基于生成对抗网络和注意力机制的医学图像超分辨率重建
2023-02-08冉文兵梁永超
冉文兵,梁永超,覃 芹,陈 旋,张 利,2
(1 贵州大学 大数据与信息工程学院;2 贵州大学 省部共建公共大数据国家重点实验室,贵阳 550025)
0 引言
在临床医学中,电子计算机断层扫描(CT)技术是利用X 射线对人体进行照射,并结合高精度的探测器检测射线能量的衰减情况,实现对人体内部的患病部位进行快速成像。但是由于临床CT 设备的分辨率、噪声和人体所能承受的辐射量等因素的限制,以及数据存储过程中信息丢失,导致在医学诊断中难以获得足够的病理信息。为了解决这一问题可以对成像设备进行提升或设计更好的软件算法,但更新成像设备的代价较大。因此,通过使用相关算法实现CT 图像的超分辨率重建(SR)具有重要意义。
超分辨率重建技术最早出现在光学工程领域,是指从低分辨率(LR)图像重建出高分辨(HR)图像[1]。1984 年Tsai 等人[2]提出基于频域的超分辨重建技术,使用多帧LR 图像重建单帧HR 图像。目前,关于图像超分辨率重建技术大致可以分为基于插值、重建模型以及深度学习3 大类。插值方法主要包括临近插值、双三次插值和双线性插值等,这类方法重建的速度快,但重建图像存在模糊和伪影;重建模型主要包括迭代反投影(IBP)和凸集投影法(POCS)等,这类方法对于图像中细节部分的重建需要引入大量的先验知识;基于深度学习的重建方法比基于插值和重建模型的重建效果好很多,并且能够实现LR 图像到HR 图像端到端映射,是目前用于图像超分辨率重建的主流方法。
2014 年,Dong 等人[3]首次提出使用深度学习技术用于图像的超分辨率重建,通过使用包含特征提取、非线性映射和图像重建3 个部分的卷积神经网络实现单幅图像的超分辨率重建,但容易产生棋盘伪影;2017 年,Ledig 等人[4]提出一种基于生成对抗网络(GAN)和残差学习的超分辨重建生成对抗网络(SRGAN),并使用一个由对抗损失和内容损失组成的损失函数,解决了在较大缩放因子情况下的图像细节纹理的恢复问题;为了进一步提升图像的重建质量,2018 年,Wang 等人[5]对SRGAN 中的损失函数进行改进,并引入没有批归一化的残差中的残差密集块(RRDB)作为网络的基本单元,提出了增强的SRGAN(ESRGAN)。这些方法在自然图像的超分辨率重建中取得较好的效果。与此同时,Zheng等人[6]基于CycleGAN提出一种无监督的GAN 实现CT 图像的超分辨率重建,在结构相似性(SSIM)上取得一定的提升。本文的目标是基于GAN 和注意力机制提出一种有效的医学图像超分辨率重建方法,并在SRGAN 的损失函数的基础之上引入全变分损失改善图像细节纹理的重构。除此之外,使用退化学习方法模拟图像的退化过程,弥补传统退化模型的缺陷,使本文方法更具有现实意义。
1 相关理论
1.1 生成对抗网络
2014 年,Goodfellow 等人[7]首次提出生成对抗网络,是一种通过博弈过程估计生成的模型架构。GAN 主要由生成器和鉴别器组成,模型结构如图1所示,生成器将输入的随机噪声或样本数据进行处理后输出;鉴别器则将生成器的输出和真实的数据进行对比和判断生成器输出的真实性。通过生成器与鉴别器之间的相互对抗,最终生成器与鉴别器之间达到纳什均衡状态,并使得生成器产生的图像逐渐趋于真实图像。GAN 与受限玻尔兹曼机(RBM)、生成随机网络(GSN)和深度信念网络(DBNs)等生成模型相比,具有较好的图像生成能力,故在图像风格迁移、图像合成、超分辨率重建和去噪等领域得以广泛应用。尤其在图像的超分辨率重建中,GAN 在学习流行之间的映射有很好的效果,在一定程度上可以防止重建图像的高频细节和图像纹理缺失,以及图像平滑等问题[8]。
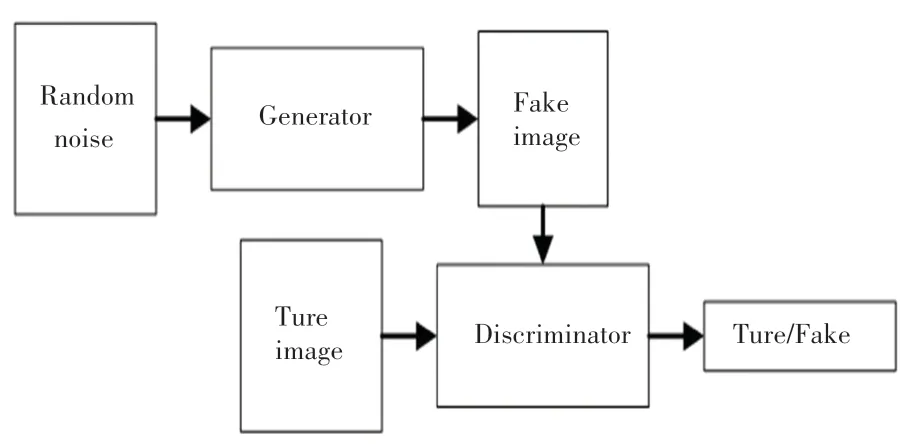
图1 生成对抗网络模型Fig.1 Generate adversarial network models
1.2 注意力机制
在生物的视觉系统中,对视场内的聚焦是有所区别的,通过关注场景中的关键区域获取有价值的信息,这种视觉特性在深度学习中也得到广泛应用。在深度学习中,注意力机制的实现主要通过权重掩膜标识出图像中的特殊区域。目前根据关注的细粒度可以划分为两大类:硬注意力机制和软注意力机制。软注意力机制在计算过程中具有可微性,因此,相对于硬注意力机制训练难度较小。Hu 等人[9]提出一种简单有效且开销小的通道注意力机制模块SENet,可以自适应地校准通道级的特征响应;Roy等人[10]提出一种空间注意力机制,对空间特征进行压缩和激发,实现在空间中校准特征映射。除此之外,大量的研究表明,通过共同利用空间注意力机制和通道注意力机制可以提高网络的重构性能。如:Woo 等人[11]将通道注意力机制与空间注意力进行级联,提出卷积块注意力模块(CBAM),该模块先将输入特征通过通道注意力机制得到通道权重掩膜并与输入特征相乘,然后将结果与通过空间注意力机制获取空间权重掩膜相乘得到最终的输出特征。
受到以上研究的启发,本文提出一种能够实现医学图像超分辨率重建的网络模型,通过使用残差特征提取模块和CBAM 模型在图像的特征空间中进行特征提取和筛选,以减少冗余信息的学习和参数量,提升网络的性能和重建效果。
1.3 模拟观测
在一般的图像超分辨率重建过程中,通常是将原始的高分辨率图像通过模糊、降采样和加噪等方法进行处理,得到与原始高分辨率图像对应的低分辨率图像,最终得到理论退化模型数据集(X,Y),x表示理论模型模拟的低分辨率图像,具体过程可以由式(1)表示为
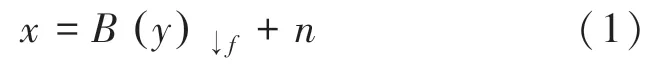
其中,y表示原始的高分辨率图像;↓f表示尺度因子为f的双三次降采样操作;B为高斯模糊算子;n为方差σ =0.025 的高斯噪声。
式(1)可以简化为

其中,H(·) 为退化核。
但通过这种方式模拟的LR 图像对真实场景中的噪声和压缩等因素的反映是明显不足的,而且实际生活中很难得到HR 图像和LR 图像之间完全对应的数据集。为了解决这一问题,采用未配对的原始图像集,将HR 图像通过DSGAN 进行退化学习模拟真实场景的LR 图像得到退化学习数据集后用于超分辨率重建,具体过程如图2 所示。x为实际的LR 图像且与HR 图像y并无映射关系,将HR 图像经过下4 倍采样的LR 图像s,使用DSGAN模型和LR 图像x对图像s进行矫正得到更符合真实场景的LR 图像
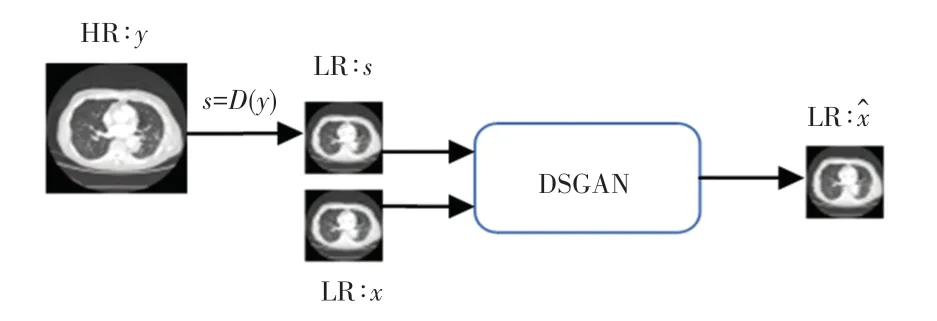
图2 使用DSGAN 模型模拟LR 图像的具体过程Fig.2 DSGAN model is used to simulate the specific process of LR image
2 模型结构
2.1 本文模型
目前,大多数基于深度学习的超分辨重建技术,在医学图像上重建的结果过于模糊且缺失大量的细节纹理,利用GAN 较强的拟合能力可以在一定程度上解决这一问题。SRGAN 通过使用深度残差网络,能够提取自然图像中更丰富的细节信息,其生成器中的残差结构如图3(a)所示。基于本文的应用背景,对SRGAN 生成器和鉴别器进行优化。在生成器的残差模块中,由于批量归一化层(BN)增加模型的计算复杂度和开销,故在本文所使用的残差结构中将其去除,仅保留卷积层和PReLU 层,并引入CBAM 混合注意力模块,组成具有通道和空间注意力的残差块,称之为RES-CB,如图3(b)所示。
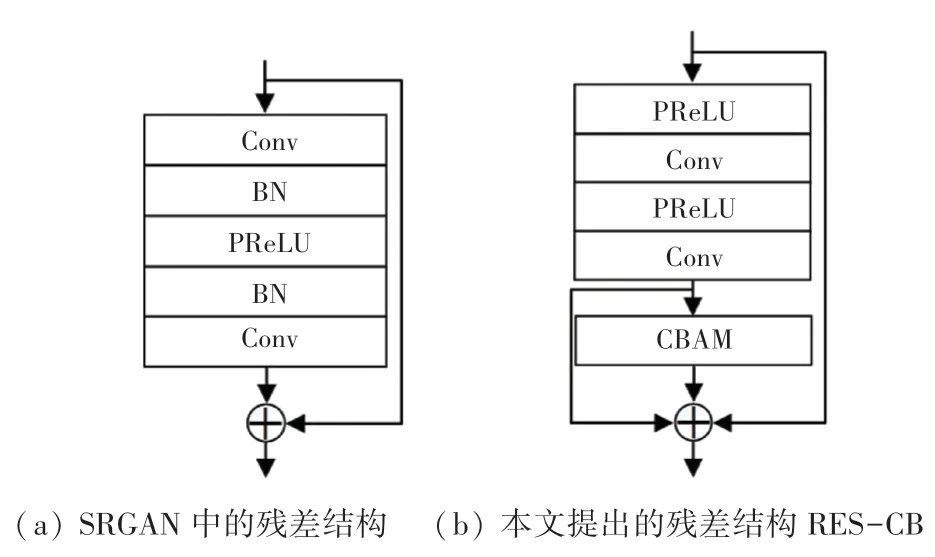
图3 两种残差结构对比Fig.3 Comparison of two residual structures
生成器主要由5 个RES-CB 模块堆叠而成,具体结构如图4 所示。输入图像通过退化学习或理论模型模拟的LR 图像,经过采样因子f为2、3 和4 的上采样,再使用5×5 的卷积,5 个RES-CB 模块,5×5 的转置卷积层(Tconv)和投影层(Proj)[12]处理后,与只经过上采样的图像相加,最后通过剪切层(Clipping)将图像中的像素值约束在0~255 之间得到重建后的SR 图像其中,Proj 层主要用于计算近端映射和数据的保真度,并在反向传播的过程中会对该层的参数进行微调。
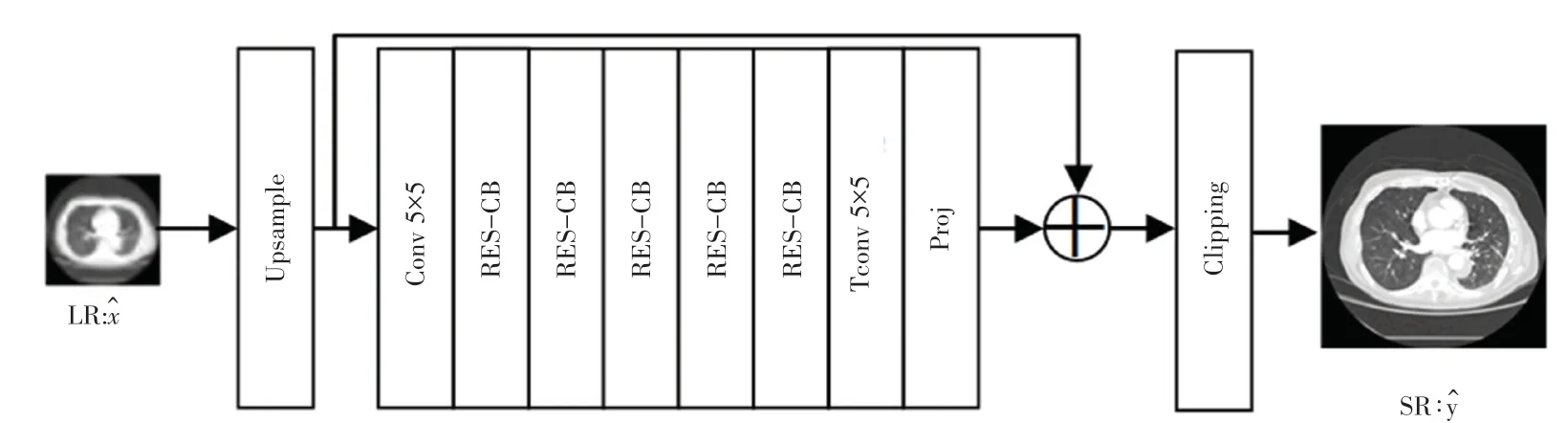
图4 生成器模型结构Fig.4 Generator model structure
鉴别器网络用于区分真实的HR 图像和虚假的SR 图像结构,如图5 所示。鉴别器主要由7 个卷积特征提取块(Conv、BN 和LReLU)组成,各个特征提取块中的卷积层由卷积核大小为4,步长为2 以及卷积核大小为3 步长为1 的卷积交替构成,能够把特征映射从64 增加到512,在鉴别器的末端,通过两个全连接层和Sigmoid 函数得到最后的鉴别结果。
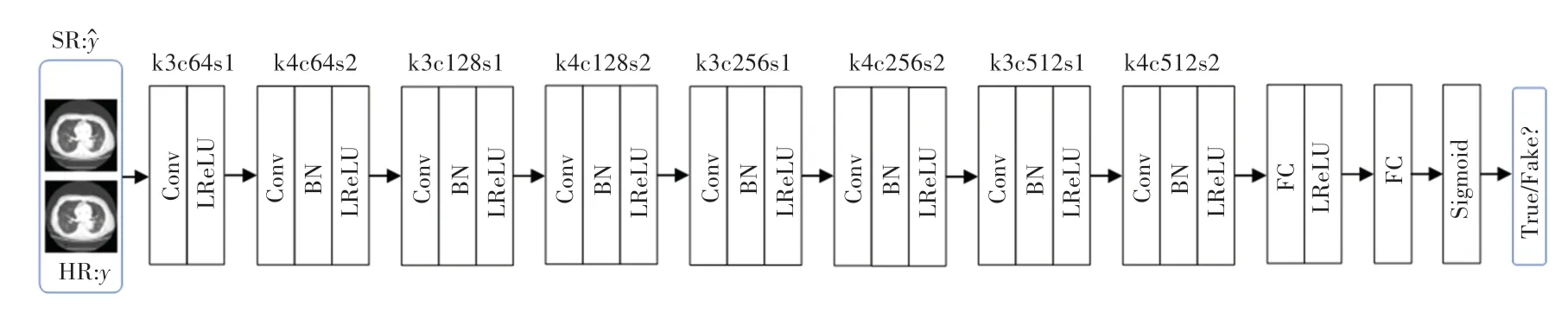
图5 鉴别器模型结构Fig.5 Discriminator model structure
2.2 损失函数
为了使用本文提出GAN 模型能够实现医学图像的超分辨率重建,使用以下损失函数计算重建误差并指导模型的优化。
感知损失(LPER):使用预训练的VGG-19 网络分别对HR 图像和SR 图像进行特征提取,计算二者之间的欧式距离,以此来关注图像的感知质量,公式为
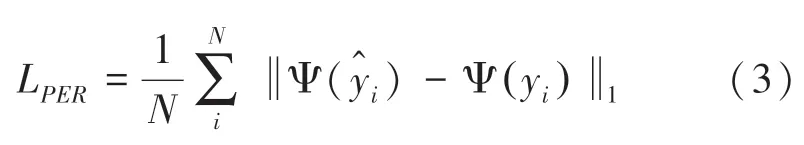
其中,yi表示第i张真实的HR 图像表示第i张重建的SR 图像;Ψ(·) 为VGG-19 预训练网络所提取到的特征;N为模型训练中小批量大小。
对抗损失(LADV):使用鉴别器对真实的HR 图像和生成的SR 鉴别结果,对生成器进行约束,以提升重建图像的视觉效果。公式为
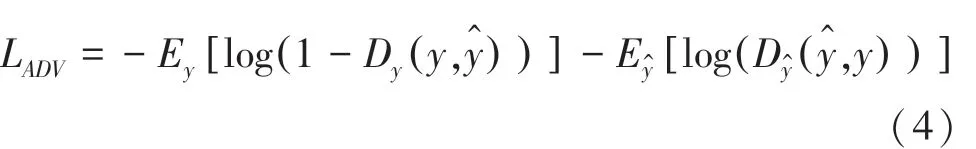
其中,Ey和分别是对小批量的HR 图像和SR 图像求取均值,通过鉴别器Dy求取生成的SR 图像与真实的HR 图像之间的差距。
像素级MSE 损失(L1):在图像超分辨重建中,经常使用MSE 计算虚假的SR 图像和真实的HR 图像之间的像素级距离,以此来对生成器的训练进行约束,公式(5)为
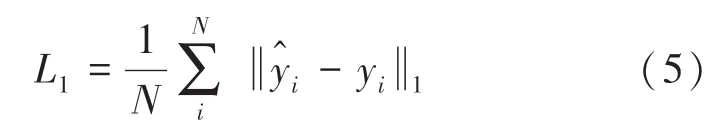
全变分损失(LTV):主要可以使图像中梯度变化较小的区域,产生一定的锐度,在一定程度上提升图像的细节纹理,公式(6)为
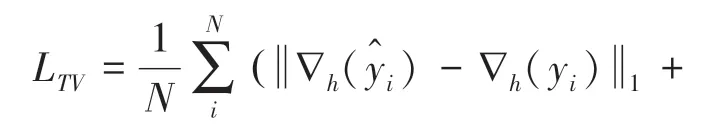
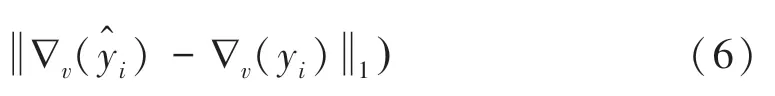
其中,∇h和∇v分别为水平和垂直梯度算子。
最终模型训练所使用的损失函数为
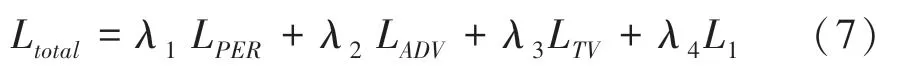
其中,λ1、λ2、λ3和λ4为各部分损失的权重,其值分别为1、1、1 和10。
3 实验分析
3.1 实验数据集
本文实验数据采用公开的肺结节患者的胸部CT 图像数据集LIDC-IDRI,从中选取纹理清晰、结构复杂的550 张图像,其中400 张作为训练集,100张作为验证集,50 张作为测试集。原始数据集中的LR 图像集与HR 图像集并无一一对应关系。在训练之前,通过公式(1)的理论模型得到与HR 图像具有映射关系的理论退化模型数据集 (X,Y) ;通过将HR 图像下采样从理论上模拟LR 图像s,通过LR图像x和DSGAN 生成LR 图像得到退化学习的数据集
3.2 参数设置
表1 实验环境Tab.1 Experimental environment
3.3 实验结果与分析
首先将本文提出的重建模型与其它重建模型Bicubic、SRCNN、SRGAN、ESRGAN 进行尺度因子为4 的重建对比,实验结果见表2。在理论退化模型数据集上,本文的重建模型相比于Bicubic、SRCNN、SRGAN 和 ESRGAN 在PSNR上 分 别 提 升 了3.38 dB、2.54 dB、1.47 dB 和0.74 dB,在SSIM上分别提升了0.087 4、0.033 9、0.038 0 和0.046 6,验证了本文的重建模型相对于其他重建模型能够更好地完成CT 图像的重建;在退化学习数据集上,本文的重建方法的PSNR达到了28.98 dB,SSIM达到了0.864 2。通过对比几种重建方法分别在两种数据集上的重建指标结果,表明本文的重建方法不仅在传统的理论退化模型的LR 图像上得到不错的效果,还在使用退化学习模拟CT 成像和存储过程中受到图像退化后的LR 图像上也能取得很好的效果。
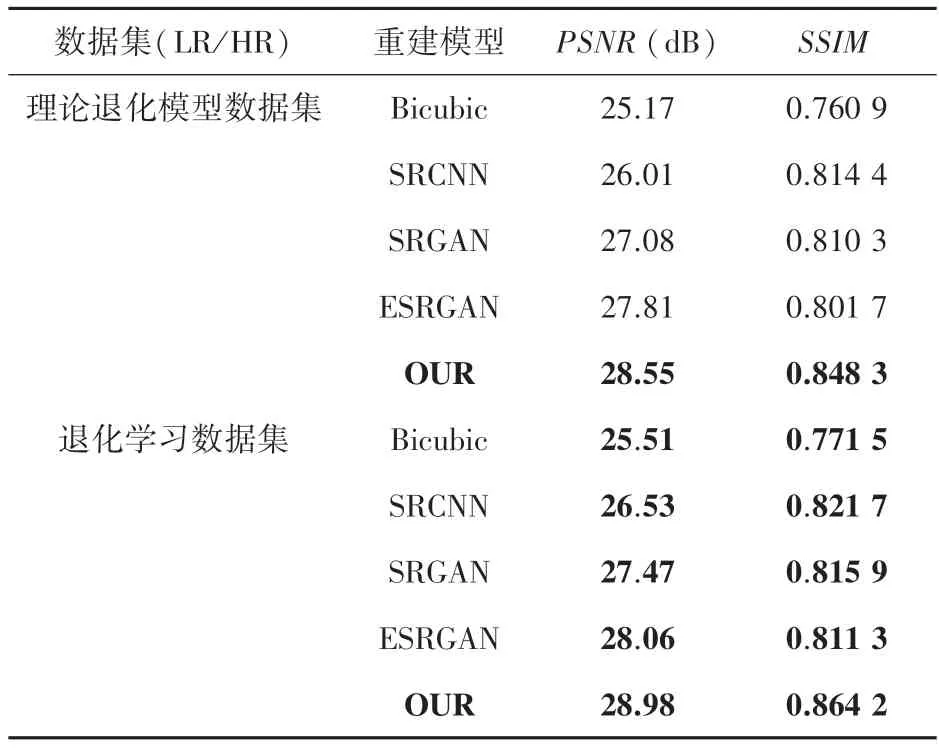
表2 不同重建方法在理论退化模型数据集和退化学习数据集上的实验结果对比Tab.2 Comparison of experimental results of different reconstruction methods on theoretical degenerate model dataset and degenerate learning dataset
为了定性分析几种方法重建的图像质量,给出了5 种重建方法在退化学习数据集上,进行尺度因子为4 的重建结果,如图6 所示。图6(a)为原始的HR 图像,图6(b)为通过Bicubic 重建的图像,图6(c)为通过SRCNN 重建的图像,图6(d)为通过SRGAN 重建的图像,图6(e)为通过ESRGAN 重建的图像,图6(f)为本文提出模型的重建结果。从图6 可以看出,Bicubic 和SRCNN 的结果过于模糊,且在组织结构的分界线上较为平滑;SRGAN 在组织的边界有明显的伪影;ESRGAN 的结果在组织边界较为尖锐且引入大量的噪声;本文提出的模型在这几种方法中的重建效果较为突出,但是与原始的HR图像相比,对于细节纹理的重建仍然略显不足。
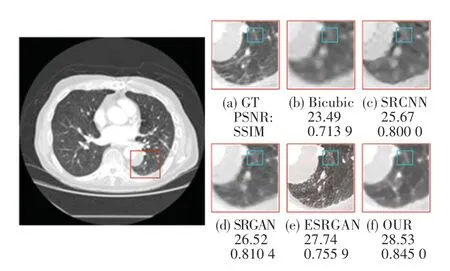
图6 5 种方法重建的CT 图像对比Fig.6 Comparison of CT images reconstructed by five methods
本文的重建方法可以实现不同尺度因子的超分辨重建,不同尺度重建的结果见表3。除了使用PSNR和SSIM分析重建图像质量,还使用学习感知图像块相似度(LPIPS)对重建图像感知质量进行比较。LPIPS的值越小,说明图像的感知质量越好。LPIPS在重建尺度因子为4 的LPIPS比×2 和×3 分别高出了0.091 5 和0.080 9。下采样因子为2、3 和4 的LR 图像和通过本文重建方法得到的SR 图像,如图7 所示。尺度因子较小的LR 图像保留的信息较多,通过对重建的图像进行对比,尺度因子为2 的SR 图像中的细节更为清晰。
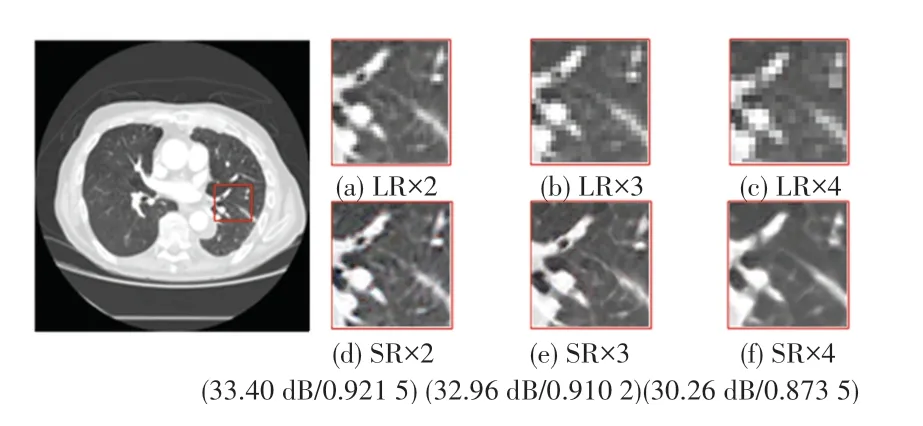
图7 不同尺度因子重建的CT 图像对比Fig.7 Comparison of CT images reconstructed with different scale factors
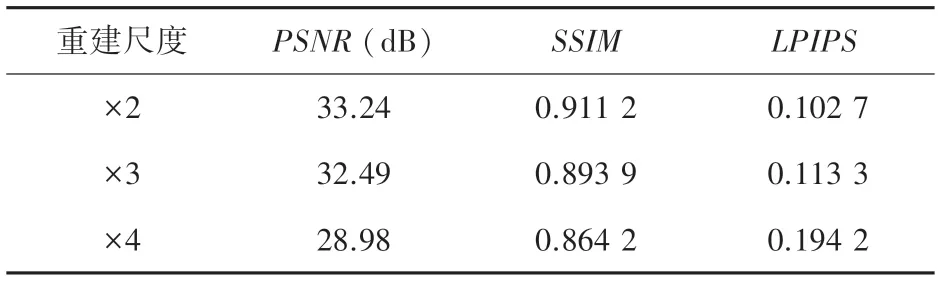
表3 本文的方法在退化学习数据集上进行不同尺度重建的实验结果对比Tab.3 The method in this paper compares the experimental results of reconstruction at different scales on degenerate learning datasets
经过上述的客观指标评价和主观视觉分析,可见本文提出的超分辨重建算法,在CT 图像的重建中具有一定的优越性,从而证明了本文提出网络模型和数据模拟方法的有效性。本文使用退化学习算法可以对真实场景的LR 图像进行模拟,让重建方法更具有现实意义;通过混合注意力机制从空间和通道两方面对指导特征有选择性地学习,提高网络性能和训练效果。
3.4 消融实验
为了充分证明CBAM 和全变分损失(LTV)在本文方法中的重要性和效果,在消融实验中将对这两部分进行定量分析。通过在退化学习数据集进行4组尺度因子为4 的对比实验,结果见表4。通过比较第1 组和第4 组实验,本文网络模型通过结合CBAM 和LTV使得PSNR和SSIM分别提升了0.62 dB和0.025 8,LPIPS降低了0.024 8。说明将CBAM 和LTV加入到本文的网络模型中,对医学图像的超分辨率重建是有效的。
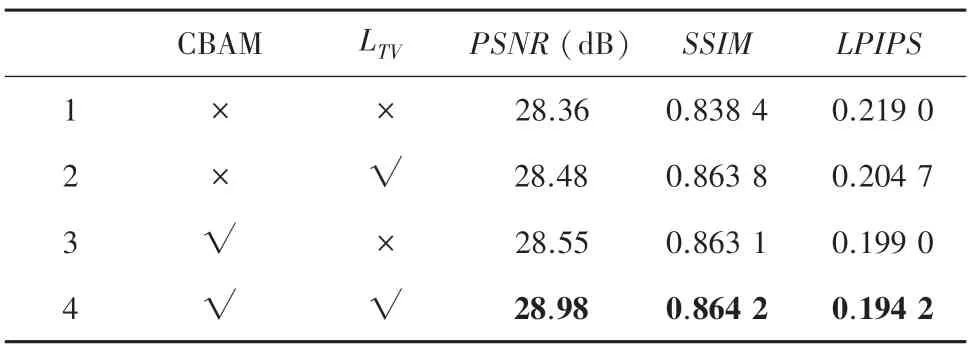
表4 对CBAM 和LTV进行消融实验的结果对比Tab.4 The results of ablation experiments were compared between CBAM and LTV
4 结束语
本文提出了一种用于医学图像超分辨率重建的深度学习方法,主要通过改进的SRGAN 模型中的残差特征提取模块,并将其和混合注意力机制CBAM 相结合,提出具有通道和空间注意力的残差特征提取模块。使用该模块构建GAN 的生成器在对人体胸部CT 图像进行超分辨率重建可以取得较好的效果。此外,通过退化学习模拟低分辨率数据,解决传统退化模型的局限性。通过将几种常用的超分辨重建方法与本文的方法进行对比分析,验证了该方法在医学图像超分辨重建方面具有一定的潜力。在未来的工作中,仍然需要探索更好的方法解决大尺度重建的部分细节丢失问题,以及需要使用更好的定量评估方法分析医学图像超分辨重建效果。
