基于改进YOLO-v3 的无人机遥感图像农村地物分类
2023-02-10雷荣智杨维芳苏小宁
雷荣智,杨维芳,苏小宁
(1.兰州交通大学 测绘与地理信息学院,甘肃 兰州 730070;2.甘肃省地理国情监测工程实验室,甘肃兰州 730070;3.地理国情监测技术应用国家地方联合工程研究中心,甘肃兰州 730070)
近年来,随着“建设社会主义新农村”和“乡村振兴”等惠农惠民政策的实施[1],农村土地利用和规划工作也在紧锣密鼓地进行中,地物识别和分类在土地利用和规划中起着至关重要的作用,是观察农村土地变化和经济发展的重要手段[2]。
基于此,文中提出一种基于改进YOLO-v3 的无人机遥感图像建筑物和农田目标检测算法,该算法引入SPP(Spatial Pyramid Pooling)层和PAN 结构对YOLO-v3 网络进行改进。添加SPP 层,使得网络能够在多种尺度学习图像的特征,同时在YOLO-v3 原生FPN(Feature Pyramid Networks)基础上添加PAN结构,增加语义特征,提高识别精度。实验结果表明,与原生的YOLO-v3 算法相比,改进后的YOLO-v3 网络对建筑物和农田的识别更快速、更准确,具有一定的优势。
1 算法原理
1.1 算法简介
YOLO 算法是使用深度神经网络对对象的位置进行检测和分类的算法,其优点有检测速度足够快,而且相较其他算法,准确率也较高[3]。YOLO 算法的工作模式是对目标对象的边界框直接预测,将目标区域预测和目标类别预测两个步骤合二为一[4]。
在以往的检测算法中,检测模型的核心原理都是使用分类器对目标图像的不同切片进行评判。YOLO 算法则将对象检测定义为一个回归问题,直接将原始图像分割成不重合的网格[5],然后对于每个网格,网络预测边界框及其与每个类别相对应的概率,最后对于每个类的对象,应用非最大抑制(Non Max Suppression)方法过滤出置信度小于阈值的边界框。基于上述分析,可以认为特征图的每个元素也是对应原始图像的一个小方块,利用每个元素可以预测中心点在该小方格内的目标[6],这就是YOLO算法的朴素思想。YOLO-v3 算法作为YOLO 算法中经典的一代,在以往的结构上做出了改进,增加了多尺度检测和更深的网络结构Darknet53,上述的改进是YOLO 算法最主要的改进,其他的变动都是对网络的细节进行微调。
1.2 算法原理
YOLO 的主要思想是利用单独的卷积神经网络(Convolutional Neural Networks,CNN)进行预测,YOLO 网络的工作原理是使输入的图像经过神经网络的重重变换后变为一个输出的张量[7]。
下面以最初的YOLO-v1 算法为例介绍YOLO 系列算法。YOLO-v1 算法的基础网络结构来源于卷积神经网络,其主体结构由24 个卷积层和两个全连接层构成,卷积层负责提取图像特征,全连接层负责每个类别位置的检测[8],提供概率信息,最后输出层使用线性函数作为激活函数,其他层的激活函数都是Leaky ReLU。
YOLO 算法的优点在于速度非常快,将目标检测的流程进行简化,化为回归问题。测试时将新的图像输入至神经网络中进行预测。其次,YOLO 在进行预测时,会对图像进行全面推理[9]。在目标检测的背景误检方面,YOLO 的误检数量比Faster R-CNN 少了一半。由于YOLO 具有高度泛化能力,因此在应用于新领域或碰到意外输入时,不易出现故障[10]。文中使用目前较成熟的YOLO-v3 算法作为基础网络,YOLO-v3 由三个主体结构组成,主要包括输入层、基础网络和三个网络分支,具体网络结构如图1 所示。

图1 YOLO-v3网络结构
2 实验和分析
2.1 研究区与数据集
以江西省丰城市某村的无人机遥感图像为数据源,该图像采用多旋翼无人机低空倾斜摄影实时航拍得到。无人机搭载索尼IL CE-6000 数码相机进行图像获取,空间分辨率可达0.02 m,传感器尺寸为23.5 mm,镜头焦距为35.3 mm、25 mm,获取时间为2019 年3 月。对获取的图像进行图像畸变校正,筛选校正过的图像,然后对所筛选的图像进行裁剪和压缩,最后对图像进行增光处理,共获得740 幅图像。随机抽取540 幅图像作为训练样本,200 幅作为测试样本,训练样本与测试样本不重复。将540 幅训练样本图像在labelImg 进行数据集的制作,数据集命名为Air,数据集制作过程如图2 所示。

图2 Air1数据集制作过程
文中所采用的无人机遥感图像的空间分辨率较高,不但可以使地物信息更加丰富,还可以使地物信息的几何结构和纹理信息显示更加清晰。研究区内的农田多为水稻田,呈不规则形状分布,建筑物是二层或三层独栋建筑,在无人机遥感图像中纹理清晰,两者在颜色和形状上有明显差别。
2.2 环境配置
实验环境基于Linux Ubuntu 18.04 操作系统,采用Pytorch-1.7 框架,以CPU intel i7-10700K 和GPU RTX3090处理器作为硬件支持,运行环境是Anaconda Python。
2.3 网络改进
为了提高模型的检测和识别能力,文中在YOLO-v3模型中引入SPP结构和PAN 结构对YOLO-v3 模型进行改进,融入SPP 结构使模型可以接收任意尺寸的图像数据,从多种尺度上对图像特征进行池化,解决了输入图像数据尺寸需固定的难题,提高了模型对多尺寸目标的适应能力;同时,利用PAN 结构增强了语义特征信息,形成“FPN+PAN”模块,传递定位信息,提高模型的识别精度。
2.3.1 SPP
CNN 的结构由卷积层、池化层、全连接层、激活层等部分组成,其中卷积层对于输入数据的大小并没有要求,唯一对数据大小有要求的是全连接层。在以往的卷积神经网络中,往往要求数据的大小是固定的,比如著名的VGG-16 要求输入数据大小为224×224。
数据以固定的大小输入时,往往存在诸多问题。首先,在所制作的Air1 数据集中,所得到的图像数据的尺寸并不是固定的。在实地踏勘研究区域发现,房屋和田地面积大小不一,呈不规则分布。因此,在无人机图像中的房屋和田地中,图像高宽比并不是固定的,所得到的数据集也存在数据大小不同的情况,如图3 所示,对房屋和田地框出的地物类别高宽比不同;其次,由于数据大小不一,如果不能满足模型的输入需求,图像将不会在模型中进行运算。为了满足模型的输入需求,必须对图像进行裁剪或变形拉伸,改变特征的尺寸,从而使图像产生失真,这不但不利于模型的识别,直接降低模型的检测精度,而且模型的运行效率也大打折扣。

图3 Air1数据集中的田地与房屋
文中在网络结构中引入SPP 结构,解决了CNN输入图像大小必须固定的问题,使得输入图像的高宽比和大小可以为任意值,同时SPP 从多种尺度上对图像特征进行池化,解决了CNN 对图像特征重复提取的问题,提高了选框的速度,在一定程度上提高了模型对多尺寸目标的适应能力,节省了计算成本,提高了模型的运行效率。
图4 所示为SPP 结构示意图。SPP 结构被添加在卷积神经网络的卷积层和全连接层之间,最上面为卷积层,最下面为全连接层,通过SPP 结构接收不同尺寸的数据图像。

图4 SPP结构示意图
除此之外,对于池化层来说,池化核和步长的大小对网络性能是有影响的,且不同的任务通常也需要不同参数的池化。在网络中,SPP 结构可以融合多种池化参数,通过这种方式,可以提高网络的适应能力,因此可以在一定程度上提高模型的性能。
该实验中,在YOLO-v3 的Res4 结构之后添加SPP 结构,使得网络能够在多种尺度学习图像的特征,适应了Air 数据集中所呈现出的不同图像尺寸。
2.3.2 PAN结构
为了提高模型的性能和特征识别能力,在原始的YOLO-v3 网络的FPN 层之后添加一个向上的金字塔结构,将低层的强定位信息传递上去。在YOLO-v3 原生FPN 的基础上添加PAN 结构形成双塔结构,如图5 所示。

图5 PAN结构示意图
FPN 作为通用的特征提取器,在目标检测和分类任务上给模型带来显著的性能提升。其主要原理是通过上采样和对低层特征做融合得到预测的特征图,采取自顶向底的模式,将高层的强语义特征传递下来,将高级特征与低级特征进行融合,增加了语义特征,但是对定位信息没有传递,而定位信息对于特征识别也具有一定的影响。
2.3.3 实验结果
为了验证所提出的改进YOLO-v3 算法的有效性,将其与YOLO-v3算法进行对比,改进的YOLO-v3算法运行实验结果可视化如图6 所示。
文中采用的评价指标为AP、Recall 和Precision。AP 表示平均精度,使用积分的方式计算Precision-Recall 曲线与坐标轴围成图形的面积,AP 值越大,说明分类模型的检测精度越高。mAP(mean Average Precision)为所有AP 值的平均值。
Recall 表示召回率,主要针对的是某一类样本的预测信息,表示原始样本中预测正确的样本正确率[11]。计算公式如下:

式中,TP 是实际为正样本预测为正样本的数量,FN 是实际为正样本预测为负样本的数量。Recall越高,说明模型对正样本的识别能力越强[12]。
Precision 表示准确率,主要针对的是预测结果,表示原始样本中预测为正确样本中真正正样本的比率,计算公式如下:

式中,FP 是实际为负样本预测为正样本的数量。Precision 越高,说明模型对负样本的区分能力越强[13]。
F1-score 是Recall 和Precision的综合,F1-score越高,说明分类模型越稳健[14],其计算公式如下:
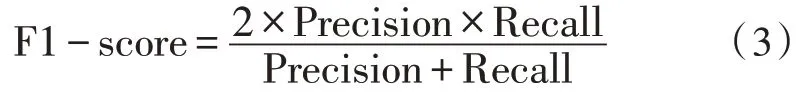
为了验证文中算法的有效性,将Air 数据集分别在YOLO-v3 模型和改进的YOLO-v3 模型中进行对比实验,其中YOLO-v3 是未进行改进的模型,骨干网络采用Darknet-53[15]。在改进的YOLO-v3 模型中添加SPP 层和PAN 结构,目的是提高目标检测的精度和提高检测速度。
Air 数据集在YOLO-v3 模型的各种评价指标效果如图7 所示,左边部分是农田在YOLO-v3 的测试效果,在图中以ground 命名,右边部分是房屋在YOLO-v3 的测试效果,在图中以house 命名。该实验取阈值为0.5,阈值的取值范围在[0,1]之间,该值的设定没有绝对的标准,需要根据数据集和模型的实际情况进行调整。实验中经过调整发现,当阈值取0.5 时,模型的运行效果最佳,每个指标都趋于平衡,不会出现非常优秀或者非常差的情形。因此,选择该实验的阈值为0.5。模型在运行中,使用0.5 阈值区分正负样本,小于0.5 为负样本,反之为正样本。从图7 可以看出,Air 数据集中的房屋在YOLO-v3 模型的识别效果较为突出,农田的分类效果较好。

图7 YOLO-v3在Air数据集上的AP、Recall、Precision
Air 数据集在改进YOLO-v3 模型的各种评价指标效果如图8 所示,左边部分是农田在YOLO-v3改进版的测试效果,右边部分是房屋在改进的YOLO-v3 的测试效果,同样以ground 和house 进行命名,阈值同样选取0.5。从图8 可以看出,改进的YOLO-v3 模型对房屋的识别效果比对农田的识别效果好。
由图7 和图8 可知,从AP、Recall 和Precision 三个指标来看,在农田的识别方面,改进的YOLO-v3模型的预测效果略高于YOLO-v3 模型,其中AP 值和Recall略微提升,在平均精度方面稍逊色于YOLO-v3模型。而在房屋的识别方面,改进的YOLO-v3 模型的预测效果有显著提升,AP 值提升3.85%,说明模型对房屋的识别效果更高。在房屋类别的识别准确率方面也得到了提升,在召回率方面,改进的YOLOv3 模型对房屋的识别效果是最优秀的。

图8 YOLO-v3改进版在Air数据集上的AP、Recall、Precision
在图9 和表1 对农田和房屋两个类别的AP 值和mAP 进行了再次说明和计算。根据计算,YOLO-v3模型对于农田和房屋两个类别的mAP 值为0.706 7,改进的YOLO-v3 模型的mAP 值为0.726 0,相比较,后者的检测分类效果优于前者。在农田的检测分类方面,两个模型的AP 值相差非常小,而在房屋的检测分类方面,改进的YOLO-v3 模型的AP 值高于YOLO-v3 模型。mAP 值是对两个类别AP 值进行平均得到的评测值,通过对比发现,改进的模型mAP值更高,比YOLO-v3 模型高0.02,说明经过添加SPP层和PAN 结构,模型能够在多种尺度上学习图像的特征,并且融合了低级特征和高级特征的信息。同时,从精度和召回率两个指标来看,改进的YOLO-v3模型在房屋的识别上优于YOLO-v3模型。总的来说,在房屋和农田两种地物的识别上,改进的YOLO-v3模型均优于YOLO-v3 模型。
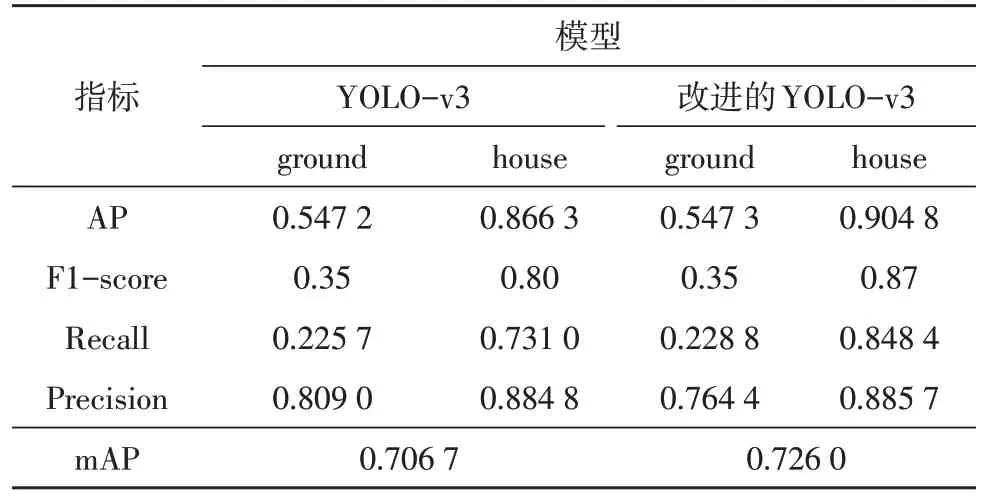
表1 两个模型的训练结果比较

图9 YOLO-v3和改进的YOLO-v3模型的AP和mAP
3 结论
文中针对模型精度高、性能更优和检测速度快等需求,提出基于改进的YOLO-v3 模型,针对实际需求和数据集的需要做出改进,即添加SPP 层和PAN 结构,通过SPP 层解决数据集存在的输入图像尺寸必须固定的问题,从多种尺度上对图像特征进行池化,提高了模型对多尺寸目标的适应能力;PAN结构可以自底向上传递强定位特征,结合FPN 层自顶向下传递强语义特征,形成“双塔结构”,从主干层对检测层进行参数聚合,通过PAN 结构增强多个尺度的定位能力,提升模型的分类效果。改进的YOLO-v3 模型的提出,针对Air 数据集的农田和房屋,基本满足了两种地物分类检测的准确性和实时性需求,对农村地物分类和新农村的建设起到重要的作用。在之后的工作中,将针对主干网络进一步升级和优化,旨在于提高检测精度、速度和模型泛化能力。
