法包括AP(Affinity Propagation)算法、谱聚类(Spectral Clustering,SC)算法[16]等,此类算法的思想是将聚类问题通过邻近度矩阵转换为图,以此划分问题并实现聚类。
AP 算法将数据对象看作为各节点来构建样本网络,通过网络中的各个边传递节点间的“消息”,即吸引度(Responsibility)和归属度(Availability),以此计算聚类中心完成聚类任务;谱聚类算法将数据看作空间中的点,点与点之间用边相连接,距离远的点权重低,距离近的点权重高,通过切分数据点组成的图完成聚类任务。
4.7 模糊聚类算法
模糊聚类算法包括FCM(Fuzzy C-means)算法[17]等,此类算法的核心是利用“模糊集合理论”克服分类中的缺点,以模糊集合论为数学基础实现聚类分析。
FCM 通过数据点的隶属度来确定归属聚类簇,通过建立模糊矩阵及目标函数迭代,构建隶属矩阵来确定数据所属的类。该算法理论简单、应用广泛,但对噪声敏感,容易陷入局部最优。
综上所述,传统的文本聚类算法各有优缺点,表2 为常见算法间的性能比较。

Table 2 Comparison of common text clustering algorithms表2 常见文本聚类算法比较
4.8 融合聚类算法
为了优化聚类效果,不少学者提出融合聚类算法。例如,Fredana 等[18]提出将K-Means 融合投票机制,以解决K-Means 无法确定簇个数的问题,有效提升聚类准确率。Hu 等[19]提出一种融合维基百科增强文本语义的文本聚类算法,在Reuters 数据集中的测评表明,该算法的聚类性能相较于传统方法平均提升16.2%,但聚合型层次聚类算法在文本聚类时的合并操作是不可逆的。吕琳等[20]提出融合蚁群优化算法,使聚合型层次聚类算法能够更好地选择合并点,在UCI 的3 个不同的数据集中的测评表明,该算法的聚类准确率相较于传统K-means 算法均存在不同程度的提升。Ai 等[21]利用粗粒度聚类融合Spark,建立两层余弦相似性聚类模型,相较于HTD-LDA 模型在准确率方面提升19.5%。李玥等[22]提出融合改进量子粒子群优化算法和K-Means 算法,相较于传统K-Means 算法在准确率、召回率及F 值方面均具有较大的提升。潘成胜等[23]为解决K-Means 局部最优解问题,融合改进的灰狼优化算法提高聚类的收敛速度、寻找能力和文本聚类准确率。Bezdam等[24]提出一种融合果蝇优化的K-means 算法,解决了初始质心随机化的问题,在20Newsgroups 等数据集中的测试结果表示,该算法纯度、准确率等指标相较于传统K-means算法均存在不同程度的提升。表3 为部分融合聚类算法与传统聚类算法的效果比较。
5 基于深度学习的文本聚类
5.1 聚类流程
基于深度学习的文本聚类主要包括分词、去除停用词、利用模型得到原始词向量、利用神经网络等模型提取特征、文本聚类等步骤,如图2所示。
5.2 研究现状
现阶段,深度学习已广泛适用于图像处理、语音处理、自然语言处理、计算机视觉等领域。常见的深度学习模型包括卷积神经网络(Convolutional Neural Networks,CNN)、循环神经网络(Recurrent Neural Network,RNN)、长短期记忆网络(Long Short Term Memory,LSTM)、双向长短时记忆网络(BiLSTM)、Transformer 等。
5.2.1 卷积神经网络
卷积神经网络是一种具有卷积操作的前馈神经网络,由卷积层、池化层和全连接层构成。其中,卷积层负责特征提取,利用权重矩阵与卷积核矩阵相乘得到各区域的特征,通常设置多组卷积核以获得不同角度的特征;池化层也称为下采样层,主要对数据进行降维;全连接层则输出最后结果。卷积神经网络特征提取示意图如图3所示。
刘鼎立[25]提出一种基于改进卷积神经网络的文本聚类方法。首先,通过Word2Vec 模型训练得到原始特征词向量,将该向量作为CNN 的输入;然后,将卷积核宽度设置为词向量的维数值以确保扫描范围的完整性,并在卷积层中增加多个空洞率不同的卷积核,对文本特征进行精确提取;接下来,采用最大池化思想将卷积层中的最大向量作为关键特征;最后,通过全连接层输出提取的文本特征。通过在Stack Overflow 英文新闻数据集中的测试结果表明,该方法相较于TF-IDF 提取特征的K-Means 算法,在准确率方面提升22.9%;相较于TF-IDF 算法仅将词频作为唯一的衡量标准,Word2Vec 模型能够从语义角度提取准确代表原始文本的特征向量。

Table 3 Comparison between fusion clustering algorithm and traditional clustering algorithm表3 融合聚类算法与传统聚类算法的效果比较

Fig.2 Flow of text clustering based on deep learning图2 基于深度学习文本聚类流程
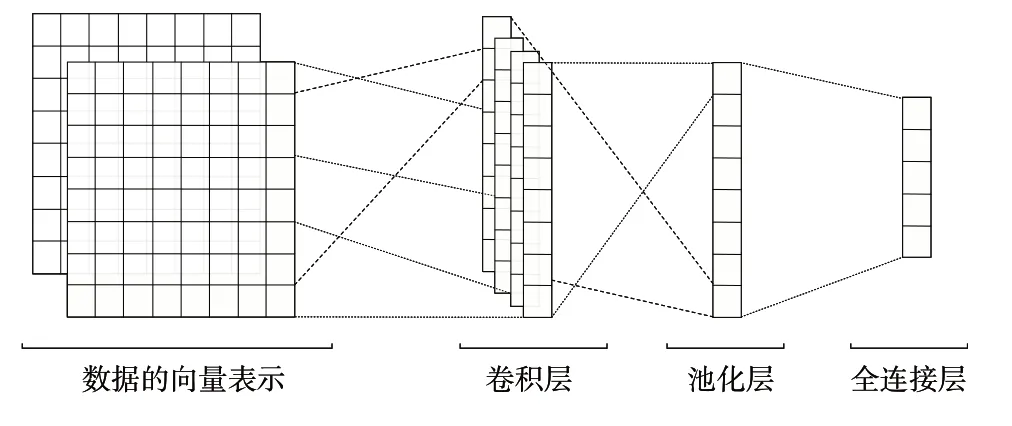
Fig.3 Convolutional neural network feature extraction图3 卷积神经网络特征提取
孙昭颖等[26]提出一种用于短文本聚类的改进卷积神经网络框架。首先,利用Word2Vec 模型学习词与词之间的语义关联,通过多维向量表示单个词,将短文本转化为多维向量,以此改进CNN 的输入;然后,构建高度可滑动的卷积核以提高每个词向量的准确性;最后,将其合理组合成一个完整的特征向量作为短文本的全部特征。该框架改善了短文本因数据稀疏性及高维度特性导致文本聚类准确率低、计算复杂度高等问题。通过由搜狐新闻标题组成的数据集上的测试结果表明,该框架的F 值高于70%,而传统K-Means 算法F值仅为50%左右。
贾君霞等[27]提出一种基于Doc2Vec 和卷积神经网络的特征提取方法。首先,通过Doc2Vec 的DM 模型训练得到句向量,并将该向量作为CNN 的输入;然后,计算卷积核宽度以获取完整的句向量特征;接下来,采用最大池化思想将卷积层中最大向量作为关键特征;最后,通过全连接层输出提取出的文本特征。通过搜狗新闻数据集上的测试结果表明,Doc2Vec+CNN 模型的准确率为77.6%,而Doc2Vec模型的准确率仅为69.4%。
5.2.2 循环神经网络
循环神经网络是一种用于处理序列数据的人工神经网络,作为特征提取工具,RNN 通过模拟神经元的生理模式提取特征,实现模型层与层的相互连接。
由于在长语句应用中RNN 会“遗忘”初始内容信息,因此利用长短期记忆确保信息的完整性。具体的,LSTM在RNN 的基础上增加了一个“门”装置,通过控制“记忆门”与“遗忘门”实现上下文信息的有效存储与更新;BiLSTM 则将前向的LSTM 与后向的LSTM 相互结合,在对词向量进行特征提取时效果更好,能够获得更多的上下文语义关系特征。
万昊雯[28]提出一种短文本聚类模型ST-CNN。首先,利用BiLSTM 挖掘短文本前后文信息,获得深层语义关系依赖和向量化的文本特征;然后,结合改进CNN 模型提取更具代表性的文本低维特征。通过在微博和头条的数据集上的测试结果表明,该模型相较于K-Means 聚类,在ARI与NMI指数方面均存在不同程度的提升。
表4 为部分基于深度学习文本聚类与传统文本聚类算法的效果比较。综上所述,基于深度学习的文本聚类方法可充分利用文本的前后文信息对词向量进行语义扩展,并通过神经网络提取低维且客观的文本特征,以提高聚类效果。

Table 4 Comparison between text clustering based on partial depth learning and traditional text clustering表4 部分基于深度学习的文本聚类与传统文本聚类效果比较
6 结语
本文对文本聚类的研究背景、聚类流程、评价指标、常用数据集和文本聚类算法进行阐述与归纳,将文本聚类技术的发展分为以下3 个阶段:①以传统聚类算法K-Means为代表的文本聚类技术;②采用融合聚类算法的文本聚类技术;③基于深度学习的文本聚类技术。
在经过这3 个阶段的发展后,文本聚类技术在理论研究方面取得了显著成效,在应用实践中获得良好效果。但文本聚类技术的研究仍存在以下不足之处,有待进一步提高和完善:尚未形成标准化数据集和评价指标,不同研究项目所采用的数据集各不相同,难以横向比较不同的研究成果;现有文本聚类算法的准确率仍未超过90%,无法适用于对聚类效果要求较高的应用场景。
目前,基于深度学习的方法在挖掘语义关系、提取文本特征、降低文本维度等方面具有明显优势,但如何在此基础上深入挖掘深度学习在文本聚类相关技术领域的潜力,将是后期首要的研究方向。
