基于生成对抗网络的鱼眼图像校正方法
2023-02-18祁自建聂亚杰张嘉伟
祁自建,聂亚杰,张嘉伟
(中国船舶集团有限公司第七一八研究所,河北 邯郸 056027)
0 引言
随着科技的进步,鱼眼镜头被广泛应用于视频监控、自动驾驶和医疗检测等领域。然而鱼眼镜头捕获的图像不适用于为大多数透视图像设计的计算机视觉技术,如目标追踪、运动估计、场景分割等任务[1]。因此,鱼眼图像的校正问题成为了研究热点。
在鱼眼镜头出现后的几十年间,人们尝试用各种校正算法校正鱼眼图像。基于投影模型的鱼眼图像校正算法有两种不同模型:一种是球面投影模型,另一种是抛物面投影模型。运用球面投影模型校正鱼眼图像的关键是找到鱼眼图像的光学中心和球面模型半径,但在实际应用中两者很难被找到。一般都是假设图像的中心点为该图像的光学中心,半径取鱼眼图像中有效圆形区域的半径。抛物面模型复杂,在实际应用中模型实现困难。杨玲等[2]提出一种应用经纬映射的鱼眼图像校正方法,不需要标定参数即可将半球鱼眼图像校正为正常图像;Kannala 等[3]假设图像光心到投影点的距离和投影光线与主轴之间夹角的多项式存在比例关系,是目前比较受欢迎的模型;廖士中等[4]通过选取图像中合适的控制点,然后利用多项式和双线性插值方法进行鱼眼图像校正。
基于标定的校正算法主要是通过外部设备对鱼眼相机的内外参数进行标定,借助标定板,通过标定板的真实坐标与鱼眼成像平面坐标之间的坐标转换,实现鱼眼图像校正。该方法校正精度高,但对实验设备精度要求高[5]。Chan 等[6]提出一种改进的自动棋盘检测算法,以避免原始约束和用户干预,然后采用自适应自动角点检测,将鱼眼成像函数用泰勒技术展开,根据最大似然准则进行非线性细化,完成鱼眼图像的标定与校正;Radka 等[7]提出一种用于鱼眼标定的非中心模型,该模型是对之前中心模型的扩展,使用该模型不需要提供详细的鱼眼镜头参数;Lu 等[8]提出一种鱼眼镜头无模型校正方法,即基于单幅图像的启发式B-spline 模型;吴军等[9]以待标定鱼眼相机近似垂直棋盘格获取的单张影像为对象,通过椭圆轮廓约束、灭点约束等多种几何约束分阶段求解相机参数;皮英东等[10]利用直接线性变化DLT 和鱼眼影像上标定的控制点信息快速求解球面投影参数。
卷积神经网络的出现给鱼眼图像校正带来了新的解决方案,Rong 等[11]在模拟鱼眼图像数据集上训练Alexnet,将鱼眼图像畸变参数分为401 类,通过网络获取畸变参数来纠正失真图像,但有限的离散参数导致训练后的网络在复杂的鱼眼图像校正上表现不佳;Yin 等[12]提出一种上下文协作网络,在网络中添加高维特征和语义特征,但由于高维特征、语义特征只能提供有限信息,在鱼眼图像校正中效果较差;薛村竹[13]提出一种明确的几何约束用来改善鱼眼图像的网络感知,该网络依靠鱼眼中曲线校正后应该为直线的假设,对于图像中线段较少的网络校正效果差,而且需要边缘标签、失真标签和正常图像的多个标签,针对边缘标签的边缘网络还要进行预训练;Sha 等[14]通过简化抛物线模型,将其与神经网络结合在一起进行鱼眼图像校正,并在网络中增加图像超分辨率结构,以解决校正图像分辨率较低的问题;李有强[15]提出一种基于卷积神经网络的鱼眼镜头标定方法,该方法通过改进U-Net 网络校正鱼眼图像圆弧坐标作为前置网络,然后通过残差网络进行鱼眼镜头内部参数预测,获得参数后再根据立方盒展开原理对图像进行校正展开;Nobuhiko 等[16]通过神经网络学习视场超过180°的鱼眼图像的外在参数(倾斜、滚动角)和内在参数(焦距),完成参数学习后进行鱼眼图像校正。
基于生成的方法主要是通过生成对抗网络(Generative Adversarial Network,GAN)直接生成校正图像。Liao等[17]提出自动校正径向失真生成对抗网络,该网络是第一个用于径向失真校正的对抗网络,采用无监督的学习方式,通过学习失真图像与正常图像的分布,让失真图像的分布通过网络后逐渐靠近正常图像的分布。然而,该网络在同时重建图像内容和结构方面负担过重,导致校正后的图像内容模糊,图像结构无法完全校正。之后Liao 等[18]又提出一种针对单张图像,不区分生成鱼眼图像的模式进行失真校正的方法,主要是将鱼眼图像的生成模型统一到失真校正图像上,图像上每一个点代表当前位置的失真程度,该方法更准确地对扭曲的结构进行了校正。然而,使用GAN 进行校正时,级联网络容易导致图像细节丢失,一般跳跃连接会导致失真扩散。Yang 等[1]针对跳跃连接带来较大误差的问题,将特征级校正引入网络,在生成网络的不同层中使用外观流对图像特征进行校正,以此减少跳跃连接带来的误差。
综上可知,基于深度学习的鱼眼图像校正算法都聚焦在GAN 网络,而GAN 网络存在跳跃连接带来的误差增大问题。本文通过在生成网络的编码器中添加畸变参数预测模块,并将预测的畸变参数嵌入到生成网络的解码器中,以此减少跳跃连接带来的误差。最后通过实验对比,分析其在数据集上的表现。
1 研究方法与相关理论
1.1 生成对抗网络
生成对抗网络是2014 年由Goodfellow 等[19]提出的一种新型神经网络结构,主要结构如图1 所示。其包含生成器G 和判别器D,生成器的主要任务是生成能够欺骗判别器的图像,让判别器无法判断是生成器生成的图像还是真实存在的图像。判别器的任务则是尽量识别出图像是生成的还是真实存在的。
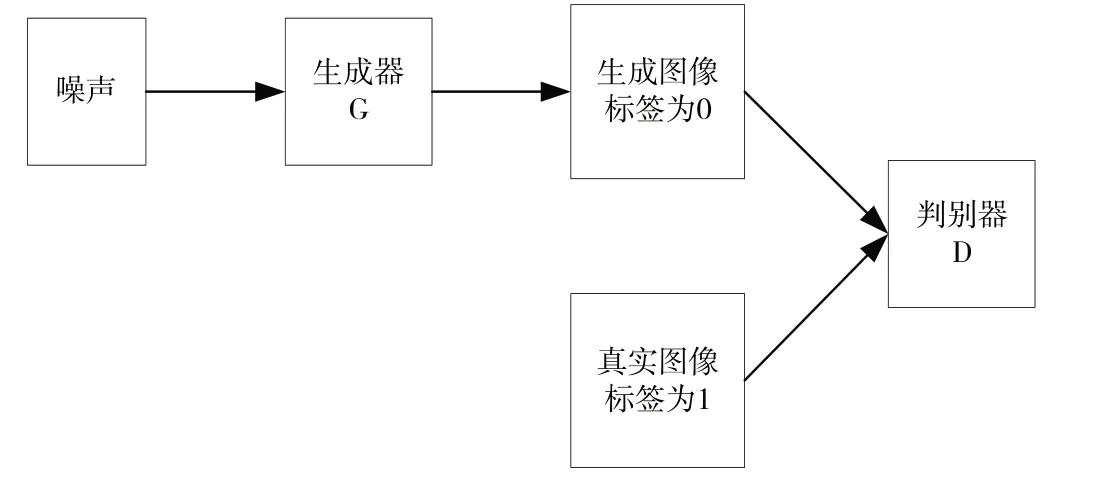
Fig.1 Generative adversarial network architecture图1 生成对抗网络结构
在网络训练期间,生成器努力生成可欺骗判别器的图像,而判别器试图识别出由生成器生成的“假图像”。两个网络互相交替训练,因此该训练过程被称为对抗训练。通过对抗训练让生成图像的分布逐渐靠近真实图像的分布,当判别器无法分辨真假图像时,生成对抗网络训练完成,其训练过程如下:
假设:pdata表示真实数据分布,pz表示生成器分布,x 表示从真实分布采样的样本,z 表示从生成器采样的样本。具体训练过程为:①生成器G 是一个生成图像的网络,接收一个随机噪声z,通过该噪声生成图像,记作G(z);②D是一个判别网络,判别一张图像是否是真实的,其输入参数x 代表一张图像,输出D(x)代表为真实图像的概率。若为1,则代表100%为真实图像;若为0,则代表不是真实图像;③一般情况下是先多训练几次生成器,然后训练判别器。重复几次过后,得到最后的生成模型。
生成对抗网络的损失函数如式(1)所示。式(1)中的min max 可以理解为更新判别器时需要最大化公式,更新生成器时需要最小化公式。这是一个寻找纳什均衡的过程,寻找其最小、最大上界。
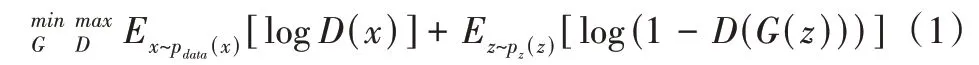
判别器模型参数更新时,对于来自真实分布pdata的样本x 而言,希望D(x)的输出越接近1 越好,即logD(x)越大越好;对于噪声z 生成的数据G(z)而言,希望D(G(z))尽量接近0,即log (1 -D(G(z)))越大越好。
生成器模型参数更新时,希望G(z)尽可能与真实数据一样,即pz=pdata,因此希望D(G(z))尽量接近1,即log (1 -D(G(z)))越小越好。
生成对抗网络经过多年发展,已经演变出多种不同网络,例如条件生成对抗网络,将无监督的生成对抗网络变成半监督或者有监督的模型。深度卷积网络近年来备受研究人员关注,董访访等[20]使用深度卷积神经网络进行品牌服装图像检索;程广涛等[21]用深度卷积神经网络进行烟雾识别。神经网络中的池化层不可逆,深度卷积生成对抗网络将对抗网络与深度卷积神经网络相结合,在下采样过程中不使用池化层,而是选择改变卷积层步长的方法进行下采样,上采样过程中的反卷积网络也是采用改变反卷积层步长的方法进行上采样。
1.2 鱼眼图像数据集
在使用卷积神经网络进行鱼眼图像校正时,要求数据集规模较大,因此数据集一般采用合成鱼眼图像的方式进行制作。合成鱼眼图像的映射形式包含两种:除法模型与多项式模型。
1.2.1 除法模型
在图像坐标系中,透视图像上的任意点Pu(x,y)与图像中心P0(x0,y0)的欧式距离可以表示为ru,Pu在鱼眼图像中有一个对应点Pd(xd,yd),Pd与畸变中心的距离表示为rd。ru与rd之间的映射关系除法模型如式(2)所示:
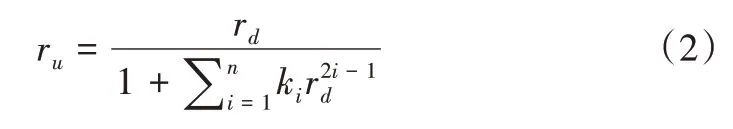
其中,ki为失真参数,通过改变ki的值来改变鱼眼畸变程度。n是参数数量,一般来说,n越大,多项式次数越多,用多项式模型表示的畸变状态就越复杂。图2 展示的是正常图像与除法模型生成鱼眼图像之间的对比,图中左边部分为正常图像,右边部分为除法模型生成的鱼眼图像。
1.2.2 多项式模型
与除法模型相比,多项式模型在设计入射光角度方面更为特殊。入射光角度与光透镜角度之间的关系如式(3)所示,θu表示入射光角度,θd是光通过透镜的角度。


Fig.2 Comparison of normal image and image generated by the division model图2 正常图像与除法模型生成图像对比
鱼眼图像一般有4 种投影模型,分别是正交投影模型、等距投影模型、球面透视投影模型、等立体角投影模型[22]。在使用多项式模型生成鱼眼图像时,选择等距投影模型,rd和θd满足等距投影关系,其中rd=f·,f是鱼眼相机的焦距。对于针孔相机,投影模型应该是rd=f·tanθd,简化得到式(4):
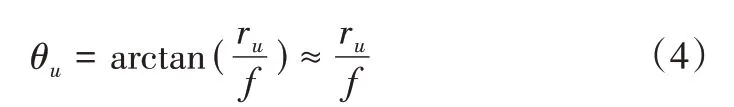
ru与rd之间的关系如式(5)所示:

将ki和f合并得到式(6),在生成鱼眼图像时主要考虑k的取值:

为了简化模型,本文采用单参数多项式方法生成鱼眼图像数据集。因为模型中有参数预测网络,并将预测的参数嵌入到后面的模型中。原图像从包含400 多种场景的Places 数据集中进行选择,图像大小为256×256,本文的鱼眼图像训练集包含38 400 张图像,测试集包含2 560 张图像。单参数K 的取值范围为10-4~10-6[9]。
在图3 中,左边为背景图像,中间为原图像,右边为单参数生成的鱼眼图像,可以看到制作出来的鱼眼图像与真实图像以及原图像之间在内容上有一定差别,内容上缩小了,原因是在生成鱼眼图像时,原图像中的部分像素会丢失。为使鱼眼图像与真实图像之间的内容保持一致,在制作真实图像时对原图像进行部分切割[1]。

Fig.3 Comparison between single-parameter generated image,real image and original image图3 单参数生成图像与真实图像以及原图像之间对比
2 模型与评价指标
2.1 模型
2.1.1 模型整体结构
模型整体结构如图4 所示,包含3 部分,分别是生成网络、判别网络和参数预测网络。生成网络主要通过多层残差网络对特征进行提取,下采样过程通过修改卷积网络中的步长替代池化操作,通过编码器不断进行下采样后获得图像特征,解码器的残差网络则将编码器的输出以及参数预测网络输入的γ 参数进行结合,再进行多次上采样操作得到生成图像。上采样操作是反卷积过程,编码器与解码器在每个残差网络中都有跳跃连接。
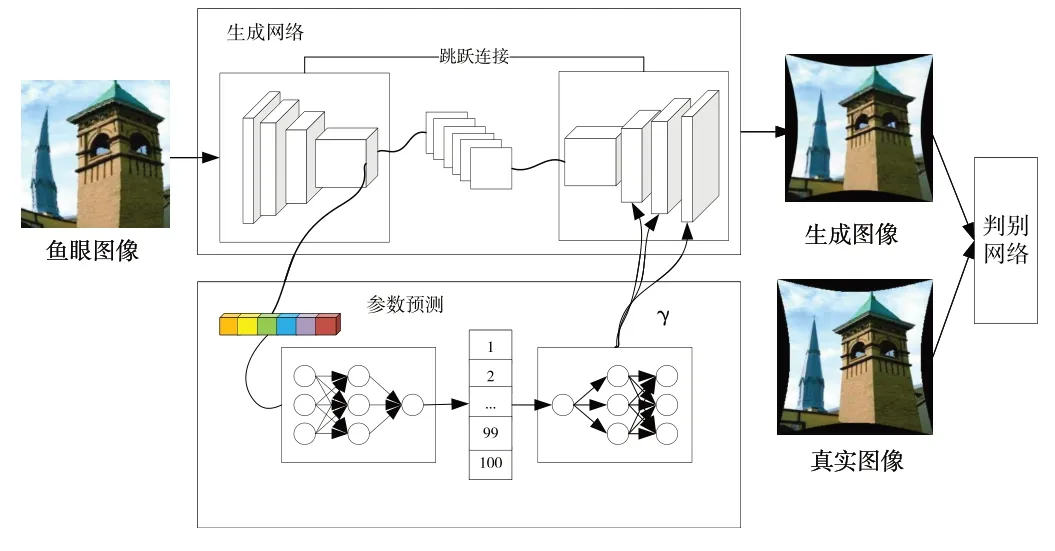
Fig.4 Overall structure of the network model in this paper图4 本文网络模型整体结构
参数预测网络的输入是编码器最后一层的高维特征,通过自适应平均池化函数将每个特征图的大小变成1×1,然后将上一步得到的多维张量变成一维张量,将一维张量通过全连接网络进行参数预测,对预测的参数进行编码后获得畸变参数γ,并将畸变参数传到生成网络的解码器残差块中。判别网络接收生成网络生成的图像和真实图像,真实图像的标签为1,生成图像的标签为0,对输入图像进行二分类,判别图像真假。
2.1.2 残差网络模块
残差网络模块包含两个卷积和一个激活函数,输入与输出维度保持一致。第一个卷积层的卷积核大小为3×3,第二个卷积层的卷积核大小为1×1,如图5 所示。编码器中的残差模块只有卷积和激活函数,不包括虚线框中的部分,解码器残差网络模块的输出是将γ嵌入到输出中。
2.1.3 判别网络结构
判别网络整体结构如图6 所示,判别网络将输入的图像不断通过卷积网络加激活函数的结构进行下采样。卷积核大小选择为5×5,卷积核个数分别为16、32、48、64、64,最后通过全连接层预测输入图像是正常图像还是鱼眼图像。
2.1.4 损失函数
预测损失选择L1 损失函数作为预测参数与真实参数之间的损失函数,减少异常值的惩罚项。N 为从训练样本中取样的个数,Ppre为预测参数,Pgt为真实参数,LP为预测损失,如式(7)所示:

Fig.5 Residual block network structure图5 残差块网络结构
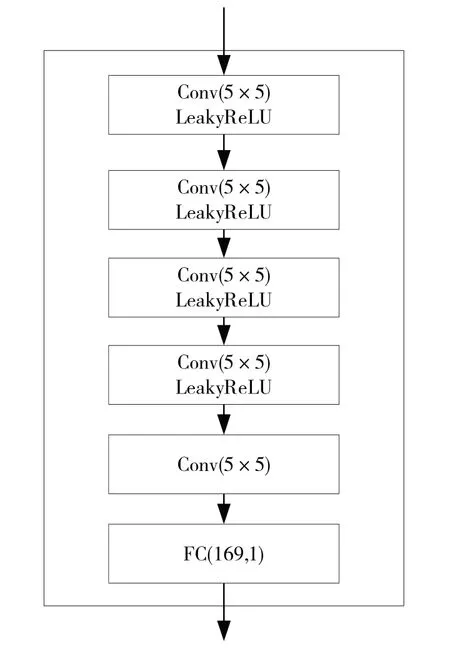
Fig.6 Discriminant network structure图6 判别网络结构
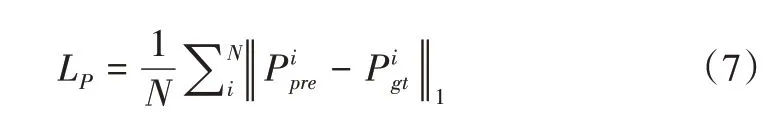
生成损失也选择L1 损失,如式(8)所示,计算图像与背景图像每个通道、每个像素点之间的L1损失。

生成网络的总体损失函数如式(9)所示:
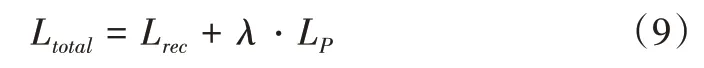
判别网络判断真假图像的问题可以看作是一个二分类任务,因此选择二分类交叉熵损失(BCEloss)作为判别网络的损失函数。
2.2 评价指标
峰值信噪比(PSNR)用于评价重建图像与背景图像之间的相似度,其数值越高,两个图像之间的相似度越高。通过式(10)计算两个图像之间的均方误差,然后通过式(11)计算PSNR。MAXI是图像中可能最大的像素值,若使用8位表示像素,则MAXI的值为255。
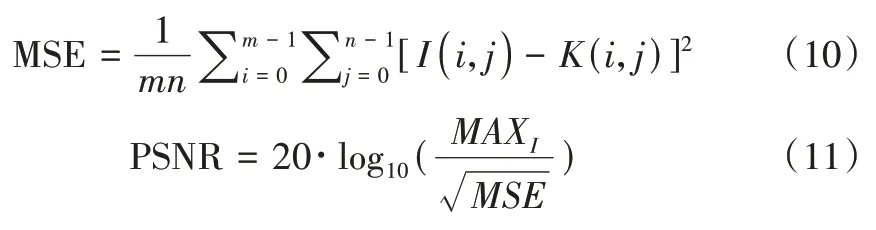
结构相似性(SSIM)用于评价两个图像之间的相似度[23],该指标从对比度、亮度、结构3 个方面对图像进行相似性比较。结构相似性值的范围为[0,1],当值越靠近1,说明两个图像之间的相似度越高。计算SSIM 需要计算两个图像各自的均值,如式(12)所示:

标准差的计算公式如式(13)所示:

图像协方差的计算公式如式(14)所示:
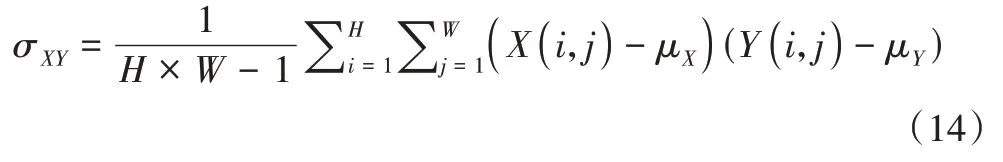
SSIM 一般选用均值作为亮度的估计,如式(15)所示:
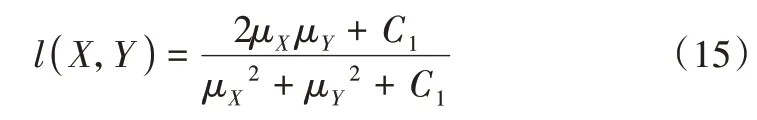
标准差作为对比度的估计,如式(16)所示:

协方差作为结构相似程度的度量,如式(17)所示:
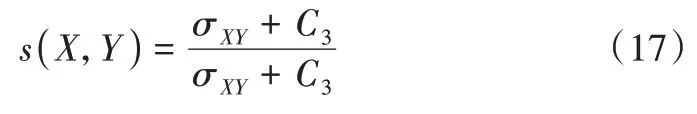
SSIM 的计算公式如式(18)所示,其中α、β、γ 取值均为1。

SSIM 选取图像中的部分区域进行计算,可能存在误差,而多尺度结构相似性(MS-SSIM)[24]在图像中选择多个区域进行计算,然后取多个区域SSIM 的平均值,相比SSIM评价更加合理。用滑动窗口将图像分成N 块,加权计算每一窗口的均值、方差以及协方差,权值满足求和为1,通常采用高斯核,然后计算对应块的结构相似度,最后将平均值作为两图像之间的结构相似性进行度量。
3 实验与分析
3.1 实验环境与过程
实验环境如表1 所示。在生成网络的总损失函数中存在一个超参数λ,在实验中将其设置为0.001。深度学习中针对损失函数的优化包含多种优化器:随机梯度下降(SGD)、带有动量的梯度下降、自适应矩估计(Adam)。一般常用的优化器为SGD 和Adam,本文选择Adam 作为优化器。学习率是影响模型训练的重要参数,若学习率太高,损失函数无法收敛;若学习率低,损失函数下降速度慢,无法完成学习。本文的学习率从0.000 1 开始,在训练过程中动态调整学习率。根据训练轮次,每10 次对学习率进行修改。每轮次训练需要30 多分钟,模型在训练30 轮次后损失几乎保持不变,因此训练轮次选择50 次,每一轮次输入图像为16 张。针对预测参数是否对图像校正结果产生影响,在训练中进行了带有参数预测模型和不带有参数预测模型的对比实验。在本文模型的生成网络中,每个模块都可以包含多个残差块,也进行了对比实验,残差块个数分别为1、2、3、4。

Table 1 Experimental environment表1 实验环境
3.2 实验结果
从鱼眼数据集中选择3 个不同种类的图像作为对比,选择的图像如图7 所示。对比方法选择了经纬度校正方法和文献[1]中提到的基于外观流的渐进互补网络鱼眼图像校正方法。

Fig.7 Fisheye dataset image图7 鱼眼图像数据集图像
图8 是鱼眼图像经过经纬度校正后的图像,通过与图7 中的图像进行比较,虽然图像中的畸变被校正,但是在图像的顶端和低端又有了新的畸变,而且相比图7 内容有所减少。图9 是鱼眼图像经过文献[1]中的基于外观流的渐进互补网络鱼眼图像校正方法校正后的图像,相较于图8,图9 不仅对鱼眼图像进行了校正,而且图像内容保存更加完整。

Fig.8 Results of latitude and longitude correction method图8 经纬度校正方法结果

Fig.9 Results of appearance flow-based progressive complementary network correction method图9 基于外观流的渐进互补网络校正方法结果
图10 是鱼眼图像经过本文方法校正后的图像,图11是鱼眼图像对应的真实背景图像。图10 的校正效果与图9 相比更加接近背景图像,图9 中的左侧图像电梯门还存在一点点“凸起”,图10 中左侧图像电梯门已经不存在“凸起”;图10 中间的文字与图9 相比也更加清晰;图10 中的右侧图像与图9 中的图像相比也是“凸起”消失,更加接近图11中的背景图像。

Fig.10 Correction results in this paper图10 本文校正结果

Fig.11 Groundtruth image图11 真实背景图像
3.3 实验结果分析
针对鱼眼图像校正效果,选择PSNR、SSIM、MS-SSIM3个定量指标进行比较,测试集计算结果如表2 所示。本文方法在3 个指标上均高于文献[1]中基于外观流的渐进互补网络方法,PSNR 从25.596 提高到28.039、SSIM 从0.800提高到0.875、MS-SSIM 从0.943提高到0.970。
由表3 可知,将参数预测嵌入到生成网络之后,其校正效果与没有参数嵌入的网络相比有所提高,数值的增加主要体现在PSNR 和SSIM 值上,证明参数嵌入确实可以提高模型对鱼眼图像的校正效果。

Table 2 Correction results of different methods表2 不同方法校正结果

Table 3 Correction result with and without parameter network表3 有无参数网络校正结果
不同残差块对模型带来的影响如表4 所示。前期残差块个数增加对模型校正效果的影响是积极的,残差块个数增加后模型的校正效果也得到提升,但当残差块个数增加到4 个时,模型校正效果却会下降,而且随着残差块的增加,整个模型的参数量也在不断增加。综合来看,本文网络中的残差块个数应该为3。
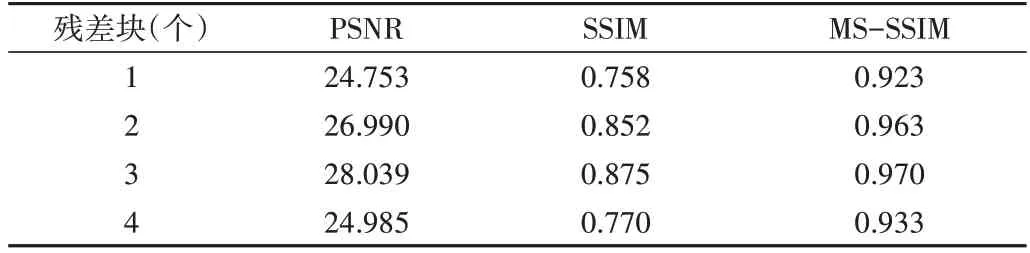
Table 4 Influence of the number of residual blocks on the model表4 残差块个数对模型的影响
4 结语
针对生成对抗网络在鱼眼图像校正过程中由于跳跃连接带来的误差和解码器负担过重问题,提出一种结合生成对抗网络和鱼眼校正参数预测网络的算法。该算法通过在模型的生成网络中添加鱼眼校正参数预测模块,将生成网络编码器的输出作为预测网络的输入,然后将预测的参数嵌入到生成网络的解码器中,用预测的参数指导鱼眼图像解码过程,以此减少跳跃连接带来的误差损失和解码器负担,提高模型校正鱼眼图像的质量。实验结果表明,在鱼眼图像数据集上,校正图像与背景图像的峰值信噪比(PSNR)达到28.039,相比之前的方法提升了9.5%;结构相似度(SSIM)达到0.875,相比之前的方法升了7.5%。本文模型虽然在一定程度上减少了跳跃连接带来的误差,但是模型生成的校正图像在放大后的某些部分还存在像素模糊的问题,如何直接通过模型生成较高质量的校正图像是下一步需要研究的问题。
