基于GL2-DNN的面向语句覆盖的程序缺陷定位方法
2023-02-17刘振宇
彭 玲 刘振宇 彭 敏
(南华大学计算机学院 湖南 衡阳 421000)
0 引 言
随着互联网和计算机行业的飞速发展,程序的规模也随之扩大,愈加复杂,保证程序的安全性已经成为提高程序质量极其重要的因素之一。但是,在程序的开发与维护中常常会出现人为或逻辑的错误,从而导致出现程序失效的概率提高[1-2]。所以程序调试与整个程序开发周期并行进行,在程序开发和维护中极其重要,而程序缺陷定位又是其最重要和最耗时的工作之一。因此,准确定位缺陷位置,能有效地减少开发过程中的错误,提高程序的高可靠性和降低维护成本。
多年来,为了提高程序缺陷定位的效率,中外学者对自动化程序缺陷定位提出了多种方法,大致分为三类:基于切片、基于程序频谱和基于状态修改。基于程序切片(slicing-based)[3-5]缺陷定位方法:程序切片,即缩小被测程序范围,主要是构建一个被测程序内可能造成程序失效的语句的集合,尽可能缩小查找范围,提高调试效率。该类方法适用在规模较大的程序上,因为需要分析程序的依赖关系,所以过程复杂,对程序员的代码理解能力要求较高,且处理后的代码量一般还是很大,仍需进一步简化。基于程序频谱(spectrum-based)缺陷定位方法主要是在被测程序上执行其特定的测试用例集并统计失败测试用例和成功测试用例的覆盖信息[6],可以是程序中不同的元素的覆盖信息,例如可执行语句或程序块[7]、函数[8]和执行路径[9],然后根据预先定义的可疑度计算公式计算每条语句的可疑度,然后根据可疑度大小,由大到小寻找缺陷语句。该类方法相较于程序切片方法复杂度低,工作人员可根据排序后的结果,从可疑度最大的语句开始调试,调试效率提升。但是该方法没有考虑语句间的依赖关系,并且会受到偶然成功的测试用例的影响。基于程序状态(state-based)[10-11]缺陷定位方法首先对比成功测试用例和失败测试用例执行过程中的运行状态的差异,再按照不同规则对失败测试用例的运行状态进行修改,最后根据修改后得到的测试结果来定位缺陷语句。该方法复杂度较低,但是仅适用于很小范围的缺陷类型。
除上述三种方法外,近年来,国内外学者提出了将神经网络应用于程序测试的缺陷定位领域。Wong等[12]提出了一种基于RBF神经网络的程序错误定位方法。秦兴生等[13]提出了利用神经网络集成的程序故障预测方法。张柯等[14]提出了基于增强径向函数神经网络的程序错误定位方法。Zheng等[15]提出将深度神经网络(Deep Neural Network,DNN)应用于程序缺陷定位方面。一系列的研究成果表明基于机器学习和深度学习的程序缺陷定位模型相较于传统程序缺陷定位模型,定位缺陷的有效性有所提升,并降低了程序调试成本,但是神经网络中各种参数的设置会直接影响其定位效果,一般都由经验去人工选择参数,不仅费时费力,且效率低。
本文将遗传算法有效的全局随机搜索能力、L2正则化防止模型过拟合与深度神经网络学习复杂非线性能力结合起来,提出一种基于GL2-DNN模型的静态程序缺陷定位算法。建立GL2-DNN缺陷定位模型,使用遗传算法自动选择最优参数,将测试用例集运行时的语句覆盖信息作为该模型的训练数据集,构建虚拟测试集,输出语句的可疑度值,然后根据可疑度大小,由大到小排序确定定位,调试错误。与Ochiai、Jaccard、Tarantula、RBFN和BPN五种缺陷定位算法的定位效率进行比较,结果表明本文的方法更能有效定位程序缺陷。
1 遗传算法+L2正则项优化深度神经网络(GL2-DNN)
1.1 DNN的基本结构
神经网络技术起初被称为感知机(perceptron),拥有输入层、一个隐藏层和输出层。输入向量通过隐藏层达到输出层,在输出层得到结果。但单层感知机不具备学习复杂非线性关系的能力,直到二十世纪八十年代出现多层感知机(multilayer perceptron)才克服这个缺点。Hinton等[16]提出了深度神经网络算法(DNN),将神经网络隐藏层层数加到多层,神经网络真正意义上有了“深度”。神经网络基于单层感知机,而DNN具有更多的隐藏层数,在处理多维数据时,与单层感知机相比,具备学习复杂非线性关系的能力,进一步挖掘数据特征之间的联系以及各特征与结果之间的联系。


图1 DNN基本结构
1.2 GL2-DNN模型
本文将遗传算法有效的全局随机搜索能力[19]、L2正则化防止模型过拟合与深度神经网络学习复杂非线性能力结合起来,降低DNN中各参数对DNN模型性能的影响,提高模型性能,实现对模型空间的限制,从而提升模型的泛化能力,避免陷入局部最优和收敛速度慢。


图2 GL2-DNN模型训练流程
GL2-DNN模型训练流程:
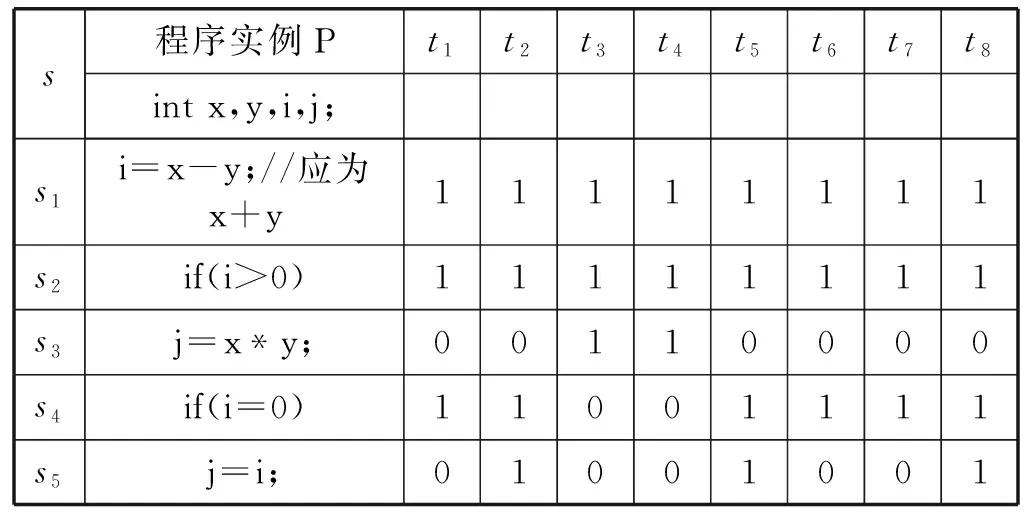
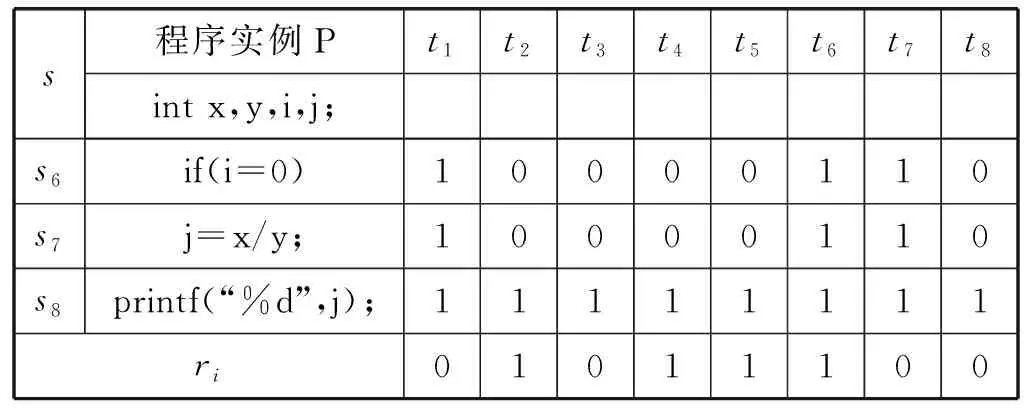
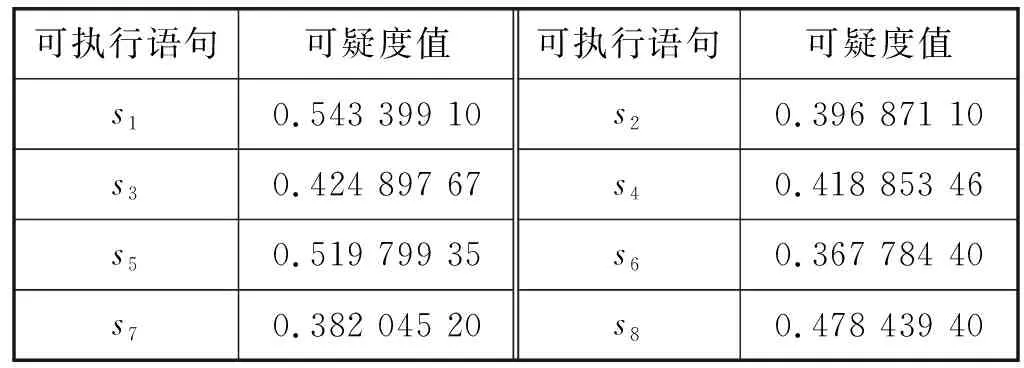
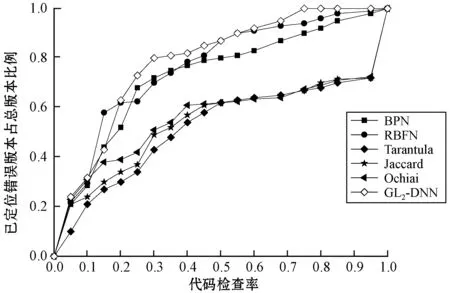
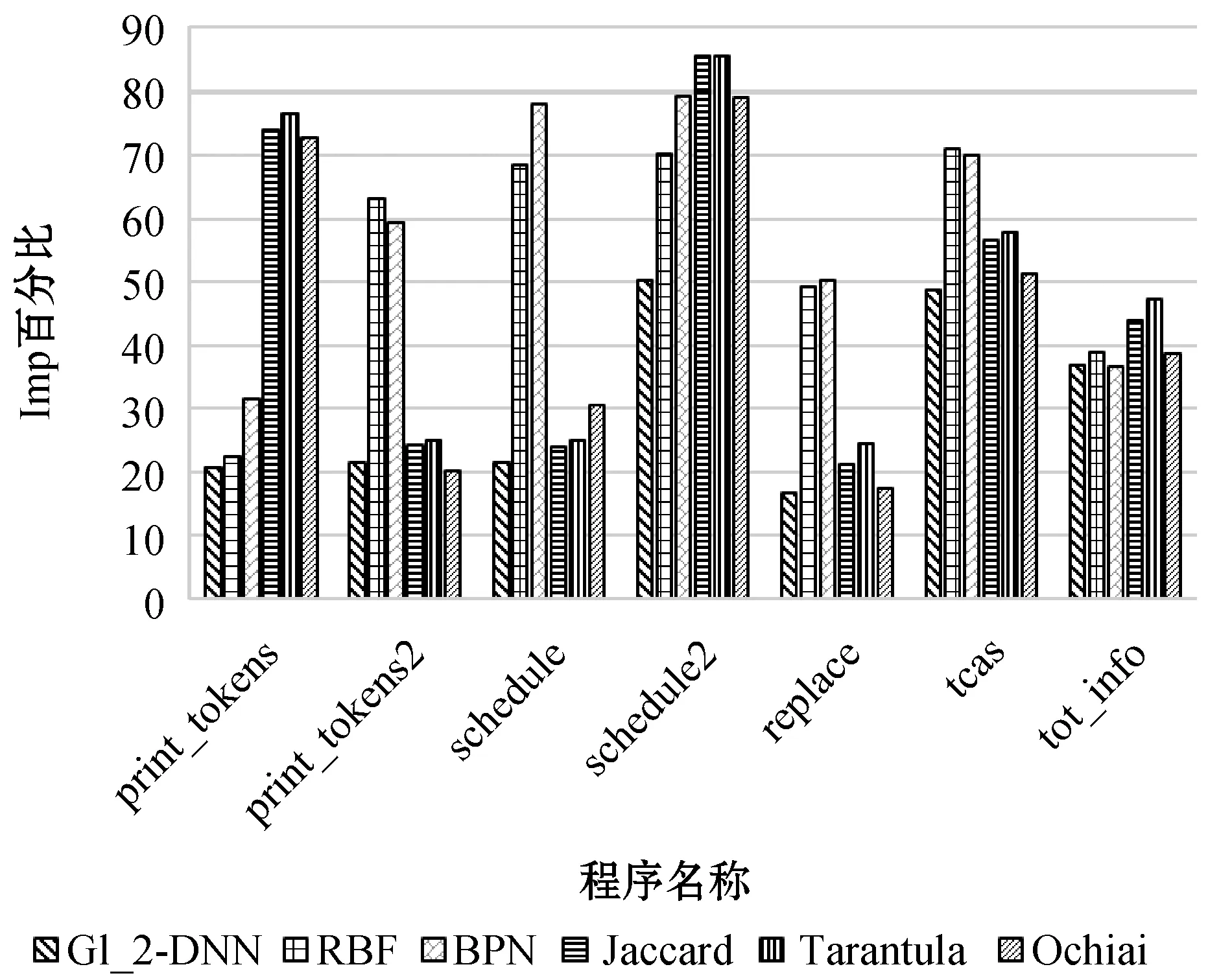
(1) 设置种群数目和优化变量:获得遗传初始种群N,即将DNN中的各隐藏层神经元数量nl(0 (2) 通过实数编码的方式给遗传算法初始种群进行编码,每个编码串即每个染色体包含了设定的所有优化目标,其中nl∈[1,300],η∈[0.000 01,0.05],epoch∈[1,100],λ∈[0.000 1,0.5]。 (1) (4) 由于tournament selection算法不需要对所有适应度值进行排序处理,对比轮盘赌法拥有更小的复杂度,易并行化处理,因此将其作为选择算子的选择策略,选择当前种族群中较好的个体作为父代,将染色体传给下一代。 (5) 使用洗牌交叉算法,在交叉之前,利用随机排序random.shuffle函数在父代中进行洗牌操作,若产生的随机数小于所给的交叉率大小,则进行交叉变换。 (6) 在变异算子中,若产生的随机数小于所给的变异率,则进行变异。各隐藏层神经元的个数nl(0 c.epoch=abs(c.epoch+random.randint(-10,10) (2) c.η=abs(c.η+random.uniform(-0.005,0.005))) (3) c.λ=abs(c.λ+random.uniform(-0.005,0.005))) (4) c.nl=abs(c.nl+random.randint(-20,20))) (5) (7) 将经过遗传算法筛选出来的最优个体作为DNN模型各隐藏层神经元数目nl(0 (6) (7) (10) 在交叉熵损失函数后加上L2正则项,抑制权重系数过大,其计算公式表示为: (8) (9) (12) 将更新后的权重作为下一轮训练的网络连接权重,返回第(8)步,直到达到理想状态或者达到设定的训练周期数。 假设程序P有m条可执行语句,sj为每条可执行语句的标号(j∈[1,m])。为P制定n组测试用例,组成测试用例集合T,每组测试用例记为ti,ri为程序P在第i组测试用例上运行后的状态值,若实际输出值与期望输出值不符,ri则为1,ti为失败测试用例,反之ri则为0,ti为成功测试用例。C为程序P在测试用集T上运行时的可执行语句覆盖信息。程序缺陷定位根据测试用例在程序上运行,收集其覆盖信息及测试用例状态,然后使用模型分析并进行缺陷定位。所以在程序缺陷定位方法中,一组测试用例应该含有输入、预期输出、语句覆盖信息及状态值。 人工智能(Artificial Intelligence)是当今时代最热门、最抢眼的技术词汇,已经激起了一场新的技术革新浪潮。将人工智能技术结合到酒店业,我们可以将酒店系统采集到客户的所有信息数据上传到云端,在云端大数据分析工具 (大数据分析技术可以快速对大量的数据进行相关性分析)的帮助下对采集的客人信息结合历史数据进行精准分析和画像[13]。 假设存在一个错误但能正常运行的程序P,该程序有8条可执行语句,其中S={s1,s2,s3,s4,s5,s6,s7,s8},s1为缺陷语句。针对程序P的测试用例集T={t1,t2,t3,t4,t5,t6,t7,t8},以及各组测试用例的语句覆盖信息和状态,如表1所示。 表1 程序实例P及其覆盖信息 续表1 如图3所示,基于GL2-DNN的缺陷定位算法流程如下: 图3 GL2-DNN缺陷定位算法流程 (1) 把源程序在测试用例集上运行,获取每个测试用例的语句覆盖信息及状态值,集合成信息表,作为GL2-DNN缺陷定位模型的训练数据集。例如,在表1中t1的语句覆盖信息为c11=(1,1,0,1,0,1,1,1),状态值r1=0。 (2) 建立GL2-DNN缺陷定位模型。模型隐藏层层数经实验对比后确定,输入层神经元的个数等于源程序的可执行语句数,将测试用例的语句覆盖信息Ci=(ci1,ci2,…,cim)作为模型输入,状态值ri当作对比标签,来计算权重误差。以表1为实例,有8组输入数据,每组输入数据中包含了8个特征值,即8个输入神经元,每组输入数据有其相应的对比标签,如第一组输入数据为c1=(1,1,0,1,0,1,1,1),其对比标签为r1=0。 (3) 训练GL2-DNN缺陷定位模型。通过迭代训练,直到达到迭代满足结束训练条件为止。GL2-DNN缺陷定位模型训练过程如图4所示。 图4 GL2-DNN缺陷定位模型训练 (4) 模型训练完成后,设计一组虚拟测试用例,虚拟测试用例个数与源程序的可执行语句数相等,且每个虚拟测试用例依次仅覆盖一条语句,即为m×m的单位矩阵[20],如式(10)所示。 (10) (5) 将虚拟测试用例数据作为已训练好的模型的输入,依次输出每个虚拟测试用例的预测结果fi(i∈[1,m])。将预测结果fi视为对应可执行语句的出错可疑度,如f1为源程序中s1的出错可疑度值。表1程序实例P的模型输出结果如表2所示。 表2 程序实例P模型输出结果 (6) 将预测结果f1,f2,…,fm进行降序排列,测试人员从高往低进行缺陷语句定位,若可疑度越高,则该语句越优先被检查。例如根据表2,将程序实例P的可执行语句进行排序,则为s1s5s8s3s4s2s7s6,缺陷语句s1可疑度值最大,则测试人员可以优先检测s1,进行调试修改,从而提高定位效率,降低时间成本。 使用测试数据集Siemens Suite[21]作为本文实验的研究对象,该数据集可从Software-artifact Infrastructure Repository(SIR)获得。Siemens Suite是由西门子公司发布并常用于程序缺陷定位领域研究的测试套件[22],其中包含了七个中小型程序,每个子程序中包含了其正确版本、相应的若干错误版本及若干的测试用例,如表3所示。 表3 Siemens Suite 大多数的错误版本的错误存在于单行代码中,少数错误版本中的错误会跨越多行,如tcas程序中的错误版本v31、v32和v33。Siemens Suite数据集中共有132个错误版本,在本文实验中只应用了120个错误版本,排除掉了12个错误版本:(1) 没有失败测试用例:replace程序v32、schedule2程序v9;(2) 头文件包含错误,主程序文件不包含:print_tokens程序v4、v6,tcas程序的v13、v14、v36、v38,tot_info程序v6、v10、v19、v21。 实验主要包括四个阶段:第一个阶段是数据预处理,主要是信息采集、程序特征提取、正确版本与错误版本对比获取状态值,整合数据;第二个阶段将第一阶段整合的数据作为GL2-DNN模型的输入与对比标签,训练模型,经过多次实验对比,GL2-DNN模型的隐藏层数为5时,定位效果最好;第三阶段将虚拟测试用例集作为已确定最佳层数并已训练好的GL2-DNN模型的输入,进行语句可疑度预测,输出语句可疑度值;第四阶段是根据训练好的GL2-DNN模型输出的预测值对可疑语句进行降序排列、定位缺陷语句并计算定位效率等。为了验证GL2-DNN程序缺陷定位模型的良好性能,选取了文献[14,23]中Ochiai、Jaccard、Tarantula、RBFN、BPN等程序缺陷定位方法与之进行定位效率比较。 本文采用与文献[23]类似的评估指标,即以代码检查率ρ作为程序缺陷定位方法有效性的评估指标,公式为: (11) 式中:ρ表示在找到缺陷语句之前所需要查找语句的比例,ρ越小,代表定位效率越高;F表示源程序中可执行语句总数;f表示找到程序缺陷需要检查的语句数目,即缺陷语句的可疑度排名。当ρ相同,即在查找相同语句数量的情况下,能定位的错误版本数越多,则代表程序缺陷定位算法越有效,定位效率越高。图5比较了GL2-DNN、Ochiai、Jaccard、Tarantula、RBFN和BPN六种缺陷定位算法在同一代码检查率的情况下,已定位的错误版本比例,x轴表示代码检查率,y轴表示已定位了的错误版本数占总错误版本数的比例。 图5 六种程序缺陷定位算法代码检查率比较 可以看出,代码检查率在[0,0.1]区间上时,GL2-DNN的定位错误版本比例为0.24,略高于Ochiai、Jaccard、RBFN和BPN,但在(0.1,0.2)区间上时,RBFN的定位错误版本比例高于GL2-DNN,如在代码检查率为0.15时,RBFN的定位错误版本比例为0.58,GL2-DNN为0.43。除此之后,GL2-DNN的定位错误版本比例均高于Ochiai、Jaccard、Tarantula、RBFN和BPN,且在代码检查率为0.75时,已定位错误版本比例接近100%,代表使用GL2-DNN算法定位缺陷时,只需查找75%的语句,便可找出所有错误版本的缺陷语句,而Ochiai、Jaccard、Tarantula、RBFN和BPN则需要查找90%及以上。由此可看出在整体区间上的实验结果GL2-DNN算法定位程序缺陷比其他算法更有效。 代码检查率是从整体去比较算法的定位效率,为了进一步验证GL2-DNN缺陷定位算法的有效性,还需进一步进行细节比较,则引入标准Imp百分比[14],表示在已定位到单个程序所有错误版本的错误情况下,已查找的可执行语句总和占所有错误版本可执行语句总和的百分比,也可理解为在单个程序集上的平均代码检查率的平均值。Imp百分比越小,则定位效率越高,时间成本越低。在测试数据集Siemens Suite上分别使用六种程序缺陷定位算法的Imp百分比如图6所示,可看出,在print_tokens2程序中,定位效率最好的是Ochiai算法,Imp百分比为20.3%,略高于GL2-DNN算法。但在print_tokens、schedule、schedule2、replace、tcas、tot_info程序中,GL2-DNN算法的Imp百分比均低于其他六种算法,尤其在schedule2程序中,GL2-DNN算法定位效率表现最好,Imp百分比远远低于其他六种算法,其平均差为29.48%。因此,从图6整体可看出,在单个子程序集中,GL2-DNN缺陷定位算法虽然在单个程序中的缺陷定位效率不是最优,但是在多数子程序中表现最优。 图6 六种程序缺陷定位算法Imp值比较 经以上实验对比结果可知,GL2-DNN缺陷定位算法可以有效地减少代码检查率,便能定位到缺陷,提高了定位精确度,且比其他算法更稳定,没有出现较大极差。 本文将遗传算法、L2正则化与深度神经网络相结合,提出一种基于GL2-DNN的静态程序缺陷定位算法,相较于现有的基于神经网络程序缺陷定位算法来说,可以自主选择最优参数,提高定位准确度,降低时间成本。虽然对于复杂程序问题而言,其时间复杂度上升,但提高了精确度,且该模型对特征工程要求相对较低,优化过程独立于预测过程,一旦获取最优超参数,便可缩短模型的训练和预测时间。 实验表明,该算法与Ochiai、Jaccard、Tarantula、RBFN和BPN五种缺陷定位算法相比较,定位效率与准确率均有所提升,且代码检查率降低了约15百分点。 虽然该算法的实验结果良好,但仍然存在不足:(1) 由于本文着重考虑消除相似测试用例对于定位结果的影响,所以对于程序语句和变量的依赖性对其定位结果产生的影响考虑不足;(2) 数据集Siemens Suite大多为单一缺陷,所以本文在多错误互相之间的关系上考虑不足,现实中的程序缺陷并不单一且关系复杂;(3) 未考虑测试用例的优化选取,未验证测试用例的选取对定位效率的影响;(4) 以测试数据集Siemens Suite实验样本,未在其他平台进行实验,未验证其跨平台性。 未来将针对该算法的不足进行进一步研究。主要有几个方面:将研究焦点定位于多缺陷定位,满足多故障程序定位的需求;进行测试用例优化,以提高缺陷定位效率;选择更大的程序集进行实验,扩展缺陷种类。

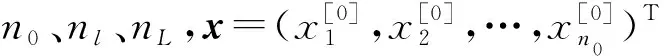


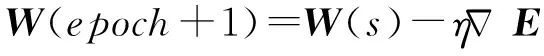
2 基于GL2-DNN的缺陷定位算法
2.1 程序缺陷定位问题描述
2.2 基于GL2-DNN的缺陷定位算法流程



3 实验与结果分析

4 结 语
