基于概率图模型的多机器人自组织协同围捕方法
2023-02-09黄依新相晓嘉孙懿豪
黄依新 ,相晓嘉 ,周 晗 ,闫 超 ,常 远 ,孙懿豪
(1.国防科技大学智能科学学院,湖南长沙 410073;2.军事科学院,北京 100091)
1 引言
近年来,受生物群体智能的启发,多机器人系统受到了越来越广泛的关注[1].典型的多机器人任务场景已经从跟踪、搜索扩展到编队控制、协同围捕等[2-3].其中,多机器人协同围捕在民用和军事领域具有重要的实用价值,已经逐渐成为多机器人系统领域的研究热点之一[4-5].
多机器人协同围捕的任务是通过多个机器人的协同行为搜索并捕获非合作的围捕对象[6].其中最为关键的问题是在保证机器人安全的前提下,考虑目标运动状态、环境障碍信息等不确定因素的影响,机器人之间如何高效协作,搜索并捕获围捕对象.
近年来,许多学者针对多机器人协同围捕问题开展了广泛的研究.Zhang等[7]提出了一种结合强化学习和人工势场方法的混合协同围捕算法来实现多机器人自组织协同围捕.该算法将人工势场方法作为预定义的规则集成到强化学习过程中,采用深度强化学习来学习自适应动态环境的协同围捕策略,并在现实场景下的实体机器人上验证了该算法的可行性和有效性.然而,其所提出的强化学习方法需要进行大量的训练,且对机器人的感知范围没有限制,不适用于感知受限条件下的围捕任务.黄天云等[8]面对机器人群体协同围捕问题,提出了一种基于松散偏好规则的自组织协同方法.该方法将协同围捕行为分解为目标约束方向上的聚集行为与垂直目标方向上的个体间分散行为,通过设置机器人的松散偏好规则使其形成理想队形.但其所提方法没有考虑个体避障的情况,无法有效应对环境障碍威胁.罗家祥等[9]针对感知受限的多机器人在未知环境下的协同围捕问题,提出了一种结合简化虚拟速度和航向避障的多机器人自主围捕算法,实现了高效的围捕和避障.然而,该算法对机器人与目标的初始位置有严格要求,不适用于目标位置不确定的场景.张红强等[10-11]针对未知动态环境下的多机器人围捕问题提出了一种基于简化虚拟受力模型的自组织围捕方法,使得多机器人系统能够在躲避障碍的前提下保持良好的围捕队形.然而,该算法需要围捕机器人始终可以获得目标信号,该假设在现实中难以实现.
针对现有方法存在的任务可扩展性差、环境适应性弱等问题,本文使用概率图模型(probabilistic graphical model)技术实现多机器人在不确定因素影响下的自组织协同高效围捕.概率图模型[12]可通过融合多源信息模拟人类对不确定知识的因果推理过程,已广泛应用于自主决策[13]、无人驾驶[14]和故障诊断[15-16]等领域.概率图模型以图结构的方式对实际问题进行建模,将环境中的不确定因素归结为模型中某些变量的概率分布.可通过修改概率图模型的结构来实现对不同任务的适用与不同环境的适应.
因此,本文针对多机器人系统在复杂环境下协同高效围捕非合作动态目标问题,设计一种基于概率图模型的多机器人自组织协同围捕方法.主要贡献如下:
1)以概率图模型理论为基础,提出了一种自组织协同围捕方法,实现了多机器人系统在感知能力受限、环境结构未知、目标状态不确定的场景下的高效协同围捕,具有较好的环境适应性.
2)设计了可扩展的协同围捕“感知-决策”概率图模型,能够根据任务或者环境的不同,在不改变其他参数的情况下,只增减模型的部分节点即可完成模型的扩展,具备任务可扩展能力.
3)本文设计的算法是自组织的,具备规模可扩展以及抗风险能力,机器人数量规模的变化不受算法层面的限制,且能够保证在部分个体故障的情况下,其余个体仍能够继续执行任务.
2 系统建模与任务描述
2.1 运动学模型
考虑由N个围捕机器人,1个被围捕的非合作运动目标以及M个障碍物所组成的系统.定义R={Ri|i=1,2,···,N}为N个围捕机器人的集合,其中下标表示机器人的编号.各机器人位置的集合为P={pi ∈R2|i=1,2,···,N},围捕机器人的感知范围受限,记围捕机器人的感知半径为Dr.
定义1围捕机器人的运动学模型为
式中:pi(t)=[xi(t)yi(t)]T为机器人Ri在t时刻的位置,vi(t)为机器人Ri在t时刻的速率,φi(t)表示机器人Ri在t时刻的运动方位角,Δt为单位时间.根据实际情况,围捕机器人运动模型的速率应有上限,则有vi(t)≤表示围捕机器人的最大速率.
假设1围捕机器人个体具有以下能力[9]:
1)机器人Ri的感知范围为以自身位置pi为圆心,以Dr为半径的区域;
2)机器人能够感知并识别感知范围内的目标、同伴以及障碍,获取其位置信息;
3)机器人个体之间可使用通信手段共享感知信息.
考虑到被围捕目标一般具有环境感知与危险躲避的能力[17],作出如下假设:
假设2被围捕目标Re具有以下能力:
1)被围捕目标Re的感知范围为以自身位置pe为圆心,以De为半径的区域;
2)Re能够感知并识别自身感知范围内的所有威胁(包括障碍与围捕机器人),获取其位置信息;
3)Re的行为是理性的,在遇到危险时总是会采取规避行为.
2.2 目标逃逸策略
目标可根据其所感知的环境信息做出相应的动作.结合目标所处的不同条件,设计被围捕目标的运动状态为漫步、避险与瘫痪3种[9].漫步状态: 目标Re未感知到任何威胁,将进行随机游走;避险状态:Re感知自身受到威胁,将进行威胁躲避;瘫痪状态: 目标受到围捕机器人攻击导致瘫痪,失去移动能力.
定义2目标的运动控制为
其中:
表示进入目标感知范围内的威胁物位置的集合;O=为M个障碍物位置的集合;
为进入致目标瘫痪范围内的机器人位置的集合;Db为捕获半径,表示机器人可攻击致目标瘫痪的距离.
目标在漫步状态下的速率记为vw,φw表示目标在漫步状态下的运动方位角.漫步状态表明当前目标的感知范围内不存在障碍或围捕机器人,即F=∅,在目标感知中自身此时没有危险,设计目标在漫步状态下的运动速率vw和方位角φw服从均匀分布,即
目标在避险状态下的运动方位角记为φΣ,目的是尽可能逃离包围圈.参考人工势场法[18]的思想,设计目标的逃逸策略为以最大速率朝远离威胁的方向逃离,其逃逸方向φΣ构拟为
2.3 任务描述
本文考虑的围捕任务指的是在一个存在M个障碍的有界场地中,N个机器人在躲避障碍的同时搜索并围捕一个非合作的运动目标.若某一机器人与目标之间的距离小于捕获半径Db,则目标将被该机器人所捕获.围捕机器人通过协同合作,尽可能搜索并靠近目标,最终使得至少1个机器人个体进入以目标为圆心,以给定长度Db为半径的区域内,使得目标被机器人个体捕获,从而完成围捕任务(如图1所示).
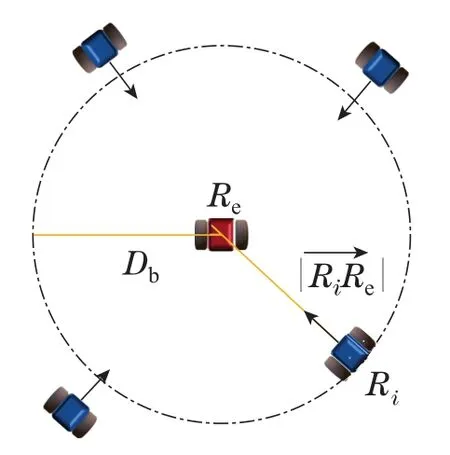
图1 期望围捕效果示意Fig.1 Expected capture results
机器人个体到被围捕目标位置的偏差距离即Ri与Re的欧式距离可以记为围捕任务的数学描述如下:
定义3给定第2.1节和第2.2节中的个体运动学模型与目标逃逸策略,设计控制律Vi和φi,使得∃Ri ∈R,有成立.
3 基于概率图模型的自组织协同围捕方法
为解决在感知能力受限、环境结构未知、目标状态不确定的场景下,机器人之间如何高效搜索并捕获围捕对象的问题,本文提出基于概率图模型的自组织协同围捕方法.首先,构建可扩展的协同围捕“感知-决策”概率图模型结构,并为模型中各节点状态设计概率分布参数估计方法.而后,为提高围捕效率,将围捕任务阶段化,设计狼群狩猎行为启发的围捕策略.最后,基于该模型根据机器人的感知信息进行动作决策,得到机器人个体的运动方位角φi及其运动速率vi.
3.1 概率图模型基础
概率图模型的基本组成[19]包含一个图模型结构G以及其所对应的条件概率θ,可表示为
其中:U={Ui|i=1,2,···,n}为概率图结构中的节点变量;Lij表示变量间的因果关系,由父节点Ui指向子节点Uj;Paj表示节点Uj的父节点集.θ={P(Uk|Pak),Uk ∈U}表示父节点对子节点的影响程度.
给出一个定义在U上的概率图模型,根据概率图模型结构中的条件独立性假设和链式法则,其联合概率分布可以表示为各个节点条件概率的乘积[19],即
模型的概率推断是指在给定概率图模型结构G和条件概率θ的情况下,计算某个变量状态取值的最大概率.本文主要基于概率图模型的最大后验假设问题进行概率推断,决策出围捕机器人应采取的动作.最大后验假设问题是指假设部分子节点状态已知,将已知节点状态作为推断证据,修正父节点概率分布,求父节点中概率最大的对应状态.
3.2 模型结构设计
针对不确定环境下的多机器人自组织协同围捕任务,本文设计了可扩展的“感知-决策”概率图模型结构G(如图2所示).模型包含2个节点层,分别为决策层与感知层.决策层包含一个决策节点,用于动作的决策;感知层由n个节点组成,用于表征机器人所感知环境中的不确定知识.模型中各节点的有向连接关系为
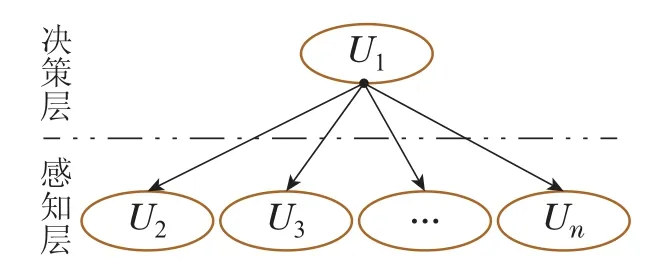
图2 “感知-决策”概率图模型Fig.2 Perception-decision probabilistic graphical model
其中:Lij的取值表示节点之间是否存在有向连接,若Lij的取值为1,则表示节点Ui和节点Uj之间存在由Ui指向Uj的有向连接,即节点Ui是Uj的父节点;否则表示节点之间不存在有向连接,即不存在直接因果关联.图2中节点的含义以及状态取值可根据不同任务需求进行具体设计.
注1在实际应用中,面对复杂多变的任务场景,所提出的“感知-决策”模型可通过模块化的节点设计进行模型修改,达到灵活适应不同任务场景的目的,而无需重新设计整个模型.这是由于所设计的模型结构特性使得感知层节点具有可扩展性.具体而言,所设计概率图模型的特殊结构使感知层节点间具备条件独立性,即部分感知层节点的变化不影响其余感知层节点的概率分布.因此,当任务或环境变化时,仅需增减部分节点即可实现对不同任务场景的适应,体现节点可扩展性,进而使得模型具有任务可扩展能力.
下面针对具体的多机器人自组织协同围捕任务场景,将所设计的概率图模型实例化展示.
综合考虑多机器人自组织协同围捕场景中的感知范围受限、环境障碍未知以及目标位置不确定等因素,设计该围捕场景下的“感知-决策”概率图模型.如图3所示,模型共有6个节点,1个决策层节点,其他5个为感知层节点.模型节点变量及其状态取值如表1所示.
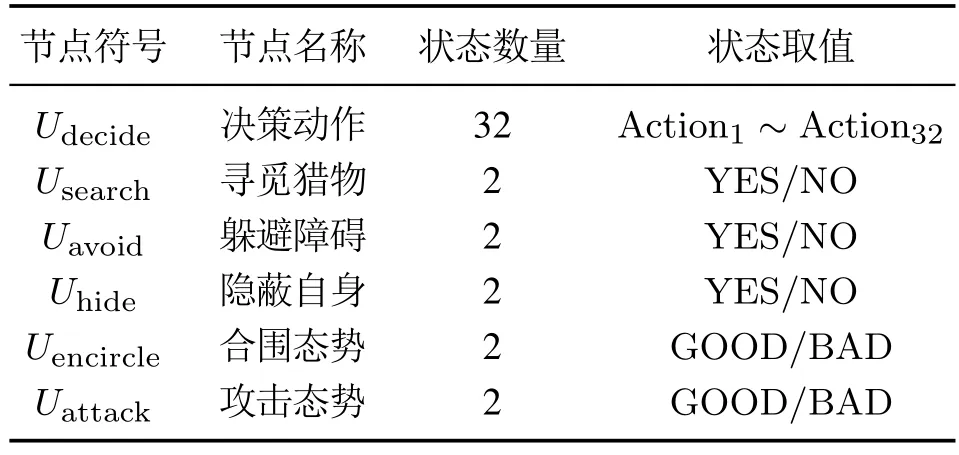
表1 模型节点及状态取值Table 1 Model node and state values
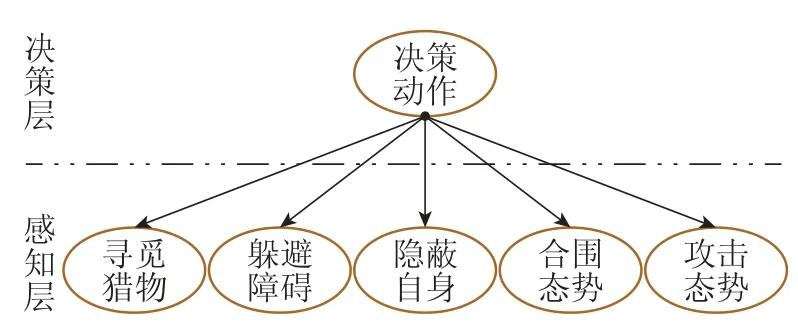
图3 实例化的“感知-决策”概率图模型Fig.3 Instantiated perception-decision probabilistic graphical model
如表1所示,设计节点Udecide的状态与围捕机器人Ri的动作空间一一对应.由第2.1节所描述的个体运动学模型可知,机器人的运动控制通过设计机器人的运动速率和运动方位角来实现.为便于计算,将围捕机器人的动作空间设计为离散的动作空间.围捕机器人Ri运动速率的可选范围为
围捕机器人运动方位角的可选范围为
动作空间由机器人的速率及其运动方位角的不同组合所组成,不同动作对应Udecide的不同状态取值.
3.3 概率参数估计
构建完整的概率图模型结构G后,即确定模型中各个节点之间的逻辑连接关系后,还需要确定概率图模型每个节点的条件概率θ.
为保证“感知-决策”模型的因果性和逻辑性,每个节点的条件概率应满足以下约束条件:
式中:Ui代表模型的某一节点,Sj为节点Ui的状态取值,m表示节点的状态总数,P(Ui=Sj|Pai)表示节点Ui的状态为第j个取值的概率.上述约束中,式(13a)表示各节点的状态对应发生的概率应处于区间[0,1]中,其含义为某一事件发生的概率不会超过1,且不为负数.式(13b)表示各节点的所有状态取值对应发生的概率之和为1,其含义为任一节点任一时刻有且只有一个状态取值,所有状态发生的概率总和为1.
基于式(13a)-(13b)所表述的约束条件,本文针对不同节点的状态含义设计相应状态概率分布的估计方法,具体如下.
为便于后续节点的条件概率估计,定义Rij为机器人Ri在执行决策动作Actionj时将会产生的虚拟机器人.Rij在t时刻的感知范围记为Aij(t).记
表示父节点状态为Sj时节点U*状态为Si的概率.
1)决策动作节点Udecide的状态概率分布估计.
由于该节点为根节点,无任何父节点,此时该节点概率为先验概率,一般根据专家经验或者逻辑分析得到.在概率图模型的统计推断过程中,根节点的先验概率分布是指在不考虑其他因素的情况下各个状态取值的概率[19].当没有任何外部信息输入时,认为先验概率服从均匀分布,即每个状态的先验概率相等,而节点Udecide的状态与动作空间数量相同,共有Naction个,则P(Udecide=Sj)=1/Naction.
由于节点Udecide为模型的根节点,其子节点都有且仅有一个共同的父节点Udecide,因此其条件概率受其父节点Udecide的状态取值所影响.根据概率图模型的条件独立性假设,即每个节点相对其他所有非父节点具有独立性,则给定父节点Udecide的状态取值,节点Usearch,Uavoid,Uhide,Uencircle和Uattack的条件概率相互独立,因此可根据节点Udecide的所有状态取值,独立地计算其余节点的条件概率,从而得到概率图模型的条件概率θ.
2)寻觅猎物节点Usearch的状态概率分布估计.
该节点用于应对场景中目标位置不确定的情况,将被围捕目标作为猎物,引入生物信息素概念,辅助围捕机器人进行猎物寻觅.
通常情况下,Ri在寻觅目标时,应尽可能地探索未知区域,探索过的区域范围越大则相应发现目标的概率越高.考虑到目标的位置是动态变化的,若不考虑机器人探索区域的时效性,则存在Ri探索全局后仍旧未发现目标的情况.针对上述问题,为Usearch节点设计条件概率估计方法,使Ri的探索区域具有时效性.
自然界中,某些生物会利用信息素来标记生物所探索和占领的区域[20-21].受生物启发,引入信息素来标记围捕机器人已探索过的区域,通过信息素随时间衰变的特性,赋予机器人探索区域时效性.设计围捕机器人Ri每移动一步则在对应位置留下信息素点并记录标记该信息素点的时刻为T,信息素的作用范围定义为Ri在T时刻的感知范围.信息素的值随时间而衰减
围捕机器人Ri感知范围内信息素总值越大,表示Ri近期内探索过该区域的可能性越大,则Ri可能发现猎物的概率越低.节点Usearch的状态概率估计为
其中
3)躲避障碍节点Uavoid的状态概率估计.
该节点用于应对环境中存在未知障碍的情况,通过设定障碍安全距离,结合Rij的位置判断Ri撞上障碍的可能性.
设计避障节点Uavoid的状态概率估计为
其中:Ok代表障碍,为Rij到障碍Ok的距离,Dob表示机器人与障碍之间的安全距离.式(18a)表示,当Rij到障碍Ok的距离大于围捕机器人与障碍之间的安全距离Dob时,Ri不会撞上障碍,此时机器人能够躲避障碍的概率为1,否则,Ri撞上障碍的概率较大,机器人能够避障的概率为0.
4)隐蔽自身节点Uhide的状态概率估计.
在围捕问题中,被围捕目标通常具有威胁躲避功能,在感知到威胁时一般会远离威胁源进行逃逸.为尽量减少由于目标逃逸产生复杂的博弈问题[22],以目标感知范围设定目标围捕安全域,围捕机器人在安全域之外隐蔽自身同时对目标进行合围.因此判断机器人能否隐蔽自身可转化为判断猎物是否会发现围捕机器人.
设计隐蔽自身节点Uhide的概率估计为
显然,若Ri执行决策动作Actionj会进入Re的感知范围,则猎物会发现Ri并且开始逃逸,此时该状态对应的概率应为1;否则,该状态对应的概率应为0.基于上述规则,即可实现节点Uhide的状态概率估计.
5)合围态势节点Uencircle的状态概率估计.
参考文献[23],采用期望动态围捕点辅助机器人对目标进行合围.首先,根据目标位置为机器人设置期望围捕点I={Ii|i=1,2,···,N}.期望围捕点均匀分布在以目标位置为圆心,期望合围半径Dc为半径的圆周上.而后,使用匈牙利算法[24-25]以机器人到围捕点的距离作为代价,给机器人分配期望围捕点,从而将合围态势的好坏的判定与围捕机器人到各自期望围捕点距离的远近相关联,机器人到对应围捕点距离越小,则认为合围态势越好.
6)攻击态势节点Uattack的状态概率估计.
该节点用于表征机器人的动作对目标的攻击态势.通常情况下,机器人距离目标越近,意味着越有可能攻击成功,因此其概率与围捕机器人相对目标的距离成负相关.
设计节点Uattack状态的概率估计为
至此,结合第3.2节所设计的概率图模型结构以及本节设计的概率分布估计方法即可构建完整的“感知-决策”概率图模型,基于该模型根据感知信息可推断当前最佳决策行为,下面介绍围捕策略与算法流程.
3.4 围捕策略
狼作为生物圈的顶级掠食者之一,在个体能力不占优的情况下,仍可通过团队协作狩猎比狼群个体更大更强的猎物.狼群的协同狩猎行为由多个觅食状态组成[26],通常包含: 搜索、合围和捕获等状态.
受狼群狩猎行为启发,机器人采取分散围攻的策略以提高围捕效率.设计一种多机器人协同围捕策略,将围捕任务划分为搜索、合围与捕获3个阶段性子任务,依据不同的阶段任务设计各阶段的期望节点状态(如表2所示).根据各阶段任务,基于第3.2节和第3.3节构建的“感知-决策”概率图模型,估计各节点状态取值的概率分布,择取使感知层各节点的期望状态概率最大的决策动作为模型输出.

表2 阶段及任务划分Table 2 Division of the stage and tasks
围捕机器人按照预设流程依次进行,完成本阶段任务后转入执行下一阶段.
4 实验验证
为验证所提算法的有效性,本章设计如下实验进行算法性能的验证.
4.1 场景设计
实验场景见图4,N个围捕机器人对一个逃逸目标进行围捕,围捕区域为200×200的矩形区域,其中:Ri为围捕机器人,Re为逃逸目标,黑色实心区域为障碍物,蓝色虚线圆代表机器人个体的感知半径,红色虚线圆代表目标的感知半径.

图4 仿真实验场景Fig.4 Simulation experiment scenario
围捕机器人通过感知外部环境,结合自身位置决策出下一步的运动速率与方向,使其在规避障碍碰撞的前提下围捕逃逸目标.具体参数设置见表3.

表3 实验环境参数Table 3 Experimental environment parameters
按照上述实验设置,分别设计节点可扩展性实验、环境适应性实验以及系统抗风险性实验,以验证所提方法的性能.为验证模型可迁移性,基于Gazebo平台进行软件在环围捕实验.最后,设计与其他文献方法的对比实验以验证所提方法的有效性.
4.2 节点可扩展性验证
为验证模型节点可扩展性,分别设计无障碍环境和有障碍环境下的仿真围捕实验,实验设置中有障碍环境下机器人的决策模型仅比无障碍环境下的决策模型多考虑一个避障节点Uavoid,模型其余参数设置完全一致.以3个围捕机器人围捕一个目标的情况为例进行仿真实验,分析实验结果.
实验1无障碍环境下的仿真围捕实验.由于实验环境中不存在障碍物,因此机器人Ri不必考虑避障问题,其决策模型无避障节点Uavoid.实验设置围捕机器人R1-R3的初始位置分别为R1:(-60,-80),R2:(-20,-60)和R3:(70,-70),机器人最大运动速率为2.5 m/s,目标的初始位置为(-87,40),目标最大运动速率为3 m/s.
无障碍环境下的全程运动轨迹如图5所示.其中:蓝色曲线为机器人运动轨迹,红色曲线为目标运动轨迹,箭头代表轨迹运动方向.机器人按照预设流程依次完成了3个阶段任务:1)搜索阶段: 机器人与目标距离较远,互相无法感知到对方的位置,此阶段机器人在搜索目标,而目标在场景区域内随机游走.该阶段从t=1 s持续到t=34 s,直到有一个机器人发现目标,完成搜索任务,转入合围阶段;2)合围阶段: 目标仍然随机运动.机器人R1在t=35 s时发现目标位置,其始终将自身与目标的距离控制在10~15 m之间,同时召唤其他同伴前来合围,机器人R2和机器人R3则向目标前进,以构成围捕队形.该阶段从t=35 s持续到t=73 s,直到机器人到达各自的期望动态围捕点,对目标形成合围时,转入捕获阶段;3)捕获阶段:该阶段从t=74 s持续到t=79 s,机器人已在目标周围构成围捕队形,一同向目标趋近完成围捕.t=79 s时,R3成功捕获目标,完成围捕任务.
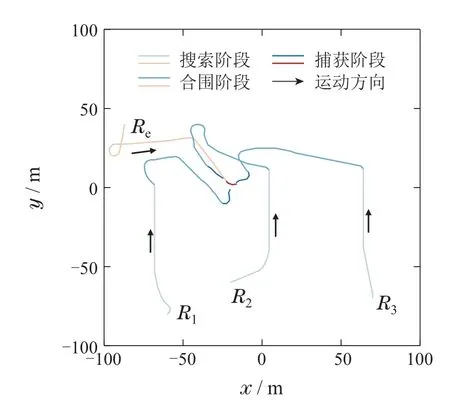
图5 无障碍环境下的全程运动轨迹Fig.5 Full motion trajectory in an obstacle-free environment
实验2有障碍环境下的仿真围捕实验.在无障碍环境实验设置的基础上,增加5个圆形障碍物,其余设置同实验一相同.因任务环境新增障碍物,依据节点可扩展性,在决策模型中加入避障节点Uavoid以应对环境变化.
有障碍环境下,3个机器人协同围捕一个逃逸目标的全程运动轨迹如图6所示,实验共持续82 s.可以看出,围捕机器人R1-R3能够实现在避障的同时对目标进行合围.图6中R1在经过黑色障碍区域时,运动轨迹出现了明显的弯折,表现出机器人的避障行为.该行为呈现出机器人的避障能力,进而体现所提方法对障碍的适应性.
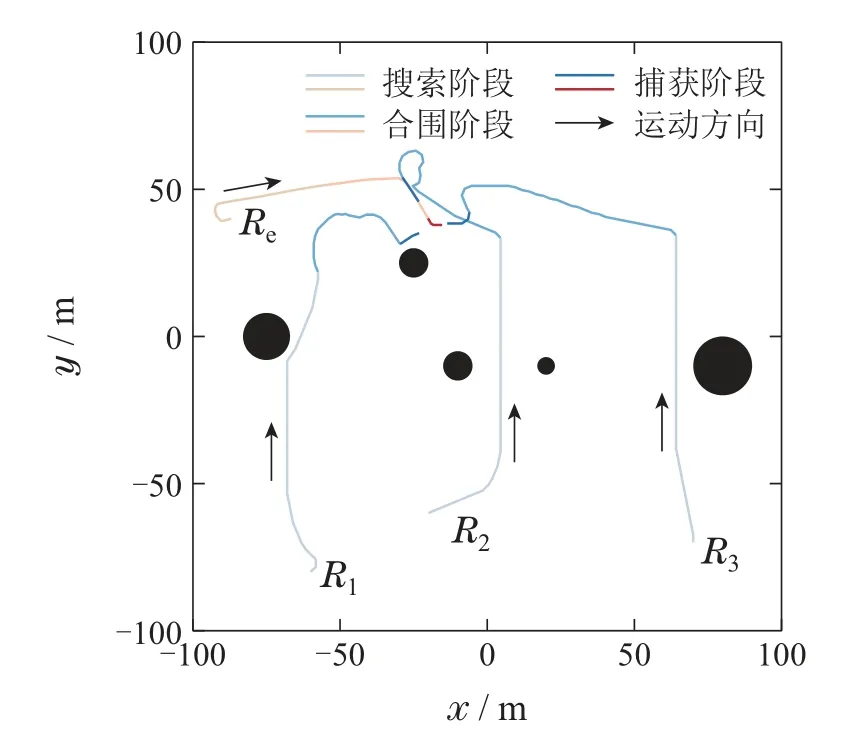
图6 有障碍环境下的全程运动轨迹Fig.6 Full motion trajectory in an obstructed environment
实验结果表明,在决策模型只增加避障节点的情况下,可使机器人具备避障能力,能够按照预期流程在躲避障碍的同时对目标进行搜索并围捕.究其原因,是所设计的“感知-决策”模型的特殊结构使得感知层节点之间具备条件独立性,即部分感知层节点的增减不会影响到其余感知层节点的概率分布.因此,在环境条件发生变化时,仅需增减部分节点即可实现对不同任务场景的适应,体现节点的可扩展性.
4.3 环境适应性验证
为验证所提算法对不同环境的自适应性,进一步测试算法性能,探究围捕机器人的数量、场景面积、障碍数量以及机器人和被围捕目标之间个体运动性能差异的不同对围捕成功率的影响,设计如下实验.
实验1探究围捕机器人的数量以及围捕机器人和被围捕目标之间个体运动性能差异的不同对围捕成功率的影响.为排除偶然误差影响,随机初始化围捕机器人Ri和被围捕目标Re的位置,以及障碍物的位置和大小,测试在不同环境设置下,使用相同的模型参数,围捕机器人能否顺利完成围捕任务.同时将被围捕目标与围捕机器人的最大移动速率比(即作为围捕机器人与目标的个体运动性能差异的指标,探究个体运动性能差异的不同以及围捕机器人的数量对围捕成功率的影响.
实验环境设置如图4所示.被围捕目标的初始化位置为范围内随机,其范围为(40,100),对应图中的红色斜线矩形区域.围捕机器人位置的随机初始化范围如图中的蓝色斜线区域所示,为黑色竖线矩形区域对应的是障碍物Oi初始化位置的随机范围:障碍物半径的随机取值范围为(3,10).值得说明的是,所提算法并不受初始化条件约束,上述随机初始化设置一方面是为了尽可能让目标与围捕机器人的初始位置相互远离;另一方面是让障碍在围捕过程中起到阻挡作用,从而保证任务难度.
基于上述环境设置,对围捕机器人与被围捕目标的最大移动速率比(即)为1.0~3.0,且围捕机器人数量为3~10的情况进行围捕实验.对每组实验参数分别进行100次实验并统计围捕成功率,如图7所示.可以看出,面对围捕机器人Ri和被围捕目标Re的初始位置不同,以及障碍物的位置和大小不同的情况,围捕机器人都能顺利完成围捕任务,验证所提算法的环境自适应性.

图7 围捕成功率Fig.7 Success rate of capture
进一步分析可得,Ri与Re的最大移动速率比增大时,围捕成功率呈现减小趋势,因此围捕成功率与成负相关.当足够大时,目标能够利用较强的机动性能在围捕机器人即将包围目标时迅速逃逸包围圈,使得围捕成功的概率降低.这一趋势表明,当被捕捉目标的运动性能比围捕机器人的运动性能更好时,目标更难被捕捉,因此围捕成功率会降低.同时,随着围捕机器人数量的增多,围捕成功率也逐渐增大,这表明当围捕机器人数量增加时,围捕的效率将会相应提高,因此围捕成功率与围捕机器人数量成正相关.此外,在增大同时机器人数量减少到一定阈值时,图7中可以看出围捕成功率有一个明显的断层.经过拟合后大致以70%为判定标准,绘制出围捕机器人的能力边界线(见图7).认为当给定速率比时,指派参与围捕的机器人数量应在能力边界线以内,即预期围捕成功率在70%以上,以保证机器人能顺利完成任务的概率.
图8 展示的是成功捕获目标时,任务的平均完成时间.眼见可得,随着围捕机器人数量的减少,速率比的增大,围捕任务平均耗时呈现增大趋势.该结果符合逻辑常理,证明所提围捕方法具有一定的逻辑性.具体而言,围捕机器人数量的增多可以增加搜索与围捕的覆盖面积,进而提高任务效率,从而提高捕获目标的成功率.而在增大的情况下,由于目标具有相对更高的机动性,更难被捕捉,因此需要更多的时间.此外,当围捕任务对时间有限制时,应尽可能快地完成任务,即尽量在短时间内捕获目标.参考上述实验结果,可安排更多的围捕机器人参与围捕任务来提高围捕效率,从而缩短任务耗时.

图8 围捕任务完成时间Fig.8 Completion time for the pursuit mission
实验2探究场景障碍数量的不同对围捕成功率的影响.为探究围捕成功率和围捕时间与障碍密度之间的变化关系,设计不同障碍场景条件下的围捕仿真实验.围捕机器人的数量为5,围捕机器人的最大运动速率为1.5 m/s,目标的最大运动速率为3 m/s,在200×200的障碍场地中对障碍数量为10~90的情况进行围捕仿真实验.为保证围捕任务的难度,围捕机器人与被围捕目的初始位置分别随机在场景的两端,障碍位置与大小在场景中随机初始化,对每组参数各进行100次实验,得到结果如表4所示.

表4 不同障碍数量下的实验结果Table 4 Experimental results under different number of obstacles
显然,在固定围捕机器人数量、围捕机器人与目标的运动速率以及感知半径等参数的前提条件下,随着障碍数量的增加,围捕的成功率有减小趋势,围捕任务的完成时间呈现增大的趋势.究其原因,是障碍数量的增加增大了围捕任务的难度,在围捕过程中,机器人与目标之间往往存在多个障碍物,使得机器人无法直线前往合围,从而增大了实现捕获的距离,进而增加了目标可逃逸时间.并且,由于目标的机动性能较好,相对的避障能力也较强,因此,障碍数量的增多更有利于目标的逃逸,从而导致围捕成功率的降低.
实验3探究场景面积的不同对围捕成功率的影响.为探究面积的变化与围捕成功率以及围捕时间之间的关系,本文设计了不同面积条件下的仿真实验.机器人的数量为10,围捕机器人的最大运动速率为1.5 m/s,目标的最大运动速率为3 m/s,分别在尺寸为800×800至2000×2000的无障碍场地中进行围捕实验.围捕机器人与目标的初始位置分别随机在场景的两端,以确保围捕机器人与目标的初始距离足够远,从而增加围捕任务的难度.每组参数各进行100次实验,得到不同场景面积下的实验结果如表5所示.

表5 不同场景面积下的实验结果Table 5 Experimental results under different areas
由表5可知,在固定围捕机器人数量、围捕机器人与目标的运动速率以及感知半径等参数的前提条件下,任务场景的面积增加时,围捕成功率呈现降低趋势,围捕任务完成的平均耗时对应增加.究其原因,是因为随着围捕场景面积的增大,围捕机器人的感知范围无法对围捕场景进行全覆盖,增大了搜索目标的难度,减小了搜索到目标的成功率,从而使得围捕不成功的概率增大.此外,在本文的实验设计中,围捕机器人与被围捕目的初始位置分别随机在场景的两端,面积增加将导致目标与围捕机器人的初始距离增大,造成围捕机器人搜索到目标的时间增大.同时目标的可活动区域也会增大,由于目标的机动性能较围捕机器人更好,从搜索目标到形成合围态势的时间也会增加,围捕任务完成的平均耗时同步增加.因此,当任务场景的面积足够大时,围捕成功率将会降低.
4.4 抗风险性验证
实际任务执行过程中往往存在因各种未知风险,使得部分围捕机器人发生故障无法继续任务的情况.由于所提为自主协同的围捕算法,算法的计算与决策过程是自组织的,理论上,即使部分个体出现故障,其余围捕机器人仍旧能够继续完成围捕任务.为验证算法的抗风险性,设计如下实验,测试在部分围捕机器人发生故障时,其余机器人能否继续完成任务.
以6个机器人围捕一个目标的任务为例进行实验.机器人最大运动速率目标最大运动速率图9为抗风险性仿真实验结果.
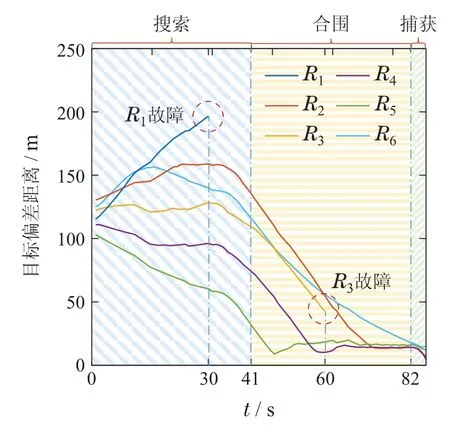
图9 抗风险性仿真实验结果Fig.9 Results of risk resistance simulation experiment
图9定量展示了围捕过程各机器人与目标之间的偏差距离.可以看见,R1和R3分别于t=30 s时刻和t=60 s时刻发生故障,除故障的R1和R3外,其余机器人与被围捕目标的偏差距离整体是逐渐收敛的.说明在R1和R3故障后,其余机器人正常执行围捕任务,仍能继续对目标进行搜索、合围并捕获.
该实验结果验证了所设计围捕方法的抗风险性,围捕机器人通过自主感知环境(包含目标、障碍、同伴等),基于感知信息作出决策并执行,部分机器人发生故障对其余围捕机器人的自主决策与动作执行没有影响,其他机器人仍旧能够执行围捕任务.
综上,考虑到实际任务过程中的未知风险与机器人的能力边界,在已知速率比时,应在能力边界线内安排参与围捕任务的机器人数量冗余,确保其在部分机器人故障时,其余机器人仍具有按要求完成任务的能力.
4.5 模型可迁移性验证
为验证模型可迁移性,基于机器人操作系统(robot operating system,ROS)环境下的Gazebo平台进行软件在环围捕实验.限制机器人的最大速度为2.5 m/s,目标最大速度为3 m/s.采用无人机作为基本的机器人个体与目标模型,在有障碍环境下对围捕算法的实用性进行验证.
实验结果如图10所示.其中: 虚线圆圈所指的是被围捕目标,实线圆圈内的是围捕机器人,圆柱体为障碍物.实验开始时,机器人先在场景内搜索目标,同时躲避环境障碍,目标则于场景中进行漫步移动,如图10(a)所示.机器人发现目标后,转入合围阶段,对目标进行合围.在图10(b)中,R1-R3在躲避障碍的同时包围目标,并即将完成对目标的合围.最终,在t=76 s时机器人成功捕获目标,如图10(c)所示.实验结果表明,所提围捕算法模型能够直接迁移应用在ROS环境下的Gazebo平台中,体现所提算法的模型可迁移性.
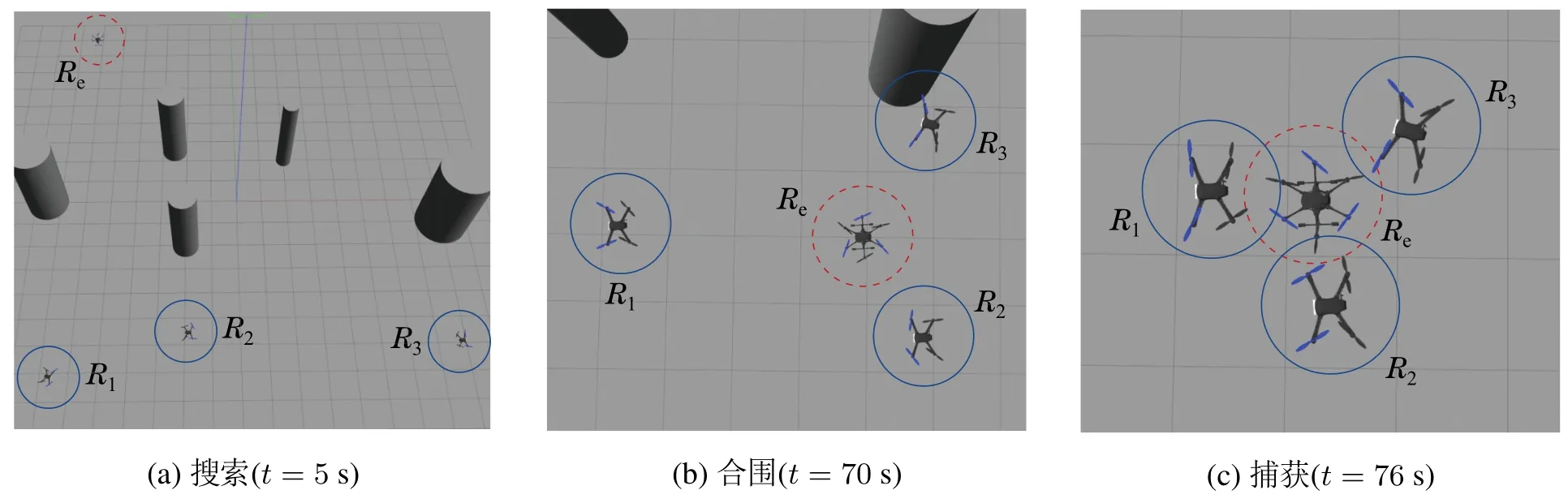
图10 有障碍环境下的ROS仿真结果Fig.10 ROS simulation results in an obstructed environment
4.6 对比实验
为了验证所提算法的优越性,本节选取以下3种围捕算法作为基准进行对比实验:
1)动态围捕点算法(DHP):文献[23]提出了一种基于动态围捕点(dynamic hunting points,DHP)的多机器人协同围捕方法,使得机器人能在无障碍环境下实现对目标的围捕.然而,DHP方法未考虑机器人的避障,不适用于有障碍场景下的围捕;
2)人工势场法(APF):基于人工势场法(artificial potential field,APF)的经典围捕算法可构造虚拟人工势场,通过设计目标的“引力”与障碍的“斥力”现实有障碍环境下的围捕;
3)分散围攻法(APF+): 针对目标机动性能强于机器人的情况,将APF方法与第3.4节的分散围攻策略结合,设计“APF+策略”的分散围攻法以提高围捕效率.
分别在无障碍环境和有障碍环境下进行对比实验,实验场景大小为200×200,围捕机器人数量为4,围捕机器人的最大运动速率为1.5 m/s,目标的最大运动速率为3 m/s,障碍场景的障碍数量为90.
实验结果如图11所示.图11左侧为无障碍环境下的实验结果,图11右侧为有障碍环境下的围捕成功率.结果表明,在上述实验场景中,本文所提方法的围捕成功率显著高于其他方法,证明所提方法的有效性与优越性.

图11 对比实验结果Fig.11 Comparative experimental results.
5 结论
本文针对感知能力受限、环境结构未知、目标状态不确定的场景下多机器人协同围捕任务,提出了基于概率图模型的多机器人自组织协同围捕方法.主要工作如下: 1)建立了围捕机器人与目标的运动学模型,给出了围捕任务的数学描述;2)基于概率图模型理论基础,建立了多机器人协同围捕的“感知-决策”概率图模型,设计了模型节点状态的概率分布估计方法;3)对比实验验证了所提方法的有效性与优越性,数值仿真实验与软件在环实验验证了所提方法的节点可扩展性、环境适应性、抗风险性和模型可迁移性.
在进一步的研究工作中,本文考虑对环境中更多的不确定因素进行概率表征,深入剖析概率估计中所包含的不确定知识,提炼概率表征规则,进一步优化概率分布参数估计方法.同时,将所提方法进行三维场景实例化,对多目标场景下的围捕问题进行研究.
