面向泛娱乐文本的层次多标签分类方法
2023-02-17陈若愚刘秀磊于汝意
陈若愚 刘秀磊 于汝意
1(北京信息科技大学网络文化与数字传播北京市重点实验室 北京 100101) 2(北京信息科技大学数据与科学情报分析实验室 北京 100101)
0 引 言
泛娱乐指的是以知识产权(Intellectual Property,IP)资源为核心,创建以互联网和移动互联网为基础多个领域共生的粉丝经济[1]。泛娱乐化现象的表现形式为内容生产的娱乐化,信息的内容、形式和包装等各方面都渗入了娱乐元素[2]。随着论坛、博客、网络杂志及微博等互联网媒体和手机等移动终端媒体的普及,大众对网络的使用由工作学习扩大到生活娱乐中。泛娱乐化现象延伸至互联网等新型媒体中,同时互联网等新型媒体的迅猛发展也加快了泛娱乐信息传播速度。
在多标签分类中,若类别标签存在树形结构或者有向无环图等预定义结构时,将其称之为层次多标签分类。目前针对多标签分类问题的解决主要有问题转换和算法适应两种方法[3-5]。问题转换中常见的方法有二元关联、分类器链等算法。二元关联方法不考虑标签关联性,将多标签学习问题进行转化,将原问题转换为多个独立二分类问题。Read等[6]提出了分类器链算法,将原问题转化为呈链式结构的二分类问题,基于前面分类器的输出来预测后续分类器的结果[7]。该方法虽然考虑了标签相关性,但因链式结构的串行化特点而无法实现并行化。算法适应中常见的方法有MLKNN、IMLIA和RankSVM等。MLKNN算法基于K近邻算法改进而来,使得该算法可以处理多标签分类问题,具有较好的表现[8]。但是MLKNN算法缺乏对标签相关性的处理,因此张敏灵[9]对该算法进行改进,通过融合标签相关性进而提出了IMLIA算法。RankSVM提出了一种新的思路,将原来的排序问题转换成可以使用SVM算法解决的分类问题[10]。
层次多标签分类在蛋白质功能预测、基因功能预测等领域具有较为广泛的研究。在蛋白质功能预测领域,Otero等[11]提出了一种针对蛋白质功能预测的分层多标签分类问题的蚁群优化算法,在涉及数百个或数千个类别标签的十六个具有挑战性的生物信息学数据集上进行评估,并将其与用于分层多标签分类的最新决策树归纳算法进行比较,取得了较好的效果。Cerri等[12]提出了一种名为HMC-LMLP的局部方法,该方法在每个层次级别使用一个多层感知器,上一级的预测结果作为下一级预测的网络的输入,而且利用两种截然不同的多层感知器算法:反向传播和弹性反向传播。另外,该方法还使用专门针对多标签问题的错误度量来训练网络。在蛋白质功能预测数据集中,该方法具有竞争性的预测准确性。Yuan等[13]提出了具有多个头部和多个末端的深度神经网络(DNN)模型,该方法在基准数据集上相较于传统方法有明显提升。在基因功能预测领域,Barutcuoglu等[14]提出了一个贝叶斯框架,利用基于功能分类约束来组合多个分类器。通过在贝叶斯框架中组合预测,以获得最可能的一致预测集;该方法在GO的105个节点的子层次结构中,该框架改进了对93个节点的预测,取得了较好的效果。Stojanova等[15]提出了一种基于树的算法,用于在分层多标签分类(HMC)设置中,该算法考虑网络自相关,利用2个不同的PPI网络,在12个酵母数据集上取得了显著的效果。Fodeh等[16]提出了一种创新的预测系统的开发和评估方法,利用非负矩阵分解(NMF)进行特征缩减,使用二进制相关方法对基因进行分类,并尝试了几种分类器,表明二元关联和K最近邻(KNN)分类器的组合效果最好,在UniProtKB/Swiss-Prot数据集的评估显示,按照F1量度,最佳性能为0.84。Li等[17]通过使用基因本体层次结构注释基因功能来改进多实例层次聚类,该方法将基因本体层次结构与多实例多标签学习框架结构结合在一起。使用多标签支持向量机(MLSVM)和多标签K最近邻算法(MLKNN)来预测基因的功能。
虽然上述算法在各自领域数据集上取得了较好的效果,但是并未对泛娱乐领域层次结构中有向无环图结构的数据处理提供解决方法。本文在总结分析现有的层次多标签分类算法的基础上,提出一种基于最优路径的层次多标签分类方法。该方法首先根据现有标签构建DAG结构并将DAG结构转化为较易处理的树形结构;然后,采用局部策略为树形结构中每个节点分别训练基分类器,同时为每个节点设置贡献值,贡献值由分类器输出概率与层次权重组合而成,贡献值大于阈值时该节点设置为1,否则为0;最后,对树形结构进行深度优先遍历生成路径,计算各路径得分,选择满足层次约束且得分最高的路径作为最终预测集合。
1 基于最优路径层次多标签分类方法
泛娱乐领域层次多标签分类中,标签之间一般具有层次结构特征,如图1所示。针对现有标签的层次结构,为了融合标签间关联性,提高分类器分类性能,本文提出基于最优路径层次多标签分类方法。首先,根据标签层次结构构建有向无环图结构并随后转化为树形结构;然后,采用局部策略为结构中的每个节点对应的标签训练一个分类器;其中,基分类器采用支持向量机方法;最后,通过组合各路径中各节点的预测结果得到整体预测结果,设计路径打分策略,根据阈值和层次约束,选择最优路径作为最终预测标签集合。
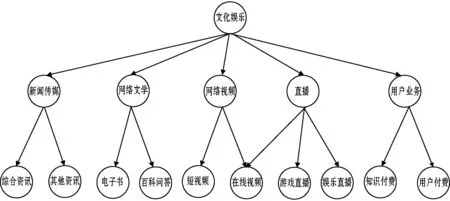
图1 泛娱乐文本情报类别标签层次结构
1.1 层次结构构建
当前的主要标签体系如图2所示。一级标签“文化娱乐”;二级标签有“新闻传媒”“网络视频”“网络文学”“直播”和“用户业务”;三级标签有“综合资讯”“其他资讯”“游戏直播”“娱乐直播”“知识付费”和“用户付费”等。其中“其他资讯”标签下的数据由“媒体号”“科技资讯”“军事资讯”和“报纸杂志”等合并而成。正如图2中二级标签下实线框内的标签,此类标签下的数据量较少,不再为该标签训练分类器,后期由人工标注。本文处理的标签为图2中虚线框内的标签。

图2 标签体系
层次多标签分类中,根据面临的标签体系,分为树形结构和有向无环图结构。不同于树形结构,有向无环图结构节点能存在多个父节点。目前的标签体系中,三级标签“短视频”“在线视频”属于二级标签“网络视频”,也属于二级标签“直播”,存在一个节点有多个父节点的结构特征。因此,根据当前面对的标签结构特征,构建有向无环图结构,用于挖掘标签的层次结构信息。
本文将有向无环图结构转化为树形结构进行层次多标签文本分类。初始时设置DAG结构中所有节点的Visited属性为False,对DAG结构进行广度优先遍历,如果遍历到的节点Visited属性为True,则复制该节点及其子节点,并且子节点的Visited属性设置为False,更新该节点的父节点的指针,指向新增节点;如果遍历到的节点Visited属性为False,则将该节点的Visited属性设置为True。
如图3所示,将DAG结构转换成Tree结构。节点D第二次遍历时,Visited属性已经设置为True,因此复制D节点,生成节点D2,并更改父节点的指针,指向节点D2,转化后如图3中的TREE。

图3 DAG结构转TREE结构
1.2 局部分类器训练
SVM在解决问题时将结构风险以及经验风险最小化作为考察因素,所以具有稳定性。SVM采用铰链损失函数作为代价函数,由于支持向量唯一决定了决策边界,其取值特点导致支持向量机具有稀疏性。考虑到支持向量机稳定性、稀疏性的优点,以及本文研究内容使用的数据集特点,采用支持向量机作为基分类器。
对于具有N个实例的语料,分配80%的实例作为训练集,记为D,其他实例作为测试集T。Le=(Xe,Ye),其中:Xe为300维的特征向量,Ye∈L;L={y1,y2,…,yn},表示实例所属的类别或标签的有限集合。Ye是L的元素,若某实例在某类别下判定为正,则yi=1,若实例在某类别下判定为负,则yi=0,因此Ye∈{0,1}n。
除了根节点之外,在层次结构中的所有节点都表示一个类别或者标签,用yi表示,针对每一个非叶节点,yi训练一个分类器Ci。基分类器Ci可以选择能给出预测类别的概率值或者可以把返回值转化成概率值的多类分类器。基分类器预测的样本包含yi标签下的样本以及yi标签的子标签下的样本,记为child(yi),不归属于yi和child(yi)的样本,记为unchild(yi)。基分类器的训练正样本由child(yi)为1的样本构成,这些样本的标注的标签集合都含有yi的子节点标签,用PS(Ci)表示。基分类器训练集的负样本由不归属于yi和child(
yi)的样本组成,用NS(Ci)表示。考虑到训练数据的平衡性,有需要时对数据进行欠采样,欠采样数据的数量与yi及child(yi)对应的训练样本数量的均值成正比。图4给出了节点y1基分类器训练集构造过程。正样本PS(C1)包含的数据为归类到子标签y3、y4的数据,负样本NS(C1)包含的数据为不属于y1标签的y2、y5和y6标签下的数据。考虑到正负样本的均衡,定义正样本的标签个数为lc,样本数量为InsC,则负样本的样本数量为正样本各标签数量的平均数,即:count=InsC/lc。
1.3 最优路径选择
基于最优路径的层次多标签分类技术通过局部策略为每个标签训练基分类器。每个节点的贡献值C由该节点所在层次的权重ω以及基分类器预测为正的概率P组合而成。通过组合路径上各节点的贡献值,将预测结果合并为一个二进制分值y。其中,权重由当前标签在结构中所处的层次决定。错误的分类发生在顶部的代价往往比发生在底部的代价更大,同时层次高的标签拥有更多的训练数据以及类别之间具有大的差异性,对分类具有更高的贡献,因此,层次越深,则权重越小,权重的计算式表示为:
(1)
式中:level(i)为节点i的层次深度;maxL为最长路径长度;权重随着层次加深而线性减小,保证权重延层均匀分布。每条路径的得分计算为:
(2)
式中:scorem表示第m条路径的得分;n表示路径中的节点数;C(yi)表示节点yi的贡献值;ω(yi)示节点yi的权重;P(yi|xe)表示对实例xe在局部基分类器yi预测为正的概率。
以图5为例,图中除root根节点外,每个节点均计算该节点的权重与概率输出值。路径得分为每条路径上节点贡献值的和,图中有{y1,y3}、{y1,y4}、{y2,y5}、{y2,y6}四条路径,对四条路径的得分做排序,选择最大的得分路径作为预测标签集合。图中四条路径对应的得分分别为1.025、0.950、0.625、0.725,则实例xe预测的标签集合为{y1,y3}。特别地,选择作为候选预测集合的路径需满足层次约束,父节点预测为正的路径才能作为有效路径进行后续的选择最优路径操作。
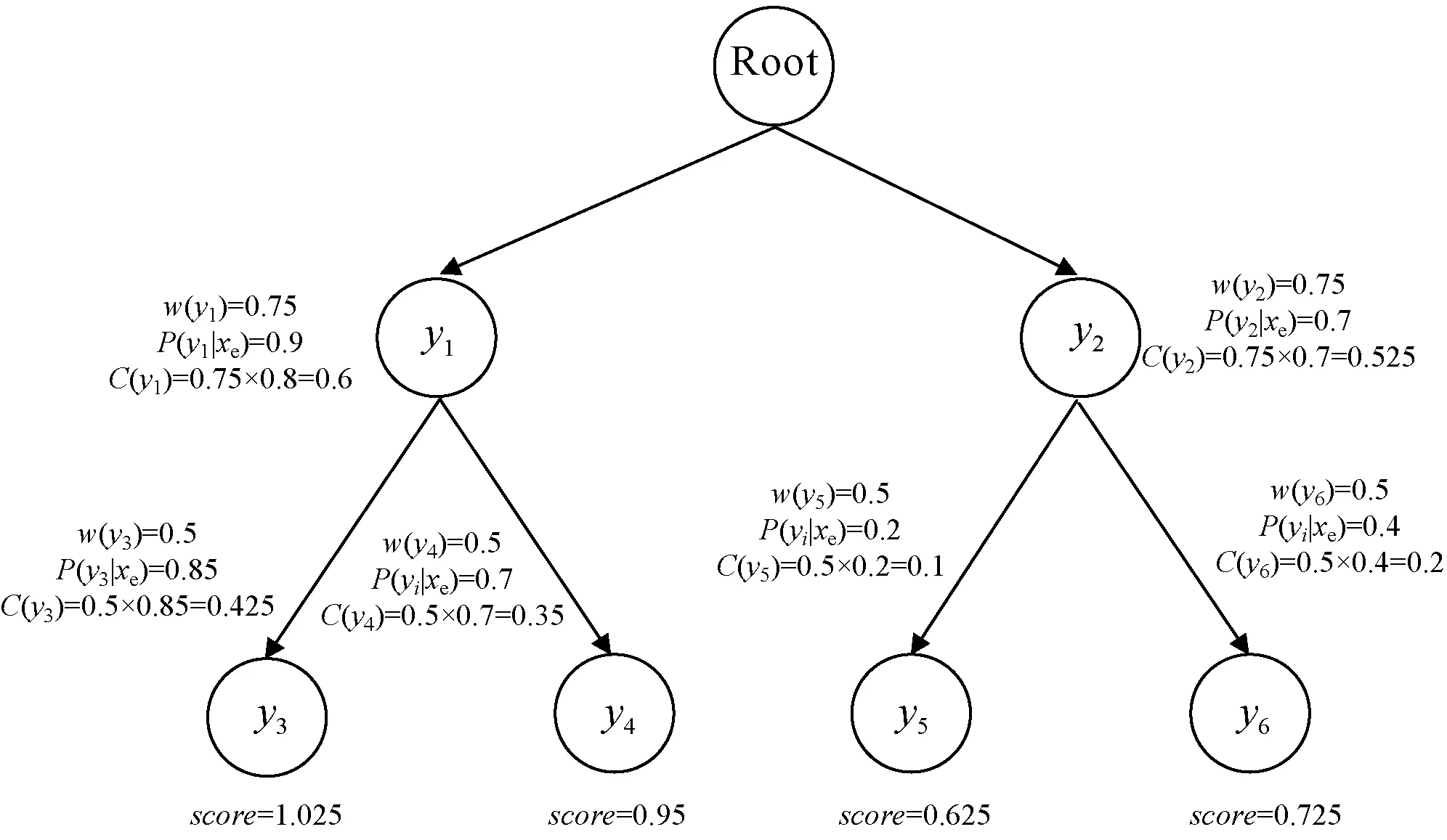
图5 路径得分计算示意图
2 实验与结果分析
2.1 实验描述
本文使用的语料来源于互联网中抓取的泛娱乐领域的“文化娱乐”公开资讯数据,数据标签由领域专家进行标注,该数据已经过多个领域专家审核,共43 852条。表1给出了各级别标签更详细的统计数据。

表1 数据统计表
表2中,|P|表示类别标签总数,PM表示每个样本实例中平均拥有的标签数量,D表示特征的维度,N表示样本的总数,H表示层次标签的深度。

表2 统计信息表
2.2 性能评估
本部分进行了5组实验,分类器分别采用分类器链(CC)、二元关联(BR)、MLKNN、SVM多标签分类,以及基于最优路径层次多标签分类器(本文方法)。评价指标采用多标签分类常用的汉明损失(Hamming Loss)、准确率(Accuracy)和宏平均Macro-F1值。对比实验结果如表3所示。

表3 实验结果对比表
其中汉明损失是常用的衡量多标签分类效果的评价指标。汉明损失计算数据中被误分类的标签个数,汉明损失的值越小,则说明模型的效果越好,当汉明损失的值为0时,则说明该分类方法完全拟合所有数据,其计算公式如式(3)所示。
(3)
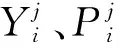
由图6可知,本文提出的基于最优路径的层次多标签分类技术相比二元关联、分类器链、SVMMLKNN算法,汉明损失更低,说明预测的标签集合中错误样本的比例相对更低。本文方法的准确率高于MLKNN的准确率、二元分类算法的准确率及分类器链算法的准确率。但是,准确率可能会受样本影响,因此不能仅凭该评价指标衡量分类器性能的好坏。通过对比Macro-F1值,可以看出本文方法的Macro-F1值高于其他算法的Macro-F1值。通过对比分类器链、二元分类、SVM多标签分类和MLKNN四种分类方法的实验结果可知,本文方法的分类器性能更为优越。
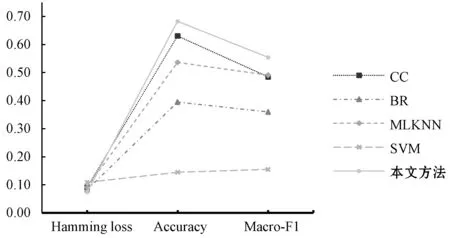
图6 实验结果对比
3 结 语
由于泛娱乐文本情报预测类别标签具备有向无环图结构特性,本文针对该特性提出一种基于最优路径层次多标签分类方法。实验证明,该方法相比未明确考虑标签相关性的分类器链、二元关联、MLKNN和SVM多标签分类等算法,效果更优。该研究为泛娱乐领域文本情报层次多标签分类提供了一种有效的实践。然而,该方法基分类器采用的SVM,未针对不同节点的数据进行优化,同时随着标签的增加,每个节点训练分类器的时间成本增加,因此,针对各节点个性化训练基分类器以及训练基分类器并行化将是下一步工作的重点和难题。
