基于Selenium 与SVM的Web自动化测试方法
2023-02-18张曦煌蔡晶晶柴志雷奚智雯
张曦煌,蔡晶晶,柴志雷,3,奚智雯
(1.江南大学 人工智能与计算机学院,江苏 无锡 214215;2.无锡太湖学院 智能装备学院,江苏 无锡 214064;3.江南大学 江苏省模式识别与计算智能工程实验室,江苏 无锡 214215)
0 引言
由于敏捷开发技术的兴起,Web 应用产品的开发周期逐渐缩短,产品更新升级日趋频繁。随着产品不断迭代更新,Web 应用的规模和系统复杂度增加,对Web 产品的质量要求也随之越来越高[1]。
传统手工测试方式效率低、资源消耗大,通常难以满足大规模Web 应用的测试需求。因此,自动化测试逐渐成为Web 应用测试的主流测试方式[2],该方法不仅节省时间、人力等资源,还能显著提高测试效率。
然而,在实际操作过程中部署自动化测试时,会存在以下局限性[3]:
(1)测试用例覆盖率差。在一些复杂测试任务中,仍需要手工进行测试。
(2)测试用例复用性低。当产品迭代升级后,需要重新编写测试用例,测试人员的工作量较大[4]。
(3)成本投入高。自动化测试前期需要巨额的成本投入,后期如果缺乏成本控制方案和测试计划,项目往往会因为资金问题而以失败告终[5]。
为了解决以上问题,文献[6]提出一种适用于统一建模语言和序列图生成测试用例方法。Ansari 等[7]借助自然语言处理的功能需求生成测试用例,在减少工作量的同时,提高了工作效率。Verma 等[8]提出一种测试用例优先级比较的方法来检测Web 应用中存在的错误,该方法包括风险策略和多样性策略。其中,风险策略是指选择每次迭代中风险最大的测试用例;多样性策略则通过最大化测试过的测试用例之间的距离来设定测试用例优先级。通过结合以上两种策略,能够有效提高Web 应用中缺陷检测的准确率。高应波[9]结合数据驱动和关键字驱动模式,运用图像匹配算法设计一款混合驱动的自动化测试框架,该框架能够识别非Web 控件,有效提高Web 应用测试过程中的自动化程度。李吟等[10]设计了一款自动化测试的框架以提高自动化测试的覆盖率。
在传统自动化测试方法中,Web 应用更新后与历史版本相类似的功能测试仍需要编写测试用例[11]。为此,本文结合Selenium 自动化测试框架和SVM(Support Vector Machines,SVM)模型,从历史测试经验中对模型展开训练。首先,通过测试用例完成Web 前端页面的功能测试,并对前端页面功能所采用的测试用例进行分类预测;然后,借助自动化测试平台执行测试用例得到测试结果;最后,通过测试结果完善Web 应用。此外,为了验证所提方法的有效性,将该方法应用于一个真实运行的FPGA 公有云平台中进行Web测试。
1 Web自动化测试
自动化测试是Web 应用测试领域的发展趋势,目的是简化敏捷开发中重复的测试任务[12]。具体操作为:在测试需求的基础上,对Web 应用编写自动运行的测试用例以获取测试结果[13]。其中,自动化测试的本质是实现自动化机器测试,主要包括开发并执行测试用例、使用自动化测试工具验证开发需求两个部分。通过该技术帮助测试人员在规定时间内,尽可能多地执行测试用例[14]。
2 基于SVM的Web自动化测试方法
2.1 SVM
SVM 属于有监督分类学习模型,依赖于支持向量分类超平面,具体原理如图1 所示。由于在SVM 中少数支持向量决定了最终的聚类结果,可通过该特点在实际应用中获取关键样本,剔除冗余样本以减少计算量。此外,该方法计算的复杂性取决于支持向量的数目,在一定程度上避免了“维数灾难”。
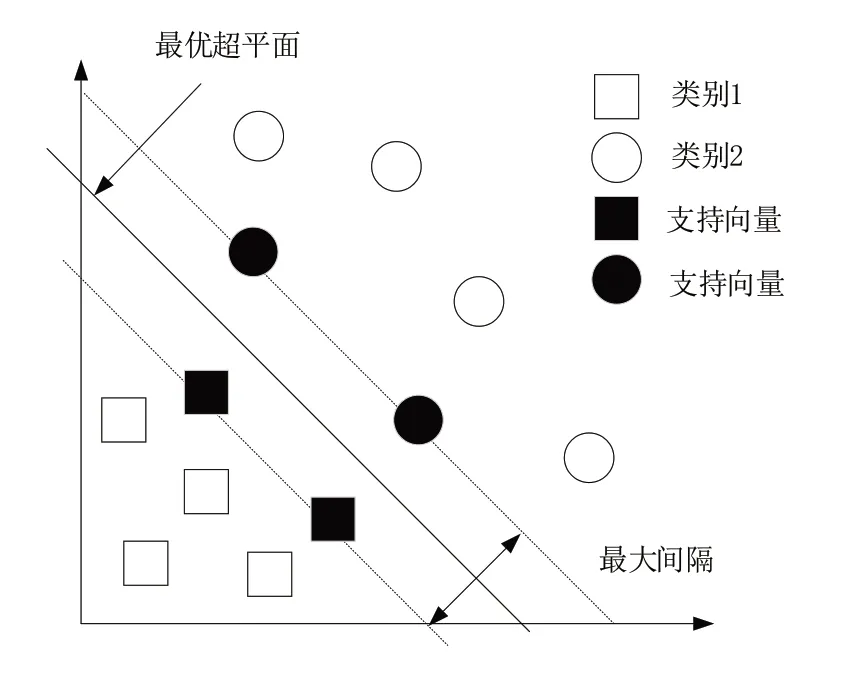
Fig.1 SVM schematic图1 SVM原理
本文使用SVM 分类Web 元素(文本信息)的测试用例。在实验过程中,首先将训练集中的文本数据进行特征提取(数值化处理),将其转化为特征向量。
然后,依据“间隔最大化”原则寻找一个超平面对样本进行分割[15],计算公式如下:

其中,w=(w1,w2,w3…wd)为法向量,决定超平面的方向,b为决定超平面与原点间距离的位移项。
接下来,计算两个异类支持向量到超平面的距离之和d,计算公式如下:

其中,d为间隔距离。
最后,只需要找到满足式(3)中约束条件的w、b,使d最大,即为“最大间隔”的超平面,计算公式如下:
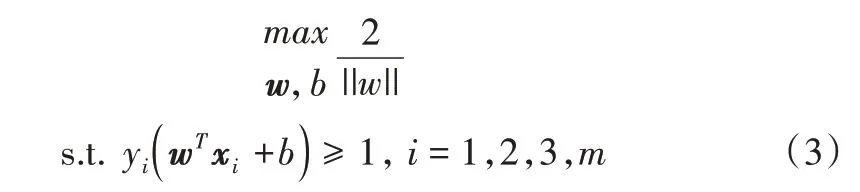
式中,最大化间隔仅需最大化||w||-1,等价于最小化||w||2。因此,式(3)可重写为:
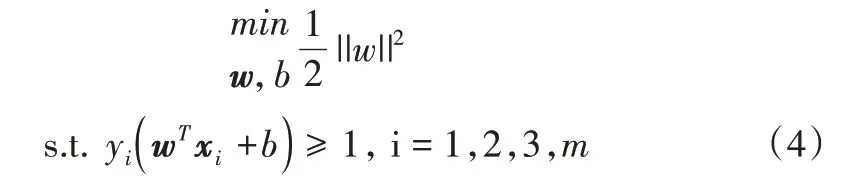
2.2 Selenium 框架
Selenium 框架主要应用于Web 应用自动化测试工具,工作原理如图2 所示。在处理自动化测试任务时,首先向Selenium 框架中集成的浏览器驱动Web Driver 发送请求,在Web Driver 收到测试脚本后对其进行解析;然后将结果发送至对应的浏览器;最后由浏览器执行测试用例并返回测试结果[16]。
由图2 可见,Selenium 框架的主要组件包括Selenium IDE、Selenium Web Driver 及Selenium Grid 模块[17]。其中,Selenium IDE 主要用于录制用户操作,生成测试用例;Selenium Web Driver 是在Selenium Remote Control 基础上优化和升级的新模块,支持多种编程语言编写测试用例,可直接给浏览器发送命令;Selenium Grid 是运行不同浏览器下的Selenium 网格,支持跨平台运行测试用例。Selenium 自动化测试框架如图3所示。
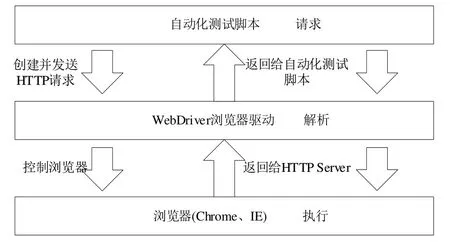
Fig.2 Selenium schematic图2 Selenium 原理
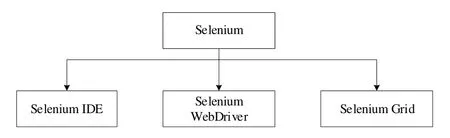
Fig.3 Selenium framework architecture图3 Selenium 框架架构
3 实验设置
3.1 实验架构
实验架构主要包含数据获取模块、机器学习模块和测试用例执行模块,用来获取一个网页所有网页功能的测试结果。其中,数据获取模块获取网页元素;机器学习模块预测每个Web 元素的测试用例;Selenium 框架模块执行Web 元素的测试用例并展现测试结果。实验整体架构如图4所示。

Fig.4 Overall architecture of the experiment图4 实验整体架构
3.2 实验环境及配置
实验平台为PyCharm,电脑配置为Intel(R)Core(TM)i7-9700CPU @300GHz,操作系统为Windows 10专业版。
3.3 数据获取
通过Request 函数向指定URL(Uniform Resource Locator)网址发起访问请求、处理响应请求,以获取静态页面的Web 元素。其中,Web 元素为Web 应用中前端页面中的HTML(Hyper Text Markup Language)标签,例如文本框、按钮等。然后,采用Beautiful Soup 解析Web 页面数据处理后的网页元素以提取指定数据。
3.4 数据预处理
目前,通常采用Beautiful Soup 模块提取页面数据。该模块不仅能规则化解析页面数据,还能提供html.parser 和lmxl 两种页面解析方式。由于lmxl 解析方式将Web 页面源码解析成一个DOM(Document Object Model)树,便于定位和提取Web 元素,因此本文选择该方法进行实验。通过Beautiful Soup 对象中的find、select、find_all 等方法,获取指定页面上的a、select、input、button 等标签如表1所示。

Table 1 Web element table表1 Web元素表
3.5 预测测试用例
本文选择FPGA 公有云平台中前端页面的数据构建训练集(见表2)。训练集和测试集均来源于同一个数据集,共1 700 条数据。在实验执行过程中,随机抽取70%数据设置为训练集,剩余数据设置为测试集。
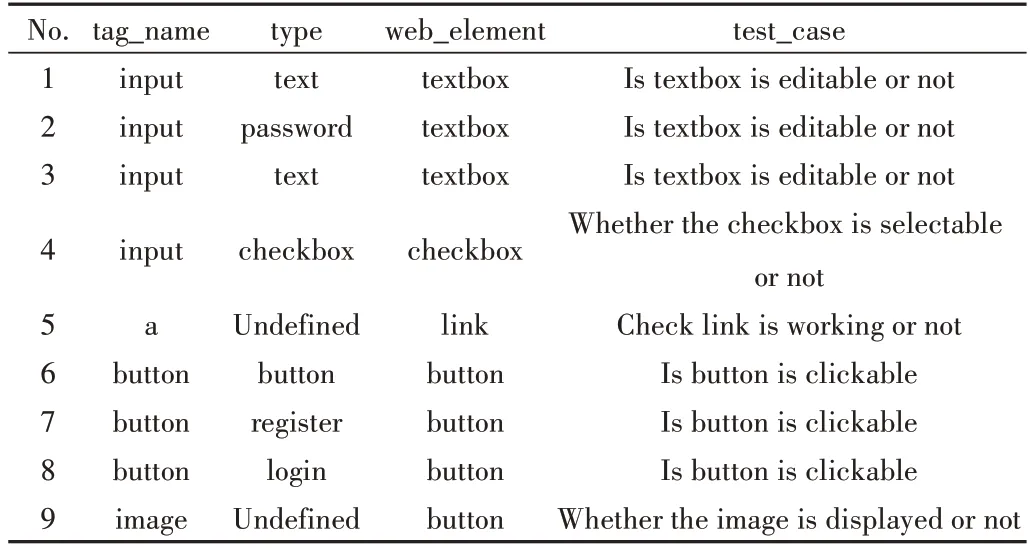
Table 2 Training set表2 训练集
由表2 可知,训练集包含tag_name(标签名称)、type(标签类型)、web_element(元素名称)、test_case(测试用例)。其中,web_element 作为特征列、test_case 列作为类标签列。测试用例类别主要包括文本框是否可编辑、按钮是否可点击、页面是否跳转、图片显示是否正常、链接标签是否成功跳转、单选按钮是否选中、文件是否可上传。
在特征提取过程中,首先采用数值化处理方法建立单词到数字的映射关系,将单词转换为数字;然后,采用SVM和决策树对模型进行拟合,并采用网格搜索和交叉验证方法寻找模型的最佳参数;最后,将测试数据输入模型预测每个Web元素的测试用例。
图5(彩图扫OSID 码可见,下同)为采用20 条测试数据对训练后的模型进行测试的结果。其中,横轴表示每个测试用例,纵轴表示测试用例的类别,红色点为每个测试用例的真实类别,蓝色点为模型预测类别。如果预测正确,红色点将完全覆盖蓝色。
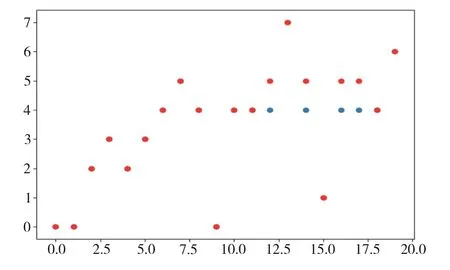
Fig.5 Scatter plot of test case prediction图5 预测测试用例散点图
由图5 可见,仅有4 条数据的分类结果发生错误,原因可能是训练数据量较少,在对数据集进行特征提取时发生特征相似的情况。
3.6 评价指标
准确率是衡量分类模型分类正确的次数,如果预测样本标签与真实标签集严格匹配,则精度为1,否则精度为0。准确率计算公式如式(5)所示:
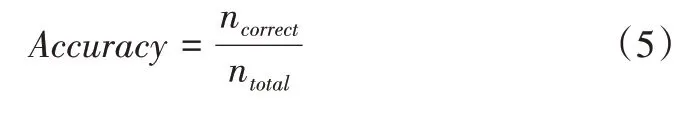
其中,ntotal为总样本个数,ncorrect为被正确分类的样本个数。
混淆矩阵(见图6)属于模型评估的一部分,能够快速计算分类任务的准确率。

Fig.6 Confusion matrix图6 混淆矩阵
图6 中,T(True)代表正确,F(False)代表错误,P(Positive)为1,表示正例,N(Negative)为0,表示负例;TP 表示实际为正且被预测为正的样本数量;FP 表示实际为负但被预测为正的样本数量;FN 表示实际为正却被预测为负的样本数量;TN 代表TN 表示实际为负被预测为负的样本的数量。结合混淆矩阵,准确率可表达为:

3.7 执行模块
在为每个Web 元素所需要的测试用例进行分类预测后,基于Selenium 框架的自动化测试系统将开始执行测试用例。该系统可详细展示测试用例的执行情况,并且支持在浏览器上运行。此外,还能够在多种浏览器下完成测试任务,便于测试人员对Web 应用进行跨平台、跨浏览器的兼容性测试。
4 基于Selenium 的Web自动化测试系统
4.1 系统介绍
Selenium 的Web 自动化测试系统基于Selenium Web Driver 驱动原理,结合了Web 开发与数据可视化的技术。该系统支持在网页上构建测试计划、执行测试用例、日志记录、测试报告的生成、邮件通知等功能,能够让测试人员清晰了解每个测试用例的执行情况,同时降低测试成本。自动化测试系统的功能模块如图7所示。

Fig.7 Function block of automated test system图7 自动化测试系统功能模块
4.2 系统实现
自动化测试系统的整体架构包括测试用例执行模块、浏览器驱动模块、SVM 预测测试用例模块、测试结果反馈模块,如图8所示。
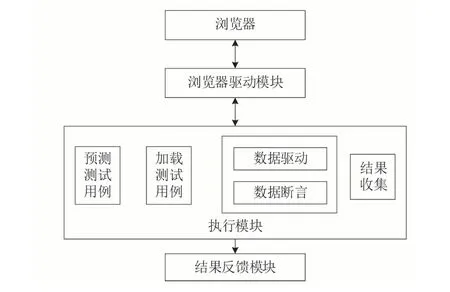
Fig.8 Architecture of automated test system图8 自动化测试系统架构
由图8 可见,执行模块包含测试用例预测、测试用例加载、数据驱动和结果收集;SVM 模块使用Python 对SVM分类模型进行封装,以获取目标页面的元素并预测测试用例分类。
4.3 系统使用
测试人员登录自动化系统,将分类结果输入自动化测试系统中完成以下流程:构建测试用例运行计划、运行计划中测试用例、查看测试用例运行结果、反馈测试结果。
5 实验结果与分析
5.1 参数确定
本文采用网格搜索和交叉验证方法(Grid Search CV)确定SVM 和决策树模型中的参数。该方法在指定参考范围内,利用参数训练学习器,根据步长依次调整参数值寻找模型准确率最高的参数值。
通过该方法,最终确定模型的两个主要参数,如表3所示。其中,Kernel 代表算法使用的内核模型;C 代表误差项的正则化参数;Gamma 为用于非线性SVM 的超参数,隐含地决定了数据映射到新特征空间后的分布状况。

Table 3 Main parameters表3 主要参数
5.2 模型比较
在控制模型核心参数相同的条件下,分别对FPGA 公有云平台前端页面中的Web 元素功能进行自动化测试,得到模型的主要评价指标,如表4所示。

Table 4 Evaluation index of classification model表4 分类模型的评价指标(%)
由表4 可知,SVM 的准确率相较于决策树模型提高4.43%;相较于朴素贝叶斯分类模型,准确率提高5.12%。
5.3 测试用例执行结果
将测试用例输入自动化测试系统,执行两个页面的测试任务,预测96 个Web 元素的测试用例,测试结果如表5所示。

Table 5 Test case operation status表5 测试用例运行状况
6 结语
本文为解决现有Web 应用的自动化测试任务中,测试用例只能根据测试人员设定好的顺序执行,无法链接新的Web 元素,尤其在页面更新后,仍需要重写测试用例的问题。借助SVM 根据历史测试经验,对新页面进行测试。
实验结果表明,SVM 相较于决策树及朴素贝叶斯模型,分类效果更优。借助该系统执行Web 元素的测试任务,可实时获取测试用例的执行状况,及时将遇见的问题反馈给开发人员。下一步,将持续优化测试用例的覆盖率,以提高测试自动化程度。
