改进YOLOv3算法及其在航拍图像车辆检测中的应用
2023-02-17丛眸张平王宁
丛 眸 张 平 王 宁
1(长春理工大学计算机科学技术学院 吉林 长春 130022) 2(陆军装甲兵学院 北京 100072) 3(公安部第三研究所 北京 100142)
0 引 言
航拍图像中的车辆目标检测在空中监测等领域具有重要的应用,但航拍图像中的车辆目标存在目标体积小、细节不充分等特点,给目标检测任务带来了极大的挑战[1]。随着计算机视觉技术的快速发展,基于卷积神经网络(Convolutional Neural Networks,CNN)的目标检测方法因其无须人工提取特征以及适应性强等特点已成为目标检测领域中的主流方法,并得到了广泛的应用[2]。目前,基于CNN的目标检测方法主要可以分为两种:基于建议区域提取的方法和基于回归的方法[3-4]。基于建议区域提取的方法的思路是首先在卷积特征图上提取建议区域,而后对建议区域进行精确检测。这种方法具有检测精度较高,但检测速度较慢的特点,其代表方法有R-CNN[5]、Faster R-CNN[6]、R-FCN[7]等。基于回归的方法主要从回归的角度进行目标检测,只需要进行单次检测就能得到检测结果,检测速度快,代表方法有SSD[8]、YOLO[9]等。
YOLOv3[10]是在YOLO的基础上发展而来的,是YOLO系列方法的集大成者,具有检测精度高、速度快等优点。目前,YOLOv3在诸多目标检测场景中得到了广泛的应用,并针对具体应用场景进行了相应的改进。王兵等[11]针对安全帽的检测任务,在YOLOv3的基础上,改进了广义交并比的计算方法以及模型的损失函数,改进后的算法取得了较好的检测效果。Kharchenko等[12]将简化后的YOLOv3应用于航拍图像的目标检测,通过迁移学习以及重新设计锚框等,实现了较好的检测效果。
本文将YOLOv3应用于航拍图像中的车辆目标检测领域,为提高目标检测的精度,对YOLOv3的网络参数与结构进行了改进。使用K-means++方法[13]对航拍图像车辆数据集进行维度聚类,并对YOLOv3的锚框参数进行修改,从而加快网络训练时的收敛速度。针对航拍车辆数据集中的目标尺度较小以及特征不明显等特点,通过改进网络结构,在特征提取网络中集成空间金字塔池化(Spatial Pyramid Pooling,SPP)模块[14]来丰富卷积特征的表达能力,以及设计4个不同尺度的卷积特征图并通过卷积特征融合机制来实现对多层级卷积特征的融合,从而实现对航拍图像车辆目标的精确检测。
1 YOLOv3算法原理
YOLOv3是Redmon等[15]在YOLOv2的基础上改进而来的,采用Darknet53网络提取图像的卷积特征,并结合残差网络中的短连接以及多尺度检测的思想,在最后的特征金字塔网络上通过YOLO层来实现对目标的精确检测,网络结构如图1所示。
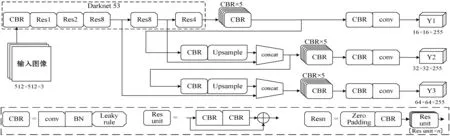
图1 YOLOv3的网络结构
YOLOv3使用较多的CBR和Res结构,其中CBR表示将1×1或3×3的卷积核进行标准规范化操作,而后使用Leaky rule激活函数进行非线性化;Resn由CBR与n个Res unit组成,其中,Res unit由2个不同尺度的卷积核构成的CBR和短连接组成。为实现细粒度检测,YOLOv3使用了多尺度特征进行目标检测,而Darknet53最后的卷积层输出的卷积特征尺度为16×16,因此YOLOv3通过采用了上采样与浅层卷积特征图连接,输出3个不同尺度的卷积特征,并在不同尺度应用不同尺度的锚框,从而得到最终的检测结果。YOLOv3借鉴了残差网络结构,从而形成了更深的网络层级,并结合多尺度检测,提升目标检测的性能,特别是对小目标检测的性能。此外,在整个YOLOv3网络舍弃了目标检测模型中经常使用的池化层和全连接层,而是通过在前向传播过程中改变卷积的步长来实现卷积特征尺度的变化,极大地降低了网络的计算量,使其具有较高的检测速度。
目标检测模型的损失通常由位置损失和分类损失组成,而YOLOv3的损失lall除了由分类损失lclass和位置损失lcoord之外,还增加了置信度损失lconf,其中置信度损失lconf由存在目标的网格的损失与不存在目标的网格的损失组成。
2 改进的YOLOv3检测模型
2.1 锚框参数优化
网络模型能够通过不断地学习训练来调整边界框的大小,但合适的初始化边界框尺寸能够加快网络的训练并提高网络模型的性能。YOLOv3中引入了Faster R-CNN中锚框的思想,并通过K-means方法计算锚框的大小,即首先随机选取数据集中K个点作为聚类中心,然后针对数据集中的每个样本计算其到K个聚类中心的距离并将其分类到距离最小的聚类中心所对应的类别中,接着再针对每个类别重新计算聚类中心,最后重复上述2个步骤,直到聚类中心的位置不再变化。通过K-means[16]得到的锚框尺度有效地提升了YOLOv3的性能,但直接使用已有的锚框尺度并不适用于航拍图像车辆数据集。此外,由于K-means的聚类结果受初始点的选取影响较大。为更好地选取锚框的尺寸,本文使用K-means++算法代替原有的K-means方法。与K-means相比,K-means++对初始点的选择进行了改进,放弃了原有的随机选择K个聚类中心的理念,而是通过随机选取一个聚类中心之后通过轮盘法选取后续的聚类中心,使得K个聚类中心的距离足够远。在得到K个聚类中心之后再继续原K-means计算锚框尺寸。与K-means相比,K-means++计算初始点的选择时耗费了一点的时间,但在迭代过程中能够更快收敛,提高了网络训练速度。
由于改进后的网络在4个不同分辨率的卷积特征图上进行目标检测,因此本文通过K-means++算法得到了12个锚框尺度,并按照锚框大小按照卷积特征图的分辨率将12个锚框尺度平均分配到每个卷积特征图上,即每个卷积特征图上分配3个不同尺度的锚框。
2.2 网络结构改进
在YOLOv3的基础上,针对航拍图像中车辆目标的特点,通过在Darknet53的第5层与第6层之间集成SPP模块来丰富卷积特征的表达能力,以及在特征提取网络之后结合卷积特征融合制来融合多层级卷积特征,并设计4个不同尺度的卷积特征图来预测目标来提高目标检测的性能。改进后的网络结构如图2所示。
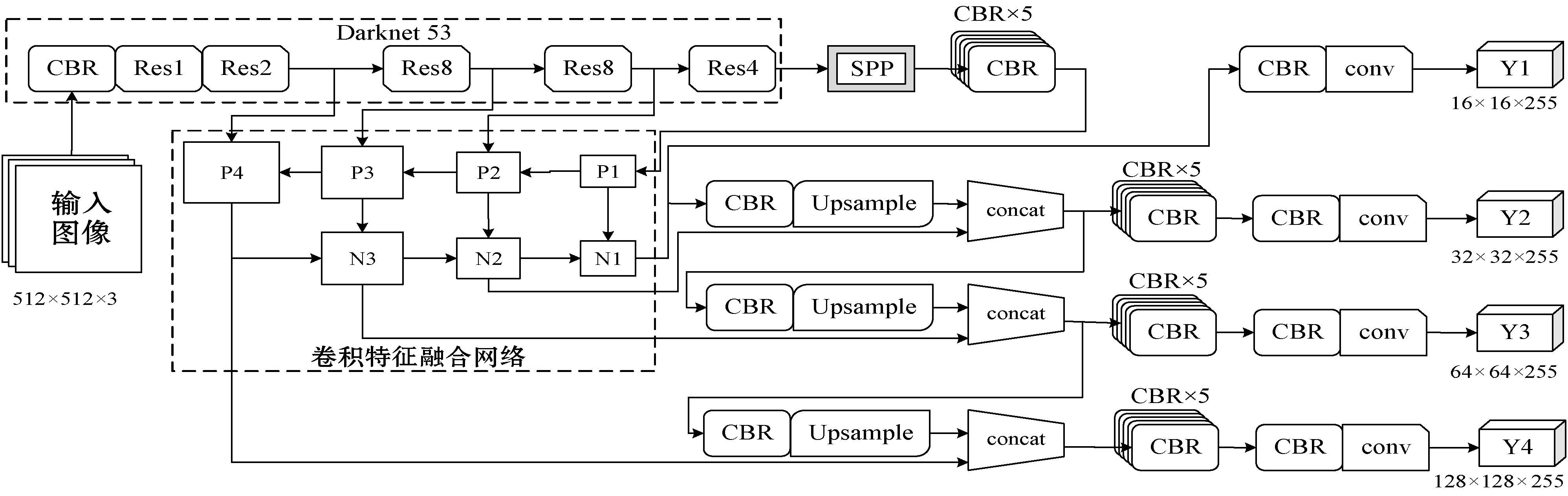
图2 改进后的YOLOv3网络结构
2.2.1集成SPP模块的特征提取网络
SPP由微软研究院的何凯明提出,其最初目的是用于解决目标检测模型中对图像区域裁剪、缩放时图像失真问题、对图像重复提取卷积特征的问题。随着研究的不断深入,SPP可以用于实现全局特征与局部特征的融合,从而丰富卷积特征的表达能力,更有利于实现对不同尺度目标的自动检测。
SPP模块的详细结构如图3所示。本文在YOLOv3中的第5层与第6层之间集成了SPP模块。SPP模块有4个并行的分支组成,分别是卷积核尺度为5×5、9×9和13×13的池化操作以及一个短连接,其中池化操作采取的池化方式为步长为1的最大值池化,最后联合4个分支的卷积特征并通过1×1和3×3的卷积核进行再次融合。SPP模块能够有效地提升YOLOv3的检测效果。
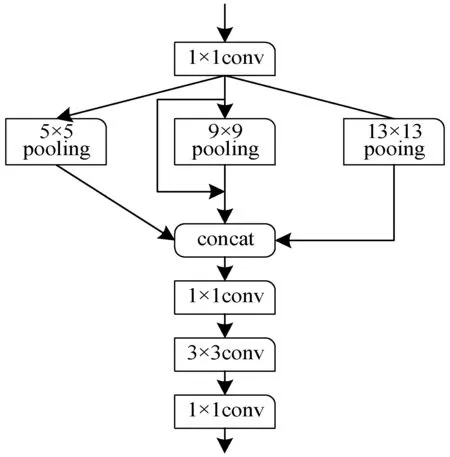
图3 SPP模块详细结构
2.2.2融合多层卷积特征的特征金字塔
随着深度CNN层级的不断提升,深层卷积特征的分辨率不断降低,但具有更好的特征表达能力,而浅层的卷积特征的分辨率较大,特征表达能力不如深层卷积特征。YOLOv3利用了3个不同分辨率的卷积特征来实现对目标的检测,但对于这些不同分辨率的卷积特征图没有进行较好的融合,本文针对航拍图像中车辆目标尺度较少的特点,设计了4层卷积特征金字塔来对目标进行检测,并通过结合特征融合机制,使得输入到YOLO检测层之前的卷积特征更好地融合了深层卷积特征与浅层卷积特征。卷积特征融合网络主要分为2部分:自下而上的特征融合以及自上而下的特征融合,其结构如图2中虚线框内所示,具体实现方式如下:首先,将SPP模块得到的卷积特征经过CBR送入P1,并将其通过上采样增大一倍的分辨率,使其与darknet53的第5层卷积特征具有相同的尺寸;接着,将上采样后的卷积特征与第5层的卷积特征进行融合得到P2,将P2再次通过上采样增大一倍的分辨率并与darknet53的第4层卷积特征相融合得到P3,并按照类似的步骤得到P4,上述部分为自下而上的特征融合;然后,将P4通过池化降低一倍的分辨率并与P3相融合,得到卷积特征N3,并按照类似步骤得到P2;最后,将N2降低一倍的分辨率并与P1相融合,上述步骤为自上而下的特征融合。至此,特征融合步骤完成,而后将N1、N2和N3分别送入YOLOv3原有的网络结构中,并按照相同的网络结构设计出应用于P4的检测层,并完成后续的目标检测流程。相比于YOLOv3直接使用单层卷积特征(如Y1)或简单融合多层卷积特征,本文通过特征融合机制能够更好地对多层卷积特征进行融合,使得融合后的卷积特征同时具有浅层卷积特征与深层卷积特征的特点,有利于更好地实现对目标的自动检测。
3 实验与结果分析
3.1 航拍图像车辆目标检测数据集
VEDAI航拍图像车辆目标检测数据集[17]由原始大视场卫星图像分割成较小图像组成,共分为4个子集,即大尺度彩色图像(LCI)、小尺度彩色图像(SCI)、大尺度红外图像(LII)、小尺度红外图像(SII)。其中,小尺度图像的分辨率512×512,是分辨率为1 024×1 024的大尺度图像的缩小版。由于本文主要针对彩色图像进行目标检测以及输入图像的分辨率为512×512,因此本文选择了VEDAI数据集的子集SCI作为航拍图像车辆目标检测数据集。SCI数据集共标注了6种类型的车辆,并将这6种不同类型的车辆目标分为小型车辆与大型车辆等2大类,各类型车辆的目标数量如表1所示。
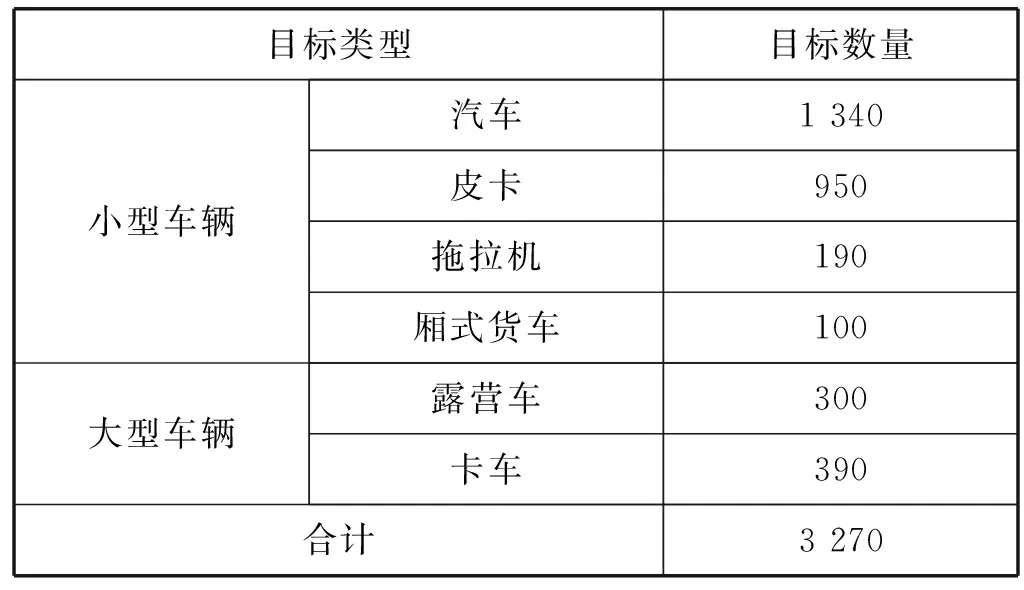
表1 SCI数据集中各类目标的数量
根据SCI数据集中对目标类型的分类,采用2种方法来验证改进后的YOLOv3对车辆目标的检测性能,并与原YOLOv3进行对比:1) 将SCI数据集中的车辆类型分为2类,即小型车辆与大型车辆,并随机挑选出80%的图像作为训练集,其余的20%作为测试集;2) 对SCI数据集中的6类车辆目标进行检测,并对网络进行模型分解实验,验证本文提出各改进策略的有效性。
3.2 结果分析
所有的实验均在操作系统为ubuntu16.04、CPU:i7- 8700/GPU:RTX 2080Ti的图像处理工作站上进行,采用的深度学习架构为Keras。对YOLOv3以及改进后的YOLOv3分别进行训练与测试,其中训练阶段的初始学习率为0.001,当训练迭代次数为10 000次和20 000次时,学习率分别降为0.000 1和0.000 01,并在迭代次数为30 000时终止网络训练。由于SCI数据集中图像以及目标数量相对较少,本文还通过图像旋转、增加对比度等数据增强手段来提高网络的泛化能力。
3.2.1实验1
将SCI数据集中的车辆目标分为2类:小型车辆与大型车辆,分别对YOLOv3以及改进后的YOLOv3进行测试。采用信息检索领域中对相关性的评价指标Precision-Recall曲线来反映各模型对检测出的目标准确程度与召回程度,即查准率P、查全率R、综合指数F1、PR曲线下面积,即平均均值精度(mean average precision,mAP)。测试结果如表2所示。本文方法的PR曲线如图4所示。
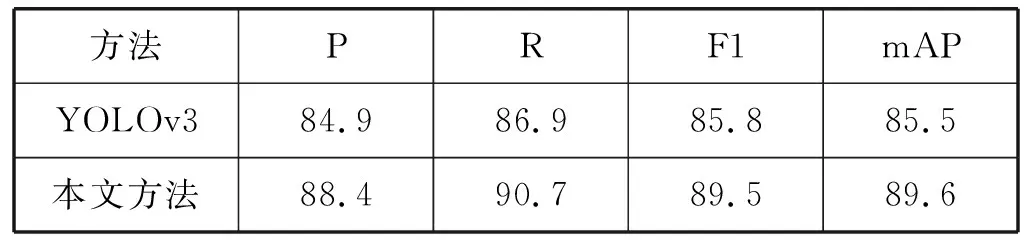
表2 不同方法对2类目标检测结果的对比(%)
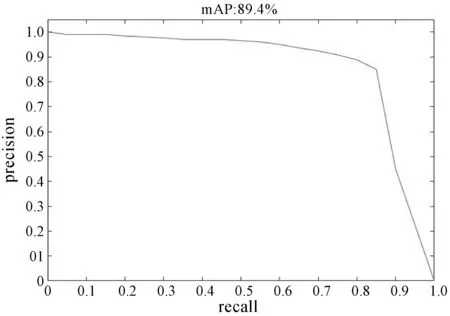
图4 本文方法取得的PR曲线
从表2可以看出,与YOLOv3相比,本文提出的改进YOLOv3能够有效地提升对航拍图像中的车辆目标的检测性能,其中查准率由84.9%提升到88.4%,查全率由86.9%提高到90.7%,综合指数F1由85.8%提高到89.5%,mAP由85.5%提高到89.6%。
3.2.2实验2
分别应用YOLOv3以及本文方法对SCI数据集中的6类车辆目标进行检测,并计算各类目标的均值精确度(Average Precision,AP)以及整体的mAP。测试结果如表3所示,改进后的YOLOv3将mAP从59.7%提升到了64.2%,其中6类目标中有5类目标的AP得到了提升,只有卡车类目标的AP略有下降,但下降幅度较少。
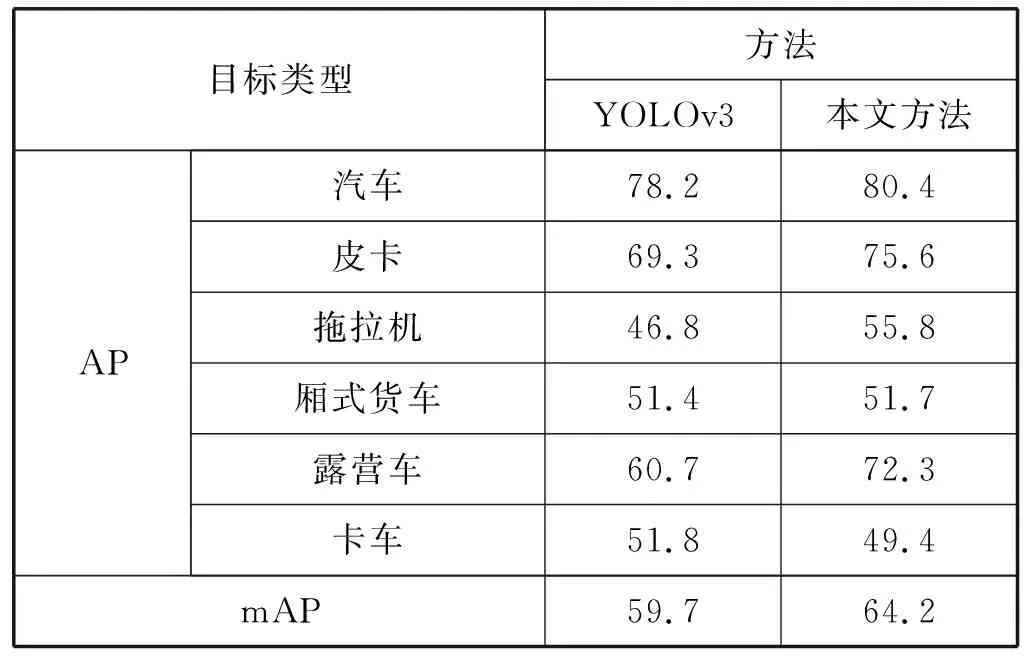
表3 不同方法对6类目标检测结果的对比(%)
与YOLOv3相比,本文提出的网络结构有3处改进,因此在测试时需要对各改进策略进行单独测试。此外,本文主要针对小目标进行检测,因此还与经典的小目标检测模型FPN[18]进行了对比。在SCI数据集上的测试模型共有5种,分别是原YOLOv3、在卷积特征提取网络中集成SPP模块的YOLOv3(YOLOv3-spp)、结合卷积特征融合机制的YOLOv3(RH-YOLOv3)、采用4层卷积特征金字塔改进的YOLOv3(YOLOv3-ft)、本文方法、FPN。各方法在SCI数据集上取得的mAP如表4所示。
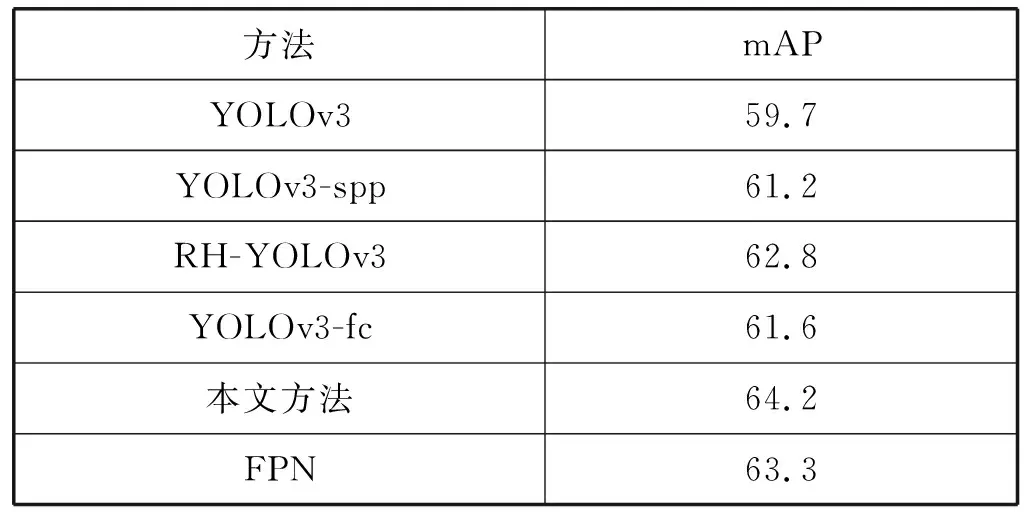
表4 各方法在SCI数据集上取得的mAP(%)
可以看出,本文提出的几种改进措施均能有效地提升航拍图像车辆目标检测的mAP,其中,在特征提取网络上集成SPP模块来丰富特征的表达能力能够使mAP提升1.5百分点;通过卷积特征融合机制来融合多层级的卷积特征可以使mAP提升3.1百分点;使用4层卷积特征金字塔则能够使mAP提升1.9百分点;综合使用上述几种改进措施,则能够使mAP提升4.5百分点,这也证明了本文使用的上述3种策略的有效性。FPN取得的mAP为63.3%,比本文方法取得的mAP低了0.9百分点,这也证明了本文方法能够更好地适用于航拍图像中车辆目标检测任务。
图5展示了本文方法和YOLOv3的部分检测结果。对于第一行中图像,YOLOv3和本文方法均能检测出航拍图像中的2个汽车目标,但本文方法的检测置信度高于YOLOv3。在第2行的航拍图像中存在3个目标,但YOLOv3只检测出了2个目标,漏检了图像右侧的卡车目标,而本文方法检测出了全部的目标,且具有较高的置信度。

(a) YOLOv3 (b) 本文方法图5 YOLOv3与本文方法的部分检测结果对比
4 结 语
本文针对航拍图像中的车辆目标检测任务,提出一种YOLOv3改进方法。使用K-means++聚类方法来优化锚框参数并提高网络训练效率。在YOLOv3的基础上,通过在特征提取网络中集成SPP模块,以及通过卷积特征融合网络来融合多层级的卷积特征并设置4层卷积特征金字塔来预测航拍图像中的车辆目标。改进的YOLOv3使mAP从原来的59.7%提升到了64.2%,有效地提高了航拍图像中车辆目标检测的精度。
