深度森林在用户购买预测中的应用
2023-02-17付红玉
付红玉 贺 红
(山东大学机电与信息工程学院 山东 威海 264200)
0 引 言
1990年至1993年,电子商务的概念被引入中国,经过20多年的发展,中国电商上市公司数、交易规模、网民规模、网购用户规模等持续攀升。电子商务平台商品繁多,在为用户提供产品和服务的同时,加大了用户在海量数据中快速、准确地找到符合用户偏好的产品的难度[1]。而且,随着电商领域发展到一定规模,流量的快速增长最终会停止,提高流量转换率将成为一个电商企业保持长期、稳定发展的决定性因素[2]。基于此,电商服务技术得以快速发展,各大电商平台逐步由应用支撑向服务支撑迈进。
由于电商独特的平台优势,在活跃的购买行为下,潜藏了更多的用户行为数据,如用户的浏览、点击、关注行为及反映用户偏好的评论行为等。这些行为数据呈指数级增长,其特点是数据量大、多样性强、价值大且密度低,符合大数据的特点,被称为电商大数据[3]。电商大数据带来了信息过载的问题,基于电商大数据的个性化推荐系统,可以整合多源异构数据,实时、准确地向用户推荐符合其意愿的产品,既能提高用户购物体验,又能提高电商平台转换率,进而提升企业竞争力,是有效解决信息过载问题的有效方案[4]。预测是推荐的基础,“用户购买行为预测”作为商品推荐系统研究的重点问题之一,近几年来发展迅速。目前研究多集中于集成学习算法,多数学者旨在通过算法改进和模型融合等手段,提高用户复购预测准确率。本文从两方面对用户购买预测模型进行改进:(1) 引入时间滑动窗口技术和窗口权重递减设置,从数量特征、时序特征等五方面构建全面的训练特征。(2) 基于深度森林算法框架,引入随机森林、XGBoost等多种集成算法搭建多层异源集成算法模型,预测用户购买行为。
1 相关工作
推荐系统的定义由Resnick于1997年首次提出,已走过20多年的发展之路,目前传统的推荐算法主要有协同过滤推荐、基于内容的推荐、基于关联规则的推荐、基于知识的推荐和混合推荐5种分类[5]。在不同的应用领域,传统推荐算法存在很多问题,学者们从多角度考虑,提出了一系列改进的推荐算法。基于用户的协同过滤和基于物品的协同过滤算法[6]对用户-商品评分依赖性强,在用户和商品数量不稳定的领域推荐效果较差。Deshpande等[7]提出了一种基于模型的推荐算法,通过引入不同项目间相似性计算得到的算法模型比传统的推荐算法快两个数量级,且表现出更高质量的推荐效果。针对数据稀疏情况下推荐质量不佳的问题,岳希等[8]从评分空缺填补、考虑共同评分项数量等方面进行优化,提出了一种针对稀疏数据的推荐算法,且随着数据稀疏度增大,模型效果更加明显。
推荐算法逐渐走向成熟,预测作为推荐的基础也成为国内外学者的研究热点。在预测问题的研究中,电商平台借助技术手段深入挖掘并分析用户的历史行为,发现用户行为特征、偏好和购买规律,在现有数据基础上,预测用户未来购买行为,以实现精准营销,优化平台购买服务,提高平台运行效率[9]。同时,精确的预测算法有助于平台获取老用户的保有价值、新用户的提升价值以及潜在用户的挖掘价值,进一步提高平台转化率[10]。在特征工程方面,李俊卿等[11]强调输入特征向量的选择是建立预测模型关键的一步,他提出了一种基于随机森林筛选预测模型输入向量的方法,通过降低模型复杂度,加快模型预测速度的同时提高了预测的精度。在模型搭建方面,Zhao等[12]在2014年使用机器学习和降维(SVD)方法,利用天猫—特定特征数据预测用户购买行为,得到了很好的效果。Martínez等[13]使用Logistic Lasso、extreme learning machine和gradient tree boost分别搭建预测模型,预测用户在未来一个月的购买行为,实验结果表明梯度提升树预测效果最佳,这是集成学习在数值预测问题中的新探索。
近年来,深度学习算法很流行。它们由逐层神经网络构成,具有很强的表示学习能力,在各领域预测问题研究中取得显著的成果[14]。但深度学习模型参数较多,训练时间长。南京大学周志华教授于2017年首次提出深度森林的概念[15],同时提出了一种以随机森林为基分类器的多粒度级联森林(multi-Grained Cascade forest,gcForest)深度树集成方法。该框架提出至今,已被应用于多个领域。Hu等[16]基于深度森林算法框架,搭建了一个既保留深度学习的特征表示能力,又考虑召回率和模型训练时间等其他评价指标的新模型,新模型取得了比集成学习算法更优异的表现。葛绍林等[17]提出了一种基于深度森林的用户购买行为预测模型,在阿里平台真实数据集上构建用户行为特征,输入模型预测,实验结果表明深度森林模型在降低时间开销的同时提高了预测准确率。
综上所示,这些技术只是简单地从特征提取或模型选择单方面进行改进。特征提取时未考虑数据间的时序关系,特征构建不够全面。模型选择单一,未考虑多样性对模型整体建设的重要性。本文通过对真实数据集进行可视化操作,针对数据集稀疏性特点,有针对性地从五方面提取重要特征。电商平台数据更新频繁,对模型训练效率要求高,基于多种集成学习算法,提出了基于深度森林模型的用户购买行为预测模型,在本文特征集上进行训练,能得到很好的预测表现。深度森林是一个深度树集成方法,具有比深度神经网络少得多的超参数,可以避免大规模的参数拟合来节省时间,在许多与深度神经网络竞争的领域表现出了出色的分类性能[18-19]。模型中的超参数有较强的鲁棒性,在近乎完全一样的超参数设置下,对不同领域不同数据的分类任务都能取得不错的分类效果。
2 预测模型
2.1 问题场景
在电商平台中,用户对日用品的购买具有一定规律性,在购买某品类物品时,会先浏览该品类的不同商品,在挑选和比较商品的过程中,会产生一系列的操作行为,如本文数据集中的浏览、关注行为等。不同用户拥有不同的购物习惯,部分用户要达到一定浏览次数才会产生购买行为,也有用户习惯先关注心仪物品,日后从关注列表进行购买。
2.2 特征构建
在预测问题的研究中,决定最终预测结果好坏的,是特征的构建和模型的选择。在某种程度上,特征构建的重要性甚至超过了模型的选择。本文在原始数据集基础上,从五个方面提取特征,从浏览—购买、关注—购买、购买—评论三个角度来扩展特征。同时,引入时间滑动窗口技术,构建动态时序序列,主要工作流程如图1所示。

图1 基于时间滑窗的特征构建流程图
(1) 基本特征。包括用户性别、年龄、级别,商品的价格、参数等基本特征共7个。
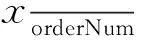
(1)

(2)
式中:Δtu,i=tu,i-tu,i-1表示[A,B]窗口内,第i次购买和第i-1次购买之间的时间差,以天为单位。权重wi:
(3)
(4)
(5)
用户浏览、关注和评论行为的数量特征和时序特征的提取与上述一致。
(4) 组合特征。在以上已提取特征的基础上,进行关联特征的组合。将数量特征(12个)与时序特征(4个)分别组合,构建用户活跃度指数特征,生成12×4=48个新特征xactive1:
(6)
(5) 时间滑动窗口特征。以上构建的83个特征的是在单时间窗口内进行的特征提取,本文初步设定的窗口个数为3个,窗口权重按由近及远依次设定为w1=2,w2=1.5,w3=1。至此,本节一共得到83×3=249个特征。
2.3 深度森林算法
深度森林算法的产生基于两个目的:一方面,增强输入特征的差异性;另一方面,增强模型对特征的处理能力。前者通过多粒度扫描模块实现,后者通过多层级联森林模块实现。
图2为多粒度扫描过程,多粒度扫描其实是引用了类似卷积神经网络滑动窗口的技术,目前主要针对输入的一维时序序列和二维图像数据进行扫描和特征提取。本文分类任务是将输入的一维时序数据分为两类,在扫描一维时序特征时,假设输入特征向量为300维,采样窗口设定为100维,通过逐步滑窗采样,最终扫描产生201个子样本(默认采样步长为1,所以子样本数=(300-100)/1+1=201)。将子样本分别输入森林A和森林B中进行训练,每个样本输出一个2维的概率特征向量,原始输入的300维特征向量经多粒度扫描后最终生成804维类特征向量,将所有向量连接起来作为级联森林的输入特征向量。

图2 多粒度扫描过程
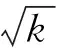
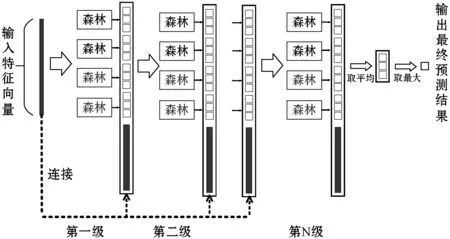
图3 级联森林结构的图示
多粒度扫描的特征输入级联森林模块,经过层层学习最终得到训练的学习模型和预测结果。本文提取的原始数据为一维时序数据,输入的特征向量为249维。特征的提取基于用户历史行为数据,特征间具有很强的时序关系,故在多粒度扫描模块,我们设计3个滑动窗口分别进行特征提取,滑动窗口维度分别为50维、100维、150维,滑动步长均为1。基于gcForest的用户复购预测模型整体结构如图4所示。
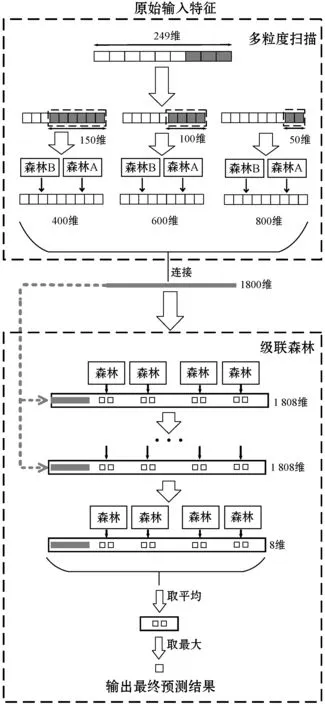
图4 用户复购预测模型整体结构图示
其输入是特征工程模块提取的原始样本集(其中一行样本数据由基本特征、数量特征和时序特征等5类特征构成的数据和标签组成),经多粒度扫描模块后,共提取特征1 800维,作为级联森林第一级的输入,第一级训练后产生4×2=8维增强特征,加上1 800维粒度扫描得到的特征向量,形成1 808维变换特征向量作为第二级的输入。以此类推,完成整个级联森林的模型训练,重复以上过程直到模型性能收敛。算法1是深度森林模型的详细算法描述。
算法1深度森林算法描述
Input:训练集D={(x1,y1),(x2,y2),…,(xn,yn)}
测试集T={(xn+1,yn+1),(xn+2,yn+2),…,(xm,ym)}
深度森林最大层数M
Process
D0=多粒度扫描(D)
fori in Mdo
用训练集D训练得到2个随机森林和2个完全随机森林,两者结合构成级联森林的第i层;

计算测试集T在当前层的模型上的预测准确率pi
ifpi-pi-1<0(i>0)do
训练终止,输出深度森林模型。
end
else
得到级联森林第i层输出的二维类向量Y,与Di-1(i>0)中的特征进行拼接,得到下一层森林的输入Di+1
endif
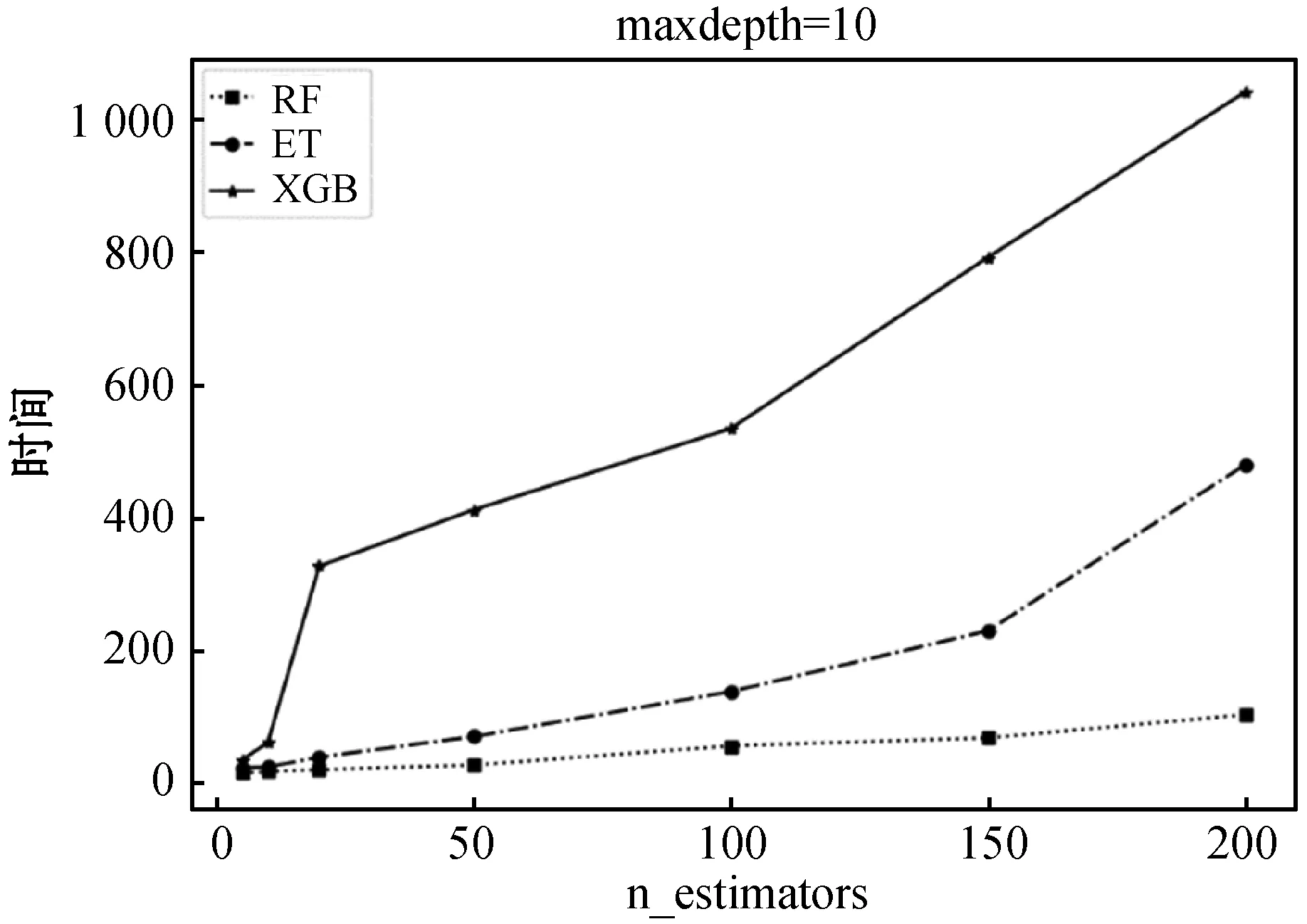
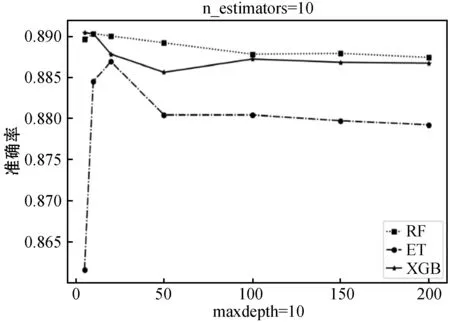
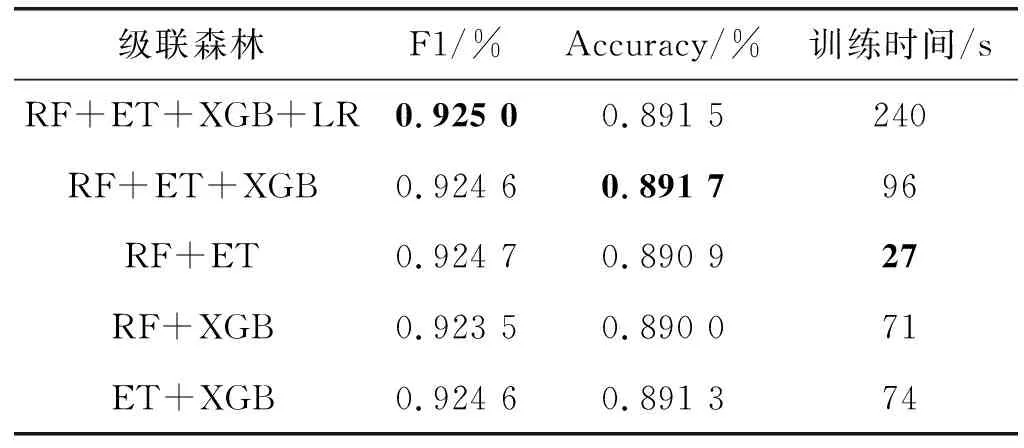
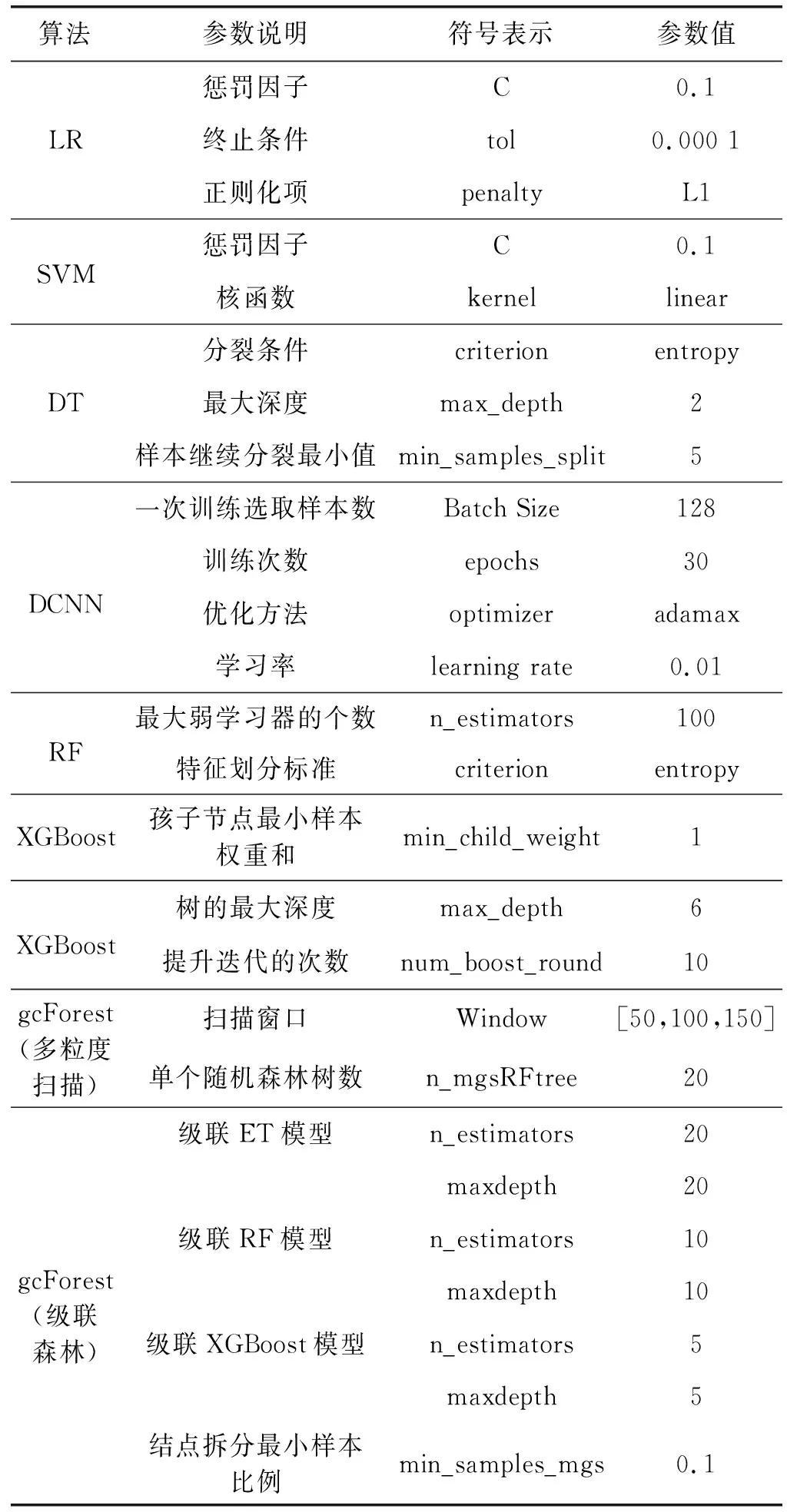
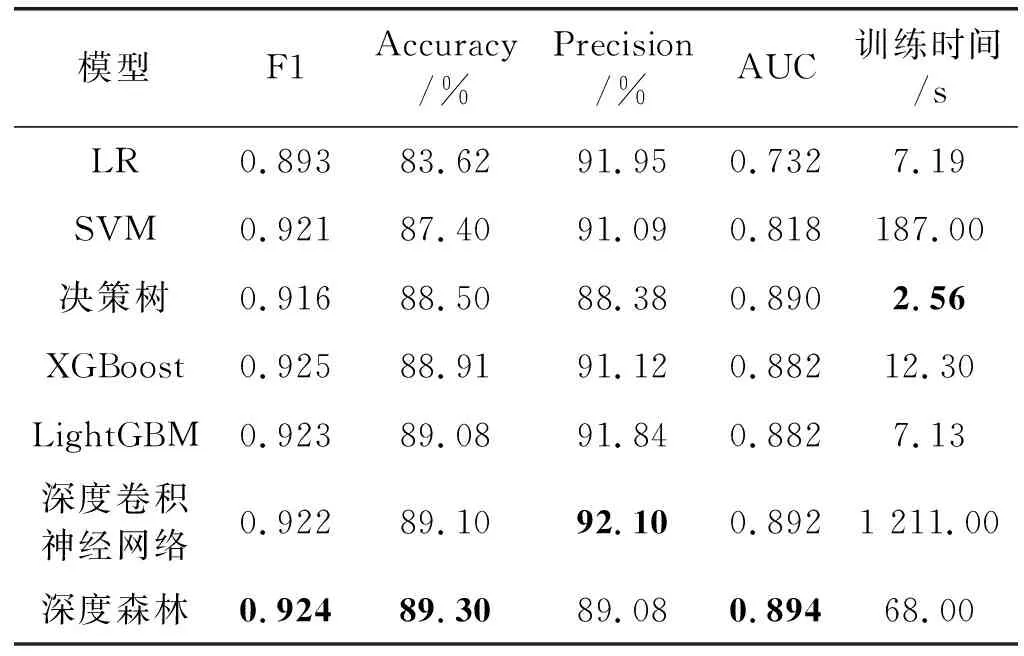
ifi 训练终止,输出深度森林模型 end else 跳转至for循环 endif endfor Output:深度森林模型 本实验基于京东平台2017年大数据算法比赛提供的真实数据集,为京东商城在2016年5月1日至2017年4月30日期间,9万多名用户对近4 000多个日用品的浏览、关注、购买和评论行为。 数据集中包括两个特殊的时间段:双十一期间和6·18期间,据统计,京东2019年双十一当天日活跃用户数(DAU)达4 786万,为平时日活跃用户数的几十倍,故对双十一和6·18期间的用户行为参考平日数据进行均衡化处理;特征矩阵中每一条样本由user_id唯一标识,该属性不能刻画样本自身的分布规律,属无关属性,应删除;构建数量特征时,存在少量用户只有用户描述,无任何行为数据,将该类用户信息删除,不参与训练;原始数据集正负样本不均衡(16 774个负样本和48 718个正样本),本文使用SMOTE技术[20]生成23 824个新的负样本得到正负样本比为1.2 ∶1的均衡数据集。 训练集构建时间范围为2016年9月1日—2017年3月31日,其中2016年9月1日—2017年2月28日为特征提取时间范围,由三个时间滑动窗口共同提取特征,2017年3月份的用户购买行为作为标签(0代表无购买行为,1代表至少有一次购买行为)。同理,测试集在2016年10月1日—2017年3月31日区间内提取特征,以2017年4月份的购买行为作为标签进行预测评估。 本文实验采用5个标准的评估指标:准确率(Accuracy)、查准率(Precious)、查全率(Recall)、F1和AUC(Area Under Curve)。准确率指的是正确预测的样本数占总预测样本数的比值,它不考虑预测的样本是正例还是反例。查准率指正确预测的正样本数占所有预测为正样本的数量的比值,查准率越高,证明对有购买行为预测越准确,推荐算法越精准。查全率指正确预测的正样本数占真实正样本总数的比值。查准率和查全率是相互作用的两个指标,一个指标的增加会导致另一指标的下降,因此,选用F1作为衡量模型整体性的指标。AUC被定义为ROC曲线下的面积,其取值区间为[0,1],AUC值可以很直观地评估模型表现,值越接近1表示模型分类效果越好。 评估指标表示如式(7)-式(10)所示。 (7) (8) (9) (10) 本实验平台基于Python语言搭建,实验硬件环境为英特尔i7- 7700 CPU @ 3.60 GHz处理器,8 GB内存,操作系统为Windows 10专业版,实验的主要配置如表1所示。 表1 实验配置表 深度森林模型中森林的构建是模型建立的核心,而决策树的构建是森林的核心,因此森林中决策树的数量和深度会直接影响模型的训练效率和分类效果。深度森林可以级联多种模型,多样性对模型的设计尤为关键[21],因此,本文尝试级联逻辑回归(LR)、随机森林(RF)、极端随机树(ET)、梯度提升树(XGB)中多种森林模型,并通过实验确定模型种类和超参数。 如图5(a)所示,各个森林模型整体均呈现随n_estimate参数增大准确率先增加后趋向平稳的趋势。其中,RF和XGB模型预测准确率相当。由于n_estimate参数的增加会带来时间上的开销,图5(b)对模型训练时间进行对比,可以明显看出,n_estimate参数越大,模型的训练时间越长。 (a) 准确率评估表现 (b) 训练时间评估表现图5 n_estimators参数不同设置下模型表现 此外,我们对各模型随参数maxdepth的变化情况进行对比。图6(a)可知,随着maxdepth参数的增大,模型准确率不但没有提高,反而有所降低。在图6(b)中,对于RF和ET模型而言,maxdepth参数的增大没有带来时间上的开销,但XGB模型随maxdepth参数的增大,运行时间增加非常明显。 (a) 准确率指标评估 (b) 训练时间上的表现图6 maxdepth参数不同设置下模型的表现 通过综合分析图5、图6中模型表现,对以上三个模型的超参数进行设置(表2)。 表2 级联森林中各模型参数设置 以上提到的三种模型在分类表现上各有优势:RF模型的方差和偏差都比较低,因而在实验中拥有最高的准确率和最快的训练效率;ET模型的方差相对RF进一步减少,偏差有所增大,分类准确率稍有下降;XGBoost(表3中简称:XGB)作为梯度提升集成学习算法的典型代表,拥有非常高的准确率,只是时间开销比较大。级联模型的多样性直接影响分类效果,本文通过级联以上多个模型,得到多种级联森林的实验结果(表3)。 表3 多种级联森林分类预测评估 通过对模型表现进行多方面对比,综合考虑模型准确率和运行时间等评估指标,我们选择RF、ET和XGB三种模型组成深度森林的级联森林模块。 为突出深度森林算法的优势,基于以上数据集,本文引入传统机器学习算法:逻辑回归(LR)、支持向量机(SVM)、决策树(Decision Tree,DT)、深度卷积神经网络(DCNN)和集成算法随机森林(Random Forest,RF)、XGBoost进行预测和对比,各算法的部分超参数设置在表4中列出。表5列出了模型在各个指标上的表现情况,其中每个评估指标上表现最好的算法使用黑体加粗标识。 表4 本文所用机器学习算法超参数设置表 表5 各模型在不同指标上的表现 可以看出,深度森林模型在预测用户复购行为上的表现比传统机器学习算法更好,与深度卷积神经网络相比,虽然模型在预测准确率上优势不明显,但深度森林模型的训练时间仅为深度卷积神经网络的1/20,随着数据量的增加,模型训练时间差距可能会更加明显。对电商平台应用场景而言,这是非常重要的评估标准。 本文将深度森林算法应用于真实数据集下用户购买行为预测中,同时引入时间滑动窗口技术和窗口权重递减设置,经数据分析、特征提取、缺失值剔除及数据平衡化等处理后得到用于训练的特征数据。后从模型多样性的角度出发,构建由多个集成学习算法组成的深度森林模型。电商平台真实场景下,数据量更大,数据更新更快,因此本文模型还有更进一步改进和提升的空间。3 实验分析
3.1 数据处理
3.2 评估指标
3.3 实验环境
4 实验结果及分析



5 结 语
