基于特征词的教学综合评语量化研究
2023-02-18陆存豪
陈 建,向 露,徐 晶,陆存豪
(扬州大学 机械工程学院,江苏 扬州 225000)
0 引言
课堂教学质量评价是高校稳定教学秩序、提高教学质量的重要举措之一。评价工作的客观性和评价数据的充分运用是教务部门重要的关注点,一般由课堂的教学评价(通常用优秀、良好、一般、合格、不合格表示)、专家对教师授课的综合评语(由专家根据教师授课情况和自己对授课质量标准的理解,用文字进行表述)、专家对学生学习情况的评价(由专家根据学生的课堂表现评分,通常分为优秀、良好、一般)3个方面构成。
课堂教学评价对于提高人才培养质量具有重要意义,许多学者对此进行了研究。杨志波[1]、丁元春等[2]、朱玥[3]利用层次分析法构建教学质量评价体系,对教学质量各指标的权重结果进行分析并提出相应建议;杨益等[4]运用层次分析法与灰色聚类法构建课堂教学质量评价体系,教学实践结果表明,该方法有效、可靠,且可实行性较强;唐顺定等[5]提出基于层次分析法的模糊综合评判法对教学质量进行研究;岳琪等[6]提出一种基于遗传算法和反向传播神经网络的混合算法对教学质量评价指标进行打分,实验结果表明,该算法能够有效实现对教学质量的评价;Yang[7]结合层次分析法(AHP)与BP 神经网络提出一种评估英语课堂质量的新方法,实验结果显示,与不使用AHP相比,使用该方法后英语课堂质量评估精度提高了1.9%,召回率提高了1.3%;Zhang 等[8]、李燕燕等[9]利用基于遗传算法与神经网络的课堂教学质量评价方法,以有效提高课堂教学质量评价精度。高校课堂质量评价需要对整个课堂活动进行考察,通过评价内容及时反馈课堂教学问题,但以上方法并未将专家的评价内容加入模型中,因此无法全面评判不同课程教学质量的差异[10]。此外,上述方法的课堂评价结果划分比较简单,只分为优秀、良好、一般、合格、不合格,在授课等级结果相同的情况下,无法判断出哪一节课的教学质量更好。
在每位专家对同一门课程评判结果不一致的情况下,不同课程的教学质量也存在差异,因此将专家对教师授课的综合评语转化为评定教师授课水平的量化指标显得尤为重要。对专家的教学综合评语进行量化,不仅可判断出哪一节课的教学质量更好,而且能减少专家主观性评判带来的误差。本文创新性地提出基于专业特征词与大数据特征词的两种评分模型,对教学综合评语进行量化打分,以帮助对比综合评价等级相同时课堂教学质量的差异。实验结果表明,大数据特征词评分模型可更好地区分不同课程的教学质量,评价结果符合实际,结果真实、可靠。
1 教学质量评价指标确定
课堂教学质量评价受到很多因素影响,教师是课堂教学活动的直接负责人,教师的教学态度、教学内容、方法手段、教学成效等都是影响教学质量的客观因素。因此,科学、合理地进行课堂教学质量评价,对于促进教师提升业务水平、创新教学手段改革,从而提高人才培养质量具有重要意义。
根据某高校提供的课堂教学评价重点内容和参考标准,给出教学质量评价的 4 个一级指标及对应权重,如表1所示。

Table 1 Key contents and reference standards of classroom teaching evaluation表1 课堂教学评价重点内容与参考标准
由表1 可知,一级指标包括教学态度、教学内容、方法手段、教学成就,且每个指标都有相应的评价内容和权重。查阅文献[11]、[12]发现,教学质量评价指标体系一般包含教学态度、教学内容、教学方法、教学效果4 个方面,各高校可在此基础上结合自身教学特点及实际情况制定符合自身的教学质量评价体系[13]。
根据某高校提供的5 821 条课堂教学评价数据,选取其中的5条数据进行展示,如表2所示。

Table 2 Course evaluation data表2 课程评价数据
2 综合评分模型构建
各高校在进行课堂教学质量评价时,会将课堂教学评价重点内容作为参考,因此表1 中的评价内容可作为评语打分的依据,由此建立专业特征词评分模型。课堂教学评价内容是教学质量分析与研究的重要基础,所以有必要对专家的评价内容进行研究。为了避免专家在借鉴表1 的内容作为参考时带有主观性的表达,故根据类似表2 的教师教学总体评价内容,建立大数据特征词评分模型。
2.1 专业特征词评分模型
将表1 的课堂教学评价重点内容中4 个项目的特征词挑选出来形成词语集合N,并分别给4 个项目的特征词赋予不同权重,对需要评分的评语进行特征词搜索,然后乘以相应权重后累加分数。对课堂教学评价内容进行观察,发现评语中经常出现“不”“没”“无”等否定词表示课程教学的不足。因此,在计算过程中需要对否定词进行搜索,并减去相应分值。则评语集合中第i条综合评语的得分Xi为:
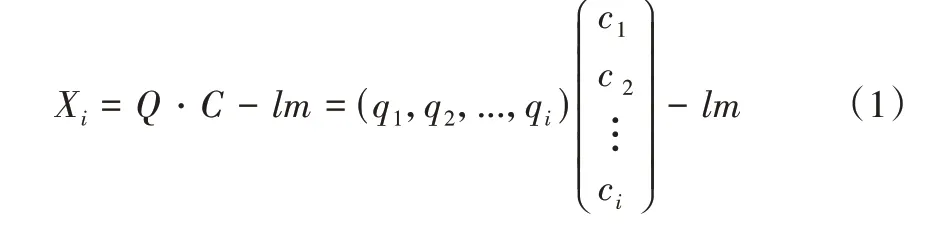
式中,Q=(q1,q2,…,qi),其中qi为评语中符合第i个项目的特征词个数;C=(c1,c2,…,ci),其中ci为第i个项目中每个词所赋予的权重;m表示评语中出现否定词的次数;l表示否定词权重。
由式(1)可知,以表1 的教学评价重点内容提取出的特征词和否定词作为依据,对评语的每个词进行检索,查找特征词与否定词个数,并分别乘上对应系数,最后得出每条评语的分数,由此可区分不同课程的教学质量。
2.2 大数据特征词评分模型
将某高校课堂教学评价数据按教师教学综合评价和学生综合评价进行等级划分,评语等级分为双优秀、一优一良、双良3 部分。选取对应的不同特征词集合,并将每个特征词集合赋予不同权重。对课堂评语进行特征词搜索,然后乘以相应权重后累加求和,从而计算出各课堂评价内容的分数。对课堂教学评价进行观察,评语中除出现“不”“没”“无”等否定词表示教学课程的不足,计算过程需要减去相应分值外,发现双良评语都会出现“建议”一词,而双优评语中未出现。为避免因特征词过多而出现良好评语分数大于优秀评语的情况,但凡评语中出现“建议”一词,将所得总分乘上系数k。评语集合中第j条综合评语的得分为:

式中,P=(p1,p2,…,pj),其中pi为评语中符合第j个特征词集合的特征词个数;G=(g1,g2,…,gj),gj为第j个特征词集合中每个词所赋予的权重;n表示评语中出现否定词的次数;d表示否定词权重。
同理,由式(2)可知,从专家的评价内容中提取出3 个不同特征词合集作为依据对评语进行检索,查找特征词个数与否定词个数,并分别乘上对应系数,最后得出每条评语的分数,由此区分不同课程的教学质量。
3 实验结果与分析
为了检验上述两种模型的实际情况并进行对比,本文根据某高校提供的课堂教学评价数据进行实验,并对其中20 门课程的评分结果进行展示,实验流程如图1 所示。以专业特征词评分模型为例,首先利用Python 的jieba 函数将综合评语切分成若干词语,然后将每个词与特征词进行对比。若词语相同则加上对应权重,进入下一个词与特征词进行对比;若词语与专业特征词无法对应,直接进行下一个词与特征词进行对比且不计分。按上述方式查找否定词并累计分数,将综合评语的所有词语对比完之后,对所得的分数进行加减,最后求出综合评语的总分。大数据特征词评分模型的评分流程同理。
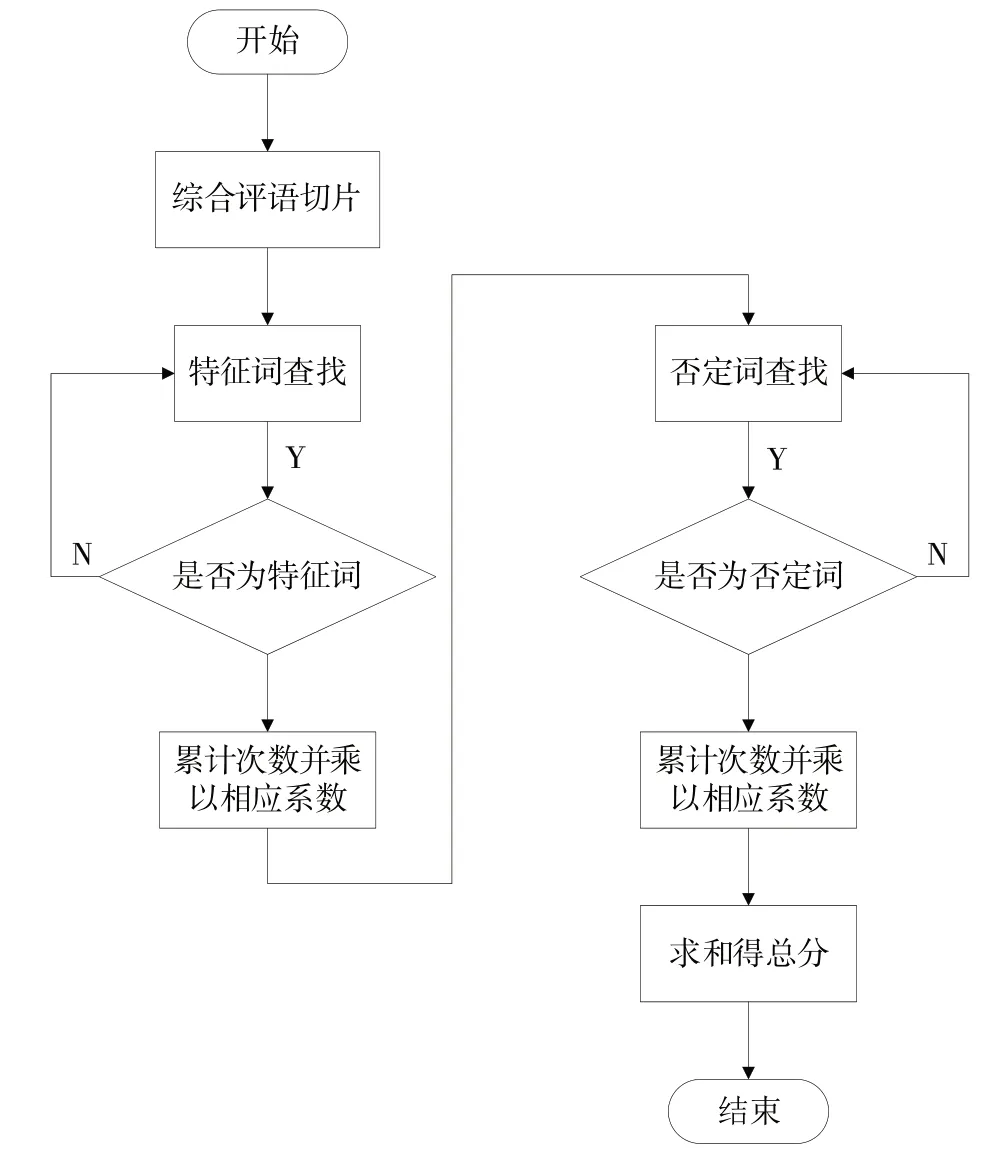
Fig.1 Experimental process图1 实验流程
3.1 专业特征词选取
根据表1 课堂教学评价的重点内容和参考标准,结合实际选取课堂教学评价的专业特征词,如表3所示。
由表3、式(1)可知C=(0.2,0.3,0.3,0.2),分别代表课程4 个项目的不同权重;l取C 的均值,l=0.25;q1、q2、q3、q4分别代表评语中教学态度、教学内容、方法手段和教学组织4个指标特征词出现的次数。

Table 3 Characteristic words and their weights of each item in theory course表3 理论课各项目特征词及权重
3.2 大数据特征词选取
由表2 可知,根据教学综合评价和学生综合评价结果,把“教师教学总体评价及改进意见”列表分为双优秀、一优一良、双良评价3 部分,并利用Python 的jieba 函数对3部分评语内容进行词语切片,选出3 部分重复率最高的特征词,组成3 个不同特征词集合,根据评语等级对特征词集合赋予不同权重,如表4 所示。由表4 可知,在特征词统计过程中发现双优评语中除有双优特征词外,还会出现双良和一优一良评语的特征词,双良评语中也会出现少量双优评语的特征词。为更好地确定评语等级,本文选取特征词顺序为双良特征词集合、一优一良特征词集合、双优特征词集合,每个集合都排除前一个集合所出现的特征词。由表4、式(2)可知,G=(0.2,0.3,0.5),d取G的均值,d=0.3。

Table 4 Characteristic words and their weights in three parts表4 3部分特征词及权重
3.3 k值选取
k值取值范围为(0,1),若k值过大,模型精确度不高,很难区分不同等级的课;若k值过小,导致同等级别不同评语的区分度不高,造成模型精度较低。如图2 所示,k值取0.5时模型精度最高,故本文取k值为0.5。
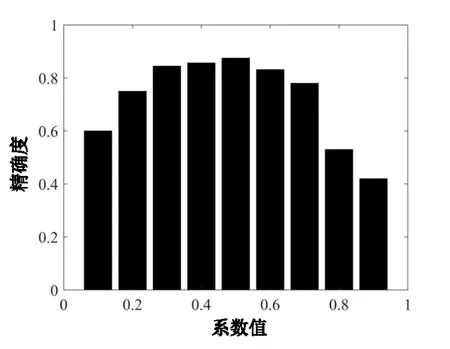
Fig.2 Relationship between k value and model precision图2 k值与模型精度的关系
3.4 结果分析
在参考的5 821 条高校课堂教学评价数据中,取20 门课程的评价内容分别带入专业特征词评分模型、大数据特征词评分模型中,结果展示如表5 所示。由表5 可知,按专业特征词评分模型进行求解后,1-20 条记录的量化结果由小到大的排序为4、8、11、19、3、2、9、13、15、17、18、14、7、10、16、1、5、20、6、12。按大数据特质词评分模型进行求解后,1-20 条记录的量化结果由小到大的排序为4、9、3、11、8、7、10、1、6、2、20、14、19、18、5、17、16、15、13、12。将两种方法的排序结果与教师教学综合评价、学生学习综合评价作对比,不同模型的结果比较如表6所示。

Table 5 Evaluation of scoring results by two methods表5 两种方法评价得分结果

Table 6 Comparison of model results表6 模型结果比较
由表6 可知,专业特征词评分模型精度低于大数据特征词评分模型,结果显示考虑否定词的计算会提高模型精度,考虑否定词的大数据特征词评分模型的精度高达87.5%。专业特征词评分模型精度较低的原因是专业特征词评分模型按照表1 标准内容所提取出的特征词与实际评语匹配度不高,且在实际搜索中出现频率不高。教师进行评价时带有自己的主观意见,会根据自己的习惯用语书写评论,所以利用大数据特征词评分模型,在教师的评论中提取重复率高的特征词,按评语所处等级赋予不同权重,模型结果与对应序号的教师教学综合评价、学生学习综合评价的匹配度更高。匹配度不能完全一致的原因是不同教师对同一节课带有不同的主观性,会出现同一节课评分不一致或类似评语评分不一致的情况。总体而言,大数据特征词评分模型的准确度较高。通过表6 模型的精度对比可知,考虑否定词时模型的精度更高,说明课堂教学评语的正负情感也会影响评分结果,考虑评语的情感会提高模型精度。
4 结语
课堂教学评价是教师教学质量的重要参考标准,本文通过提取评语中的特征词构建大数据特征词综合评分模型,将专家评语进行量化,同时也考虑到评语中出现的否定词对模型精度的影响,有效利用专家评语作为课堂教学质量的评价参考。该方法可帮助在最终评价等级结果相同的情况下判断出哪一节课的教学质量更好,同时能减少由于专家评价主观性对结果造成的误差。大数据特征词综合评分模型避免了课堂教学质量结果模糊、简单的缺点,对实际教学质量的评价具有重要参考价值,可为以后提高课堂教学质量提供一种易于操作、有效、可靠的方法。
