自主空战机动决策技术研究进展与展望
2023-02-09周思航张中杰
陈 浩,黄 健,刘 权,周思航,张中杰
(国防科技大学智能科学学院,长沙湖南 410073)
1 引言
21世纪以来,有人/无人作战飞机在局部地区战争中发挥了重要作用,可以说掌握了制空权就掌握了现代战争的主动权[1].特别是在2022年俄乌冲突初期,俄罗斯首轮精确打击的目标就是乌克兰境内的指挥中心、机场、空军基地等,从而瘫痪其空中力量并掌握制空权,为后续空降兵部队和地面部队扫除空面威胁.可见,空中力量对于战争的走向至关重要.战斗机是形成并扩大空中优势的主战力量,世界各国对新一代战斗机的研发一直是军事领域的热点[2].例如,美国正加紧研制穿透性制空作战飞机,进一步提出了空战智能化、自主化的要求,以达到其在《空中优势2030飞行计划》[3]中破解“反介入/区域拒止”能力的建设目标.
随着先进武器装备和人工智能技术的不断融合发展,战斗机在形成并扩大空中优势中发挥着愈发重要的作用,世界各军事大国也愈发重视对自主空战(autonomous air combat)的研究.空战决策作为战斗机的“灵魂”和“大脑”[4-5],是现代空战的核心.如何在环境高复杂、博弈强对抗、响应高实时、信息不完整、边界不确定的现代空战环境[6]下构建智能化的机动决策模型是当前亟待解决的问题.随着计算机硬件技术、机器学习算法、大数据等人工智能技术的不断迭代发展,军用通信设备、干扰设备、机载传感器等武器装备的不断革新,军事智能逐步走向战场,必将对以战斗机空战为主要形式的空面战场引发深刻变革.
本文重点关注自主空战中的机动决策问题,整体结构如下: 第2节给出了自主空战机动决策的定义,并分析了其在实际空战中的重要意义;第3节阐述了自主空战机动决策在现代空战各领域发展中的重要作用;第4节详细梳理了现有自主空战机动决策建模和求解方法,总结对比了各研究分支的发展脉络、特点、优势及缺陷;第5节基于1v1典型空战任务,从统计意义上对比了不同类型方法的性能差异;第6节展望了下一步值得研究和探索的方向;第7节总结了本文工作.
2 空战分类与机动决策的定义
按照开展对抗的交战距离划分,空战可以分为以航炮或近距空空导弹作为主要武器的视距内(within visual range)空战和以中远程空空导弹作为武器的超视距(beyond visual range)空战.视距内空战又称近距空战、视距内格斗、狗斗(dogfight)等,其作战距离的上限一般在10 km.超视距空战又可细分为中距空战和远距空战,对应的作战范围分别为10~100 km和100 km以上[7].
一直以来,空战决策是现代战争的关键,空战决策的好坏将直接影响整个空战任务完成的质量[8].空战决策可以细分为目标分配和机动决策,而机动决策是空战决策的核心[9].总结已有研究[10-13],本文对空战机动决策(air combat maneuver,ACM)定义如下:
定义1机动决策是指我机为获取空中优势,并对敌机构成威胁,综合考虑机动能力、当前态势等信息,控制作战飞机进行机动的过程.
在超视距空战中,机动决策的主要目的是尽快将敌机暴露在我方空空导弹的攻击范围内,并通过机动站位逃离敌方导弹攻击区,从而避免我机受到威胁,力求达到“先敌发现、先敌发射、先敌命中”的目标.在以航炮为主要武器的视距内空战中,我机需要通过连续机动决策获取尾后的优势占位,并摆脱敌机追击,从而提高我机的生存概率和对敌的毁伤概率.特别是在高强度的近距狗斗中,合理的机动决策至关重要.在以红外近距空空导弹为武器的近距空战中,尽管红外格斗导弹无须以占据尾后位置作为发射的必要条件[6],但是高效且准确的机动占位仍然是在现代空战中获取态势优势的基础.
随着传感器技术和导弹技术的不断发展,战斗机感知战场环境的能力和打击范围有了显著提升,超视距空战的地位逐渐凸显.然而,这并不意味着视距内空战将被替代,相反,以机动决策为核心的视距内空战仍是世界各国研究的热点[14-16].
2017年8月,美国国防高级研究计划局(defense advanced research projects agency,DARPA)战略技术办公室(strategy technology office)提出了马赛克战(Mosaic warfare)[17]的概念.马赛克战旨在将作战概念从成本高、开发周期长的有人系统转向有人和低成本无人系统的混合形式,从而实现作战系统的快速开发、部署和升级,以应对不断变化的威胁.如图1所示,2019年公布的空战演进(air combat evolution,ACE)项目[18]则认为是实现马赛克战的入口,其目的是通过局部的自动化空战,增强人机互信机制,而人类飞行员负责更宏观的空中战场[19].
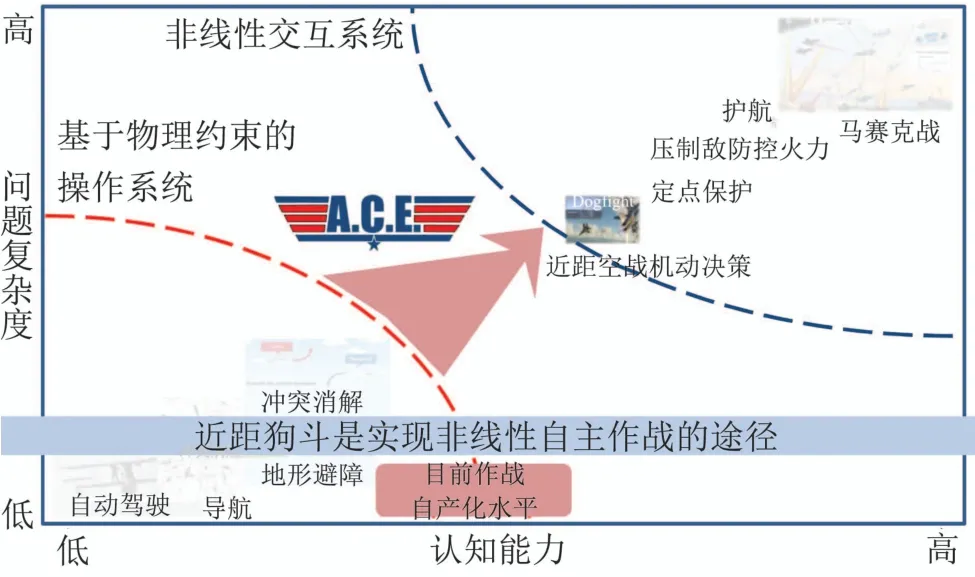
图1 马赛克战、ACE项目、近距狗斗的关系[18]Fig.1 Relationships between Mosaic warfare,ACE,and dogfight[18]
由于近距狗斗场景具有明确定义的目标、可测量的结果和固有的物理限制,ACE项目将1v1近距自主空战机动决策作为其初始的挑战场景,并逐渐扩展至2v1和2v2的对抗环境中,最终达到马赛克战的要求,整个过程如图2所示.
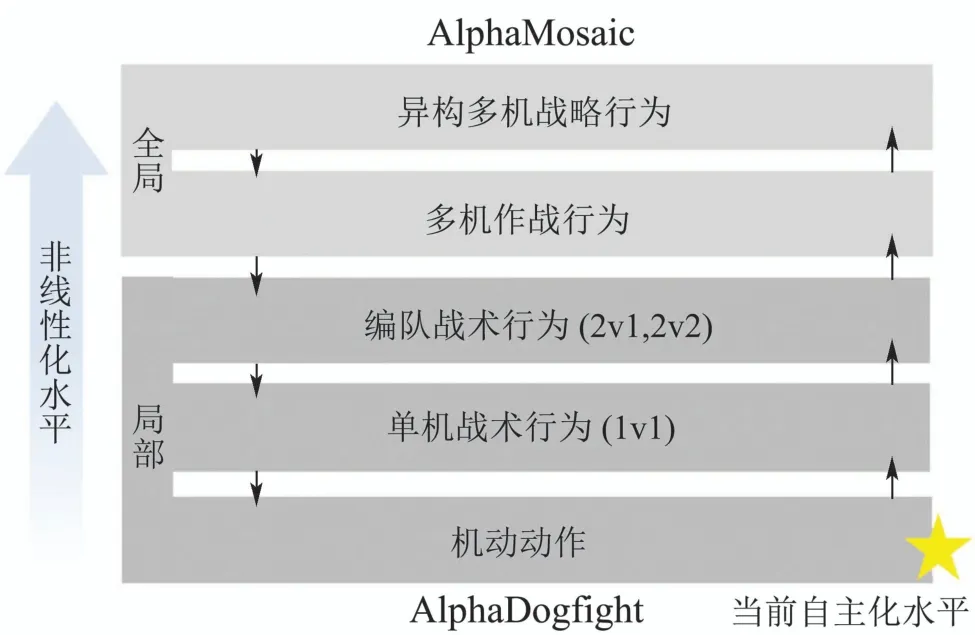
图2 AlphaDogfight到AlphaMosaic的演变[18]Fig.2 Evolution from AlphaDogfight to AlphaMosaic[18]
视距内自主空战机动决策问题的复杂度关系[18]如图3所示,其对抗环境动态复杂,状态空间复杂度介于西洋跳棋与国际象棋之间.由于各种干扰设备的影响,视距内空战不是完全可观测的,隶属于不完美信息博弈的范畴,其信息可观测程度介于雅达利视频游戏[20]和扑克之间,例如,在狗斗过程中我机难以实时获取敌机的姿态信息.与此同时,其对决策的效率和实时性要求较高,每分钟内的决策次数超过了自动驾驶和雅达利视频游戏.此外,对抗数据获取难度大、敌机动作具有欺骗性、决策规则不完备、相关专业知识复杂等[21]是自主空战机动决策问题区别于图3中其他任务领域的显著特征.
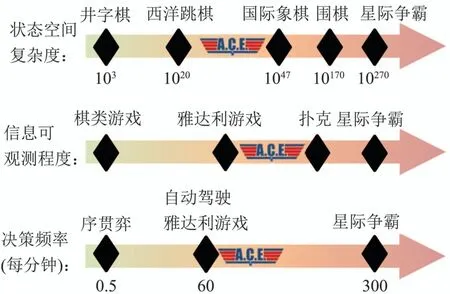
图3 视距内自主空战机动决策的复杂度[18]Fig.3 Complexity of ACM within visual range[18]
在实际应用中,相较于超视距空战,视距内空战仍不可替代的原因主要有: 1)中远距空空导弹未能击落对手时,将被迫转入视距内空战[22];2)交战规则、政治策略和目标识别困难等将会限制空空导弹的应用[23];3)空空导弹的机动能力、装配时间和弹头限制等制约了其最小射程[16];4)敌方电子对抗和曳光弹等干扰措施极大削弱了空空导弹的性能,但几乎不会对航炮产生影响[24];5)航炮射击不依赖于雷达系统,而空空导弹必须与雷达紧密配合,极易受到敌机机动和干扰设备的影响;6)广泛采用隐身技术的新一代战机限制了现有侦察探测手段的效能,导致发现敌机时可能已在视距内空战的范围内.
此外,美军现役的先进战斗机(例如,F-22和F-35)仍然装备航炮用于近距空战.视距内的1v1空战和基本战机机动(basic fighter maneuver)仍然是战斗机飞行员训练的重要课目[25],熟练掌握基本机动动作是执行空中防御、护航、定点保护等任务的基础.
综上,未来空战很可能发起于视距外而最终决胜于视距内[26],视距内自主空战机动决策仍具有重要意义.总结已有研究[9,25,27-32],对自主空战机动决策定义如下.
定义2自主空战机动决策是指利用数学优化、人工智能等方法,基于当前态势和作战目标,模拟对有人/无人作战飞机的操纵决策,自主地生成机动动作的过程.
3 现代空战对自主机动决策的需求
3.1 提高空战决策效率和准确性
在现代强对抗、高动态空战[6]中,战斗机飞行员在执行任务时需要获取并融合各机载传感器、地面站、队内友方作战飞机、当前敌我双方态势等多方面信息,态势评估后再进行战术机动和攻击站位.然而,在高强度的对抗中,人类飞行员不仅身体要承受巨大过载,其心理和生理均会遭遇严峻挑战[29,33].同时,飞行员的态势感知、信息融合能力很难保证长时间处于巅峰状态,更难以在短时间内充分利用这些信息,进而影响了其决策质量.另一方面,现代空战环境的复杂性对飞行员的决策效率和准确性提出了更高要求.美军约翰·博伊德上校在20世纪60年代提出使用OODA(observe orient decide act,OODA)环描述空战过程时就指出:战斗机飞行员不是胜于肌肉的反应速度,而是胜于大脑到肌肉的关联速度[34].人类的视觉反应时间平均约为0.15~0.3 s[35],再加上与友方合作和最优方案选取的时间,单纯依靠人类飞行员将很难满足现代空战对于决策效率的要求.
3.2 减轻飞行员决策压力
人工智能技术在信息融合、态势评估、矩阵计算、反应速度等方面具有天然优势,研究基于人工智能的机载辅助决策系统将很大程度上减轻飞行员的压力,从而提高空战决策的效率和准确度.典型的空战辅助决策系统有飞行员助手(pilot’s associate)[36]和战术任务管理系统(tactical mission management system)[37].此外,ACE项目也将建立人机互信机制、缓解飞行员的决策压力作为一项重点研究内容.另一方面,发展具备自主决策能力的智能化无人作战飞机,将智能决策技术与战斗机平台深度融合,通过减小对飞机机动性和最大过载的限制,突破人类飞行员心理和生理极限,有效降低了飞行员风险和空战成本的同时提升了战机的作战效能[27].
3.3 提升无人装备作战效能
现代战争中,无人作战飞机执行的任务逐渐由侦察监视向综合打击、对地火力压制等战术任务转变[1,14],但这些任务基本都需要人在环路控制,对数据链路带宽和实时性要求高,而无人机与地面站的通信链路极容易受天气和电磁干扰的影响,极大限制了其在强对抗复杂空战中的应用,难以发挥出其应有的作战效能[38-39].因此,无人作战飞机必须尽量脱离地面站的控制,深度融合智能决策技术,实现自主决策和自主控制[40].《美国无人系统发展路线图FY2011-2036》[41]中也明确指出,军用无人机发展的最终目标就是实现完全的自主化.另一方面,自主空战决策模型的嵌入可以辅助地面和空中作战人员进行引导和决策,从而极大减轻了地面领航员和空战编队作战人员的压力[42].
3.4 实现有人/无人协同作战
有人/无人战斗机协同作战的概念对空战自主性提出了新的要求.在这一背景下,有人机飞行员统揽全局,负责高层次的认知活动,例如,制定全局交战策略,选择并确定目标的优先级,确定使用的武器种类等.而智能化的无人战斗机负责具体自主机动、战术执行、提供战场信息、对敌打击以及对有人机的保护等[27].在有人/无人协同的框架下,世界各国开展了一系列“忠诚僚机”(loyal wingman)项目.2019年3月,美国空军研究实验室(air force research laboratory,AFRL)发布了“空中博格”(Skyborg)项目[43-44](其概念机如图4所示),并于2019年12月与Kratos 等公司签订了开发合同[45],该项目旨在将智能决策算法等集成于低成本可消耗的无人机,并实现与有人机协同作战.2020年12 月,Kratos 公司研发的XQ-58A“女武神”无人机与美军现役先进五代机F-22和F-35A完成了编队飞行试验(如图5所示)[29].2021年8月,通用原子航空系统公司完成了其研发的MQ-20无人机与改造后King Air 2000战斗机的有人/无人编队飞行试验[46].此外,2020年8月,俄罗斯Kronshtadt 公司公布了名为“雷霆”的无人机,并称该无人机可以与苏-57战斗机实现有人/无人协同突防任务[47].2021 年12月,澳大利亚皇家空军也完成了其首架忠诚僚机的试飞,并对其关键特性进行了分析[48].

图4 Skyborg概念机Fig.4 Concept of Skyborg

图5 XQ-58A“女武神”与F-22、F-35A有人机编队飞行Fig.5 F-22 Raptor,F-35A and XQ-58A flying in formation
3.5 探索新战术战法
随着战斗机相关技术的不断迭代发展,作战飞机的机动性能、挂载武器和机载传感器性能等都有了质的提升,例如,先进无人战斗机在自主空战机动决策系统的加持下,可以完成超越人类飞行员身体承受极限的大过载机动.唯有将新一代战机与新的战术战法、机动策略相结合,才能充分挖掘其作战能力.现有的战术战法基本来源于飞行员的实战经验,但这些战术认知受限于当时战斗机的机动能力和人类的生理、心理限制.此外,目前也有对轨迹自动生成技术的研究[49-51],但这些方法仍受限于模型的表达能力、人类的固有认知和模型求解能力[6].因此,为充分发挥新型无人装备的作战效能,需要在智能化自主空战的大背景下,突破人类认知瓶颈和模型表达限制,借助深度强化学习(deep reinforcement learning,DRL)、自博弈等人工智能方法,探索新的空战战术战法.
综上,深入研究智能化自主空战机动决策相关技术,对于现代空战发展及制胜未来空中战场具有重要意义.此类技术的研究运用不仅可以辅助有人机决策,有效提高无人装备作战效能,还能够为有人/无人协同作战提供核心技术支撑.
我国在自主空战机动决策领域的研究虽处于起步阶段,但在实际应用需求的牵引下,相关工作正积极展开,并取得了一定成果.首先,近年来各大学会和研究所多次合作举办了具有广泛影响力的学术论坛(如,全国空中智能博弈论坛[52]),为技术交流和研讨提供了持续且广阔的支撑平台,有力促进了国内自主空战决策技术的发展.同时,智能空战比赛逐渐成为驱动技术创新的主要动力,如航空工业成都所举办的“龙智杯”智能AI空战大赛、空军装备部发起的“天行杯”智能空战算法挑战赛、指控学会主办的世界空中智能博弈大赛等.上述比赛在战机控制粒度、对抗规模、应用模式等方面存在明显差异,从不同侧面推动了自主空战决策模型的技术创新.其次,目前具有智能对抗能力的空战系统已初现端倪,如中电科28所开发的“空战智能参谋系统”[53]能够根据获取的当前复杂态势为指挥员提供决策建议,从而减轻指挥员实时决策压力;白杨时代、渊亭等科技公司融合先验规则、模仿学习、DRL、自博弈等技术实现了具有一定泛化能力的决策模型.此外,2022年我国首次公开了双座版歼-20战机[54],有望支持后座飞行员操控无人僚机,从而为战机遂行有/无人协同等复杂作战任务奠定了基础.
4 自主空战机动决策方法
自主空战机动决策过程示例如图6所示.决策算法以敌我双方构成的态势信息作为输入,结合我机机动性能、机载武器和作战目标,通过数学建模求解[55]、在线推理[56]、规则匹配[10]、智能优化[35]、深度神经网络[57]等手段,从机动动作库或战术库中选择最优决策方案执行.

图6 自主空战机动决策示意图Fig.6 Diagram of autonomous air combat maneuvers
本文将现有自主空战机动决策的研究分为:基于博弈论的方法、基于优化理论的方法和基于数据驱动的方法3大类.总的来说,基于博弈论的方法建模和求解直观且易于理解,但计算量庞大,决策实时性难以保证,且适用场景有限;基于优化理论的方法适应性强,可扩展性好,但其性能强烈依赖态势评估模型的质量,且实时性差;基于数据驱动的方法实时性好,决策时不需要遍历解空间,但决策模型普遍需要大量数据支撑.每一类方法对应的研究分支以及每种方法的优势和缺陷总结如表1所示.
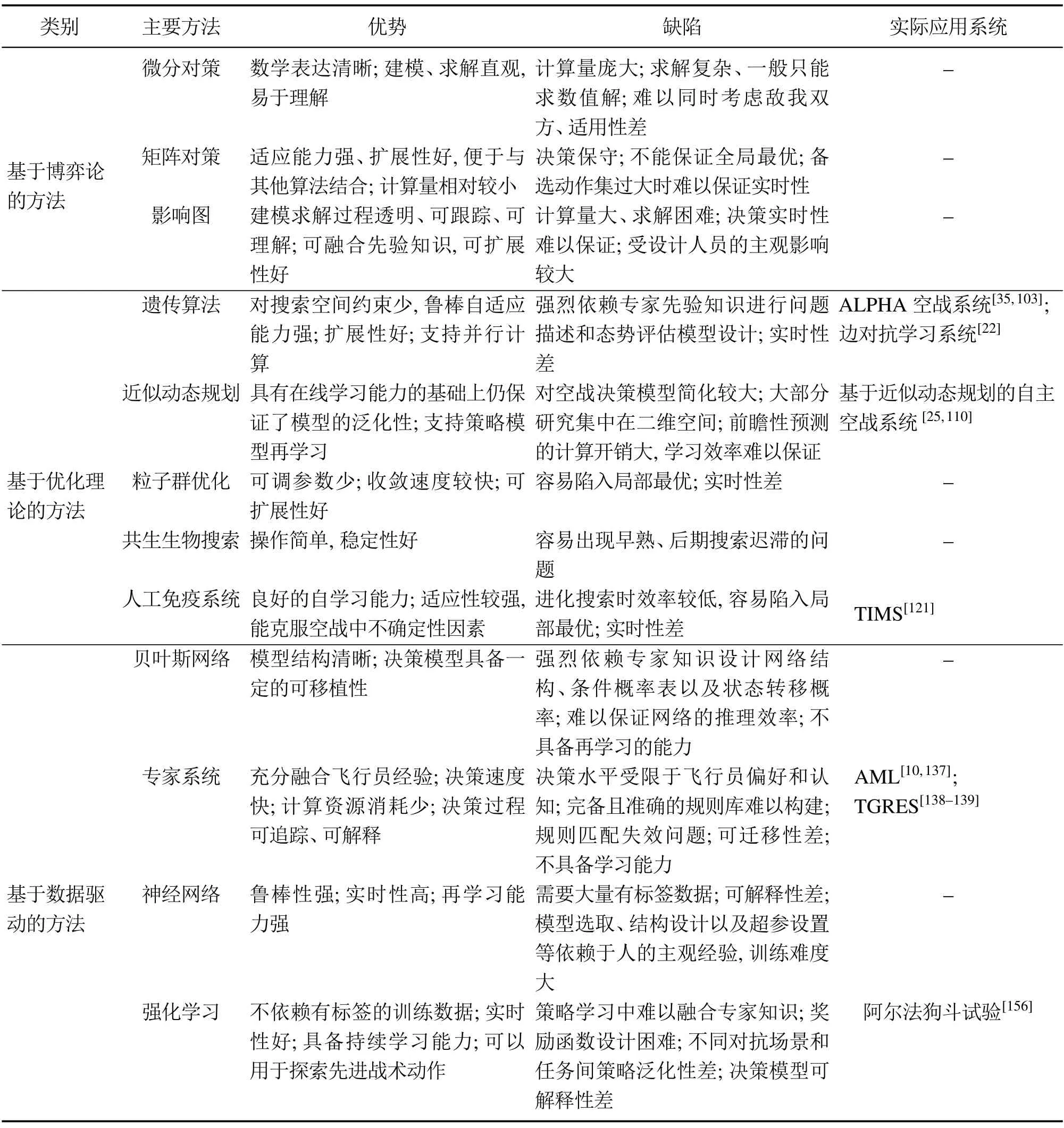
表1 自主空战机动决策方法对比总结Table 1 Comparison of autonomous air combat maneuver decision-making methods
4.1 基于博弈论的方法
基于博弈论的方法主要包括: 基于微分对策的方法、基于矩阵对策的方法和基于影响图的方法等,各类方法的主要研究分支如图7所示.
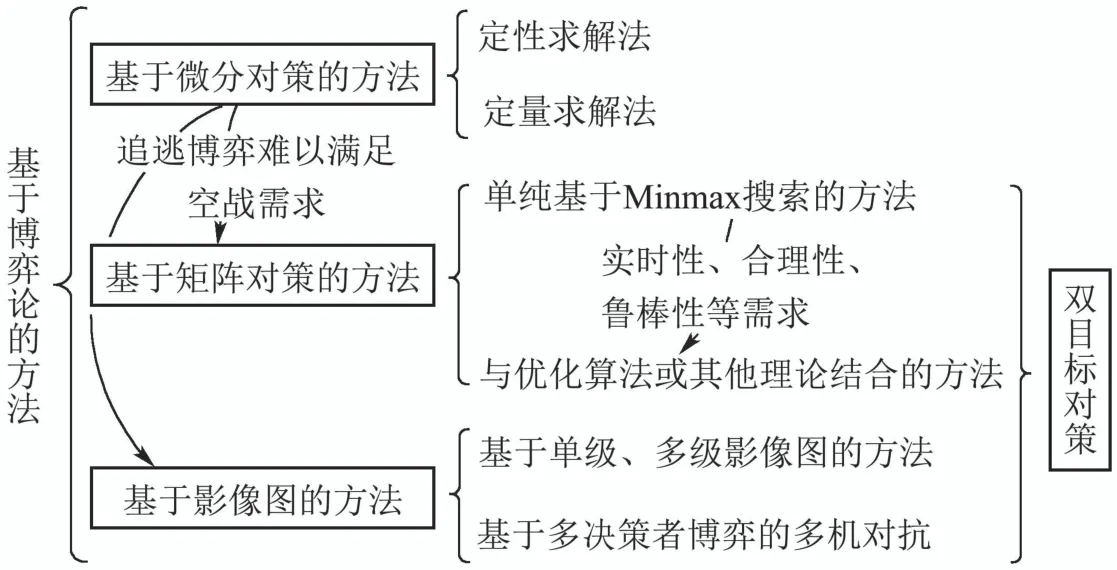
图7 基于博弈论方法的主要研究分支Fig.7 Research branches based on game theory
4.1.1 基于微分对策的方法
微分对策的命名来源于Isaacs对“追逃博弈(pursuit-evasion games)”的研究[55],由于对该类问题的求解基于博弈论框架,且动力学模型由微分方程描述,因此将这类方法称为微分对策或微分博弈.
基于微分对策的机动决策通过建立描述空战双方状态转移和控制规律的微分方程,借助动态博弈理论求解机动策略.该类方法主要针对1v1空战中的追逃问题,借鉴《Differential games》[58]中的Homicidal Chauffeur Game问题,假设空战双方一方扮演追逐者,一方扮演逃逸者,且在对抗过程中角色不发生改变.其求解方式主要是将微分对策问题转化为单边或双边优化问题[59],主要思路有定性求解[60-61]和定量求解[62-63]两种.
定性求解法不需要目标函数,而是将实现某种空战结果作为目标.Getz和Leitman[60]研究了能够保证智能体在定性双目标微分对策中获胜的初始状态集和对应策略的约束条件.Raivio[61]在三维空间内中距空空导弹捕获区的研究中,建立了与原问题等价的角度微分博弈模型,使用定性方法避免了求解原问题复杂的必要条件.
定量求解法构建与具体参数相关的优化目标函数,通过求解目标函数极值获得机动策略.其最初研究主要集中于在二维或三维空间内开展的导弹对飞机追逃对策问题[64-65]和1v1 空战机动决策问题[63].Horie和Conway[59]将战机的追逃机动决策用微分对策建模,并将其转化为双边优化问题,使用与非线性规划相结合的半直接法求数值解.针对空战中传统态势函数分段连续、难以用于微分对策的问题,有研究利用空战中的相对态势要素构建支付函数,并将最优策略求解转化为非线性规划问题,使用半直接法求解对抗策略[66-67].此外,为降低模型的计算复杂度,提高决策效率,还有研究通过预测双方态势信息,将双边极值问题转化为单边极值优化问题,从而满足空战对抗的时性要求[68-69].
总结: 基于微分对策的机动决策优势在于数学描述清晰、建模和求解直观且易于理解,但其缺点也是显而易见的.首先,求解微分对策的计算量庞大,往往只能求得数值解,因此只适用于简单场景;其次,由于其显式或隐式地使用微分或梯度搜索定位解的具体位置,此类方法本质上仍具有局部属性[22];最后,该类方法难以同时考虑敌我双方,仅在空战追逃问题中取得了一些研究成果,与实际空战仍有较大差距,难以应用于复杂空战问题.
4.1.2 基于矩阵对策的方法
随着战斗机和导弹技术的不断发展,以“追逃博弈”为主的微分对策难以满足空战实际的需要,基于双目标对策(two-target game)[70-71]的自主机动决策研究应运而生.基于矩阵对策的方法是双目标对策的一条重要分支.
矩阵对策可以看作微分对策的离散形式,属于静态博弈的范畴.其主要思路是: 首先,选取影响空战决策的指标参数构建态势评价函数.然后,在每个决策时刻遍历所有可用的机动动作,结合态势评价函数构建双方的支付矩阵.最后,根据Minmax原理求解一段时间内的最优机动决策序列.
Austin等人[72]首先将矩阵对策引入空战机动决策中,针对丘陵地区的1v1直升机空战问题,考虑朝向、距离、速度和地形间隙等态势因素构建支付矩阵,并用Minmax搜索求解矩阵对策,结果表明该方法可以做出有经验飞行员才能完成的动作.类似地,车竞等人[73]将战斗机策略分为攻击和逃逸两大类,在基于F-16战机模型的1v1空战中,使用矩阵对策求解机动策略.刘昊天等人[74]构建了多机对抗的支付矩阵,并用对局迭代求解混合策略的纳什均衡.然而上述方法计算量大,当备选机动动作较多时难以满足决策实时性.
为了提高决策实时性和合理性,有研究将矩阵对策与优化算法相结合,将纳什均衡求解问题转化为优化问题,提高了决策效率和智能化程度[75-77].文献[75]使用矩阵对策获取最优策略的大致范围,再用遗传算法(genetic algorithm,GA)[78]求解精确的机动控制.文献[77]将我敌双方的态势优势之差作为支付函数,利用量子粒子群算法求解两机博弈的纳什均衡.
其次,还有研究将美国国家航空航天局(national aeronautics and space administration,NASA)提出的7种基本机动动作进行拓展,设计了基于统计学原理的机动决策方法,以达到精确控制的目的[79-83].文献[79]将基本机动动作扩展至45种,整合矩阵对策与统计学原理筛选出最优机动动作,以提高决策的鲁棒性.文献[80]提出1331种机动策略,利用试探机动[28]的方式进行机动动作选择.然而,动作库扩充带来的直接影响是每次决策时需要遍历的动作数量更多,计算量更大,决策效率更低.
此外,综合考虑空中战场信息的不确定性,还有研究将模糊理论引入矩阵对策的求解过程[28,84-86].文献[85]提出模糊策略子集的概念,并构建了模糊策略下的支付矩阵,使用量子粒子群法求解纳什均衡.文献[86]提出了基于直觉模糊的支付矩阵,并使用改进的差分进化算法求解纳什均衡,有效提升了决策模型的收敛效率.
最后,为了提高构建的支付矩阵的合理性,有研究提出根据空战态势调整各态势评价函数权重的方法,主要包括提前设计[80]和自动调整[28,87-88]两类.
总结: 基于矩阵对策的机动决策优势在于适应能力强、扩展性好,便于与其他理论或算法结合,计算量相对微分对策较小.此类方法的缺陷主要包括以下几个方面: 首先,采用Minimax算法求解纳什均衡,其潜在假设是敌我双方都采用最保守的方式选择机动动作,因此难以应对使用复杂策略的敌机;其次,输出的机动策略只能保证预测的时间段内为最优,不能保证全局最优性,当备选动作集过大或规划周期较长时,难以满足决策实时性;最后,其决策质量依赖于具体的态势评价函数,然而在实际应用中难以构建完备的态势评估模型.
4.1.3 基于影响图的方法
基于影响图的机动决策是双目标对策的另一条研究分支.影响图是由结点集合和弧集合构成的有向无环图,建模求解过程可以融合先验信息,被广泛应用于求解带有不确定性的复杂问题.
Virtanen等人[89]首先将影响图应用于1v1空战机动决策,考虑两机距离、方位角和进入角等信息构建空战态势,基于飞行员的经验给出贝叶斯先验概率,以获取最大效用值为目标求解影响图模型.在此基础上,Virtanen等人[56]将多级影响图引入空战机动决策,以解决双目标对策的问题.为获取最优对抗轨迹,将多级影响图转化为离散时间动态优化问题,并使用非线性规划求解.类似地,Zhong等人[90]用多级影响图描述1v1序贯机动决策,并将其转化为二阶优化问题.
考虑多个决策者参与博弈的多机对抗,文献[91]首次将动态博弈、多级影响图和多决策者模型融合,并使用滚动时域法[92]求解机动策略.同时,有研究将多对多空战转化为多个1v1空战,然后用影响图建模求解1v1空战机动策略[93-94].进一步地,文献[95]在多机对抗中,使用优化算法进行目标动态分配,然后使用影响图模型求解多机对抗策略.文献[96]在1v1空战多级影响图模型的基础上,根据战机空战能力在多机对抗中进行角色划分,并引入协同因子提升机群整体协同能力.
此外,考虑到空战态势的不完全可观测性,文献[97]提出基于状态预测的影响图模型,使用无迹卡尔曼滤波更新信念状态.针对多机对抗问题,还设计了合作控制策略以保证全局效用最优.吴江等人[98]针对影响图描述非对称、不确定性问题的局限性,提出条件弧和决策簇扩展的影响图和基于条件分解的求解方法.针对飞行员确定的先验似然函数差异性大、主观性强等问题,周思羽等人[99]提出基于随机决策准则的多级影响图决策方法,分析了不同决策准则对空战仿真的影响.
总结: 基于影响图的机动决策优势在于将问题结构表示与决策者意见相分离,用图的形式清晰表示出各决策量之间的相互关系,整个建模求解过程透明、可跟踪、可理解[91];影响图模型可以融合飞行员和专家的先验知识,可扩展性好,能够直观表现出评估模型对决策的影响;其用概率模型表示出了空战中存在的不确定性.此类方法的缺陷主要包括以下几个方面: 首先,影响图模型计算量大、求解困难,只能通过滚动时域法等求解一段时间内的近似最优解;其次,巨大的计算量必将导致决策实时性难以保证;此外,影响图模型受设计人员的主观影响较大,飞行员的性格偏好都会影响决策模型的性能.
4.2 基于优化理论的方法
基于优化理论的方法主要包括: 基于GA的方法、基于近似动态规划(adaptive dynamic programming)的方法、基于粒子群优化(particle swarm optimization)算法[100]的方法、基于共生生物搜索(symbiotic organisms search)算法[101]的方法和基于人工免疫系统(artificial immune system)[102]的方法等,各类方法的主要研究分支如图8所示.
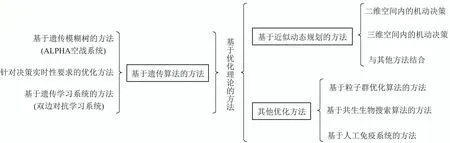
图8 基于优化理论方法的主要研究分支Fig.8 Research branches based on optimization theory
4.2.1 基于遗传算法的方法
GA是最成熟的优化算法之一,其适应能力强、对解空间的要求较少,被广泛应用于空战机动决策的研究中.
GA在机动决策中最成功的应用案例应属2016年辛辛那提大学与AFRL共同开发的“ALPHA”超视距空战机动决策系统[35,103].“ALPHA”空战系统将GA与多个模糊交互系统相结合,构成遗传模糊树.通过将复杂决策任务分解,从而压缩解空间,使用分布式计算保证决策效率.另外,遗传模糊树具有设计灵活、易于扩展的优点,便于与其他算法或先验知识相结合.该系统在基于“先进仿真、集成、建模框架”[104]的超视距空战仿真环境中战胜了经验丰富的退役空军上校Gene Lee.“ALPHA”的成功标志着人工智能技术在空战机动决策领域具备了战胜人类飞行员的能力.
针对基于GA的机动决策模型寻优时间长、实时性差的问题,已有学者开展了广泛研究[26,105].文献[26]在态势到机动动作映射数据的基础上,构建了模糊树决策模型,并使用GA 求解,提高了决策的实时性.张涛等人[105]考虑多种态势因素构建优化目标,将战机控制量离散化并进行实数编码,采用滚动时域控制的思想[92],使用伪并行GA进行机动决策,提高了算法收敛速度的同时抑制了“早熟”现象.还有研究用GA离线优化机动决策专家系统树,有效提高了决策模型的适应性[106].
GA的另一个成功应用为波音公司和西英格兰大学开发的双边对抗学习系统[22],其由遗传学习系统[107-108]扩展而来.针对配备有推力矢量(thrust vectoring)发动机的先进战斗机(以X-31战斗机为例),双边对抗学习系统期望通过自主训练的方式,充分利用X-31战机的过失速能力,探索大攻角空战战术或超机动动作.另一方面,发现的新机动动作又可以指导新型战机的分析和设计.该系统的目标是学习适用于整个状态空间且具有泛化性的模型参数.因此,严格意义上来讲,双边对抗学习系统应归属于基于数据驱动的学习类方法.然而,该模型的学习泛化能力与深度学习相比仍存在较大差距.类似地,谢建峰等人[109]将强化学习(reinforcement learning,RL)引入GA,将整个决策模型分为分类器子系统和规则发现子系统,而不构建显式的目标函数.分类器子系统负责与环境交互并分配奖励,而规则发现子系统负责使用GA产生新规则.然而,该研究没有给出分类器具体的形式化建模方法和更新机制.
总结: 基于GA的机动决策优势在于GA对搜索空间约束少,鲁棒自适应能力强;扩展性好,易于与其他算法结合,且支持并行计算.此类方法的缺陷主要包括以下几个方面: 首先,强烈依赖专家先验知识进行问题描述和态势评估模型设计,而空战环境复杂多变,态势评估模型的完备性和准确性难以保证[33];其次,对于每个态势输入都需要在解空间内寻优,实时性差.
4.2.2 基于近似动态规划的方法
近似动态规划克服了动态规划应用于具有高维离散或连续状态空间任务时出现的“维度灾难”问题,其核心是基于函数拟合的思想,以连续函数估计真实的效用值函数.
最早且最具代表性的工作要属2008 年McGrew[25,110]将近似动态规划用于1v1空战机动决策问题.该研究构建了包括两机相对位置、绝对坐标、目标进入角在内的30维态势特征描述集合,并将状态空间离散化为105个状态.最终在两机速度不变的二维水平空间内进行了仿真和实物验证,结果表明该方法在不借助专家知识的前提下可以学习到合理的机动策略,并能够保证决策实时性要求.类似地,文献[111]将近似动态规划用于二维空间的1v1空战机动决策,并从双机使用Minmax策略对抗时产生的历史轨迹中采样,避免了对巨大状态空间的探索,加速了策略收敛.但以上研究均假设战斗机的动作空间仅包括左转、右转和保持,与实际差距较大.
Hu等人[112]将此类方法扩展至三维空间,将可用动作空间扩展为NASA提出的7种基本机动动作,并给出了敌机直线飞行或使用近似动态规划方法决策时两机的对抗轨迹,但其对抗模型较为简单.徐安等人[113]在空战飞行器隐蔽接敌任务中提出了优势区和暴露区的概念,并给出了基于近似动态规划的策略学习与策略提取方法.更进一步地,文献[114]考虑空战对抗过程中的过冲和碰撞问题,通过引入风险概率调整长期收益值函数对文献[113]中的方法进行了改进.
此外,还有研究将近似动态规划与其他方法结合用于空战机动决策.黄长强等人[88]采用近似动态规划的思想对空战过程按时域进行划分,并在此基础上将人工势场法引入蚁狮优化算法,在每个分规划阶段求解最优机动策略.梅丹等人[115]将近似动态规划与微分对策相结合,分析了博弈双方的均衡策略,并给出了策略迭代求解方法.该研究在二维对抗环境中验证了算法的可行性,但是存在学习周期长、仅适用于简单机动的问题.
总结: 相比于其他方法,基于近似动态规划的机动决策研究相对较少,且基本在McGrew[25,110]工作的基础上仅根据任务需求进行了少量改进.此类方法的优势在于: 具备在线学习能力的基础上仍保证了模型的泛化性能;其通过在历史对抗数据中采样进行效用值函数更新,因此,可以由已有策略模型或专家系统生成对抗轨迹,从而实现在已有策略模型基础上再学习.此类方法的缺陷主要包括以下几个方面: 首先,对空战决策模型的状态空间和动作空间进行了较大简化,大部分研究都集中在二维空间内,若将其扩展至三维场景,采样状态选取、策略学习和策略提取方法需要在保证可接受的时间开销下重新设计优化;其次,在策略提取时需要通过Rollout[116]的方式进行前瞻性预测,预测步数增加虽然提高了决策准确率,但带来了巨大的计算量,从而影响了决策实时性;此外,许多实现细节针对具体任务进行设计,方法的可迁移性和泛化性仍需要进一步研究.
4.2.3 其他优化方法
粒子群优化算法是一种模拟鸟类觅食行为的随机搜索算法,在空战决策中,一般将粒子群优化算法与其他方法相结合求解机动策略.陈侠等人[84]以导弹发射的价值为依据,建立了多机对抗矩阵对策模型,并将粒子群优化算法和区间数多属性方案排序法相结合求解纳什均衡.文献[117]基于战斗机的能力构建人工势场函数,并将其引入粒子群优化算法的指标函数.当我机不在敌机人工势场范围内时,依靠人工势场法确定机动策略;当我机处于敌方人工势场范围时,首先由人工势场法确定机动方向,然后由粒子群算法求解准确的最优机动策略.通过这种方式,改善了基础算法的全局搜索能力,提高了计算效率.此外,文献[27]将改进的混合粒子群优化算法引入多机对抗的目标分配问题,将多对多空战转化为多个1v1对抗,避免了传统粒子群优化算法易陷入局部最优的问题.在此基础上,使用RL 算法求解1v1机动决策策略.粒子群优化算法可调参数少,收敛速度较快,可扩展性好,但容易陷入局部最优.同时,面对高维、连续的空战状态空间,此类方法同样存在搜索时间长、决策难以满足空战实时性要求的问题.
共生生物搜索算法通过互利共生、共栖以及寄生3种算子模拟生物种群间的交互关系,从而使种群不断进化,逼近最优解.高阳阳等人[118]将机动决策问题转化为多目标优化问题,针对原有算法收敛精度低和易陷入局部最优的缺陷,在寄生操作时,使用基于适应度的动态变异率代替固定变异率.同时,利用梯度思想引导生物体变异,进一步提高了算法效率.韩瑾等人[119]将空战机动决策问题转化为鲁棒多目标优化问题,为提升运算效率和决策的完备性,使用基于自适应和精英反向学习策略改进的共生生物算法求解机动决策的控制量.类似地,文献[120]基于可达集理论,通过遍历所有可选动作预测敌机状态.在此基础上,使用共生生物搜索算法求解机动决策控制量.共生生物搜索算法操作简单,稳定性好,在收敛速度和精度上优于传统优化算法,但在处理高维非线性复杂优化问题时容易出现早熟、后期搜索迟滞的问题.
人工免疫系统模拟生物免疫系统中抗原和抗体的关系,其可以看作一个能够处理各种扰动和不确定性的鲁棒自适应系统.Kaneshige 和Krishnakumar[121]首先将人工免疫系统方法引入空战机动决策,提出战术免疫机动系统(tactical immunized maneuvering system,TIMS).TIMS以敌机的位置和速度等信息作为抗原,基本机动动作作为抗体,使用遗传和进化算法模拟生物免疫系统的自适应能力.为了提高在线决策的实时性,TIMS借鉴生物免疫系统中记忆细胞的作用,维护了一个存放以往成功经验(动作序列)的数据库,并根据问题-解的映射关系进行管理.当遇到与以往经历类似的态势时,可以迅速做出反应.此外,借鉴生物免疫系统中疫苗和机体的关系,TIMS还支持利用训练集离线学习对抗策略.针对TIMS容易陷入局部最优和收敛性不稳定的问题,文献[122]将序列关联数据挖掘引入TIMS,当TIMS在有限的时间内不能收敛至稳定解时,由数据挖掘算法提供机动策略,从而提高了系统决策效率和适用性.针对TIMS在免疫搜索进化时效率较低的问题,嵇慧明等人[12]将空战态势特征离散化处理并用二进制编码,融合改进的天牛须搜索算法和TIMS模型,有效提高了算法的收敛精度、收敛速度和全局搜索能力.此外,针对传统人工免疫算法难以保持种群多样性,容易产生早熟收敛的问题,文献[123]提出一种并行人工免疫算法,设计了新的移民算子用于提高种群多样性和搜索效率,并将提出的算法用于多机协同目标分配.基于TIMS的空战机动决策方法具有良好的自学习能力和实时性,能较好地克服空战中不确定性因素的影响.其次,此类方法还具有一定的持续学习能力,适应性较强.此类方法的缺陷主要在于进化搜索时效率较低,容易陷入局部最优.
除以上具有代表性的研究之外,应用于空战决策的优化算法还包括: 差分进化算法[124]、蚁群算法[125]、一致性拍卖算法[126]、狼群算法[127]等.
4.3 基于数据驱动的方法
基于数据驱动的方法主要包括: 基于贝叶斯网络的方法、基于专家系统的方法、基于神经网络的方法和基于RL的方法等,各类方法的主要研究分支如图9所示.

图9 基于数据驱动方法的主要研究分支Fig.9 Research branches based on data-driven methods
4.3.1 基于贝叶斯网络的方法
贝叶斯网络形式上与影响图结构类似,同样将空战机动决策过程用有向无环图描述.贝叶斯网络中的节点代表影响决策的态势要素,而有向弧代表节点间的依赖关系.
文献[128]基于超视距空战中典型的战术,梳理了以态势评估结果为前件,典型战术动作为后件的推理规则,并基于此构建了贝叶斯网络.陈军等人[129]提出结合粗糙集的贝叶斯网络,利用粗糙集压缩专家知识和态势信息,降低了网络复杂度,提高了决策效率.耿文学等人[130]考虑空战环境的不确定性,将连续型节点变量模糊化处理,提出基于模糊贝叶斯网络的机动决策模型.还有研究将产生式规则与贝叶斯网络相结合,综合考虑目标威胁和打击效果进行决策[131].
在此基础上,考虑空战中时间变化的动态特性,有研究将动态贝叶斯网络引入机动决策[132-133],并使用滤波推理算法求解网络模型.文献[132]抽取空战仿真数据中积累的信息和依赖关系,构建了动态贝叶斯网络决策模型及其先验概率表,并将构建的决策模型用于研究给定不同事件时的策略输出.
上述大部分研究仅含糊地指出条件概率表和状态转移概率根据先验知识设计,而没有给出具体的设计方法.为缓解人的主观偏好对决策模型的影响,有学者针对贝叶斯网络参数优化展开研究[134-135].文献[134]提出在先验知识和客观数据的基础上进行参数优化,在样本数据不足时,主要考虑先验概率分布,随着样本积累,采用贝叶斯估计理论优化网络参数,以提高机动决策性能.文献[135]采用期望最大参数学习法优化动态贝叶斯网络参数,有效提高了双机协同空战的效率.
总结: 基于贝叶斯网络的机动决策优势在于其模型结构清晰,能够反映出飞行员在决策时的思维过程.网络由影响决策模型对抗性能的关键要素构成,可通过分析敌我对抗数据并结合专家经验总结获得;决策过程不用过多考虑飞机的动力学和运动学模型,因此,决策模型具备一定的可移植性.此类方法的缺陷主要包括以下几个方面: 首先,网络结构、条件概率表以及状态转移概率的设计强烈依赖于飞行员或专家的先验知识,其对最终决策模型的性能起决定性作用,同时,网络参数优化需要大量样本数据支撑;其次,当网络中的态势信息节点过多时,将难以保证网络的推理效率;此外,贝叶斯网络本质上是对先验知识和客观数据规律的拟合,不具备再学习的能力,不能创造出新的战术战法.
4.3.2 基于专家系统的方法
专家系统是指利用专业知识和推理过程,模仿领域内专家解决复杂问题的计算机程序[136],其主要由规则库、数据库、推理机和人机交互接口等部分构成.基于专家系统的机动决策是研究最早,可靠度和成熟度最高的方法之一.
20世纪60~70年代,NASA就针对F-4战斗机着手构建了基于飞行员经验和专家知识的自适应机动逻辑(adaptive maneuvering logic,AML)[10,137]专家系统,用于视距内双机空战.专家经验和偏好以硬编码的形式存储于机动决策系统中,提取的产生式规则以IF-THEN的形式表示.AML系统有在线和离线两种工作模式,在线仿真模式为飞行员提供了战术机动训练平台,而离线模式可以用于战斗机与武器系统的组合研究及评估.
现代空战环境复杂程度的不断提高和先进高性能战斗机的出现对专家系统提出了新的要求.20世纪90年代,NASA公布了战术引导研究与评估系统(tactical guidance research and evaluation system,TGRES)[138-139],其战术决策生成器PALADIN系统[140]可以看作AML系统的升级版本.二者的工作原理都是首先预测一定时间段内敌机的运动轨迹,并根据系统预置的专家规则,遍历我方可用机动动作,然后评估对应的态势优劣,最后选择态势最优对应的机动动作执行,或将机动指令转化为升降舵、方向舵和副翼偏转的控制量.
由机动动作构成的数据库和飞行员经验构成的规则库是专家系统的核心.对于复杂系统来说,构建准确、完备的规则库十分困难.例如,随着空战规模的扩展和战机性能的提升,构成规则前件的态势要素必然会更为复杂,此时不仅难以将专家知识提炼为结构化的规则,而且态势要素间复杂的关联关系容易造成“维度灾难”.同时,不完备的规则库将会导致专家系统在非预期态势输入下失效.
已有学者将专家系统与其他方法结合,以克服规则前件无法匹配时专家系统失效的问题.一种思路是当专家系统失效时用其他决策方法作为补充.王志刚等人[141]将试探机动和专家系统结合,在非预期情况下结合态势优势函数,遍历试探机动集获得最优动作.Geng等人[142]将专家系统与模糊贝叶斯网络结合,当输入信息不完全或不准确时,调用模糊贝叶斯网络模块决策,否则使用专家系统决策.傅莉等人[143]建立了与机动决策专家系统对应的最优控制模型,当专家系统失效时,采用滚动时域的思想求解最优控制模型,代替专家系统决策,从而提高了整个系统的适应性.
另一种思路是融合专家系统与其他优化算法共同决策.王炫等人[106]将专家系统与GA结合,提出了进化式专家系统树决策模型.离线阶段根据在线应用评价结果,采用GA对专家系统的规则库进行优化.该决策系统的输出为机动指令而非原子机动动作或各舵面的控制量,且仅在二维简单任务中进行了验证.谭目来等人[124]针对逃逸机动问题,将模糊专家系统与改进差分进化算法相结合,采用改进的差分进化算法结合态势优势函数在可行域内求解具体控制量的输出.
总结: 基于专家系统的机动决策优势在于决策模型充分考虑了飞行员经验和空战专家理论知识,决策速度快,计算资源消耗少;其决策过程具有全程可追踪和可解释性.此类方法的缺陷主要包括以下几个方面: 首先,专家系统的性能依赖于规则的准确性,决策水平受限于飞行员偏好和认知;其次,随着空战复杂程度的提升,构建完备且准确的规则库将十分困难,这不仅需要从大量知识和对局数据中提炼结构化的规则,还要选取合理的态势要素构成规则前件,并避免出现“维度灾难”问题;此外,不完备的规则库带来的直接影响就是规则匹配失效的问题;最后,专家系统一般针对某一具体机型设计,不易修改,可迁移性差,且不具备通过对局数据更新优化决策模型的能力.
4.3.3 基于神经网络的方法
基于神经网络的方法在泛化性上可以看作是基于专家系统方法的进一步扩展,其有效解决了专家系统在非预期输入时决策失效的问题.
机动决策问题中,一类神经网络模型以空战战术或宏动作作为模型输出.文献[144]提出以12维空战态势特征为输入、17种典型机动动作执行概率为输出的神经网络拟合AML的决策逻辑,提升了系统泛化能力的同时,弱化其人为设计的属性.此外,该研究也提出了直接从仿真数据出发构建神经网络决策模型的方法.李锋等人[145]设计了15种空战战术,并以此为基础设计了以目标进入角、目标方位角和高度差为输入、具体战术执行概率为输出的模糊神经网络用于超视距空战机动决策.Teng等人[146]将自组织神经网络引入空战机动决策,并提出从规则中自动抽取状态空间和动作空间的方法,最终抽取15维属性信息构建态势输入并设计了13种攻防策略.借助自适应共振理论和RL方法,该模型的学习能力和泛化性能可实现迭代提升.
另一类网络模型以基本机动动作或具体控制量作为输出.文献[147]提出以目标方位角、进入角、目标距离、敌我速度差、敌我高度差等为态势输入、17个基本机动动作为输出的神经网络决策模型,并用专家系统生成学习案例训练该网络.但该研究仅简述了实施方案,没有给出具体的实现过程.张宏鹏等人[148]设计了36种基本机动动作用于离线训练以当前态势和控制量为输入,未来态势为输出的神经网络预测模型.在线阶段,根据当前态势遍历所有可用动作,结合决策目标函数选取最优动作执行.张菁等人[149]将深度神经网络与人工势场法相结合,针对超视距空战中的协同博弈问题,构建了以敌我双方位置、航线信息以及友方位置信息作为输入,人工势场函数系数为输出的神经网络模型.使用基于GA和滚动时域控制的思想生成训练样本,在2v1空战环境下验证了算法的可行性.此外,也有研究利用卷积神经网络特征提取和泛化能力强[150]、循环神经网络处理时序相关性数据的优势[151-152],将其与其他方法融合用于空战机动决策.
总结: 基于神经网络的机动决策优势在于其鲁棒性强,自适应能力相较于专家系统有明显提升,能够根据以往经验在未经历的态势输入下做出合理决策;此类方法的实时性高,在线应用时不需要遍历解空间也不需要在规则库中进行匹配;神经网络再学习能力强,可以根据提供的数据不断优化策略模型.此类方法的缺陷主要包括以下几个方面: 首先,合理的决策模型需要使用大量的有标签数据进行训练,现阶段在空战领域获取高质量的机动决策数据仍非常困难;其次,基于神经网络的决策模型是一个“黑箱”,可解释性差,难以与可解释的人类知识融合;此外,神经网络的模型选取、结构设计以及超参设置等依赖于具体任务类型和研究人员的主观经验,模型训练难度大.
4.3.4 基于强化学习的方法
近年来,RL在自主空战机动决策中的应用得到了国内外学者的广泛关注,特别是DRL技术在围棋[153]、星际争霸II[154]和DOTA 2[155]等即时战略游戏中取得开创性成果后,基于DRL的空战机动决策也取得了突破性进展.
2020年8月,在ACE项目开展的1v1“阿尔法狗斗试验”(AlphaDogfight trails)中,如图10所示,基于DRL的Falco算法(冠军)和PHANG-MAN算法(亚军)操作模拟的F-16战斗机均以5:0的压倒性优势在1v1视距内空战中完胜人类飞行员[156].两算法都能抓住人类飞行员的失误,从正面或侧面发起进攻.PHANG-MAN在训练中更注重长远的位置收益而非瞬时奖励,没有考虑对手生命值对我机策略的影响,并且更倾向于保护自身安全.相比于PHANG-MAN,Falco的策略则更加激进,能在正面交锋中险胜.由此也可以看出,奖励函数设计对于基于DRL的对抗策略学习至关重要.
2020年11月,DARPA宣布进一步深入研究,以将基于DRL的机动决策算法扩展至2v1和2v2近距空战机动决策中,并计划于2024年移植到真实作战飞机上[157].至2023年2月,ACE项目中的智能算法已可以控制全尺寸的F-16战斗机.
目前RL在空战机动决策中的研究可以大致分为:基于值函数的方法、基于确定性策略梯度的方法、基于随机性策略梯度的方法等.现有研究中对抗规模主要以1v1为主,大多数多机对抗一般通过目标分配等方法转化为局部双机对抗[158].
1)基于值函数的方法
基于值函数的方法主要适用于离散动作空间的任务,战机的动作空间一般为基本机动动作或战术动作.对于此类方法的研究最多,主要集中在将Q-learning[159]、深度Q 网络(deep Q-learning network,DQN)[160]及其变种算法与态势优势/威胁评估函数相结合,用于解决空战机动决策问题.
由于Q-learning基于Q表中的值函数做决策,只适用于具有离散状态空间的任务.为将其应用于高维连续的空战环境,有学者对给定态势下Q值函数估计问题展开研究.文献[161]将自适应共振理论引入RL,以实现自适应的状态空间分割,免去了手动设计近似函数的问题.Xu等人[162]为了缓解连续状态空间离散化导致的“维度灾难”问题,将模糊理论引入状态空间和奖励函数构建,并使用Nash-Q 算法[163]求解机动策略.而更为常见的是以神经网络作为函数估计器,例如,有研究利用径向基神经网络可并行、容错及函数逼近能力强等优势[164],将其引入Q-learning,用于估计我机的动作值函数[31,165-167].然而,径向基神经网络设计及参数训练较为复杂,不仅需要训练样本确定高斯核函数的中心和宽度,还需要通过RL更新网络权值.此外,还有研究使用概率神经网络预测敌机动作执行概率,并将其引入Q-learning从而辅助对抗策略学习[168].受限于模型的表达能力,基于Q-learning的方法仅适用于简单对抗场景.
基于深度神经网络的DQN实现了对空战机动决策状态空间的高效抽象和拟合.文献[169]设计了基于DQN的人机交互空战系统,包括: 空战仿真环境子系统,用于人机交互和态势评估;战机操作子系统,用于控制仿真环境中的战机;UAV自学习子系统使用DQN学习空战对抗策略.为进一步缓解状态空间巨大对算法收敛性的影响,潘耀宗等人[170]针对战机向攻击区域自主机动的问题,以战机与目标的距离和当前速度与目标区域的夹角为切入点,分别构建DQN网络学习机动策略.同时,基于DQN的方法在空战环境中普遍存在易陷入局部最优的问题.为了缓解该问题,有研究采用分段训练的思想,由易到难学习对抗策略[38,171-173].例如,Yang等人[38]将学习分为两个阶段,第1阶段对手仅使用简单的平飞或盘旋机动,而第2阶段对手采用基于规则的策略.文献[173]提出交替冻结自博弈方法,通过交替冻结一方的策略,并从零训练另一方,从而实现对抗策略不断优化,有效避免了“红皇后”效应.
为进一步提升基于DQN决策模型的鲁棒性,有学者与其他技术结合开展了相关研究.Xu等人[174]将深度信念网络(deep belief network,DBN)引入空战机动决策,在离线训练阶段,用GA 产生状态-动作行为对训练DBN,学习空空对抗规则.在线交互阶段,基于DBN和Q-learning选择机动动作并执行.胡东愿等人[175]考虑空战的序贯决策属性,将长短期记忆网络引入Dueling-DQN[176],以连续4个时刻的态势序列作为网络输入,在1v1环境中验证了算法的有效性.
此外,面向特定的敌机策略类型,有研究将DQN与博弈论相结合以获得有针对性的对抗策略.文献[177]将纳什均衡引入基于DQN的双机对抗,构建基于敌我双方动作的值函数网络,提出了ϵ-纳什均衡动作选择策略.该方法可以看作基于神经网络的Nash-Q算法[163].类似地,文献[178-179]将双机对抗问题建模为零和博弈,以神经网络作为Minimax-Q[180]的联合动作值函数估计器,提出Minimax-DQN算法,并分别在二维追逃环境和三维对抗环境中验证了算法的可行性.然而,此类方法的隐含假设是敌机总是遵循纳什均衡选择机动动作,因此学习到的对抗策略保守甚至非最优.孔维仁等人[181]在二维空间内探索了将参数共享、虚拟自博弈等技术与DQN融合,并用自编码器对状态空间进行降维,从而实现规模可变的同构多机对抗.
2)基于确定性策略梯度的方法.
相比基于值函数的方法,基于确定性策略梯度的方法一般用于具有连续动作空间的任务,战机的动作空间一般为各舵面或各角度控制量及发动机推力或油门等.此类研究主要集中在深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法[182]及其变种算法的应用.殷宇维等人[183]采用基于卷积神经网络的DDPG,以5个连续时刻的态势信息作为网络输入,结合优先采样机制加速策略学习.该研究在二维的MaCA 平台[184]进行了验证分析,但是仅列出了胜率曲线对比,没有给出具体的对抗轨迹.
为缓解DDPG 值函数过估计对机动决策模型性能稳定性及收敛速度的影响,有学者采用DDPG与Double DQN[159]相结合的双延迟确定性策略梯度(twin delayed deep deterministic policy gradient,TD3)算法训练机动决策模型.文献[185]为TD3设计了成功和失败两个经验回放区,网络更新时以一定比例分别从两经验区中采样,一定程度上提高了样本利用效率.然而,该算法仅在二维环境中进行了简单验证,且从实验结果来看,相比于TD3算法,其胜率提升并不明显.周攀等人[40]以迎角、滚转角和油门作为连续控制量,设计了态势优势函数作为实时奖励,并将TD3用于视距内空战机动决策.该研究称其在人机对抗仿真平台中战胜了空战专家系统和人类飞行员.
由于取消了离散动作空间的限制,此类方法中的战机模型比基于值函数类方法更加准确,空战仿真更加贴合实战.例如,单圣哲等人[186]选取法向过载、推力和速度滚转角作为连续控制量,建立了基于四元数的战机动力学模型,有效避免了用欧拉角描述战机姿态时的“万向锁”问题.基于此,该研究对比了DDPG、TD3和软执行器-评价器(soft actorcritic,SAC)[187]3种算法在1v1近距空战中的性能.还有研究探索将DDPG在MAS中的扩展算法MADDPG[188]用于多机空战机动决策[42,189].目前此类研究对空战环境进行了较大简化,实验验证相对简单.
3)基于不确定性策略梯度的方法.
基于不确定性策略梯度类方法的适用性更强,其可用于具有离散和连续动作空间的空战机动决策任务,且训练过程相对稳定.该类研究主要集中在近端策略优化(proximal policy optimization,PPO)算法[190]及其变种算法的应用.施伟等人[191]将PPO应用于多机对抗,在“集中训练,分布执行”框架下整合了自适应权重优先采样和经验共享等机制,并在墨子平台[192]验证了算法的有效性.该研究中战机的动作空间为设定的航向、速度、高度等宏动作指令,而非原子机动动作或舵面控制量.Piao等人[193]设计了14种典型机动动作并将PPO用于超视距空战,并提出基于关键事件的奖励塑形机制用于缓解训练初期冷启动的问题[194].然后,在完全可观测的WUKONG空战环境[195]中验证了算法的有效性.结果表明该方法不依赖专家指导,仅通过自博弈可以学习到有价值的空战战术行为,并具备持续进化能力.为聚合复杂空战态势,压缩状态空间,从而进一步提升学习效率和稳定性,唐文泉等人[196]将注意力机制[197]引入PPO,构建了基于敌机威胁的注意力模型用于综合考虑多架敌机的影响.该方法虽然针对2v2环境进行研究,但决策时没有考虑友方的影响,且实验验证中蓝方策略为简单的直行或转弯机动.
为缓解空战中动作空间大、难以收敛的问题,有学者提出将知识模型引入基于PPO的决策模型学习过程.文献[198]将Options理论[199]引入PPO并应用于超视距空战,提出基于Options的近端策略分层优化算法.其中,每个Option为提前设计的基本机动动作或组合的复杂动作,从而一定程度上避免了盲目搜索,提高了学习效率.另外,Zhou等人[200]模仿人类大脑决策过程,将知识分为短期记忆和长期记忆两类,二者有相同的网络结构,而每种记忆由宣言式知识(可解释的知识)网络和程序化知识(基于直觉的知识)网络构成,其分别对应于PPO中的值函数网络和策略网络.该研究称长短期记忆的联合使用可以保证策略的稳定性,避免了低概率事件导致知识突变.究其本质,该算法与分布式PPO[201]的整个学习框架较为相似.另一方面,若采用分布式DRL的架构,基于PPO的方法在训练时可以有效提高样本利用效率,从而加快策略收敛速度.
总结: 基于RL的机动决策优势在于其不依赖有标签的训练数据,通过与环境充分交互收集在线数据并不断优化对抗策略;此类方法具备持续学习能力,例如,可以借助自博弈技术实现对抗策略的迭代提升;借助策略蒸馏技术[202]实现多决策模型的知识提炼.总的来说,基于RL机动决策的研究仍处于起步阶段,还有许多问题需要攻克.首先,大量试错交互带来的一个问题是需要处理“探索”与“利用”的均衡,而如何在学习过程中有效融合战法战例、专家知识等加速策略学习仍是一个难点;其次,奖励函数设计对于策略学习至关重要,目前仍没有统一设计规律可遵循;此外,RL的策略一般针对某具体任务,不同应用场景和任务间的策略泛化性差,目前对于如何在新任务中合理利用已有对抗策略的研究较少;最后,与基于神经网络的方法类似,决策模型可解释性差仍是制约其应用于军事领域的关键问题.
5 典型场景下性能对比分析
为对比第4节中不同类方法的特点和性能差异,本节分别从基于博弈论的方法、基于优化理论的方法和基于数据驱动的方法中选取矩阵对策、基于扩展学习规则系统的启发加速马尔科夫博弈(heuristic accelerated Markov games with XCS,HAMXCS)算法[203]、DQN[160]和PPO[190]作为典型代表,对比4种算法在1v1典型空战任务中的性能表现,其中HAMXCS隶属于基于遗传学习系统的方法,DQN和PPO隶属于基于RL的方法.
5.1 对抗环境设置
考虑以近距空空导弹为机载武器的1v1空战机动决策问题.战斗机采用伪六自由度模型[204-205],并被限定在200 km×200 km×20 km的三维空间内.参考已有研究[12,118],本实验假设搭载某型近距空空导弹的战斗机参数如表2所示.空空导弹相关参数构成的不可逃逸区如图11所示.战斗机的动作空间为前述7种基本战机机动动作.

表2 以近距空空导弹为机载武器的战机参数设置Table 2 Parameter settings of the fighter using short-range air-to-air missiles

图11 近距空空导弹不可逃逸区示意图Fig.11 Diagram of non-escape zone for short-range air-to-air missiles
本实验中,敌我双方的初始位置坐标为:[95 km,100 km,5 km],[110 km,100 km,5 km],双方初始速度为200 m/s,初始速度滚转角和航迹倾斜角都为0°,敌机航迹偏转角为0°,我机航迹偏转角为180°,此时两机相向飞行.在该初始态势下,敌我双方处于均势.当一方获得开火机会,一方超出约定的三维空间,一方失速(<80 m/s)或超速(>400m/s),超过允许最大高度(18 km)或小于最低高度(0.2 km),到达最大时间约束(500个时间步)时,回合结束,并根据上述约束判断战机是否存活,而后两机位置和姿态角重置.综合考虑近距空空导弹的不可逃逸区和敌我双方的态势关系,以我机为例,若相对态势满足qr<30°,qb>120°,β<45°,1.5 km<d<4.0 km,则我机获得开火机会,其中:qr为目标方位角;qb为目标航向角;β为两机速度夹角;d为两机距离.
5.2 实验设计
选取qr,qb,β,d,vR,Δv,hR,Δh构成相对态势要素,其中:vR为我机速度;Δv为我敌双方速度差;hR为我机高度;Δh为我敌高度差.HAMXCS需对上述态势信息进行离散化和二进制编码,qr和qb的编码由3位二进制数表示,其余态势信息由2 位二进制数表示,具体实现细节此处不再展开.将相对态势信息离散化和编码后,状态信息由18位二进制数组成.DQN和PPO在上述8种态势要素的基础上进一步扩展,采用11维相对态势[206]作为状态输入.各代表算法的决策过程如图12所示.
参考已有以空空导弹为机载武器的战斗机空战态势评估方法[12,207],引入角度、距离、速度和高度等态势优势函数并构成合成态势优势fsit=ωafa+ωdfd+ωvfv+ωhfh,其中fa,fv,fh分别为文献[207]中的角度优势、速度优势和高度优势,fd为文献[12]中的距离优势,ωa,ωd,ωv和ωh分别为角度优势、距离优势、速度优势和高度优势的权重.本实验中,ωa=ωd=ωv=ωh=0.25.与各算法对抗过程中,敌机始终以获取最大合成态势优势为目标选择动作执行.若没有动作能使得当前态势优势得到提升,则随机选择机动动作执行.
对于矩阵对策模型,态势评价同样采用上述态势优势函数.对于具有学习演化能力的算法HAMXCS,DQN和PPO,为缓解对抗环境奖励稀疏的影响,训练过程中奖励函数由环境奖励和上述态势优势奖励两部分组成.我机获得开火机会时获得正向奖励,我机失速或超速、超出高度约束、敌机获得开火机会时从环境中获得惩罚,且回合结束.使用上述算法的决策模型在本环境中共训练50万回合.
决策模型在线应用阶段,各类决策模型分别与前述敌机对抗100回合,并评估在线性能.为了进行统计意义上的结果分析,此阶段进行30次重复实验.
5.3 结果对比分析
选取模型学习耗时、模型在线应用阶段敌我开火率、存活率、单次对局所需步数、单次决策耗时为性能指标,对比各类方法的特点和性能差异,具体实验统计结果如表3 所示,决策模型应用阶段统计30次重复实验后各指标的均值和标准差,最优数据以粗体显示.
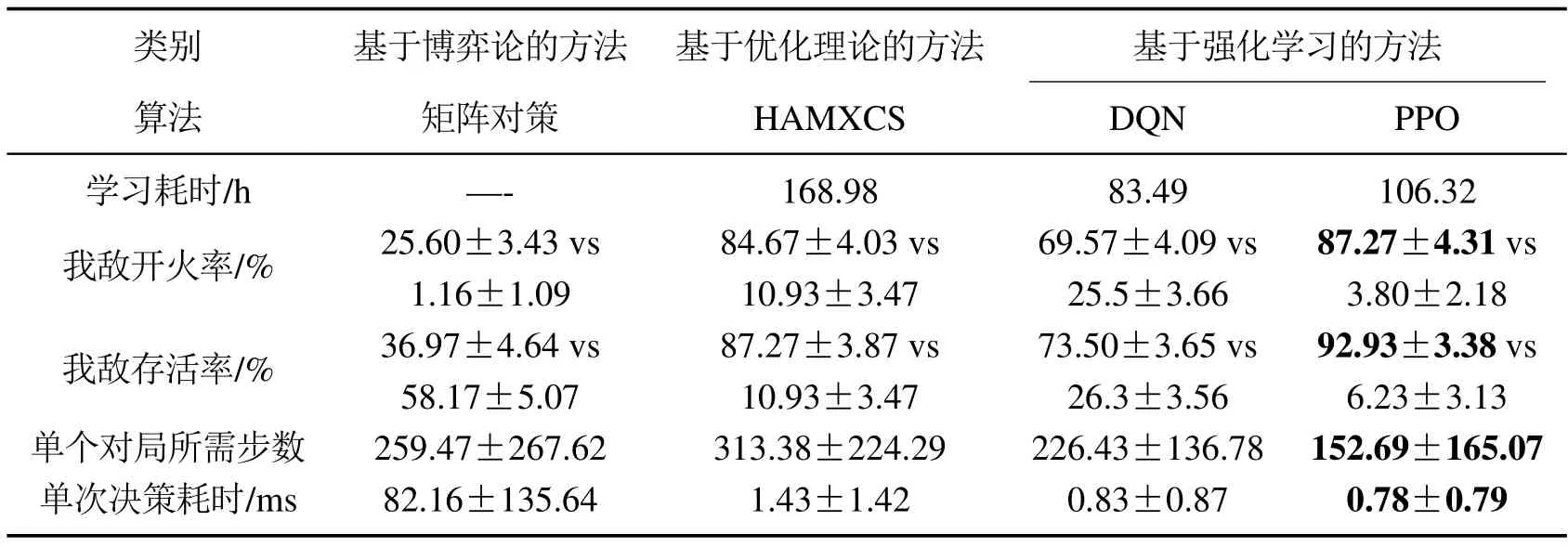
表3 固定初始态势下不同类型方法在1v1空战任务中的性能对比Table 3 Performance comparison of different methods in 1v1 air combat with fixed initial situations
从表3中可以看出,矩阵对策的最大优势在于其不需要预先训练模型,但其在线对抗性能较差,我机开火率和存活率最低,单步决策耗时最长,在实际更为复杂的应用中难以保证实时性.另一方面,由于每个决策时刻敌机以获取最大态势优势为目标执行动作,而使用矩阵对策的我机以Minmax原理为决策依据,因此对敌机行动做出了准确预测.虽然此时我机对抗性能较差,但与其对抗的敌机在所有对比算法中获得的开火机会最少,开火率仅约为1.2%.基于遗传学习系统的HAMXCS集成了遗传算法模块和RL模块,模型训练所需时间最长,在线对抗性能略弱于PPO,但其学习后的决策模型具有一定的可解释性.HAMXCS每个决策时刻不需要在解空间内搜索,只需匹配学习后的规则集,因此克服了传统基于优化理论的方法实时性差的问题,但与基于RL的算法相比仍有差距.在线应用阶段,基于RL的方法在决策效率方面表现出了明显优势,单次决策平均耗时在1 ms以内.所有对比方法中,PPO的对抗性能最优,开火率超过87%,存活率约为93%.
为进一步说明基于RL类方法(以表3中性能最好的PPO为例)的优势,在决策模型应用阶段对敌我双方初始态势添加随机因素.具体地,每回合开始时我机在[90 km 80 km 3 km]~[130 km 120 km 7 km],敌机在[75 km 80 km 3 km]~[115 km 120 km 7 km]空间内随机产生,敌我两机初始航迹偏转角为0°~180°内的随机值,其余设定保持不变,对抗后各方法性能对比如表4 所示.对比表3和表4中的结果可以看出矩阵对策在两种设定下性能基本一致,PPO在两种初始态势下均有较好的性能表现,而HAMXCS在随机初始态势场景下性能损失明显.上述结果表明,RL类算法通过与环境交互可以获得具有一定泛化能力的决策模型,与其他类方法相比在对抗性能和决策效率方面优势明显.

表4 随机初始态势下各方法在1v1空战任务中的性能对比Table 4 Performance comparison of different methods in 1v1 air combat with random initial situations
6 下一步研究展望
第4节中传统方法(除RL外的其他方法)在自主空战机动决策的应用中普遍存在: 1)强烈依赖专家知识或有标签的数据;2)需要准确、完备的态势评估模型;3)求解复杂、实时性差等问题.对应上述技术短板,基于DRL方法的优势主要体现在: 1)通过与环境交互进行试错学习,不依赖专家规则库或大量有标签的训练样本,避免了大量规则梳理工作的同时,在各种态势输入下的适应性强,避免了决策失效的问题;2)策略学习具有自主性,不需要构建复杂的状态转移方程和完备的态势评估模型;3)决策时不需要通过试探机动[80]或优化搜索等方式在解空间内寻找最优机动动作,训练后的RL策略模型可以根据空战态势信息实现实时决策,且具有长期战术规划能力[29];4)策略模型具备持续学习能力,其为新战术战法探索、作战方案优化提供了新思路,而新战法又可以反哺新型作战飞机的设计[22].
鉴于上述优势,DRL结合博弈对抗理论的自主空战机动决策方法逐渐成为目前研究的主要方向.同时,近年来计算机硬件技术的不断发展为DRL类算法处理复杂的空战机动决策问题提供了算力保障.综合上述研究现状和总结分析,下一步自主空战机动决策方法的研究可以从以下几个方面入手.
6.1 研究融合空战领域先验知识的学习框架
如前所述,DRL任务通过与环境充分试错交互,获取大量数据进行离线或在线学习,即使简单的环境也需要数以万计的数据,巨大的样本复杂度限制了DRL在自主空战机动决策中的应用效果.与此同时,空战对抗环境状态空间连续且奖励稀疏,单纯从零学习(learning from scratch)最优策略十分困难.相比之下,人类在面对复杂任务时都是在已有知识的基础上再学习.在学习中有效融合战法战例、专家和飞行员经验等,是加速策略学习的有效手段.这些知识作为初始策略可能并不完全适用于新任务,但有效避免了冷启动和学习初期不必要的“探索”过程.
首先,需要解决领域内先验知识形式化描述与存储的问题.人与神经网络之间的认知方式存在较大差异,自然语言描述的知识或符号化的规则难以被DRL决策模型融合与理解.另一方面,空战领域知识复杂零散、不同类型知识描述格式差异大.因此,需要制定标准将空战机动决策领域内作战规则与条令、空战专家知识(如,典型机动动作)以及飞行员经验描述为形式统一的格式化规则,并通过领域知识图谱等方式进行管理.
同时,将上述知识引入DRL与对抗环境的交互回路,从而实现跨认知层次上知识的相互补充,最终引导策略学习是关键.文献[206]提出将基于BDI的认知行为模型与DRL融合,实现了认知行为知识基础上的持续学习.然而,该研究仍集中在1v1和1v2的空战场景中,未能发挥基于BDI的智能体编程语言在多智能体协作任务中优势.借助其消息通信机制提高基于DRL的多机协同对抗效率是下一步值得研究的问题.
6.2 探索具有可解释性机动决策模型的学习方法
基于DRL的策略模型是一个“黑箱”,人类难以理解其中的规则映射关系,限制了其应用在金融、军事等对安全性和可解释性要求较高的领域.空战机动决策领域专业知识复杂,若要建立可靠的人机互信机制,决策模型的可解释性是未来研究中必须解决的难题.
目前基于DRL的自主空战研究大多集中于学习高效且准确的对抗策略,而对于机动决策模型的可解释性关注较少.一方面应继续探索深度神经网络模型“黑箱”的内在机理与诠释方法.另一方面,参考双边对抗学习系统[22]的策略更新机制,在学习规则系统(learning classifier system,LCS)框架的基础上开展相关研究是获得可解释机动决策模型的可行思路.具体地,LCS整合了GA和RL的优势,其中,GA负责新规则产生与演化,而RL负责规则参数更新.若将LCS框架扩展至博弈对抗环境,使用二进制或实数对态势信息编码,在保证我机对抗性能的同时,演化具有准确性、泛化性和可解释性的规则库,进而能够获得可理解的机动决策模型.然而,该方法的缺陷在于其策略学习效率与DRL相比仍有较大差距,且目前没有成熟的算法框架和硬件加速方法.同时,规则库规模也是影响模型对抗性能和算法收敛速度的重要因素.
另一种思路是将DRL方法与其他可解释性强的方法(如,基于博弈论的方法)相结合,使其作为决策过程的一环,例如,某态势下执行的战术动作由可解释模型获得,而油门及各舵面控制量的输出由学习模型计算.
6.3 构建实战条件约束的对抗实验环境
实际空战机动环境复杂度高,对抗态势瞬息万变,决策模型需要在短时间内融合大量机载传感器和地面站获取的态势信息并做出合理决策.现有研究基本假设空战环境及敌机信息完全透明,忽略信息处理和融合所需时间.同时,假设敌机实时位置、速度甚至姿态角度均已知,并依赖上述信息构造敌我相对态势作为学习模型的输入.然而,在实际空战中,由于雷达等电子对抗设备的干扰以及天气的影响,战场环境是不完全可观测的.此时,空战对抗属于不完美信息博弈,获取的敌机信息很可能是不连续的甚至是带有欺骗性的,而完全依赖敌机私有信息构造态势输入的决策模型将失效.数字孪生技术是缓解上述问题的可行思路,其通过构建与真实战场环境要素(如,战场环境、武器装备、作战行为等)相一致的高逼真仿真模型,为自主空战机动决策模型训练与验证提供实验环境支撑,可以有效缓解DRL模型从仿真到现实(sim to real)[208]部署困难的问题.另一方面,孪生系统可以通过超实时多分支推演预测给定态势下执行不同动作(序列)的效果,从而为决策模型评估提供有效支撑.
其次,现有研究大多假设敌机轨迹固定或策略单一,仅针对特定的对手开展对抗策略学习或借鉴自博弈机制学习一个具有泛化性的对抗策略.然而,在高强度对抗的条件下,敌机的策略可能会实时发生变化,例如,若将敌机飞行员的空战知识和战斗经验看作敌机策略库,其在对抗过程中根据当前战场态势和作战目标从策略库中选取策略执行,这时,如果我机仍使用单一策略或通过在线学习的方式求解,应对策略则难以保证决策的实时性和准确性.针对上述需求,研究不完全可观测环境下的对手建模[209]技术,并将其与策略重用方法结合用于快速、准确检测敌机策略类型,并重用己方策略库是解决该问题的有效途径.
此外,如前所述,现有基于DRL的多机对抗研究基本都先通过目标分配转化为1v1对抗,未在对抗中有效考虑多机协作机制.然而,1v2、2v2甚至更大规模的编队间空战是目前主要的作战样式.若要将对抗规模进一步扩展,多机对手建模、信度分配、多机策略识别、奖励函数设计等都是需要着重考虑的问题.
6.4 建设高效权威的模型训练与验证支撑平台
现有算法的性能验证大多在自研模型和平台上开展,不同研究间对抗环境设计及战机的动力学模型和运动学模型差异大.虽然从实验结果上都有一定的说服力,但算法间横向性能对比困难,改变对抗环境或战机模型可能导致算法性能下降甚至失效.因此,建设高效权威的自主空战机动决策模型训练与验证平台是当前亟待解决的问题之一.
首先,需要解决战机模型准确度的问题.现有研究中,战机建模主要有三自由度模型、六自由度模型和四元数模型等,各类模型简化程度和动力学约束又有差异.同时,这些模型与战斗机实装还有较大差距,性能参数设置不够真实合理.若要获得准确可靠的机动决策策略,战机和环境模型的准确性是基础.
同时,需要明确平台的设计与开发架构.平台应采用面向服务的架构,将模型学习训练任务放在后台服务器,而前台采用灵活、可视化效果好的轻量级代码以降低对客户端硬件的要求.空战对抗环境的接口应采用类似OpenAI gym wrapper风格的包装器[210],以适配主流DRL算法与环境的交互方式.同时,对抗环境模型、战机模型、算法模型、模型配置文件与对抗平台之间应采用模块化松耦合的集成方式,支持格式化的模型添加与配置,从而不断丰富和完善空战对抗环境和装备模型库.
此外,需要考虑模型训练过程的优化.平台应通过可视化渲染引擎,支持从二维和三维视角展示敌我双方的对抗轨迹和姿态变化,以便于对抗策略验证.其次,平台应支持仿真速率调整和场景渲染开关,从而缓解学习训练速度与对抗过程可视化之间的矛盾.此外,应支持从客户端监测服务端模型的训练进度,并支持训练结果回收本地,从而保证模型训练质量.
最后,需要研究模型训练产生数据的再利用.敌我双方对抗产生的大量数据中隐含了各自的行为序列模式.平台应集成数据挖掘算法,从交互数据中挖掘人类可理解的潜在知识,从而为优化我机对抗策略和探索新战术战法提供新思路.
7 总结
本文首先剖析了自主机动决策在超视距和视距内空战中的重要意义.其次,分析总结了自主空战机动决策在现代化空战及未来发展中的作用和地位.然后,对现有空战决策建模和求解方法进行了分类,详细梳理了每一类方法的发展脉络、研究分支以及代表性方法,总结了每种方法的优势和缺陷,并在典型对抗场景中对比了不同类型方法的性能差异和特点.同时,对比传统方法,阐述了DRL类方法的优势,并得出DRL结合博弈对抗理论的自主空战机动决策方法将是未来研究的重点.最后,从融合先验知识、决策模型可解释性、仿真对抗环境逼真度以及训练验证支撑平台建设等角度展望了下一步值得研究和探索的方向.
