基于学生画像的学生评价系统设计与实现
2023-02-18马辛巳于明鹤张天成
马辛巳,于明鹤,王 虹,张天成
(1.东北大学 软件学院;2.东北大学 计算机科学与工程学院,辽宁 沈阳 110169)
0 引言
加强学生技能培训的多样化、个性化是高等教育发展的迫切需要。近年来,随着互联网行业技术的不断更新,数据挖掘、人工智能等新兴技术不断涌现,这些技术逐渐被应用于生活的各个领域。在技能培训体系中,能否运用相关互联网技术从海量信息中提取适当、有用的信息和智力资源,提高教学质量,已经成为评价高校教学质量的重要指标之一[1]。
教育部召开的2021 届高校毕业生就业进展新闻发布会指出,2021 届全国高等院校毕业生总规模达到909 万,相比前年增长了35 万[2],我国高等教育正一步步走向大众化。随着智能时代的到来,信息技术与教育的进一步融合正在深刻改变教育教学方式。“十四五”规划,明确提出了“深化新时代教育评价改革,建立健全教育评价制度和机制”的目标[3]。同时,中共中央、国务院印发《深化新时代教育评价改革总体方案》[4]中指出“坚持科学有效,改进结果评价,健全综合评价,充分利用信息技术提高教育评价的科学性、专业性”。在此情况下,利用大数据集、机器学习等新兴技术构成的学生画像技术,可成为全面刻画学生能力、服务于教学评价的重要手段[5]。为了实现这一目的,本文设计并实现了一个基于用户画像的学生评价系统。该系统可实现数据预处理、数据向量化,完成对学生各个维度的特征分类。通过构建学生画像,系统对各维度上的数据进行加权计算,最终形成对学生的综合评价,帮助教师全面、准确地了解每一位学生的情况。
1 关键技术介绍
(1)K-means 聚类算法。K-means 聚类算法是一种深度学习相关的迭代聚类分析算法,其认为数据点对于聚类中心的欧氏距离较近,即属于同一类别,从而将相似数据聚到一个类中。具体过程如算法1所示。
算法1K-means 聚类算法

(2)用户画像技术。用户画像的概念最早由交互设计之父Alan[6]提出,从文献总数、学科分布和资金支持3 方面来看,国外的用户肖像研究起步明显早于中国,在2010 年左右相差最多。2015 年该研究在国内进入快速发展时期,文献数量开始呈大量增长趋势[7]。可以看出,用户画像是近年来在国内兴起的热点研究问题。
用户画像主要基于大量用户积累的数据,结合相应需求与场景,沉淀出一系列标签,这些标签共同为产品迭代提供数据支撑。通过用户行为构建各种标签,实时刻画用户画像,从而进行产品运营辅助。
画像构建过程主要包括以下3 个阶段:①数据采集。在用户画像研究中,用户数据主要通过社会调查、网络数据收集和平台数据库收集获得;②特征提取。指从用户数据中提取特征标签的过程,主要通过人工与机器学习算法两种方法完成特征提取;③画像可视化。指将构建的用户画像用各种直观、清晰的视觉图形呈现出来的过程,例如直方图、雷达图、标签云等。
目前,很多研究者进行了用户画像构建研究。韩梅花等[8]在构造抑郁情绪种子词的基础上,计算抑郁情感指数,从而构建抑郁群体用户画像,并基于此为具有抑郁特征的用户推送相应阅读治疗资源;王凌霄等[9]基于大量社会化问答社区用户的活动指标数据,构建用户画像并从中识别用户群体与用户质量;Rossi 等[10]采集机场用户的手机轨迹数据,并抽取机场用户的实时行为特征,研发了一个决策支持系统,为机场用户提供信息与建议;张琳娟等[11]通过双聚类算法分析用户用电数据,研究用户用电行为;Liang 等[12]通过构建机器学习模型提取用户特征,对非定向上网行为进行研究以预测学生的学业成绩;吴文瀚[13]将数据分析与数据验证过程相结合,通过KL 散度和AIO社会学模型选取具有代表性的计算样本与标签样本,并利用CH-Score 和SH-Score 明确算法与相关参数,利用聚类算法,通过TGI 解读集群数据结果,最终利用关联规则发现年轻用户对汽车的需求。
面对庞大且不断增长的学生群体,本文通过数据分析与可视化相关技术,准确描绘与建模学生特点,生成相关学生画像并进行评价。主要通过聚类算法的应用,根据各科目属性和特点对学生成绩进行聚类,生成恰当的特征标签,据此开发学生评价系统,使用户画像有了更广阔的应用场景,实现了用户画像技术与高校教学间的融合,为学生的下一步学习提供参考。同时,可为教师指导、定制个性化培养方案提供数据依据,也为管理者提供决策支持,实现教学效果和人才培养质量的提升。
2 学生画像构建
传统意义上对学生学习成绩、学习能力和学习过程的数据评价是基于排名或分数段的,例如90 分以上为优秀,80~90 之间为良好。由于成绩与评价数据分布的不稳定性和密度不确定性等原因,无法非常准确地衡量一个学生的实际情况。例如课程难度较高,90 分以上的学生较少,可能85 分以上的学生即处于整体优秀状态,此类问题使用传统计算方法无法准确进行评估。基于以上前提,且学生成绩大部分符合正态分布特征,本文通过K-means 聚类分析确定数据的实际分类情况。其中,课程分析是单次调用聚类算法的显示,词云评价图及标签云是多次调用后进行归一化等处理后的结果。
(1)数据收集与预处理。本文数据集来源于高校教务处学生数据,脱敏后导出得到1 888 行个人基本信息与竞赛、论文、实践活动信息,以及107 195 行学生成绩信息。为确保数据与实际教学情况相符,从而保证评价模型的适用性,数据集包含了多个专业学科方向的学生数据。
使用Navicat 导入工具将Excel 中的数据导入到数据库中,在导入之前对数据进行相应的清理操作。使用Excel自带的vlookup()函数分离出学生、教师、课程分类等信息。将五级分制、二级分制等转化为int 型成绩,对于是否选修项,必修为1,选修为0;修读类型正常为1,重修为2;考试类别正常为1,补考为2。
(2)K-means 算法应用。调用算法对课程成绩进行聚类,为后续特征标签构建提供输入。本系统的K-means 算法使用Python 语言编写,系统框架使用SpringBoot[14]编写,因此涉及到Java调用Python 的方法,具体代码如下:

由于Python 程序调用了numpy、matplotlib、pymysql 等依赖包,此方式调用时import 不到相应环境,因此使用anaconda 配置好环境之后,需要import sys 将其路径引入到main.py文件中。
针对Runtime.getRuntime().exec()的异常处理问题,当代码有异常时,由于调用后未及时捕捉进程输出,因此控制台没有输出,导致开发调试困难。解决办法为启动该进程后,再启动一个线程及时获取异常信息。
(3)特征标签构建算法。基于K-means 算法对学生评价特征标签进行构建,参考高校对本科生的培养计划及课程大类分类进行特征划分较为全面、可靠。系统共分为六大特征标签,即math、humanities、specialty、electives、code、innovation,分别代表学生的数学与自然科学、人文、专业基础、专业选修、工程实践能力、创新能力六大能力值。给出标签基准分为5 分,运用分母限制,通过运算保证标签分数在1~9 分之间。学生每多选一门课,算法运行对应的评分机制,直至得出最终评分,具体描述如算法2所示。
算法2特征能力标签构建算法


科目标签得分与每个标签下的课程数量有直接关系,一旦挂科(低于60 分)还会启动相应的减分机制。奖罚体系以标签内所有课程数量为分母,结合具体课程的聚类情况赋予分子进行评分,标签评分随着每增加一门科目进行动态更新。由于分母的限制,每增加一门课程,课程数量增加,在属于同一聚类结果(分子一定)的情况下,对最终得分的影响会逐渐缩小,因此一定程度上避免了因某一标签得分较低,进而选取大量该标签下课程进行刷分的行为。由于已经掌握了该标签下大量课程的知识,因此在后续奖惩体系中只有拥有较高级的聚类结果才会有较多加分,从而对最终结果造成较大影响。
系统在确定一位学生进行特征能力标签构建之后,根据其所修的课程成绩进行单项排序。通过比较可得出:特征能力标签得分较高的课程成绩在全体学生中排名靠前,得分较低的课程成绩则不理想,可在一定程度上体现出算法的有效性。以学号为“711”的学生为例,该学生“数学与自然科学”标签下的高等数学、大学物理、数值分析得分分别为99、97、91,在同年级241 名同学中排名第3、7、20 名。而“专业基础”标签下的计算机体系结构、计算机网络得分为72、78,在同年级241 名同学中排名第217、131 名。基于上述成绩,该同学的六大特征标签:数学与自然科学、人文、专业基础、专业选修、工程实践能力、创新能力得分分别为8.27、7.70、6.77、7.00、8.11、6.75,所有学生标签均值得分为6.14、6.48、6.13、6.82、6.53、6.89。系统根据上述标签得分最终形成雷达图,如图1所示。

Fig.1 Radar chart example图1 雷达图示例
(4)学生画像生成。通过算法得到六大特征标签值之后,在画像中加入竞赛、论文、志愿时长、实践活动等信息,形成综合、全面的学生画像。在后续系统开发中,将此学生画像通过柱状图、雷达图、词云图等可视化方法更加直观地展现给系统用户。词云图中文字大小即标签数值,并根据每位学生在学科竞赛、社会工作和论文发表等方面取得的成绩增加对应的文字标签。以学号为“711”的学生为例,其词云图如图2所示。

Fig.2 Example of wordcloud chart图2 词云图示例
该学生可根据此画像保持自己的竞争优势,同时弥补画像所展现出的不足,教师可根据学生画像定制培养方案,公司可根据画像寻找所需的人才,以达到共赢的目的。
3 需求分析
基于学生画像的学生评价系统主要是针对学生评价和个性化教学相关服务的需求而开发的,主要工作是记录每天的教学数据、维护信息,对数据进行挖掘形成学生标签云。系统应具有学生画像分析、数据处理、系统管理三大功能。学生画像分析主要负责给出某门课程的学生成绩分布占比以及最高分、最低分、平均分等信息,根据学号查询该学生所有科目成绩,并通过相关算法对其成绩进行分析,得出评价标签;数据处理主要负责数据收集与清洗,对学生成绩、科目信息进行增删改查操作;系统管理主要负责身份验证管理,对个人用户信息、账号信息进行增删改查等操作。
图3 是整个系统的用例概要。在系统中,一些通用功能需要进行良好地封装,而且需尽量避免魔法值的出现,以确保后续需求变更时方便修改。对于业务数据量的增大,可以使用SpringClound 相关技术将其快速拆分为微服务项目进行集群部署;对于数据集的增大,可以考虑采用elastatic search 技术进行快速查询,且可以对聚类算法进行一定优化与改进。综上所述,本系统具有极大的可扩展空间。

Fig.3 System use case图3 系统用例
4 系统分析与设计
针对上述功能需求,本系统的设计如图4 所示。该系统为B/S 应用程序,对各种浏览器有较好的兼容性。系统采用MVC 架构[15],分为4 部分:存储层、业务流程层、控制层以及前端页面。同时系统采用高内聚、低耦合、易于系统扩展的设计,以便后续作进一步升级。

Fig.4 System architecture图4 系统架构
系统主要设计三大功能模块,即学生画像分析、数据采集处理和系统管理模块。本系统要求用户必须在登录状态下才能使用系统功能,未登录时访问系统任何其他资源将跳转到登录页面。学生画像模块是整个系统的核心部分,包括数据预处理和矢量变换,利用模型训练可以构建学生的能力画像与特征标签,是业务逻辑和算法的主要实现部分;数据采集模块是整个系统算法的数据来源,包括算法所需数据的增删改查;系统管理模块是基础模块,由系统管理员操作,维护基础数据,建立系统用户权限,以保证系统的正常运行。
本系统采用关系型数据库MySQL[16]与非关系型数据库Redis,并采用mybatis 持久化层框架进行分页等操作;后端选用SpringBoot 框架进行开发,同时集成了jsr303、lombok、jackson、JWT、log4j 等相关技术以降低系统耦合度,辅助系统开发;前端页面展示选用vue[17]框架集成elementui和v-chart实现,开发过程中采用junit进行单元测试。系统开发完成后将其部署在Linux操作系统上运行。
5 系统实现
5.1 学生画像分析
学生画像分析模块基于本文设计的学生画像构建技术,实现对学生当前状态进行分析。用户登录成功后在左侧导航栏选择“学生画像”页面,3 列分别为单科目聚类算法、学生评价词云图和雷达图。具体实现页面如图5所示。
(1)基于K-means 聚类的课程分析。同一门课程选择不同的聚类中心数量进行聚类,结果如图6 所示,k 值分别为2、3、4、5。在计算时去除不及格成绩的影响,默认Kmeans 聚类算法的k 值为3,将学生成绩分为中、良、优秀3类,聚类算法结果更加清晰,实际效果最好。
(2)学生特征标签构建。雷达图与柱状图采用vchart组件进行实现,搜索框中输入学号可进行切换。雷达图提供平均标签值的数据,并且可以在搜索多位学生学号时进行比对,查看其在各个标签能力值方面的差异。平均分基准数据随着计算过的学生画像越来越多,不断进行动态更新。
(3)学生评价词云图实现。学生评价词云图在学生特征标签构建基础上,采用ve-wordcloud 进行构建,依据标签构建结果对其进行显示。采用wordExtend 设置随机字体颜色,并利用人像轮廓图片设置词云图形状。
5.2 数据处理
5.2.1 数据库操作
(1)关系型数据库。使用mybatis-generator 生成实体类、Example、Mapper 和xml 文件,减少了手动编码的代码量,加快了开发速度,并且应用log4j 打印相应日志,便于调试。
本系统选用逻辑分页,并不依赖于物理实体,将所有数据都查询出来,然后通过RowBounds 在内存进行分页。
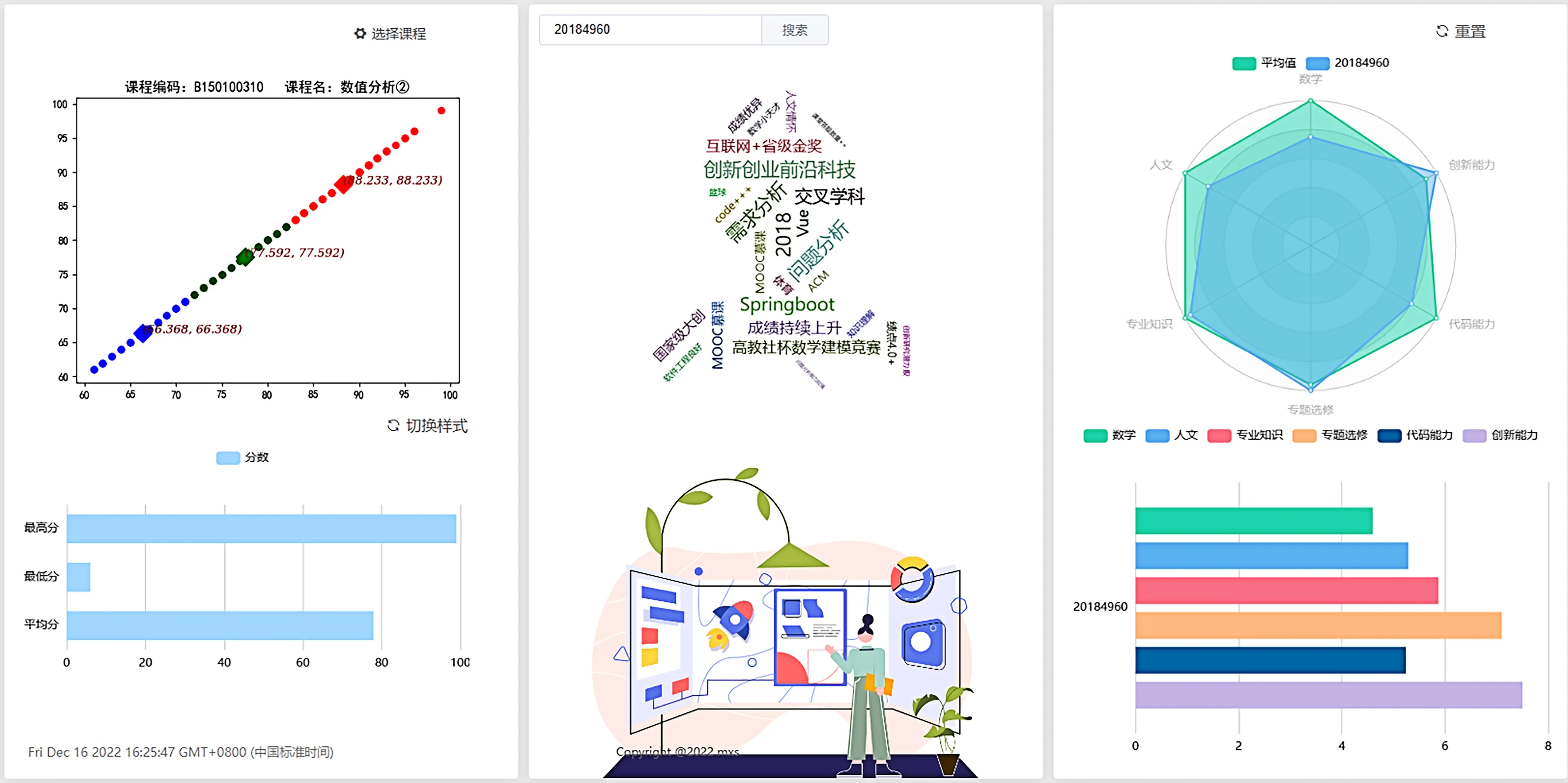
Fig.5 Student portrait page图5 学生画像页面

Fig.6 K-means schematic diagram图6 K-means示意图
(2)非关系型数据库。Redis 默认使用Java 序列化存储Java 对象,实体类必须实现Serializable 接口,编码不方便,且使用序列化形式码流大,不易传输,无法进行跨语言协同,因此将Redis 存储格式变更为json 格式进行对象存储,具体代码如下:

5.2.2 课程数据处理
用户登录成功后在左侧导航栏选择“课程编辑”页面,其主体由表格构成,可以对课程信息进行增删改查操作。具体实现页面如图7所示。
在表格前设置check 框,用户可以选择进行批量删除操作,删除功能可提供二次确认。还可提供单行数据操作功能,将表格中的一项更改为可编辑输入框。

Fig.7 Course editing page图7 课程编辑页面
在前端增加表单验证功能,在后端实体类上,为应对需求变更,使用了Lombok,在实体类上增加@Data、@AllArgsConstructor、@NoArgsConstructor 注释来自动生成构造方法和getter、setter方法。
提供模糊查询功能,在后台使用动态sql,通过关键字“like”进行拼接。点击“新增”按钮,可以跳出dialog,部分数据项具有下拉框选择功能。
提供数据导出功能,使用Export2Excel.js 将表格数据导出为Excel文件。
5.3 系统管理
5.3.1 token身份验证
登录页面如图8 所示。考虑到安全性及系统性能,由于使用普通账号密码登录会频繁调用数据库而影响系统性能,本系统对于用户登录采取JWT 的token 身份验证方式。使用加密算法HMAC256 生成token,可在一定程度上保证安全性,使用拦截器获取并验证token,拦截所有请求,通过判断是否有@LoginRequired 注解,决定是否需要登录。
5.3.2 系统信息查询

Fig.8 Login page图8 登录页面
管理员登录成功后将显示系统主页。其中,饼图可查看具体课程的分数区间占比,柱状图可搜索对应学号学生的所有课程成绩。系统主页如图9所示。

Fig.9 System homepage图9 系统主页
(1)头像上传。用户点击页面显示的头像可进行头像更换。该功能使用el-upload 实现,在前端接收图片时限制图片小于5M。存储过程为:以form 形式传回后台,服务器使用UUID 生成随机字符串+截取源文件的后缀名来重定义文件名,并写入到本地服务器。获取过程为:查找前端服务器中该用户的头像文件是否存在,若不存在则向后端服务器接口发起请求,调用数据库查询后返回。
(2)个人资料增删改查。点击个人信息框的“修改资料”后跳出dialog,如图10 所示。其中编号和学校由系统后台统一给出,用户不可更改,性别选项为下拉框选择格式。加入正则表达式验证邮箱和手机号格式及内容是否为空,以确保数据的有效性。服务器端为防止从postman等软件跳过前端页面直接注入数据,加入JSR303 校验,以确认数据不为空且符合相应格式要求。

Fig.10 Information modification图10 修改资料页面
(3)选择课程进行成绩查询。点击饼图“设置”按钮后跳出课程成绩查询,类比多层级下拉框的样式实现,调用后端对该课程进行统计分析。使用动态SQL 语句,考虑到sql 注入,防止给sql 语句传入1 等信息导致所有信息被查出来,因此使用占位符#{},而不是字符串拼接${}。
(4)选择学号进行分数显示。柱状图显示分数,默认第一位学生的学号,可以通过搜索框进行切换。使用vchart 的ve-histogram 组件,由于每位学生所修科目量较大,导致显示不全,因此需要通过chartExtend 属性进入底层echart中使用series的barWidth 进行设置。
6 系统测试
(1)登录功能测试。对系统的首次登录、token 身份验证及刷新时间、登录时能否记住密码等功能进行测试,表1对登录功能的测试用例进行了详细说明。经过测试得出系统登录功能良好,具有记住密码的能力,在token 未失效时段内可自动登录。

Table 1 Test cases of log in function表 1 登录功能测试用例表
(2)统计数据查询测试。对系统主页的头像上传、资料修改、课程选择、图标生成等功能进行测试,表2 对统计数据查询的测试用例进行了详细说明。经过测试得出统计数据查询功能良好,头像上传可以在前端存储,且短时间内可以加载出图片,邮箱、手机号格式的正则表达式正确,可以正确查询课程成绩分布与个人成绩柱状图。

Table 2 Test cases of statistics queries表 2 统计数据查询测试用例表
(3)学生画像构建测试。对系统的聚类结果、学生评价词云图、特征标签构建、成绩分析、标签数值柱状图等进行测试,表3 对统计数据查询的测试用例进行了详细说明。经过测试得出学生画像模块功能良好,Java 调用Python 时正确未出错,K-means 算法聚类结果无空类,词云图轮廓为人形,且文字大小与得分成正比,雷达图可同时展现个人标签得分与平均标签得分。

Table 3 Test cases of student profile表 3 学生画像测试用例表
(4)数据库修改测试。对数据库的修改功能进行测试,表4 对统计数据的增加、删除、查询及更新的测试用例进行了详细说明。经过测试得出数据库运行良好,前端所有数据的增删改查及其他操作均可以在数据库中对应实现。

Table 4 Test cases of database表 4 数据库测试用例表
(5)性能测试。系统的性能测试包括吞吐量测试、响应时间测试等,由于要应用到线上环境,本系统需要对这些指标进行测试。系统性能测试用例如表5所示。
经过测试,系统并发性能良好。从系统并发数来看,在目前预计的实际应用中,管理员数量不会超过100 个,而有数千名学生使用该系统。按照性能分析中的“二八原则”,同时可能有几百名学生使用本系统,目前看来系统可以满足此并发量。

Table 5 Test cases of performance表 5 性能测试用例表
系统经过验证与测试,性能符合需求,可以较好地实现特征标签构建与学生评价功能,且标签形象直观,人机交互友好。
7 结语
系统以高等院校为应用场景,通过对教学数据的收集、清洗、挖掘,实时构建学生能力特征标签,生成学生评价词云图,从而实现可视化反馈学习状态与教学成果。该系统可以帮助学生了解自己的学习情况,同时让教师随时掌握教学情况,并根据系统提供的信息定制个性化的学生培养方案。
本文完成了基本学生评价系统的设计与实现,未来还可以从业务完善、数据分析、算法创新等方面进行改进,例如综合学生的日常行为及校外学习等数据,设计更加完善的多元评价机制。在模型选择上,还可探索更多适合教育领域的模型进行算法运算。同时在数据量、用户量不断增大的情况下,可以适当增加算法的复杂度,将本系统拆分为微服务项目进行集群部署,以保证并发量。
