基于YOLOv5的香烟目标检测算法
2023-02-18李丹妮穆金庆
李丹妮,栾 静,穆金庆
(新疆师范大学 计算机科学技术学院,新疆 乌鲁木齐 830054)
0 引言
在计算机视觉领域,目标检测是计算机视觉中的关键课题之一,其目标是寻找目标的边界框并对图像进行分类。近年来,随着深度学习技术的发展,目标检测主流算法的精度和速度都有了很大提升,针对大目标和中目标的检测,检测效果取得了不错的结果,但是在小目标上(通常定义像素32x32 以下的目标)的检测性能仍然不尽人意。由于目标的低分辨率和有限的像素,小目标检测是困难的。其主要原因在于小目标通常缺乏充足的外观信息,无法将它们与背景或相似的目标区分开来。同时,小目标检测还存在着数据集缺乏的问题,PASCAL VOC[1]中包含的目标都是通常大小的目标;COCO[2]中的小目标数量太少且分布不均匀;WIDER FACE、FDDB 小人脸数据集和DOTA、UCAS-AOD 航拍数据集,不具有目标检测通用性[3]。由此可见,小目标检测任务任重而道远。
近年来,深度卷积网络在目标检测领域占据主导地位,如two-stage 方法中的Faster R-CNN[4],one-stage 方法中的SSD[5]、YOLOv3[6]、YOLOv4[7]等。Faster R-CNN 由region proposal network(RPN)组成,首先选择对象的候选边界框,然后利用Fast R-CNN[8]进一步生成准确的对象区域和类别标签,在VOC2012 数据集上达到最高的精度34.9%AP,对于小、中、大目标的精度分别为15.6%AP、38.7%AP 和50.9%AP。SSD 基于一组预设的锚框直接预测不同尺度特征图的目标位置和尺度,以VGG-16 作为主干网络在COCO 数据集上的达到的最高精度为28.8%AP,对于小、中、大目标的精度分别为10.9%AP、31.8%AP 和43.5%AP。YOLOv3 通过对YOLOv2[9]进行了一系列设计更改,例如设计跨尺度预测和使用Darknet-53 作为主干网络进行特征提取,在COCO 数据集上达到33%AP,对于小、中、大目标的精度分别为18.3%AP、35.4%AP 和41.9%AP。YOLOv4 使用CSPDarknet-53 作为主干网络,利用SPP[10]和PANnet[11]结构加强特征提取,使模型的检测精度达到43.5%AP,对小、中、大目标的检测精度分别为26.7%AP、46.7%AP 和53.3%AP。上述几种目标检测算法在大目标、中目标检测中表现出明显的优势,但对于小目标检测,效果却不尽人意。
吸烟现在普遍存在于日常生活中,其不仅影响吸烟者的健康与生命,而且对他人及空气质量的危害也不容小觑。尽管我国在公共场所、公共交通工具等地明令禁止吸烟,采取张贴禁烟指示牌等措施,但防控效果差强人意。针对这一现象,将本文要检测的目标的小目标定为香烟目标。
目前国内对香烟目标检测的文献微乎其微,普遍是对吸烟行为的检测,主要是基于烟雾动态特征、行为识别等。张洋等[12]提出一种基于弱监督细粒度结构与EfficientDet 网络的吸烟行为识别算法。该算法使用弱监督细粒度两级注意力模型框架形成候选区域块,再通过融合选择相关块形成特定物体的物体级筛选器以及定位判别性部件的局部级筛选器结果,对吸烟行为进行有效的识别,算法准确率达到93.10%;徐婉晴等[13]提出一种利用人体骨骼关键点和吸烟行为之间的关系来进行吸烟行为检测的算法,该算法通过检测人体骨骼关键点和脸部关键点计算手腕到嘴角中点和同侧眼睛的距离比,从而判断该比值是否属于吸烟动作的黄金比例来区分是否为吸烟行为,算法准确率达到92%;陈睿龙等[14]提出一种基于卷积神经网络的视频图像特征提取和特征融合的吸烟行为检测方法,该方法通过定位烟头的位置判断是否为吸烟行为。
上述提到的目标检测主流算法及吸烟行为检测相关文献,反映出现阶段小目标检测发展缓慢、检测困难和检测效果不佳等问题。为了改进这些问题,本文提出一种基于YOLOv5 的香烟目标检测算法,融合SENet[15]注意力机制模块,提升复杂场景中香烟目标的检测精度,通过训练数据增强、改变损失函数提高了模型的鲁棒性。
1 YOLOv5目标检测模型
1.1 模型框架
YOLOv5 是一种单阶段目标检测算法,与YOLOv4 相比较,具有均值权重更小、训练时间更短、检测速度更快的特点。YOLOv5 的检测策略为:将输入的图像分为若干网格,包含检测目标的网格负责预测目标位置,最终输出与真实框契合度最高的预测框。YOLOv5 模型包括输入端、Backbone、Neck、Head 四部分。输入端包括Mosaic 数据增强,将4 张图像随机缩放、随机裁剪、随机排布。Backbone 为特征提取部分,包括卷积层、C3 和SPPF结构:卷积层中封装了分组卷积、BN 层以及SiLU 激活函数三个功能;C3 模块简化了之前的BottleneckCSP 结构,使得模型捕获特征的能力增强;SPPF 结构替换了SPP[10](空间金字塔池化)结构,使模型的前向计算和反向计算速度提升了约1.5 倍。Neck 中采用了特征金字塔FPN 与路径聚合网络PAN 结合的结构,将常规的FPN 层与自底向上的特征金字塔进行结合,将所提取的语义特征与位置特征进行融合,同时将主干层与检测层进行特征融合,使模型获取更加丰富的特征信息。Head 输出预测结果。
YOLOv5 结构可以抽象理解为采用FPN+PAN 结构的组合,采用了大量的卷积和C3 结构。卷积层结构包括普通卷积conv、BN 层和SiLU[16]激活函数。C3 结构是BottleneckCSP 结构减少一个卷积层得到。BottleneckCSP 与CSP结构相似,CSP 结构由Chien-yao Wang 等[17]提出的,在denseNet 特征融合结构的基础上对输入特征图像进行分割,目的是为了减少梯度重复计算,提升模型的速度。YOLOv5模型结构如图1所示。
1.2 YOLOv5在香烟目标检测中的缺陷
YOLOv5 模型现阶段已有了良好的目标检测性能和预测速度,但应用于香烟目标的识别检测,仍然存在以下缺陷:
(1)主干网络有较多的C3 结构和卷积层,其卷积操作中的卷积核包含大量参数,导致模型中含有大量参数,降低了模型的计算速度。因为香烟目标较小,所以在特征提取过程中通过大量的卷积运算之后,香烟目标的特征信息在图片较为全面的特征信息中无法凸显,使模型对类似于香烟等小目标检测速度下降。
(2)当预测框在真实框内部且两者大小恒定时,GIoU[18]函数的值即为并交比,无法实现高精度的定位。GIoU 是一种距离函数,由式(1)所示,其中C 为预测框和真实框的最小外接框面积,B 为预测框,Bgt 为真实框(groud truth)。


Fig.1 YOLOv5 model structure图1 YOLOv5模型结构
其中IoU(交并比)为预测框与真实框交集与并集的比值,由式(2)所示。两个框相离时,并交比为0;当预测框位于真实框内部但两者不等时,并交比的值恒定为B/Bgt;最理想情况为预测框和真实框完全重叠,并交比的值为1。
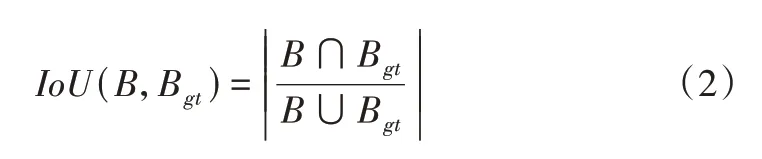
定位损失函数LGIoU 公式由式(3)所示:

在GIoU 函数中,真实框与预测框距离越远,C值越大,GIoU 无限趋近于-1,定位损失函数LGIoU(B,Bgt)无限趋近于2。显而易见,应用GIoU 函数存在一个问题:当真实框包含预测框且两者大小固定时,其并交比恒定为预测框与真实框面积的比值,无论预测框在真实框的任何位置,损失值都不变。
2 改进的YOLOv5模型
2.1 主干网络引入注意力机制
注意力机制(Attention Mechanism)源于对人类视觉的研究,其目标是从众多信息中挑选出对当前任务目标更为关键的信息。本文在对香烟目标识别中引入注意力机制,赋予香烟目标更大的权重,让模型更关注与香烟目标有关的重要区域。在多数实验中,在模型中引入注意力机制会显著提高模型性能,但引入位置并没有固定的要求,只要对模型性能有改进即可。
本文在通道维度引入Squeeze-and-Excitation Networks(SENet)网络结构,将其插入到现有的多种网络结构中,都取得了较好的实验效果。SENet 采用了一种全新的特征重标定策略,通过自学习方式自动获取每个特征通道的权重,并按照此权重来提升有用的特征,抑制对当前检测任务作用不大的特征[15]。其结构如图2所示。

Fig.2 Squeeze-and-Excitation network structure图2 Squeeze-and-Excitation 网络结构
该结构中的两个关键操作为Squeeze 操作和Excitation操作。给定一个输入X,其特征通道数为C',宽为W',高为H',经过Backbone 中的卷积操作后得到特征通道数为C、宽高为W、H的特征U。此后的操作与传统的CNN 不同:首先是Squeeze 操作,它通过全局池化的方式,将H×W二维向量变成一个实数,且输出的维度和输入的特征通道数相匹配;其次是Excitation 操作,该操作使用两个全连接层,组成一个Bottleneck 结构来建模通道间的相关性,为每个通道生成一个权重值;最后为Reweight 重标定操作,即通过scale 乘法,将Excitation 操作输出的权重值,即每个特征通道的重要性,逐通道加权到之前的特征U上,完成在通道维度上对原始特征的重标定[19]。
本文将SEnet 应用于Backbone 中,即在Backbone 的每一个C3 之后插入一个SEnet 结构,具体结构如图3 所示。原始特征图X 输入到Backbone 结构中,每经过一次C3 卷积操作,就进入到SEnet 结构中。使用全局平均池化作为Squeeze 操作。Excitation 操作包含两个全连接层FC、ReLU激活函数和Sigmoid[16]函数。第一个全连接层FC 对通道数进行降维,衰减因子为r,此目的是为了降低后续的计算量;第二个全连接层将通道数恢复到原来的维度。使用两个全连接层可以更好的拟合通道间复杂的相关性,具有更多的非线性,并且减少了计算量和参数量。Sigmoid 函数将参数值转化为一个0~1 间的归一化权重值。最后通过scale 乘法操作将归一化的权重值逐通道加权到之前的特征上[20]。
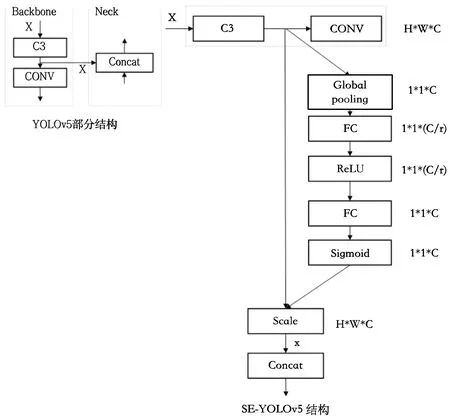
Fig.3 SE-YOLOv5 structure图3 SE-YOLOv5结构
2.2 改进边界框定位损失函数GIoU
为解决上述GIoU 存在的问题,即当真实框包含预测框且两者大小固定时,其并交比恒定为预测框与真实框面积的比值,无论预测框在真实框的任何位置,损失值都不变。本文采用CIoU[21](Complete-IOU),由式(4)所示。与GIoU 相同的是,CIoU 还是需要找到最小外接框,与 GIoU不同的是,CIoU 进一步强调了距离的重要性和预测框与真实框长宽比例问题。

其中,ρ2为预测框和真实框中心点距离的平方,c2为最小外接框对角线的平方,ν为预测框和真实框长宽比例差值的归一化;α 为平衡长宽比例造成的损失和IoU 造成的损失的平衡因子。
CIoU 中归一化中心点距离的最小化导致快速收敛,重叠区域和纵横比的一致性有助于更好地匹配两个框。
3 实验及结果分析
本文采用的图像处理单元(GPU)为TESLA K80,依赖pytorch1.7.0、python3.7,框架为改进的YOLOv5。共设计4组实验,分别在自制香烟数据集下测试传统YOLOv5 和两个改进部分对香烟目标检测性能的影响。在COCO test 数据集下与小目标检测经典模型SSD 和DSSD[22]进行比较,综合判断改进模型的性能。
3.1 数据集
现有的香烟目标检测数据集较少且数据量不大,本文数据集均来源于互联网,来源不一,通过网络爬虫技术,爬取百度和谷歌网站上的香烟、吸烟行为图片,截取网络视频及影视作品中的香烟和吸烟动作,完成了实验数据集的制作。数据量共6 808 张,训练集(验证集)和测试集按照4:1 的比例划分,其中训练集(验证集)包含图片5 447 张,验证集包含图片1 361 张。为保证数据与实际场景相符,以保证检测模型的适用性,数据集包含各个场景的真实图像,如工作、生活、街头等,其中包括香烟数据、手拿香烟或香烟相似物数据、无香烟数据,数据丰富,具有科研价值。数据集示例如图4所示(彩图扫OSID 码可见,下同)。
使用Github 上的开源标注工具YOLO Mark 进行香烟目标数据标注。标注参数为五元组(class,x,y,w,h),其中class表示检测目标类别;(x,y)表示真实框的中心点坐标;w,h表示真实框的宽度和长度。x,y,w,h需先经过归一化处理成0~1之间的数值。香烟目标标注如图5所示。
3.2 评价指标

Fig.4 Dataset example图4 数据集示例

Fig.5 Cigarette target annotation图5 香烟目标标注
本文使用F1值和mAP作为改进模型的评价指标[20]。F1值是精准率和召回率的调和平均,用于综合反映整体指标,F1较高时表明实验所用方法有效,由式(5)所示。mAP值越高,表明模型的检测效果越好,由式(6)所示,

其中,Precision为查准率,Recall为查全率;AveragePrecision(c)为一个类c的平均精度,它表示在验证集上所有图像对于类c的Precision之和与所有包含类c目标的图像数量的比值;N(classes)表示所有目标类别数量。
3.3 香烟目标检测实验设计与检测结果分析
3.3.1 改进部分对模型检测性能的影响
改进模型的训练结果如图6 所示。可以看出,训练前期损失值下降速度较快,随着训练次数的增加,损失曲线降幅变缓,最终趋于平稳。
图7 采用可视化方式显示出数据集中目标的宽高比。可以看出,归一化后,香烟目标的宽高比普遍在0.1左右,说明数据确实很小,也会面临模糊问题,导致数据质量降低。
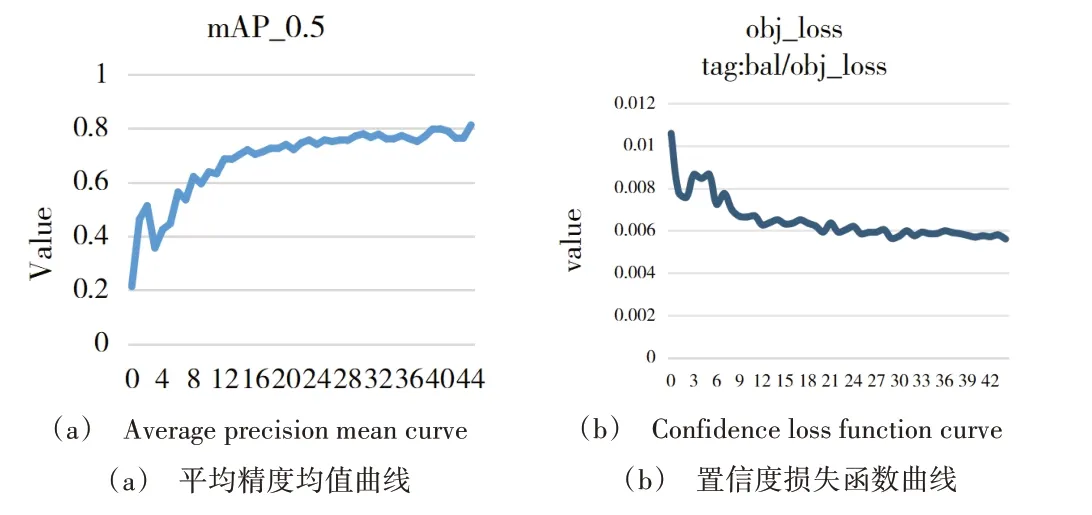
Fig.6 Model training results图6 模型训练结果

Fig.7 Visualization of target aspect ratio distribution of cigarettes图7 香烟目标宽高比分布可视化
为了验证改进方法对传统YOLOv5 的性能影响,本文对比了引入注意力机制和改进损失函数的模型与传统YOLOv5 模型的实验效果,每组实验的训练参数相同,比较结果如表1。由表1 可知,SEnet 注意力机制的引入能够在通道维度对特征图的每个通道进行特征压缩与自学习,实现对原始香烟特征的重标定,加大重要特征的权重值;改进损失函数GIoU 为CIoU 作为定位框损失函数,解决了GIoU 函数在预测框位于真实框内部的情况下退化为IoU的问题,提高了模型定位的精确度。改进后模型的mAP 值为0.81,比传统YOLOv5 的mAP 值提高0.104;F1 为0.797,比传统YOLOv5 模型提高0.103,且改进模型在训练中需要更少的显存。

Table 1 Detection performance of the improved model表1 改进模型的检测性能
图8 为改进前后检测性能对比。传统YOLOv5 模型对香烟目标的检测效果如图8(a)所示,改进模型对香烟的检测效果如图8(b)所示,改进后模型的识别效果有了明显提高。

Fig.8 Comparison of improved model and YOLOv5 detection results图8 改进模型与YOLOv5检测结果比较
3.3.2 改进模型与主流目标检测模型的性能比较
目前小目标检测领域主流的检测模型有R-FCN、SSD、DSSD、RetinaNet[23]等,采用mAP 指标作为每种检测模型的评估指标,在COCO-test 数据集上做对比实验,实验结果如图9 所示,与其他小目标检测模型的效果对比如表2 所示。由表2 可知,本文提出的改进模型相比于SSD、DSSD 等主流的小目标检测模型具有更好的检测性能。在保证检测速度的同时,精确度有了一定的提高,与主流模型相比具有一定优势。
4 结语
本文针对公共场所中吸烟行为防控效果差的问题,提出了一种基于传统YOLOv5 的改进的香烟目标检测模型。该模型提高了模型的识别速度,降低了卷积计算量。一方面,为了解决由于香烟目标较小,在特征提取过程中通过大量卷积运算之后特征信息不突出的问题,在主干网络Backbone 结尾加入SEnet 注意力机制,实现在通道维度上原始特征的重标定,通过自学习的方式增大了香烟目标重要特征通道的权重值。另一方面,为了解决当预测框在真实框内部且两者大小恒定时,GIoU 函数的值退化为并交比,无法实现高精度定位的问题,本文使用CIoU 作为定位框回归损失函数,进一步强调了距离的重要性以及预测框与真实框长宽比例问题,其中归一化中心点距离的最小化处理方法使检测速度快速收敛,重叠区域和纵横比的一致性有助于更好地匹配真实框和预测框。

Table 2 Performance comparison with main target detection models表2 与主流小目标检测模型性能对比

Fig.9 Detection accuracy of SE-YOLOv5 in COCO-test dataset图9 SE-YOLOv5在COCO-test数据集的检测精度
通过对比实验,验证了本文提出的改进模型能够准确、快速地检测出生活、工作等场景图像中的香烟目标。本文方法的mAP 达到0.81,比YOLOv5 的mAP 值提高0.104,F1 值达到0.797,比YOLOv5 模型提高0.103;在COCO test 数据集上达到62.1%mAP,比RetinaNet 等小目标检测网络提升了3 个百分点。实现了检测效果的高准确性和高速率,检测性能在自制数据集上高于目标检测领域主流的目标检测模型,可为吸烟行为管控提供有益的帮助。未来将进一步提高模型的检测速度,扩大数据量,进一步降低误检率,提升模型在实际生活应用中的检测效果。
