基于改进LeNet-5网络的污泥沉降比检测研究
2023-02-18王告
王 告
(中冶华天工程技术有限公司 互联网+研究院,江苏 南京 210000)
0 引言
工业废水处理[1]一直是当前以及未来的重点研究领域,污泥沉降比(SV)是指将曝气池活性污泥混合液倒进量筒中至满刻度,静置一段时间后沉淀污泥和混合液的体积比,在活性污泥法运行中,污泥沉降比是需要测定的主要项目。传统的污泥沉降比检测以人工为主,工作量大且不可控,会对结果会造成不可统计的误差。神经网络技术目前广泛应用于图像处理领域,Lou 等[2]通过分析污水处理工艺并结合人工神经网络和数学回归分析法建造污泥容积指的数据驱动模型,该方法可极大提高计算精度,但是数据驱动模型的大部分输入参数本身就不易测量,从而导致其应用性大为降低。基于粗糙集-BP 神经网络的污泥测量模型得以改进[3],在一定程度上改善了神经网络性能,但不能实现测量的实时性。郭晓燕[4]利用改进粒子群算法优化RBF 神经网络对污泥容积指进行预测,并用实验数据证明了有效性,此方法是RBF 神经网络的一种尝试,虽然展现了很好的预测效果,但是每次实验都需要调整辅助变量值且无法做到实时性。针对以上研究方法中出现的问题,本文以传统的LeNet-5 神经网络为研究对象,参考Inception-V3 网络搭建特点对其进行改进,训练之前先对数据集进行预处理,再对目标进行颜色阈值判定,并在训练过程中提出一种轻量化特征重用网络模型和正则分类,经过大量实验调参和测试,最终准确率可达96%以上,实验中以100 张图片作为实验对象,结果统计每张图片的平均识别时间只需要0.46s,实时性问题也得到满足。
1 LeNet-5神经网络
LeNet-5[5]模型于1998 年被提出,它是第一个成功应用于数字识别问题的卷积神经网络。LeNet-5 模型总共有7层,模型结构如图1所示。
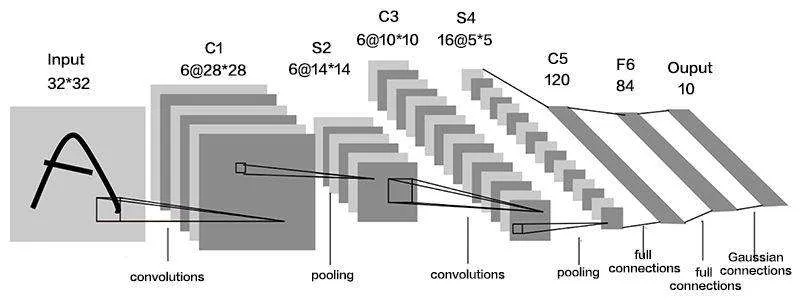
Fig.1 Network structure of LeNet-5图1 LeNet-5网络结构
LeNet-5 神经网络包含1 个输入层、3 个卷积层、2 个池化层以及1 个全连接层。每层都包含可训练参数,每个层有多个Feature Map,每个FeatureMap 通过一种卷积滤波器提取输入的一种特征,由于LeNet-5 神经网络是最早应用于数字识别的网络,并且对于单个数字的识别效果可达99%以上。由于本次实验需要研究的是量筒上的数字识别,因此对该网络进行改进并完成测试可以不破坏原有网络结构,将并联搭建方式引入网络,并根据训练集的种类和数量进行层数扩充,然后进行参数优化从而得到最优训练结果。
1.1 LeNet-5模型优化
传统的神经网络改进算法中,一般都是以串联的方式增加卷积层池化层,这样造成的后果是不但准确率不会有太大改善而且增加了网络训练时间。本文参考Inceptionv3[6]网络搭建特点,将并联式搭建理论引入LeNet-5 神经网络中,提高了神经网络获取多维特征的能力,而且由于并联式特征提取可以有效地减少梯度消失问题,增强了模型的健壮性。结合训练集的数量及所分种类,最终将LeNet-5 神经网络由7 层扩充到14 层,将串联和并联方式进行组合,并且对于卷积核的尺寸和个数也作了改进,具体改进内容如下:①传统的LeNet-5 神经网络只有7 层,本文改进后的网络深度提高到14 层,并采用Dropout 策略减少由于训练参数过多而导致的过拟合现象;②使用BN 层,BN 层[7]的作用是对数据集进行归一化处理,解决内部变量转换从而改善前向传播过程中的梯度消失问题;③对网络结构增加了两个并联层,增强了复杂图片特征提取能力,增强了模型健壮性;④对于激活函数的选取,LeNet-5神经网络的激活函数是Sigmoid,在反向传播过程中会出现导数为0 的情况,会导致误差无法向前传播,因此只能完成浅层次学习。ReLU 激活函数[8]反向传播过程中可以很快地将梯度传输到上层网络,加快收敛速度。
在卷积核数量和类别选取上。传统的LeNet-5 神经网络选择5*5 的卷积核,对于多维特征难以完整提取出来。为此,本文将5*5 卷积核替换为两个3*3,并且将3*3 的卷积核转变为1*3 和3*1 之间的组合进行表示,提高网络对特征获取的能力[9]。
改进后的LeNet-5神经网络模型如图2所示。

Fig.2 Improved network structure图2 改进后的网络结构
如图2 所示,修改后的神经网络中一共包含14 层,增加了两个并联结构Inception 层,提高了获取多维特征的能力。并联层结构如图3所示。

Fig.3 Schematic diagram of parallel layer structure图3 并联层结构
如图3 所示,Inception 层主要包含3 个卷积层和1 个池化层,卷积核conv_filter1、conv_filter2、conv_filter3 尺寸分别为1*1、3*3 和5*5,卷积核以并联的形式进行连接,并且在每个卷积核与1*1 进行组串联。以往研究结果表明,1*1 的卷积核可以很好地降低模型参数。并联的方式打破了传统直接增加深度造成的过拟合问题,并且可以很好地增强多维特征提取能力,提高实验准确度。
1.2 模型正则
对于每一个训练examplex,模型计算每个Labelk∈{1...K}的概率为:p(k|x)=,其中zi是logits或未归一化的对数概率[10]。训练集上单个example标签的实际概率分布(Ground-TruthDistribution)进行归一化处理:,为了简洁计算,忽略p和q对x的依赖。定义单个example上 的crossentropy为l=最小化crossentropy等价于最大化一个标签的对数极大似然值的期望(expectedlog-likelihoodofalabel),这里标签根据q(k)选择。crossentropy损失函数关于logitszk处处可微,因此可以使用梯度下降训练深度网络。其梯度有一个相当简单的形式:=p(k) -q(k),其范围为-1~1。
对于一个真实的标签:对于所有k/=y的情况,要求q(y)=1。在这种情况下,最小化交叉熵[11]等价于最大化正确标签的对数似然。对于一个标签为y的examplex,最大化q(k)=δk,y时的对数似然,这里q(k)=δk,y是狄拉克δ函数。在k=y时,狄拉克函数等于1,其余等于0。通过训练,正确logit的zy应该远大于其他zk(z/=y),zy一般取值较大,但是容易引起过拟合:如果模型学习将所有概率分配到真实标签的逻辑单元上,泛化是没有保证的。鼓励最大logit和其他logit的差异(KL距离)越大越好,结合有界梯度(doundedgradient),降低了模型适应能力。直觉上,适应能力降低的原因应该是模型对其预测太过于自信。如果目标是最大化训练标签的对数似然,那这很可能不是预期所需,它对模型进行了正则并且使得模型的适应性更强。考虑一个独立于训练examplex的标签分布u(k),和一个smoothing参数ϵ。对于一个训练标签为y的example,替代标签分布q(k|x)=δk,y为:
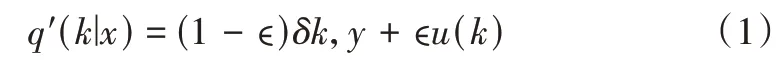
新的分布是原始标签分布和一个指定分布u(k)的混合,两部分的权重为1 -ϵ。使用标签的先验分布作为u(k)=1/K,LSR 的另一种损失函数可以通过研究交叉熵损失函数获得:
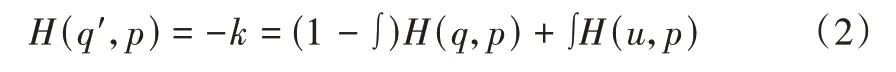
等价于用一对损失函数H(q,p)和H(u,p)代替单个损失函数H(q,p)。损失函数的第二项惩罚了预测标签的分布和先验分布u的偏差with相对权重。因 为H(u,p)=DKL(u∣p) +H(u),所以该偏差可以被KL散度捕获。当u是均匀分布时,H(u,p)衡量的是预测分布p和均匀分布之间的相似性,该相似性可用负熵-H(p)加以衡量。
2 实验过程
2.1 实验流程
本次实验采用的设备包括显示器、工作台、计算机和海康威视摄像头,具体实验流程如图4所示。

Fig.4 Experimental process图4 实验流程
(1)数据采集。通过现场人员在废水池中取得,每次实验将将1 000ml 废水置于量筒中作为实验对象,利用海康威视监测0~30min内污泥沉降比变化。
部分数据集展示如图5所示。

Fig.5 Partial training dataset display图5 部分训练集展示
(2)图像处理。主要是图像预处理,由于图像背景固定,因此预处理重点主要包含目标增强[12]、裁剪、滤波二值等,以更好地突出目标。
(3)区间判定。计算目标在图像中的高度,通过颜色阈值判定及比例确定污泥所处的大致区间。
(4)图像训练。将处理后的训练集图像放进改进后的神经网络中进行训练,通过大量实验调参,优化模型参数。
(5)图像分类。将测试图片进行模型预测,得到分类结果。
2.2 实验结果
基于深度学习的污泥沉降比检测主要是对传统的LeNet-5 神经网络进行合理的扩充和优化以完成图片分类。本文将此次研究的15 类刻度标尺图片以7∶2∶1 的形式算出的训练集、验证集和测试集的数量全部投入训练,并得出梯度及损失函数变化如图6所示。
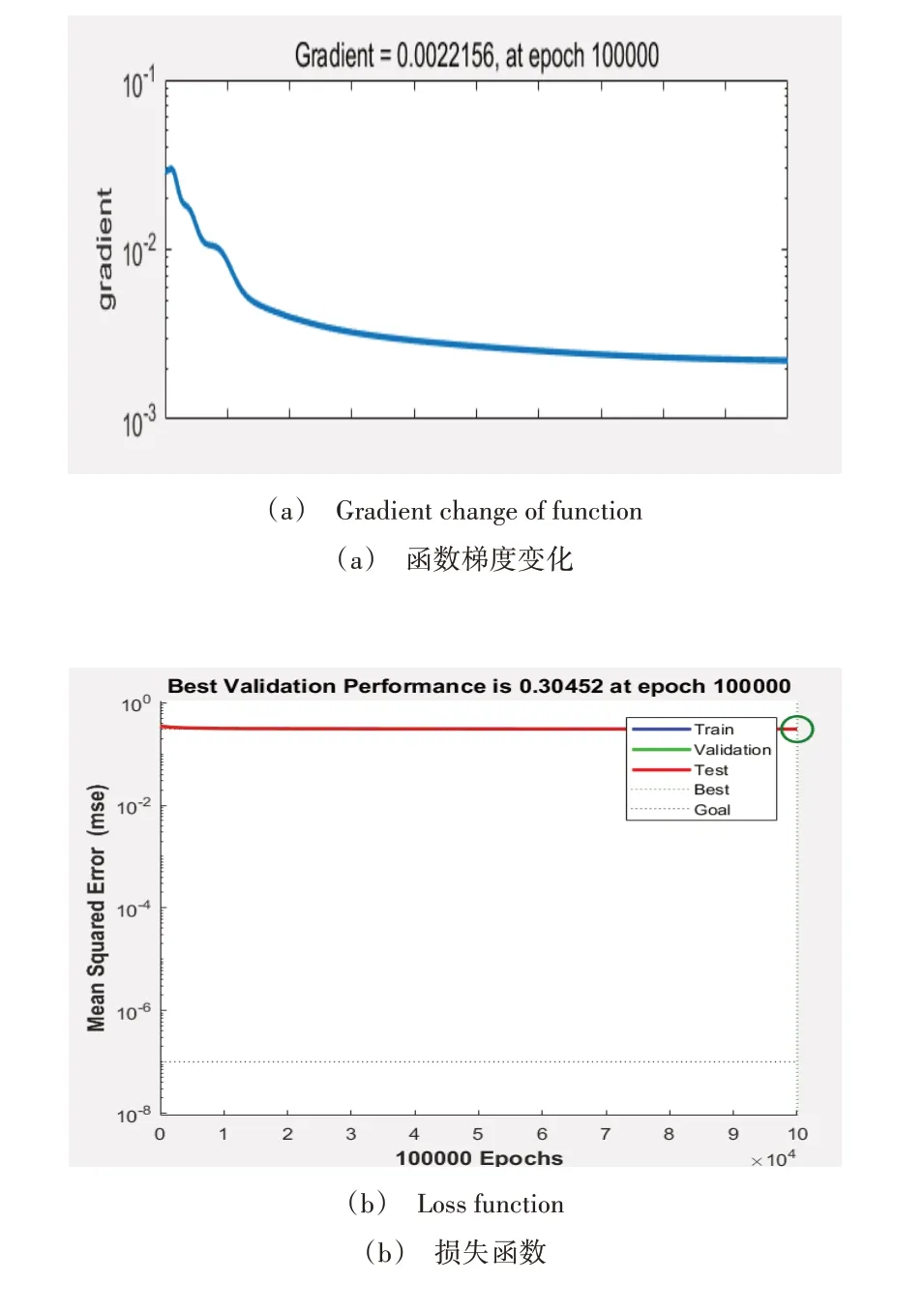
Fig.6 Gradient and loss function change图6 梯度及损失函数变化
根据实验结果可知,改进后的神经网络训练105轮梯度和损失函数已经趋于稳定。最终测试准确率可达96%以上,测试集训练过程展示如图7所示。

Fig.7 Training process display图7 训练过程展示
由于本次使用的数据集对背景干扰未做太大处理,且拍摄角度有反光,因此肉眼所见效果不佳,但是由于训练集和测试集都处于同一环境,在标签确定下的情况,系统仍然可以对图片进行很好的分类识别。基于C/S 结构[13],借助后端语言Python 和Django 框架搭建系统并进行显示,随机挑选一张图片的测试结果如图8所示。

Fig.8 Identification results of sludge sedimentation ratio图8 污泥沉降比识别结果
识别结果展示中,左边为系统对图片的识别预测,一共设有4 个值,分别是590ml、600ml、580ml、540ml 以及对应的概率,概率最大的值则被认为是该量筒的读数,右边为该污泥的照片。可以看出,该系统很好地识别出了读数,虽然有反光影响,但是由于训练时增加了该环境下的训练集,因此当测试集出现这种情况时系统依然可以准确识别出来。为了验证准确率,分别选取原神经网络、改进后的神经网络、AlexNet 和Vgg-16 4 种网络进行实验,在100、150、200的测试集进行测试,结果统计如表1所示。

Table 1 Recognition rate statistics表1 识别率统计
结果表明,改进后的神经网络对测试集的识别准确率基本维持在97%左右,在4 种神经网络的对比实验中,改进后的神经网络的识别率高于其他3 种,与Vgg-16 接近,但是Vgg-16 网络复杂、训练难度大,无疑会增加训练成本。因此性能上还是改进后的网络更加满足条件,并且随着数据集的增大,准确率可以保持稳定,模型健壮性也有所增强。
3 结语
本文提出了基于改进的LeNet-5 的神经网络污泥沉降比检测研究,通过参考Inception-v3 网络搭建特点对LeNet-5 神经网络进行改进,引入并联式搭建理论提高模型并行获取特征的能力,并在训练过程中引入轻量化特征重用网络模型和正则分类器模式消除训练过程中Label-Dropout 的边缘效应。经过大量实验结果表明,在相同数据集上改进的神经网络识别率达97.2%,远高于原网络训练结果。虽然此次训练集背景并未对背景多做处理,但是使用深度学习的方法仍然可以准确加以识别。后续将继续参考其他神经网络搭建特点对该网络进行优化[14],并且对数据集进行增强处理[15],提高训练速度和准确率,实现在其他复杂环境下真正意义的智能化操作。
