基于反事实推理的阅读理解去偏方法
2023-02-18扆雅欣孙欣伊谭红叶
扆雅欣,孙欣伊,谭红叶,2
(1.山西大学 计算机与信息技术学院;2.山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
0 引言
机器阅读理解作为一项综合的自然语言处理任务,受到了工业界和学术界的广泛关注。该任务需要模型深度分析文章语义以及文章与问题之间的联系,并准确回答问题。当前,绝大多数机器阅读理解模型利用深度神经网络进行建模和优化[1-2],已在多个数据集上接近甚至超过人类表现。然而已有多项研究表明,阅读理解模型倾向于利用数据集偏见[3-5],不需要理解原文进行推理就能获得高性能。
为了消除数据偏见对模型产生的不良影响,前人已进行许多研究[3,6-10]。现有方法可以分为两类:①面向数据集的偏见消除方法,该类方法通过移除数据集中含偏样例的方式生成无偏数据集,从而避免模型获取有偏的先验知识,如Yu 等[6]面向阅读理解多项选择任务中随机猜测引起的数据偏见,提出对模型设置多个随机种子,并移除模型在所有情况下预测正确的样例,得到无偏数据集;②面向模型的偏见消除方法,有研究者通过调整模型对训练集中每个样例的学习强度以阻止模型利用偏见,降低数据偏见对模型的影响,如Mahabadi 等[3]提出两阶段的学习策略训练模型,通过捕捉数据集中的有偏样例并降低其权重,减少模型对偏见的依赖。
近年来,反事实推理作为因果推理的一种重要手段[11],被引入偏见消除任务中。反事实推理是指对过去已发生的事实进行否定,进而构建一种可能性假设的思维活动[12]。基于反事实推理的消偏方法尝试借助因果关系解释反事实事件,分析模型中存在的偏见,并通过调整模型的预测输出以减轻数据偏见对模型的影响。该方法不需要重新训练模型,只在测试时调整模型的输出,便可实现无偏预测。
本文提出一种基于反事实推理的阅读理解去偏方法。首先在原始训练集上训练模型,形成有偏的阅读理解模型;再基于问题和选项构建反事实输入,生成对应的反事实输出,反应模型捕捉到的偏见;最后结合模型的原始输出和反事实输出消除偏见,实现无偏预测。在典型的中英文阅读理解数据集C3与Dream 上的相关实验结果表明,本文提出的去偏方法能够有效降低数据集中的问题导向偏见和选项导向偏见对模型的影响,提升模型性能。
1 相关工作
1.1 阅读理解任务
当前主流阅读理解方法主要基于注意力机制和预训练语言模型[13],这些方法在一些数据集上的性能已经接近甚至超过了人的预期表现。如:BERT[14]模型在SQuAD[15]数据集上F1值高达93.2%,超越人类表现(F1值91.2%)。
然而有研究表明,模型的阅读理解能力远不及人类。如Yu 等[8]在构建逻辑推理阅读理解数据集Reclor 时,指出其中包含随机猜测选中答案、特定词汇指示正确答案等偏见,这些偏见会降低模型泛化能力;Sugawara 等[7]以SQuAD、DuoRC[14]等多个数据集为基础研究阅读理解任务,根据问题句主题词是否指示答案类型、答案是否出现在与问题最相似的句子中,将数据集划分为简单子集和困难子集,发现模型在多个困难子集上的性能均明显下降,表明模型存在偏见。因此,偏见消除是一个亟待解决的问题。
1.2 偏见消除
现有的偏见消除方法针对阅读理解、自然语言推理和常识推理等自然语言处理任务进行研究,研究思路包括面向数据集的偏见消除和面向模型的偏见消除。
(1)面向数据集的偏见消除。该类方法通过一定的策略移除数据集中的有偏样例,并形成无偏数据集,避免模型在训练阶段捕获偏见。如Yu 等[8]为消除多项选择任务中模型随机猜测答案的影响,对模型设置多个随机种子,并移除模型在所有情况下都预测正确的样例;Zellers 等[17]提出对抗性过滤算法,将人类可识别的词联想转化为机器可识别的向量联想,过滤数据集中可能存在的词汇选择、假设句长度特征等引起的数据偏见;Sakaguchi 等[18]在文献[17]的基础上提出可减少迭代次数的轻量对抗过滤算法,去除仅基于向量表示就能得出正确答案的样例,形成一个新的无偏或少偏的数据集。
(2)面向模型的偏见消除。目前,该类方法主要通过调整模型对训练集中的有偏样例和无偏样例的学习权重,以阻止模型利用数据偏见。如Mahabadi 等[3]提出利用两阶段学习策略训练模型,先找到数据集中的有偏样例并调整训练集中各类样例的权值,使模型训练时重点学习无偏样例,降低数据偏见对模型的影响;Liu 等[19]对于机器学习模型在现实应用中出现的性别和种族歧视等问题,提出基于强化学习的去偏框架,并采用去偏奖励函数和KL 值,降低了数据集中的政治偏见对模型的影响。
1.3 反事实推理
反事实推理是一种新的面向模型的消偏方法。反事实推理与因果推理密切相关,是个体对不真实的条件或可能性进行替换的一种思维过程[12]。该方法被应用于视觉问答[20]、文本分类[21]和推荐系统[10]等机器学习模型偏见消除任务中。如Niu 等[20]基于反事实推理分析视觉问答系统中存在的语言偏见;Wei 等[10]利用反事实推理,通过多任务训练得到反事实输出,消除物品流行度对推荐系统的影响;Chen 等[22]在文本分类去偏任务中引入反事实推理调整模型输出,消除偏见。
已有的面向数据集的偏见消除方法需要一对一构建无偏数据集,经济成本高昂,且可移植性较差,很难迁移到其他领域。本文受文献[20]、文献[22]的启发,提出一种基于反事实推理的面向模型的阅读理解去偏方法。本文与他们的不同之处在于:文献[20]、文献[22]分别面向视觉问答和文本分类任务,而本文面向阅读理解任务进行偏见消除研究,并根据任务特点消除问题导向偏见和选项导向偏见对模型预测的影响。此外,文献[20]对原始输出和反事实输出进行非线性组合得到去偏输出,而本文与文献[22]均采用线性组合调整模型输出,实现无偏预测,这种方法具有模型简单、训练速度快等优势,有效节约了时间成本。
2 去偏方法
2.1 相关定义与模型架构
2.1.1 相关定义
(1)因果推理与反事实推理。因果推理是研究如何科学地识别变量间因果关系的理论。反事实推理与因果推理密切相关,通常指人们对已发生事件进行否定的心理活动,一般以反事实条件句的形式出现,可以表示为“如果不......,那么.......”。如人们迟到时,会想“如果早点动身,那么就不会迟到了”。具体到模型去偏中,反事实推理可以用于分析如果某些变量采用不同的值(也称反事实输入),结果会如何改变,进而评估模型捕获到的偏见。
(2)因果图。反事实推理在具体应用中可以抽象化为如图1 所示的因果示意图。其中,节点X、Y和C分别表示原因、结果和中间变量(又称混淆因子),当X直接作用于Y,则X到Y存在一条有向边(如X→Y),称为前门路径。如果X和Y在变量C的作用下具有因果关系(如X→C→Y),称为后门路径[19],这种情况很可能涉及到虚假的因果关系。为了正确分析X和Y之间的因果关系,需要消除混淆因子C的作用,阻断后门路径(如图1(b)所示)。
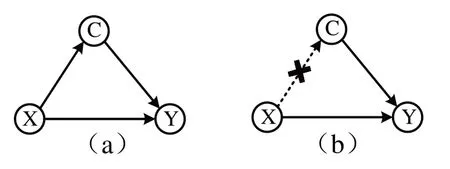
Fig.1 Causal diagram图1 因果示意图
2.1.2 模型架构
本文提出一种基于反事实推理的阅读理解去偏方法。利用图1 中因果示意图的原理,基于阅读理解任务特点构造图2 虚线框所示的反事实因果图,其中篇章p、问题q和候选选项o均为原因节点,Y表示相应的模型输出,对应结果节点,中间变量C表示模型捕捉到的多种偏见。
如图2 所示,该方法包括偏见提取和偏见消除两个模块。
(1)偏见提取模块。该模块通过构建反事实输入提取问题导向偏见和选项导向偏见。①问题导向偏见:通过在篇章、选项基础上,仅保留问题疑问词构建反事实输入得到反事实输出以获得;②选项导向偏见:通过仅为模型提供选项而不提供篇章和问题构造反事实输入得到反事实输出,以此反映模型捕捉到的相应偏见。
(2)偏见消除模块。基于模型的原始输出和反事实输出得到无偏预测,本文通过从原始输出中移除模型捕捉到的问题导向偏见和选项导向偏见以调整模型预测,实现偏见消除。
2.2 偏见提取
传统的阅读理解模型通常基于数据集得到的先验知识,在推理阶段最大化先验概率预测答案,但数据中存在的偏见会导致模型预测的置信度不高。本文借助贝叶斯公式表示偏见对模型预测的影响,如式(1)所示。

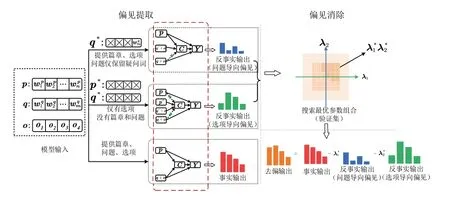
Fig.2 Reading comprehension debiasing method frame based on counterfactual reasoning图2 基于反事实推理的阅读理解去偏方法框架
在多项选择阅读理解任务中,X表示篇章p、问题q和候选选项o等模型输入,Y表示模型的预测输出,c∈C表示混淆因子。
消除X→C→Y后门路径的常用方法是采用do(·)操作,得到X和Y之间真正的因果关系。do(·)操作形式化如式(2)所示。
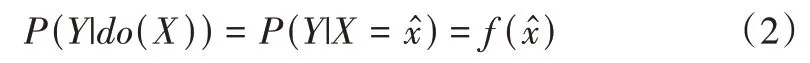
(1)基于问题导向的反事实输入。本文通过只提供问题q中的疑问词,保持篇章p、选项o不变,构建基于问题导向的反事实输入,获得模型相应的反事实输出f()。具体操作可以形式化为式(3)。
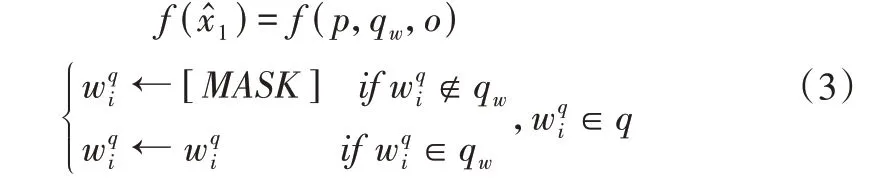
其中,qw表示问题中的疑问词部分,[MASK]表示屏蔽某个词的特殊标记。对于问题q中的第i个词,如果属于疑问词qw则保留,否则用[MASK]进行标记。
(2)基于选项导向的反事实输入。本文通过仅提供选项o,不提供篇章p和问题q,构建基于选项导向的反事实输入,并通过模型获得对应的反事实输出f()。具体操作如式(4)所示。
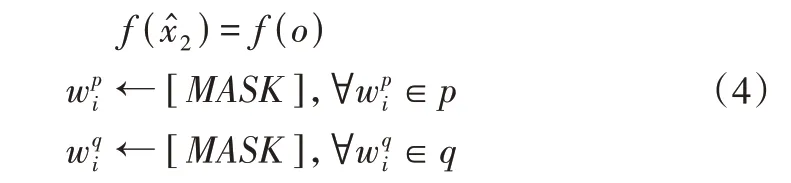
对模型的反事实输出进行统计发现,基于问题导向与选项导向的反事实输出准确率分别为83%和73%,表明模型存在相应偏见。
2.3 偏见消除
本文通过从原始输出中移除模型捕捉到的问题导向偏见和选项导向偏见调整模型预测,实现偏见消除。该过程可形式化为:
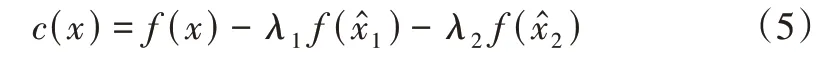
其中,c(x)和f(x)表示调整后的模型输出,f(x)表示原始模型输出,f()表示基于问题导向的反事实输出,f()表示基于选项导向的反事实输出,λ1和λ2是两个独立的参数,用于平衡两类反事实输出对模型的影响。该函数的目标是找到一组最优的参数组合,在优化参数的过程中不断降低问题导向偏见和选项导向偏见对模型预测的影响,最终得到最优的去偏输出。
具体应用中,在二维空间中采用网格搜索最佳的参数组合[20],形式化表示如下:
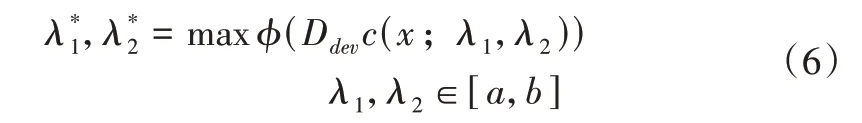
其中,ϕ表示评价指标,评价模型在验证集Ddev上的性能,本文选择准确率作为评价指标表示使模型性能最优的参数组合,[a,b]是搜索区间,具体实验中设置为[-2,2]。
3 实验与结果分析
3.1 实验设置
3.1.1 数据集
本文选择汉语阅读理解数据集C3 和英文阅读理解数据集Dream 进行实验。主要原因为:①两个数据集均为公开发布的阅读理解数据集,被很多研究者用作基准数据集;②两个数据集任务形式为多项选择题,便于设计反事实输入,探索本文所提思路的有效性。未来还将针对阅读理解其他任务形式进行拓展研究;③C3 和Dream 数据集风格相同,但语种不同,前者为汉语,后者为英语,可以更好地探究本文所提方法在不同语种上的效果与普适性。
(1)C3 数据集。汉语多项选择数据集,包含13 369 个对话或普通文本、19 557 道多项选择题。数据来源于汉语第二语言考试。
(2)Dream 数据集。英语阅读理解数据集,包含6 444个对话和10 197 个多项选择问题。数据来源于英语第二语言考试。
3.1.2 模型
本文选择3 种代表性阅读理解模型Bert、Ernie[26]和XLNet[27]进行实验。
(1)Bert。该模型采用多层双向Transformer 架构,利用掩码语言模型(Masked Language Model,MLM)和句子预测(Next Sentence Prediction)两项预训练任务在大规模文本语料上进行训练得到。该模型在多个自然语言任务上取得最佳性能,包括阅读理解任务。
(2)Ernie。其由百度提出,在基于Bert 模型的基础上改进了预训练MLM 任务,将对字掩盖变为对词、实体等语义单元进行掩盖,使模型可以学习完整概念的语义表示,对先验语义知识单元进行建模,增强了模型的语义表示能力。该模型在中文阅读理解任务上超越Bert。
(3)XLNet。该模型作为Bert 的改进版,是一种通用的自回归预训练模型。其利用排列语言建模,结合了自回归语言模型和自编码语言模型的优点,克服了Bert 掩码语言模型带来的预训练和微调效果存在差异的缺点,在10 多项任务上(如阅读理解任务、自然语言推理任务等)的性能已经超过Bert。
3.1.3 准确率
C3 和Dream 问题的形式为多项选择式,属于客观题,测评以准确率(Accuracy)作为评测标准。
3.2 实验结果
3.2.1 模型去偏结果分析
C3 和Dream 数据集上的实验结果如表1 所示。可以看出,与原始Bert、Ernie 和XLNet 模型相比,去偏后的模型在C3 和Dream 数据集上的性能均有提升。其中,Bert 去偏效果最好,与原始模型相比,去偏后的模型在C3 验证集和测试集上的性能分别提升2.69%和2.31%,在Dream 验证集和测试集上的性能分别提升3.12%和1.21%。
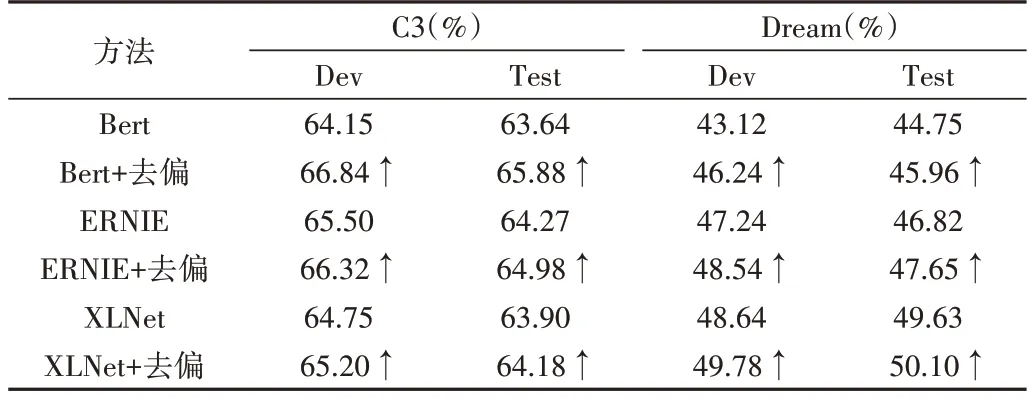
Table 1 Results of C3 and Dream datasets表1 C3和Dream数据集的实验结果
同时,本文为了分析实验结果的合理性,根据原始模型的答题结果,将C3 和Dream 测试集划分为正确子集(如C3_true、Dream_true)和错误子集(如 C3_wrong、Dream_wrong)。原始模型在正确子集和错误子集上的性能分别为100%和0,去偏模型在错误子集和正确子集上的实验结果如表2、表3所示。
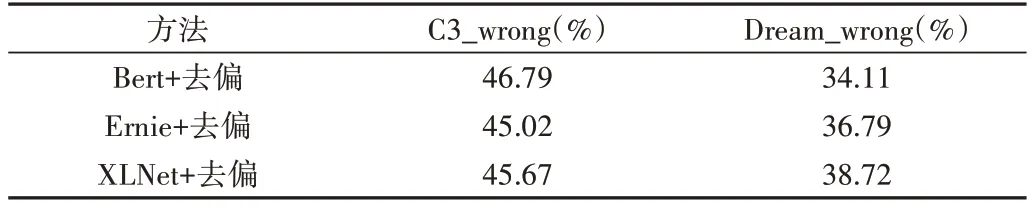
Table 2 Results of debiasing models on wrong subsets表2 去偏模型在错误子集上的实验结果
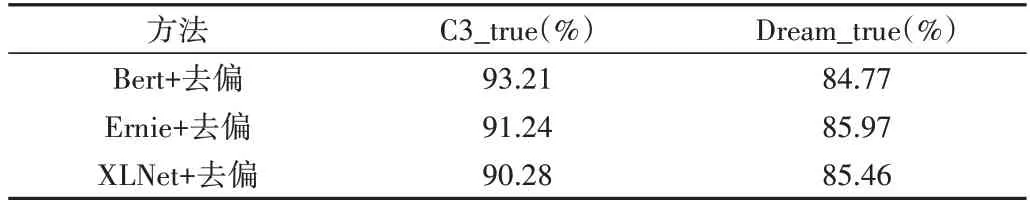
Table 3 Results of debiasing models on right subsets表3 去偏模型在正确子集上的实验结果
从表2 可以看出,去偏后的模型在C3 与Dream 错误子集上的性能均有大幅度提升。其中,XLNet 去偏后的模型在C3_wrong 和Dream_wrong 数据集上的性能分别提升45.67%和38.72%,表明模型经过优化后,在错误样例上的表现有极大提升。如表4 所示,样例1 为原始模型预测错误而去偏模型预测正确的题目。
样例1 的选项分布如图3 所示。可以看出,原始模型的事实输出和问题导向偏见的反事实输出皆为A 选项正确,选项导向偏见的反事实输出为B 选项正确。当λ1=0.2,λ2=-0.3 时,通过式(5)进行模型优化后,去偏模型的输出为B 选项正确,同时也是正确答案。

Table 4 Example of debiasing model表4 模型去偏样例
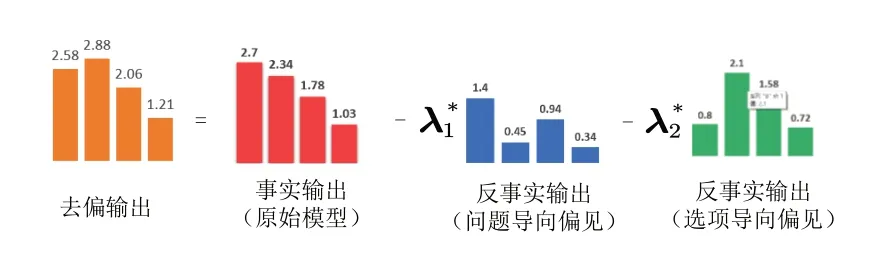
Fig.3 Option distribution for example 1图3 样例1选项分布
结合表1 和表2 可以看出,优化后的模型在所有数据上的提升幅度不如错误子集上的提升幅度,主要原因在于优化后的模型在正确子集上的性能相比原始模型(100%)有所下降(见表3),可能是由于原始模型利用了数据集偏见作出正确决策,当引入消偏方法后,模型会对决策方法进行修正,因此模型性能会有一定幅度的下降,这也表明去偏后的模型更为合理。具体如表5中样例2所示。

Table 5 Example of debiasing model表5 模型去偏样例
3.2.2 消融实验
由于去偏后的Bert 模型效果最好,因此本文针对Bert进行消融实验以分析问题导向偏见消除和选项导向偏见对模型的贡献,结果如表6所示,其中Δ 表示模型准确率的增量。
从表6 可以看出,与原始Bert 模型在C3 数据集上的性能相比,引入问题导向偏见消除操作后模型性能提升3.70%,引入选项导向偏见消除操作后模型性能提升1.33%,表明问题导向偏见对模型影响更大。当同时引入两种类型的偏见消除操作后,模型性能在平衡参数的作用下提升2.74%,有效减少了偏见对模型的影响。
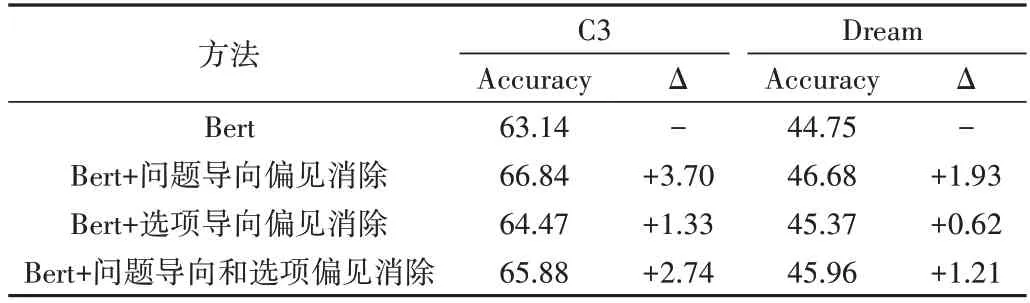
Table 6 Ablation results of Bert表6 Bert消融实验结果(%)
3.2.3 不同手段对去偏结果的影响
有研究者将反事实推理引入到其他自然语言推理去偏任务中,采用非线性组合的方式将反事实输出和原始事实输出结合起来[18]优化模型,而本文采用线性组合的方式实现阅读理解任务的偏见消除。线性和非线性去偏方法对比结果如表7所示。
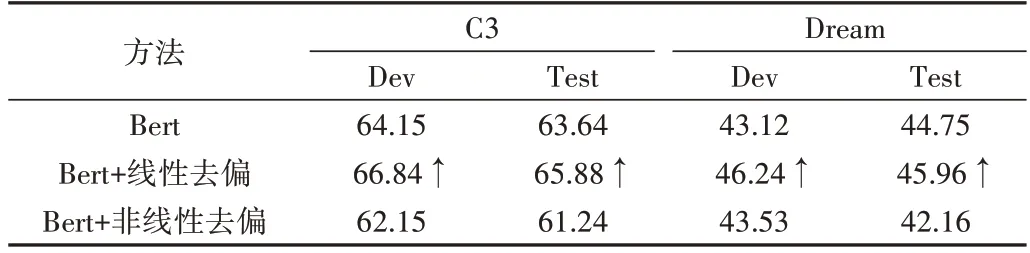
Table 7 Comparison of results表7 对比试验结果(%)
从表7 可以看出,非线性去偏方法在阅读理解任务中的效果低于本文方法,两个方法在C3 测试集上的准确率相差4.64%。
4 结语
本文提出了一种基于反事实推理的阅读理解任务去偏方法,首先在原始数据集上训练得到包含多种偏见的基础模型,然后构建模型的反事实输入并获得反事实输出,提取模型中的问题导向偏见和选项导向偏见,最后结合模型的原始输出和反事实输出调整模型预测,降低偏见对模型的影响。本文在C3 和Dream 阅读理解数据集上做了大量实验,结果表明,本文所提方法能够降低偏见对模型预测的影响,有效消除数据偏见,极大提升了模型能力。未来还将探索阅读理解数据集中的多种偏见,并采用不同的手段消除偏见,提升模型性能。
